正则表达式是匹配模式,要么匹配字符,要么匹配位置。请记住这句话
# 第一章 正则表达式字符匹配攻略
# 1.1 两种模糊匹配
如果正则只有精确匹配是没多大意义的,比如
/hello/,也只能匹配字符串中的"hello"这个子串
var regex = /hello/;
console.log( regex.test("hello") );
// => true
- 正则表达式之所以强大,是因为其能实现模糊匹配
- 而模糊匹配,有两个方向上的“模糊”:横向模糊和纵向模糊
# 1.1.1 横向模糊匹配
- 横向模糊指的是,一个正则可匹配的字符串的长度不是固定的,可以是多种情况的
- 其实现的方式是使用量词。譬如
{m,n},表示连续出现最少m次,最多n次
比如
/ab{2,5}c/表示匹配这样一个字符串:第一个字符是“a”,接下来是2到5个字符“b”,最后是字符“c”。测试如下
var regex = /ab{2,5}c/g;
var string = "abc abbc abbbc abbbbc abbbbbc abbbbbbc";
console.log( string.match(regex) );
// => ["abbc", "abbbc", "abbbbc", "abbbbbc"]
# 1.1.2 纵向模糊匹配
纵向模糊指的是,一个正则匹配的字符串,具体到某一位字符时,它可以不是某个确定的字符,可以有多种可能
- 其实现的方式是使用字符组。譬如
[abc],表示该字符是可以字符“a”、“b”、“c”中的任何一个
var regex = /a[123]b/g;
var string = "a0b a1b a2b a3b a4b";
console.log( string.match(regex) );
// => ["a1b", "a2b", "a3b"]
只要掌握横向和纵向模糊匹配,就能解决很大部分正则匹配问题
# 1.2 字符组
需要强调的是,虽叫字符组(字符类),但只是其中一个字符。例如
[abc],表示匹配一个字符,它可以是“a”、“b”、“c”之一
# 1.2.1 范围表示法
如果字符组里的字符特别多的话,怎么办?可以使用范围表示法
- 如果字符组里的字符特别多的话,怎么办?可以使用范围表示法
- 比如
[123456abcdefGHIJKLM],可以写成[1-6a-fG-M]。用连字符-来省略和简写 - 因为连字符有特殊用途,那么要匹配“
a”、“-”、“z”这三者中任意一个字符,该怎么做呢? - 不能写成
[a-z],因为其表示小写字符中的任何一个字符。 - 可以写成如下的方式:
[-az]或[az-]或[a\-z]。即要么放在开头,要么放在结尾,要么转义。总之不会让引擎认为是范围表示法就行了
# 1.2.2 排除字符组
- 纵向模糊匹配,还有一种情形就是,某位字符可以是任何东西,但就不能是"
a"、"b"、"c" - 此时就是排除字符组(反义字符组)的概念。例如
[^abc],表示是一个除"a"、"b"、"c"之外的任意一个字符。字符组的第一位放^(脱字符),表示求反的概念
# 1.2.3 常见的简写形式
有了字符组的概念后,一些常见的符号我们也就理解了。因为它们都是系统自带的简写形式
\d就是[0-9]。表示是一位数字。记忆方式:其英文是digit(数字)D就是[^0-9]。表示除数字外的任意字符\w就是[0-9a-zA-Z_]。表示数字、大小写字母和下划线。记忆方式:w是word的简写,也称单词字符。- `W
是[^0-9a-zA-Z_]`。非单词字符 \s是[ \t\v\n\r\f]。表示空白符,包括空格、水平制表符、垂直制表符、换行符、回车符、换页符。记忆方式:s是space character的首字母\S是[^ \t\v\n\r\f]。 非空白符.就是[^\n\r\u2028\u2029]。通配符,表示几乎任意字符。换行符、回车符、行分隔符和段分隔符除外。记忆方式:想想省略号...中的每个点,都可以理解成占位符,表示任何类似的东西
如果要匹配任意字符怎么办?可以使用
[\d\D]、[\w\W]、[\s\S]和[^]中任何的一个。
# 1.3 量词
量词也称重复。掌握
{m,n}的准确含义后,只需要记住一些简写形式
# 1.3.1 简写形式
{m,}表示至少出现m次{m}等价于{m,m},表示出现m次?等价于{0,1},表示出现或者不出现。记忆方式:问号的意思表示,有吗?+等价于{1,},表示出现至少一次。记忆方式:加号是追加的意思,得先有一个,然后才考虑追加*等价于{0,},表示出现任意次,有可能不出现。记忆方式:看看天上的星星,可能一颗没有,可能零散有几颗,可能数也数不过来
# 1.3.2 贪婪匹配和惰性匹配
var regex = /\d{2,5}/g;
var string = "123 1234 12345 123456";
console.log( string.match(regex) );
// => ["123", "1234", "12345", "12345"]
- 其中正则
/\d{2,5}/,表示数字连续出现2到5次。会匹配2位、3位、4位、5位连续数字 - 但是其是贪婪的,它会尽可能多的匹配。你能给我6个,我就要5个。你能给我3个,我就3要个。反正只要在能力范围内,越多越好
- 我们知道有时贪婪不是一件好事(请看文章最后一个例子)。而惰性匹配,就是尽可能少的匹配
var regex = /\d{2,5}?/g;
var string = "123 1234 12345 123456";
console.log( string.match(regex) );
// => ["12", "12", "34", "12", "34", "12", "34", "56"]
其中
/\d{2,5}?/表示,虽然2到5次都行,当2个就够的时候,就不在往下尝试了
- 通过在量词后面加个问号就能实现惰性匹配,因此所有惰性匹配情形如下
{m,n}?
{m,}?
??
+?
*?
.*是贪婪模式.*?是勉强模式
对惰性匹配的记忆方式是:量词后面加个问号,问一问你知足了吗,你很贪婪吗?
# 1.4 多选分支
- 一个模式可以实现横向和纵向模糊匹配。而多选分支可以支持多个子模式任选其一
- 具体形式如下:
(p1|p2|p3),其中p1、p2和p3是子模式,用|(管道符)分隔,表示其中任何之一 - 例如要匹配"
good"和"nice"可以使用/good|nice/。测试如下
var regex = /good|nice/g;
var string = "good idea, nice try.";
console.log( string.match(regex) );
// => ["good", "nice"]
- 但有个事实我们应该注意,比如我用/good|goodbye/,去匹配"goodbye"字符串时,结果是"good":
var regex = /good|goodbye/g;
var string = "goodbye";
console.log( string.match(regex) );
// => ["good"]
- 而把正则改成
/goodbye|good/,结果是
var regex = /goodbye|good/g;
var string = "goodbye";
console.log( string.match(regex) );
// => ["goodbye"]
也就是说,分支结构也是惰性的,即当前面的匹配上了,后面的就不再尝试了
# 1.5 案例分析
匹配字符,无非就是字符组、量词和分支结构的组合使用罢了
# 1.5.1 匹配16进制颜色值
- 要求匹配
#ffbbad
#Fc01DF
#FFF
#ffE
分析
- 表示一个16进制字符,可以用字符组
[0-9a-fA-F] - 其中字符可以出现
3或6次,需要是用量词和分支结构 - 使用分支结构时,需要注意顺序
var regex = /#([0-9a-fA-F]{6}|[0-9a-fA-F]{3})/g;
var string = "#ffbbad #Fc01DF #FFF #ffE";
console.log( string.match(regex) );
// => ["#ffbbad", "#Fc01DF", "#FFF", "#ffE"]
# 1.5.2 匹配时间
要求匹配
- 23:59
- 02:07
分析
- 共4位数字,第一位数字可以为
[0-2] - 当第1位为2时,第2位可以为
[0-3],其他情况时,第2位为[0-9] - 第3位数字为
[0-5],第4位为[0-9]
var regex = /^([01][0-9]|[2][0-3]):[0-5][0-9]$/;
console.log( regex.test("23:59") );
console.log( regex.test("02:07") );
// => true
// => true
如果也要求匹配7:9,也就是说时分前面的0可以省略
var regex = /^(0?[0-9]|1[0-9]|[2][0-3]):(0?[0-9]|[1-5][0-9])$/;
console.log( regex.test("23:59") );
console.log( regex.test("02:07") );
console.log( regex.test("7:9") );
// => true
// => true
// => true
# 1.5.3 匹配日期
比如
yyyy-mm-dd格式为例
要求匹配 2017-06-10
分析
- 年,四位数字即可,可用
[0-9]{4} - 月,共12个月,分两种情况01、02、……、09和10、11、12,可用
(0[1-9]|1[0-2]) - 日,最大31天,可用
(0[1-9]|[12][0-9]|3[01])
var regex = /^[0-9]{4}-(0[1-9]|1[0-2])-(0[1-9]|[12][0-9]|3[01])$/;
console.log( regex.test("2017-06-10") );
// => true
# 1.5.4 window操作系统文件路径
F:\study\javascript\regex\regular expression.pdf
F:\study\javascript\regex\
F:\study\javascript
F:\
分析
- 整体模式是: 盘符:
\文件夹\文件夹\文件夹\ - 其中匹配
F:\,需要使用[a-zA-Z]:\\,其中盘符不区分大小写,注意\字符需要转义 - 文件名或者文件夹名,不能包含一些特殊字符,此时我们需要排除字符组
[^\\:*<>|"?\r\n/]来表示合法字符。另外不能为空名,至少有一个字符,也就是要使用量词+。因此匹配“文件夹\”,可用[^\\:*<>|"?\r\n/]+\\ - 另外“文件夹\”,可以出现任意次。也就是
([^\\:*<>|"?\r\n/]+\\)*。其中括号提供子表达式。 - 路径的最后一部分可以是“文件夹”,没有\,因此需要添加
([^\\:*<>|"?\r\n/]+)?
var regex = /^[a-zA-Z]:\\([^\\:*<>|"?\r\n/]+\\)*([^\\:*<>|"?\r\n/]+)?$/;
console.log( regex.test("F:\\study\\javascript\\regex\\regular expression.pdf") );
console.log( regex.test("F:\\study\\javascript\\regex\\") );
console.log( regex.test("F:\\study\\javascript") );
console.log( regex.test("F:\\") );
// => true
// => true
// => true
// => true
其中,JS中字符串表示\时,也要转义
# 1.5.5 匹配id
要求从
<div id="container" class="main"></div>中提取出id="container"
var regex = /id=".*?"/
var string = '<div id="container" class="main"></div>';
console.log(string.match(regex)[0]);
// => id="container"
小结
掌握字符组和量词就能解决大部分常见的情形,也就是说,当你会了这二者,JS正则算是入门了
# 第二章 正则表达式位置匹配攻略
正则表达式是匹配模式,要么匹配字符,要么匹配位置。请记住这句话
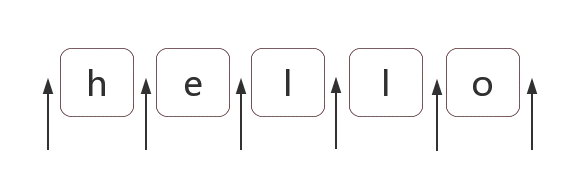
# 2.1 什么是位置
位置是相邻字符之间的位置。比如,下图中箭头所指的地方
# 2.2 如何匹配位置
在ES5中,共有6个锚字符
^ $ \b \B (?=p) (?!p)
# 2.2.1 $和^
^(脱字符)匹配开头,在多行匹配中匹配行开头$(美元符号)匹配结尾,在多行匹配中匹配行结尾
比如我们把字符串的开头和结尾用
"#"替换(位置可以替换成字符的!
var result = "hello".replace(/^|$/g, '#');
console.log(result);
// => "#hello#"
多行匹配模式时,二者是行的概念,这个需要我们的注意
var result = "I\nlove\njavascript".replace(/^|$/gm, '#');
console.log(result);
/*
#I#
#love#
#javascript#
*
# 2.2.2 \b和\B
\b是单词边界,具体就是\w和\W之间的位置,也包括\w和^之间的位置,也包括\w和$之间的位置
- 比如一个文件名是"
[JS] Lesson_01.mp4"中的\b,如下
var result = "[JS] Lesson_01.mp4".replace(/\b/g, '#');
console.log(result);
// => "[#JS#] #Lesson_01#.#mp4#"
# 2.2.3 (?=p)和(?!p)
(?=p),其中p是一个子模式,即p前面的位置- 比如
(?=l),表示'l'字符前面的位置
var result = "hello".replace(/(?=l)/g, '#');
console.log(result);
// => "he#l#lo"
而(
?!p)就是(?=p)的反面意思,比如
var result = "hello".replace(/(?!l)/g, '#');
console.log(result);
// => "#h#ell#o#"
分别是正向先行断言和负向先行断言,具体是(?<=p)和(?<!p)
(?=p)就与^一样好理解,就是p前面的那个位置
# 2.3 位置的特性
- 对于位置的理解,我们可以理解成空字符""
- 比如"hello"字符串等价于如下的形式
"hello" == "" + "h" + "" + "e" + "" + "l" + "" + "l" + "o" + ""
等价于
"hello" == "" + "" + "hello"
因此,把
/^hello$/写成/^^hello$$$/,是没有任何问题的
var result = /^^hello$$$/.test("hello");
console.log(result);
// => true
# 2.4 相关案例
# 2.4.1 不匹配任何东西的正则
/.^/
# 2.4.2 数字的千位分隔符表示法
比如把"12345678",变成"12,345,678"
弄出最后一个逗号
使用
(?=\d{3}$)就可以做到
var result = "12345678".replace(/(?=\d{3}$)/g, ',')
console.log(result);
// => "12345,678"
弄出所有的逗号
因为逗号出现的位置,要求后面3个数字一组,也就是
\d{3}至少出现一次
- 此时可以使用量词
+
var result = "12345678".replace(/(?=(\d{3})+$)/g, ',')
console.log(result);
// => "12,345,678"
匹配其余案例
写完正则后,要多验证几个案例,此时我们会发现问题
var result = "123456789".replace(/(?=(\d{3})+$)/g, ',')
console.log(result);
// => ",123,456,789"
- 因为上面的正则,仅仅表示把从结尾向前数,一但是3的倍数,就把其前面的位置替换成逗号。因此才会出现这个问题
- 我们知道匹配开头可以使用
^,但要求这个位置不是开头怎么办 (?!^),你想到了吗?测试如下
var string1 = "12345678",
string2 = "123456789";
reg = /(?!^)(?=(\d{3})+$)/g;
var result = string1.replace(reg, ',')
console.log(result);
// => "12,345,678"
result = string2.replace(reg, ',');
console.log(result);
// => "123,456,789"
支持其他形式
如果要把"12345678 123456789"替换成"12,345,678 123,456,789"。
- 此时我们需要修改正则,把里面的开头
^和结尾$,替换成\b
var string = "12345678 123456789",
reg = /(?!\b)(?=(\d{3})+\b)/g;
var result = string.replace(reg, ',')
console.log(result);
// => "12,345,678 123,456,789"
- 其中
(?!\b)怎么理解呢? - 要求当前是一个位置,但不是\b前面的位置,其实
(?!\b)说的就是\B - 因此最终正则变成了:
/\B(?=(\d{3})+\b)/g
# 2.4.3 验证密码问题
- 密码长度6-12位,由数字、小写字符和大写字母组成,但必须至少包括2种字符。
- 此题,如果写成多个正则来判断,比较容易。但要写成一个正则就比较困难。
- 那么,我们就来挑战一下。看看我们对位置的理解是否深刻
简化
不考虑“但必须至少包括2种字符”这一条件。我们可以容易写出
var reg = /^[0-9A-Za-z]{6,12}$/;
判断是否包含有某一种字符
假设,要求的必须包含数字,怎么办?此时我们可以使用(
?=.*[0-9])来做
var reg = /(?=.*[0-9])^[0-9A-Za-z]{6,12}$/;
同时包含具体两种字符
- 比如同时包含数字和小写字母,可以用(
?=.*[0-9])(?=.*[a-z])来做
var reg = /(?=.*[0-9])(?=.*[a-z])^[0-9A-Za-z]{6,12}$/;
我们可以把原题变成下列几种情况之一
- 同时包含数字和小写字母
- 同时包含数字和大写字母
- 同时包含小写字母和大写字母
- 同时包含数字、小写字母和大写字母
var reg = /((?=.*[0-9])(?=.*[a-z])|(?=.*[0-9])(?=.*[A-Z])|(?=.*[a-z])(?=.*[A-Z]))^[0-9A-Za-z]{6,12}$/;
console.log( reg.test("1234567") ); // false 全是数字
console.log( reg.test("abcdef") ); // false 全是小写字母
console.log( reg.test("ABCDEFGH") ); // false 全是大写字母
console.log( reg.test("ab23C") ); // false 不足6位
console.log( reg.test("ABCDEF234") ); // true 大写字母和数字
console.log( reg.test("abcdEF234") ); // true 三者都有
解惑
/(?=.*[0-9])^[0-9A-Za-z]{6,12}$/对于这个正则,我们只需要弄明白(?=.*[0-9])^即可- 分开来看就是(
?=.*[0-9])和^ - 表示开头前面还有个位置
- (
?=.*[0-9])表示该位置后面的字符匹配.*[0-9],即,有任何多个任意字符,后面再跟个数字
# 第三章 正则表达式括号的作用
- 括号的作用,其实三言两语就能说明白,括号提供了分组,便于我们引用它。
- 引用某个分组,会有两种情形:在
JavaScript里引用它,在正则表达式里引用它
# 3.1 分组和分支结构
这二者是括号最直觉的作用,也是最原始的功能
# 3.1.1 分组
- 我们知道
/a+/匹配连续出现的“a”,而要匹配连续出现的“ab”时,需要使用/(ab)+/ - 其中括号是提供分组功能,使量词
+作用于“ab”这个整体,测试如下:
var regex = /(ab)+/g;
var string = "ababa abbb ababab";
console.log( string.match(regex) );
// => ["abab", "ab", "ababab"]
# 3.1.2 分支结构
而在多选分支结构(
p1|p2)中,此处括号的作用也是不言而喻的,提供了子表达式的所有可能
I love JavaScript
I love Regular Expression
var regex = /^I love (JavaScript|Regular Expression)$/;
console.log( regex.test("I love JavaScript") );
console.log( regex.test("I love Regular Expression") );
// => true
// => true
- 如果去掉正则中的括号,即
/^I love JavaScript|Regular Expression$/,匹配字符串是"I love JavaScript"和"Regular Expression",当然这不是我们想要的
# 3.2 引用分组
- 这是括号一个重要的作用,有了它,我们就可以进行数据提取,以及更强大的替换操作
- 而要使用它带来的好处,必须配合使用实现环境的API
- 以日期为例。假设格式是
yyyy-mm-dd的,我们可以先写一个简单的正则
var regex = /\d{4}-\d{2}-\d{2}/;
然后再修改成括号版的:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
为什么要使用这个正则呢
提取数据
比如提取出年、月、日,可以这么做
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
console.log( string.match(regex) );
// => ["2017-06-12", "2017", "06", "12", index: 0, input: "2017-06-12"]
match返回的一个数组,第一个元素是整体匹配结果,然后是各个分组(括号里)匹配的内容,然后是匹配下标,最后是输入的文本。(注意:如果正则是否有修饰符g,match返回的数组格式是不一样的)
- 另外也可以使用正则对象的
exec方法
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
console.log( regex.exec(string) );
// => ["2017-06-12", "2017", "06", "12", index: 0, input: "2017-06-12"]
同时,也可以使用构造函数的全局属性
$1至$9来获取
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
regex.test(string); // 正则操作即可,例如
//regex.exec(string);
//string.match(regex);
console.log(RegExp.$1); // "2017"
console.log(RegExp.$2); // "06"
console.log(RegExp.$3); // "12"
替换
想把
yyyy-mm-dd格式,替换成mm/dd/yyyy怎么做
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
var result = string.replace(regex, "$2/$3/$1");
console.log(result);
// => "06/12/2017"
其中replace中的,第二个参数里用
$1、$2、$3指代相应的分组。等价于如下的形式:var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
var result = string.replace(regex, function() {
return RegExp.$2 + "/" + RegExp.$3 + "/" + RegExp.$1;
});
console.log(result);
// => "06/12/2017"
- 也等价于:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
var result = string.replace(regex, function(match, year, month, day) {
return month + "/" + day + "/" + year;
});
console.log(result);
// => "06/12/2017"
# 3.3 反向引用
除了使用相应
API来引用分组,也可以在正则本身里引用分组。但只能引用之前出现的分组,即反向引用。
比如要写一个正则支持匹配如下三种格式
2016-06-12
2016-06-12
2016.06.12
最先可能想到的正则是:
var regex = /\d{4}(-|\/|\.)\d{2}(-|\/|\.)\d{2}/;
var string1 = "2017-06-12";
var string2 = "2017/06/12";
var string3 = "2017.06.12";
var string4 = "2016-06/12";
console.log( regex.test(string1) ); // true
console.log( regex.test(string2) ); // true
console.log( regex.test(string3) ); // true
console.log( regex.test(string4) ); // true
其中/和.需要转义。虽然匹配了要求的情况,但也匹配"2016-06/12"这样的数据
- 假设我们想要求分割符前后一致怎么办?此时需要使用反向引用
var regex = /\d{4}(-|\/|\.)\d{2}\1\d{2}/;
var string1 = "2017-06-12";
var string2 = "2017/06/12";
var string3 = "2017.06.12";
var string4 = "2016-06/12";
console.log( regex.test(string1) ); // true
console.log( regex.test(string2) ); // true
console.log( regex.test(string3) ); // true
console.log( regex.test(string4) ); // false
- 注意里面的
\1,表示的引用之前的那个分组(-|\/|\.)。不管它匹配到什么(比如-),\1都匹配那个同样的具体某个字符 - 我们知道了
\1的含义后,那么\2和\3的概念也就理解了,即分别指代第二个和第三个分组
看到这里,此时,恐怕你会有三个问题
括号嵌套怎么办?
以左括号(开括号)为准。比如:
var regex = /^((\d)(\d(\d)))\1\2\3\4$/;
var string = "1231231233";
console.log( regex.test(string) ); // true
console.log( RegExp.$1 ); // 123
console.log( RegExp.$2 ); // 1
console.log( RegExp.$3 ); // 23
console.log( RegExp.$4 ); // 3
我们可以看看这个正则匹配模式:
- 第一个字符是数字,比如说1,
- 第二个字符是数字,比如说2,
- 第三个字符是数字,比如说3,
- 接下来的是\1,是第一个分组内容,那么看第一个开括号对应的分组是什么,是123,
- 接下来的是\2,找到第2个开括号,对应的分组,匹配的内容是1,
- 接下来的是\3,找到第3个开括号,对应的分组,匹配的内容是23,
- 最后的是\4,找到第3个开括号,对应的分组,匹配的内容是3。
引用不存在的分组会怎样?
因为反向引用,是引用前面的分组,但我们在正则里引用了不存在的分组时,此时正则不会报错,只是匹配反向引用的字符本身。例如\2,就匹配"\2"。注意"\2"表示对"2"进行了转意
var regex = /\1\2\3\4\5\6\7\8\9/;
console.log( regex.test("\1\2\3\4\5\6\7\8\9") );
console.log( "\1\2\3\4\5\6\7\8\9".split("") );
# 3.4 非捕获分组
- 之前文中出现的分组,都会捕获它们匹配到的数据,以便后续引用,因此也称他们是捕获型分组
- 如果只想要括号最原始的功能,但不会引用它,即,既不在API里引用,也不在正则里反向引用。此时可以使用非捕获分组(
?:p),例如本文第一个例子可以修改为:
var regex = /(?:ab)+/g;
var string = "ababa abbb ababab";
console.log( string.match(regex) );
// => ["abab", "ab", "ababab"]
# 3.5 相关案例
至此括号的作用已经讲完了,总结一句话,就是提供了可供我们使用的分组,如何用就看我们的了
# 3.5.1 字符串trim方法模拟
trim方法是去掉字符串的开头和结尾的空白符。有两种思路去做
- 第一种,匹配到开头和结尾的空白符,然后替换成空字符。如
function trim(str) {
return str.replace(/^\s+|\s+$/g, '');
}
console.log( trim(" foobar ") );
// => "foobar"
- 第二种,匹配整个字符串,然后用引用来提取出相应的数据
function trim(str) {
return str.replace(/^\s*(.*?)\s*$/g, "$1");
}
console.log( trim(" foobar ") );
// => "foobar"
这里使用了惰性匹配
*?,不然也会匹配最后一个空格之前的所有空格的
# 3.5.2 将每个单词的首字母转换为大写
function titleize(str) {
return str.toLowerCase().replace(/(?:^|\s)\w/g, function(c) {
return c.toUpperCase();
});
}
console.log( titleize('my name is epeli') );
// => "My Name Is Epeli"
思路是找到每个单词的首字母,当然这里不使用非捕获匹配也是可以的。
# 3.5.3 驼峰化
function camelize(str) {
return str.replace(/[-_\s]+(.)?/g, function(match, c) {
return c ? c.toUpperCase() : '';
});
}
console.log( camelize('-moz-transform') );
// => "MozTransform"
其中分组
(.)表示首字母。单词的界定是,前面的字符可以是多个连字符、下划线以及空白符。正则后面的?的目的,是为了应对str尾部的字符可能不是单词字符,比如str是'-moz-transform '
# 3.5.4 中划线化
驼峰化的逆过程
function dasherize(str) {
return str.replace(/([A-Z])/g, '-$1').replace(/[-_\s]+/g, '-').toLowerCase();
}
console.log( dasherize('MozTransform') );
// => "-moz-transform"
# 3.5.5 html转义和反转义
// 将HTML特殊字符转换成等值的实体
function escapeHTML(str) {
var escapeChars = {
'¢' : 'cent',
'£' : 'pound',
'¥' : 'yen',
'€': 'euro',
'©' :'copy',
'®' : 'reg',
'<' : 'lt',
'>' : 'gt',
'"' : 'quot',
'&' : 'amp',
'\'' : '#39'
};
return str.replace(new RegExp('[' + Object.keys(escapeChars).join('') +']', 'g'), function(match) {
return '&' + escapeChars[match] + ';';
});
}
console.log( escapeHTML('<div>Blah blah blah</div>') );
// => "<div>Blah blah blah</div>";
其中使用了用构造函数生成的正则,然后替换相应的格式就行了
- 倒是它的逆过程,使用了括号,以便提供引用,也很简单
// 实体字符转换为等值的HTML。
function unescapeHTML(str) {
var htmlEntities = {
nbsp: ' ',
cent: '¢',
pound: '£',
yen: '¥',
euro: '€',
copy: '©',
reg: '®',
lt: '<',
gt: '>',
quot: '"',
amp: '&',
apos: '\''
};
return str.replace(/\&([^;]+);/g, function(match, key) {
if (key in htmlEntities) {
return htmlEntities[key];
}
return match;
});
}
console.log( unescapeHTML('<div>Blah blah blah</div>') );
// => "<div>Blah blah blah</div>"
通过key获取相应的分组引用,然后作为对象的键
# 3.5.6 匹配成对标签
要求匹配
<title>regular expression</title>
<p>laoyao bye bye</p>
不匹配
<title>wrong!</p>
- 匹配一个开标签,可以使用正则
<[^>]+>, - 匹配一个闭标签,可以使用
<\/[^>]+>
但是要求匹配成对标签,那就需要使用反向引用,如:
var regex = /<([^>]+)>[\d\D]*<\/\1>/;
var string1 = "<title>regular expression</title>";
var string2 = "<p>laoyao bye bye</p>";
var string3 = "<title>wrong!</p>";
console.log( regex.test(string1) ); // true
console.log( regex.test(string2) ); // true
console.log( regex.test(string3) ); // false
- 其中开标签
<[^>]+>改成<([^>]+)>,使用括号的目的是为了后面使用反向引用,而提供分组。 - 闭标签使用了反向引用
,<\/\1> - 另外
[\d\D]的意思是,这个字符是数字或者不是数字,因此,也就是匹配任意字符的意思
# 第四章 正则表达式回溯法原理
# 4.1 没有回溯的匹配
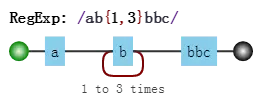
假设我们的正则是
/ab{1,3}c/,其可视化形式是
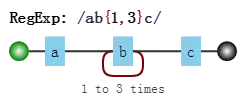
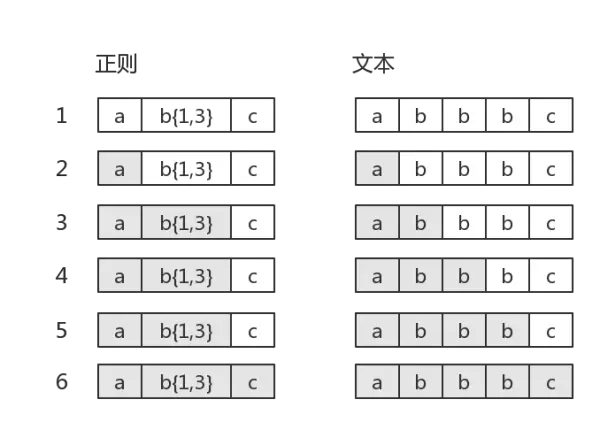
而当目标字符串是"abbbc"时,就没有所谓的“回溯”。其匹配过程是:
其中子表达式
b{1,3}表示“b”字符连续出现1到3次
# 4.2 有回溯的匹配
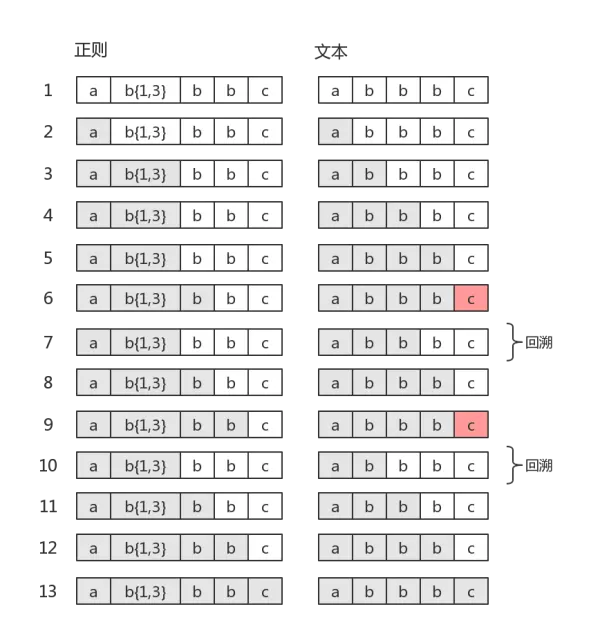
如果目标字符串是"abbc",中间就有回溯
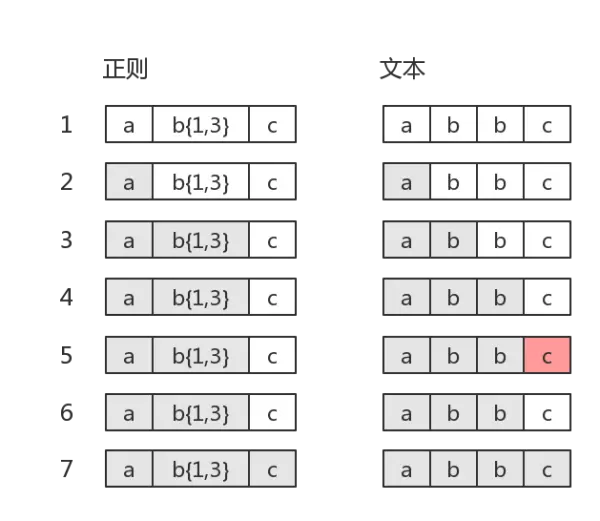
图中第5步有红颜色,表示匹配不成功。此时
b{1,3}已经匹配到了2个字符“b”,准备尝试第三个时,结果发现接下来的字符是“c”。那么就认为b{1,3}就已经匹配完毕。然后状态又回到之前的状态(即第6步,与第4步一样),最后再用子表达式c,去匹配字符“c”。当然,此时整个表达式匹配成功了
- 图中的第6步,就是“回溯”
你可能对此没有感觉,这里我们再举一个例子。正则是
- 目标字符串是:
"acd"ef,匹配过程是
- 图中省略了尝试匹配双引号失败的过程。可以看出.*是非常影响效率的。
- 为了减少一些不必要的回溯,可以把正则修改为
/"[^"]*"/
# 4.3 常见的回溯形式
正则表达式匹配字符串的这种方式,有个学名,叫回溯法
- 回溯法也称试探法,它的基本思想是:从问题的某一种状态(初始状态)出发,搜索从这种状态出发所能达到的所有“状态”,当一条路走到“尽头”的时候(不能再前进),再后退一步或若干步,从另一种可能“状态”出发,继续搜索,直到所有的“路径”(状态)都试探过。这种不断“前进”、不断“回溯”寻找解的方法,就称作“回溯法”
- 本质上就是深度优先搜索算法。其中退到之前的某一步这一过程,我们称为“回溯”。从上面的描述过程中,可以看出,路走不通时,就会发生“回溯”。即,尝试匹配失败时,接下来的一步通常就是回溯
那么JS中正则表达式会产生回溯的地方都有哪些呢
贪婪量词
之前的例子都是贪婪量词相关的。比如
b{1,3},因为其是贪婪的,尝试可能的顺序是从多往少的方向去尝试。首先会尝试"bbb",然后再看整个正则是否能匹配。不能匹配时,吐出一个"b",即在"bb"的基础上,再继续尝试。如果还不行,再吐出一个,再试。如果还不行呢?只能说明匹配失败了。
- 虽然局部匹配是贪婪的,但也要满足整体能正确匹配
- 如果当多个贪婪量词挨着存在,并相互有冲突时,此时会是怎样?
- 答案是,先下手为强!因为深度优先搜索。测试如下:
var string = "12345";
var regex = /(\d{1,3})(\d{1,3})/;
console.log( string.match(regex) );
// => ["12345", "123", "45", index: 0, input: "12345"]
其中,前面的
\d{1,3}匹配的是"123",后面的\d{1,3}匹配的是"45"
惰性量词
惰性量词就是在贪婪量词后面加个问号。表示尽可能少的匹配,比如
var string = "12345";
var regex = /(\d{1,3}?)(\d{1,3})/;
console.log( string.match(regex) );
// => ["1234", "1", "234", index: 0, input: "12345"]
- 其中
\d{1,3}?只匹配到一个字符"1",而后面的\d{1,3}匹配了"234" - 虽然惰性量词不贪,但也会有回溯的现象。比如正则是:
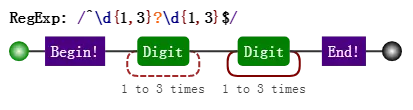
目标字符串是"12345",匹配过程是
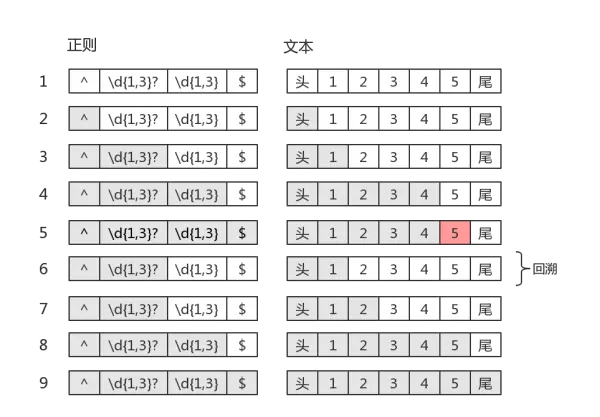
知道你不贪、很知足,但是为了整体匹配成,没办法,也只能给你多塞点了。因此最后
\d{1,3}?匹配的字符是"12",是两个数字,而不是一个
分支结构
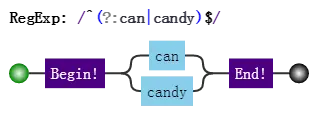
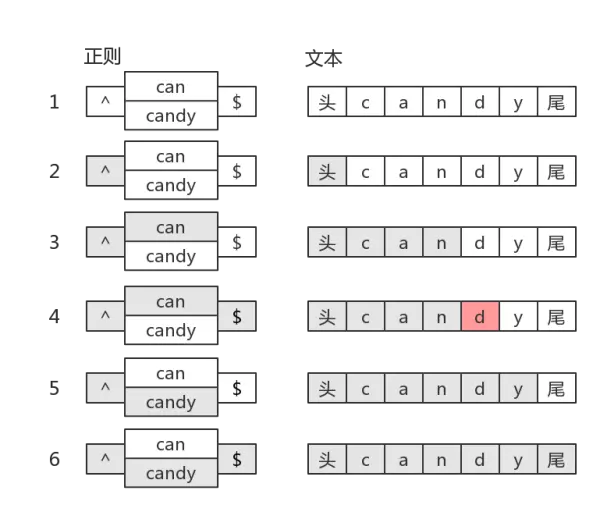
我们知道分支也是惰性的,比如
/can|candy/,去匹配字符串"candy",得到的结果是"can",因为分支会一个一个尝试,如果前面的满足了,后面就不会再试验了。分支结构,可能前面的子模式会形成了局部匹配,如果接下来表达式整体不匹配时,仍会继续尝试剩下的分支。这种尝试也可以看成一种回溯
目标字符串是"candy",匹配过程
小结
简单总结就是,正因为有多种可能,所以要一个一个试。直到,要么到某一步时,整体匹配成功了;要么最后都试完后,发现整体匹配不成功
- 贪婪量词“试”的策略是:买衣服砍价。价钱太高了,便宜点,不行,再便宜点。
- 惰性量词“试”的策略是:卖东西加价。给少了,再多给点行不,还有点少啊,再给点
- 分支结构“试”的策略是:货比三家。这家不行,换一家吧,还不行,再换
# 第五章 正则表达式的拆分
# 5.1 结构和操作符
而在正则表达式中,操作符都体现在结构中,即由特殊字符和普通字符所代表的一个个特殊整体。
JS正则表达式中,都有哪些结构呢?
- 字符字面量、字符组、量词、锚字符、分组、选择分支、反向引用
具体含义简要回顾如下
- 字面量,匹配一个具体字符,包括不用转义的和需要转义的。比如a匹配字符"a",又比如
\n匹配换行符,又比如\.匹配小数点。 - 字符组,匹配一个字符,可以是多种可能之一,比如
[0-9],表示匹配一个数字。也有\d的简写形式。另外还有反义字符组,表示可以是除了特定字符之外任何一个字符,比如[^0-9],表示一个非数字字符,也有\D的简写形式。 - 量词,表示一个字符连续出现,比如
a{1,3}表示“a”字符连续出现3次。另外还有常见的简写形式,比如a+表示“a”字符连续出现至少一次。 - 锚点,匹配一个位置,而不是字符。比如^匹配字符串的开头,又比如\b匹配单词边界,又比如
(?=\d)表示数字前面的位置。 - 分组,用括号表示一个整体,比如
(ab)+,表示"ab"两个字符连续出现多次,也可以使用非捕获分组(?:ab)+。 - 分支,多个子表达式多选一,比如
abc|bcd,表达式匹配"abc"或者"bcd"字符子串。 - 反向引用,比如
\2,表示引用第2个分组
其中涉及到的操作符有
- 转义符
\ - 括号和方括号
(...)、(?:...)、(?=...)、(?!...)、[...] - 量词限定符
{m}、{m,n}、{m,}、?、*、+ - 位置和序列
^、$、\元字符、 一般字符 - 管道符(竖杠)
|
上面操作符的优先级从上至下,由高到低
这里,我们来分析一个正则
/ab?(c|de*)+|fg/
- 由于括号的存在,所以,
(c|de*)是一个整体结构 - 在
(c|de*)中,注意其中的量词*,因此e*是一个整体结构 - 又因为分支结构
“|”优先级最低,因此c是一个整体、而de*是另一个整体 - 同理,整个正则分成了
a、b?、(...)+、f、g。而由于分支的原因,又可以分成ab?(c|de*)+和fg这两部分
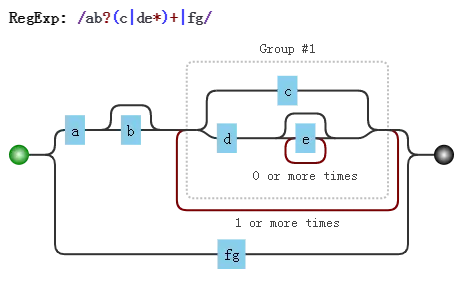
# 5.2 注意要点
匹配字符串整体问题
- 因为是要匹配整个字符串,我们经常会在正则前后中加上锚字符^和$
- 比如要匹配目标字符串
"abc"或者"bcd"时,如果一不小心,就会写成/^abc|bcd$/
量词连缀问题
假设,要匹配这样的字符串
每个字符为a、b、c任选其一
字符串的长度是3的倍数
- 此时正则不能想当然地写成
/^[abc]{3}+$/,这样会报错,说+前面没什么可重复的 - 此时要修改成
/([abc]{3})/
元字符转义问题
- 所谓元字符,就是正则中有特殊含义的字符
- 所有结构里,用到的元字符总结如下
^ $ . * + ? | \ / ( ) [ ] { } = ! : - ,
当匹配上面的字符本身时,可以一律转义
var string = "^$.*+?|\\/[]{}=!:-,";
var regex = /\^\$\.\*\+\?\|\\\/\[\]\{\}\=\!\:\-\,/;
console.log( regex.test(string) );
// => true
- 其中string中的\字符也要转义的
- 另外,在string中,也可以把每个字符转义,当然,转义后的结果仍是本身
var string = "^$.*+?|\\/[]{}=!:-,";
var string2 = "\^\$\.\*\+\?\|\\\/\[\]\{\}\=\!\:\-\,";
console.log( string == string2 );
// => true
字符组中的元字符
跟字符组相关的元字符有
[]、^、-。因此在会引起歧义的地方进行转义。例如开头的^必须转义,不然会把整个字符组,看成反义字符组
var string = "^$.*+?|\\/[]{}=!:-,";
var regex = /[\^$.*+?|\\/\[\]{}=!:\-,]/g;
console.log( string.match(regex) );
// => ["^", "$", ".", "*", "+", "?", "|", "\", "/", "[", "]", "{", "}", "=", "!", ":", "-", ","]
# 5.3 案例分析
身份证
/^(\d{15}|\d{17}[\dxX])$/
因为竖杠“
|”,的优先级最低,所以正则分成了两部分\d{15}和\d{17}[\dxX]
\d{15}表示15位连续数字\d{17}[\dxX]表示17位连续数字,最后一位可以是数字可以大小写字母"x"
** IPV4地址**
/^((0{0,2}\d|0?\d{2}|1\d{2}|2[0-4]\d|25[0-5])\.){3}(0{0,2}\d|0?\d{2}|1\d{2}|2[0-4]\d|25[0-5])$/
得出如下的结构:
((...)\.){3}(...)
上面的两个(...)是一样的结构。表示匹配的是3位数字。因此整个结构是
3位数.3位数.3位数.3位数
然后再来分析(...)
(0{0,2}\d|0?\d{2}|1\d{2}|2[0-4]\d|25[0-5])(0{0,2}\d|0?\d{2}|1\d{2}|2[0-4]\d|25[0-5])
它是一个多选结构,分成5个部分
0{0,2}\d,匹配一位数,包括0补齐的。比如,9、09、009;0?\d{2},匹配两位数,包括0补齐的,也包括一位数;1\d{2},匹配100到199;2[0-4]\d,匹配200-249;25[0-5],匹配250-255。
# 第六章 正则表达式编程
# 6.1 正则表达式的四种操作
# 6.1.1 验证
- 验证是正则表达式最直接的应用,比如表单验证
- 在说验证之前,先要说清楚匹配是什么概念
- 所谓匹配,就是看目标字符串里是否有满足匹配的子串。因此,“匹配”的本质就是“查找”
比如,判断一个字符串中是否有数字
使用search
var regex = /\d/;
var string = "abc123";
console.log( !!~string.search(regex) );
// => true
使用test
var regex = /\d/;
var string = "abc123";
console.log( regex.test(string) );
// => true
使用match
var regex = /\d/;
var string = "abc123";
console.log( !!string.match(regex) );
// => true
使用exec
var regex = /\d/;
var string = "abc123";
console.log( !!regex.exec(string) );
// => true
其中,最常用的是test
# 6.1.2 切分
- 匹配上了,我们就可以进行一些操作,比如切分
- 所谓“切分”,就是把目标字符串,切成一段一段的。在JS中使用的是split
- 比如,目标字符串是"html,css,javascript",按逗号来切分
var regex = /,/;
var string = "html,css,javascript";
console.log( string.split(regex) );
// => ["html", "css", "javascript"]
又比如,如下的日期格式
2017/06/26
2017.06.26
2017-06-26
可以使用split“切出”年月日
var regex = /\D/;
console.log( "2017/06/26".split(regex) );
console.log( "2017.06.26".split(regex) );
console.log( "2017-06-26".split(regex) );
// => ["2017", "06", "26"]
// => ["2017", "06", "26"]
// => ["2017", "06", "26"]
# 6.1.3 提取
- 虽然整体匹配上了,但有时需要提取部分匹配的数据
- 此时正则通常要使用分组引用(分组捕获)功能,还需要配合使用相关API。
这里,还是以日期为例,提取出年月日。注意下面正则中的括号
match
var regex = /^(\d{4})\D(\d{2})\D(\d{2})$/;
var string = "2017-06-26";
console.log( string.match(regex) );
// =>["2017-06-26", "2017", "06", "26", index: 0, input: "2017-06-26"]
exec
var regex = /^(\d{4})\D(\d{2})\D(\d{2})$/;
var string = "2017-06-26";
console.log( regex.exec(string) );
// =>["2017-06-26", "2017", "06", "26", index: 0, input: "2017-06-26"]
test
var regex = /^(\d{4})\D(\d{2})\D(\d{2})$/;
var string = "2017-06-26";
regex.test(string);
console.log( RegExp.$1, RegExp.$2, RegExp.$3 );
// => "2017" "06" "26"
search
var regex = /^(\d{4})\D(\d{2})\D(\d{2})$/;
var string = "2017-06-26";
string.search(regex);
console.log( RegExp.$1, RegExp.$2, RegExp.$3 );
// => "2017" "06" "26"
replace
var regex = /^(\d{4})\D(\d{2})\D(\d{2})$/;
var string = "2017-06-26";
var date = [];
string.replace(regex, function(match, year, month, day) {
date.push(year, month, day);
});
console.log(date);
// => ["2017", "06", "26"]
其中,最常用的是
match
# 6.1.4 替换
找,往往不是目的,通常下一步是为了替换。在JS中,使用replace进行替换
比如把日期格式,从yyyy-mm-dd替换成yyyy/mm/dd:
var string = "2017-06-26";
var today = new Date( string.replace(/-/g, "/") );
console.log( today );
// => Mon Jun 26 2017 00:00:00 GMT+0800 (中国标准时间)
# 6.2 相关API注意要点
从上面可以看出用于正则操作的方法,共有6个,字符串实例4个,正则实例2个
String#search
String#split
String#match
String#replace
RegExp#test
RegExp#exec
search和match的参数问题
- 我们知道字符串实例的那4个方法参数都支持正则和字符串
- 但
search和match,会把字符串转换为正则的
var string = "2017.06.27";
console.log( string.search(".") );
// => 0
//需要修改成下列形式之一
console.log( string.search("\\.") );
console.log( string.search(/\./) );
// => 4
// => 4
console.log( string.match(".") );
// => ["2", index: 0, input: "2017.06.27"]
//需要修改成下列形式之一
console.log( string.match("\\.") );
console.log( string.match(/\./) );
// => [".", index: 4, input: "2017.06.27"]
// => [".", index: 4, input: "2017.06.27"]
console.log( string.split(".") );
// => ["2017", "06", "27"]
console.log( string.replace(".", "/") );
// => "2017/06.27"
match返回结果的格式问题
match返回结果的格式,与正则对象是否有修饰符g有关
var string = "2017.06.27";
var regex1 = /\b(\d+)\b/;
var regex2 = /\b(\d+)\b/g;
console.log( string.match(regex1) );
console.log( string.match(regex2) );
// => ["2017", "2017", index: 0, input: "2017.06.27"]
// => ["2017", "06", "27"]
- 没有g,返回的是标准匹配格式,即,数组的第一个元素是整体匹配的内容,接下来是分组捕获的内容,然后是整体匹配的第一个下标,最后是输入的目标字符串。
- 有g,返回的是所有匹配的内容。
- 当没有匹配时,不管有无g,都返回
null
exec比match更强大
当正则没有
g时,使用match返回的信息比较多。但是有g后,就没有关键的信息index了
- 而
exec方法就能解决这个问题,它能接着上一次匹配后继续匹配
var string = "2017.06.27";
var regex2 = /\b(\d+)\b/g;
console.log( regex2.exec(string) );
console.log( regex2.lastIndex);
console.log( regex2.exec(string) );
console.log( regex2.lastIndex);
console.log( regex2.exec(string) );
console.log( regex2.lastIndex);
console.log( regex2.exec(string) );
console.log( regex2.lastIndex);
// => ["2017", "2017", index: 0, input: "2017.06.27"]
// => 4
// => ["06", "06", index: 5, input: "2017.06.27"]
// => 7
// => ["27", "27", index: 8, input: "2017.06.27"]
// => 10
// => null
// => 0
test整体匹配时需要使用^和$
这个相对容易理解,因为test是看目标字符串中是否有子串匹配正则,即有部分匹配即可
- 如果,要整体匹配,正则前后需要添加开头和结尾
console.log( /123/.test("a123b") );
// => true
console.log( /^123$/.test("a123b") );
// => false
console.log( /^123$/.test("123") );
// => true
split相关注意事项
- split方法看起来不起眼,但要注意的地方有两个的
第一,它可以有第二个参数,表示结果数组的最大长度
var string = "html,css,javascript";
console.log( string.split(/,/, 2) );
// =>["html", "css"]
第二,正则使用分组时,结果数组中是包含分隔符的
var string = "html,css,javascript";
console.log( string.split(/(,)/) );
// =>["html", ",", "css", ",", "javascript"]
replace是很强大的
总体来说replace有两种使用形式,这是因为它的第二个参数,可以是字符串,也可以是函数
当第二个参数是字符串时,如下的字符有特殊的含义
$1,$2,...,$99匹配第1~99个分组里捕获的文本$&匹配到的子串文本- `$`` 匹配到的子串的左边文本
$'匹配到的子串的右边文本$$美元符号
例如,把"2,3,5",变成"5=2+3":
var result = "2,3,5".replace(/(\d+),(\d+),(\d+)/, "$3=$1+$2");
console.log(result);
// => "5=2+3"
当第二个参数是函数时,我们需要注意该回调函数的参数具体是什么
"1234 2345 3456".replace(/(\d)\d{2}(\d)/g, function(match, $1, $2, index, input) {
console.log([match, $1, $2, index, input]);
});
// => ["1234", "1", "4", 0, "1234 2345 3456"]
// => ["2345", "2", "5", 5, "1234 2345 3456"]
// => ["3456", "3", "6", 10, "1234 2345 3456"]
此时我们可以看到
replace拿到的信息,并不比exec少
修饰符
g全局匹配,即找到所有匹配的,单词是globali忽略字母大小写,单词ingoreCasem多行匹配,只影响^和$,二者变成行的概念,即行开头和行结尾。单词是multiline