上一节我们已经知道,shouldComponentUpdate 是我们进行性能优化的利器,我们之后的优化方案都会基于它来进行。
# 优化方案一:PureComponent (memo) 进行浅层比较
上一节我埋下了一个伏笔,就是 PureComponent 或者 memo 将会进行新旧数据的浅层比对。你可能会比较好奇,浅层比较是怎么比较的呢?口说无凭,我觉得让大家直观地感受一下比较重要,所以我暂且扒出 PureComponent 浅比较部分的核心源码让大家体会一下,大家不用紧张,其实逻辑非常简单。
function shallowEqual (objA: mixed, objB: mixed): boolean {
// 下面的 is 相当于 === 的功能,只是对 + 0 和 - 0,以及 NaN 和 NaN 的情况进行了特殊处理
// 第一关:基础数据类型直接比较出结果
if (is (objA, objB)) {
return true;
}
// 第二关:只要有一个不是对象数据类型就返回 false
if (
typeof objA !== 'object' ||
objA === null ||
typeof objB !== 'object' ||
objB === null
) {
return false;
}
// 第三关:在这里已经可以保证两个都是对象数据类型,比较两者的属性数量
const keysA = Object.keys (objA);
const keysB = Object.keys (objB);
if (keysA.length !== keysB.length) {
return false;
}
// 第四关:比较两者的属性是否相等,值是否相等
for (let i = 0; i < keysA.length; i++) {
if (
!hasOwnProperty.call (objB, keysA [i]) ||
!is (objA [keysA [i]], objB [keysA [i]])
) {
return false;
}
}
return true;
}
从我写的注释可以看出,在这里开启了四道关卡,但终究还是浅层比较。在下面的情况会判断失灵。
// 调用 state.a.push("2")
state: {a: ["1"]} -> state: {a: ["1", "2"]}
其实 a 数组已经改变了,但是浅层比较会表示没有改变,因为数组的引用没有变。看到没有?一旦属性的值为引用类型的时候浅比较就失灵了。
这就是这种方式最大的弊端,由于 JS 引用赋值的原因,这种方式仅仅适用于无状态组件或者状态数据非常简单的组件,对于大量的应用型组件,它是无能为力的。
# 优化方案二:shouldComponentUpdate 中进行深层比对
为了解决方案一带来的问题,我们现在不做浅层比对了,我们把 props 中所有的属性和值进行递归比对。
我们把上面浅层比对的代码进行一些魔改:
function deepEqual (objA: mixed, objB: mixed): boolean {
// 下面的 is 相当于 === 的功能,只是对 + 0 和 - 0,以及 NaN 和 NaN 的情况进行了特殊处理
// 第一关:保证两者都是基本数据类型。基础数据类型直接比较出结果。
// 对象类型咱就不比了
if (objA == null && objB == null) return true;
if (typeof objA !== 'object' &&
typeof objB !== 'object' &&
is (objA, objB)) {
return true;
}
// 第二关:只要有一个不是对象数据类型就返回 false
if (
typeof objA !== 'object' ||
objA === null ||
typeof objB !== 'object' ||
objB === null
) {
return false;
}
// 第三关:在这里已经可以保证两个都是对象数据类型,比较两者的属性数量
const keysA = Object.keys (objA);
const keysB = Object.keys (objB);
if (keysA.length !== keysB.length) {
return false;
}
// 第四关:比较两者的属性是否相等,值是否相等
for (let i = 0; i < keysA.length; i++) {
if (
!hasOwnProperty.call (objB, keysA [i]) ||
!is (objA [keysA [i]], objB [keysA [i]])
) {
return false;
} else {
if (!deepEqual (objA [keysA [i]], objB [keysA [i]])){
return false;
}
}
}
return true;
}
当访问到对象的属性值的时候,将属性值再进行递归比对,这样就达到了深层比对的效果。但是想想一种极端的情况,就是在属性有一万条的时候,只有最后一个属性发生了变化,那我们就不得已将一万条属性都遍历。这是非常浪费性能的。
# 优化方案 3: immutable 数据结构 + SCU (memo) 浅层比对
回到问题的本质,无论是直接用浅层比对,还是进行深层比对,我们最终是想z知道组件的 props (或 state) 数据有无发生改变。
在这样的条件下,immutable 数据应运而生。
# 什么是 immutable 数据?它有什么优势?
immutable 数据一种利用结构共享形成的持久化数据结构,一旦有部分被修改,那么将会返回一个全新的对象,并且原来相同的节点会直接共享。
具体点来说,immutable 对象数据内部采用是多叉树的结构,凡是有节点被改变,那么它和与它相关的所有上级节点都更新。
用一张动图来模拟一下这个过程:
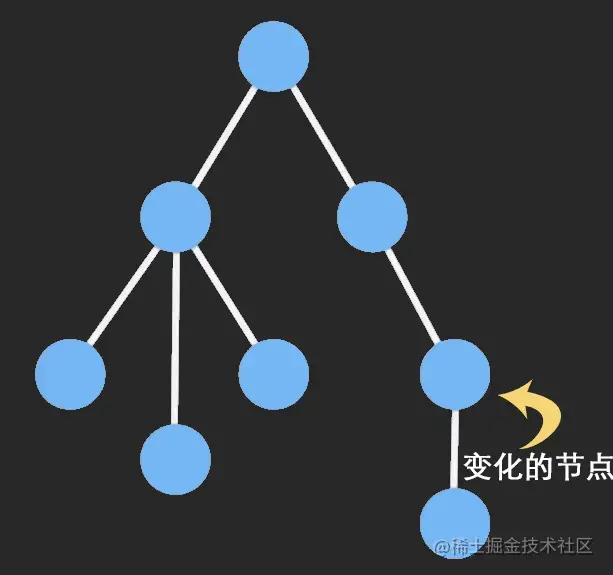
是吧!只更新了父节点,比直接比对所有的属性简直强太多,并且更新后返回了一个全新的引用,即使是浅比对也能感知到数据的改变。
因此,采用 immutable 既能够最大效率地更新数据结构,又能够和现有的 PureComponent (memo) 顺利对接,感知到状态的变化,是提高 React 渲染性能的极佳方案。
不过有一说一,immutable 也有一些被部分开发者吐槽的点,首先是 immutable 对象和 JS 对象要注意转换,不能混用,这个大家注意适当的时候调用 toJS 或者 fromJS 即可,问题并不大。
其次就是对于 immutable API 的学习成本的争议。我觉得这个问题见仁见智吧,我的观点是:如果你目前沉溺在已经运用得非常熟练的技术栈当中,不说深入学习新技术,连新的 API 都懒得学,我觉得对个人成长来说是一个不太好的征兆。
而且,项目中涉及的 api 并没有那么复杂,完全没必要从头到尾把 immutable.js 的 Api 全都记住。接下来我们就来悉数一下项目将要用到的 immutable 的功能。
# 项目中涉及的 immutable 方法
# 1.fromJS
它的功能是将 JS 对象转换为 immutable 对象。
import {fromJS} from 'immutable';
const immutableState = fromJS ({
count: 0
});
大家以后会经常在 redux 的 reducer 文件中看到这个 api, 是 immutable 库当中导出的方法。
# 2. toJS
和 fromJS 功能刚好相反,用来将 immutable 对象转换为 JS 对象。但是值得注意的是,这个方法并没有在 immutable 库中直接导出,而是需要让 immutable 对象调用。比如:
const jsObj = immutableState.toJS ();
# 3.get/getIn
用来获取 immutable 对象属性。通过与 JS 对象的对比来体会一下:
//JS 对象
let jsObj = {a: 1};
let res = jsObj.a;
//immutable 对象
let immutableObj = fromJS (jsObj);
let res = immutableObj.get ('a');
//JS 对象
let jsObj = {a: {b: 1}};
let res = jsObj.a.b;
//immutable 对象
let immutableObj = fromJS (jsObj);
let res = immutableObj.getIn (['a', 'b']);// 注意传入的是一个数组
# 4.set
用来对 immutable 对象的属性赋值。
let immutableObj = fromJS ({a: 1});
immutableObj.set ('a', 2);
# 5. merge
新数据与旧数据对比,旧数据中不存在的属性直接添加,旧数据中已存在的属性用新数据中的覆盖。
let immutableObj = fromJS ({a: 1});
immutableObj.merge ({
a: 2,
b: 3
});// 修改了 a 属性,增加了 b 属性
好了,到这里项目中为什么要使用 immutable 数据以及基本的使用就给大家讲清楚了








