当面试官问你
node的时候,更多引导面试官用node做前端工程化,去引导到webpack、npm、打包工具上面去说说自己的想法,不要引导到自己会后端,后台不是会一点node语法就能写的
# 1 package.json版本号规则
major.minor.patch
- 主版本号.次版本号.修补版本号(
major.minor.patch) major:新的架构调整,不兼容老版本minor:新增功能,兼容老版本patch:修复bug,兼容老版本
~和^的区别
~会匹配最近的小版本依赖包,比如~1.2.3会匹配所有1.2.x版本,但是不包括1.3.0^会匹配最新的大版本依赖包,比如^1.2.3会匹配所有1.x.x的包,包括1.3.0,但是不包括2.0.0*安装最新版本的依赖包,比如*1.2.3会匹配x.x.x
那么该如何选择呢?当然你可以指定特定的版本号,直接写
1.2.3,前面什么前缀都没有,这样固然没问题,但是如果依赖包发布新版本修复了一些小bug,那么需要手动修改package.json文件;~和^则可以解决这个问题
- 但是需要注意
^版本更新可能比较大,会造成项目代码错误,所以 建议使用~来标记版本号,这样可以保证项目不会出现大的问题,也能保证包中的小bug可以得到修复。- 版本号写
*,这意味着安装最新版本的依赖包,但缺点同上,可能会造成版本不兼容,慎用
我们举个例子:
- 假设我们中安装了
vue, 当我们运行安装npm install vue -save的时候,在项目中的package.json的vue版本是vue: ^3.0.0, 我们电脑安装的vue版本就是3.0.0版本,我们把项目代码提交后,过了一段时间,vue发布了新版本3.0.1,这时新来一个同事,从新git clone克隆项目,执行npm install安装的时候,在他电脑的vue版本就是3.0.1了,因为^只是锁了主要版本,这样我们电脑中的vue版本就会不一样,从理论上讲(大家都遵循语义版本控制的话),它们应该仍然是兼容的,但也许bugfix会影响我们正在使用的功能,而且当使用vue版本3.0.0和3.0.1运行时,我们的应用程序会产生不同的结果。- 大家思考思考,这样的话,不同人电脑安装的依赖版项目,是不是都有可能不一样,就会导致每个人电脑运行的应用程序产生不同的结果。就会存在bug的隐患。
- 这时也许有同学想到,那么我们在package.json上面锁死依赖包的版本号不就可以了? 直接写
vue: 3.0.0锁死,这样大家安装vue的版本都是3.0.0版本了。- 这个想法固然是不错的,但是你只能控制你自己的项目锁死版本号,那你项目中依赖包的依赖包呢?你怎么控制限制别人锁死版本号呢?
- 为了解决这个不同人电脑安装的所有依赖版本都是一致的,确保项目代码在安装所执行的运行结果都一样,这时
package-lock.json就应运而生了
# 2 package.json 与 package-lock.json 的关系
package-lock.json 是在 npm(^5.x.x.x)后才有,中途有几次更改
package-lock.json它会在npm更改node_modules目录树 或者package.json时自动生成的 ,它准确的描述了当前项目npm包的依赖树,并且在随后的安装中会根据package-lock.json来安装,保证是相同的一个依赖树,不考虑这个过程中是否有某个依赖有小版本的更新
它的产生就是来对整个依赖树进行版本固定的(锁死)
- 当我们在一个项目中
npm install时候,会自动生成一个package-lock.json文件,和package.json在同一级目录下。package-lock.json记录了项目的一些信息和所依赖的模块。这样在每次安装都会出现相同的结果. 不管你在什么机器上面或什么时候安装 - 当我们下次再
npm install时候,npm发现如果项目中有package-lock.json文件,会根据package-lock.json里的内容来处理和安装依赖而不再根据package.json
注意
使用cnpm install时候,并不会生成 package-lock.json 文件,也不会根据 package-lock.json 来安装依赖包,还是会使用 package.json 来安装。
package-lock.json 可能被意外更改的原因
package.json文件修改了- 挪动了包的位置:将部分包的位置从
dependencies移动到devDependencies这种操作,虽然包未变,但是也会影响package-lock.json
# 3 npm 模块安装机制
- 发出
npm install命令1查询node_modules目录之中是否已经存在指定模块 - 若存在,不再重新安装
- 若不存在
npm向registry查询模块压缩包的网址- 下载压缩包,存放在根目录下的
.npm目录里 - 解压压缩包到当前项目的
node_modules目录
# 4 模块化的差异 AMD CMD COMMONJS ESMODULE
AMD是依赖前置,define写法CMD语法requireAMD和CMD是动态引入,运行时才知道的ESMODULE是静态引入,好处方便wepback打包依赖图谱分析CommonJs是单个值导出,ES6 Module可以导出多个CommonJs是动态语法可以写在判断里,ES6 Module静态语法只能写在顶层CommonJs的this是当前模块,ES6 Module的this是undefined
# 5 Node 的 Event Loop: 6个阶段
timer阶段: 执行到期的setTimeout / setInterval队列回调I/O阶段: 执行上轮循环残流的callbackidle,preparepoll: 等待回调- 执行回调
- 执行定时器
- 如有到期的
setTimeout / setInterval, 则返回timer阶段 - 如有
setImmediate,则前往check阶段
check- 执行
setImmediate
- 执行
close callbacks
# 6 Koa相关
# koa洋葱模型怎么实现的
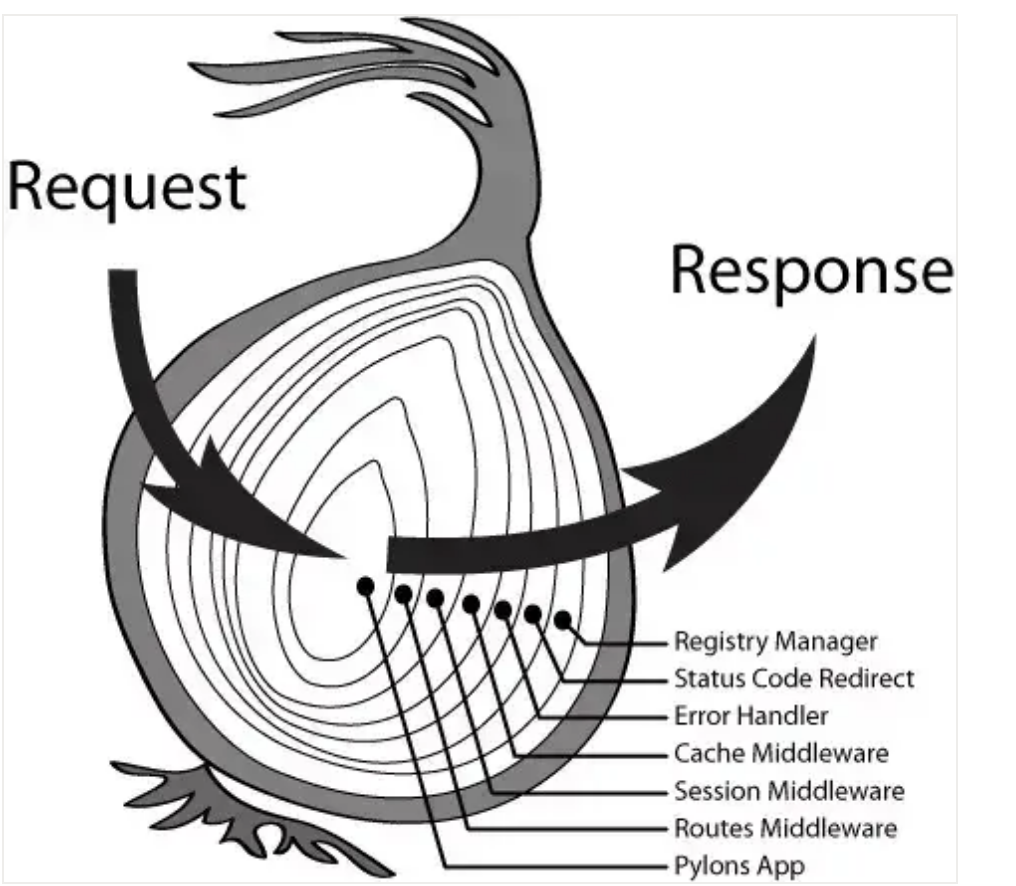
- 中间件执行就像洋葱一样,最早
use的中间件,就放在最外层。处理顺序从左到右,左边接收一个request,右边输出返回response - 一般的中间件都会执行两次,调用
next之前为第一次,调用next时把控制传递给下游的下一个中间件。当下游不再有中间件或者没有执行next函数时,就将依次恢复上游中间件的行为,让上游中间件执行next之后的代码
例如下面这段代码
const Koa = require('koa')
const app = new Koa()
app.use((ctx, next) => {
console.log(1)
next()
console.log(2)
})
app.use((ctx, next) => {
await next()
console.log(3)
})
app.use((ctx) => {
console.log(4)
})
app.listen(3001)
//执行结果是 1=>4=>3=>2
app.use()把中间件函数存储在middleware数组中,最终会调用koa-compose导出的函数compose返回一个promise,中间函数的第一个参数ctx是包含响应和请求的一个对象,会不断传递给下一个中间件。next是一个函数,返回的是一个promise
koa 中间件实现源码大致思路如下:
// 注意其中的compose函数,这个函数是实现中间件洋葱模型的关键
// 场景模拟
// 异步 promise 模拟
const delay = async () => {
return new Promise((resolve, reject) => {
setTimeout(() => {
resolve();
}, 2000);
});
}
// 中间件模拟
const fn1 = async (ctx, next) => {
console.log(1);
await next();
console.log(2);
}
const fn2 = async (ctx, next) => {
console.log(3);
await delay();
await next();
console.log(4);
}
const fn3 = async (ctx, next) => {
console.log(5);
}
const middlewares = [fn1, fn2, fn3];
// compose 实现洋葱模型
const compose = (middlewares, ctx) => {
const dispatch = (i) => {
let fn = middlewares[i];
if(!fn){ return Promise.resolve() }
return Promise.resolve(fn(ctx, () => {
return dispatch(i+1);
}));
}
return dispatch(0);
}
compose(middlewares, 1);
# 如果中间件中的next()方法报错了怎么办
中间件链错误会由
ctx.onerror捕获,该函数中会调用this.app.emit('error', err, this)(因为koa继承自events模块,所以有'emit'和on等方法),可以使用app.on('error', (err) => {}),或者app.onerror = (err) => {}进行捕获。
# co的原理是怎样的
co的原理是通过不断调用generator函数的
next方法来达到自动执行generator函数的,类似async、await函数自动执行
# 7 Express、koa实现原理以及对比
底层建立在
node.js内置的http模块上。http模块生成服务器的原始代码如下
var http = require("http");
var app = http.createServer(function(request, response) {
response.writeHead(200, {"Content-Type": "text/plain"});
response.end("Hello world!");
});
app.listen(3000, "localhost");
Express框架的核心是对http模块的再包装Express框架等于在http模块之上,加了一个中间层- 它最大的特点就是,一个中间件处理完,再传递给下一个中间件
- 比如自带
Router、路由规则等 callback太多
koa2特点
- 洋葱模型
- 没有自带路由,由koa-router管理
- 没有callback
# 8 请介绍一下 require 的模块加载机制
这道题基本上就可以了解到面试者对 Node 模块机制的了解程度 基本上面试提到
- 先计算模块路径
- 如果模块在缓存里面,取出缓存
- 加载模块
- 输出模块的
exports属性即可
// require 其实内部调用 Module._load 方法
Module._load = function(request, parent, isMain) {
// 计算绝对路径
var filename = Module._resolveFilename(request, parent);
// 第一步:如果有缓存,取出缓存
var cachedModule = Module._cache[filename];
if (cachedModule) {
return cachedModule.exports;
// 第二步:是否为内置模块
if (NativeModule.exists(filename)) {
return NativeModule.require(filename);
}
/********************************这里注意了**************************/
// 第三步:生成模块实例,存入缓存
// 这里的Module就是我们上面的1.1定义的Module
var module = new Module(filename, parent);
Module._cache[filename] = module;
/********************************这里注意了**************************/
// 第四步:加载模块
// 下面的module.load实际上是Module原型上有一个方法叫Module.prototype.load
try {
module.load(filename);
hadException = false;
} finally {
if (hadException) {
delete Module._cache[filename];
}
}
// 第五步:输出模块的exports属性
return module.exports;
};
手写一个Require简版
const path = require('path'); // 路径操作
const fs = require('fs'); // 文件读取
const vm = require('vm'); // 文件执行
// node模块化的实现
// node中是自带模块化机制的,每个文件就是一个单独的模块,并且它遵循的是CommonJS规范,也就是使用require的方式导入模块,通过module.export的方式导出模块。
// node模块的运行机制也很简单,其实就是在每一个模块外层包裹了一层函数,有了函数的包裹就可以实现代码间的作用域隔离
// require加载模块
// require依赖node中的fs模块来加载模块文件,fs.readFile读取到的是一个字符串。
// 在javascrpt中我们可以通过eval或者new Function的方式来将一个字符串转换成js代码来运行。
// eval
// const name = 'poetry';
// const str = 'const a = 123; console.log(name)';
// eval(str); // poetry;
// new Function
// new Function接收的是一个要执行的字符串,返回的是一个新的函数,调用这个新的函数字符串就会执行了。如果这个函数需要传递参数,可以在new Function的时候依次传入参数,最后传入的是要执行的字符串。比如这里传入参数b,要执行的字符串str
// const b = 3;
// const str = 'let a = 1; return a + b';
// const fun = new Function('b', str);
// console.log(fun(b, str)); // 4
// 可以看到eval和Function实例化都可以用来执行javascript字符串,似乎他们都可以来实现require模块加载。不过在node中并没有选用他们来实现模块化,原因也很简单因为他们都有一个致命的问题,就是都容易被不属于他们的变量所影响。
// 如下str字符串中并没有定义a,但是确可以使用上面定义的a变量,这显然是不对的,在模块化机制中,str字符串应该具有自身独立的运行空间,自身不存在的变量是不可以直接使用的
// const a = 1;
// const str = 'console.log(a)';
// eval(str);
// const func = new Function(str);
// func();
// node存在一个vm虚拟环境的概念,用来运行额外的js文件,他可以保证javascript执行的独立性,不会被外部所影响
// vm 内置模块
// 虽然我们在外部定义了hello,但是str是一个独立的模块,并不在村hello变量,所以会直接报错。
// 引入vm模块, 不需要安装,node 自建模块
// const vm = require('vm');
// const hello = 'poetry';
// const str = 'console.log(hello)';
// wm.runInThisContext(str); // 报错
// 所以node执行javascript模块时可以采用vm来实现。就可以保证模块的独立性了
// 分析实现步骤
// 1.导入相关模块,创建一个Require方法。
// 2.抽离通过Module._load方法,用于加载模块。
// 3.Module.resolveFilename 根据相对路径,转换成绝对路径。
// 4.缓存模块 Module._cache,同一个模块不要重复加载,提升性能。
// 5.创建模块 id: 保存的内容是 exports = {}相当于this。
// 6.利用tryModuleLoad(module, filename) 尝试加载模块。
// 7.Module._extensions使用读取文件。
// 8.Module.wrap: 把读取到的js包裹一个函数。
// 9.将拿到的字符串使用runInThisContext运行字符串。
// 10.让字符串执行并将this改编成exports
// 定义导入类,参数为模块路径
function Require(modulePath) {
// 获取当前要加载的绝对路径
let absPathname = path.resolve(__dirname, modulePath);
// 自动给模块添加后缀名,实现省略后缀名加载模块,其实也就是如果文件没有后缀名的时候遍历一下所有的后缀名看一下文件是否存在
// 获取所有后缀名
const extNames = Object.keys(Module._extensions);
let index = 0;
// 存储原始文件路径
const oldPath = absPathname;
function findExt(absPathname) {
if (index === extNames.length) {
throw new Error('文件不存在');
}
try {
fs.accessSync(absPathname);
return absPathname;
} catch(e) {
const ext = extNames[index++];
findExt(oldPath + ext);
}
}
// 递归追加后缀名,判断文件是否存在
absPathname = findExt(absPathname);
// 从缓存中读取,如果存在,直接返回结果
if (Module._cache[absPathname]) {
return Module._cache[absPathname].exports;
}
// 创建模块,新建Module实例
const module = new Module(absPathname);
// 给模块添加缓存
// 添加缓存也比较简单,就是文件加载的时候将文件放入缓存中,再去加载模块时先看缓存中是否存在,如果存在直接使用,如果不存在再去重新,加载之后再放入缓存
Module._cache[absPathname] = module;
// 加载当前模块
tryModuleLoad(module);
// 返回exports对象
return module.exports;
}
// Module的实现很简单,就是给模块创建一个exports对象,tryModuleLoad执行的时候将内容加入到exports中,id就是模块的绝对路径
// 定义模块, 添加文件id标识和exports属性
function Module(id) {
this.id = id;
// 读取到的文件内容会放在exports中
this.exports = {};
}
Module._cache = {};
// 我们给Module挂载静态属性wrapper,里面定义一下这个函数的字符串,wrapper是一个数组,数组的第一个元素就是函数的参数部分,其中有exports,module. Require,__dirname, __filename, 都是我们模块中常用的全局变量。注意这里传入的Require参数是我们自己定义的Require
// 第二个参数就是函数的结束部分。两部分都是字符串,使用的时候我们将他们包裹在模块的字符串外部就可以了
Module.wrapper = [
"(function(exports, module, Require, __dirname, __filename) {",
"})"
]
// _extensions用于针对不同的模块扩展名使用不同的加载方式,比如JSON和javascript加载方式肯定是不同的。JSON使用JSON.parse来运行。
// javascript使用vm.runInThisContext来运行,可以看到fs.readFileSync传入的是module.id也就是我们Module定义时候id存储的是模块的绝对路径,读取到的content是一个字符串,我们使用Module.wrapper来包裹一下就相当于在这个模块外部又包裹了一个函数,也就实现了私有作用域。
// 使用call来执行fn函数,第一个参数改变运行的this我们传入module.exports,后面的参数就是函数外面包裹参数exports, module, Require, __dirname, __filename
Module._extensions = {
'.js'(module) {
const content = fs.readFileSync(module.id, 'utf8');
const fnStr = Module.wrapper[0] + content + Module.wrapper[1];
const fn = vm.runInThisContext(fnStr);
fn.call(module.exports, module.exports, module, Require,__filename,__dirname);
},
'.json'(module) {
const json = fs.readFileSync(module.id, 'utf8');
module.exports = JSON.parse(json); // 把文件的结果放在exports属性上
}
}
// tryModuleLoad函数接收的是模块对象,通过path.extname来获取模块的后缀名,然后使用Module._extensions来加载模块
// 定义模块加载方法
function tryModuleLoad(module) {
// 获取扩展名
const extension = path.extname(module.id);
// 通过后缀加载当前模块
Module._extensions[extension](module);
}
// 至此Require加载机制我们基本就写完了,我们来重新看一下。Require加载模块的时候传入模块名称,在Require方法中使用path.resolve(__dirname, modulePath)获取到文件的绝对路径。然后通过new Module实例化的方式创建module对象,将模块的绝对路径存储在module的id属性中,在module中创建exports属性为一个json对象
// 使用tryModuleLoad方法去加载模块,tryModuleLoad中使用path.extname获取到文件的扩展名,然后根据扩展名来执行对应的模块加载机制
// 最终将加载到的模块挂载module.exports中。tryModuleLoad执行完毕之后module.exports已经存在了,直接返回就可以了
// 测试
let json = Require('./test.json');
let test2 = Require('./test2.js');
console.log(json);
console.log(test2);
# 9 exports.xxx=xxx 和 Module.exports={}有什么区别
exports 其实就是 module.exports
// module.exports vs exports
// 很多时候,你会看到,在Node环境中,有两种方法可以在一个模块中输出变量:
// 方法一:对module.exports赋值:
// hello.js
function hello() {
console.log('Hello, world!');
}
function greet(name) {
console.log('Hello, ' + name + '!');
}
module.exports = {
hello: hello,
greet: greet
};
// 方法二:直接使用exports:
// hello.js
function hello() {
console.log('Hello, world!');
}
function greet(name) {
console.log('Hello, ' + name + '!');
}
function hello() {
console.log('Hello, world!');
}
exports.hello = hello;
exports.greet = greet;
// 但是你不可以直接对exports赋值:
// 代码可以执行,但是模块并没有输出任何变量:
exports = {
hello: hello,
greet: greet
};
// 如果你对上面的写法感到十分困惑,不要着急,我们来分析Node的加载机制:
// 首先,Node会把整个待加载的hello.js文件放入一个包装函数load中执行。在执行这个load()函数前,Node准备好了module变量:
var module = {
id: 'hello',
exports: {}
};
// load()函数最终返回module.exports:
var load = function (exports, module) {
// hello.js的文件内容
...
// load函数返回:
return module.exports;
};
var exportes = load(module.exports, module);
// 也就是说,默认情况下,Node准备的exports变量和module.exports变量实际上是同一个变量,并且初始化为空对象{},于是,我们可以写:
exports.foo = function () { return 'foo'; };
exports.bar = function () { return 'bar'; };
// 也可以写:
module.exports.foo = function () { return 'foo'; };
module.exports.bar = function () { return 'bar'; };
// 换句话说,Node默认给你准备了一个空对象{},这样你可以直接往里面加东西。
// 但是,如果我们要输出的是一个函数或数组,那么,只能给module.exports赋值:
module.exports = function () { return 'foo'; };
// 给exports赋值是无效的,因为赋值后,module.exports仍然是空对象{}。
// 结论
// 如果要输出一个键值对象{},可以利用exports这个已存在的空对象{},并继续在上面添加新的键值;
// 如果要输出一个函数或数组,必须直接对module.exports对象赋值。
// 所以我们可以得出结论:直接对module.exports赋值,可以应对任何情况:
module.exports = {
foo: function () { return 'foo'; }
};
// 或者:
module.exports = function () { return 'foo'; };
// 最终,我们强烈建议使用module.exports = xxx的方式来输出模块变量,这样,你只需要记忆一种方法。
# 10 Node 的异步 I/O
# 请介绍一下 Node 事件循环的流程
- 在进程启动时,Node 便会创建一个类似于 while(true)的循环,每执行一次循环体的过程我们成为 Tick。
- 每个 Tick 的过程就是查看是否有事件待处理。如果有就取出事件及其相关的回调函数。然后进入下一个循环,如果不再有事件处理,就退出进程。
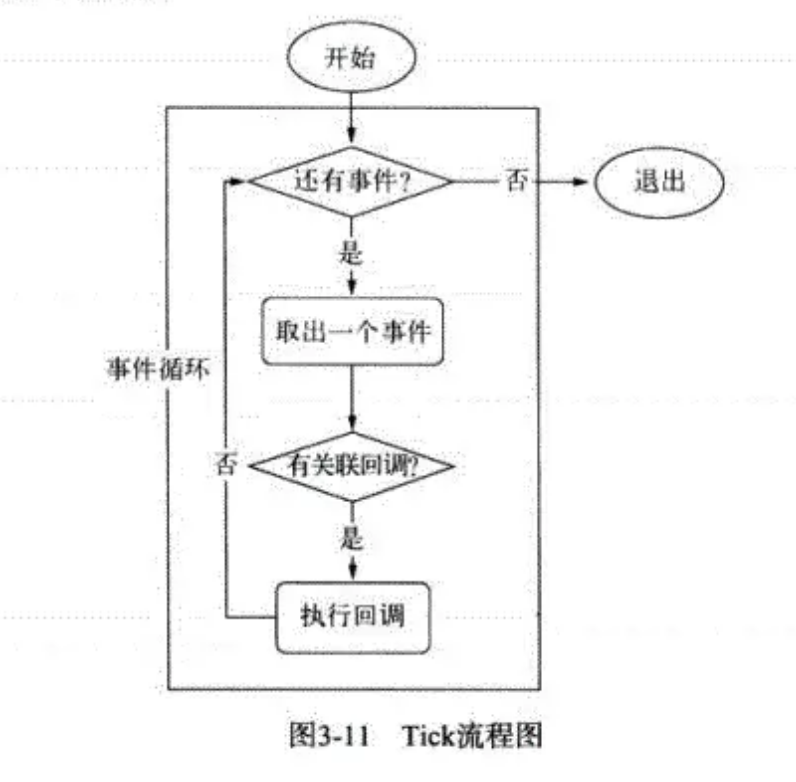
# 在每个 tick 的过程中,如何判断是否有事件需要处理呢
- 每个事件循环中有一个或者多个观察者,而判断是否有事件需要处理的过程就是向这些观察者询问是否有要处理的事件。
- 在 Node 中,事件主要来源于网络请求、文件的 I/O 等,这些事件对应的观察者有文件 I/O 观察者,网络 I/O 的观察者。
- 事件循环是一个典型的生产者/消费者模型。异步 I/O,网络请求等则是事件的生产者,源源不断为 Node 提供不同类型的事件,这些事件被传递到对应的观察者那里,事件循环则从观察者那里取出事件并处理。
- 在 windows 下,这个循环基于 IOCP 创建,在*nix 下则基于多线程创建
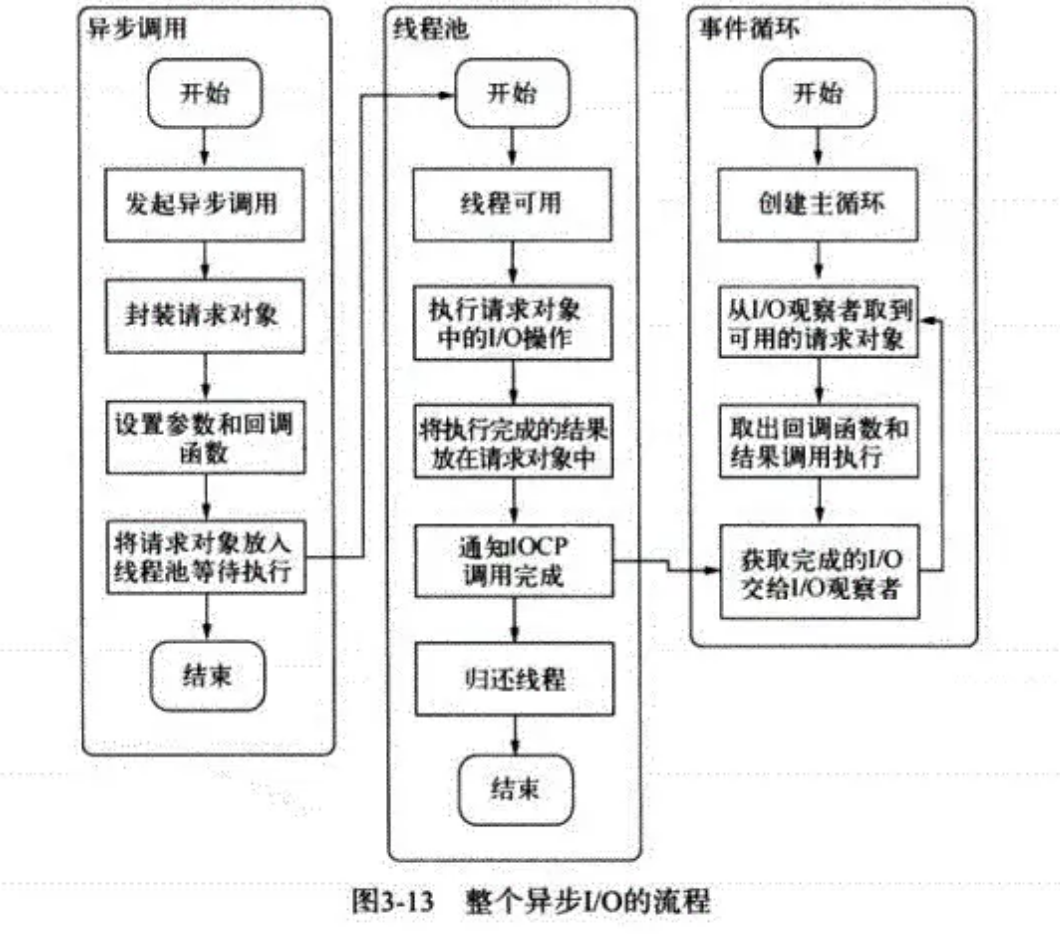
# 描述一下整个异步 I/O 的流程
# 11 V8 的垃圾回收机制
# 如何查看 V8 的内存使用情况
使用 process.memoryUsage(),返回如下
{
rss: 4935680,
heapTotal: 1826816,
heapUsed: 650472,
external: 49879
}
heapTotal和heapUsed代表V8的内存使用情况。external代表V8管理的,绑定到 Javascript 的 C++对象的内存使用情况。rss, 驻留集大小, 是给这个进程分配了多少物理内存(占总分配内存的一部分) 这些物理内存中包含堆,栈,和代码段。
# V8 的内存限制是多少,为什么 V8 这样设计
64 位系统下是
1.4GB, 32 位系统下是0.7GB。因为1.5GB的垃圾回收堆内存,V8 需要花费 50 毫秒以上,做一次非增量式的垃圾回收甚至要 1 秒以上。这是垃圾回收中引起 Javascript 线程暂停执行的事件,在这样的花销下,应用的性能和影响力都会直线下降。
# V8 的内存分代和回收算法请简单讲一讲
在 V8 中,主要将内存分为新生代和老生代两代。新生代中的对象存活时间较短的对象,老生代中的对象存活时间较长,或常驻内存的对象。

新生代
新生代中的对象主要通过 Scavenge 算法进行垃圾回收。这是一种采用复制的方式实现的垃圾回收算法。它将堆内存一份为二,每一部分空间成为 semispace。在这两个 semispace 空间中,只有一个处于使用中,另一个处于闲置状态。处于使用状态的 semispace 空间称为 From 空间,处于闲置状态的空间称为 To 空间

- 当开始垃圾回收的时候,会检查 From 空间中的存活对象,这些存活对象将被复制到 To 空间中,而非存活对象占用的空间将会被释放。完成复制后,From 空间和 To 空间发生角色对换。
- 应为新生代中对象的生命周期比较短,就比较适合这个算法。
- 当一个对象经过多次复制依然存活,它将会被认为是生命周期较长的对象。这种新生代中生命周期较长的对象随后会被移到老生代中。
老生代
老生代主要采取的是标记清除的垃圾回收算法。与 Scavenge 复制活着的对象不同,标记清除算法在标记阶段遍历堆中的所有对象,并标记活着的对象,只清理死亡对象。活对象在新生代中只占叫小部分,死对象在老生代中只占较小部分,这是为什么采用标记清除算法的原因
标记清楚算法的问题
主要问题是每一次进行标记清除回收后,内存空间会出现不连续的状态
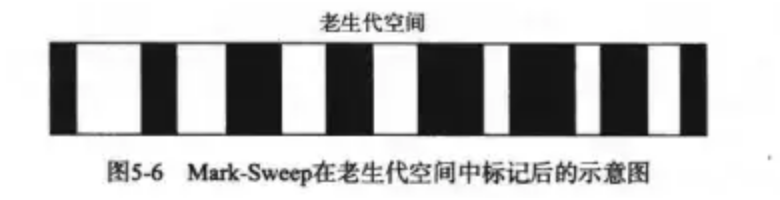
- 这种内存碎片会对后续内存分配造成问题,很可能出现需要分配一个大对象的情况,这时所有的碎片空间都无法完成此次分配,就会提前触发垃圾回收,而这次回收是不必要的。
- 为了解决碎片问题,标记整理被提出来。就是在对象被标记死亡后,在整理的过程中,将活着的对象往一端移动,移动完成后,直接清理掉边界外的内存。
哪些情况会造成 V8 无法立即回收内存
闭包和全局变量
请谈一下内存泄漏是什么,以及常见内存泄漏的原因,和排查的方法
- 什么是内存泄漏
- 内存泄漏(Memory Leak)指由于疏忽或错误造成程序未能释放已经不再使用的内存的情况。
- 如果内存泄漏的位置比较关键,那么随着处理的进行可能持有越来越多的无用内存,这些无用的内存变多会引起服务器响应速度变慢。
- 严重的情况下导致内存达到某个极限(可能是进程的上限,如 v8 的上限;也可能是系统可提供的内存上限)会使得应用程序崩溃。常见内存泄漏的原因 内存泄漏的几种情况:
全局变量
a = 10;
//未声明对象。
global.b = 11;
//全局变量引用
// 这种比较简单的原因,全局变量直接挂在 root 对象上,不会被清除掉。
闭包
function out() {
const bigData = new Buffer(100);
inner = function () {
}
}
闭包会引用到父级函数中的变量,如果闭包未释放,就会导致内存泄漏。上面例子是 inner 直接挂在了 root 上,那么每次执行 out 函数所产生的 bigData 都不会释放,从而导致内存泄漏。需要注意的是,这里举得例子只是简单的将引用挂在全局对象上,实际的业务情况可能是挂在某个可以从 root 追溯到的对象上导致的
事件监听
Node.js 的事件监听也可能出现的内存泄漏。例如对同一个事件重复监听,忘记移除(removeListener),将造成内存泄漏。这种情况很容易在复用对象上添加事件时出现,所以事件重复监听可能收到如下警告
emitter.setMaxListeners() to increase limit
排查方法想要定位内存泄漏,通常会有两种情况
- 对于只要正常使用就可以重现的内存泄漏,这是很简单的情况只要在测试环境模拟就可以排查了。
- 对于偶然的内存泄漏,一般会与特殊的输入有关系。想稳定重现这种输入是很耗时的过程。如果不能通过代码的日志定位到这个特殊的输入,那么推荐去生产环境打印内存快照了。
- 需要注意的是,打印内存快照是很耗 CPU 的操作,可能会对线上业务造成影响。快照工具推荐使用 heapdump 用来保存内存快照,使用 devtool 来查看内存快照。
- 使用 heapdump 保存内存快照时,只会有 Node.js 环境中的对象,不会受到干扰(如果使用 node-inspector 的话,快照中会有前端的变量干扰)。
PS:安装 heapdump 在某些 Node.js 版本上可能出错,建议使用
npm install heapdump -target=Node.js版本来安装。
# 12 Buffer 模块
# 新建 Buffer 会占用 V8 分配的内存吗
不会,Buffer 属于堆外内存,不是 V8 分配的。
# Buffer.alloc 和 Buffer.allocUnsafe 的区别
Buffer.allocUnsafe创建的 Buffer 实例的底层内存是未初始化的。新创建的 Buffer 的内容是未知的,可能包含敏感数据。使用 Buffer.alloc() 可以创建以零初始化的 Buffer 实例。
# Buffer 的内存分配机制
- 为了高效的使用申请来的内存,Node 采用了 slab 分配机制。slab 是一种动态的内存管理机制。Node 以 8kb 为界限来来区分 Buffer 为大对象还是小对象,如果是小于 8kb 就是小
Buffer,大于 8kb 就是大 Buffer。例如第一次分配一个 1024 字节的 Buffer,Buffer.alloc(1024),那么这次分配就会- 用到一个 slab,接着如果继续Buffer.alloc(1024),那么上一次用的 slab 的空间还没有用完,因为总共是 8kb,1024+1024 = 2048个字节,没有 8kb,所以就继续用这个 slab 给 Buffer 分配空间。如果超过 8kb,那么直接用 C++底层地宫的SlowBuffer来给Buffer对象提供空间。
# Buffer 乱码问题
例如一个份文件 test.md 里的内容如下:
床前明月光,疑是地上霜,举头望明月,低头思故乡
我们这样读取就会出现乱码:
var rs = require('fs').createReadStream('test.md', {highWaterMark: 11});
// 床前明???光,疑???地上霜,举头???明月,???头思故乡
一般情况下,只需要设置 rs.setEncoding('utf8') 即可解决乱码问题
# 13 webSocket
# webSocket 与传统的 http 有什么优势
- 客户端与服务器只需要一个 TCP 连接,比
http长轮询使用更少的连接 webSocket服务端可以推送数据到客户端- 更轻量的协议头,减少数据传输量
# webSocket 协议升级简述一下
首先,WebSocket 连接必须由浏览器发起,因为请求协议是一个标准的 HTTP 请求,格式如下:
GET ws://localhost:3000/ws/chat HTTP/1.1
Host: localhost
Upgrade: websocket
Connection: Upgrade
Origin: http://localhost:3000
Sec-WebSocket-Key: client-random-string
Sec-WebSocket-Version: 13
该请求和普通的 HTTP 请求有几点不同:
GET请求的地址不是类似/path/,而是以ws://开头的地址;- 请求头
Upgrade: websocket和Connection: Upgrade表示这个连接将要被转换为WebSocket连接; Sec-WebSocket-Key是用于标识这个连接,并非用于加密数据;Sec-WebSocket-Version指定了WebSocket的协议版本。
随后,服务器如果接受该请求,就会返回如下响应:
HTTP/1.1 101 Switching Protocols
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: server-random-string
该响应代码 101 表示本次连接的 HTTP 协议即将被更改,更改后的协议就是 Upgrade: websocket 指定的 WebSocket 协议
# 14 https
# https 用哪些端口进行通信,这些端口分别有什么用
443端口用来验证服务器端和客户端的身份,比如验证证书的合法性80端口用来传输数据(在验证身份合法的情况下,用来数据传输)
# 身份验证过程中会涉及到密钥, 对称加密,非对称加密,摘要的概念,请解释一下
- 密钥:密钥是一种参数,它是在明文转换为密文或将密文转换为明文的算法中输入的参数。密钥分为对称密钥与非对称密钥,分别应用在对称加密和非对称加密上。
- 对称加密:对称加密又叫做私钥加密,即信息的发送方和接收方使用同一个密钥去加密和解密数据。对称加密的特点是算法公开、加密和解密速度快,适合于对大数据量进行加密,常见的对称加密算法有
DES、3DES、TDEA、Blowfish、RC5和IDEA。 - 非对称加密:非对称加密也叫做公钥加密。非对称加密与对称加密相比,其安全性更好。对称加密的通信双方使用相同的密钥,如果一方的密钥遭泄露,那么整个通信就会被破解。而非对称加密使用一对密钥,即公钥和私钥,且二者成对出现。私钥被自己保存,不能对外泄露。公钥指的是公共的密钥,任何人都可以获得该密钥。用公钥或私钥中的任何一个进行加密,用另一个进行解密。
- 摘要:摘要算法又称哈希/散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用 16 进制的字符串表示)。算法不可逆。
# 为什么需要 CA 机构对证书签名
如果不签名会存在中间人攻击的风险,签名之后保证了证书里的信息,比如公钥、服务器信息、企业信息等不被篡改,能够验证客户端和服务器端的“合法性”。
# https 验证身份也就是 TSL/SSL 身份验证的过程
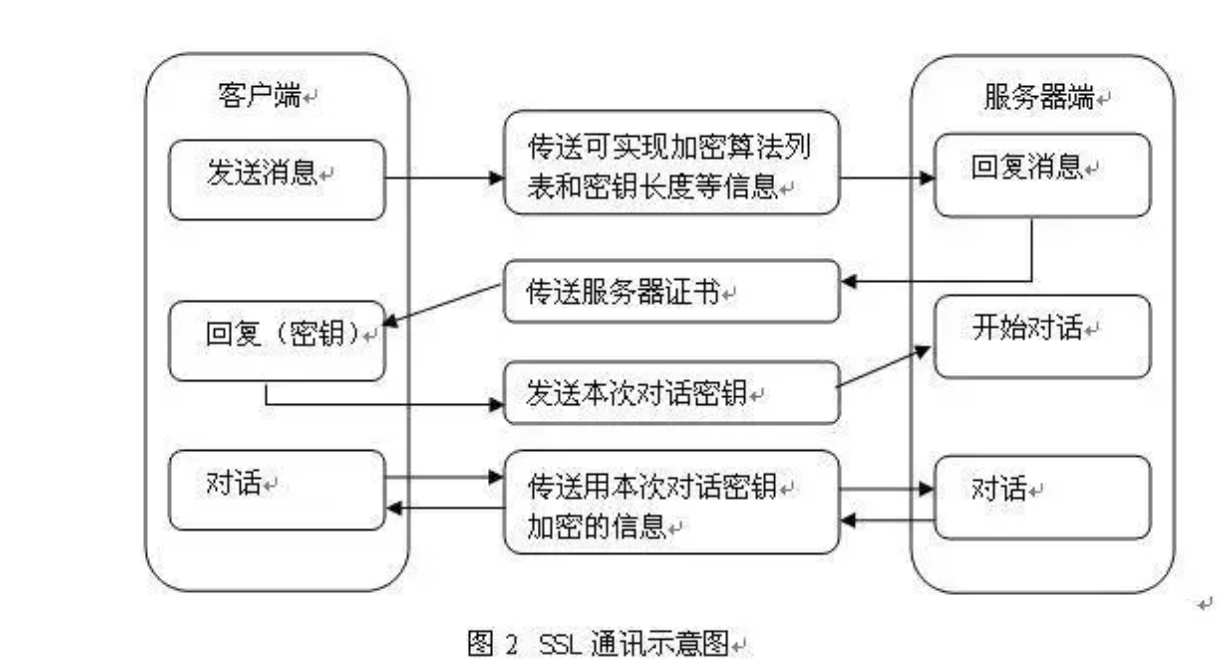
# 15 进程通信
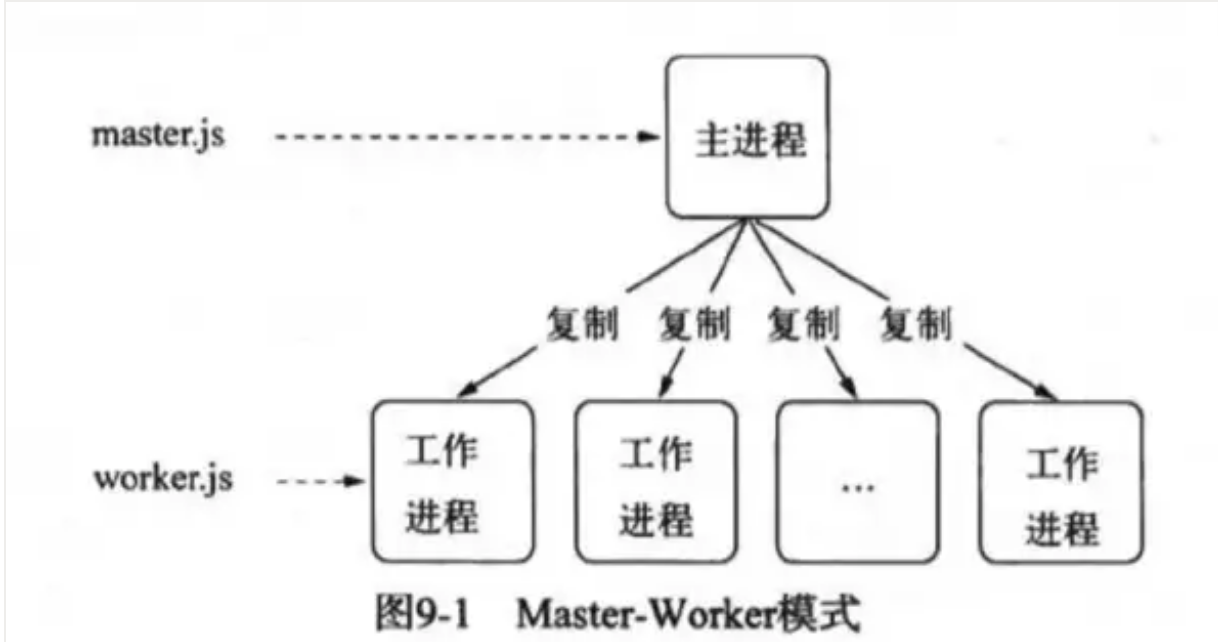
# 请简述一下 node 的多进程架构
面对 node 单线程对多核 CPU 使用不足的情况,Node 提供了
child_process模块,来实现进程的复制,node 的多进程架构是主从模式,如下所示:
var fork = require('child_process').fork;
var cpus = require('os').cpus();
for(var i = 0; i < cpus.length; i++){
fork('./worker.js');
}
在 linux 中,我们通过
ps aux | grep worker.js查看进程

这就是著名的主从模式,Master-Worker
# 请问创建子进程的方法有哪些,简单说一下它们的区别
spawn():启动一个子进程来执行命令exec(): 启动一个子进程来执行命令,与 spawn()不同的是其接口不同,它有一个回调函数获知子进程的状况execFlie(): 启动一个子进程来执行可执行文件fork(): 与spawn()类似,不同电在于它创建 Node 子进程需要执行 js 文件spawn()与exec()、execFile()不同的是,后两者创建时可以指定timeout属性设置超时时间,一旦创建的进程超过设定的时间就会被杀死exec()与execFile()不同的是,exec()适合执行已有命令,execFile()适合执行文件。
# 实现一个 node 子进程被杀死,然后自动重启代码的思路
在创建子进程的时候就让子进程监听 exit 事件,如果被杀死就重新 fork 一下
var createWorker = function(){
var worker = fork(__dirname + 'worker.js')
worker.on('exit', function(){
console.log('Worker' + worker.pid + 'exited');
// 如果退出就创建新的worker
createWorker()
})
}