# 前端性能优化篇
# 一、前言
# 知识体系: 从一道面试题说起
在展开性能优化的话题之前,我想先抛出一个老生常谈的面试问题:
从输入 URL 到页面加载完成,发生了什么?
- 这个问题非常重要,因为我们后续的内容都将以这个问题的答案为骨架展开。我希望正在阅读这本小册的各位可以在心里琢磨一下这个问题——无须你调动太多计算机的专业知识,只需要你用最快的速度在脑海中架构起这个抽象的过程——我们接下来所有的工作,就是围绕这个过程来做文章。
- 我们现在站在性能优化的角度,一起简单地复习一遍这个经典的过程:首先我们需要通过 DNS(域名解析系统)将 URL 解析为对应的 IP 地址,然后与这个 IP 地址确定的那台服务器建立起 TCP 网络连接,随后我们向服务端抛出我们的 HTTP 请求,服务端处理完我们的请求之后,把目标数据放在 HTTP 响应里返回给客户端,拿到响应数据的浏览器就可以开始走一个渲染的流程。渲染完毕,页面便呈现给了用户,并时刻等待响应用户的操作(如下图所示)。
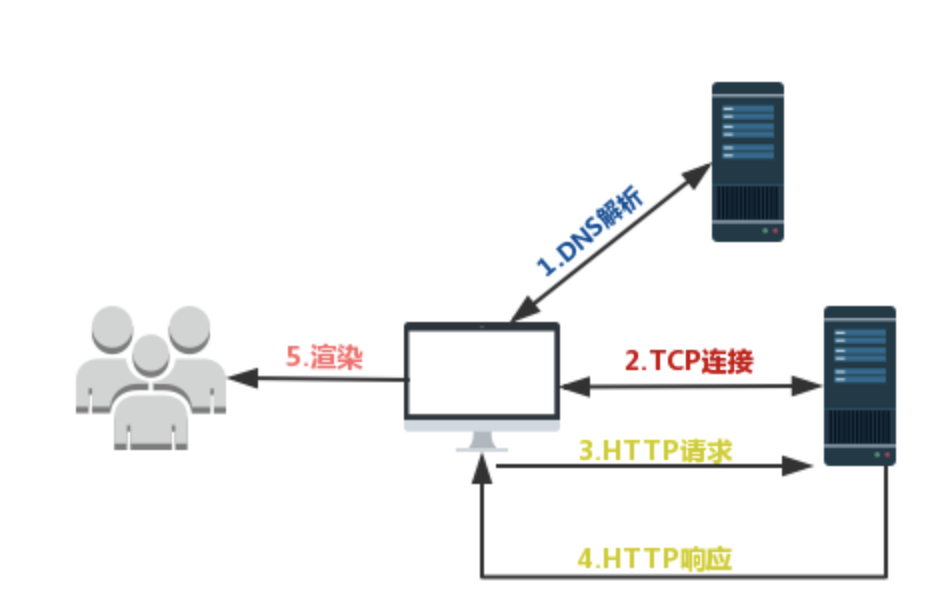
我们将这个过程切分为如下的过程片段:
DNS解析TCP连接HTTP请求抛出- 服务端处理请求,
HTTP响应返回 - 浏览器拿到响应数据,解析响应内容,把解析的结果展示给用户
大家谨记,我们任何一个用户端的产品,都需要把这 5 个过程滴水不漏地考虑到自己的性能优化方案内、反复权衡,从而打磨出用户满意的速度。
# 从原理到实践:各个击破
- 我们接下来要做的事情,就是针对这五个过程进行分解,各个提问,各个击破。
具体来说,DNS 解析花时间,能不能尽量减少解析次数或者把解析前置?能——浏览器 DNS 缓存和 DNS prefetch。TCP 每次的三次握手都急死人,有没有解决方案?有——长连接、预连接、接入 SPDY 协议。如果说这两个过程的优化往往需要我们和团队的服务端工程师协作完成,前端单方面可以做的努力有限,那么 HTTP 请求呢?——在减少请求次数和减小请求体积方面,我们应该是专家!再者,服务器越远,一次请求就越慢,那部署时就把静态资源放在离我们更近的 CDN 上是不是就能更快一些?
以上提到的都是网络层面的性能优化。再往下走就是浏览器端的性能优化——这部分涉及资源加载优化、服务端渲染、浏览器缓存机制的利用、DOM 树的构建、网页排版和渲染过程、回流与重绘的考量、DOM 操作的合理规避等等——这正是前端工程师可以真正一展拳脚的地方。学习这些知识,不仅可以帮助我们从根本上提升页面性能,更能够大大加深个人对浏览器底层原理、运行机制的理解,一举两得!
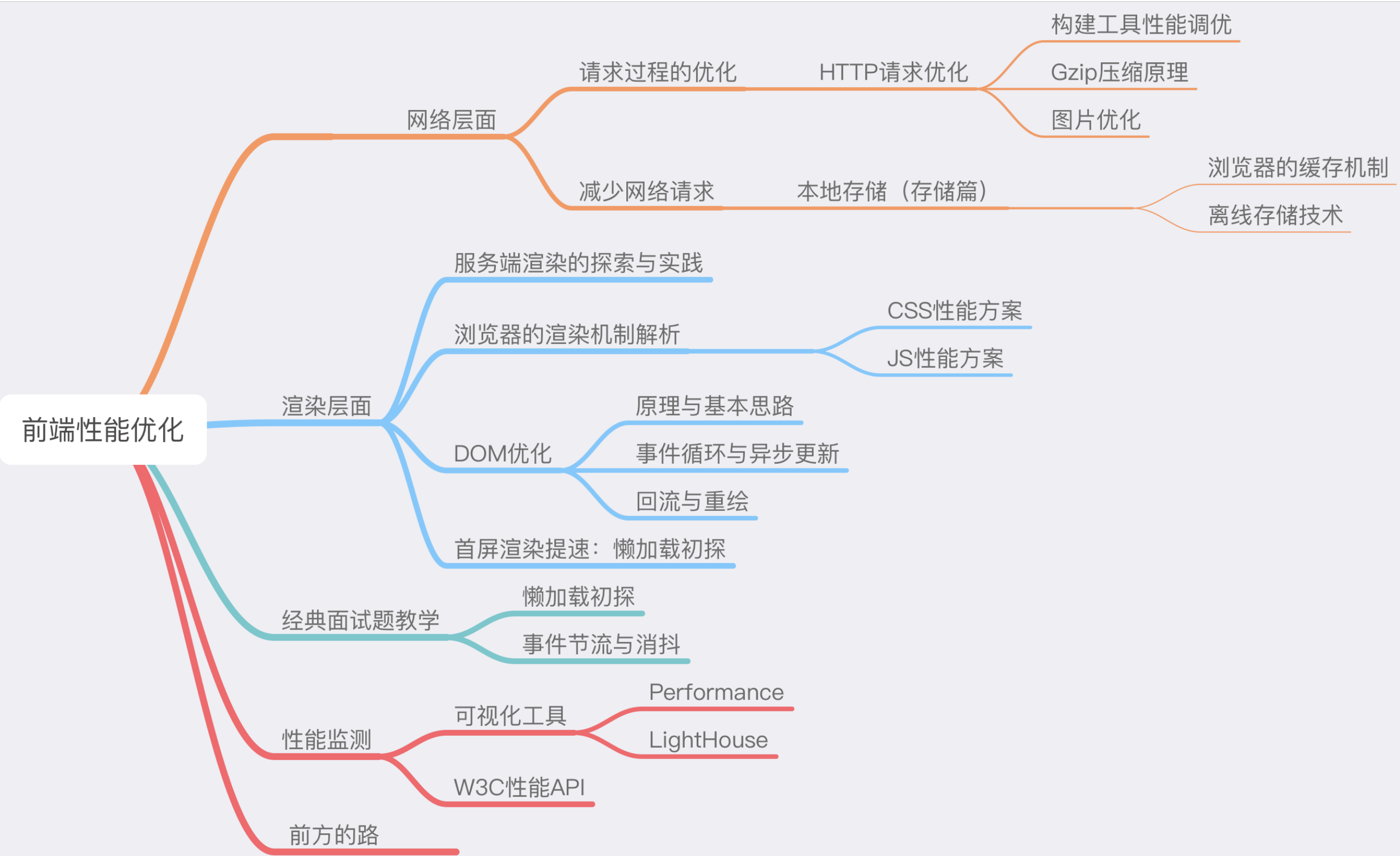
我们整个的知识图谱,用思维导图展示如下:
# 二、网络篇 1:webpack 性能调优与 Gzip 原理
从现在开始,我们进入网络层面的性能优化世界。
大家可以从第一节的示意图中看出,我们从输入 URL 到显示页面这个过程中,涉及到网络层面的,有三个主要过程:
DNS解析TCP连接HTTP请求/响应
对于 DNS 解析和 TCP 连接两个步骤,我们前端可以做的努力非常有限。相比之下,HTTP 连接这一层面的优化才是我们网络优化的核心。因此我们开门见山,抓主要矛盾,直接从 HTTP 开始讲起。
HTTP 优化有两个大的方向:
- 减少请求次数
- 减少单次请求所花费的时间
这两个优化点直直地指向了我们日常开发中非常常见的操作——资源的压缩与合并。没错,这就是我们每天用构建工具在做的事情。而时下最主流的构建工具无疑是 webpack,所以我们这节的主要任务就是围绕业界霸主 webpack 来做文章。
# webpack 的性能瓶颈
相信每个用过 webpack 的同学都对“打包”和“压缩”这样的事情烂熟于心。这些老生常谈的特性,我更推荐大家去阅读文档。而关于 webpack 的详细操作,则推荐大家读读这本 关于 webpack 的掘金小册 (opens new window),这里我们把注意力放在 webpack 的性能优化上。
webpack 的优化瓶颈,主要是两个方面:
webpack的构建过程太花时间webpack打包的结果体积太大
# webpack 优化方案
1. 构建过程提速策略
1.1 不要让 loader 做太多事情——以 babel-loader 为例
babel-loader 无疑是强大的,但它也是慢的。
最常见的优化方式是,用
include或exclude来帮我们避免不必要的转译,比如webpack官方在介绍babel-loader时给出的示例:
module: {
rules: [
{
test: /\.js$/,
exclude: /(node_modules|bower_components)/,
use: {
loader: 'babel-loader',
options: {
presets: ['@babel/preset-env']
}
}
}
]
}
这段代码帮我们规避了对庞大的
node\_modules文件夹或者bower\_components文件夹的处理。但通过限定文件范围带来的性能提升是有限的。除此之外,如果我们选择开启缓存将转译结果缓存至文件系统,则至少可以将 babel-loader 的工作效率提升两倍。要做到这点,我们只需要为loader增加相应的参数设定:
loader: 'babel-loader?cacheDirectory=true'
- 以上都是在讨论针对
loader的配置,但我们的优化范围不止是loader们。
举个🌰,尽管我们可以在
loader配置时通过写入exclude去避免babel-loader对不必要的文件的处理,但是考虑到这个规则仅作用于这个loader,像一些类似UglifyJsPlugin的webpack插件在工作时依然会被这些庞大的第三方库拖累,webpack构建速度依然会因此大打折扣。所以针对这些庞大的第三方库,我们还需要做一些额外的努力。
1.2 不要放过第三方库
第三方库以
node\_modules为代表,它们庞大得可怕,却又不可或缺。
- 处理第三方库的姿势有很多,其中,
Externals不够聪明,一些情况下会引发重复打包的问题;而CommonsChunkPlugin每次构建时都会重新构建一次vendor;出于对效率的考虑,我们这里为大家推荐DllPlugin。 DllPlugin是基于Windows动态链接库(dll)的思想被创作出来的。这个插件会把第三方库单独打包到一个文件中,这个文件就是一个单纯的依赖库。这个依赖库不会跟着你的业务代码一起被重新打包,只有当依赖自身发生版本变化时才会重新打包。
用
DllPlugin处理文件,要分两步走:
- 基于
dll专属的配置文件,打包dll库 - 基于
webpack.config.js文件,打包业务代码
以一个基于 React 的简单项目为例,我们的
dll的配置文件可以编写如下:
const path = require('path')
const webpack = require('webpack')
module.exports = {
entry: {
// 依赖的库数组
vendor: [
'prop-types',
'babel-polyfill',
'react',
'react-dom',
'react-router-dom',
]
},
output: {
path: path.join(__dirname, 'dist'),
filename: '[name].js',
library: '[name]_[hash]',
},
plugins: [
new webpack.DllPlugin({
// DllPlugin的name属性需要和libary保持一致
name: '[name]_[hash]',
path: path.join(__dirname, 'dist', '[name]-manifest.json'),
// context需要和webpack.config.js保持一致
context: __dirname,
}),
],
}
编写完成之后,运行这个配置文件,我们的
dist文件夹里会出现这样两个文件:
vendor-manifest.json
vendor.js
vendor.js不必解释,是我们第三方库打包的结果。这个多出来的vendor-manifest.json,则用于描述每个第三方库对应的具体路径,我这里截取一部分给大家看下:
{
"name": "vendor_397f9e25e49947b8675d",
"content": {
"./node_modules/core-js/modules/_export.js": {
"id": 0,
"buildMeta": {
"providedExports": true
}
},
"./node_modules/prop-types/index.js": {
"id": 1,
"buildMeta": {
"providedExports": true
}
},
...
}
}
随后,我们只需在
webpack.config.js里针对dll稍作配置:
const path = require('path');
const webpack = require('webpack')
module.exports = {
mode: 'production',
// 编译入口
entry: {
main: './src/index.js'
},
// 目标文件
output: {
path: path.join(__dirname, 'dist/'),
filename: '[name].js'
},
// dll相关配置
plugins: [
new webpack.DllReferencePlugin({
context: __dirname,
// manifest就是我们第一步中打包出来的json文件
manifest: require('./dist/vendor-manifest.json'),
})
]
}
一次基于
dll的webpack构建过程优化,便大功告成了!
1.3 Happypack——将 loader 由单进程转为多进程
大家知道,
webpack是单线程的,就算此刻存在多个任务,你也只能排队一个接一个地等待处理。这是webpack的缺点,好在我们的CPU是多核的,Happypack会充分释放 CPU 在多核并发方面的优势,帮我们把任务分解给多个子进程去并发执行,大大提升打包效率。
HappyPack的使用方法也非常简单,只需要我们把对loader的配置转移到HappyPack中去就好,我们可以手动告诉HappyPack我们需要多少个并发的进程:
const HappyPack = require('happypack')
// 手动创建进程池
const happyThreadPool = HappyPack.ThreadPool({ size: os.cpus().length })
module.exports = {
module: {
rules: [
...
{
test: /\.js$/,
// 问号后面的查询参数指定了处理这类文件的HappyPack实例的名字
loader: 'happypack/loader?id=happyBabel',
...
},
],
},
plugins: [
...
new HappyPack({
// 这个HappyPack的“名字”就叫做happyBabel,和楼上的查询参数遥相呼应
id: 'happyBabel',
// 指定进程池
threadPool: happyThreadPool,
loaders: ['babel-loader?cacheDirectory']
})
],
}
# 构建结果体积压缩
1. 文件结构可视化,找出导致体积过大的原因
这里为大家介绍一个非常好用的包组成可视化工具——webpack-bundle-analyzer (opens new window),配置方法和普通的 plugin 无异,它会以矩形树图的形式将包内各个模块的大小和依赖关系呈现出来,格局如官方所提供这张图所示:
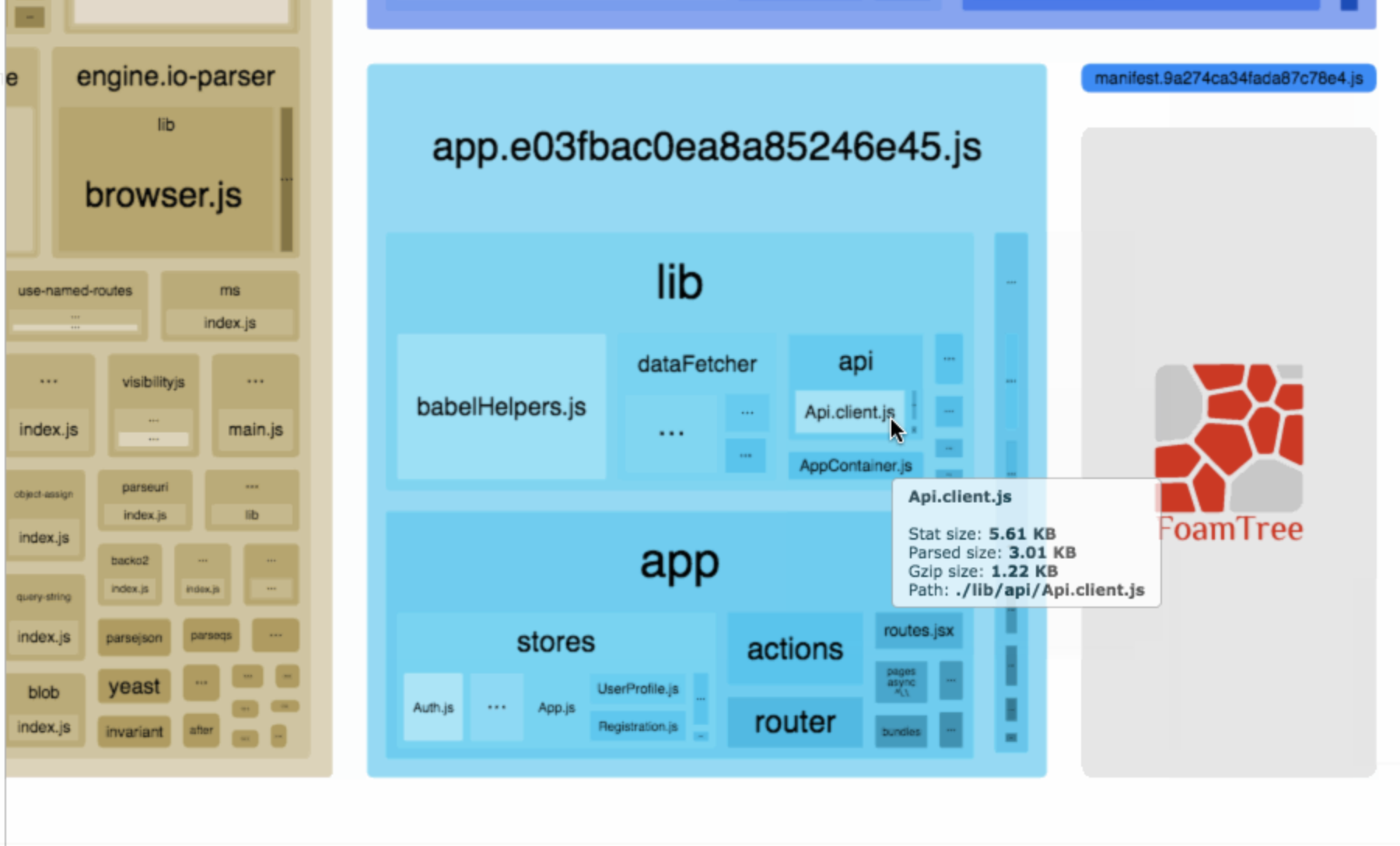
在使用时,我们只需要将其以插件的形式引入:
const BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin;
module.exports = {
plugins: [
new BundleAnalyzerPlugin()
]
}
2. 拆分资源
这点仍然围绕
DllPlugin展开,可参考上文。
2.1 删除冗余代码
- 一个比较典型的应用,就是
Tree-Shaking。 - 从
webpack2开始,webpack 原生支持了 ES6 的模块系统,并基于此推出了Tree-Shaking。webpack 官方是这样介绍它的:
Tree shaking is a term commonly used in the JavaScript context for dead-code elimination, or more precisely, live-code import. It relies on ES2015 module import/export for the static structure of its module system.
- 意思是基于
import/export语法,Tree-Shaking可以在编译的过程中获悉哪些模块并没有真正被使用,这些没用的代码,在最后打包的时候会被去除。 - 举个🌰,假设我的主干文件(入口文件)是这么写的:
import { page1, page2 } from './pages'
// show是事先定义好的函数,大家理解它的功能是展示页面即可
show(page1)
pages文件里,我虽然导出了两个页面:
export const page1 = xxx
export const page2 = xxx
但因为
page2事实上并没有被用到(这个没有被用到的情况在静态分析的过程中是可以被感知出来的),所以打包的结果里会把这部分:
export const page2 = xxx;
- 直接删掉,这就是
Tree-Shaking帮我们做的事情。 - 相信大家不难看出,
Tree-Shaking的针对性很强,它更适合用来处理模块级别的冗余代码。至于粒度更细的冗余代码的去除,往往会被整合进 JS 或 CSS 的压缩或分离过程中。 - 这里我们以当下接受度较高的
UglifyJsPlugin为例,看一下如何在压缩过程中对碎片化的冗余代码(如console语句、注释等)进行自动化删除:
const UglifyJsPlugin = require('uglifyjs-webpack-plugin');
module.exports = {
plugins: [
new UglifyJsPlugin({
// 允许并发
parallel: true,
// 开启缓存
cache: true,
compress: {
// 删除所有的console语句
drop_console: true,
// 把使用多次的静态值自动定义为变量
reduce_vars: true,
},
output: {
// 不保留注释
comment: false,
// 使输出的代码尽可能紧凑
beautify: false
}
})
]
}
- 有心的同学会注意到,这段手动引入
UglifyJsPlugin的代码其实是webpack3的用法,webpack4现在已经默认使用uglifyjs-webpack-plugin对代码做压缩了——在webpack4中,我们是通过配置optimization.minimize与optimization.minimizer来自定义压缩相关的操作的。 - 这里也引出了我们学习性能优化的一个核心的理念——用什么工具,怎么用,并不是我们这本小册的重点,因为所有的工具都存在用法迭代的问题。但现在大家知道了在打包的过程中做一些如上文所述的“手脚”可以实现打包结果的最优化,那下次大家再去执行打包操作,会不会对这个操作更加留心,从而自己去寻找彼时操作的具体实现方案呢?我最希望大家掌握的技能就是,先在脑海中留下“这个xx操作是对的,是有用的”,在日后的实践中,可以基于这个认知去寻找把正确的操作落地的具体方案。
2.2 按需加载
大家想象这样一个场景。我现在用 React 构建一个单页应用,用 React-Router 来控制路由,十个路由对应了十个页面,这十个页面都不简单。如果我把这整个项目打一个包,用户打开我的网站时,会发生什么?有很大机率会卡死,对不对?更好的做法肯定是先给用户展示主页,其它页面等请求到了再加载。当然这个情况也比较极端,但却能很好地引出按需加载的思想:
一次不加载完所有的文件内容,只加载此刻需要用到的那部分(会提前做拆分)
当需要更多内容时,再对用到的内容进行即时加载
好,既然说到这十个
Router了,我们就拿其中一个开刀,假设我这个 Router 对应的组件叫做BugComponent,来看看我们如何利用webpack做到该组件的按需加载。
当我们不需要按需加载的时候,我们的代码是这样的:
import BugComponent from '../pages/BugComponent'
...
<Route path="/bug" component={BugComponent}>
- 为了开启按需加载,我们要稍作改动。
- 首先 webpack 的配置文件要走起来:
output: {
path: path.join(__dirname, '/../dist'),
filename: 'app.js',
publicPath: defaultSettings.publicPath,
// 指定 chunkFilename
chunkFilename: '[name].[chunkhash:5].chunk.js',
},
路由处的代码也要做一下配合:
const getComponent => (location, cb) {
require.ensure([], (require) => {
cb(null, require('../pages/BugComponent').default)
}, 'bug')
},
...
<Route path="/bug" getComponent={getComponent}>
对,核心就是这个方法:
require.ensure(dependencies, callback, chunkName)
- 这是一个异步的方法,webpack 在打包时,
BugComponent会被单独打成一个文件,只有在我们跳转 bug 这个路由的时候,这个异步方法的回调才会生效,才会真正地去获取BugComponent的内容。这就是按需加载。 - 按需加载的粒度,还可以继续细化,细化到更小的组件、细化到某个功能点,都是 ok 的。
等等,这和说好的不一样啊?不是说 Code-Splitting 才是 React-Router 的按需加载实践吗?
- 没错,在 React-Router4 中,我们确实是用
Code-Splitting替换掉了楼上这个操作。而且如果有使用过 React-Router4 实现过路由级别的按需加载的同学,可能会对React-Router4里用到的一个叫“Bundle-Loader”的东西印象深刻。我想很多同学读到按需加载这里,心里的预期或许都是时下大热的Code-Splitting,而非我呈现出来的这段看似“陈旧”的代码。 - 但是,如果大家稍微留个心眼,去看一下
Bundle Loader并不长的源代码的话,你会发现它竟然还是使用 require.ensure 来实现的——这也是我要把require.ensure单独拎出来的重要原因。所谓按需加载,根本上就是在正确的时机去触发相应的回调。理解了这个require.ensure的玩法,大家甚至可以结合业务自己去修改一个按需加载模块来用。
这也应了我之前跟大家强调那段话,工具永远在迭代,唯有掌握核心思想,才可以真正做到举一反三——唯“心”不破!
# Gzip 压缩原理
前面说了不少 webpack 的故事,目的还是帮大家更好地实现压缩和合并。说到压缩,可不只是构建工具的专利。我们日常开发中,其实还有一个便宜又好用的压缩操作:开启
Gzip。
具体的做法非常简单,只需要你在你的 request headers 中加上这么一句:
accept-encoding:gzip
相信很多同学对
Gzip也是了解到这里。之所以为大家开这个彩蛋性的小节,绝不是出于炫技要来给大家展示一下Gzip的压缩算法,而是想和大家聊一个和我们前端关系更密切的话题:HTTP压缩。
HTTP 压缩是一种内置到网页服务器和网页客户端中以改进传输速度和带宽利用率的方式。在使用
HTTP压缩的情况下,HTTP 数据在从服务器发送前就已压缩:兼容的浏览器将在下载所需的格式前宣告支持何种方法给服务器;不支持压缩方法的浏览器将下载未经压缩的数据。最常见的压缩方案包括Gzip和Deflate。
以上是摘自百科的解释,事实上,大家可以这么理解:
HTTP 压缩就是以缩小体积为目的,对 HTTP 内容进行重新编码的过程
Gzip的内核就是Deflate,目前我们压缩文件用得最多的就是Gzip。可以说,Gzip就是HTTP压缩的经典例题。
1. 该不该用 Gzip
- 如果你的项目不是极端迷你的超小型文件,我都建议你试试
Gzip。 - 有的同学或许存在这样的疑问:压缩
Gzip,服务端要花时间;解压Gzip,浏览器要花时间。中间节省出来的传输时间,真的那么可观吗?
答案是肯定的。如果你手上的项目是
1k、2k的小文件,那确实有点高射炮打蚊子的意思,不值当。但更多的时候,我们处理的都是具备一定规模的项目文件。实践证明,这种情况下压缩和解压带来的时间开销相对于传输过程中节省下的时间开销来说,可以说是微不足道的。
2. Gzip 是万能的吗
- 首先要承认
Gzip是高效的,压缩后通常能帮我们减少响应 70% 左右的大小。 - 但它并非万能。
Gzip并不保证针对每一个文件的压缩都会使其变小。
Gzip压缩背后的原理,是在一个文本文件中找出一些重复出现的字符串、临时替换它们,从而使整个文件变小。根据这个原理,文件中代码的重复率越高,那么压缩的效率就越高,使用Gzip的收益也就越大。反之亦然。
3. webpack 的 Gzip 和服务端的 Gzip
- 一般来说,
Gzip压缩是服务器的活儿:服务器了解到我们这边有一个Gzip压缩的需求,它会启动自己的CPU去为我们完成这个任务。而压缩文件这个过程本身是需要耗费时间的,大家可以理解为我们以服务器压缩的时间开销和CPU开销(以及浏览器解析压缩文件的开销)为代价,省下了一些传输过程中的时间开销。 - 既然存在着这样的交换,那么就要求我们学会权衡。服务器的
CPU性能不是无限的,如果存在大量的压缩需求,服务器也扛不住的。服务器一旦因此慢下来了,用户还是要等。Webpack 中Gzip压缩操作的存在,事实上就是为了在构建过程中去做一部分服务器的工作,为服务器分压。 - 因此,这两个地方的
Gzip压缩,谁也不能替代谁。它们必须和平共处,好好合作。作为开发者,我们也应该结合业务压力的实际强度情况,去做好这其中的权衡。
# 三、网络篇 2:图片优化——质量与性能的博弈
《高性能网站建设指南》的作者 Steve Souders 曾在 2013 年的一篇 博客 (opens new window) 中提到:
我的大部分性能优化工作都集中在
JavaScript和CSS上,从早期的 Move Scripts to the Bottom 和 Put Stylesheets at the Top 规则。为了强调这些规则的重要性,我甚至说过,“JS 和 CSS 是页面上最重要的部分”。几个月后,我意识到这是错误的。图片才是页面上最重要的部分。
我关注 JS 和 CSS 的重点也是如何能够更快地下载图片。图片是用户可以直观看到的。他们并不会关注 JS 和 CSS。确实,JS 和 CSS 会影响图片内容的展示,尤其是会影响图片的展示方式(比如图片轮播,CSS 背景图和媒体查询)。但是我认为 JS 和 CSS 只是展示图片的方式。在页面加载的过程中,应当先让图片和文字先展示,而不是试图保证 JS 和 CSS 更快下载完成。
这段话可谓字字珠玑。此外,雅虎军规和 Google 官方的最佳实践也都将图片优化列为前端性能优化必不可少的环节——图片优化的优先级可见一斑。
就图片这块来说,与其说我们是在做“优化”,不如说我们是在做“权衡”。因为我们要做的事情,就是去压缩图片的体积(或者一开始就选取体积较小的图片格式)。但这个优化操作,是以牺牲一部分成像质量为代价的。因此我们的主要任务,是尽可能地去寻求一个质量与性能之间的平衡点。
# 2018 年,图片依然很大
这里先给大家介绍 HTTP-Archive (opens new window) 这个网站,它会定期抓取 Web 上的站点,并记录资源的加载情况、Web API 的使用情况等页面的详细信息,并会对这些数据进行处理和分析以确定趋势。通过它我们可以实时地看到世界范围内的 Web 资源的统计结果。
截止到 2018 年 8 月,过去一年总的 web 资源的平均请求体积是这样的:
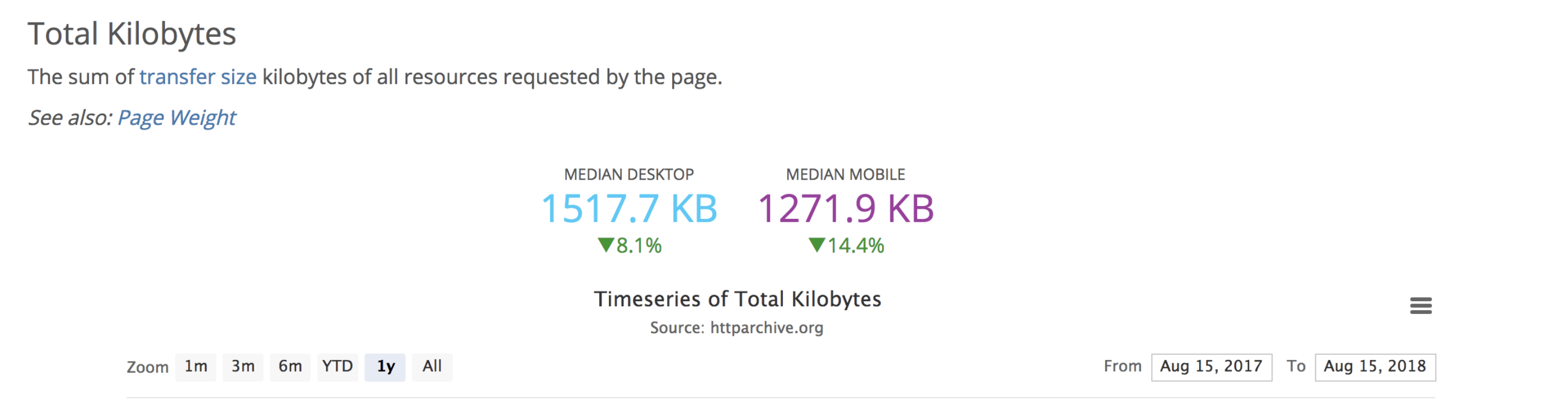
而具体到图片这一类的资源,平均请求体积是这样的:

当然,随着我们工程师在性能方面所做的努力越来越有成效,平均来说,不管是资源总量还是图片体积,都在往越来越轻量的方向演化。这是一种值得肯定的进步。
但同时我们不得不承认,如图所示的这个图片体积,依然是太大了。图片在所有资源中所占的比重,也足够“触目惊心”了。为了改变这个现状,我们必须把图片优化提上日程。
# 不同业务场景下的图片方案选型
时下应用较为广泛的 Web 图片格式有
JPEG/JPG、PNG、WebP、Base64、SVG等,这些格式都是很有故事的,值得我们好好研究一把。此外,老生常谈的雪碧图(CSS Sprites)至今也仍在一线的前端应用中发光发热,我们也会有所提及。
不谈业务场景的选型都是耍流氓。下面我们就结合具体的业务场景,一起来解开图片选型的神秘面纱!
1. 前置知识:二进制位数与色彩的关系
- 在计算机中,像素用二进制数来表示。不同的图片格式中像素与二进制位数之间的对应关系是不同的。一个像素对应的二进制位数越多,它可以表示的颜色种类就越多,成像效果也就越细腻,文件体积相应也会越大。
- 一个二进制位表示两种颜色(
0|1对应黑|白),如果一种图片格式对应的二进制位数有n个,那么它就可以呈现2^n种颜色。
2. JPEG/JPG
关键字:有损压缩、体积小、加载快、不支持透明
2.1 JPG 的优点
JPG最大的特点是有损压缩。这种高效的压缩算法使它成为了一种非常轻巧的图片格式。另一方面,即使被称为“有损”压缩,JPG的压缩方式仍然是一种高质量的压缩方式:当我们把图片体积压缩至原有体积的 50% 以下时,JPG 仍然可以保持住 60% 的品质。此外,JPG 格式以 24 位存储单个图,可以呈现多达 1600 万种颜色,足以应对大多数场景下对色彩的要求,这一点决定了它压缩前后的质量损耗并不容易被我们人类的肉眼所察觉——前提是你用对了业务场景。
2.2 使用场景
- JPG 适用于呈现色彩丰富的图片,在我们日常开发中,JPG 图片经常作为大的背景图、轮播图或 Banner 图出现。
- 两大电商网站对大图的处理,是 JPG 图片应用场景的最佳写照:
- 打开淘宝首页,我们可以发现页面中最醒目、最庞大的图片,一定是以 .jpg 为后缀的:
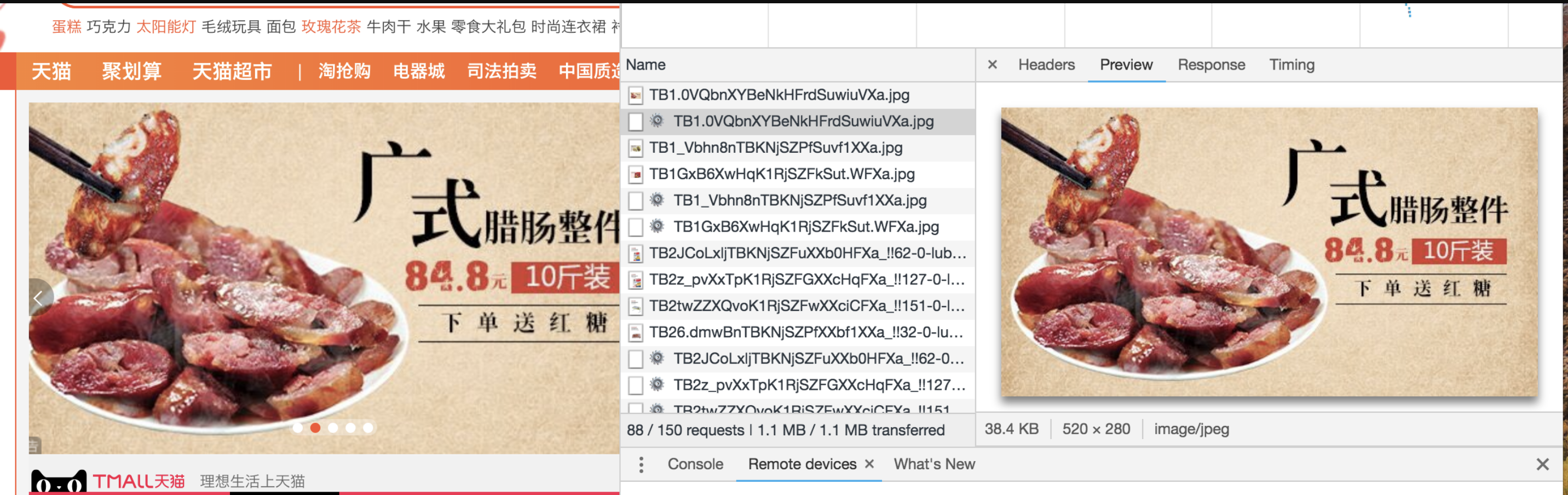
京东首页也不例外:
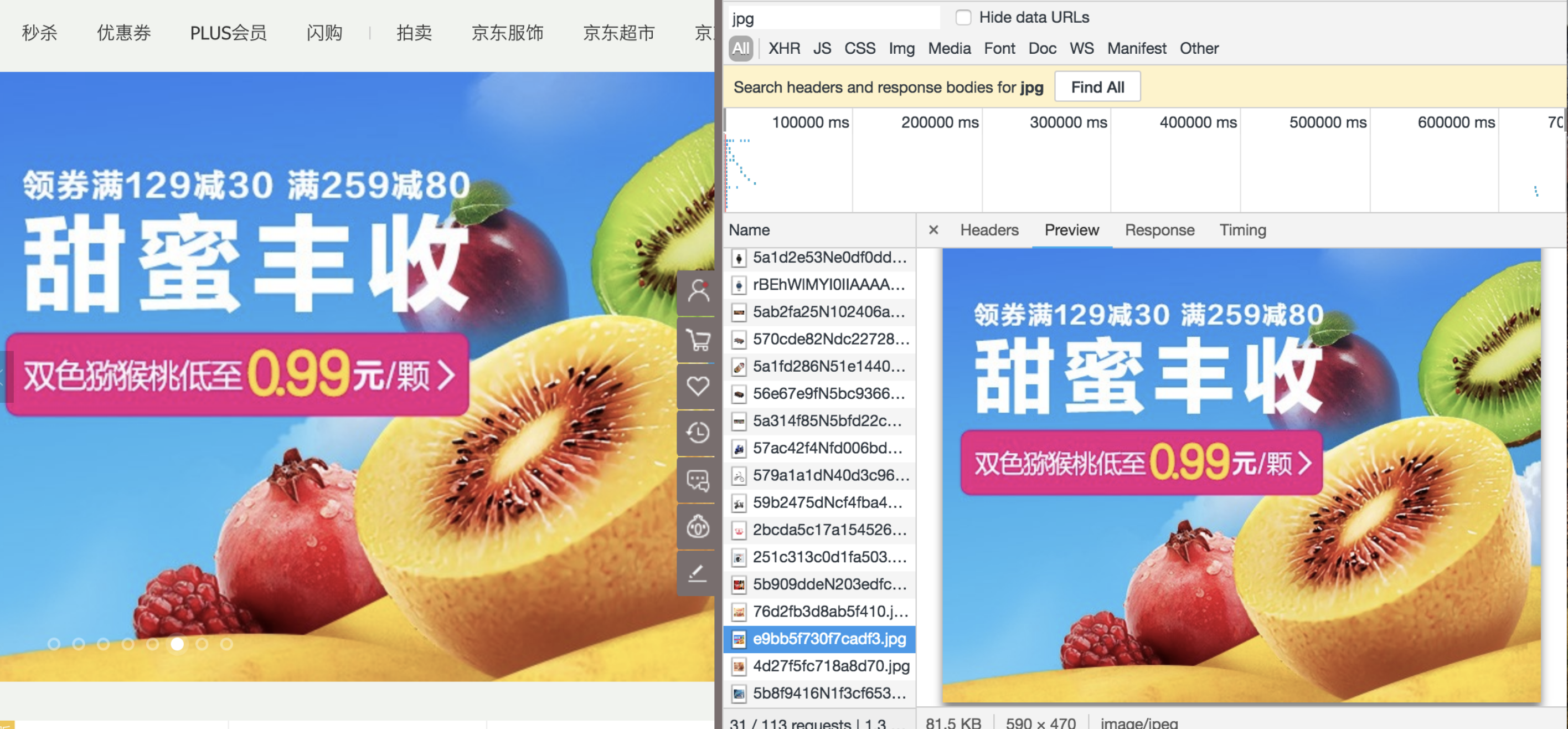
使用 JPG 呈现大图,既可以保住图片的质量,又不会带来令人头疼的图片体积,是当下比较推崇的一种方案。
2.3 JPG 的缺陷
有损压缩在上文所展示的轮播图上确实很难露出马脚,但当它处理矢量图形和 Logo 等线条感较强、颜色对比强烈的图像时,人为压缩导致的图片模糊会相当明显。
此外,JPEG 图像不支持透明度处理,透明图片需要召唤 PNG 来呈现。
3. PNG-8 与 PNG-24
关键字:无损压缩、质量高、体积大、支持透明
3.1 PNG 的优点
PNG(可移植网络图形格式)是一种无损压缩的高保真的图片格式。8 和 24,这里都是二进制数的位数。按照我们前置知识里提到的对应关系,8 位的 PNG 最多支持 256 种颜色,而 24 位的可以呈现约 1600 万种颜色。PNG图片具有比 JPG 更强的色彩表现力,对线条的处理更加细腻,对透明度有良好的支持。它弥补了上文我们提到的 JPG 的局限性,唯一的 BUG 就是体积太大。
3.2 PNG-8 与 PNG-24 的选择题
- 什么时候用
PNG-8,什么时候用PNG-24,这是一个问题。 - 理论上来说,当你追求最佳的显示效果、并且不在意文件体积大小时,是推荐使用
PNG-24的。 - 但实践当中,为了规避体积的问题,我们一般不用PNG去处理较复杂的图像。当我们遇到适合 PNG 的场景时,也会优先选择更为小巧的 PNG-8。
- 如何确定一张图片是该用
PNG-8还是PNG-24去呈现呢?好的做法是把图片先按照这两种格式分别输出,看 PNG-8 输出的结果是否会带来肉眼可见的质量损耗,并且确认这种损耗是否在我们(尤其是你的 UI 设计师)可接受的范围内,基于对比的结果去做判断。
3.3 应用场景
- 前面我们提到,复杂的、色彩层次丰富的图片,用 PNG 来处理的话,成本会比较高,我们一般会交给 JPG 去存储。
- 考虑到
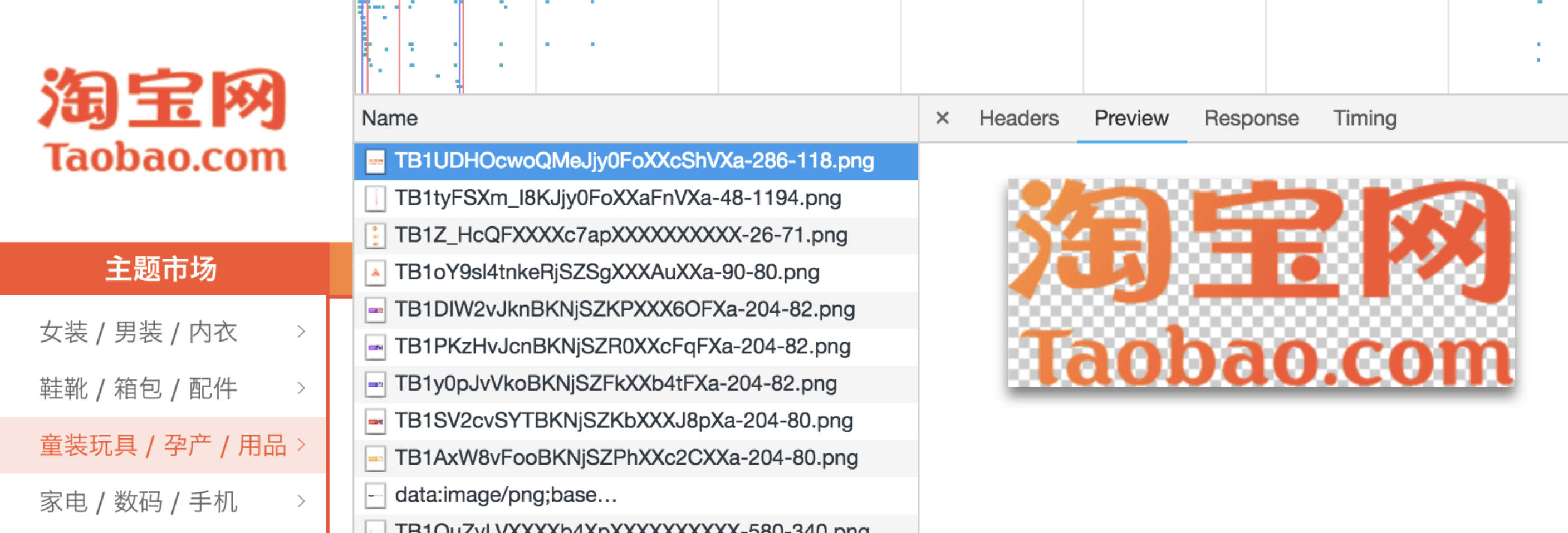
PNG在处理线条和颜色对比度方面的优势,我们主要用它来呈现小的 Logo、颜色简单且对比强烈的图片或背景等。 - 此时我们再次把目光转向性能方面堪称业界楷模的淘宝首页,我们会发现它页面上的
Logo,无论大小,还真的都是PNG格式:
主 Logo:
较小的 Logo:
颜色简单、对比度较强的透明小图也在 PNG 格式下有着良好的表现:
4. SVG
关键字:文本文件、体积小、不失真、兼容性好
SVG(可缩放矢量图形)是一种基于 XML 语法的图像格式。它和本文提及的其它图片种类有着本质的不同:SVG 对图像的处理不是基于像素点,而是是基于对图像的形状描述。
4.1 SVG 的特性
和性能关系最密切的一点就是:SVG 与 PNG 和 JPG 相比,文件体积更小,可压缩性更强。
当然,作为矢量图,它最显著的优势还是在于图片可无限放大而不失真这一点上。这使得 SVG 即使是被放到视网膜屏幕上,也可以一如既往地展现出较好的成像品质——1 张 SVG 足以适配 n 种分辨率。
此外,SVG 是文本文件。我们既可以像写代码一样定义 SVG,把它写在 HTML 里、成为 DOM 的一部分,也可以把对图形的描述写入以 .svg 为后缀的独立文件(SVG 文件在使用上与普通图片文件无异)。这使得 SVG 文件可以被非常多的工具读取和修改,具有较强的灵活性。
SVG 的局限性主要有两个方面,一方面是它的渲染成本比较高,这点对性能来说是很不利的。另一方面,SVG 存在着其它图片格式所没有的学习成本(它是可编程的)。
4.2 SVG 的使用方式与应用场景
SVG 是文本文件,我们既可以像写代码一样定义 SVG,把它写在 HTML 里、成为 DOM 的一部分,也可以把对图形的描述写入以 .svg 为后缀的独立文件(SVG 文件在使用上与普通图片文件无异)。
- 将 SVG 写入 HTML:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title></title>
</head>
<body>
<svg xmlns="http://www.w3.org/2000/svg" width="200" height="200">
<circle cx="50" cy="50" r="50" />
</svg>
</body>
</html>
- 将 SVG 写入独立文件后引入 HTML:
<img src="文件名.svg" alt="">
在实际开发中,我们更多用到的是后者。很多情况下设计师会给到我们 SVG 文件,就算没有设计师,我们还有非常好用的 在线矢量图形库 (opens new window)。对于矢量图,我们无须深究过多,只需要对其核心特性有所掌握、日后在应用时做到有迹可循即可。
5. Base64
关键字:文本文件、依赖编码、小图标解决方案
Base64 并非一种图片格式,而是一种编码方式。Base64 和雪碧图一样,是作为小图标解决方案而存在的。在了解 Base64 之前,我们先来了解一下雪碧图。
5.1 前置知识:最经典的小图标解决方案——雪碧图(CSS Sprites)
雪碧图、CSS 精灵、CSS Sprites、图像精灵,说的都是这个东西——一种将小图标和背景图像合并到一张图片上,然后利用 CSS 的背景定位来显示其中的每一部分的技术。
MDN 对雪碧图的解释已经非常到位:
图像精灵(sprite,意为精灵),被运用于众多使用大量小图标的网页应用之上。它可取图像的一部分来使用,使得使用一个图像文件替代多个小文件成为可能。相较于一个小图标一个图像文件,单独一张图片所需的 HTTP 请求更少,对内存和带宽更加友好。
我们几乎可以在每一个有小图标出现的网站里找到雪碧图的影子(下图截取自京东首页):
和雪碧图一样,Base64 图片的出现,也是为了减少加载网页图片时对服务器的请求次数,从而提升网页性能。Base64 是作为雪碧图的补充而存在的。
5.2 理解 Base64
通过我们上文的演示,大家不难看出,每次加载图片,都是需要单独向服务器请求这个图片对应的资源的——这也就意味着一次 HTTP 请求的开销。
Base64 是一种用于传输 8Bit 字节码的编码方式,通过对图片进行 Base64 编码,我们可以直接将编码结果写入 HTML 或者写入 CSS,从而减少 HTTP 请求的次数。
我们来一起看一个实例,现在我有这么一个小小的放大镜 Logo:

它对应的链接如下:
https://user-gold-cdn.xitu.io/2018/9/15/165db7e94699824b?w=22&h=22&f=png&s=3680
按照一贯的思路,我们加载图片需要把图片链接写入 img 标签:
<img src="https://user-gold-cdn.xitu.io/2018/9/15/165db7e94699824b?w=22&h=22&f=png&s=3680">
- 浏览器就会针对我们的图片链接去发起一个资源请求。
- 但是如果我们对这个图片进行 Base64 编码,我们会得到一个这样的字符串:
data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABYAAAAWCAYAAADEtGw7AAAMJGlDQ1BJQ0MgUHJvZmlsZQAASImVlwdUU8kagOeWJCQktEAEpITeBCnSpdfQpQo2QhJIKDEkBBU7uqjgWlARwYquitjWAshiw14Wwd4fiKgo62LBhsqbFNDV89477z9n7v3yzz9/mcydMwOAehxbJMpFNQDIExaI48MCmeNT05ikR4AECIAKRgEamyMRBcTFRQEoQ+9/yrubAJG9r9nLfP3c/19Fk8uTcABA4iBncCWcPMiHAMDdOCJxAQCEXqg3m1YggkyEWQJtMUwQsrmMsxTsIeMMBUfJbRLjgyCnA6BCZbPFWQCoyfJiFnKyoB+1pZAdhVyBEHIzZF8On82F/BnyqLy8qZDVrSFbZ3znJ+sfPjOGfbLZWcOsqEUuKsECiSiXPeP/nI7/LXm50qEYZrBR+eLweFnNsnnLmRopYyrk88KMmFjIWpCvC7hyexk/4UvDk5T2HziSIDhngAEASuWygyMhG0A2FebGRCn1vpmCUBZkOPdooqCAlagYi3LFU+OV/tHpPElIwhCzxfJYMptSaU5SgNLnRj6PNeSzqYifmKLIE20rFCTHQFaDfF+SkxCptHlexA+KGbIRS+NlOcP/HAOZ4tB4hQ1mnicZqgvz4gtYMUqO4rDl+ehCnlzATwxX+MEKeZLxUUN5cnnBIYq6sGKeMEmZP1YuKgiMV47dJsqNU9pjzbzcMJneFHKrpDBhaGxfAVxsinpxICqIS1TkhmtnsyPiFHFxWxAFgkAwYAIpbBlgKsgGgtbehl74S9ETCthADLIAD9grNUMjUuQ9QvhMAEXgL0g8IBkeFyjv5YFCqP8yrFU87UGmvLdQPiIHPIGcByJBLvwtlY8SDkdLBo+hRvBTdA7MNRc2Wd9POqb6kI4YQgwmhhNDiTa4Pu6Le+NR8OkPmzPugXsO5fXNnvCE0E54RLhB6CDcmSIoFv+QORNEgw6YY6iyuozvq8MtoVdXPBD3gf6hb5yB6wN7fAyMFID7wdiuUPt9rtLhir/NpdIX2ZGMkkeQ/cnWP2Ugm53v61fq1WzVXJV5ZQzPVtCw1Y9egr6bPy58R/5oiS3GDmLnsJPYBawZawBM7DjWiF3Gjsp4eG08lq+NoWjx8txyoB/BT/HYypiyWZM41jn2OH5W9oEC3vQC2ccSNFU0QyzI4hcwA+BuzWOyhByHUUxnRye4i8r2fsXW8oYh39MRxsVvuvwTAHiWQmXWNx0b7kFHngBAf/dNZ/YaLvsVABxt40jFhQodLnsQAAWowy9FDxjBvcsaVuQM3IA38AchIALEgkSQCibDOefDdSoG08AsMB+UgDKwAqwBVWAT2Ap2gj3gAGgAzeAkOAsugTZwA9yDa6UbvAB94B0YQBCEhNAQOqKHGCMWiB3ijHggvkgIEoXEI6lIOpKFCBEpMgtZgJQh5UgVsgWpRX5HjiAnkQtIO3IH6UR6kNfIJxRDqag2aohaoqNRDzQAjUQT0UloFpqPFqEL0WVoJVqD7kbr0ZPoJfQG2oG+QPsxgKliDMwEs8c8sCAsFkvDMjExNgcrxSqwGmwv1gT/6WtYB9aLfcSJOB1n4vZwvYbjSTgHz8fn4EvxKnwnXo+fxq/hnXgf/pVAIxgQ7AheBBZhPCGLMI1QQqggbCccJpyB30434R2RSGQQrYju8NtLJWYTZxKXEjcQ9xFPENuJXcR+EomkR7Ij+ZBiSWxSAamEtI60m3ScdJXUTfqgoqpirOKsEqqSpiJUKVapUNmlckzlqspTlQGyBtmC7EWOJXPJM8jLydvITeQr5G7yAEWTYkXxoSRSsinzKZWUvZQzlPuUN6qqqqaqnqrjVAWq81QrVfernlftVP1I1aLaUoOoE6lS6jLqDuoJ6h3qGxqNZknzp6XRCmjLaLW0U7SHtA9qdDUHNZYaV22uWrVavdpVtZfqZHUL9QD1yepF6hXqB9WvqPdqkDUsNYI02BpzNKo1jmjc0ujXpGs6acZq5mku1dyleUHzmRZJy1IrRIurtVBrq9YprS46RjejB9E59AX0bfQz9G5toraVNks7W7tMe492q3afjpbOGJ1knek61TpHdToYGMOSwWLkMpYzDjBuMj6NMBwRMII3YsmIvSOujnivO1LXX5enW6q7T/eG7ic9pl6IXo7eSr0GvQf6uL6t/jj9afob9c/o947UHuk9kjOydOSBkXcNUANbg3iDmQZbDS4b9BsaGYYZigzXGZ4y7DViGPkbZRutNjpm1GNMN/Y1FhivNj5u/Jypwwxg5jIrmaeZfSYGJuEmUpMtJq0mA6ZWpkmmxab7TB+YUcw8zDLNVpu1mPWZG5tHm88yrzO/a0G28LDgW6y1OGfx3tLKMsVykWWD5TMrXSuWVZFVndV9a5q1n3W+dY31dRuijYdNjs0GmzZb1NbVlm9bbXvFDrVzsxPYbbBrH0UY5TlKOKpm1C17qn2AfaF9nX2nA8MhyqHYocHh5Wjz0WmjV44+N/qro6tjruM2x3tOWk4RTsVOTU6vnW2dOc7VztddaC6hLnNdGl1ejbEbwxuzccxtV7prtOsi1xbXL27ubmK3vW497ubu6e7r3W95aHvEeSz1OO9J8Az0nOvZ7PnRy82rwOuA19/e9t453ru8n421Gssbu21sl4+pD9tni0+HL9M33Xezb4efiR/br8bvkb+ZP9d/u//TAJuA7IDdAS8DHQPFgYcD3wd5Bc0OOhGMBYcFlwa3hmiFJIVUhTwMNQ3NCq0L7QtzDZsZdiKcEB4ZvjL8FsuQxWHVsvoi3CNmR5yOpEYmRFZFPoqyjRJHNUWj0RHRq6Lvx1jECGMaYkEsK3ZV7IM4q7j8uD/GEcfFjase9yTeKX5W/LkEesKUhF0J7xIDE5cn3kuyTpImtSSrJ09Mrk1+nxKcUp7SMX70+NnjL6XqpwpSG9NIaclp29P6J4RMWDOhe6LrxJKJNydZTZo+6cJk/cm5k49OUZ/CnnIwnZCekr4r/TM7ll3D7s9gZazP6OMEcdZyXnD9uau5PTwfXjnvaaZPZnnmsyyfrFVZPXw/fgW/VxAkqBK8yg7P3pT9Pic2Z0fOYG5K7r48lbz0vCNCLWGO8PRUo6nTp7aL7EQloo58r/w1+X3iSPF2CSKZJGks0IaH7MtSa+kv0s5C38Lqwg/TkqcdnK45XTj98gzbGUtmPC0KLfptJj6TM7Nllsms+bM6ZwfM3jIHmZMxp2Wu2dyFc7vnhc3bOZ8yP2f+n8WOxeXFbxekLGhaaLhw3sKuX8J+qStRKxGX3FrkvWjTYnyxYHHrEpcl65Z8LeWWXixzLKso+7yUs/Tir06/Vv46uCxzWetyt+UbVxBXCFfcXOm3cme5ZnlRedeq6FX1q5mrS1e/XTNlzYWKMRWb1lLWStd2VEZVNq4zX7di3ecqftWN6sDqfesN1i9Z/34Dd8PVjf4b924y3FS26dNmwebbW8K21NdY1lRsJW4t3PpkW/K2c795/Fa7XX972fYvO4Q7OnbG7zxd615bu8tg1/I6tE5a17N74u62PcF7Gvfa792yj7GvbD/YL93//Pf0328eiDzQctDj4N5DFofWH6YfLq1H6mfU9zXwGzoaUxvbj0QcaWnybjr8h8MfO5pNmquP6hxdfoxybOGxweNFx/tPiE70nsw62dUypeXeqfGnrp8ed7r1TOSZ82dDz546F3Du+Hmf880XvC4cuehxseGS26X6y66XD//p+ufhVrfW+ivuVxrbPNua2se2H7vqd/XkteBrZ6+zrl+6EXOj/WbSzdu3Jt7quM29/exO7p1XdwvvDtybd59wv/SBxoOKhwYPa/5l8699HW4dRzuDOy8/Snh0r4vT9eKx5PHn7oVPaE8qnho/rX3m/Ky5J7Sn7fmE590vRC8Gekv+0vxr/Uvrl4f+9v/7ct/4vu5X4leDr5e+0Xuz4+2Yty39cf0P3+W9G3hf+kHvw86PHh/PfUr59HRg2mfS58ovNl+avkZ+vT+YNzgoYovZ8qMABhuamQnA6x0A0FLh2aENAMoExd1MLojiPikn8J9YcX+TixsAO/wBSJoHQBQ8o2yEzQIyFb5lR/BEf4C6uAw3pUgyXZwVvqjwxkL4MDj4xhAAUhMAX8SDgwMbBge/bIPJ3gHgRL7iTigT2R10s4OM2rpfgh/l34RUcT2MnhaNAAAB90lEQVQ4Ee1Tv0tbURQ+5yVqFVHs4pBioSAp1mAxUdq05sfoKrh072QXN6HdnMTVyboLShH8D+xLg8UkhjY/tJlERIQilCpKfbmn3w08eOTdl83Nu5x7z/m+737vnHeJHtZ9d4CDLhARK1esfSChWWF6TSQnRLwnSq2mp2OnQTw3bxS2D349I77bAijuAt0oJNfEtJiKj392c6ZotSfhFJfdfUE+jn1eWZwe6HL6Q0yjqHyE6zALr+eK9bl2rvfsc2wXKwskvAZQbibxYsYL1nu7UJ1H2BKiq+bfsaFslp12jD4bHHPLCdwumQi4bBuiP+Gov3vwaMqEMQqz6EER9fHjwyASMGVdU6KeB2F8jjH9cw2+sS5Hg0jodUTXRNFlEMYvzPyjBVa0YCLZpcoE2pBBTYmokgmjcz5hZl7RJEz/vV2oLDcajR6XvHdYT0qTdzQPfd7s9D/7/gotYhdqn/Chy3ovQrfMVMUwh3HpE51rLaGqw+FMNhH97aa80SisAblC9R1EN/AYej0EpGgXpARyEbzKY4i/NYkHCmux/f3GgBP6l8EjiVp40nD8/c3k2Mm3Uu2pUvIVkBEt3vVIpV/FYhea466Owi7IFPPl40jTcfKojaBNB6mp8Wkvzjc8b7HTPvkyehYKh5NwXGbiP52wD7X76cB/EiWtaCMHwyUAAAAASUVORK5CYII=
字符串比较长,我们可以直接用这个字符串替换掉上文中的链接地址。你会发现浏览器原来是可以理解这个字符串的,它自动就将这个字符串解码为了一个图片,而不需再去发送
HTTP请求。
5.3 Base64 的应用场景
既然
Base64这么棒,我们何不把大图也换成Base64呢?
- 这是因为,
Base64编码后,图片大小会膨胀为原文件的4/3(这是由 Base64 的编码原理决定的)。如果我们把大图也编码到 HTML 或 CSS 文件中,后者的体积会明显增加,即便我们减少了 HTTP 请求,也无法弥补这庞大的体积带来的性能开销,得不偿失。 - 在传输非常小的图片的时候,
Base64带来的文件体积膨胀、以及浏览器解析Base64的时间开销,与它节省掉的 HTTP 请求开销相比,可以忽略不计,这时候才能真正体现出它在性能方面的优势。
因此,Base64 并非万全之策,我们往往在一张图片满足以下条件时会对它应用 Base64 编码:
- 图片的实际尺寸很小(大家可以观察一下使用的页面的
Base64图,几乎没有超过2kb的) - 图片无法以雪碧图的形式与其它小图结合(合成雪碧图仍是主要的减少
HTTP请求的途径,Base64是雪碧图的补充) - 图片的更新频率非常低(不需我们重复编码和修改文件内容,维护成本较低)
5.4 Base64 编码工具推荐
这里最推荐的是利用 webpack 来进行 Base64 的编码——webpack 的 url-loader (opens new window) 非常聪明,它除了具备基本的 Base64 转码能力,还可以结合文件大小,帮我们判断图片是否有必要进行 Base64 编码。
除此之外,市面上免费的 Base64 编解码工具种类是非常多样化的,有很多网站都提供在线编解码的服务,大家选取自己认为顺手的工具就好。
6. WebP
关键字:年轻的全能型选手
WebP是今天在座各类图片格式中最年轻的一位,它于 2010 年被提出, 是 Google 专为 Web 开发的一种旨在加快图片加载速度的图片格式,它支持有损压缩和无损压缩。
6.1 WebP 的优点
WebP像JPEG一样对细节丰富的图片信手拈来,像 PNG 一样支持透明,像 GIF 一样可以显示动态图片——它集多种图片文件格式的优点于一身。
WebP 的官方介绍对这一点有着更权威的阐述:
与 PNG 相比,WebP 无损图像的尺寸缩小了 26%。在等效的 SSIM 质量指数下,WebP 有损图像比同类 JPEG 图像小 25-34%。 无损 WebP 支持透明度(也称为 alpha 通道),仅需 22% 的额外字节。对于有损 RGB 压缩可接受的情况,有损 WebP 也支持透明度,与 PNG 相比,通常提供 3 倍的文件大小。
我们开篇提到,图片优化是质量与性能的博弈,从这个角度看,WebP 无疑是真正的赢家。
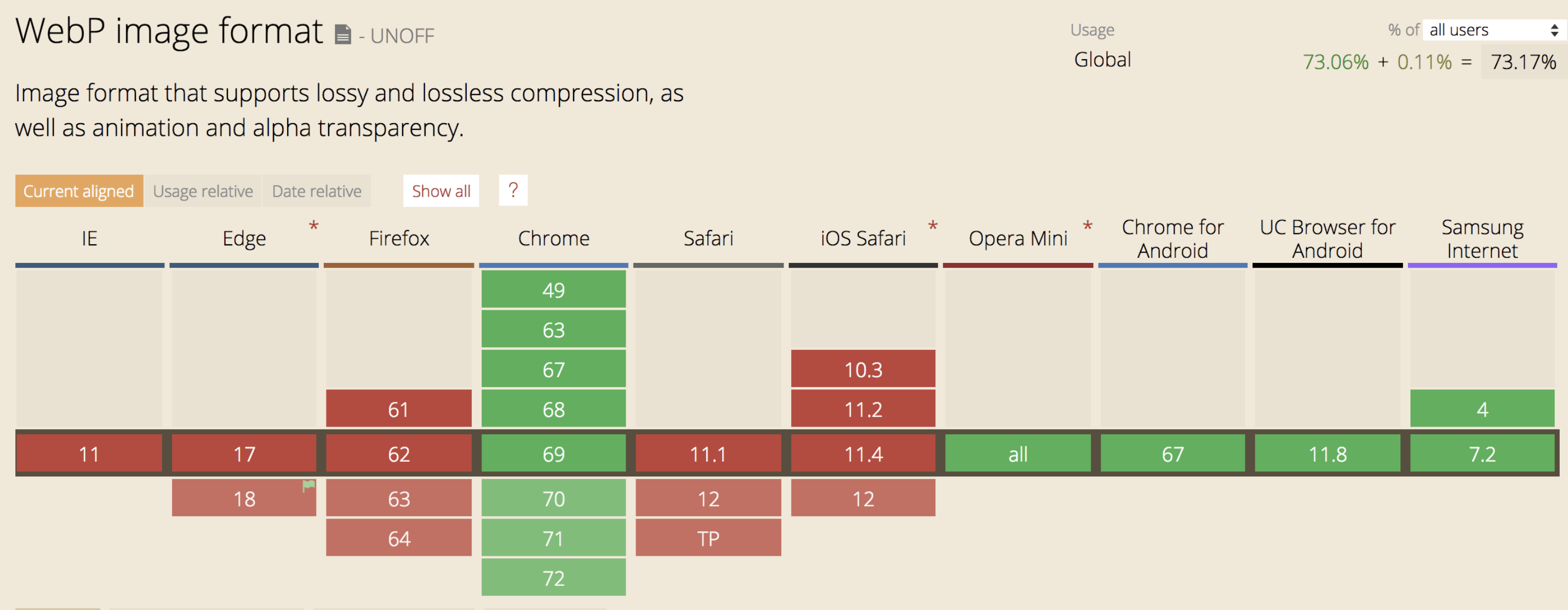
6.2 WebP 的局限性
WebP纵有千般好,但它毕竟太年轻。我们知道,任何新生事物,都逃不开兼容性的大坑。现在是 2018 年 9 月,WebP 的支持情况是这样的:
坦白地说,虽然没有特别惨(毕竟还有亲爹 Chrome 在撑腰),但也足够让人望而却步了。
此外,WebP 还会增加服务器的负担——和编码 JPG 文件相比,编码同样质量的 WebP 文件会占用更多的计算资源。
6.3 WebP 的应用场景
- 现在限制我们使用 WebP 的最大问题不是“这个图片是否适合用 WebP 呈现”的问题,而是“浏览器是否允许 WebP”的问题,即我们上文谈到的兼容性问题。具体来说,一旦我们选择了 WebP,就要考虑在 Safari 等浏览器下它无法显示的问题,也就是说我们需要准备 PlanB,准备降级方案。
- 目前真正把 WebP 格式落地到网页中的网站并不是很多,这其中淘宝首页对 WebP 兼容性问题的处理方式就非常有趣。我们可以打开 Chrome 的开发者工具搜索其源码里的 WebP 关键字:
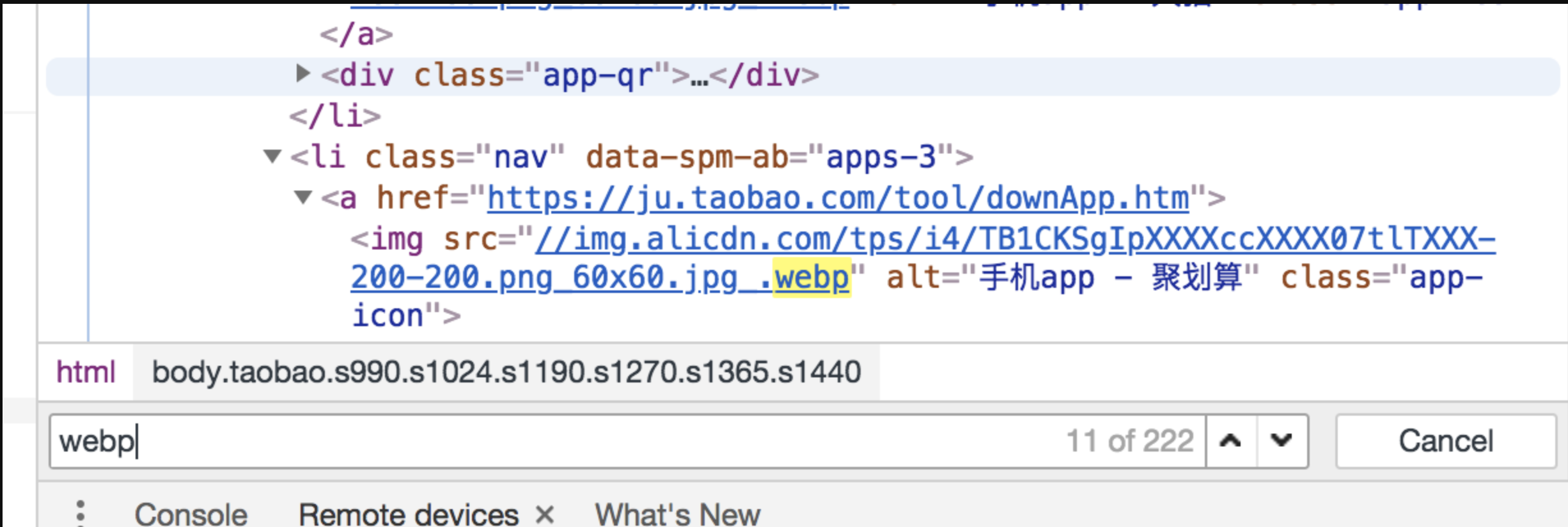
我们会发现检索结果还是挺多的(单就图示的加载结果来看,足足有 200 多条),下面大家注意一下这些 WebP 图片的链接地址(以其中一个为例):
<img src="//img.alicdn.com/tps/i4/TB1CKSgIpXXXXccXXXX07tlTXXX-200-200.png_60x60.jpg_.webp" alt="手机app - 聚划算" class="app-icon">
.webp前面,还跟了一个.jpg后缀!
我们现在先大胆地猜测,这个图片应该至少存在 jpg 和 webp 两种格式,程序会根据浏览器的型号、以及该型号是否支持 WebP 这些信息来决定当前浏览器显示的是 .webp 后缀还是 .jpg 后缀。带着这个预判,我们打开并不支持 WebP 格式的 Safari 来进入同样的页面,再次搜索 WebP 关键字:

Safari 提示我们找不到,这也是情理之中。我们定位到刚刚示例的 WebP 图片所在的元素,查看一下它在 Safari 里的图片链接:
<img src="//img.alicdn.com/tps/i4/TB1CKSgIpXXXXccXXXX07tlTXXX-200-200.png_60x60.jpg" alt="手机app - 聚划算" class="app-icon">
- 我们看到同样的一张图片,在 Safari 中的后缀从
.webp变成了.jpg!看来果然如此——站点确实是先进行了兼容性的预判,在浏览器环境支持WebP的情况下,优先使用 WebP 格式,否则就把图片降级为 JPG 格式(本质是对图片的链接地址作简单的字符串切割)。 - 此外,还有另一个维护性更强、更加灵活的方案——把判断工作交给后端,由服务器根据
HTTP请求头部的 Accept 字段来决定返回什么格式的图片。当Accept字段包含image/webp时,就返回WebP格式的图片,否则返回原图。这种做法的好处是,当浏览器对 WebP 格式图片的兼容支持发生改变时,我们也不用再去更新自己的兼容判定代码,只需要服务端像往常一样对Accept字段进行检查即可。
由此也可以看出,我们
WebP格式的局限性确实比较明显,如果决定使用WebP,兼容性处理是必不可少的。
# 小结
- 不知道大家有没有注意到这一点:在图片这一节,我用到的许多案例图示,都是源于一线的电商网站。
- 为什么这么做?因为图片是电商平台的重要资源,甚至有人说“做电商就是做图片”。淘宝和京东,都是流量巨大、技术成熟的站点,它们在性能优化方面起步早、成效好,很多方面说是教科书般的案例也不为过。
- 这也是非常重要的一个学习方法。在开篇我提到,性能优化不那么好学,有很大原因是因为这块的知识不成体系、难以切入,同时技术方案又迭代得飞快。当我们不知道怎么切入的时候,或者说当我们面对一个具体的问题无从下手的时候,除了翻阅手中的书本(很可能是已经过时的)和网络上收藏的文章(也许没那么权威),现在是不是又多了“打开那些优秀的网站看一看”这条路可以走了呢?
- 好了,至此,我们终于结束了图片优化的征程。下面,我们以存储篇为过渡,进入 JS 和 CSS 的世界!
# 四、存储篇 1:浏览器缓存机制介绍与缓存策略剖析
缓存可以减少网络
IO消耗,提高访问速度。浏览器缓存是一种操作简单、效果显著的前端性能优化手段。对于这个操作的必要性,Chrome 官方给出的解释似乎更有说服力一些:
通过网络获取内容既速度缓慢又开销巨大。较大的响应需要在客户端与服务器之间进行多次往返通信,这会延迟浏览器获得和处理内容的时间,还会增加访问者的流量费用。因此,缓存并重复利用之前获取的资源的能力成为性能优化的一个关键方面。
- 很多时候,大家倾向于将浏览器缓存简单地理解为“HTTP 缓存”。但事实上,浏览器缓存机制有四个方面,它们按照获取资源时请求的优先级依次排列如下:
Memory CacheService Worker CacheHTTP CachePush Cache
大家对
HTTP Cache(即Cache-Control、expires等字段控制的缓存)应该比较熟悉,如果对其它几种缓存可能还没什么概念,我们可以先来看一张线上网站的Network面板截图:
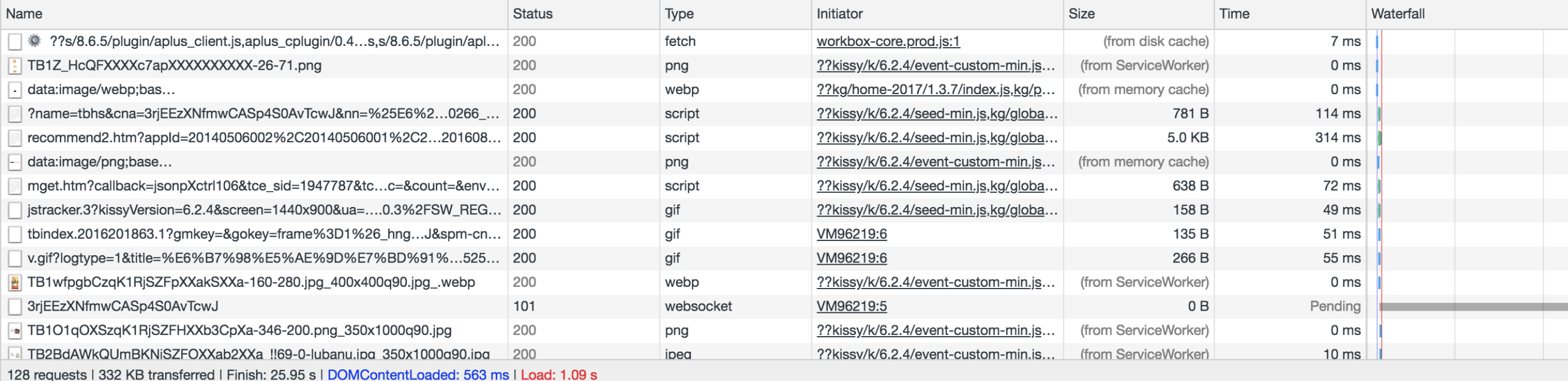
我们给 size 这一栏一个特写:
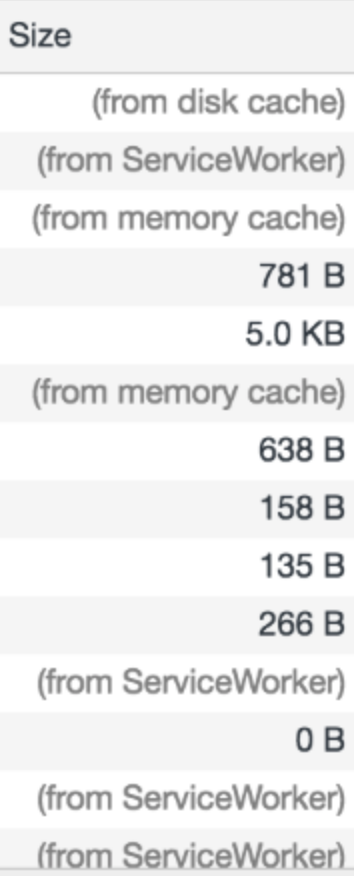
大家注意一下非数字——即形如“(
from xxx)”这样的描述——对应的资源,这些资源就是我们通过缓存获取到的。其中,“from memory cache”对标到Memory Cache类型,“from ServiceWorker”对标到Service Worker Cache类型。至于Push Cache,这个比较特殊,是HTTP2的新特性。
本节将会针对这四个方面各个击破。考虑到 HTTP 缓存是最主要、最具有代表性的缓存策略,也是每一位前端工程师都应该深刻理解掌握的性能优化知识点,我们下面优先针对 HTTP 缓存机制进行剖析。
# HTTP 缓存机制探秘
HTTP 缓存是我们日常开发中最为熟悉的一种缓存机制。它又分为强缓存和协商缓存。优先级较高的是强缓存,在命中强缓存失败的情况下,才会走协商缓存。
1. 强缓存的特征
强缓存是利用
http头中的Expires和Cache-Control两个字段来控制的。强缓存中,当请求再次发出时,浏览器会根据其中的expires和cache-control判断目标资源是否“命中”强缓存,若命中则直接从缓存中获取资源,不会再与服务端发生通信。
命中强缓存的情况下,返回的 HTTP 状态码为 200 (如下图)。

2. 强缓存的实现:从 expires 到 cache-control
- 实现强缓存,过去我们一直用
expires。 - 当服务器返回响应时,在
Response Headers中将过期时间写入expires字段。像这样:
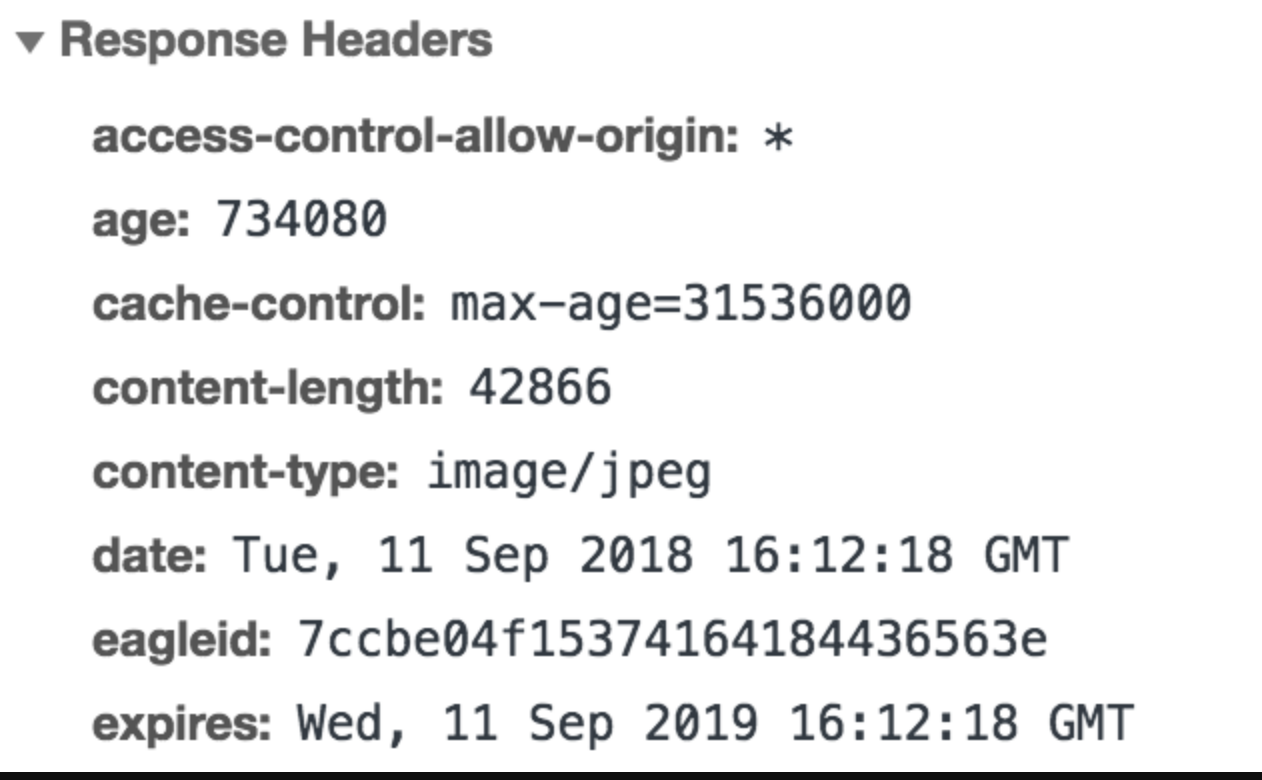
我们给 expires 一个特写:
expires: Wed, 11 Sep 2019 16:12:18 GMT
- 可以看到,
expires是一个时间戳,接下来如果我们试图再次向服务器请求资源,浏览器就会先对比本地时间和expires的时间戳,如果本地时间小于expires设定的过期时间,那么就直接去缓存中取这个资源。 - 从这样的描述中大家也不难猜测,
expires是有问题的,它最大的问题在于对“本地时间”的依赖。如果服务端和客户端的时间设置可能不同,或者我直接手动去把客户端的时间改掉,那么expires将无法达到我们的预期。 - 考虑到
expires的局限性,HTTP1.1新增了Cache-Control字段来完成expires的任务。
expires 能做的事情,Cache-Control 都能做;expires完成不了的事情,Cache-Control也能做。因此,Cache-Control可以视作是expires的完全替代方案。在当下的前端实践里,我们继续使用expires的唯一目的就是向下兼容。
现在我们给
Cache-Control字段一个特写:
cache-control: max-age=31536000
如大家所见,在
Cache-Control中,我们通过max-age来控制资源的有效期。max-age不是一个时间戳,而是一个时间长度。在本例中,max-age是 31536000 秒,它意味着该资源在 31536000 秒以内都是有效的,完美地规避了时间戳带来的潜在问题。
Cache-Control 相对于 expires 更加准确,它的优先级也更高。当 Cache-Control 与 expires 同时出现时,我们以 Cache-Control 为准。
3. Cache-Control 应用分析
Cache-Control的神通,可不止于这一个小小的max-age。如下的用法也非常常见:
cache-control: max-age=3600, s-maxage=31536000
s-maxage 优先级高于 max-age,两者同时出现时,优先考虑 s-maxage。如果 s-maxage 未过期,则向代理服务器请求其缓存内容。
这个
s-maxage不像max-age一样为大家所熟知。的确,在项目不是特别大的场景下,max-age足够用了。但在依赖各种代理的大型架构中,我们不得不考虑代理服务器的缓存问题。s-maxage就是用于表示cache服务器上(比如cache CDN)的缓存的有效时间的,并只对public缓存有效。
- 此处应注意这样一个细节:
s-maxage仅在代理服务器中生效,客户端中我们只考虑max-age - 那么什么是
public缓存呢?说到这里,Cache-Control中有一些适合放在一起理解的知识点,我们集中梳理一下:
3.1 public 与 private
public与private是针对资源是否能够被代理服务缓存而存在的一组对立概念。- 如果我们为资源设置了
public,那么它既可以被浏览器缓存,也可以被代理服务器缓存;如果我们设置了private,则该资源只能被浏览器缓存。private为默认值。但多数情况下,public并不需要我们手动设置,比如有很多线上网站的cache-control是这样的:
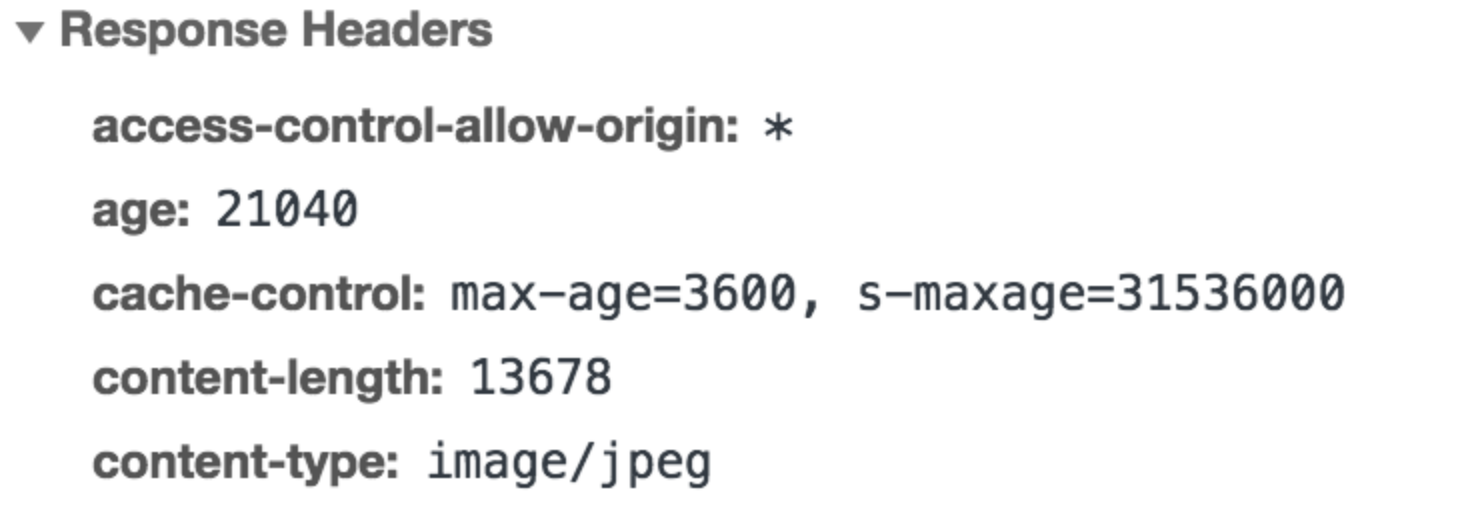
设置了
s-maxage,没设置public,那么CDN还可以缓存这个资源吗?答案是肯定的。因为明确的缓存信息(例如“max-age”)已表示响应是可以缓存的。
3.2 no-store与no-cache
no-cache绕开了浏览器:我们为资源设置了no-cache后,每一次发起请求都不会再去询问浏览器的缓存情况,而是直接向服务端去确认该资源是否过期(即走我们下文即将讲解的协商缓存的路线)。no-store比较绝情,顾名思义就是不使用任何缓存策略。在no-cache的基础上,它连服务端的缓存确认也绕开了,只允许你直接向服务端发送请求、并下载完整的响应。
4. 协商缓存:浏览器与服务器合作之下的缓存策略
- 协商缓存依赖于服务端与浏览器之间的通信。
协商缓存机制下,浏览器需要向服务器去询问缓存的相关信息,进而判断是重新发起请求、下载完整的响应,还是从本地获取缓存的资源。
如果服务端提示缓存资源未改动(Not Modified),资源会被重定向到浏览器缓存,这种情况下网络请求对应的状态码是 304(如下图)。

5. 协商缓存的实现:从 Last-Modified 到 Etag
Last-Modified是一个时间戳,如果我们启用了协商缓存,它会在首次请求时随着Response Headers返回:
Last-Modified: Fri, 27 Oct 2017 06:35:57 GMT
随后我们每次请求时,会带上一个叫
If-Modified-Since的时间戳字段,它的值正是上一次response返回给它的last-modified值:
If-Modified-Since: Fri, 27 Oct 2017 06:35:57 GMT
服务器接收到这个时间戳后,会比对该时间戳和资源在服务器上的最后修改时间是否一致,从而判断资源是否发生了变化。如果发生了变化,就会返回一个完整的响应内容,并在
Response Headers中添加新的Last-Modified值;否则,返回如上图的304响应,Response Headers不会再添加Last-Modified字段。
使用 Last-Modified 存在一些弊端,这其中最常见的就是这样两个场景:
- 我们编辑了文件,但文件的内容没有改变。服务端并不清楚我们是否真正改变了文件,它仍然通过最后编辑时间进行判断。因此这个资源在再次被请求时,会被当做新资源,进而引发一次完整的响应——不该重新请求的时候,也会重新请求。
- 当我们修改文件的速度过快时(比如花了
100ms完成了改动),由于If-Modified-Since只能检查到以秒为最小计量单位的时间差,所以它是感知不到这个改动的——该重新请求的时候,反而没有重新请求了。
这两个场景其实指向了同一个
bug——服务器并没有正确感知文件的变化。为了解决这样的问题,Etag作为Last-Modified的补充出现了。
Etag是由服务器为每个资源生成的唯一的标识字符串,这个标识字符串是基于文件内容编码的,只要文件内容不同,它们对应的Etag就是不同的,反之亦然。因此Etag能够精准地感知文件的变化。Etag和Last-Modified类似,当首次请求时,我们会在响应头里获取到一个最初的标识符字符串,举个🌰,它可以是这样的:
ETag: W/"2a3b-1602480f459"
那么下一次请求时,请求头里就会带上一个值相同的、名为 if-None-Match 的字符串供服务端比对了:
If-None-Match: W/"2a3b-1602480f459"
Etag的生成过程需要服务器额外付出开销,会影响服务端的性能,这是它的弊端。因此启用Etag需要我们审时度势。正如我们刚刚所提到的——Etag并不能替代Last-Modified,它只能作为Last-Modified的补充和强化存在。 Etag 在感知文件变化上比 Last-Modified 更加准确,优先级也更高。当 Etag 和 Last-Modified 同时存在时,以 Etag 为准。
# HTTP 缓存决策指南
行文至此,当代 HTTP 缓存技术用到的知识点,我们已经从头到尾挖掘了一遍了。那么在面对一个具体的缓存需求时,我们到底该怎么决策呢?
走到决策建议这一步,我本来想给大家重新画一个流程图。但是画来画去终究不如 Chrome 官方给出的这张清晰、权威:
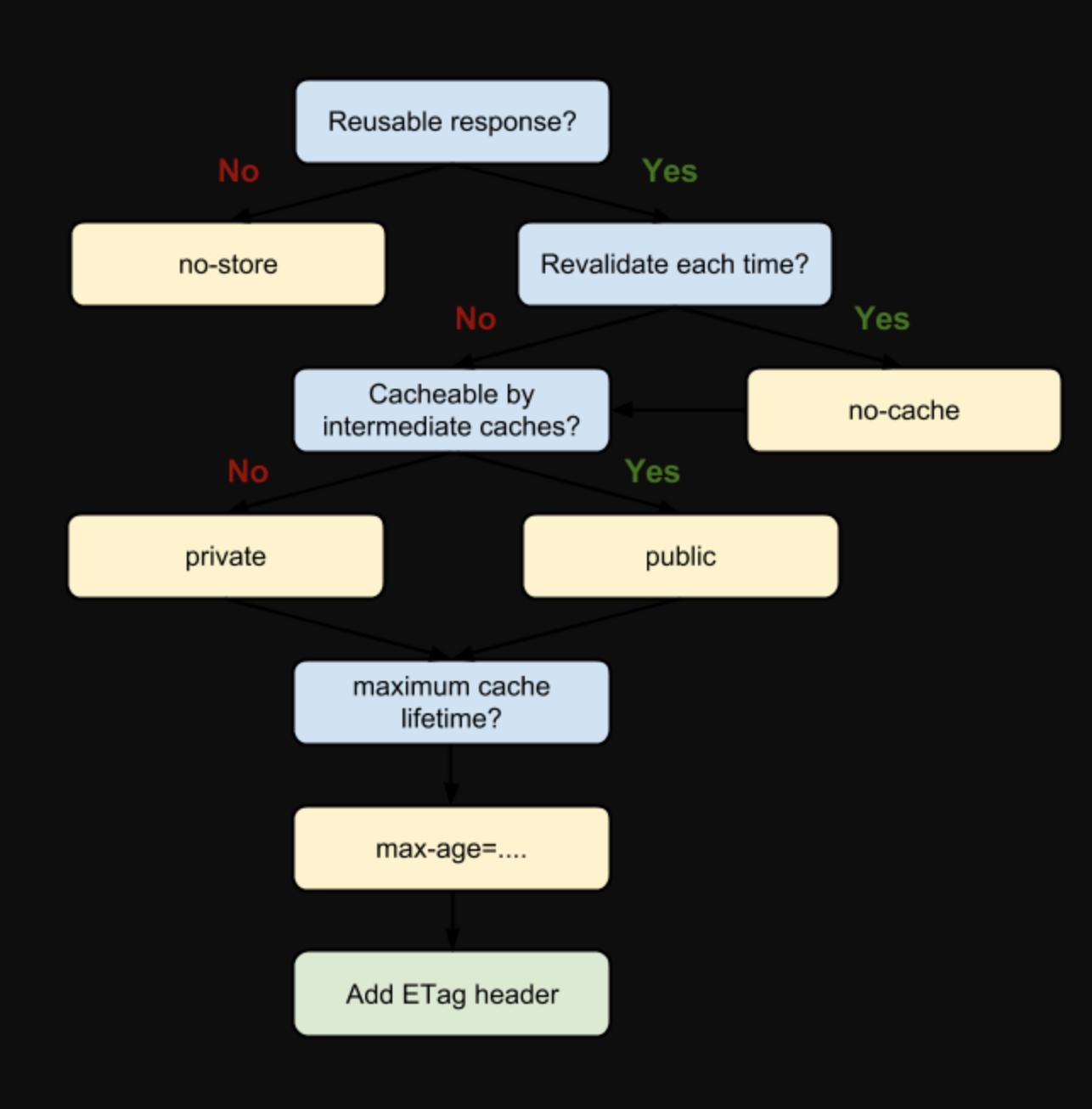
我们现在一起解读一下这张流程图:
- 当我们的资源内容不可复用时,直接为
Cache-Control设置no-store,拒绝一切形式的缓存;否则考虑是否每次都需要向服务器进行缓存有效确认,如果需要,那么设Cache-Control的值为no-cache;否则考虑该资源是否可以被代理服务器缓存,根据其结果决定是设置为private还是public;然后考虑该资源的过期时间,设置对应的max-age和s-maxage值;最后,配置协商缓存需要用到的Etag、Last-Modified等参数。 - 个人非常推崇这张流程图给出的决策建议,也强烈推荐大家在理解以上知识点的基础上,将这张图保存下来、在日常开发中用用看,它的可行度非常高。
OK,走到这里,本节最大的一座山已经被大家翻过去了。接下来的内容会相对比较轻松,大家放松心情,我们继续前行!
# MemoryCache
MemoryCache,是指存在内存中的缓存。从优先级上来说,它是浏览器最先尝试去命中的一种缓存。从效率上来说,它是响应速度最快的一种缓存。- 内存缓存是快的,也是“短命”的。它和渲染进程“生死相依”,当进程结束后,也就是 tab 关闭以后,内存里的数据也将不复存在。
那么哪些文件会被放入内存呢?
- 事实上,这个划分规则,一直以来是没有定论的。不过想想也可以理解,内存是有限的,很多时候需要先考虑即时呈现的内存余量,再根据具体的情况决定分配给内存和磁盘的资源量的比重——资源存放的位置具有一定的随机性。
- 虽然划分规则没有定论,但根据日常开发中观察的结果,包括我们开篇给大家展示的
Network截图,我们至少可以总结出这样的规律:资源存不存内存,浏览器秉承的是“节约原则”。我们发现,Base64格式的图片,几乎永远可以被塞进memory cache,这可以视作浏览器为节省渲染开销的“自保行为”;此外,体积不大的JS、CSS文件,也有较大地被写入内存的几率——相比之下,较大的JS、CSS文件就没有这个待遇了,内存资源是有限的,它们往往被直接甩进磁盘。
# Service Worker Cache
Service Worker是一种独立于主线程之外的 Javascript 线程。它脱离于浏览器窗体,因此无法直接访问 DOM。这样独立的个性使得Service Worker的“个人行为”无法干扰页面的性能,这个“幕后工作者”可以帮我们实现离线缓存、消息推送和网络代理等功能。我们借助Service worker实现的离线缓存就称为Service Worker Cache。
Service Worker的生命周期包括install、active、working三个阶段。一旦Service Worker被install,它将始终存在,只会在active与working之间切换,除非我们主动终止它。这是它可以用来实现离线存储的重要先决条件。- 下面我们就通过实战的方式,一起见识一下
Service Worker如何为我们实现离线缓存(注意看注释): 我们首先在入口文件中插入这样一段 JS 代码,用以判断和引入Service Worker:
window.navigator.serviceWorker.register('/test.js').then(
function () {
console.log('注册成功')
}).catch(err => {
console.error("注册失败")
})
在
test.js中,我们进行缓存的处理。假设我们需要缓存的文件分别是test.html,test.css和test.js:
// Service Worker会监听 install事件,我们在其对应的回调里可以实现初始化的逻辑
self.addEventListener('install', event => {
event.waitUntil(
// 考虑到缓存也需要更新,open内传入的参数为缓存的版本号
caches.open('test-v1').then(cache => {
return cache.addAll([
// 此处传入指定的需缓存的文件名
'/test.html',
'/test.css',
'/test.js'
])
})
)
})
// Service Worker会监听所有的网络请求,网络请求的产生触发的是fetch事件,我们可以在其对应的监听函数中实现对请求的拦截,进而判断是否有对应到该请求的缓存,实现从Service Worker中取到缓存的目的
self.addEventListener('fetch', event => {
event.respondWith(
// 尝试匹配该请求对应的缓存值
caches.match(event.request).then(res => {
// 如果匹配到了,调用Server Worker缓存
if (res) {
return res;
}
// 如果没匹配到,向服务端发起这个资源请求
return fetch(event.request).then(response => {
if (!response || response.status !== 200) {
return response;
}
// 请求成功的话,将请求缓存起来。
caches.open('test-v1').then(function(cache) {
cache.put(event.request, response);
});
return response.clone();
});
})
);
});
PS:大家注意 Server Worker 对协议是有要求的,必须以 https 协议为前提。
# Push Cache
预告:本小节定位为基础科普向,对 Push Cache 有深入挖掘兴趣的同学,强烈推荐拓展阅读 Chrome 工程师 Jake Archibald 的这篇 HTTP/2 push is tougher than I thought (opens new window)。
Push Cache是指HTTP2在server push阶段存在的缓存。这块的知识比较新,应用也还处于萌芽阶段,我找了好几个网站也没找到一个合适的案例来给大家做具体的介绍。但应用范围有限不代表不重要——HTTP2是趋势、是未来。在它还未被推而广之的此时此刻,我仍希望大家能对Push Cache的关键特性有所了解:
Push Cache是缓存的最后一道防线。浏览器只有在Memory Cache、HTTP Cache和Service Worker Cache均未命中的情况下才会去询问Push Cache。Push Cache是一种存在于会话阶段的缓存,当session终止时,缓存也随之释放。- 不同的页面只要共享了同一个
HTTP2连接,那么它们就可以共享同一个Push Cache。
更多的特性和应用,期待大家可以在日后的开发过程中去挖掘和实践。
# 小结
小建议!很多人在学习缓存这块知识的时候可能多少会有这样的感觉:对浏览器缓存,只能描述个大致,却说不上深层原理;好不容易记住了每个字段怎么用,过几天又给忘了。这是因为缓存部分的知识,具有“细碎、迭代快”的特点。对于这样的知识,我们应该尝试先划分出层次和重点,归纳出完整的体系,然后针对每个知识点去各个击破。
- 终于结束了对缓存世界的探索,不知道大家有没有一种意犹未尽的感觉。开篇我们谈过,缓存非常重要,它几乎是我们性能优化的首选方案。
- 但页面的数据存储方案除了缓存,还有本地存储。在下一节中,我们就将围绕本地存储展开探索。
# 五、存储篇 2:本地存储——从 Cookie 到 Web Storage、IndexDB
随着移动网络的发展与演化,我们手机上现在除了有原生 App,还能跑“WebApp”——它即开即用,用完即走。一个优秀的 WebApp 甚至可以拥有和原生 App 媲美的功能和体验。
我认为,WebApp 就是我们前端性能优化的产物,是我们前端工程师对体验不懈追求的结果,是 Web 网页在性能上向 Native 应用的一次“宣战”。
WebApp优异的性能表现,要归功于浏览器存储技术的广泛应用——这其中除了我们上节提到的缓存,本地存储技术也功不可没。
# 故事的开始:从 Cookie 说起
Cookie的本职工作并非本地存储,而是“维持状态”。- 在 Web 开发的早期,人们亟需解决的一个问题就是状态管理的问题:HTTP 协议是一个无状态协议,服务器接收客户端的请求,返回一个响应,故事到此就结束了,服务器并没有记录下关于客户端的任何信息。那么下次请求的时候,如何让服务器知道“我是我”呢?
- 在这样的背景下,Cookie 应运而生。
Cookie说白了就是一个存储在浏览器里的一个小小的文本文件,它附着在HTTP请求上,在浏览器和服务器之间“飞来飞去”。它可以携带用户信息,当服务器检查 Cookie 的时候,便可以获取到客户端的状态。
关于 Cookie 的详细内容,我们可以在 Chrome 的 Application 面板中查看到:
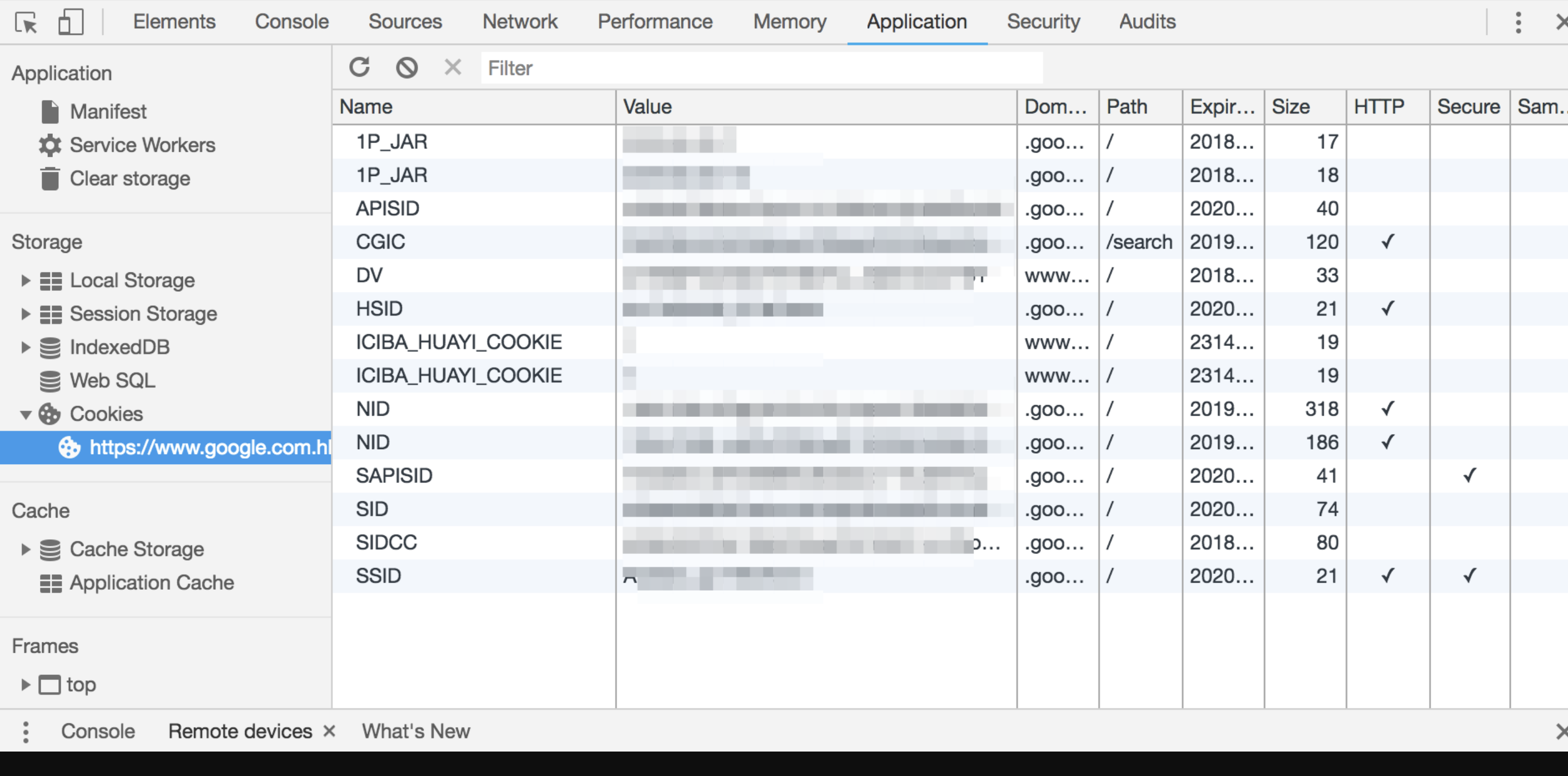
如大家所见,Cookie 以键值对的形式存在。
# Cookie的性能劣势
1. Cookie 不够大
大家知道,
Cookie是有体积上限的,它最大只能有4KB。当Cookie超过4KB时,它将面临被裁切的命运。这样看来,Cookie只能用来存取少量的信息。
2. 过量的 Cookie 会带来巨大的性能浪费
Cookie 是紧跟域名的。我们通过响应头里的 Set-Cookie 指定要存储的 Cookie 值。默认情况下,domain 被设置为设置 Cookie 页面的主机名,我们也可以手动设置 domain 的值:
Set-Cookie: name=xiuyan; domain=xiuyan.me
同一个域名下的所有请求,都会携带 Cookie。大家试想,如果我们此刻仅仅是请求一张图片或者一个 CSS 文件,我们也要携带一个 Cookie 跑来跑去(关键是 Cookie 里存储的信息我现在并不需要),这是一件多么劳民伤财的事情。Cookie 虽然小,请求却可以有很多,随着请求的叠加,这样的不必要的 Cookie 带来的开销将是无法想象的。
随着前端应用复杂度的提高,Cookie 也渐渐演化为了一个“存储多面手”——它不仅仅被用于维持状态,还被塞入了一些乱七八糟的其它信息,被迫承担起了本地存储的“重任”。在没有更好的本地存储解决方案的年代里,Cookie 小小的身体里承载了 4KB 内存所不能承受的压力。
为了弥补 Cookie 的局限性,让“专业的人做专业的事情”,Web Storage 出现了。
# 向前一步:Web Storage
Web Storage是HTML5专门为浏览器存储而提供的数据存储机制。它又分为Local Storage与Session Storage。这两组概念非常相近,我们不妨先理解它们之间的区别,再对它们的共性进行研究。
1. Local Storage 与 Session Storage 的区别
两者的区别在于生命周期与作用域的不同。
- 生命周期:
Local Storage是持久化的本地存储,存储在其中的数据是永远不会过期的,使其消失的唯一办法是手动删除;而Session Storage是临时性的本地存储,它是会话级别的存储,当会话结束(页面被关闭)时,存储内容也随之被释放。 - 作用域:
Local Storage、Session Storage和Cookie都遵循同源策略。但Session Storage特别的一点在于,即便是相同域名下的两个页面,只要它们不在同一个浏览器窗口中打开,那么它们的Session Storage内容便无法共享。
1. Web Storage 的特性
- 存储容量大:
Web Storage根据浏览器的不同,存储容量可以达到5-10M之间。 - 仅位于浏览器端,不与服务端发生通信。
2. Web Storage 核心 API 使用示例
Web Storage保存的数据内容和Cookie一样,是文本内容,以键值对的形式存在。Local Storage与Session Storage在API方面无异,这里我们以localStorage为例:
- 存储数据:
setItem()
localStorage.setItem('user_name', 'xiuyan')
- 读取数据:
getItem()
localStorage.getItem('user_name')
- 删除某一键名对应的数据:
removeItem()
localStorage.removeItem('user_name')
- 清空数据记录:
clear()
localStorage.clear()
# 应用场景
1. Local Storage
Local Storage在存储方面没有什么特别的限制,理论上Cookie无法胜任的、可以用简单的键值对来存取的数据存储任务,都可以交给Local Storage来做。
这里给大家举个例子,考虑到 Local Storage 的特点之一是持久,有时我们更倾向于用它来存储一些内容稳定的资源。比如图片内容丰富的电商网站会用它来存储 Base64 格式的图片字符串:
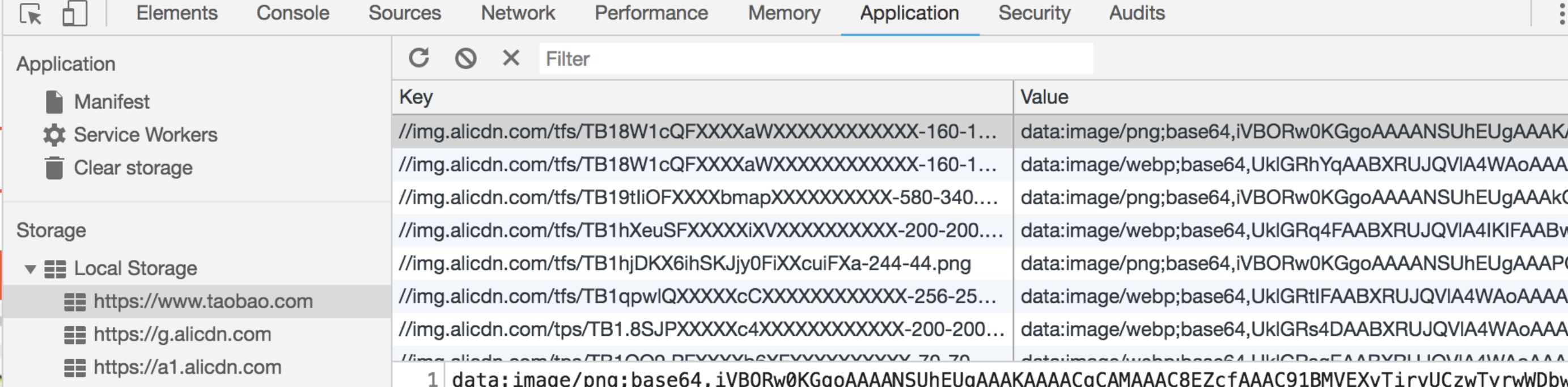
有的网站还会用它存储一些不经常更新的 CSS、JS 等静态资源。
2. Session Storage
Session Storage更适合用来存储生命周期和它同步的会话级别的信息。这些信息只适用于当前会话,当你开启新的会话时,它也需要相应的更新或释放。比如微博的Session Storage就主要是存储你本次会话的浏览足迹:
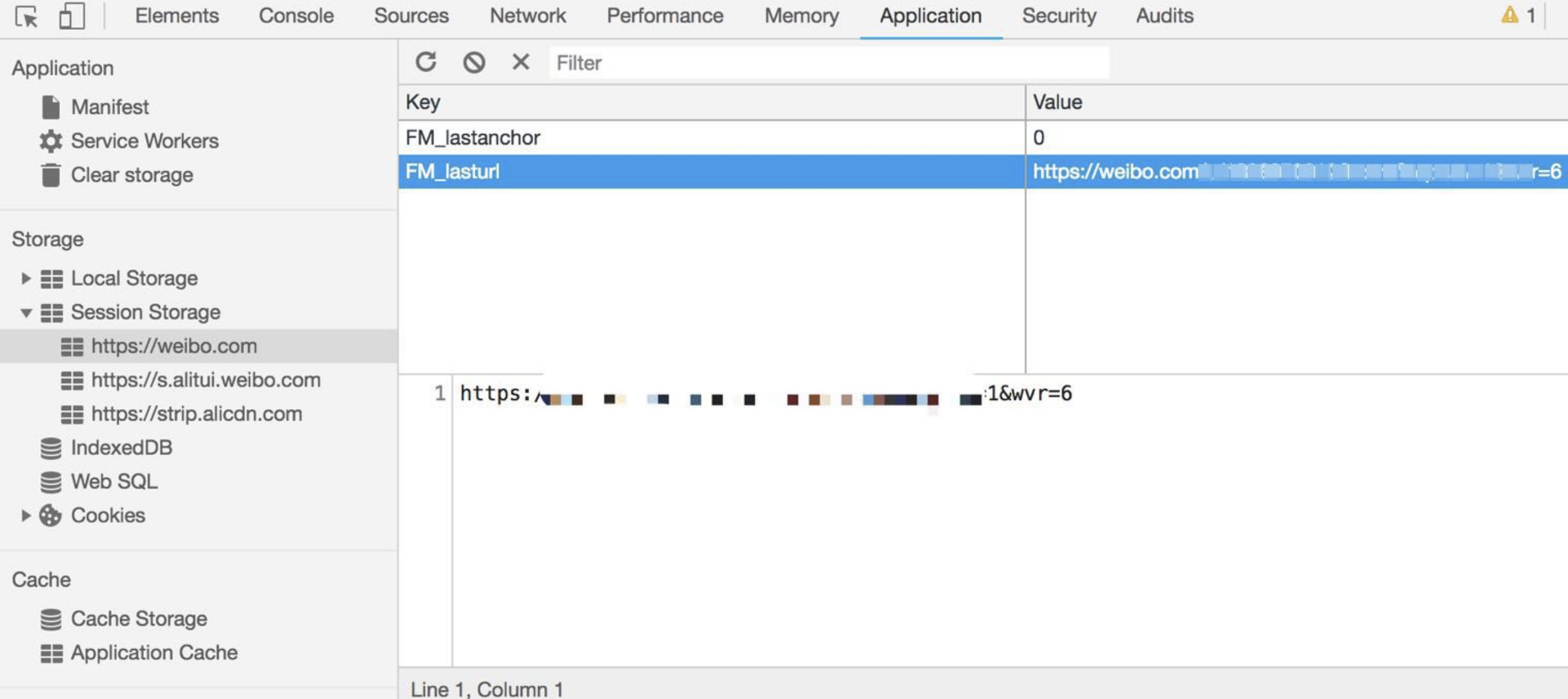
lasturl对应的就是你上一次访问的URL地址,这个地址是即时的。当你切换URL时,它随之更新,当你关闭页面时,留着它也确实没有什么意义了,干脆释放吧。这样的数据用Session Storage来处理再合适不过。- 这样看来,
Web Storage确实也够强大了。那么Web Storage是否能 hold 住所有的存储场景呢?
答案是否定的。大家也看到了,
Web Storage是一个从定义到使用都非常简单的东西。它使用键值对的形式进行存储,这种模式有点类似于对象,却甚至连对象都不是——它只能存储字符串,要想得到对象,我们还需要先对字符串进行一轮解析。
说到底,Web Storage 是对 Cookie 的拓展,它只能用于存储少量的简单数据。当遇到大规模的、结构复杂的数据时,Web Storage 也爱莫能助了。这时候我们就要清楚我们的终极大 boss——IndexDB!
# 终极形态:IndexDB
IndexDB是一个运行在浏览器上的非关系型数据库。既然是数据库了,那就不是5M、10M这样小打小闹级别了。理论上来说,IndexDB是没有存储上限的(一般来说不会小于250M)。它不仅可以存储字符串,还可以存储二进制数据。
IndexDB从推出之日起,其优质教程就层出不绝,我们今天不再着重讲解它的详细操作。接下来,我们遵循 MDN 推荐的操作模式,通过一个基本的 IndexDB 使用流程,旨在对IndexDB形成一个感性的认知:
- 打开/创建一个
IndexDB数据库(当该数据库不存在时,open方法会直接创建一个名为 xiaoceDB 新数据库)。
// 后面的回调中,我们可以通过event.target.result拿到数据库实例
let db
// 参数1位数据库名,参数2为版本号
const request = window.indexedDB.open("xiaoceDB", 1)
// 使用IndexDB失败时的监听函数
request.onerror = function(event) {
console.log('无法使用IndexDB')
}
// 成功
request.onsuccess = function(event){
// 此处就可以获取到db实例
db = event.target.result
console.log("你打开了IndexDB")
}
- 创建一个
object store(object store 对标到数据库中的“表”单位)。
// onupgradeneeded事件会在初始化数据库/版本发生更新时被调用,我们在它的监听函数中创建object store
request.onupgradeneeded = function(event){
let objectStore
// 如果同名表未被创建过,则新建test表
if (!db.objectStoreNames.contains('test')) {
objectStore = db.createObjectStore('test', { keyPath: 'id' })
}
}
- 构建一个事务来执行一些数据库操作,像增加或提取数据等。
// 创建事务,指定表格名称和读写权限
const transaction = db.transaction(["test"],"readwrite")
// 拿到Object Store对象
const objectStore = transaction.objectStore("test")
// 向表格写入数据
objectStore.add({id: 1, name: 'xiuyan'})
- 通过监听正确类型的事件以等待操作完成。
// 操作成功时的监听函数
transaction.oncomplete = function(event) {
console.log("操作成功")
}
// 操作失败时的监听函数
transaction.onerror = function(event) {
console.log("这里有一个Error")
}
IndexDB 的应用场景
通过上面的示例大家可以看出,在
IndexDB中,我们可以创建多个数据库,一个数据库中创建多张表,一张表中存储多条数据——这足以hold住复杂的结构性数据。IndexDB可以看做是LocalStorage的一个升级,当数据的复杂度和规模上升到了LocalStorage无法解决的程度,我们毫无疑问可以请出IndexDB来帮忙。
# 小结
浏览器缓存/存储技术的出现和发展,为我们的前端应用带来了无限的转机。近年来基于缓存/存储技术的第三方库层出不绝,此外还衍生出了 PWA (opens new window) 这样优秀的 Web 应用模型。可以说,现代前端应用,尤其是移动端应用,之所以可以发展到在体验上叫板 Native 的地步,主要就是仰仗缓存/存储立下的汗马功劳。
# 六、CDN 的缓存与回源机制解析
# CDN的缓存与回源机制解析
CDN (Content Delivery Network,即内容分发网络)指的是一组分布在各个地区的服务器。这些服务器存储着数据的副本,因此服务器可以根据哪些服务器与用户距离最近,来满足数据的请求。 CDN 提供快速服务,较少受高流量影响。
# 为什么要用 CDN
浏览器存储的相关知识此刻离我们还不太远,大家趁热回忆一下:缓存、本地存储带来的性能提升,是不是只能在“获取到资源并把它们存起来”这件事情发生之后?也就是说,首次请求资源的时候,这些招数都是救不了我们的。要提升首次请求的响应能力,除了我们 2、3、4 节提到的方案之外,我们还需要借助 CDN 的能力。
# CDN 如何工作
借中国地图一角来给大家举一个简单的🌰:
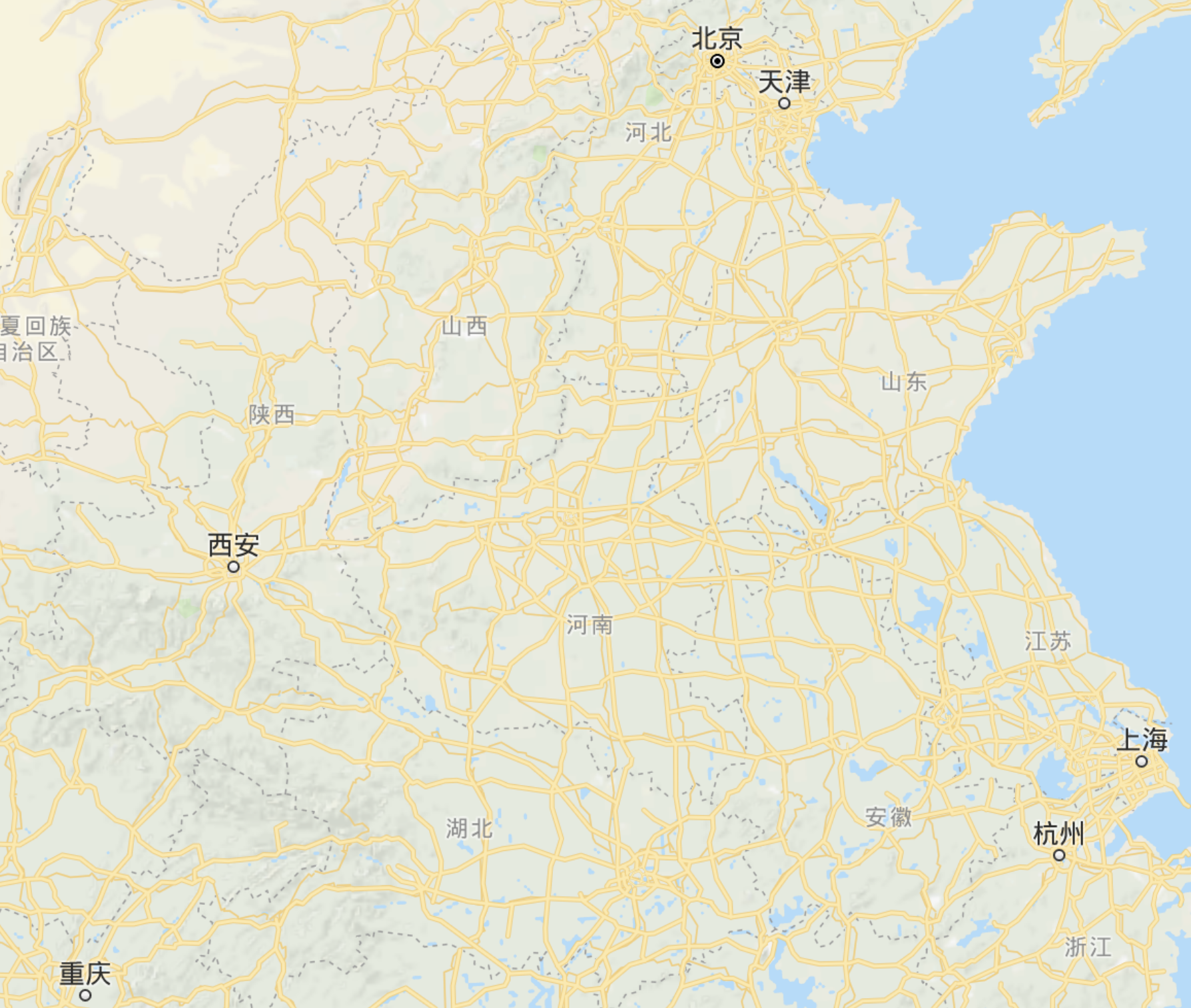
假设我的根服务器在杭州,同时在图示的五个城市里都有自己可用的机房。
此时有一位北京的用户向我请求资源。在网络带宽小、用户访问量大的情况下,杭州的这一台服务器或许不那么给力,不能给用户非常快的响应速度。于是我灵机一动,把这批资源 copy 了一批放在北京的机房里。当用户请求资源时,就近请求北京的服务器,北京这台服务器低头一看,这个资源我存了,离得这么近,响应速度肯定噌噌的!那如果北京这台服务器没有 copy 这批资源呢?它会再向杭州的根服务器去要这个资源。在这个过程中,北京这台服务器就扮演着 CDN 的角色。
# CDN的核心功能特写
CDN 的核心点有两个,一个是缓存,一个是回源。
这两个概念都非常好理解。对标到上面描述的过程,“缓存”就是说我们把资源 copy 一份到 CDN 服务器上这个过程,“回源”就是说 CDN 发现自己没有这个资源(一般是缓存的数据过期了),转头向根服务器(或者它的上层服务器)去要这个资源的过程。
# CDN 与前端性能优化
CDN往往是被前端认为前端不需要了解的东西。- 具体来说,我身边许多同学对其的了解止步于:部署界面上有一个“部署到CDN”按钮,我去点一下,资源就在 CDN 上啦!
“眼下业务开发用不到的可以暂缓了解”,这是没毛病的。但正如我小册开篇所说的,前端工程师首先是软件工程师。对整个技术架构的理解,将会反哺我们对某一具体环节的理解;知识点的适当拓展,也会对大家技术高度和技术广度的提升大有裨益。
那么,我们了解一下 CDN 是怎么帮助前端的。
CDN 往往被用来存放静态资源。上文中我们举例所提到的“根服务器”本质上是业务服务器,它的核心任务在于生成动态页面或返回非纯静态页面,这两种过程都是需要计算的。业务服务器仿佛一个车间,车间里运转的机器轰鸣着为我们产出所需的资源;相比之下,CDN 服务器则像一个仓库,它只充当资源的“栖息地”和“搬运工”。
所谓“静态资源”,就是像 JS、CSS、图片等不需要业务服务器进行计算即得的资源。而“动态资源”,顾名思义是需要后端实时动态生成的资源,较为常见的就是 JSP、ASP 或者依赖服务端渲染得到的 HTML 页面。
什么是“非纯静态资源”呢?它是指需要服务器在页面之外作额外计算的 HTML 页面。具体来说,当我打开某一网站之前,该网站需要通过权限认证等一系列手段确认我的身份、进而决定是否要把 HTML 页面呈现给我。这种情况下 HTML 确实是静态的,但它和业务服务器的操作耦合,我们把它丢到CDN 上显然是不合适的。
# CDN 的实际应用
静态资源本身具有访问频率高、承接流量大的特点,因此静态资源加载速度始终是前端性能的一个非常关键的指标。CDN 是静态资源提速的重要手段,在许多一线的互联网公司,“静态资源走 CDN”并不是一个建议,而是一个规定。
比如以淘宝为代表的阿里系产品,就遵循着这个“规定”。
打开淘宝首页,我们可以在 Network 面板中看到,“非纯静态”的 HTML 页面,是向业务服务器请求来的:
我们点击 preview,可以看到业务服务器确实是返回给了我们一个尚未被静态资源加持过的简单 HTML 页面,所有的图片内容都是先以一个 div 占位:

相应地,我们随便点开一个静态资源,可以看到它都是从 CDN 服务器上请求来的。
比如说图片:

再比如 JS、CSS 文件:


# CDN 优化细节
如何让 CDN 的效用最大化?这又是需要前后端程序员一起思考的庞大命题。它涉及到 CDN 服务器本身的性能优化、CDN 节点的地址选取等。但我们今天不写高深的论文,只谈离前端最近的这部分细节:CDN 的域名选取。
大家先回头看一下我刚刚选取的淘宝首页的例子,我们注意到业务服务器的域名是这个:
www.taobao.com
而 CDN 服务器的域名是这个:
g.alicdn.com
没错,我们不一样!
再看另一方面,我们讲到 Cookie 的时候,为了凸显 Local Storage 的优越性,曾经提到过:
Cookie是紧跟域名的。同一个域名下的所有请求,都会携带Cookie。大家试想,如果我们此刻仅仅是请求一张图片或者一个CSS文件,我们也要携带一个Cookie跑来跑去(关键是Cookie里存储的信息我现在并不需要),这是一件多么劳民伤财的事情。Cookie虽然小,请求却可以有很多,随着请求的叠加,这样的不必要的 Cookie 带来的开销将是无法想象的……
- 同一个域名下的请求会不分青红皂白地携带
Cookie,而静态资源往往并不需要Cookie携带什么认证信息。把静态资源和主页面置于不同的域名下,完美地避免了不必要的Cookie的出现! - 看起来是一个不起眼的小细节,但带来的效用却是惊人的。以电商网站静态资源的流量之庞大,如果没把这个多余的
Cookie拿下来,不仅用户体验会大打折扣,每年因性能浪费带来的经济开销也将是一个非常恐怖的数字。
# 七、渲染篇 1:服务端渲染的探索与实践
服务端渲染(SSR)近两年炒得很火热,相信各位同学对这个名词多少有所耳闻。本节我们将围绕“是什么”(服务端渲染的运行机制)、“为什么”(服务端渲染解决了什么性能问题 )、“怎么做”(服务端渲染的应用实例与使用场景)这三个点,对服务端渲染进行探索。
- 服务端渲染是一个相对的概念,它的对立面是“客户端渲染”。在运行机制解析这部分,我们会借力客户端渲染的概念,来帮大家理解服务端渲染的工作方式。基于对工作方式的了解,再去深挖它的原理与优势。
- 任何知识点都不是“一座孤岛”,服务端渲染的实践往往与当下流行的前端技术(譬如 Vue,React,Redux 等)紧密结合。本节下半场将以 React 和 Vue 下的服务端渲染实现为例,为大家呈现一个完整的 SSR 实现过程。
# 服务端渲染的运行机制
相对于服务端渲染,同学们普遍对客户端渲染接受度更高一些,所以我们先从大家喜闻乐见的客户端渲染说起。
1. 客户端渲染
客户端渲染模式下,服务端会把渲染需要的静态文件发送给客户端,客户端加载过来之后,自己在浏览器里跑一遍 JS,根据 JS 的运行结果,生成相应的 DOM。这种特性使得客户端渲染的源代码总是特别简洁,往往是这个德行:
<!doctype html>
<html>
<head>
<title>我是客户端渲染的页面</title>
</head>
<body>
<div id='root'></div>
<script src='index.js'></script>
</body>
</html>
根节点下到底是什么内容呢?你不知道,我不知道,只有浏览器把 index.js 跑过一遍后才知道,这就是典型的客户端渲染。
页面上呈现的内容,你在 html 源文件里里找不到——这正是它的特点。
2. 服务端渲染
服务端渲染的模式下,当用户第一次请求页面时,由服务器把需要的组件或页面渲染成 HTML 字符串,然后把它返回给客户端。客户端拿到手的,是可以直接渲染然后呈现给用户的 HTML 内容,不需要为了生成 DOM 内容自己再去跑一遍 JS 代码。
使用服务端渲染的网站,可以说是“所见即所得”,页面上呈现的内容,我们在 html 源文件里也能找到。
比如知乎就是典型的服务端渲染案例:
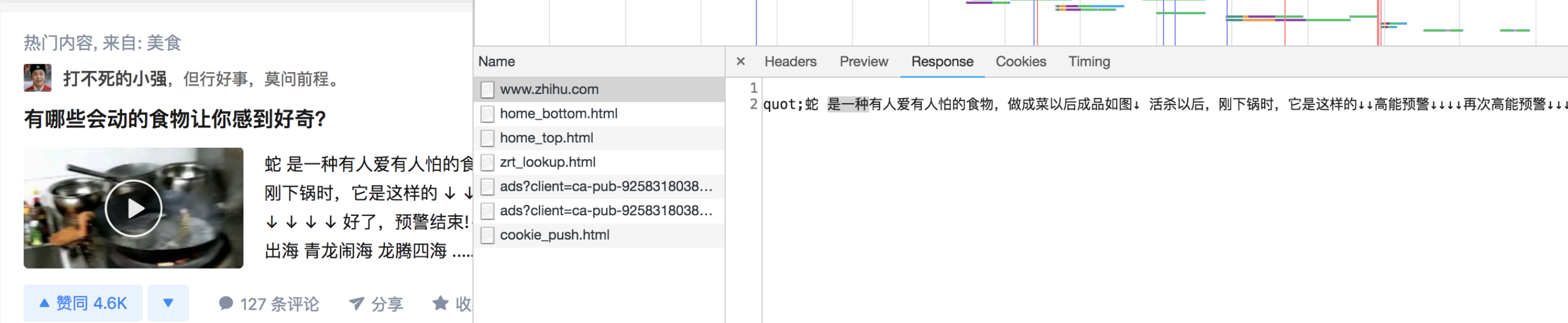
zhihu.com 返回的 HTML 文件已经是可以直接进行渲染的内容了。
# 服务端渲染解决了什么性能问题
- 事实上,很多网站是出于效益的考虑才启用服务端渲染,性能倒是在其次。
- 假设 A 网站页面中有一个关键字叫“前端性能优化”,这个关键字是 JS 代码跑过一遍后添加到 HTML 页面中的。那么客户端渲染模式下,我们在搜索引擎搜索这个关键字,是找不到 A 网站的——搜索引擎只会查找现成的内容,不会帮你跑 JS 代码。A 网站的运营方见此情形,感到很头大:搜索引擎搜不出来,用户找不到我们,谁还会用我的网站呢?为了把“现成的内容”拿给搜索引擎看,A 网站不得不启用服务端渲染。
- 但性能在其次,不代表性能不重要。服务端渲染解决了一个非常关键的性能问题——首屏加载速度过慢。在客户端渲染模式下,我们除了加载 HTML,还要等渲染所需的这部分 JS 加载完,之后还得把这部分 JS 在浏览器上再跑一遍。这一切都是发生在用户点击了我们的链接之后的事情,在这个过程结束之前,用户始终见不到我们网页的庐山真面目,也就是说用户一直在等!相比之下,服务端渲染模式下,服务器给到客户端的已经是一个直接可以拿来呈现给用户的网页,中间环节早在服务端就帮我们做掉了,用户岂不“美滋滋”?
# 服务端渲染的应用实例
下面我们先来看一下在一个 React 项目里,服务端渲染是怎么实现的。本例中,我们使用 Express 搭建后端服务。
项目中有一个叫做 VDom 的 React 组件,它的内容如下。
VDom.js:
import React from 'react'
const VDom = () => {
return <div>我是一个被渲染为真实DOM的虚拟DOM</div>
}
export default VDom
在服务端的入口文件中,我引入这个组件,对它进行渲染:
import express from 'express'
import React from 'react'
import { renderToString } from 'react-dom/server'
import VDom from './VDom'
// 创建一个express应用
const app = express()
// renderToString 是把虚拟DOM转化为真实DOM的关键方法
const RDom = renderToString(<VDom />)
// 编写HTML模板,插入转化后的真实DOM内容
const Page = `
<html>
<head>
<title>test</title>
</head>
<body>
<span>服务端渲染出了真实DOM: </span>
${RDom}
</body>
</html>
`
// 配置HTML内容对应的路由
app.get('/index', function(req, res) {
res.send(Page)
})
// 配置端口号
const server = app.listen(8000)
根据我们的路由配置,当我访问 http://localhost:8000/index (opens new window) 时,就可以呈现出服务端渲染的结果了:
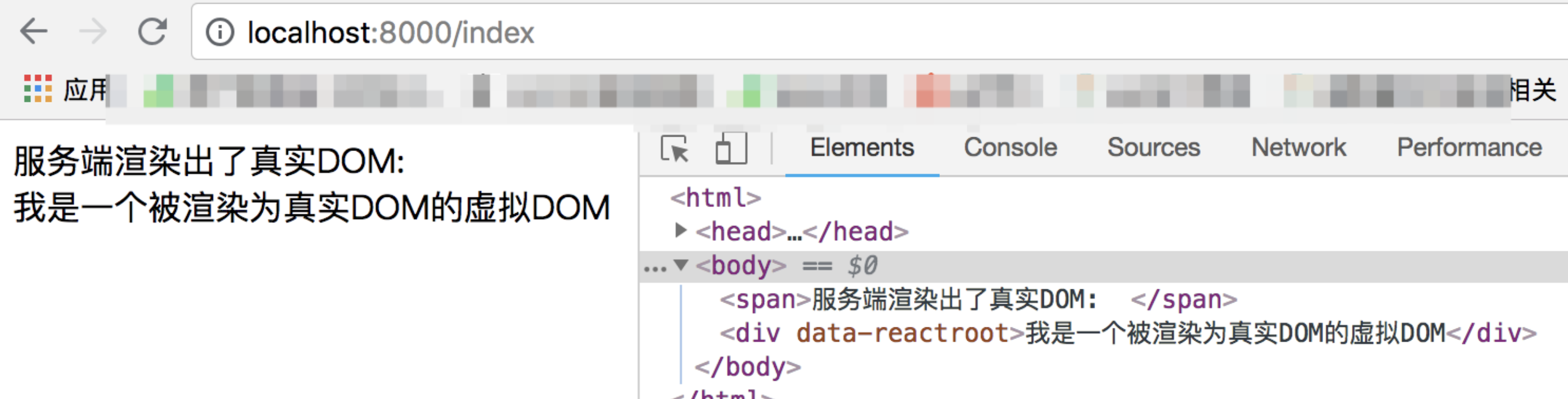
我们可以看到,
VDom组件已经被renderToString转化为了一个内容为<div data-reactroot="">我是一个被渲染为真实DOM的虚拟DOM</div>的字符串,这个字符串被插入 HTML 代码,成为了真实 DOM 树的一部分。
那么 Vue 是如何实现服务端渲染的呢?
其实是一个套路,这里基于 Vue SSR 指南 (opens new window) 中官方给出的例子为大家讲解 Vue 中的实现思路(思路见注释)。
该示例直接将 Vue 实例整合进了服务端的入口文件中:
const Vue = require('vue')
// 创建一个express应用
const server = require('express')()
// 提取出renderer实例
const renderer = require('vue-server-renderer').createRenderer()
server.get('*', (req, res) => {
// 编写Vue实例(虚拟DOM节点)
const app = new Vue({
data: {
url: req.url
},
// 编写模板HTML的内容
template: `<div>访问的 URL 是: {{ url }}</div>`
})
// renderToString 是把Vue实例转化为真实DOM的关键方法
renderer.renderToString(app, (err, html) => {
if (err) {
res.status(500).end('Internal Server Error')
return
}
// 把渲染出来的真实DOM字符串插入HTML模板中
res.end(`
<!DOCTYPE html>
<html lang="en">
<head><title>Hello</title></head>
<body>${html}</body>
</html>
`)
})
})
server.listen(8080)
- 大家对比一下 React 项目中的注释内容,是不是发现这两段代码从本质上来说区别不大呢?
以上两个小🌰,为大家演示了基本的服务端渲染实现流程。
实际项目比这些复杂很多,但万变不离其宗。强调的只有两点:一是这个
renderToString()方法;二是把转化结果“塞”进模板里的这一步。这两个操作是服务端渲染的灵魂操作。在虚拟 DOM“横行”的当下,服务端渲染不再是早年 JSP 里简单粗暴的字符串拼接过程,它还要求这一端要具备将虚拟DOM转化为真实 DOM 的能力。与其说是“把 JS 在服务器上先跑一遍”,不如说是“把Vue、React等框架代码先在Node上跑一遍”。
# 服务端渲染的应用场景
- 打眼一看,这个服务端渲染给浏览器省了这么多事儿,性能肯定是质的飞跃啊!喜闻乐见!但是大家打开自己经常访问的那些网页看一看,会发现仍然有许多网站压根儿不用服务端渲染——看来这个东西也不是万能的。
- 根据我们前面的描述,不难看出,服务端渲染本质上是本该浏览器做的事情,分担给服务器去做。这样当资源抵达浏览器时,它呈现的速度就快了。乍一看好像很合理:浏览器性能毕竟有限,服务器多牛逼!能者多劳,就该让服务器多干点活!
- 但仔细想想,在这个网民遍地的时代,几乎有多少个用户就有多少台浏览器。用户拥有的浏览器总量多到数不清,那么一个公司的服务器又有多少台呢?我们把这么多台浏览器的渲染压力集中起来,分散给相比之下数量并不多的服务器,服务器肯定是承受不住的。
- 这样分析下来,服务端渲染也并非万全之策。在实践中,我一般会建议大家先忘记服务端渲染这个事情——服务器稀少而宝贵,但首屏渲染体验和 SEO 的优化方案却很多——我们最好先把能用的低成本“大招”都用完。除非网页对性能要求太高了,以至于所有的招式都用完了,性能表现还是不尽人意,这时候我们就可以考虑向老板多申请几台服务器,把服务端渲染搞起来了~
# 八、渲染篇 2:知己知彼——解锁浏览器背后的运行机制
平时我们几乎每天都在和浏览器打交道,在一些兼容任务比较繁重的团队里,苦逼的前端攻城师们甚至为了兼容各个浏览器而不断地去测试和调试,还要在脑子中记下各种遇到的 BUG 及解决方案。即便如此,我们好像并没有去主动地关注和了解下浏览器的工作原理。我想如果我们对此做一点了解,在项目过程中就可以有效地避免一些问题,并对页面性能做出相应的改进。
“知己知彼,百战不殆”,今天,我们就一起来揭开浏览器渲染过程的神秘面纱!
# 浏览器的“心”
- 浏览器的“心”,说的就是浏览器的内核。在研究浏览器微观的运行机制之前,我们首先要对浏览器内核有一个宏观的把握。
- 开篇提到许多工程师因为业务需要,免不了需要去处理不同浏览器下代码渲染结果的差异性。这些差异性正是因为浏览器内核的不同而导致的——浏览器内核决定了浏览器解释网页语法的方式。
浏览器内核可以分成两部分:渲染引擎(Layout Engine 或者 Rendering Engine)和 JS 引擎。早期渲染引擎和 JS 引擎并没有十分明确的区分,但随着 JS 引擎越来越独立,内核也成了渲染引擎的代称(下文我们将沿用这种叫法)。渲染引擎又包括了 HTML 解释器、CSS 解释器、布局、网络、存储、图形、音视频、图片解码器等等零部件。

目前市面上常见的浏览器内核可以分为这四种:Trident(IE)、Gecko(火狐)、Blink(Chrome、Opera)、Webkit(Safari)。
这里面大家最耳熟能详的可能就是 Webkit 内核了。很多同学可能会听说过 Chrome 的内核就是 Webkit,殊不知 Chrome 内核早已迭代为了 Blink。但是换汤不换药,Blink 其实也是基于 Webkit 衍生而来的一个分支,因此,Webkit 内核仍然是当下浏览器世界真正的霸主。
下面我们就以 Webkit 为例,对现代浏览器的渲染过程进行一个深度的剖析。
# 开启浏览器渲染“黑盒”
什么是渲染过程?简单来说,渲染引擎根据 HTML 文件描述构建相应的数学模型,调用浏览器各个零部件,从而将网页资源代码转换为图像结果,这个过程就是渲染过程(如下图)。

从这个流程来看,浏览器呈现网页这个过程,宛如一个黑盒。在这个神秘的黑盒中,有许多功能模块,内核内部的实现正是这些功能模块相互配合协同工作进行的。其中我们最需要关注的,就是HTML 解释器、CSS 解释器、图层布局计算模块、视图绘制模块与JavaScript 引擎这几大模块:
HTML 解释器:将 HTML 文档经过词法分析输出 DOM 树。
CSS 解释器:解析 CSS 文档, 生成样式规则。
图层布局计算模块:布局计算每个对象的精确位置和大小。
视图绘制模块:进行具体节点的图像绘制,将像素渲染到屏幕上。
JavaScript 引擎:编译执行 Javascript 代码。
# 浏览器渲染过程解析
有了对零部件的了解打底,我们就可以一起来走一遍浏览器的渲染流程了。在浏览器里,每一个页面的首次渲染都经历了如下阶段(图中箭头不代表串行,有一些操作是并行进行的,下文会说明):
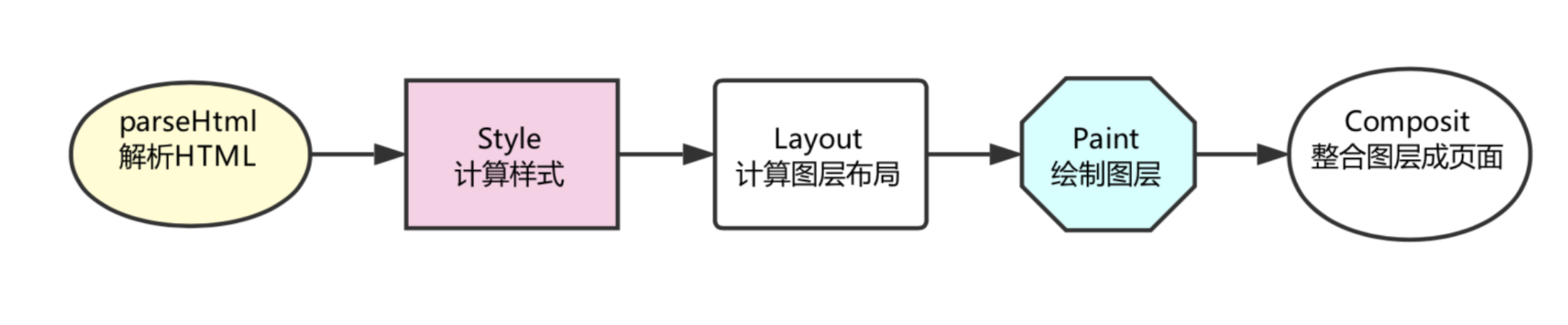
- 解析 HTML
在这一步浏览器执行了所有的加载解析逻辑,在解析 HTML 的过程中发出了页面渲染所需的各种外部资源请求。
- 计算样式
浏览器将识别并加载所有的 CSS 样式信息与 DOM 树合并,最终生成页面 render 树(:after :before 这样的伪元素会在这个环节被构建到 DOM 树中)。
- 计算图层布局
页面中所有元素的相对位置信息,大小等信息均在这一步得到计算。
- 绘制图层
在这一步中浏览器会根据我们的 DOM 代码结果,把每一个页面图层转换为像素,并对所有的媒体文件进行解码。
- 整合图层,得到页面
最后一步浏览器会合并合各个图层,将数据由 CPU 输出给 GPU 最终绘制在屏幕上。(复杂的视图层会给这个阶段的 GPU 计算带来一些压力,在实际应用中为了优化动画性能,我们有时会手动区分不同的图层)。
# 几棵重要的“树”
上面的内容没有理解透彻?别着急,我们一起来捋一捋这个过程中的重点——树!
为了使渲染过程更明晰一些,我们需要给这些”树“们一个特写:
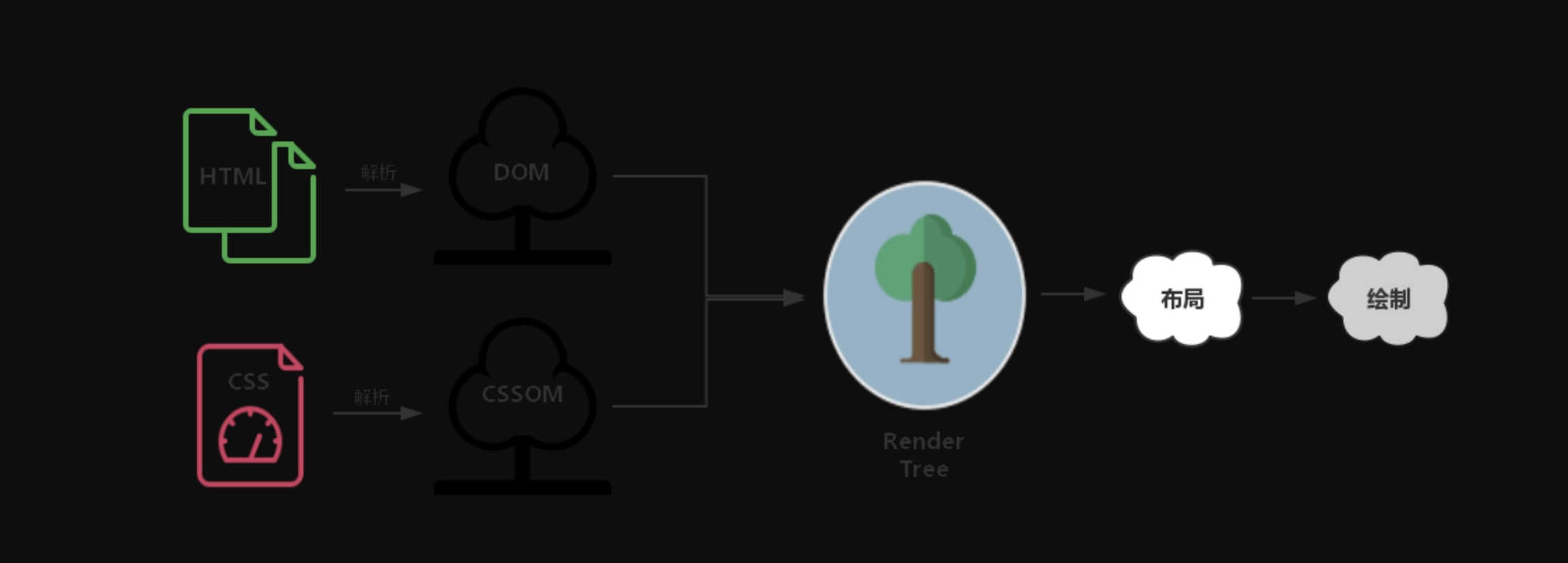
DOM 树:解析 HTML 以创建的是 DOM 树(DOM tree ):渲染引擎开始解析 HTML 文档,转换树中的标签到 DOM 节点,它被称为“内容树”。
CSSOM 树:解析 CSS(包括外部 CSS 文件和样式元素)创建的是 CSSOM 树。CSSOM 的解析过程与 DOM 的解析过程是并行的。
渲染树:CSSOM 与 DOM 结合,之后我们得到的就是渲染树(Render tree )。
布局渲染树:从根节点递归调用,计算每一个元素的大小、位置等,给每个节点所应该出现在屏幕上的精确坐标,我们便得到了基于渲染树的布局渲染树(Layout of the render tree)。
绘制渲染树: 遍历渲染树,每个节点将使用 UI 后端层来绘制。整个过程叫做绘制渲染树(Painting the render tree)。
基于这些“树”,我们再梳理一番:
渲染过程说白了,首先是基于 HTML 构建一个 DOM 树,这棵 DOM 树与 CSS 解释器解析出的 CSSOM 相结合,就有了布局渲染树。最后浏览器以布局渲染树为蓝本,去计算布局并绘制图像,我们页面的初次渲染就大功告成了。
- 之后每当一个新元素加入到这个 DOM 树当中,浏览器便会通过 CSS 引擎查遍 CSS 样式表,找到符合该元素的样式规则应用到这个元素上,然后再重新去绘制它。
- 有心的同学可能已经在思考了,查表是个花时间的活,我怎么让浏览器的查询工作又快又好地实现呢?OK,讲了这么多原理,我们终于引出了我们的第一个可转化为代码的优化点——CSS 样式表规则的优化!
# 不做无用功:基于渲染流程的 CSS 优化建议
在给出 CSS 选择器方面的优化建议之前,先告诉大家一个小知识:CSS 引擎查找样式表,对每条规则都按从右到左的顺序去匹配。 看如下规则:
#myList li {}
这样的写法其实很常见。大家平时习惯了从左到右阅读的文字阅读方式,会本能地以为浏览器也是从左到右匹配 CSS 选择器的,因此会推测这个选择器并不会费多少力气:#myList 是一个 id 选择器,它对应的元素只有一个,查找起来应该很快。定位到了 myList 元素,等于是缩小了范围后再去查找它后代中的 li 元素,没毛病。
事实上,CSS 选择符是从右到左进行匹配的。我们这个看似“没毛病”的选择器,实际开销相当高:浏览器必须遍历页面上每个 li 元素,并且每次都要去确认这个 li 元素的父元素 id 是不是 myList,你说坑不坑!
说到坑,不知道大家还记不记得这个经典的通配符:
* {}
- 入门 CSS 的时候,不少同学拿通配符清除默认样式(我曾经也是通配符用户的一员)。但这个家伙很恐怖,它会匹配所有元素,所以浏览器必须去遍历每一个元素!大家低头看看自己页面里的元素个数,是不是心凉了——这得计算多少次呀!
- 这样一看,一个小小的 CSS 选择器,也有不少的门道!好的 CSS 选择器书写习惯,可以为我们带来非常可观的性能提升。根据上面的分析,我们至少可以总结出如下性能提升的方案:
避免使用通配符,只对需要用到的元素进行选择。
关注可以通过继承实现的属性,避免重复匹配重复定义。
少用标签选择器。如果可以,用类选择器替代,举个🌰:
错误示范:
#myList li{}
课代表:
.myList_li {}
- 不要画蛇添足,id 和 class 选择器不应该被多余的标签选择器拖后腿。举个🌰:
错误示范
.myList#title
课代表
#title
减少嵌套。后代选择器的开销是最高的,因此我们应该尽量将选择器的深度降到最低(最高不要超过三层),尽可能使用类来关联每一个标签元素。
搞定了 CSS 选择器,万里长征才刚刚开始的第一步。但现在你已经理解了浏览器的工作过程,接下来的征程对你来说并不再是什么难题~
# 告别阻塞:CSS 与 JS 的加载顺序优化
说完了过程,我们来说一说特性。
HTML、CSS 和 JS,都具有阻塞渲染的特性。
HTML 阻塞,天经地义——没有 HTML,何来 DOM?没有 DOM,渲染和优化,都是空谈。
那么 CSS 和 JS 的阻塞又是怎么回事呢?
1. CSS 的阻塞
- 在刚刚的过程中,我们提到 DOM 和 CSSOM 合力才能构建渲染树。这一点会给性能造成严重影响:默认情况下,CSS 是阻塞的资源。浏览器在构建 CSSOM 的过程中,不会渲染任何已处理的内容。即便 DOM 已经解析完毕了,只要 CSSOM 不 OK,那么渲染这个事情就不 OK(这主要是为了避免没有 CSS 的 HTML 页面丑陋地“裸奔”在用户眼前)。
- 我们知道,只有当我们开始解析 HTML 后、解析到 link 标签或者 style 标签时,CSS 才登场,CSSOM 的构建才开始。很多时候,DOM 不得不等待 CSSOM。因此我们可以这样总结:
CSS 是阻塞渲染的资源。需要将它尽早、尽快地下载到客户端,以便缩短首次渲染的时间。
事实上,现在很多团队都已经做到了尽早(将 CSS 放在 head 标签里)和尽快(启用 CDN 实现静态资源加载速度的优化)。这个“把 CSS 往前放”的动作,对很多同学来说已经内化为一种编码习惯。那么现在我们还应该知道,这个“习惯”不是空穴来风,它是由 CSS 的特性决定的。
2. JS 的阻塞
- 不知道大家注意到没有,前面我们说过程的时候,花了很多笔墨去说 HTML、说 CSS。相比之下,JS 的出镜率也太低了点。
这当然不是因为 JS 不重要。而是因为,在首次渲染过程中,JS 并不是一个非登场不可的角色——没有 JS,CSSOM 和 DOM 照样可以组成渲染树,页面依然会呈现——即使它死气沉沉、毫无交互。 - JS 的作用在于修改,它帮助我们修改网页的方方面面:内容、样式以及它如何响应用户交互。这“方方面面”的修改,本质上都是对 DOM 和 CSSDOM 进行修改。因此 JS 的执行会阻止 CSSOM,在我们不作显式声明的情况下,它也会阻塞 DOM。
我们通过一个🌰来理解一下这个机制:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>JS阻塞测试</title>
<style>
#container {
background-color: yellow;
width: 100px;
height: 100px;
}
</style>
<script>
// 尝试获取container元素
var container = document.getElementById("container")
console.log('container', container)
</script>
</head>
<body>
<div id="container"></div>
<script>
// 尝试获取container元素
var container = document.getElementById("container")
console.log('container', container)
// 输出container元素此刻的背景色
console.log('container bgColor', getComputedStyle(container).backgroundColor)
</script>
<style>
#container {
background-color: blue;
}
</style>
</body>
</html>
三个 console 的结果分别为:
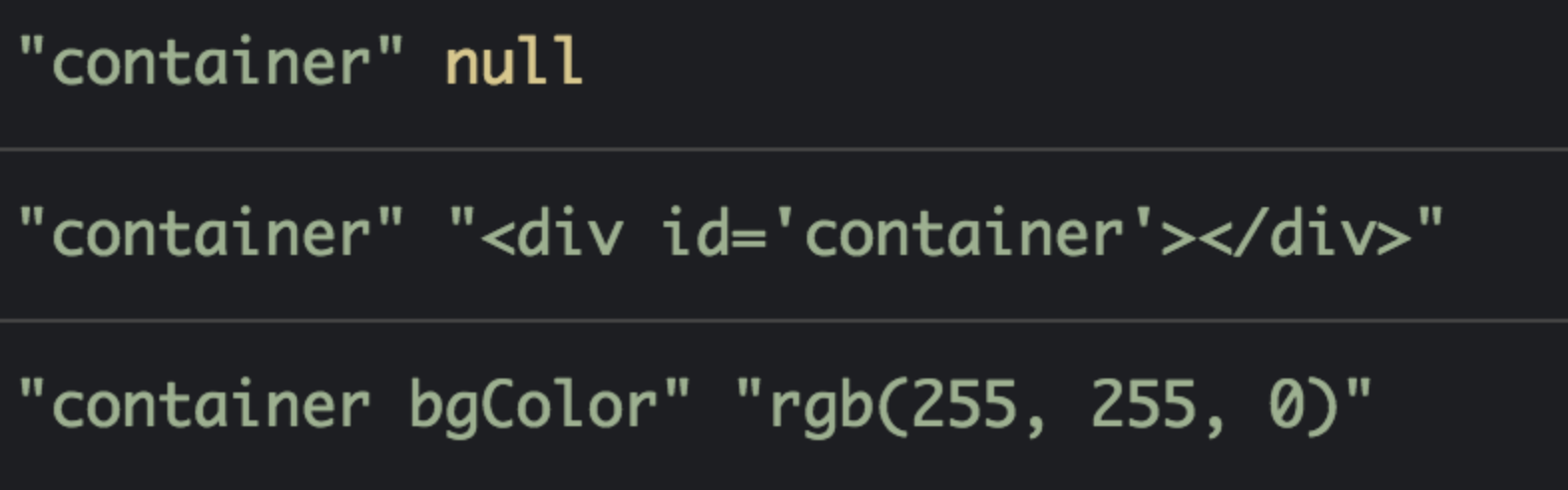
- 注:本例仅使用了内联 JS 做测试。感兴趣的同学可以把这部分 JS 当做外部文件引入看看效果——它们的表现一致。
- 第一次尝试获取 id 为 container 的 DOM 失败,这说明 JS 执行时阻塞了 DOM,后续的 DOM 无法构建;第二次才成功,这说明脚本块只能找到在它前面构建好的元素。这两者结合起来,“阻塞 DOM”得到了验证。再看第三个 console,尝试获取 CSS 样式,获取到的是在 JS 代码执行前的背景色(yellow),而非后续设定的新样式(blue),说明 CSSOM 也被阻塞了。那么在阻塞的背后,到底发生了什么呢?
- 我们前面说过,JS 引擎是独立于渲染引擎存在的。我们的 JS 代码在文档的何处插入,就在何处执行。当 HTML 解析器遇到一个 script 标签时,它会暂停渲染过程,将控制权交给 JS 引擎。JS 引擎对内联的 JS 代码会直接执行,对外部 JS 文件还要先获取到脚本、再进行执行。等 JS 引擎运行完毕,浏览器又会把控制权还给渲染引擎,继续 CSSOM 和 DOM 的构建。 因此与其说是 JS 把 CSS 和 HTML 阻塞了,不如说是 JS 引擎抢走了渲染引擎的控制权。
- 现在理解了阻塞的表现与原理,我们开始思考一个问题。浏览器之所以让 JS 阻塞其它的活动,是因为它不知道 JS 会做什么改变,担心如果不阻止后续的操作,会造成混乱。但是我们是写 JS 的人,我们知道 JS 会做什么改变。假如我们可以确认一个 JS 文件的执行时机并不一定非要是此时此刻,我们就可以通过对它使用 defer 和 async 来避免不必要的阻塞,这里我们就引出了外部 JS 的三种加载方式。
3. JS的三种加载方式
- 正常模式:
<script src="index.js"></script>
这种情况下 JS 会阻塞浏览器,浏览器必须等待
index.js加载和执行完毕才能去做其它事情。
- async 模式:
<script async src="index.js"></script>
async模式下,JS 不会阻塞浏览器做任何其它的事情。它的加载是异步的,当它加载结束,JS 脚本会立即执行。
- defer 模式:
<script defer src="index.js"></script>
defer模式下,JS 的加载是异步的,执行是被推迟的。等整个文档解析完成、DOMContentLoaded事件即将被触发时,被标记了defer的 JS 文件才会开始依次执行。
- 从应用的角度来说,一般当我们的脚本与 DOM 元素和其它脚本之间的依赖关系不强时,我们会选用
async;当脚本依赖于 DOM 元素和其它脚本的执行结果时,我们会选用defer。 - 通过审时度势地向
script标签添加async/defer,我们就可以告诉浏览器在等待脚本可用期间不阻止其它的工作,这样可以显著提升性能。
# 小结
- 我们知道,当
JS登场时,往往意味着对DOM的操作。DOM 操作所导致的性能开销的“昂贵”,大家可能早就有所耳闻,雅虎军规里很重要的一条就是“尽量减少 DOM 访问”。 - 那么 DOM 到底为什么慢,我们如何去规避这种慢呢?这里我们就引出了下一个章节需要重点解释的两个概念:CSS 中的回流(Reflow)与重绘(Repaint)。
# 九、渲染篇 3:对症下药——DOM 优化原理与基本实践
从本节开始,我们要关心的两大核心问题就是:“DOM 为什么这么慢”以及“如何使 DOM 变快”。
后者是一个比“生存还是毁灭”更加经典的问题。不仅我们为它“肝肠寸断”,许多优秀前端框架的作者大大们也曾为其绞尽脑汁。这一点可喜可贺——研究的人越多,产出优秀实践的概率就越大。因此在本章的方法论环节,我们不仅会根据 DOM 特性及渲染原理为大家讲解基本的优化思路,还会涉及到一部分生产实践。
循着这个思路,我们把 DOM 优化这块划分为三个小专题:“DOM 优化思路”、“异步更新策略”及“回流与重绘”。本节对应第一个小专题。三个小专题休戚与共、你侬我侬,在思路上相互依赖、一脉相承,因此此处严格禁止任何姿势的跳读行为。
考虑到本节内容与上一节有着密不可分的关系,因此强烈不建议没有读完上一节的同学直接跳读本节。
# 望闻问切:DOM 为什么这么慢
1. 因为收了“过路费”
把 DOM 和 JavaScript 各自想象成一个岛屿,它们之间用收费桥梁连接。——《高性能 JavaScript》
JS 是很快的,在 JS 中修改 DOM 对象也是很快的。在JS的世界里,一切是简单的、迅速的。但 DOM 操作并非 JS 一个人的独舞,而是两个模块之间的协作。
上一节我们提到,JS 引擎和渲染引擎(浏览器内核)是独立实现的。当我们用 JS 去操作 DOM 时,本质上是 JS 引擎和渲染引擎之间进行了“跨界交流”。这个“跨界交流”的实现并不简单,它依赖了桥接接口作为“桥梁”(如下图)。

过“桥”要收费——这个开销本身就是不可忽略的。我们每操作一次 DOM(不管是为了修改还是仅仅为了访问其值),都要过一次“桥”。过“桥”的次数一多,就会产生比较明显的性能问题。因此“减少 DOM 操作”的建议,并非空穴来风。
2. 对 DOM 的修改引发样式的更迭
- 过桥很慢,到了桥对岸,我们的更改操作带来的结果也很慢。
- 很多时候,我们对 DOM 的操作都不会局限于访问,而是为了修改它。当我们对 DOM 的修改会引发它外观(样式)上的改变时,就会触发回流或重绘。
- 这个过程本质上还是因为我们对 DOM 的修改触发了渲染树(Render Tree)的变化所导致的:
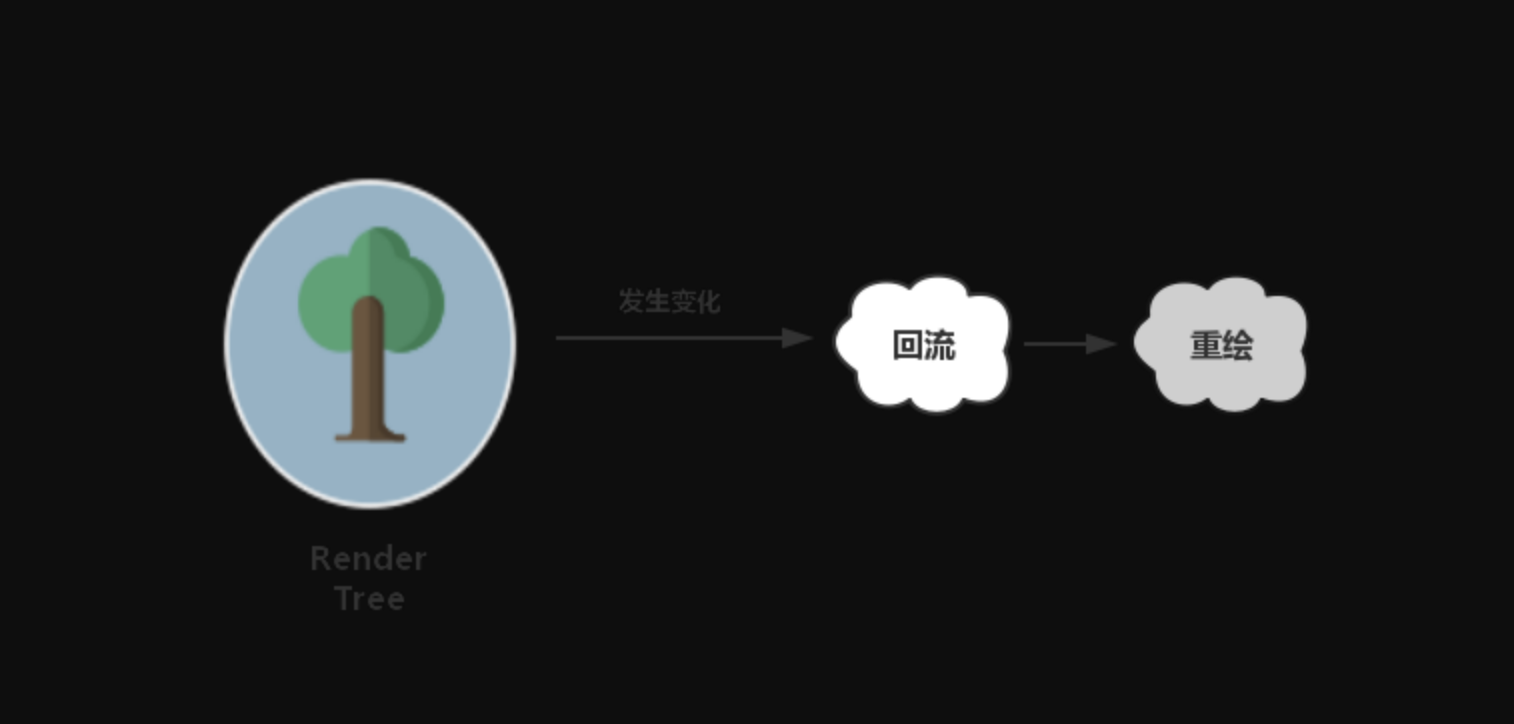
回流:当我们对 DOM 的修改引发了 DOM 几何尺寸的变化(比如修改元素的宽、高或隐藏元素等)时,浏览器需要重新计算元素的几何属性(其他元素的几何属性和位置也会因此受到影响),然后再将计算的结果绘制出来。这个过程就是回流(也叫重排)。
重绘:当我们对 DOM 的修改导致了样式的变化、却并未影响其几何属性(比如修改了颜色或背景色)时,浏览器不需重新计算元素的几何属性、直接为该元素绘制新的样式(跳过了上图所示的回流环节)。这个过程叫做重绘。
由此我们可以看出,重绘不一定导致回流,回流一定会导致重绘。硬要比较的话,回流比重绘做的事情更多,带来的开销也更大。但这两个说到底都是吃性能的,所以都不是什么善茬。我们在开发中,要从代码层面出发,尽可能把回流和重绘的次数最小化。
# 药到病除:给你的 DOM “提提速”
知道了 DOM 慢的原因,我们就可以对症下药了。
1. 减少 DOM 操作:少交“过路费”、避免过度渲染
我们来看这样一个🌰,HTML 内容如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>DOM操作测试</title>
</head>
<body>
<div id="container"></div>
</body>
</html>
此时我有一个假需求——我想往
container元素里写10000句一样的话。如果我这么做:
for(var count=0;count<10000;count++){
document.getElementById('container').innerHTML+='<span>我是一个小测试</span>'
}
这段代码有两个明显的可优化点。
第一点,过路费交太多了。我们每一次循环都调用 DOM 接口重新获取了一次 container 元素,相当于每次循环都交了一次过路费。前后交了 10000 次过路费,但其中 9999 次过路费都可以用缓存变量的方式节省下来:
// 只获取一次container
let container = document.getElementById('container')
for(let count=0;count<10000;count++){
container.innerHTML += '<span>我是一个小测试</span>'
}
第二点,不必要的 DOM 更改太多了。我们的 10000 次循环里,修改了 10000 次 DOM 树。我们前面说过,对 DOM 的修改会引发渲染树的改变、进而去走一个(可能的)回流或重绘的过程,而这个过程的开销是很“贵”的。这么贵的操作,我们竟然重复执行了 N 多次!其实我们可以通过就事论事的方式节省下来不必要的渲染:
let container = document.getElementById('container')
let content = ''
for(let count=0;count<10000;count++){
// 先对内容进行操作
content += '<span>我是一个小测试</span>'
}
// 内容处理好了,最后再触发DOM的更改
container.innerHTML = content
所谓“就事论事”,就像大家所看到的:JS 层面的事情,JS 自己去处理,处理好了,再来找 DOM 打报告。
事实上,考虑JS 的运行速度,比 DOM 快得多这个特性。我们减少 DOM 操作的核心思路,就是让 JS 去给 DOM 分压。
这个思路,在 DOM Fragment (opens new window) 中体现得淋漓尽致。
DocumentFragment接口表示一个没有父级文件的最小文档对象。它被当做一个轻量版的Document使用,用于存储已排好版的或尚未打理好格式的XML片段。因为DocumentFragment不是真实 DOM 树的一部分,它的变化不会引起 DOM 树的重新渲染的操作(reflow),且不会导致性能等问题。
- 在我们上面的例子里,字符串变量
content就扮演着一个DOM Fragment的角色。其实无论字符串变量也好,DOM Fragment也罢,它们本质上都作为脱离了真实 DOM 树的容器出现,用于缓存批量化的 DOM 操作。 - 前面我们直接用
innerHTML去拼接目标内容,这样做固然有用,但却不够优雅。相比之下,DOM Fragment可以帮助我们用更加结构化的方式去达成同样的目的,从而在维持性能的同时,保住我们代码的可拓展和可维护性。我们现在用DOM Fragment来改写上面的例子:
let container = document.getElementById('container')
// 创建一个DOM Fragment对象作为容器
let content = document.createDocumentFragment()
for(let count=0;count<10000;count++){
// span此时可以通过DOM API去创建
let oSpan = document.createElement("span")
oSpan.innerHTML = '我是一个小测试'
// 像操作真实DOM一样操作DOM Fragment对象
content.appendChild(oSpan)
}
// 内容处理好了,最后再触发真实DOM的更改
container.appendChild(content)
- 我们运行这段代码,可以得到与前面两种写法相同的运行结果。
- 可以看出,DOM Fragment 对象允许我们像操作真实 DOM 一样去调用各种各样的 DOM API,我们的代码质量因此得到了保证。并且它的身份也非常纯粹:当我们试图将其 append 进真实 DOM 时,它会在乖乖交出自身缓存的所有后代节点后全身而退,完美地完成一个容器的使命,而不会出现在真实的 DOM 结构中。这种结构化、干净利落的特性,使得 DOM Fragment 作为经典的性能优化手段大受欢迎,这一点在 jQuery、Vue 等优秀前端框架的源码中均有体现。
- 相比 DOM 命题的博大精深,一个简单的循环 Demo 显然不能说明所有问题。不过不用着急,在本节,我只希望大家能牢记原理与宏观思路。“药到病除”到这里才刚刚开了个头,下个小节,我们将深挖事件循环机制,从而深入 JS 层面的生产实践。
# 十、渲染篇 4:千方百计——Event Loop 与异步更新策略
Vue 和 React 都实现了异步更新策略。虽然实现的方式不尽相同,但都达到了减少 DOM 操作、避免过度渲染的目的。通过研究框架的运行机制,其设计思路将深化我们对 DOM 优化的理解,其实现手法将拓宽我们对 DOM 实践的认知。
本节我们将基于 Event Loop 机制,对 Vue 的异步更新策略作探讨。
# 前置知识:Event Loop 中的“渲染时机”
搞懂 Event Loop,是理解 Vue 对 DOM 操作优化的第一步。
# Micro-Task 与 Macro-Task
- 事件循环中的异步队列有两种:
macro(宏任务)队列和micro(微任务)队列。 - 常见的
macro-task比如:setTimeout、setInterval、setImmediate、script(整体代码)、I/O操作、UI渲染等。 - 常见的
micro-task比如:process.nextTick、Promise、MutationObserver等。
# Event Loop 过程解析
基于对 micro 和 macro 的认知,我们来走一遍完整的事件循环过程。
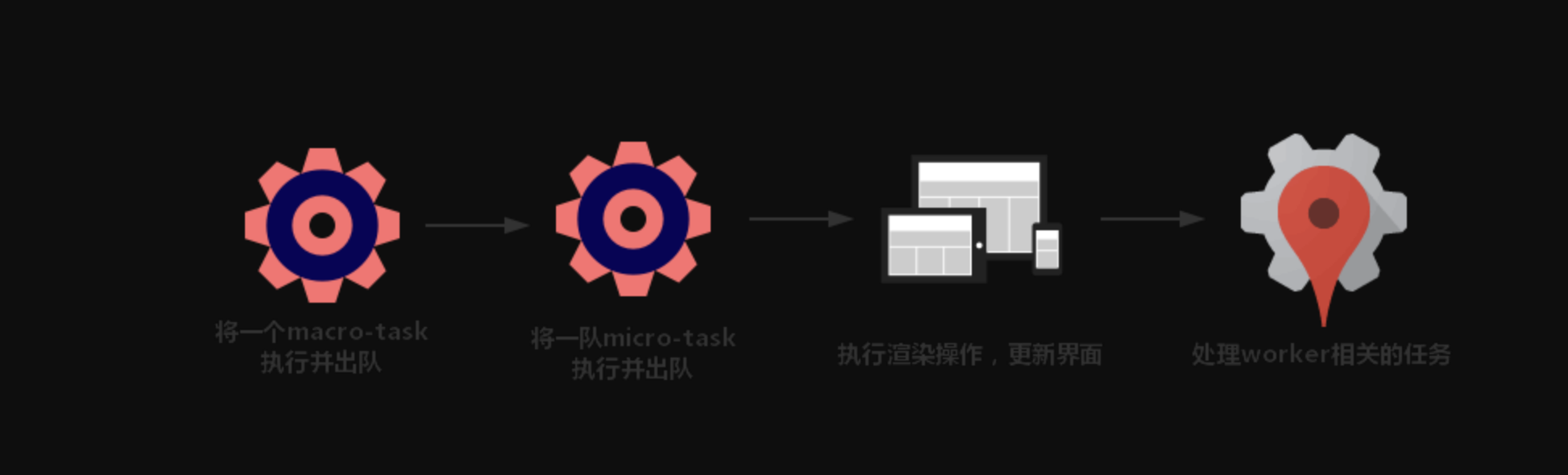
一个完整的 Event Loop 过程,可以概括为以下阶段:
- 初始状态:调用栈空。
micro队列空,macro队列里有且只有一个script脚本(整体代码)。 - 全局上下文(
script标签)被推入调用栈,同步代码执行。在执行的过程中,通过对一些接口的调用,可以产生新的macro-task与micro-task,它们会分别被推入各自的任务队列里。同步代码执行完了,script脚本会被移出macro队列,这个过程本质上是队列的 macro-task 的执行和出队的过程。 - 上一步我们出队的是一个
macro-task,这一步我们处理的是micro-task。但需要注意的是:当macro-task出队时,任务是一个一个执行的;而micro-task出队时,任务是一队一队执行的(如下图所示)。因此,我们处理micro队列这一步,会逐个执行队列中的任务并把它出队,直到队列被清空。

- 执行渲染操作,更新界面(敲黑板划重点)。
- 检查是否存在
Web worker任务,如果有,则对其进行处理 。 - 上述过程循环往复,直到两个队列都清空
我们总结一下,每一次循环都是一个这样的过程:
# 渲染的时机
- 大家现在思考一个这样的问题:假如我想要在异步任务里进行DOM更新,我该把它包装成 micro 还是 macro 呢?
- 我们先假设它是一个 macro 任务,比如我在 script 脚本中用 setTimeout 来处理它:
// task是一个用于修改DOM的回调
setTimeout(task, 0)
- 现在
task被推入的macro队列。但因为script脚本本身是一个macro任务,所以本次执行完script脚本之后,下一个步骤就要去处理micro队列了,再往下就去执行了一次render,对不对? - 但本次render我的目标task其实并没有执行,想要修改的DOM也没有修改,因此这一次的
render其实是一次无效的render。
macro不 ok,我们转向micro试试看。我用Promise来把task包装成是一个micro任务:
Promise.resolve().then(task)
那么我们结束了对 script 脚本的执行,是不是紧接着就去处理 micro-task 队列了?micro-task 处理完,DOM 修改好了,紧接着就可以走 render 流程了——不需要再消耗多余的一次渲染,不需要再等待一轮事件循环,直接为用户呈现最即时的更新结果。
因此,我们更新 DOM 的时间点,应该尽可能靠近渲染的时机。当我们需要在异步任务中实现 DOM 修改时,把它包装成 micro 任务是相对明智的选择。
# 生产实践:异步更新策略——以 Vue 为例
什么是异步更新?
当我们使用 Vue 或 React 提供的接口去更新数据时,这个更新并不会立即生效,而是会被推入到一个队列里。待到适当的时机,队列中的更新任务会被批量触发。这就是异步更新。
异步更新可以帮助我们避免过度渲染,是我们上节提到的“让 JS 为 DOM 分压”的典范之一。
1. 异步更新的优越性
- 异步更新的特性在于它只看结果,因此渲染引擎不需要为过程买单。
- 最典型的例子,比如有时我们会遇到这样的情况:
// 任务一
this.content = '第一次测试'
// 任务二
this.content = '第二次测试'
// 任务三
this.content = '第三次测试'
我们在三个更新任务中对同一个状态修改了三次,如果我们采取传统的同步更新策略,那么就要操作三次 DOM。但本质上需要呈现给用户的目标内容其实只是第三次的结果,也就是说只有第三次的操作是有意义的——我们白白浪费了两次计算。
但如果我们把这三个任务塞进异步更新队列里,它们会先在 JS 的层面上被批量执行完毕。当流程走到渲染这一步时,它仅仅需要针对有意义的计算结果操作一次 DOM——这就是异步更新的妙处。
2. Vue状态更新手法:nextTick
Vue 每次想要更新一个状态的时候,会先把它这个更新操作给包装成一个异步操作派发出去。这件事情,在源码中是由一个叫做
nextTick的函数来完成的:
export function nextTick (cb?: Function, ctx?: Object) {
let _resolve
callbacks.push(() => {
if (cb) {
try {
cb.call(ctx)
} catch (e) {
handleError(e, ctx, 'nextTick')
}
} else if (_resolve) {
_resolve(ctx)
}
})
// 检查上一个异步任务队列(即名为callbacks的任务数组)是否派发和执行完毕了。pending此处相当于一个锁
if (!pending) {
// 若上一个异步任务队列已经执行完毕,则将pending设定为true(把锁锁上)
pending = true
// 是否要求一定要派发为macro任务
if (useMacroTask) {
macroTimerFunc()
} else {
// 如果不说明一定要macro 你们就全都是micro
microTimerFunc()
}
}
// $flow-disable-line
if (!cb && typeof Promise !== 'undefined') {
return new Promise(resolve => {
_resolve = resolve
})
}
}
- 我们看到,Vue 的异步任务默认情况下都是用
Promise来包装的,也就是是说它们都是micro-task。这一点和我们“前置知识”中的渲染时机的分析不谋而合。 - 为了带大家熟悉一下常见的
macro和micro派发方式、加深对Event Loop的理解,我们继续细化解析一下macroTimeFunc()和microTimeFunc()两个方法。
macroTimeFunc() 是这么实现的:
// macro首选setImmediate 这个兼容性最差
if (typeof setImmediate !== 'undefined' && isNative(setImmediate)) {
macroTimerFunc = () => {
setImmediate(flushCallbacks)
}
} else if (typeof MessageChannel !== 'undefined' && (
isNative(MessageChannel) ||
// PhantomJS
MessageChannel.toString() === '[object MessageChannelConstructor]'
)) {
const channel = new MessageChannel()
const port = channel.port2
channel.port1.onmessage = flushCallbacks
macroTimerFunc = () => {
port.postMessage(1)
}
} else {
// 兼容性最好的派发方式是setTimeout
macroTimerFunc = () => {
setTimeout(flushCallbacks, 0)
}
}
microTimeFunc() 是这么实现的:
// 简单粗暴 不是ios全都给我去Promise 如果不兼容promise 那么你只能将就一下变成macro了
if (typeof Promise !== 'undefined' && isNative(Promise)) {
const p = Promise.resolve()
microTimerFunc = () => {
p.then(flushCallbacks)
// in problematic UIWebViews, Promise.then doesn't completely break, but
// it can get stuck in a weird state where callbacks are pushed into the
// microtask queue but the queue isn't being flushed, until the browser
// needs to do some other work, e.g. handle a timer. Therefore we can
// "force" the microtask queue to be flushed by adding an empty timer.
if (isIOS) setTimeout(noop)
}
} else {
// 如果无法派发micro,就退而求其次派发为macro
microTimerFunc = macroTimerFunc
}
我们注意到,无论是派发 macro 任务还是派发 micro 任务,派发的任务对象都是一个叫做 flushCallbacks 的东西,这个东西做了什么呢?
flushCallbacks 源码如下:
function flushCallbacks () {
pending = false
// callbacks在nextick中出现过 它是任务数组(队列)
const copies = callbacks.slice(0)
callbacks.length = 0
// 将callbacks中的任务逐个取出执行
for (let i = 0; i < copies.length; i++) {
copies[i]()
}
}
- 现在我们理清楚了:
Vue中每产生一个状态更新任务,它就会被塞进一个叫callbacks的数组(此处是任务队列的实现形式)中。这个任务队列在被丢进micro或macro队列之前,会先去检查当前是否有异步更新任务正在执行(即检查pending锁)。如果确认pending锁是开着的(false),就把它设置为锁上(true),然后对当前callbacks数组的任务进行派发(丢进micro或 macro 队列)和执行。设置pending锁的意义在于保证状态更新任务的有序进行,避免发生混乱。 - 本小节我们从性能优化的角度出发,通过解析Vue源码,对异步更新这一高效的
DOM优化手段有了感性的认知。同时帮助大家进一步熟悉了micro与macro在生产中的应用,加深了对Event Loop的理解。事实上,Vue 源码中还有许多值得称道的生产实践,其设计模式与编码细节都值得我们去细细品味。对这个话题感兴趣的同学,课后不妨移步 Vue运行机制解析 (opens new window) 进行探索。
# 小结
- 至此,我们的 DOM 优化之路才走完了一半。
- 以上我们都在讨论“如何减少 DOM 操作”的话题。这个话题比较宏观——DOM 操作也分很多种,它们带来的变化各不相同。有的操作只触发重绘,这时我们的性能损耗就小一些;有的操作会触发回流,这时我们更“肉疼”一些。那么如何理解回流与重绘,如何借助这些理解去提升页面渲染效率呢?
- 结束了 JS 的征程,我们下面就走进 CSS 的世界一窥究竟。
# 十一、渲染篇 5:最后一击——回流(Reflow)与重绘(Repaint)
开篇我们先对上上节介绍的回流与重绘的基础知识做个复习(跳读的同学请自觉回到上上节补齐 →_→)。
回流:当我们对 DOM 的修改引发了 DOM 几何尺寸的变化(比如修改元素的宽、高或隐藏元素等)时,浏览器需要重新计算元素的几何属性(其他元素的几何属性和位置也会因此受到影响),然后再将计算的结果绘制出来。这个过程就是回流(也叫重排)。
重绘:当我们对 DOM 的修改导致了样式的变化、却并未影响其几何属性(比如修改了颜色或背景色)时,浏览器不需重新计算元素的几何属性、直接为该元素绘制新的样式(跳过了上图所示的回流环节)。这个过程叫做重绘。
由此我们可以看出,重绘不一定导致回流,回流一定会导致重绘。硬要比较的话,回流比重绘做的事情更多,带来的开销也更大。但这两个说到底都是吃性能的,所以都不是什么善茬。我们在开发中,要从代码层面出发,尽可能把回流和重绘的次数最小化。
# 哪些实际操作会导致回流与重绘
- 要避免回流与重绘的发生,最直接的做法是避免掉可能会引发回流与重绘的 DOM 操作,就好像拆弹专家在解决一颗炸弹时,最重要的是掐灭它的导火索。
- 触发重绘的“导火索”比较好识别——只要是不触发回流,但又触发了样式改变的 DOM 操作,都会引起重绘,比如背景色、文字色、可见性(可见性这里特指形如visibility: hidden这样不改变元素位置和存在性的、单纯针对可见性的操作,注意与display:none进行区分)等。为此,我们要着重理解一下那些可能触发回流的操作。
1. 回流的“导火索”
最“贵”的操作:改变 DOM 元素的几何属性
- 这个改变几乎可以说是“牵一发动全身”——当一个DOM元素的几何属性发生变化时,所有和它相关的节点(比如父子节点、兄弟节点等)的几何属性都需要进行重新计算,它会带来巨大的计算量。
- 常见的几何属性有
width、height、padding、margin、left、top、border等等。此处不再给大家一一列举。有的文章喜欢罗列属性表格,但我相信我今天列出来大家也不会看、看了也记不住(因为太多了)。我自己也不会去记这些——其实确实没必要记,️一个属性是不是几何属性、会不会导致空间布局发生变化,大家写样式的时候完全可以通过代码效果看出来。多说无益,还希望大家可以多写多试,形成自己的“肌肉记忆”。
- “价格适中”的操作:改变 DOM 树的结构
这里主要指的是节点的增减、移动等操作。浏览器引擎布局的过程,顺序上可以类比于树的前序遍历——它是一个从上到下、从左到右的过程。通常在这个过程中,当前元素不会再影响其前面已经遍历过的元素。
- 最容易被忽略的操作:获取一些特定属性的值
当你要用到像这样的属性:
offsetTop、offsetLeft、offsetWidth、offsetHeight、scrollTop、scrollLeft、scrollWidth、scrollHeight、clientTop、clientLeft、clientWidth、clientHeight时,你就要注意了!
- “像这样”的属性,到底是像什么样?——这些值有一个共性,就是需要通过即时计算得到。因此浏览器为了获取这些值,也会进行回流。
- 除此之外,当我们调用了
getComputedStyle方法,或者 IE 里的currentStyle时,也会触发回流。原理是一样的,都为求一个“即时性”和“准确性”。
# 如何规避回流与重绘
了解了回流与重绘的“导火索”,我们就要尽量规避它们。但很多时候,我们不得不使用它们。当避无可避时,我们就要学会更聪明地使用它们。
1. 将“导火索”缓存起来,避免频繁改动
有时我们想要通过多次计算得到一个元素的布局位置,我们可能会这样做:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
<style>
#el {
width: 100px;
height: 100px;
background-color: yellow;
position: absolute;
}
</style>
</head>
<body>
<div id="el"></div>
<script>
// 获取el元素
const el = document.getElementById('el')
// 这里循环判定比较简单,实际中或许会拓展出比较复杂的判定需求
for(let i=0;i<10;i++) {
el.style.top = el.offsetTop + 10 + "px";
el.style.left = el.offsetLeft + 10 + "px";
}
</script>
</body>
</html>
这样做,每次循环都需要获取多次“敏感属性”,是比较糟糕的。我们可以将其以 JS 变量的形式缓存起来,待计算完毕再提交给浏览器发出重计算请求:
// 缓存offsetLeft与offsetTop的值
const el = document.getElementById('el')
let offLeft = el.offsetLeft, offTop = el.offsetTop
// 在JS层面进行计算
for(let i=0;i<10;i++) {
offLeft += 10
offTop += 10
}
// 一次性将计算结果应用到DOM上
el.style.left = offLeft + "px"
el.style.top = offTop + "px"
2. 避免逐条改变样式,使用类名去合并样式
比如我们可以把这段单纯的代码:
const container = document.getElementById('container')
container.style.width = '100px'
container.style.height = '200px'
container.style.border = '10px solid red'
container.style.color = 'red'
优化成一个有 class 加持的样子:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
<style>
.basic_style {
width: 100px;
height: 200px;
border: 10px solid red;
color: red;
}
</style>
</head>
<body>
<div id="container"></div>
<script>
const container = document.getElementById('container')
container.classList.add('basic_style')
</script>
</body>
</html>
- 前者每次单独操作,都去触发一次渲染树更改,从而导致相应的回流与重绘过程。
- 合并之后,等于我们将所有的更改一次性发出,用一个 style 请求解决掉了。
3. 将 DOM “离线”
我们上文所说的回流和重绘,都是在“该元素位于页面上”的前提下会发生的。一旦我们给元素设置 display: none,将其从页面上“拿掉”,那么我们的后续操作,将无法触发回流与重绘——这个将元素“拿掉”的操作,就叫做 DOM 离线化。
仍以我们上文的代码片段为例:
const container = document.getElementById('container')
container.style.width = '100px'
container.style.height = '200px'
container.style.border = '10px solid red'
container.style.color = 'red'
...(省略了许多类似的后续操作)
离线化后就是这样:
let container = document.getElementById('container')
container.style.display = 'none'
container.style.width = '100px'
container.style.height = '200px'
container.style.border = '10px solid red'
container.style.color = 'red'
...(省略了许多类似的后续操作)
container.style.display = 'block'
有的同学会问,拿掉一个元素再把它放回去,这不也会触发一次昂贵的回流吗?这话不假,但我们把它拿下来了,后续不管我操作这个元素多少次,每一步的操作成本都会非常低。当我们只需要进行很少的 DOM 操作时,DOM 离线化的优越性确实不太明显。一旦操作频繁起来,这“拿掉”和“放回”的开销都将会是非常值得的。
# Flush 队列:浏览器并没有那么简单
- 以我们现在的知识基础,理解上面的优化操作并不难。那么现在我问大家一个问题:
let container = document.getElementById('container')
container.style.width = '100px'
container.style.height = '200px'
container.style.border = '10px solid red'
container.style.color = 'red'
这段代码里,浏览器进行了多少次的回流或重绘呢?
“
width、height、border是几何属性,各触发一次回流;color只造成外观的变化,会触发一次重绘。”——如果你立刻这么想了,说明你是个能力不错的同学,认真阅读了前面的内容。那么我们现在立刻跑一跑这段代码,看看浏览器怎么说:

- 这里为大家截取有“
Layout”和“Paint”出镜的片段(这个图是通过 Chrome 的Performance面板得到的,后面会教大家用这个东西)。我们看到浏览器只进行了一次回流和一次重绘——和我们想的不一样啊,为啥呢? - 因为现代浏览器是很聪明的。浏览器自己也清楚,如果每次 DOM 操作都即时地反馈一次回流或重绘,那么性能上来说是扛不住的。于是它自己缓存了一个 flush 队列,把我们触发的回流与重绘任务都塞进去,待到队列里的任务多起来、或者达到了一定的时间间隔,或者“不得已”的时候,再将这些任务一口气出队。因此我们看到,上面就算我们进行了 4 次 DOM 更改,也只触发了一次
Layout和一次Paint。
大家这里尤其小心这个“不得已”的时候。前面我们在介绍回流的“导火索”的时候,提到过有一类属性很特别,它们有很强的“即时性”。当我们访问这些属性时,浏览器会为了获得此时此刻的、最准确的属性值,而提前将 flush 队列的任务出队——这就是所谓的“不得已”时刻。具体是哪些属性值,我们已经在“最容易被忽略的操作”这个小模块介绍过了,此处不再赘述。
# 小结
- 整个一节读下来,可能会有同学感到疑惑:既然浏览器已经为我们做了批处理优化,为什么我们还要自己操心这么多事情呢?今天避免这个明天避免那个,多麻烦!
- 问题在于,并不是所有的浏览器都是聪明的。我们刚刚的性能图表,是 Chrome 的开发者工具呈现给我们的。Chrome 里行得通的东西,到了别处(比如 IE)就不一定行得通了。而我们并不知道用户会使用什么样的浏览器。如果不手动做优化,那么一个页面在不同的环境下就会呈现不同的性能效果,这对我们、对用户都是不利的。因此,养成良好的编码习惯、从根源上解决问题,仍然是最周全的方法。
# 十二、应用篇 1:优化首屏体验——Lazy-Load 初探
首先要告诉大家的是,截止到上个章节,我们需要大家绞尽脑汁去理解的“硬核”操作基本告一段落了。从本节开始,我们会一起去实现一些必知必会、同时难度不大的常用优化手段。
这部分内容不难,但很关键。尤其是近期有校招或跳槽需求的同学,还请务必对这部分内容多加留心,说不定下一次的面试题里就有它们的身影。
# Lazy-Load 初相见
Lazy-Load,翻译过来是“懒加载”。它是针对图片加载时机的优化:在一些图片量比较大的网站(比如电商网站首页,或者团购网站、小游戏首页等),如果我们尝试在用户打开页面的时候,就把所有的图片资源加载完毕,那么很可能会造成白屏、卡顿等现象,因为图片真的太多了,一口气处理这么多任务,浏览器做不到啊!
但我们再想,用户真的需要这么多图片吗?不对,用户点开页面的瞬间,呈现给他的只有屏幕的一部分(我们称之为首屏)。只要我们可以在页面打开的时候把首屏的图片资源加载出来,用户就会认为页面是没问题的。至于下面的图片,我们完全可以等用户下拉的瞬间再即时去请求、即时呈现给他。这样一来,性能的压力小了,用户的体验却没有变差——这个延迟加载的过程,就是 Lazy-Load。
现在我们打开掘金首页:
大家留意一栏文章右侧可能会出现的图片,这里咱们给个特写:

大家现在以尽可能快的速度,疯狂向下拉动页面。发现什么?是不是发现我们图示的这个图片的位置,会出现闪动——有时候我们明明已经拉到目标位置了,文字也呈现完毕了,图片却慢半拍才显示出来。这是因为,掘金首页也采用了懒加载策略。当我们的页面并未滚动至包含图片的 div 元素所在的位置时,它的样式是这样的:

我们把代码提出来看一下:
<div data-v-b2db8566=""
data-v-009ea7bb=""
data-v-6b46a625=""
data-src="https://user-gold-cdn.xitu.io/2018/9/27/16619f449ee24252?imageView2/1/w/120/h/120/q/85/format/webp/interlace/1"
class="lazy thumb thumb"
style="background-image: none; background-size: cover;">
</div>
- 我们注意到
style内联样式中,背景图片设置为了none。也就是说这个div是没有内容的,它只起到一个占位的作用。 - 这个“占位”的概念,在这个例子里或许体现得不够直观。最直观的应该是淘宝首页的 HTML Preview 效果:
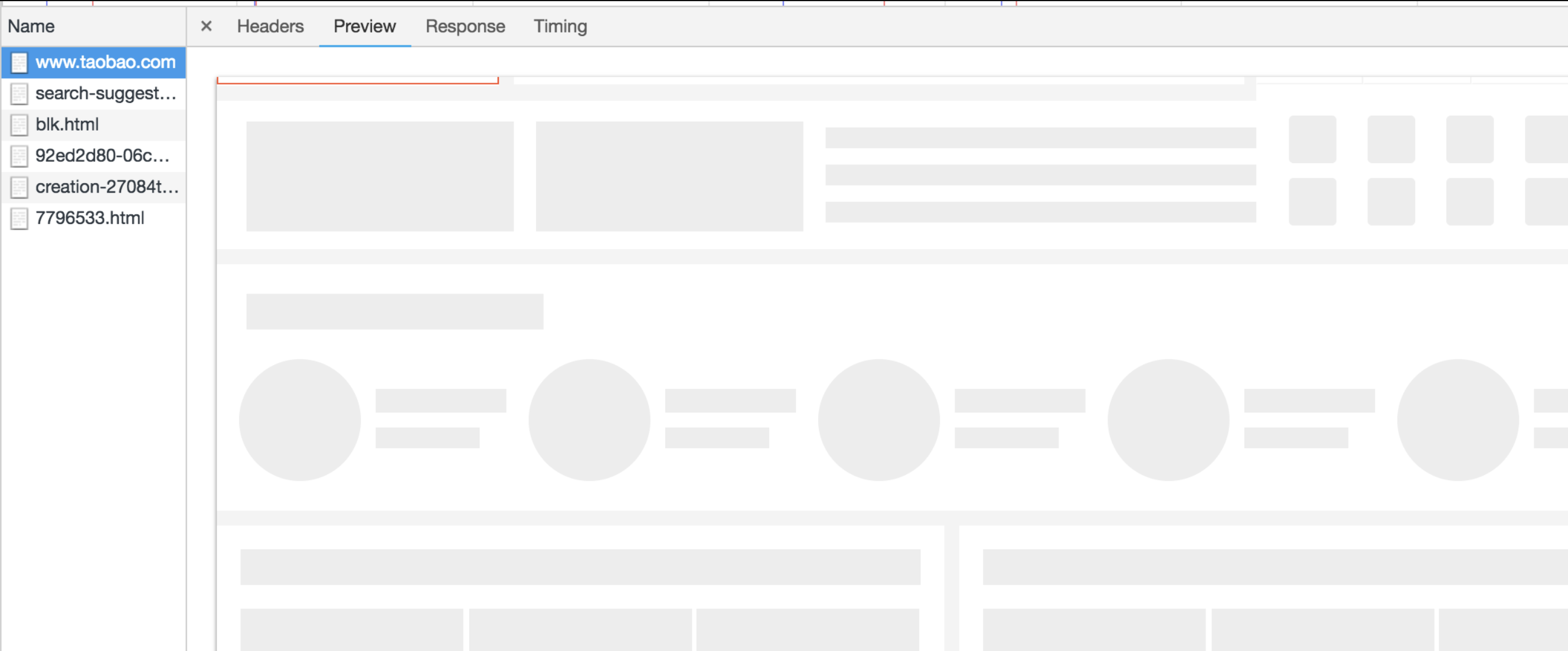
- 我们看到,这个还没来得及被图片填充完全的网页,是用大大小小的空
div元素来占位的。掘金首页也是如此。 - 一旦我们通过滚动使得这个
div出现在了可见范围内,那么div元素的内容就会发生变化,呈现如下的内容:
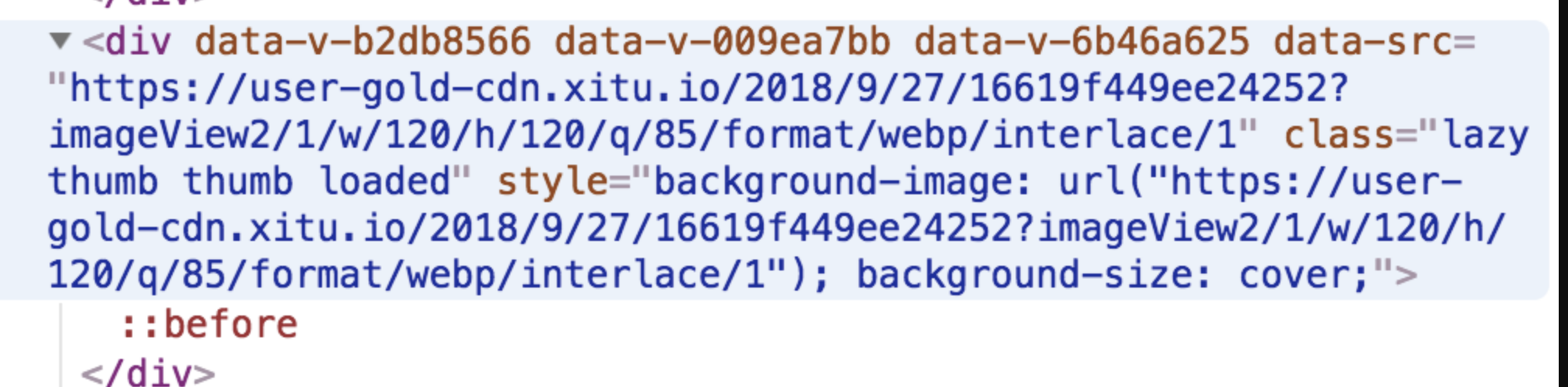
我们给 style 一个特写:
style="background-image: url("https://user-gold-cdn.xitu.io/2018/9/27/16619f449ee24252?imageView2/1/w/120/h/120/q/85/format/webp/interlace/1"); background-size: cover;"
可以看出,
style内联样式中的背景图片属性从none变成了一个在线图片的URL。也就是说,出现在可视区域的瞬间,div 元素的内容被即时地修改掉了——它被写入了有效的图片 URL,于是图片才得以呈现。这就是懒加载的实现思路。
# 一起写一个 Lazy-Load 吧!
基于上面的实现思路,我们完全可以手动实现一个属于自己的 Lazy-Load。
此处敲黑板划重点,Lazy-Load 的思路及实现方式为大厂面试常考题,还望诸位同学引起重视
首先新建一个空项目,目录结构如下:
- 大家可以往
images文件夹里塞入各种各样自己喜欢的图片。 - 我们在
index.html中,为这些图片预置img标签:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Lazy-Load</title>
<style>
.img {
width: 200px;
height:200px;
background-color: gray;
}
.pic {
// 必要的img样式
}
</style>
</head>
<body>
<div class="container">
<div class="img">
// 注意我们并没有为它引入真实的src
<img class="pic" alt="加载中" data-src="./images/1.png">
</div>
<div class="img">
<img class="pic" alt="加载中" data-src="./images/2.png">
</div>
<div class="img">
<img class="pic" alt="加载中" data-src="./images/3.png">
</div>
<div class="img">
<img class="pic" alt="加载中" data-src="./images/4.png">
</div>
<div class="img">
<img class="pic" alt="加载中" data-src="./images/5.png">
</div>
<div class="img">
<img class="pic" alt="加载中" data-src="./images/6.png">
</div>
<div class="img">
<img class="pic" alt="加载中" data-src="./images/7.png">
</div>
<div class="img">
<img class="pic" alt="加载中" data-src="./images/8.png">
</div>
<div class="img">
<img class="pic" alt="加载中" data-src="./images/9.png">
</div>
<div class="img">
<img class="pic" alt="加载中" data-src="./images/10.png">
</div>
</div>
</body>
</html>
- 在懒加载的实现中,有两个关键的数值:一个是当前可视区域的高度,另一个是元素距离可视区域顶部的高度。
- 当前可视区域的高度, 在和现代浏览器及 IE9 以上的浏览器中,可以用
window.innerHeight属性获取。在低版本 IE 的标准模式中,可以用document.documentElement.clientHeight获取,这里我们兼容两种情况:
const viewHeight = window.innerHeight || document.documentElement.clientHeight
而元素距离可视区域顶部的高度,我们这里选用 getBoundingClientRect() 方法来获取返回元素的大小及其相对于视口的位置。对此 MDN 给出了非常清晰的解释:
该方法的返回值是一个
DOMRect对象,这个对象是由该元素的getClientRects()方法返回的一组矩形的集合, 即:是与该元素相关的CSS边框集合 。
DOMRect对象包含了一组用于描述边框的只读属性——left、top、right和bottom,单位为像素。除了width和height外的属性都是相对于视口的左上角位置而言的。
其中需要引起我们注意的就是 left、top、right 和 bottom,它们对应到元素上是这样的:
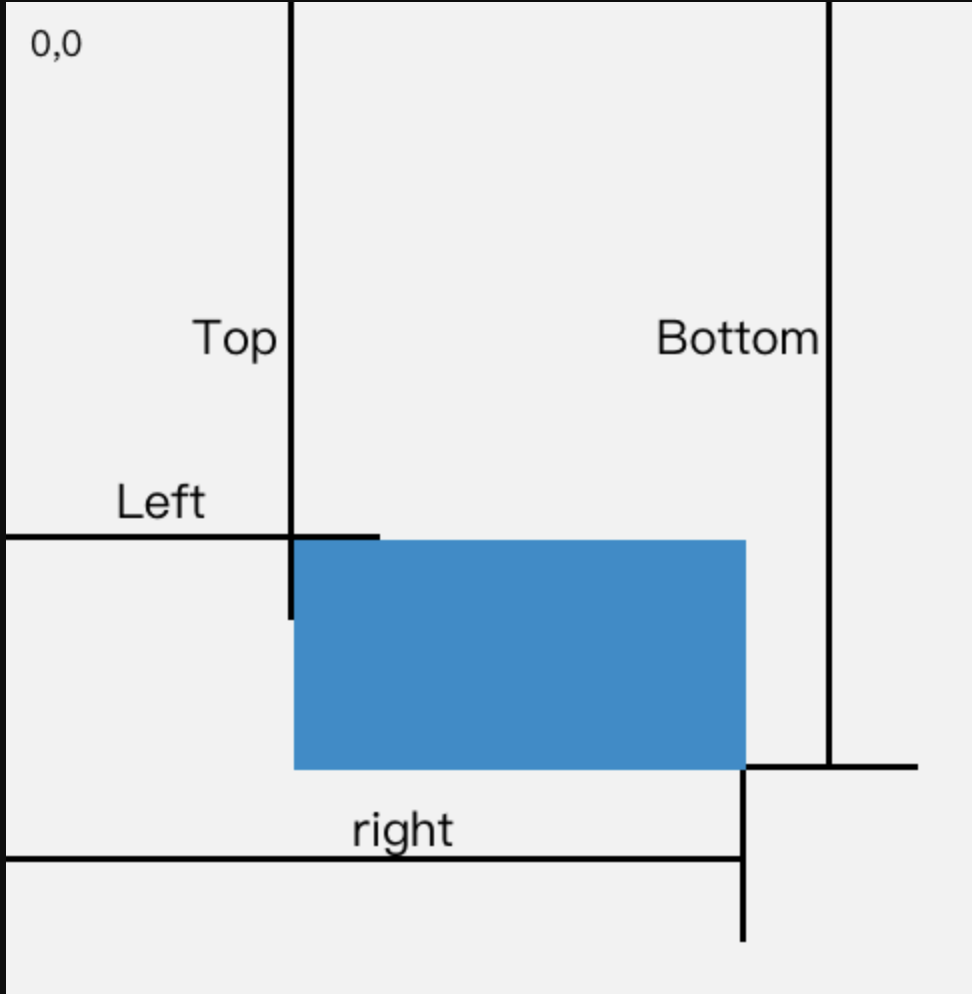
可以看出,top 属性代表了元素距离可视区域顶部的高度,正好可以为我们所用!
Lazy-Load 方法开工啦!
<script>
// 获取所有的图片标签
const imgs = document.getElementsByTagName('img')
// 获取可视区域的高度
const viewHeight = window.innerHeight || document.documentElement.clientHeight
// num用于统计当前显示到了哪一张图片,避免每次都从第一张图片开始检查是否露出
let num = 0
function lazyload(){
for(let i=num; i<imgs.length; i++) {
// 用可视区域高度减去元素顶部距离可视区域顶部的高度
let distance = viewHeight - imgs[i].getBoundingClientRect().top
// 如果可视区域高度大于等于元素顶部距离可视区域顶部的高度,说明元素露出
if(distance >= 0 ){
// 给元素写入真实的src,展示图片
imgs[i].src = imgs[i].getAttribute('data-src')
// 前i张图片已经加载完毕,下次从第i+1张开始检查是否露出
num = i + 1
}
}
}
// 监听Scroll事件
window.addEventListener('scroll', lazyload, false);
</script>
# 小结
- 本节我们实现出了一个最基本的懒加载功能。但是大家要注意一点:这个
scroll事件,是一个危险的事件——它太容易被触发了。试想,用户在访问网页的时候,是不是可以无限次地去触发滚动?尤其是一个页面死活加载不出来的时候,疯狂调戏鼠标滚轮(或者浏览器滚动条)的用户可不在少数啊! - 再回头看看我们上面写的代码。按照我们的逻辑,用户的每一次滚动都将触发我们的监听函数。函数执行是吃性能的,频繁地响应某个事件将造成大量不必要的页面计算。因此,我们需要针对那些有可能被频繁触发的事件作进一步地优化。这里就引出了我们下一节的两位主角——
throttle与debounce。
# 十三、应用篇 2:事件的节流(throttle)与防抖(debounce)
上一节我们一起通过监听滚动事件,实现了各大网站喜闻乐见的懒加载效果。但我们提到,
scroll事件是一个非常容易被反复触发的事件。其实不止scroll事件,resize事件、鼠标事件(比如mousemove、mouseover等)、键盘事件(keyup、keydown等)都存在被频繁触发的风险。
- 频繁触发回调导致的大量计算会引发页面的抖动甚至卡顿。为了规避这种情况,我们需要一些手段来控制事件被触发的频率。就是在这样的背景下,
throttle(事件节流)和debounce(事件防抖)出现了。
# “节流”与“防抖”的本质
这两个东西都以闭包的形式存在。
它们通过对事件对应的回调函数进行包裹、以自由变量的形式缓存时间信息,最后用 setTimeout 来控制事件的触发频率。
# Throttle: 第一个人说了算
throttle的中心思想在于:在某段时间内,不管你触发了多少次回调,我都只认第一次,并在计时结束时给予响应。
先给大家讲个小故事:现在有一个旅客刚下了飞机,需要用车,于是打电话叫了该机场唯一的一辆机场大巴来接。司机开到机场,心想来都来了,多接几个人一起走吧,这样这趟才跑得值——我等个十分钟看看。于是司机一边打开了计时器,一边招呼后面的客人陆陆续续上车。在这十分钟内,后面下飞机的乘客都只能乘这一辆大巴,十分钟过去后,不管后面还有多少没挤上车的乘客,这班车都必须发走。
在这个故事里,“司机” 就是我们的节流阀,他控制发车的时机;“乘客”就是因为我们频繁操作事件而不断涌入的回调任务,它需要接受“司机”的安排;而“计时器”,就是我们上文提到的以自由变量形式存在的时间信息,它是“司机”决定发车的依据;最后“发车”这个动作,就对应到回调函数的执行。
总结下来,所谓的“节流”,是通过在一段时间内无视后来产生的回调请求来实现的。只要一位客人叫了车,司机就会为他开启计时器,一定的时间内,后面需要乘车的客人都得排队上这一辆车,谁也无法叫到更多的车。
对应到实际的交互上是一样一样的:每当用户触发了一次 scroll 事件,我们就为这个触发操作开启计时器。一段时间内,后续所有的 scroll 事件都会被当作“一辆车的乘客”——它们无法触发新的 scroll 回调。直到“一段时间”到了,第一次触发的 scroll 事件对应的回调才会执行,而“一段时间内”触发的后续的 scroll 回调都会被节流阀无视掉。
理解了大致的思路,我们现在一起实现一个 throttle:
// fn是我们需要包装的事件回调, interval是时间间隔的阈值
function throttle(fn, interval) {
// last为上一次触发回调的时间
let last = 0
// 将throttle处理结果当作函数返回
return function () {
// 保留调用时的this上下文
let context = this
// 保留调用时传入的参数
let args = arguments
// 记录本次触发回调的时间
let now = +new Date()
// 判断上次触发的时间和本次触发的时间差是否小于时间间隔的阈值
if (now - last >= interval) {
// 如果时间间隔大于我们设定的时间间隔阈值,则执行回调
last = now;
fn.apply(context, args);
}
}
}
// 用throttle来包装scroll的回调
const better_scroll = throttle(() => console.log('触发了滚动事件'), 1000)
document.addEventListener('scroll', better_scroll)
# Debounce: 最后一个人说了算
防抖的中心思想在于:我会等你到底。在某段时间内,不管你触发了多少次回调,我都只认最后一次。
继续讲司机开车的故事。这次的司机比较有耐心。第一个乘客上车后,司机开始计时(比如说十分钟)。十分钟之内,如果又上来了一个乘客,司机会把计时器清零,重新开始等另一个十分钟(延迟了等待)。直到有这么一位乘客,从他上车开始,后续十分钟都没有新乘客上车,司机会认为确实没有人需要搭这趟车了,才会把车开走。
我们对比 throttle 来理解 debounce:在throttle的逻辑里,“第一个人说了算”,它只为第一个乘客计时,时间到了就执行回调。而 debounce 认为,“最后一个人说了算”,debounce 会为每一个新乘客设定新的定时器。
我们基于上面的理解,一起来写一个 debounce:
// fn是我们需要包装的事件回调, delay是每次推迟执行的等待时间
function debounce(fn, delay) {
// 定时器
let timer = null
// 将debounce处理结果当作函数返回
return function () {
// 保留调用时的this上下文
let context = this
// 保留调用时传入的参数
let args = arguments
// 每次事件被触发时,都去清除之前的旧定时器
if(timer) {
clearTimeout(timer)
}
// 设立新定时器
timer = setTimeout(function () {
fn.apply(context, args)
}, delay)
}
}
// 用debounce来包装scroll的回调
const better_scroll = debounce(() => console.log('触发了滚动事件'), 1000)
document.addEventListener('scroll', better_scroll)
# 用 Throttle 来优化 Debounce
debounce的问题在于它“太有耐心了”。试想,如果用户的操作十分频繁——他每次都不等debounce设置的delay时间结束就进行下一次操作,于是每次debounce都为该用户重新生成定时器,回调函数被延迟了不计其数次。频繁的延迟会导致用户迟迟得不到响应,用户同样会产生“这个页面卡死了”的观感。
为了避免弄巧成拙,我们需要借力 throttle 的思想,打造一个“有底线”的 debounce——等你可以,但我有我的原则:delay 时间内,我可以为你重新生成定时器;但只要delay的时间到了,我必须要给用户一个响应。这个 throttle 与 debounce “合体”思路,已经被很多成熟的前端库应用到了它们的加强版 throttle 函数的实现中:
// fn是我们需要包装的事件回调, delay是时间间隔的阈值
function throttle(fn, delay) {
// last为上一次触发回调的时间, timer是定时器
let last = 0, timer = null
// 将throttle处理结果当作函数返回
return function () {
// 保留调用时的this上下文
let context = this
// 保留调用时传入的参数
let args = arguments
// 记录本次触发回调的时间
let now = +new Date()
// 判断上次触发的时间和本次触发的时间差是否小于时间间隔的阈值
if (now - last < delay) {
// 如果时间间隔小于我们设定的时间间隔阈值,则为本次触发操作设立一个新的定时器
clearTimeout(timer)
timer = setTimeout(function () {
last = now
fn.apply(context, args)
}, delay)
} else {
// 如果时间间隔超出了我们设定的时间间隔阈值,那就不等了,无论如何要反馈给用户一次响应
last = now
fn.apply(context, args)
}
}
}
// 用新的throttle包装scroll的回调
const better_scroll = throttle(() => console.log('触发了滚动事件'), 1000)
document.addEventListener('scroll', better_scroll)
# 小结
throttle和debounce不仅是我们日常开发中的常用优质代码片段,更是前端面试中不可不知的高频考点。“看懂了代码”、“理解了过程”在本节都是不够的,重要的是把它写到自己的项目里去,亲自体验一把节流和防抖带来的性能提升。
# 十四、性能监测篇:Performance、LightHouse 与性能 API
- 性能监测是前端性能优化的重要一环。监测的目的是为了确定性能瓶颈,从而有的放矢地开展具体的优化工作。
- 平时我们比较推崇的性能监测方案主要有两种:可视化方案、可编程方案。这两种方案下都有非常优秀、且触手可及的相关工具供大家选择,本节我们就一起来研究一下这些工具的用法。
# 可视化监测:从 Performance 面板说起
Performance是 Chrome 提供给我们的开发者工具,用于记录和分析我们的应用在运行时的所有活动。它呈现的数据具有实时性、多维度的特点,可以帮助我们很好地定位性能问题。
1. 开始记录
右键打开开发者工具,选中我们的 Performance 面板:
- 当我们选中图中所标示的实心圆按钮,
Performance会开始帮我们记录我们后续的交互操作;当我们选中圆箭头按钮,Performance会将页面重新加载,计算加载过程中的性能表现。 - tips:使用
Performance工具时,为了规避其它 Chrome 插件对页面的性能影响,我们最好在无痕模式下打开页面:


2. 简要分析
这里我打开掘金首页,选中 Performance 面板中的圆箭头,来看一下页面加载过程中的性能表现:
从上到下,依次为概述面板、详情面板。下我们先来观察一下概述面板,了解页面的基本表现:

我们看右上角的三个栏目:FPS、CPU 和 NET。
FPS:这是一个和动画性能密切相关的指标,它表示每一秒的帧数。图中绿色柱状越高表示帧率越高,体验就越流畅。若出现红色块,则代表长时间帧,很可能会出现卡顿。图中以绿色为主,偶尔出现红块,说明网页性能并不糟糕,但仍有可优化的空间。
CPU:表示CPU的使用情况,不同的颜色片段代表着消耗CPU资源的不同事件类型。这部分的图像和下文详情面板中的Summary内容有对应关系,我们可以结合这两者挖掘性能瓶颈。
NET:粗略的展示了各请求的耗时与前后顺序。这个指标一般来说帮助不大。
3. 挖掘性能瓶颈
详情面板中的内容有很多。但一般来说,我们会主要去看
Main栏目下的火焰图和Summary提供给我们的饼图——这两者和概述面板中的CPU一栏结合,可以帮我们迅速定位性能瓶颈(如下图)。
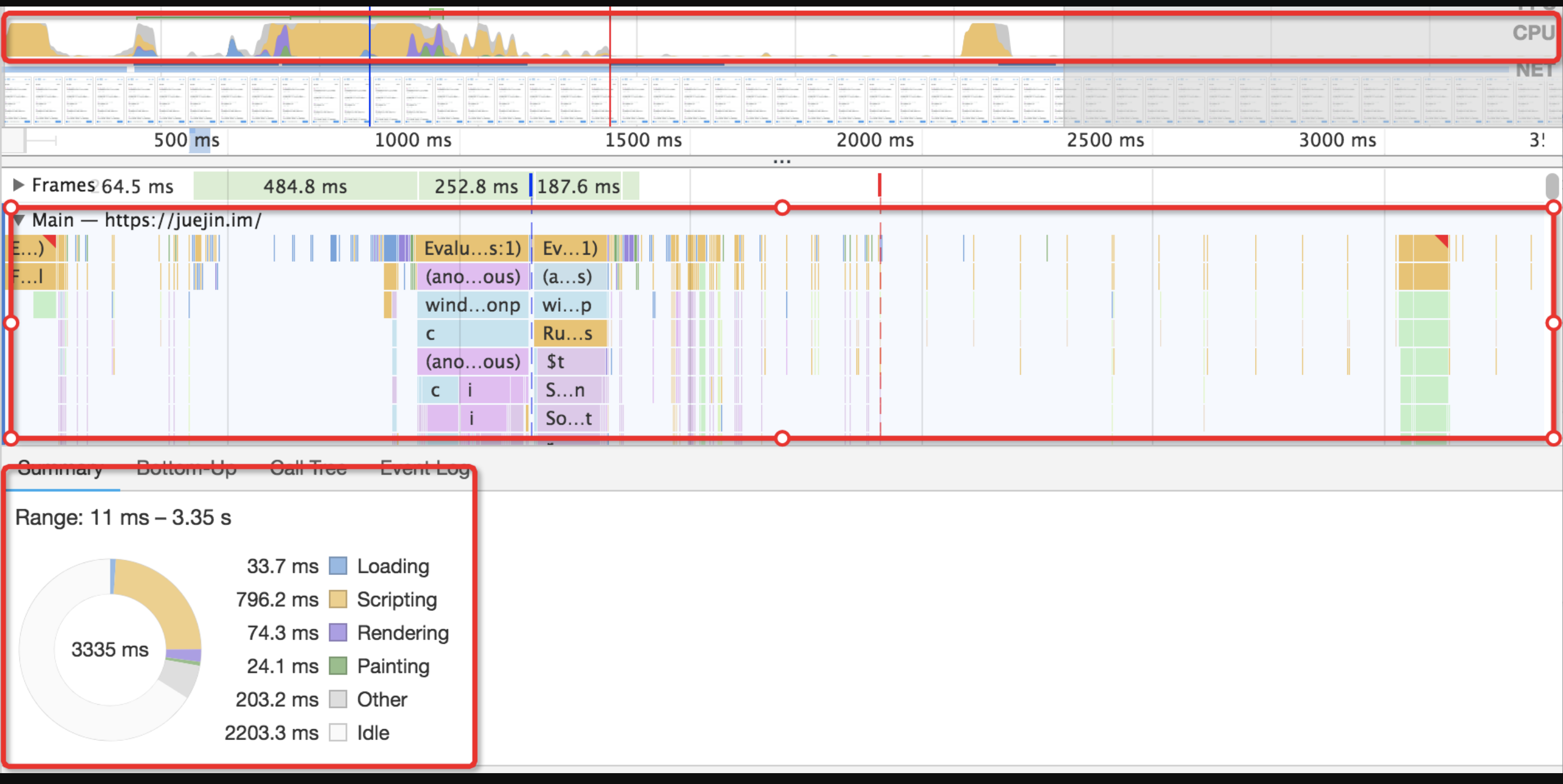
- 先看
CPU图表和Summary饼图。CPU图表中,我们可以根据颜色填充的饱满程度,确定CPU的忙闲,进而了解该页面的总的任务量。而Summary饼图则以一种直观的方式告诉了我们,哪个类型的任务最耗时(从本例来看是脚本执行过程)。这样我们在优化的时候,就可以抓到“主要矛盾”,进而有的放矢地开展后续的工作了。 - 再看
Main提供给我们的火焰图。这个火焰图非常关键,它展示了整个运行时主进程所做的每一件事情(包括加载、脚本运行、渲染、布局、绘制等)。x轴表示随时间的记录。每个长条就代表一个活动。更宽的条形意味着事件需要更长时间。y轴表示调用堆栈,我们可以看到事件是相互堆叠的,上层的事件触发了下层的事件。 CPU图标和Summary图都是按照“类型”给我们提供性能信息,而Main火焰图则将粒度细化到了每一个函数的调用。到底是从哪个过程开始出问题、是哪个函数拖了后腿、又是哪个事件触发了这个函数,这些具体的、细致的问题都将在Main火焰图中得到解答。
# 可视化监测: 更加聪明的 LightHouse
Performance无疑可以为我们提供很多有价值的信息,但它的展示作用大于分析作用。它要求使用者对工具本身及其所展示的信息有充分的理解,能够将晦涩的数据“翻译”成具体的性能问题。
程序员们许了个愿:如果工具能帮助我们把页面的问题也分析出来就好了!上帝听到了这个愿望,于是给了我们 LightHouse:
Lighthouse是一个开源的自动化工具,用于改进网络应用的质量。 你可以将其作为一个 Chrome 扩展程序运行,或从命令行运行。 为Lighthouse提供一个需要审查的网址,它将针对此页面运行一连串的测试,然后生成一个有关页面性能的报告。
敲黑板划重点:它生成的是一个报告!Report!不是干巴巴地数据,而是一个通过测试与分析呈现出来的结果(它甚至会给你的页面跑一个分数出来)。这个东西看起来也真是太赞了,我们这就来体验一下!
首先在 Chrome 的应用商店里下载一个 LightHouse。这一步 OK 之后,我们浏览器右上角会出现一个小小的灯塔 ICON。打开我们需要测试的那个页面,点击这个 ICON,唤起如下的面板:
然后点击“Generate report”按钮,只需静候数秒,LightHouse 就会为我们输出一个完美的性能报告。
这里我拿掘金首页“开刀”:
稍事片刻,Report 便输出成功了,LightHouse 默认会帮我们打开一个新的标签页来展示报告内容。报告内容非常丰富,首先我们看到的是整体的跑分情况:
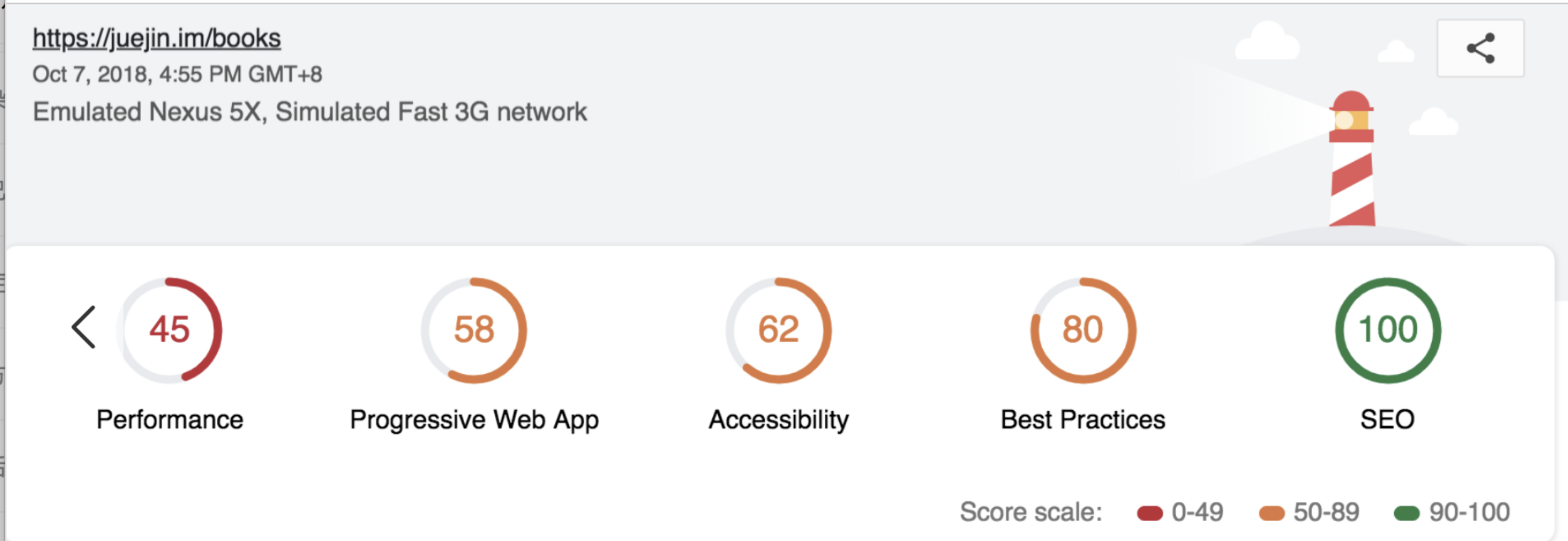
上述分别是页面性能、PWA(渐进式 Web 应用)、可访问性(无障碍)、最佳实践、SEO 五项指标的跑分。孰强孰弱,我们一看便知。
向下拉动 Report 页,我们还可以看到每一个指标的细化评估:
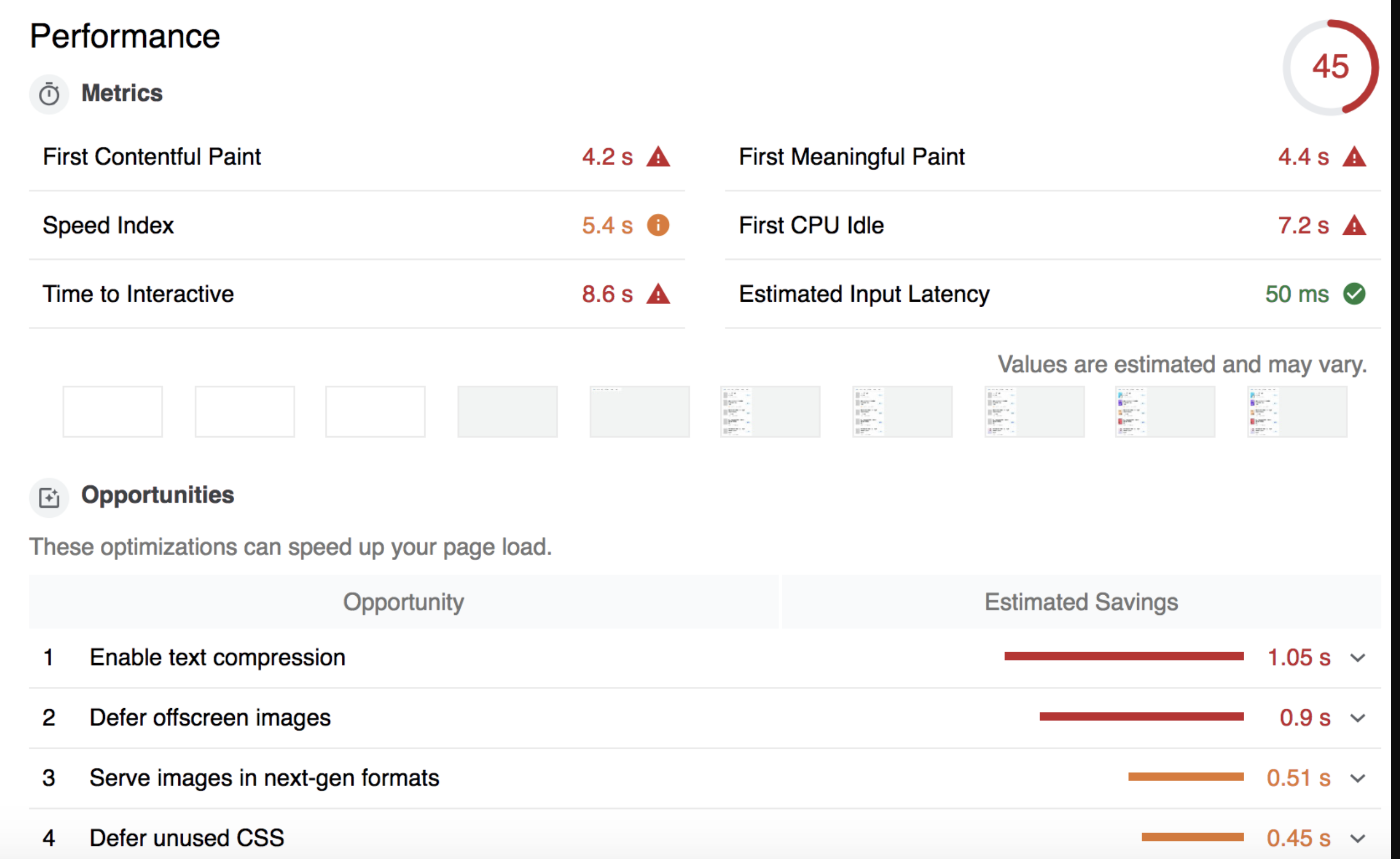
- 在“Opportunities”中,
LightHouse甚至针对我们的性能问题给出了可行的建议、以及每一项优化操作预期会帮我们节省的时间。这份报告的可操作性是很强的——我们只需要对着LightHouse给出的建议,一条一条地去尝试,就可以看到自己的页面,在一秒一秒地变快。 - 除了直接下载,我们还可以通过命令行使用
LightHouse:
npm install -g lighthouse
lighthouse https://juejin.im/books
同样可以得到掘金的性能报告。
此外,从 Chrome 60 开始,DevTools 中直接加入了基于 LightHouse 的 Audits 面板:
LightHouse因此变得更加触手可及了,这一操作也足以证明Chrome团队对LightHouse的推崇。
# 可编程的性能上报方案: W3C 性能 API
- W3C 规范为我们提供了
Performance相关的接口。它允许我们获取到用户访问一个页面的每个阶段的精确时间,从而对性能进行分析。我们可以将其理解为Performance面板的进一步细化与可编程化。 - 当下的前端世界里,数据可视化的概念已经被炒得非常热了,Performance 面板就是数据可视化的典范。那么为什么要把已经可视化的数据再掏出来处理一遍呢?这是因为,需要这些数据的人不止我们前端——很多情况下,后端也需要我们提供性能信息的上报。此外,
Performance提供的可视化结果并不一定能够满足我们实际的业务需求,只有拿到了真实的数据,我们才可以对它进行二次处理,去做一个更加深层次的可视化。
在这种需求背景下,我们就不得不祭出 Performance API了。
1. 访问 performance 对象
performance是一个全局对象。我们在控制台里输入window.performance,就可一窥其全貌:

2. 关键时间节点
在 performance 的 timing 属性中,我们可以查看到如下的时间戳:
这些时间戳与页面整个加载流程中的关键时间节点有着一一对应的关系:
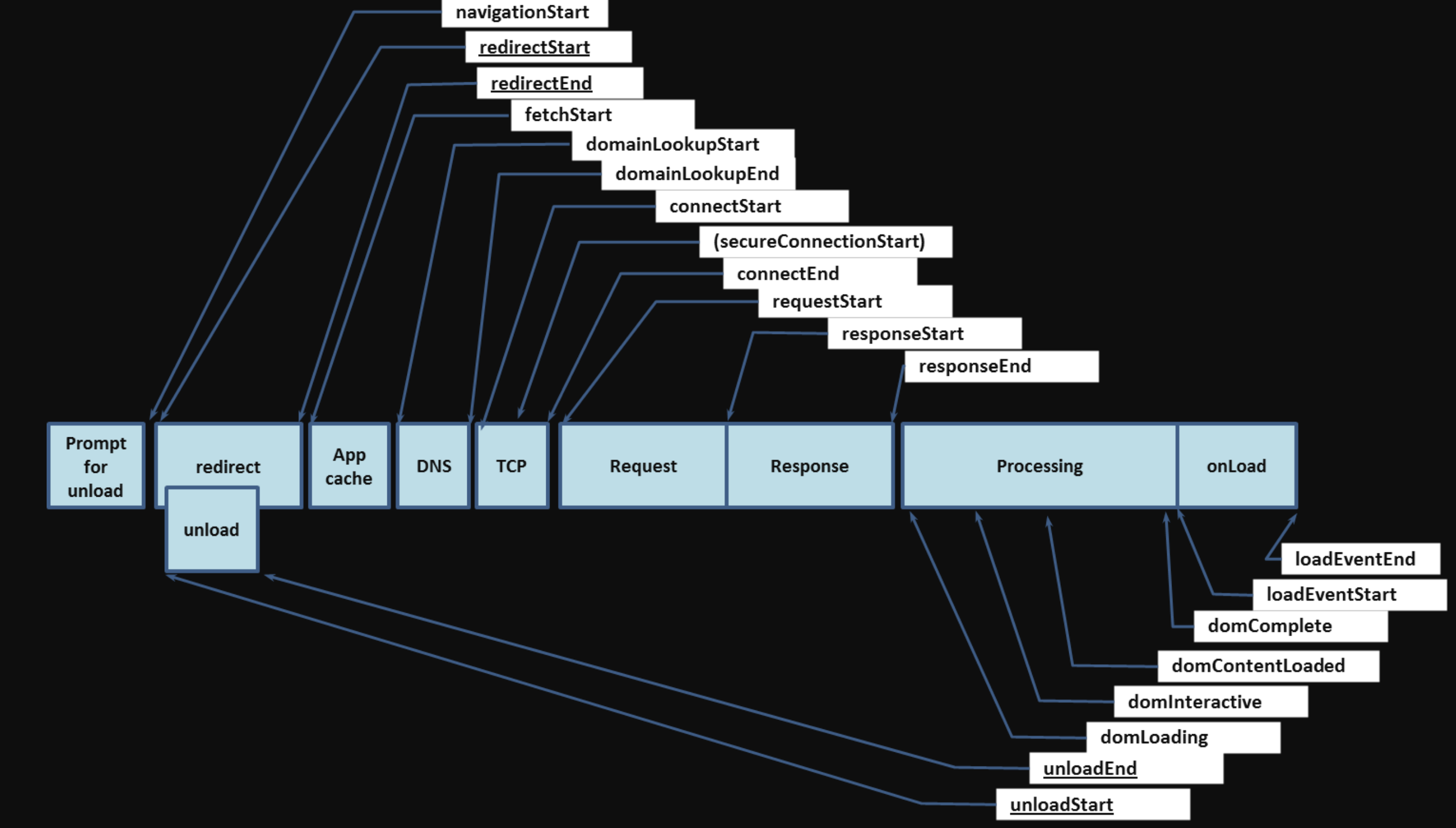
通过求两个时间点之间的差值,我们可以得出某个过程花费的时间,举个🌰:
const timing = window.performance.timing
// DNS查询耗时
timing.domainLookupEnd - timing.domainLookupStart
// TCP连接耗时
timing.connectEnd - timing.connectStart
// 内容加载耗时
timing.responseEnd - timing.requestStart
···
除了这些常见的耗时情况,我们更应该去关注一些关键性能指标:
firstbyte、fpt、tti、ready和load时间。这些指标数据与真实的用户体验息息相关,是我们日常业务性能监测中不可或缺的一部分:
// firstbyte:首包时间
timing.responseStart – timing.domainLookupStart
// fpt:First Paint Time, 首次渲染时间 / 白屏时间
timing.responseEnd – timing.fetchStart
// tti:Time to Interact,首次可交互时间
timing.domInteractive – timing.fetchStart
// ready:HTML 加载完成时间,即 DOM 就位的时间
timing.domContentLoaded – timing.fetchStart
// load:页面完全加载时间
timing.loadEventStart – timing.fetchStart
以上这些通过
Performance API获取到的时间信息都具有较高的准确度。我们可以对此进行一番格式处理之后上报给服务端,也可以基于此去制作相应的统计图表,从而实现更加精准、更加个性化的性能耗时统计。
此外,通过访问 performance 的 memory 属性,我们还可以获取到内存占用相关的数据;通过对 performance 的其它属性方法的灵活运用,我们还可以把它耦合进业务里,实现更加多样化的性能监测需求——灵活,是可编程化方案最大的优点。
# 小结
- 本节我们介绍了
Performance开发者工具、LightHouse与Performance API三种性能监测的方案。只要有Chrome浏览器,我们就可以实现上述的所有操作。 - 由此可以看出,性能监测本身并不难。它的复杂度是在与业务发生耦合的过程中提升的。我们今天打下了坚实的地基,后续需要大家在业务中去成长、去发掘这些工具的更多的潜力,这样才能建立起属于我们自己的技术金字塔。
推荐阅读:
← 2 面试指南