# 一、请求响应头中关于缓存的奥秘
# 从 HTTP 开始
首先我们了解下 HTTP 的概念:
超文本传输协议(Hyper Text Transfer Protocol,HTTP)是一个简单的请求-响应协议,它通常运行在TCP之上。它指定了客户端可能发送给服务器什么样的消息以及得到什么样的响应。
以上我们不难发现 HTTP 是一种超文本传输协议,HTTP 协议用于客户端和服务端之间的通信(通过请求和响应的交换达成通信),请求必定由客户端发出,而服务端回复响应。
HTTP 请求部分又可以称为前端工程师眼中的 HTTP,它主要发生在客户端,请求是由“报文”的形式发送的,请求报文由三部分组成:请求行、请求报头和请求正文。同样 HTTP 响应部分的响应报文也由三部分组成:状态行、响应报头和响应正文。
这里我们拎出关键与缓存有关的请求报头和响应报头,也正是我们浏览器 Network 面板中常见的 Request Headers 和 Response Headers部分,以 Chrome 为例:
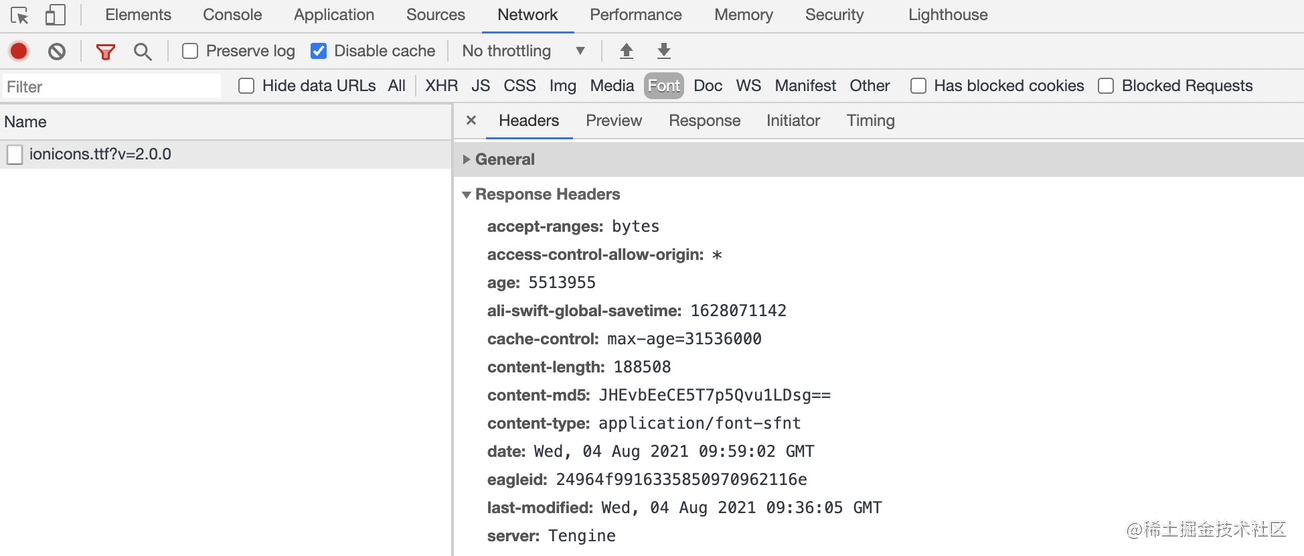
我们可以看到报头是由一系列中间用冒号 “:” 分隔的键值对组成,我们把它称为首部字段,其由首部字段名和字段值构成。如:
Content-Type: text/javascript
以上首部字段名为 Content-Type,首部字段值为 text/javascript,表示报文主体的对象类型。
首部字段又分为四种类型:
- 通用首部字段 (opens new window)(请求报头和响应报头都会用到的首部)
- 请求首部字段 (opens new window)(请求报头用到的首部)
- 响应首部字段 (opens new window)(响应报头用到的首部)
- 实体首部字段 (opens new window)(针对请求报头和响应报头实体部分使用的首部)
那么各类型的首部字段到底包含哪些首部?读者可以点击查阅以上各首部字段对应的 w3 文档进行查阅。比如通用首部字段包含了:
Cache-Control
Connection
Date
Pragma
Trailer
Transfer-Encoding
Upgrade
Via
Warning
与缓存无关的首部字段不在本小册的介绍范围内,下面我们重点介绍与缓存有关的首部字段名,为后续章节储备必要的知识。
# 与缓存有关的首部字段名
开篇我们提到了 HTTP 缓存可以拆解为强缓存和协商缓存,也就是我们需要弄清楚和强缓存、协商缓存有关的首部字段名。为了让读者便于理解和记忆,笔者我使用了以下思维导图的模式来展示:
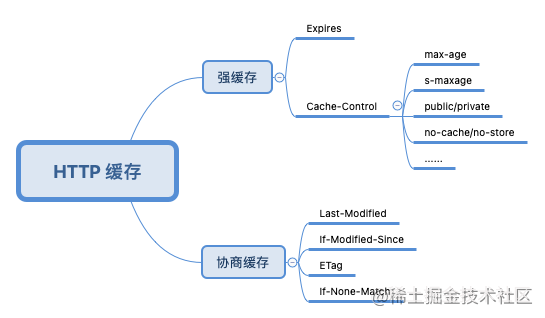
上图中和强缓存有关的首部字段名主要有两个:Expires 和 Cache-Control,我们依次来进行讲解。
Expires
Expires 首部字段是 HTTP/1.0 中定义缓存的字段,其给出了缓存过期的绝对时间,即在此时间之后,响应资源过期,属于实体首部字段。
示例
Expires: Wed, 11 May 2022 03:50:47 GMT
上述示例表示该资源将在以上时间之后过期,而在该时间之前浏览器可以直接从浏览器缓中读取数据,无需再次请求服务器。注意这里无需再次请求服务器便是命中了强缓存。
但是因为 Expires 设置的缓存过期时间是一个绝对时间,所以会受客户端时间的影响而变得不精准。
# Cache-Control
Cache-Control 首部字段是 HTTP/1.1 中定义缓存的字段,其用于控制缓存的行为,可以组合使用多种指令,多个指令之间可以通过 “,” 分隔,属于通用首部字段。常用的指令有:max-age、s-maxage、public/private、no-cache/no store 等。
示例
Cache-Control: max-age:3600, s-maxage=3600, public
Cache-Control: no-cache
max-age 指令给出了缓存过期的相对时间,单位为秒数。当其与 Expires 同时出现时,max-age 的优先级更高。但往往为了做向下兼容,两者都会经常出现在响应首部中。
同时 max-age 还可在请求首部中被使用,告知服务器客户端希望接收一个存在时间(age)不大于多少秒的资源。
而 s-maxage 与 max-age 不同之处在于,其只适用于公共缓存服务器,比如资源从源服务器发出后又被中间的代理服务器接收并缓存。
当使用 s-maxage 指令后,公共缓存服务器将直接忽略 Expires 和 max-age 指令的值。
另外,public 指令表示该资源可以被任何节点缓存(包括客户端和代理服务器),与其行为相反的 private 指令表示该资源只提供给客户端缓存,代理服务器不会进行缓存。同时当设置了 private 指令后 s-maxage 指令将被忽略。
下面再来介绍下 no-cache、no store 指令,需要注意的是这两个指令在请求和响应中都可以使用,两者看上去都代表不缓存,但在响应首部中被使用时, no store 才是真正的不进行任何缓存。
当 no-cache 在请求首部中被使用时,表示告知(代理)服务器不直接使用缓存,要求向源服务器发起请求,而当在响应首部中被返回时,表示客户端可以缓存资源,但每次使用缓存资源前都必须先向服务器确认其有效性,这对每次访问都需要确认身份的应用来说很有用。
当然,我们也可以在代码里加入 meta 标签的方式来修改资源的请求首部:
<meta http-equiv="Cache-Control" content="no-cache" />
至此,我们已经基本了解了强缓存下请求响应的两个主要首部字段,那么顺其自然,我们接着再来看看协商缓存中涉及的主要首部字段名:Last-Modified、If-Modified-Since、Etag、If-None-Match。
# Last-Modified 与 If-Modified-Since
Last-Modified 首部字段顾名思义,代表资源的最后修改时间,其属于响应首部字段。当浏览器第一次接收到服务器返回资源的 Last-Modified 值后,其会把这个值存储起来,并再下次访问该资源时通过携带 If-Modified-Since 请求首部发送给服务器验证该资源有没有过期。
示例
Last-Modified: Fri , 14 May 2021 17:23:13 GMT
If-Modified-Since: Fri , 14 May 2021 17:23:13 GMT
如果在 If-Modified-Since 字段指定的时间之后资源发生了更新,那么服务器会将更新的资源发送给浏览器(状态码200)并返回最新的 Last-Modified 值,浏览器收到资源后会更新缓存的 If-Modified-Since 的值。
如果在 If-Modified-Since 字段指定的时间之后资源都没有发生更新,那么服务器会返回状态码 304 Not Modified 的响应。
# Etag 与 If-None-Match
Etag 首部字段用于代表资源的唯一性标识,服务器会按照指定的规则生成资源的标识,其属于响应首部字段。当资源发生变化时,Etag 的标识也会更新。同样的,当浏览器第一次接收到服务器返回资源的 Etag 值后,其会把这个值存储起来,并在下次访问该资源时通过携带 If-None-Match 请求首部发送给服务器验证该资源有没有过期。
示例
Etag: "29322-09SpAhH3nXWd8KIVqB10hSSz66"
If-None-Match: "29322-09SpAhH3nXWd8KIVqB10hSSz66"
如果服务器发现 If-None-Match 值与 Etag 不一致时,说明服务器上的文件已经被更新,那么服务器会发送更新后的资源给浏览器并返回最新的 Etag 值,浏览器收到资源后会更新缓存的 If-None-Match 的值。
# 二、网页由慢到快背后的强缓存
# 由慢到快的过程
这里,我们模拟第一次打开某宝首页(浏览器未有缓存资源),打开开发者工具我们可以看到资源的加载情况。
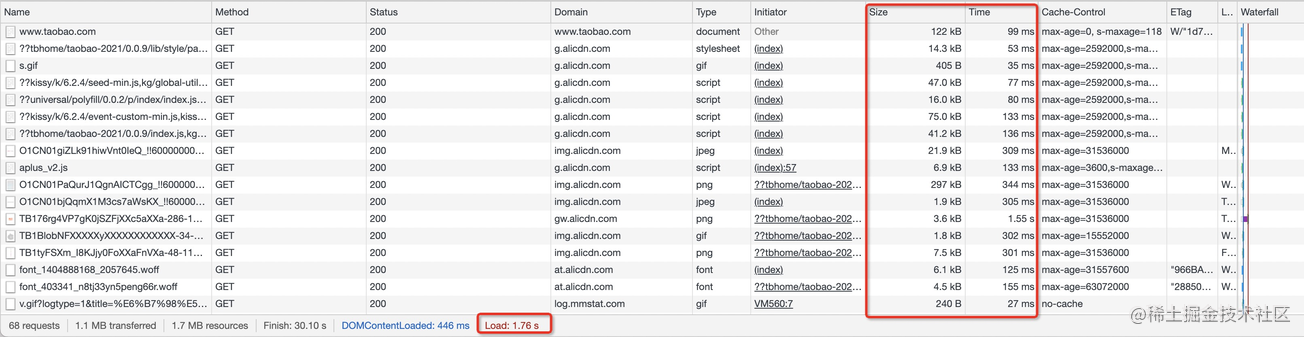
我们重点关注下 Size 和 Time 列的数据,Size 列表示浏览器从服务器获取资源的大小,Time 列表示资源加载耗时。因为几乎每一个资源都需要从服务器获取并加载,所以网页打开速度会受到影响,这里浏览器用了 1.76s 加载完了页面的所有资源(图片、脚本、样式等),1.1 MB 的数据被传输到了本地。
那么从强缓存的角度来看,其实第一次访问网页时浏览器已经开始在背后进行强缓存的判断和处理,我们可以通过下方流程图一探究竟。
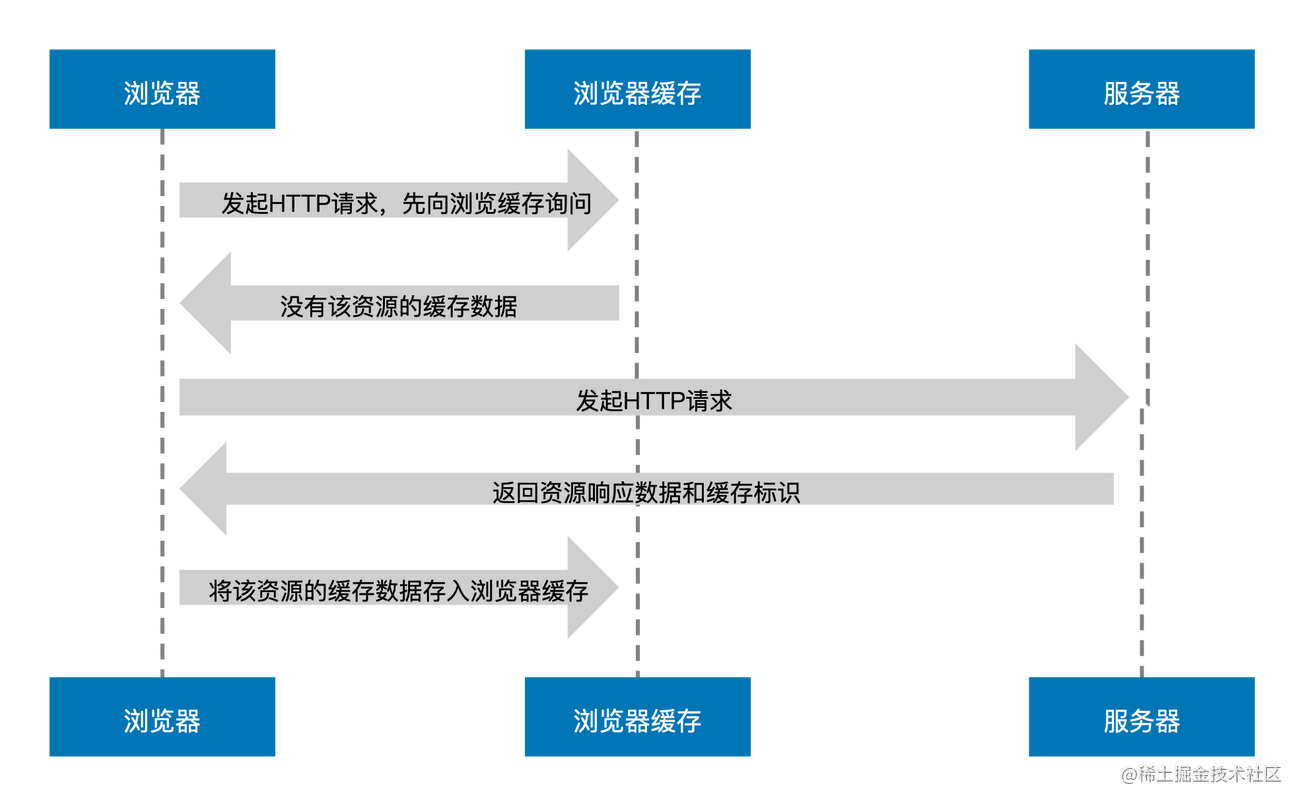
图中,当浏览器发起 HTTP 请求时,会向浏览器缓存进行一次询问,若浏览器缓存没有该资源的缓存数据,那么浏览器便会向服务器发起请求,服务器接收请求后将资源返回给浏览器,浏览器会将资源的响应数据存储到浏览器缓存中,这便是强缓存的生成过程。
接下来,聪明的读者应该已经猜到下面我们将第二次访问某宝,继续观察开发者工具中原来的几项指标。
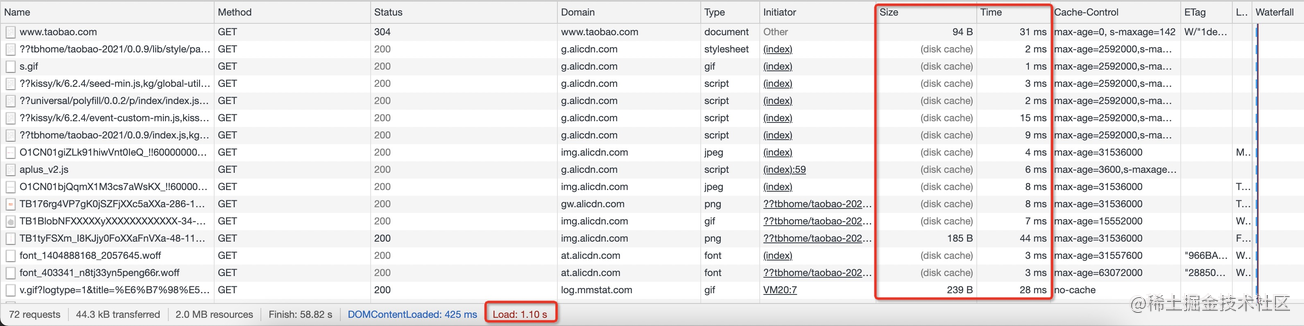
我们发现 Size 一列大部分由原先的资源加载大小变成了 disk cache(磁盘缓存),而变成这一数据对应的 Time 列资源加载速度异常之快,加载总耗时由原来的 1.76s 变成了 1.10s,而传输到本地的数据降到了 44.3 KB,加载速度提升了 37.5%(受网速影响该数据每次都不一样,只用做对比参考)。这便是强缓存生效导致的现象。
强缓存的生效流程如下图所示:
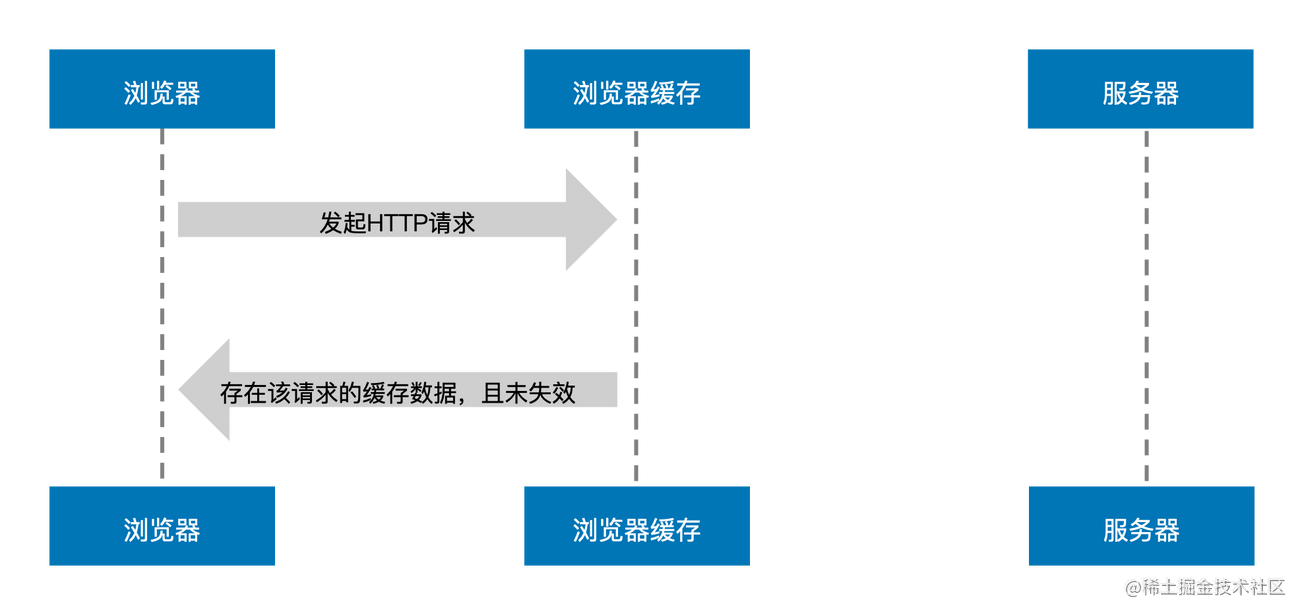
图中我们可以看到浏览器并没有和服务器进行交互,而是在发起请求时浏览器缓存告诉浏览器它那有该资源的缓存数据并且还没有过期,于是浏览器直接加载了缓存中的数据资源。就好比你要买牛奶,原本需要跑去生产厂商买,但是发现楼下的超市就有该厂商生产的牛奶并且没有过期,那你只需要花费跑一趟楼下的功夫就可以喝到新鲜的牛奶,大大缩短了你买牛奶的时间。
写到这里,大家是否会认为只有开发者工具中的 Size 值变成了 disk cache 才代表强缓存生效,也称为命中强缓存。其实不然,别忘了开篇提到除了 Disk cache,还有 Memory Cache(内存缓存)。这时候我们不关闭 Tab 页,重新刷新下某宝页面,再观察下 Network 面板中的变化。
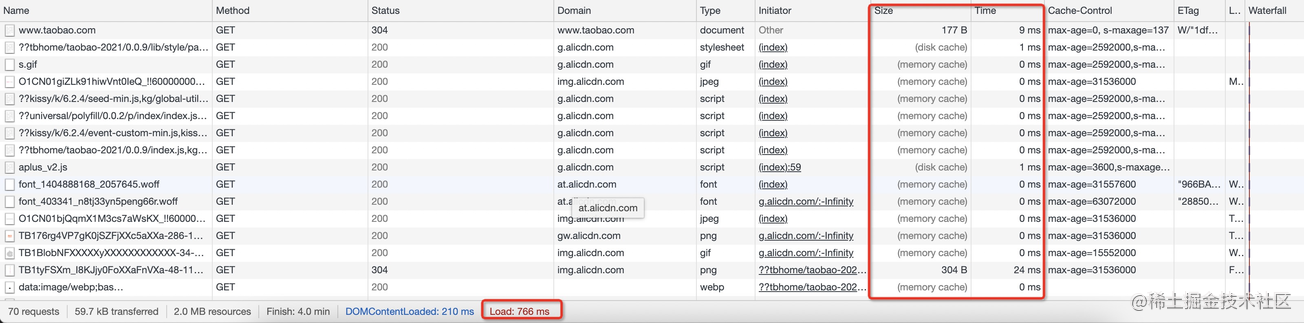
此时,开发者工具中的 Size 列大部分变成了 memory Cache,其对应的 Time 列变成了 0ms。可见,memory Cache 比 disk cache 更快,快到不需要时间。加载总耗时缩短到了 766ms。
按照缓存位置的读取顺序,相比 disk cache,浏览器会优先读取 memory Cache。通过对以上开发者工具图例的对比不难得出,读取磁盘缓存会存在稍许的耗时,而读取内存缓存是及时性的,不存在耗时。
由于 Disk cache 和 Memory Cache 这两者属于浏览器缓存的一部分,本章节不做详细的介绍,大家会在小册浏览器缓存部分与它们见面。
# max-age 与 s-maxage
我们继续来看一下那些被浏览器缓存的资源的特点,响应报头中都包含了与强缓存有关的首部字段:Expires 或 Cache-Control。
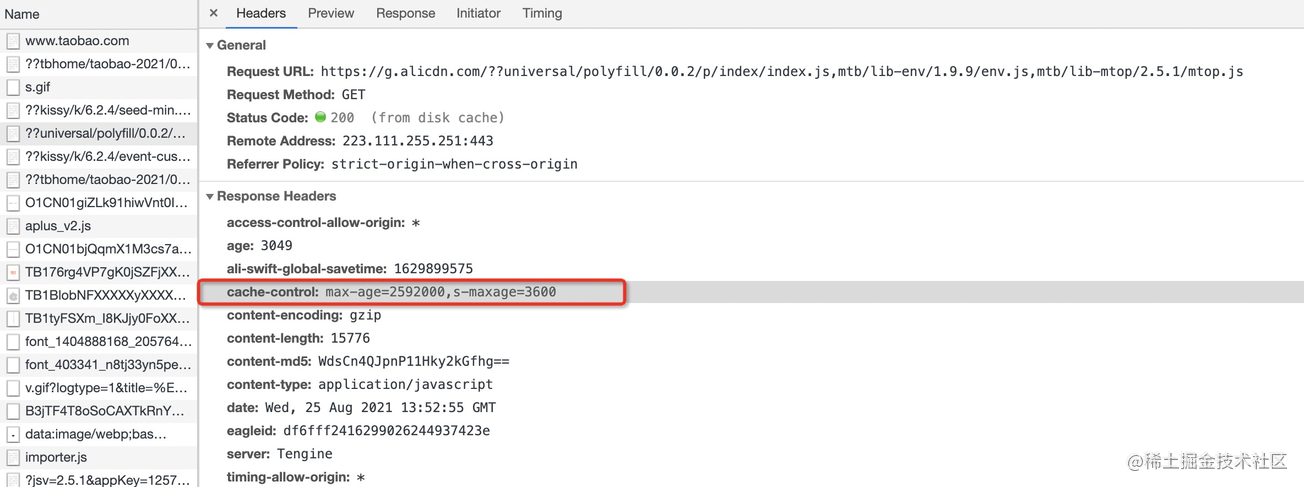
按照上图所示报头的 Cache-Control 首部,根据上一章节介绍的知识点,此资源将被浏览器缓存 2592000 秒(即 30 天),30 天之内我们再次访问,该资源都将从浏览器缓存中读取,这不难理解。但是需要注意图中首部值还包括了 s-maxage=3600 秒,下面便到了划重点的时候:
- s-maxage 仅在代理服务器中生效
- 在代理服务器中 s-maxage 优先级高于 max-age,同时出现时 max-age 会被覆盖
理解完以上两点,我们再来看一下该资源其实是一个 CDN 资源,属于代理服务器资源,在其服务器中的缓存时间并不是 30 天,而是 3600 秒(1 个小时),所以当浏览器缓存 30 天之后重新向 CDN 服务器获取资源时,此时 CDN 缓存的资源也已经过期,会触发回源机制,即向源服务器发起请求更新缓存数据。

以上例子直接描述了 max-age 与 s-maxage 的联系和区别,相信大家多思考下便会轻车熟路。
# expires 与 max-age
上篇介绍到 Expires 设置的缓存过期时间是一个绝对时间,所以会受客户端时间的影响而变得不精准,这句话怎么理解?我们以下图为例来讲解:
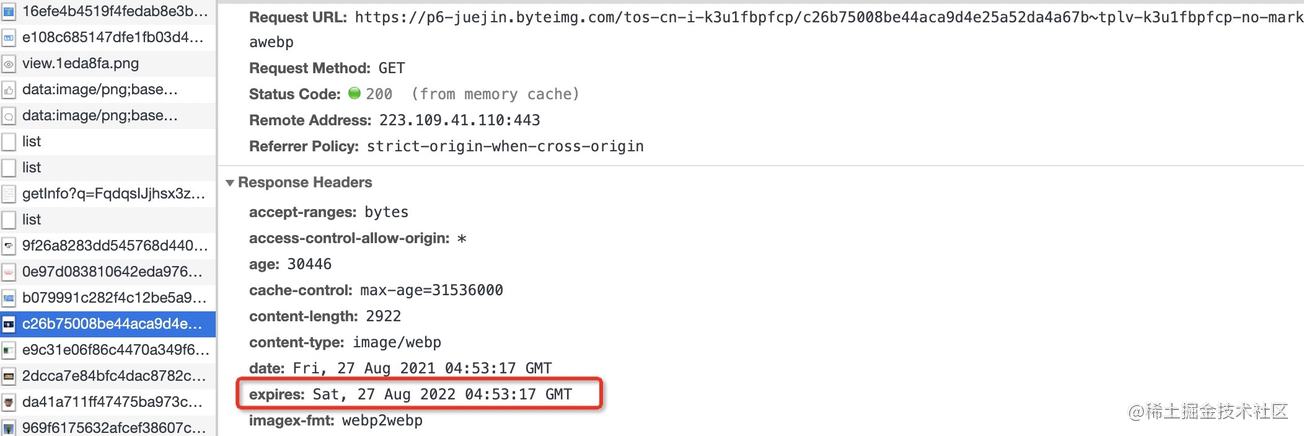
该资源是掘金首页加载的一张图片,已经被笔者浏览器缓存,其首部 expires 字段值表示浏览器可以将该资源缓存至 2022 年 8 月 27 日的上述时间点,那么在我们把图中 max-age 首部当做不存在的情况下(因为 max-age 会覆盖 expires 值),把电脑客户端时间修改为 2022 年 8 月 28 日,此时再次访问网页你会发现浏览器重新向服务器获取了该资源,原来的缓存失效了。这便解释了 expires “不精准”的概念。
expires “不精准” 是因为它的值是一个绝对时间,而 max-age 与其相反却是一个相对时间,还是拿上图举例,由于 max-age 优先级更高,表示浏览器可以将该资源缓存 3153600 秒(365天),起始时间是从浏览器获取并缓存该资源的时间开始算起。那么此时我们修改电脑客户端时间为 1 年后,该缓存是否就不会失效了?
在此笔者先给出答案:缓存还是会失效。
# 三、缓存新鲜度与使用期算法
在我们的日常生活中,每一样食品都有保质期限,在保质期内食用不会对我们的身体健康产生影响,但是一旦存储了过长的时间以致超过了保质期,我们便不能再进行食用,需要丢弃并重新购买,而强缓存亦是如此。
# 从“食品是否新鲜”到“强缓存是否新鲜”
正如与食品保质期一样,强缓存也有着它的“保质期”,我们这里一般称其为“新鲜度”。为了让读者便于理解,笔者这里拿生活中的牛奶来进行举例。
假如你的冰箱里有一瓶牛奶,那么它是否新鲜取决于哪些因素?这里相信大家面对这样的生活常识都能够清楚的知道主要取决于牛奶的保质期和生产日期。比如牛奶的保质期为 6 个月,生产日期为 2021 年 1 月 1日,那么牛奶是否新鲜的计算公式应该是:
牛奶是否新鲜 = 保质期 > (当前日期 - 生产日期)
也就是说,当当前日期减去生产日期超过 6 个月时牛奶便不新鲜了(过期了),不难得出牛奶应该在 2021 年 7 月 1 日前饮用完毕。
我们统一并简化下上述公式,使得所有食品都能公用,上述当前日期 - 生产日期其实就是 使用期,简化后的公式如下:
食品是否新鲜 = 食品保质期 > 食品使用期
那么回归强缓存,上述计算食品是否新鲜的公式同样也适用于强缓存。我们只需要把食品改为强缓存,把食品保质期修改为缓存新鲜度:
强缓存是否新鲜 = 缓存新鲜度 > 缓存使用期
按如上公式所示,强缓存是否新鲜取决于两个关键词:缓存新鲜度和缓存使用期。
# 缓存新鲜度
我们先来认识下什么是缓存新鲜度,其和食品保质期概念大体相同,单位是时间长度。那么在浏览器中强缓存的保质期限怎么计算?
小册前面部分章节介绍强缓存时涉及时间单位的首部字段主要有两个:max-age 和 expires。而缓存的新鲜度公式如下:
缓存新鲜度 = max-age || (expires - date)
上述公式不难理解:当 max-age 存在时缓存新鲜度等于 max-age 的秒数,是一个时间单位,就像保质期为 6 个月一样。当 max-age 不存在时,缓存新鲜度等于 expires - date 的值,expires 我们应该已经熟悉,它是一个绝对时间,表示缓存过期的时间,那么下面主要介绍下首部字段 date。
Date 表示创建报文的日期时间,可以理解为服务器(包含源服务器和代理服务器)返回新资源的时间,和 expires 一样是一个绝对时间,比如
date:Wed, 25 Aug 2021 13:52:55 GMT
那么过期时间(expires)减去创建时间(date)就可以计算出浏览器真实可以缓存的时间(默认已经转化为秒数),即缓存的保质期限(缓存新鲜度)。
至此,以上关于缓存新鲜度的计算公式便介绍完了,大家可以把缓存新鲜度看作是缓存的保质期(即浏览器可以缓存该资源的时间)后其公式便不难理解。
# 缓存使用期
相对于缓存新鲜度,缓存使用期的计算就比较复杂了,涉及到的公式和知识点也会相对较多,根据字面意思,缓存使用期可以理解为浏览器已经使用该资源的时间。相比食品的使用期与当前日期和生产日期有关,缓存使用期主要与响应使用期、传输延迟时间和停留缓存时间有关,计算公式如下:
缓存使用期 = 响应使用期 + 传输延迟时间 + 停留缓存时间
响应使用期
我们先来介绍下响应使用期,响应使用期可以通过以下两种方式进行计算:
- max(0, response_time - date_value)
- age_value
第一种方式中的 response_time(浏览器缓存收到响应的本地时间)是电脑客户端缓存获取到响应的本地时间,而 date_value(响应首部 date 值) 上面已经介绍过是服务器创建报文的时间,两者相减与 0 取最大值。
第二种方式直接获取 age_value (响应首部 age 值),Age 表示推算资源创建经过时间,可以理解为源服务器在多久前创建了响应或在代理服务器中存贮的时长,单位为秒。如下所示:
age:600
以下是 MDN (opens new window) 中的介绍
Age 的值通常接近于 0。表示此对象刚刚从原始服务器获取不久;其他的值则是表示代理服务器当前的系统时间与此应答中的通用头
Date(opens new window) 的值之差。
最终我们可以将以上两种方式进行组合,组合后的计算公式为:
apparent_age = max(0, response_time - date_value)
响应使用期 = max(apparent_age, age_value)
传输延迟时间
因为 HTTP 的传输是耗时的,所以传输延迟时间是存在的,传输延迟时间可以理解为浏览器缓存发起请求到收到响应的时间差,其计算公式为:
传输延迟时间 = response_time - request_time
response_time 代表浏览器缓存收到响应的本地时间,request_time 代表浏览器缓存发起请求的本地时间,两者相减便得到了传输延迟时间。
停留缓存时间
停留缓存时间表示资源在浏览器上已经缓存的时间,其计算公式为:
停留缓存时间 = now - response_time
now 代表电脑客户端的当前时间,response_time 代表浏览器缓存收到响应的本地时间,两者相减便得到了停留缓存时间。
max-age 仍然受到本地时间影响揭秘
通过上述字段及公式的介绍,最终我们总结出影响强缓存使用期的因素有以下几个:
age_value:响应首部 age 值
date_value:响应首部 date 值
request_time:浏览器缓存发起请求的本地时间
response_time:浏览器缓存收到响应的本地时间
now:客户端当前时间
需要注意的是以上 request_time、response_time 和 now 取的都是客户端本地时间,而 now 则是修改客户端本地时间直接导致强缓存失效的“罪魁祸首”。
因此一旦修改了电脑客户端本地时间为未来时间,缓存使用期的计算便会受到影响,主要是停留缓存时间会变大,从而导致缓存使用期超出缓存新鲜度范围(强缓存失效)。 这便是 max-age 仍然受到本地时间影响的原因所在。
# 四、从协商缓存到启发式缓存
协商缓存可以看作是强制缓存失效后,浏览器携带缓存标识向服务器发起请求,由服务器根据缓存标识决定是否使用缓存的过程。
由此可知,浏览器启用协商缓存的前提是强缓存失效,但是反过来强缓存失效并不一定导致浏览器启用协商缓存。下面我们来了解下协商缓存的生效流程。
# 协商缓存的生效流程
为了让大家更容易理解,笔者还是用流程图的方式来进行介绍,如下图所示:
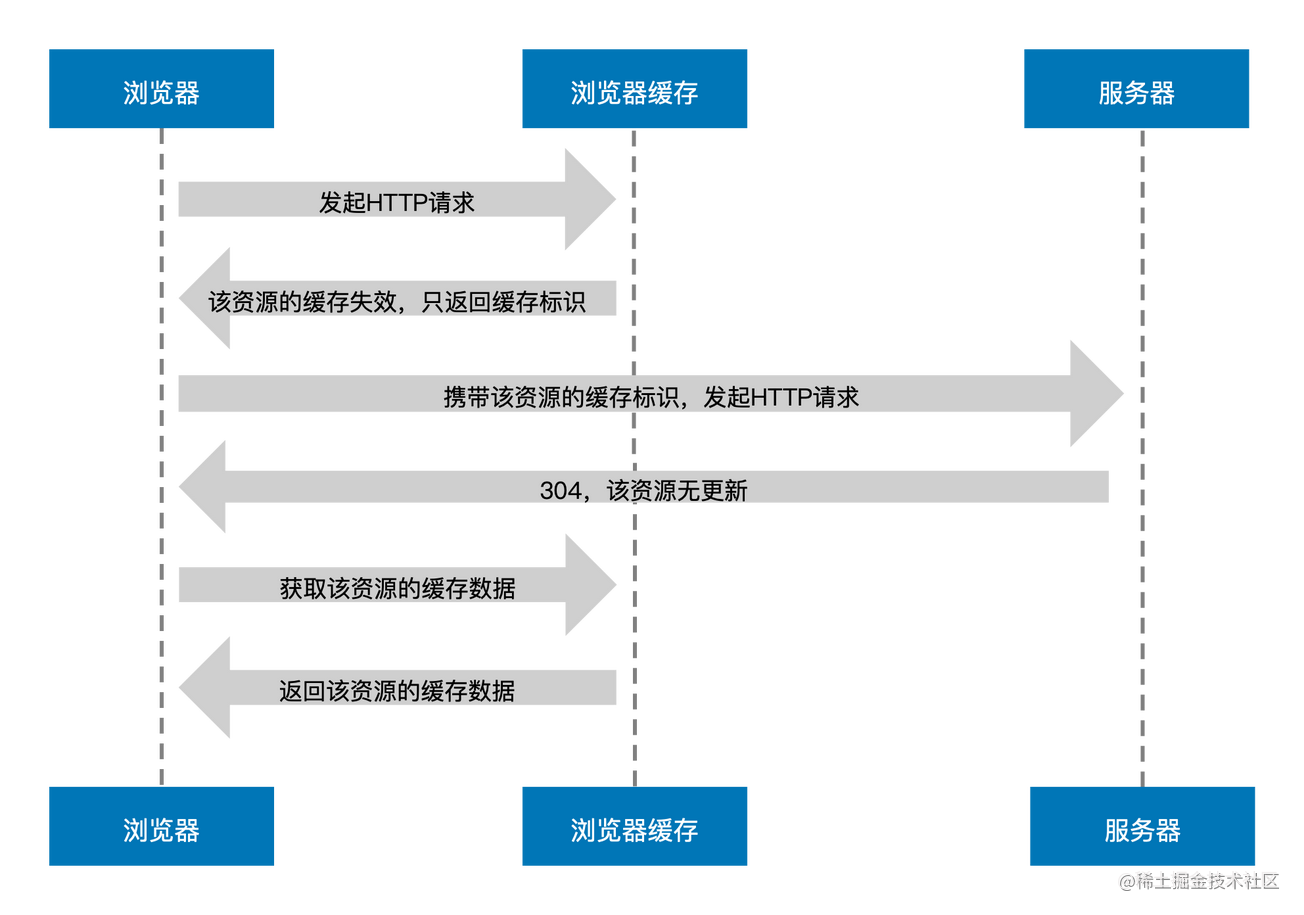
图中,我们先经历了一段强缓存的失效流程:浏览器发起 HTTP 请求后浏览器缓存发现该请求的资源失效,便将其缓存标识返回给浏览器,于是浏览器携带该缓存标识向服务器发起 HTTP 请求,之后服务器根据该标识判断这个资源其实没有更新过,最终返回 304 给浏览器,浏览器收到无更新的响应后便转向浏览器缓存获取数据。
以上步骤阐述了关于协商缓存生效的流程,其经历了一次浏览器与服务器协商的过程,并最终返回 304 未更新来达到读取缓存的目的,我们可以通过下方更为生动的对话来理解协商缓存不同流程间的关系:
小白:小黑,你几岁了?
小黑:小白,我18岁了。
- - - - - - - - - - - - - - - - - - - - - - - -
小白:小黑 ,你几岁了?我猜你18岁了。
小黑:靠,你知道还问我?(304)
- - - - - - - - - - - - - - - - - - - - - - - -
小白:小黑 ,你几岁了?我猜你18岁了。
小黑:小白 ,我19岁了。(200)
从上至下小白与小黑的对话分别代表了浏览器与服务器间进行第一次数据请求、协商缓存生效及协商缓存失效的过程。
# 缓存标识 Last-Modified 与 ETag
除了强缓存失效外,浏览器判断是否要走协商缓存还得借助上述提到的缓存标识:last-modified、eTag,这两个首部字段我们在前面章节已经有所介绍,它们是服务器响应请求时返回的报头首部,如下图所示:
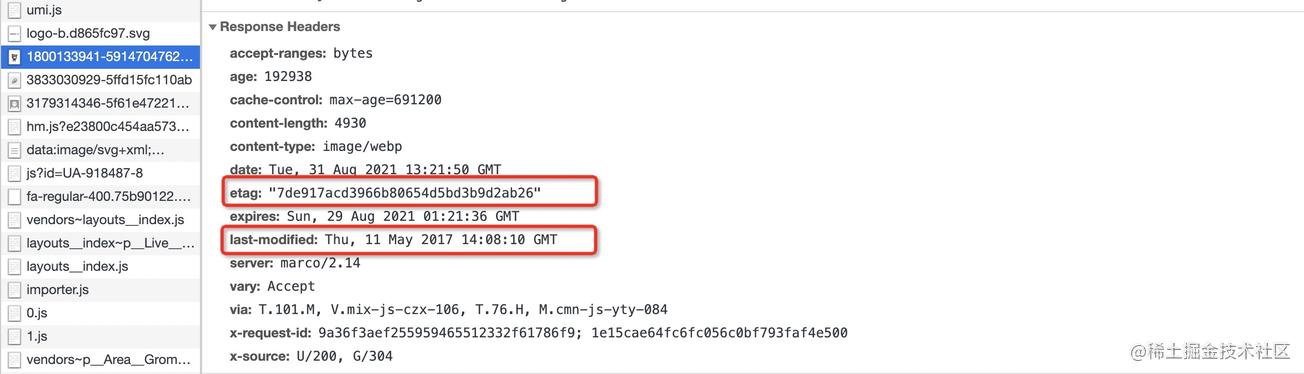
eTag 的优先级要高于 last-modified,当两者同时出现时,只有 eTag 会生效。只要有这两个缓存标识之一,在强缓存失效后浏览器便会携带它们向服务器发起请求,携带方式如下图请求头所示:

其中 if-modified-since 对应 last-modified 的值,if-none-match 对应 eTag 的值。服务器根据优先级高的缓存标识的值进行判断。
倘若 eTag 对应的 if-none-match 不存在,那么服务器会将 last-modified 对应的 if-modified-since 的时间值与服务器该资源的最后修改时间进行对比,最后判断是否走协商缓存。
那么 last-modified 有会什么弊端?服务器进行对比时一定精准吗?
last-modified 是一个时间,最小单位为秒,试想一下,如果资源的修改时间非常快,快到毫秒级别,那么服务器会误认为该资源仍然是没有修改的,这便导致了资源无法在浏览器及时更新的现象。
另外还有一种情况,比如服务器资源确实被编辑了,但是其实资源的实质内容并没有被修改,那么服务器还是会返回最新的 last-modified 时间值,但是我们并不希望浏览器认为这个资源被修改而重新加载。
为了避免以上现象的发生,在特殊的场景下,我们便需要使用 eTag。
# ETag 原理及实现
那么相比 last-modified,eTag 到底有什么优势?回答这个问题前我们需要去了解 eTag 值的生成原理,而不同的后端语言对 eTag 有着多种处理方式,这里笔者将以 node 中下载量领先的 etag (opens new window) 包为例进行介绍。
eTag 包的源码十分简洁明了,其生成 eTag 值的方式有两种,第一种方式:使用文件大小和修改时间。

图中当判断所要处理的内容是文件 stats 对象时,将会采用上述方法生成 eTag 值,最后返回的值是由文件大小和文件最后一次修改时间组成的字符串。
而当内容非文件 stats 对象时,将采用第二种方式:使用文件内容的 hash 值和内容长度。
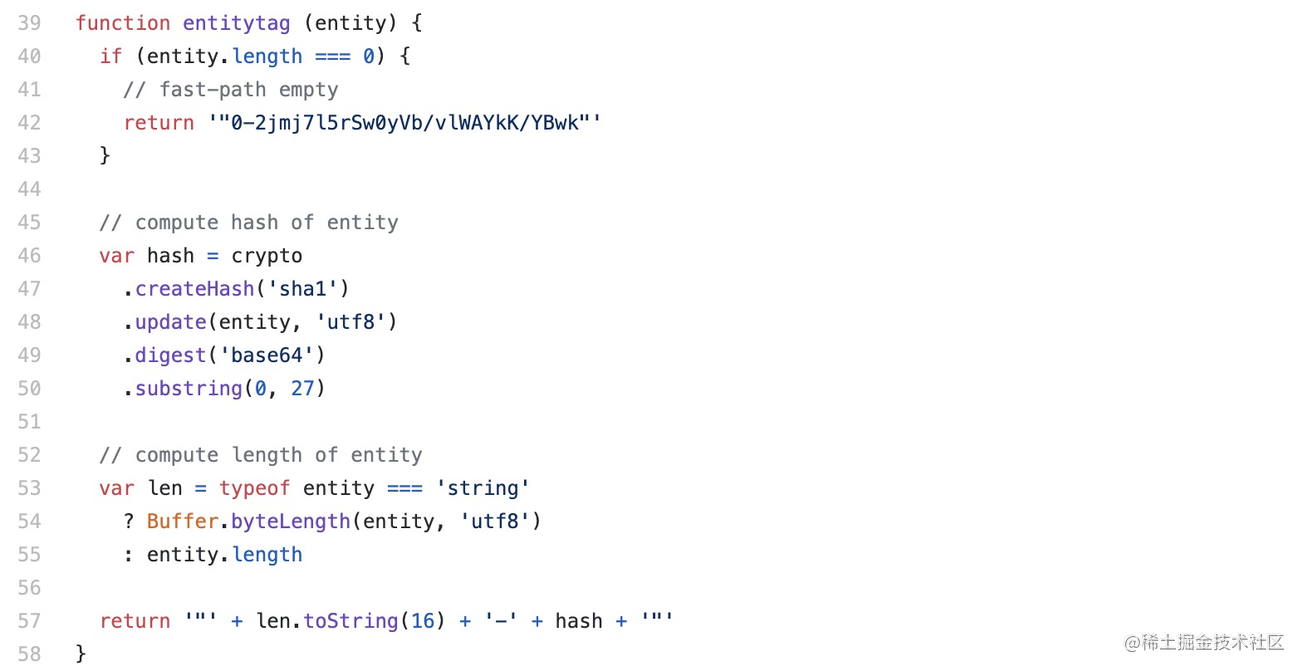
图中方法通过对内容的 hash 转化和截取,最终返回内容长度与其 hash 值组合成的字符串。
通过上述方法生成的 eTag 也被称为强 eTag 值,其不论实体发生多么细微的变化都会改变它的值。那么与其对立的便是弱 eTag 值,在 eTag 包源码中我们可以发现通过传递第二个参数 weak 值为 true 时便可启用弱校验。
弱 ETag 值只适用于提示资源是否相同。只有资源发生了根本改变,产生差异时才会改变 ETag 值。这时会在字段值最开始处附加 W/。
ETag: W/"29322-09SpAhH3nXWd8KIVqB10hSSz66"
最终我们通过针对 eTag 原理及实现的分析,不难发现使用 eTag 服务器能够更加精准的分析资源的改变,同时浏览器也便能更加精准的控制缓存。
# 启发式缓存
在强缓存的介绍章节中,我们提到计算强缓存新鲜度的公式为:缓存新鲜度 = max-age || (expires - date)。
那么大家有没有想过如果响应报头中没有 max-age(s-maxage) 和 expires 这两个关键的字段值时,强缓存的新鲜度如何计算?
有读者可能会疑惑没有了强缓存的必要字段值,浏览器还会走强缓存吗?答案是肯定的。比如下方的响应报头:
date: Thu, 02 Sep 2021 13:28:56 GMT
age: 10467792
cache-control: public
last-modified: Mon, 26 Apr 2021 09:56:06 GMT
以上报头中没有用来确定强缓存过期时间的字段,这便无法使用上面提到的缓存新鲜度公式,虽然有与协商缓存相关的 last-modified 首部,但并不会走协商缓存,反而浏览器会触发启发式缓存。启发式缓存对于缓存新鲜度计算公式如下所示:
缓存新鲜度 = max(0,(date - last-modified)) * 10%
根据响应报头中 date 与 last-modified 值之差与 0 取最大值后取其值的百分之十作为缓存时间。
启发式缓存比较容易被忽视,不了解启发式缓存的读者可能会因为这种默认的缓存模式而掉入坑里,百思不得其解,但是一旦你了解了浏览器触发启发式缓存的机制,那么很多缓存问题便会迎刃而解。
最后,笔者继续抛出一个问题:如果连 last-modified 都没有,缓存新鲜度为多少?
这种情况其实非常少见,因为一个合理的资源必定是有合理的缓存首部的,但是万一服务器真的没有配置和返回怎么办,这个问题留给大家去思考下。
# 五、HTTP 缓存方案解析
# 前端应用中的 HTTP 缓存方案
目前最流行的前端框架比如 Vue、React 等都以单页应用(SPA)的开发模式著称,关于单页应用的概念相信大家已经烂熟于心,所谓单页指的是应用由一个 HTML 文件组成,页面之间的跳转通过异步加载 JS 等资源文件的形式进行渲染,比如某宝 network 面板加载资源的形式:

当我们访问首页时,浏览器率先加载的便是 HTML 文件,后续继续加载一些首页渲染需要以及公共的资源文件,当我们跳转页面时会异步加载下一个页面所需的资源,实现页面的组装及逻辑处理。
上图中我们观察仔细的读者会发现,刷新页面或再次访问时大部分资源都命中了强缓存,唯独率先加载的 HTML 资源走了协商缓存,这是为什么?
当你吃透了 HTTP 缓存的相关知识点后,原因其实很容易解释,因为像 JS、CSS 等资源经过像 webpack 这样的打包工具打包后可以自动生成 hash 文件名,每次部署到服务器上后发生变化的资源 hash 名会更新,浏览器会当作一个新的资源去向服务器请求,没有更新的资源便会优先读取浏览器缓存。
而 HTML 不同,其文件名不会改变,我们期望浏览器每次加载时都应该向服务器询问是否更新,否则会出现新版本发布后浏览器读取缓存 HTML 文件导致页面空白报错(旧资源被删除)或应用没有更新(读取了旧资源)的问题。
根据 HTTP 缓存的规则最终我们便可以总结出如下缓存方案:
- 频繁变动的资源,比如 HTML, 采用协商缓存
- CSS、JS、图片资源等采用强缓存,使用 hash 命名
以上缓存方案也解释了在单页应用出现之前的一种现象,比如 jQuery 时代我们的资源文件一般通过在 HTML 中直接引入的方式来进行加载,同时会加上一段时间戳或者版本号代码:
<script src="./js/demo.js?ver=1.0"></script>
因为浏览器会缓存之前的 JS、CSS 版本,通过上述添加类似于 hash 值的方式能够让浏览器加载我们最新的版本。
那么关于如何让 HTML 文件走协商缓存,前提得先让浏览器强缓存失效,可以设置如下服务器响应报头:
Cache-Control: max-age=0
Last-Modified: Sat, 04 Sep 2021 08:59:40 GMT
在资源 0 秒就失效的情况下存在协商缓存触发条件的 Last-Modified 标识,这样每次访问加载的 HTML 资源就会确保是最新的,解决了 HTML 怕被浏览器强缓存的烦恼。
# Webpack 中的 Hash 模式
通过上述介绍的前端应用中 HTTP 缓存方案,我们从中了解了资源 hash 命名的重要性。然而这里所谓的 “hash” 其实是一个统称,在 webpack 中 hash 可以分为三种类型:hash、chunkhash、contenthash,每一种类型 hash 的生成规则和作用也不同。正因为 hash 存在着上述的几种类型,所以它的使用也是有讲究的,下面笔者将依次给大家进行介绍。
hash
hash 属于项目级别的 hash,意思就是整个项目中只要有文件改变该 hash 值就会变化,同时所有文件也都共用该 hash 值。
webpack 的简单配置如下:
module.exports = {
output: {
path: config.build.assetsRoot,
filename: utils.assetsPath('js/[name].[hash:8].js'),
chunkFilename: utils.assetsPath('js/[name].[hash:8].min.js'),
},
plugins:[
// 将 js 中引入的 css 进行分离
new ExtractTextPlugin({ filename: utils.assetsPath('css/[name].[hash:8].css'), allChunks: true }),
]
}
最终打包输出的资源文件名 hash 值都一样,按照缓存策略进行分析,浏览器加载所有资源都将重新请求服务器,导致没有改动资源的加载浪费,因此不建议在项目中采用这种方式进行构建。
# chunkhash
chunkhash 与 hash 不同,其属于入口文件级别的 hash,会根据入口文件(entry)的依赖进行打包,同时为了避免一些公共库、插件被打包至入口文件中,我们可以借助 CommonsChunkPlugin 插件进行公共模块的提取:
module.exports = {
entry: utils.getEntries(),
output: {
path: config.build.assetsRoot,
filename: utils.assetsPath('js/[name].[chunkhash:8].js'),
chunkFilename: utils.assetsPath('js/[name].[chunkhash:8].min.js'),
},
plugins:[
// 将 js 中引入的 css 进行分离
new ExtractTextPlugin({ filename: utils.assetsPath('css/[name].[chunkhash:8].css') }),
// 分离公共 js 到 vendor 中
new webpack.optimize.CommonsChunkPlugin({
name: 'vendor', //文件名
minChunks: function(module, count) {
// 声明公共的模块来自 node_modules 文件夹,把 node_modules、common 文件夹以及使用了2次依赖的都抽出来
return (
module.resource &&
(/\.js$/.test(module.resource) || /\.vue$/.test(module.resource)) &&
(module.resource.indexOf(path.join(__dirname, '../node_modules')) === 0 || module.resource.indexOf(path.join(__dirname, '../src/common')) === 0 || count >= 2)
);
}
}),
// 将运行时代码提取到单独的 manifest 文件中,防止其影响 vendor.js
new webpack.optimize.CommonsChunkPlugin({
name: 'runtime',
chunks: ['vendor']
})
]
}
上述配置我们将需要抽离的公共模块提取到了 vendor.js 中,同时也将 webpack 运行文件提取到了 runtime.js 中,这些公共模块一般除了升级版本外永远不会改动,我们希望浏览器能够将其存入强缓存中,不受其他业务模块的修改导致文件 chunkhash 名称变动的影响。
最终我们打包出的模块拥有不同的 chunkhash 名称,重新打包只会影响有变动的模块重新生成 chunkhash,这里大家先重点关注下 home.js 文件。

# contenthash
contenthash 是属于文件内容级别的 hash,其会根据文件内容的变化而变化,一般用于解决以下问题:
比如上方的 home.js 中单独引入了 home.css 文件,那么当 js 文件被修改后,就算 css 文件并没有被修改,由于该模块发生了改变,同样会导致 css 文件也被重复构建。此时,针对 css 使用 contenthash 后,只要其内容不变就不会被重复构建。
module.exports = {
output: {
path: config.build.assetsRoot,
filename: utils.assetsPath('js/[name].[chunkhash:8].js'),
chunkFilename: utils.assetsPath('js/[name].[chunkhash:8].min.js'),
},
plugins:[
// 将 js 中引入的 css 进行分离,使用 contenthash 判断内容的改变
new ExtractTextPlugin({ filename: utils.assetsPath('css/[name].[contenthash:8].css'), allChunks: true }),
]
}
最终构建出的 css 文件拥有了其自己的 contenthash 值:

tips:当在 module 中使用 loader 设置图片或者字体的文件名时,如包含 hash 或 chunkhash 都是不生效的,默认会使用 contenthash。
module.exports = {
module: {
rules: [{
test: /\.(png|jpe?g|gif|svg)(\?.*)?$/,
loader: 'url-loader',
options: {
limit: 5,
name: utils.assetsPath('img/[name].[hash:8].[ext]') // 设置的 hash 值不会生效
}
},
{
test: /\.(woff2?|eot|ttf|otf)(\?.*)?$/,
loader: 'url-loader',
options: {
limit: 2,
name: utils.assetsPath('fonts/[name].[hash:8].[ext]') // 设置的 hash 值不会生效
}
}]
}
}
经过一番推敲,回归 HTTP 缓存,上述的 3 种 hash 模式如何使用想必大家心里已经有了答案:将 chunkhash 和 contenthash 组合使用才能最大化的利用 HTTP 缓存中强缓存的优势,减少不必要的资源重复请求,提升网页的整体打开速度。
# 六、用户操作与 HTTP 缓存
作为一名 Web 程序开发人员,我们脱离不了对浏览器的使用,在开发过程中时常需要刷新网页、清理浏览器缓存、打开控制台调试等等,即便作为一名普通的用户,其也离不开对浏览器的依赖,经常需要在浏览器地址栏输入对应的网址进行“网上冲浪”。
上述种种行为其实换一种角度来看,都可以和缓存有关,在认清上述行为与缓存的关系之前,我们有必要先吃透行为的载体——浏览器(以 Chrome 为例)。
# Chrome 的三种加载模式
Chrome 具备三种加载模式,除了通过快捷键的方式触发,这三种模式只在开发者工具打开时才能够使用,此时我们打开开发者工具,在浏览器刷新按钮上右键鼠标便会展示这几种模式,如下图所示:
下面我们依次来进行介绍这三种模式:
模式一:正常重新加载
// 快捷键
Mac: Command + R
Windows: Ctrl + R(等同于直接按 F5)
正常重新加载这种模式对于浏览器的用户来说都很熟悉,也是我们常说的“刷新网页”,和直接点击浏览器上的刷新按钮效果一样,用户触发该模式在控制台可以看到大多数资源会命中强缓存:
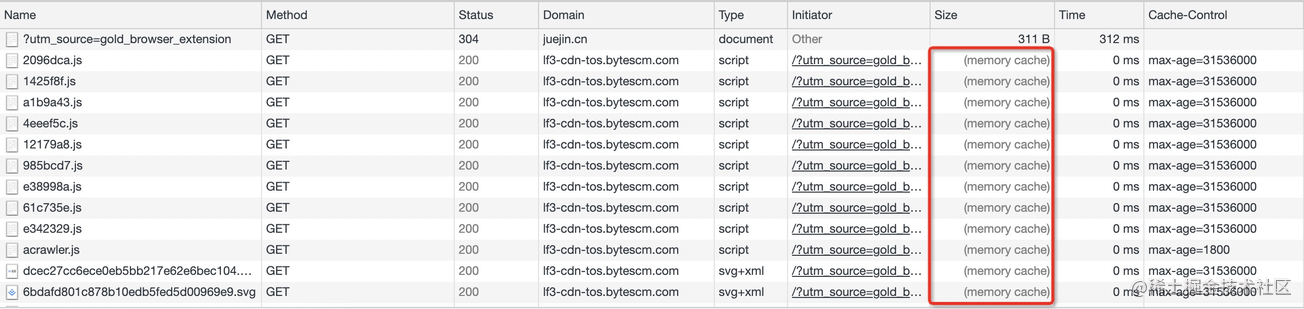
上图中刷新页面后大部分资源直接会从浏览器内存缓存(memory cache)中读取,这一现象我们会在后续章节中介绍。由此我们可以得出“正常重新加载”模式会优先读取缓存。
模式二:硬性重新加载
// 快捷键
Mac: Command + Shift + R
Windows: Ctrl + Shift + R(等同于直接按 Ctrl + F5)
硬性重新加载模式强调的是“硬性”,可以理解为我们常说的“强制刷新网页”,比如当代码部署到服务器上后仍然访问的是“旧”页面时,很多人会习惯性的强制刷新一下(Ctrl + F5)便好了,而使用“正常重新加载”却无法解决。于是我们会以为硬性重新加载会清空缓存重新向服务器请求,这是一个误区,我们来观察下硬性重新加载后的控制台:
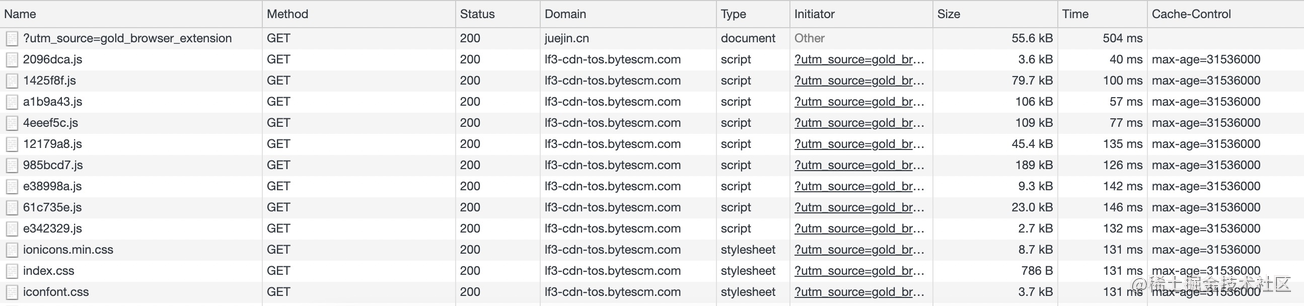
可以看到所有资源都重新向服务器获取,这个没有问题,但是检查下请求报头我们会发现,使用硬性重新加载后所有资源的请求首部都被加上了 cache-control: no-cache 和 pragma: no-cache,两者的作用都表示告知(代理)服务器不直接使用缓存,要求向源服务器发起请求,而 pragma 则是为了兼容 HTTP/1.0。
因此硬性重新加载并没有清空缓存,而是禁用缓存,其效果类似于在开发者工具 Network 面板勾选了 Disable cache 选项:

模式三:清空缓存并硬性重新加载
该模式顾名思义,其比硬性重新加载多了清空缓存的操作,因此触发该操作会将浏览器存储的本地缓存都清空掉后再重新向服务器发送请求,同时其影响的并不是当前网站,所有访问过的网站缓存都将被清除。
介绍完了 Chrome 的三种加载模式,相信也顺其自然解释了用户的一些操作和缓存的密切联系,接着笔者又要开始提问了:有时候当我们使用硬性重新加载(Ctrl + F5)时,为什么有个别资源还是走了强缓存?
读者可以在此思考一番,如果实在没有头绪就接着往下阅读。
# 为什么 Ctrl + F5 还是命中了缓存
上述介绍了硬性重新加载时资源请求报头会加上特定的两个首部来重新向服务器发起请求,从而绕过了读取浏览器缓存,那么换种思路,如果资源在硬性重新加载后还是命中缓存,是不是就说明请求报头上并没有加上特定的两个首部?
笔者通过观察和分析,发现那些命中缓存的资源都是随着页面渲染而加载的,而不走缓存的则是等待页面加载完通过脚本异步插入到 DOM 中去的,于是便得到了资源异步加载命中缓存不受硬性重新加载控制的猜想。为了验证这个猜想,我们不妨写一个 Demo 来进行试验:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Demo</title>
</head>
<body>
<div id="cache">异步资源</div>
<script>
window.onload = (function() {
setTimeout(function() {
// 异步加载背景图片
var a = document.getElementById("cache");
a.style.backgroundImage= 'url(https://aecpm.alicdn.com/simba/img/TB183NQapLM8KJjSZFBSutJHVXa.jpg)';
// 异步插入 JS 资源
var s = document.createElement('script');
s.type = 'text/javascript';
s.async = true;
s.src = 'https://g.alicdn.com/mm/tanx-cdn/t/tanxssp.js?v=2';
var x = document.getElementsByTagName('script')[0];
x.parentNode.insertBefore(s, x);
}, 1000)
})
</script>
</body>
</html>
上述代码我们通过一个 1 秒的延时器异步加载了一张背景图片和一个 JS 资源,当在确保浏览器已经缓存了以上资源的前提下,我们采用硬性重新加载后来观察 Network 面板:

发现两者都命中了强缓存,同时两者的请求报头发现都没有被加上 cache-control: no-cache 和 pragma: no-cache 两个首部,于是猜想成立。
其实原因也很简单,因为硬性重新加载并没有清空缓存,当异步资源在页面加载完后插入时,其加载时仍然优先读取缓存,如果使用清空缓存并硬性重新加载便不会出现这种现象。
tips:如果采用开发者工具 Network 面板勾选 Disable cache 选项方式,那么异步资源也不会读取缓存,原因是缓存被提前禁用了,这与硬性重新加载不同。
最后细心的读者还会发现,还有一种资源比异步资源更加“顽固”,几乎永远都是 from memory cache,不管是首次加载还是清空缓存都不奏效,它便是 base64 图片。
这一现象可以这样解释:从本质上看 base64 图片其实就是一堆字符串,其伴随着页面的渲染而加载,浏览器会对其进行解析,会损耗一定的性能。按照浏览器的“节约原则”,我们可以得出以下结论:
Base64 格式的图片被塞进 memory cache 可以视作浏览器为节省渲染开销的“自保行为”。
# 七、从跨域问题到 Nginx 响应报头配置
前端工程师作为一个承上启下的工种,承接上方的 UI 层,开启对接后端的 API 层,前端开发可以说是软件开发过程中重要的一环。正因为前端的特殊地位,因此有时候不可避免需要接触并学习其上下游知识。
一个优秀的前端工程师,往往除了精通前端本身外,还需要具备一定的软件设计能力或者服务端开发能力,而本篇文章也将由原来的纯前端层面转变到服务端 Nginx 配置层面,虽然进阶了一层,但本身其也与前端息息相关,借此笔者也将带大家更上一层楼。
# Nginx 与跨域问题
大多数前端第一次接触 Nginx 可能并不是为了配置什么 HTTP 缓存相关的响应头,而是为了解决头疼的跨域问题。比如下方常见的浏览器跨域报错:

以上是笔者在掘金首页随便找了一个接口进行本地调用后报的跨域问题,从响应报头可以看出服务端做了访问限制:
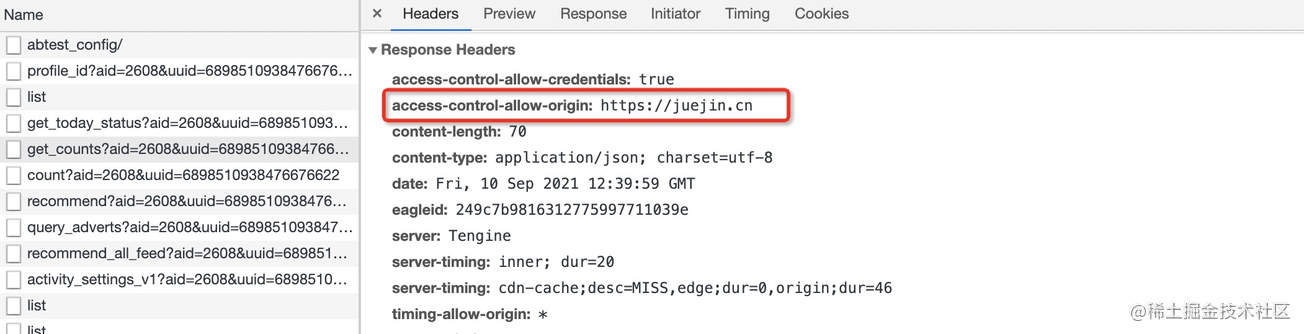
Access-Control-Allow-Origin 表示指定允许访问的域名(白名单),上述因为设置了 juejin.cn (opens new window) 的域名,所以除了该域名外的任何访问都将是不被允许的。
因此如果前端访问后端跨域,首先要检查的便是服务端或者 Nginx 配置的 Access-Control-Allow-Origin 是否包含前端域名。
有些时候 Access-Control-Allow-Origin 被设置成 * 代表允许所有域名访问,但可能还会报如下跨域问题:

该问题产生的根源其实是在前端,比如前端使用 Axios 请求库时如果开启了以下配置:
axios.defaults.withCredentials = true // 允许携带 cookie
其代表允许请求头携带 cookie,那么服务端配置 Access-Control-Allow-Origin 时就不能为 *,或者针对该类型的接口前端请求关闭该配置即可。
同时当前端配置了 axios.defaults.withCredentials = true 时,服务端需配置 access-control-allow-credentials: true。
如果浏览器发起了预检请求,那么可能还需要配置 access-control-allow-methods 和 access-control-allow-headers 报头为允许的值。比如:
access-control-allow-headers: Content-Type,Content-Length,Authorization,Accept,X-Requested-With
access-control-allow-methods: PUT,POST,GET,DELETE,OPTIONS
所谓预检请求,也就是浏览器控制台经常会看到的 OPTIONS 请求。
关于什么时候会发起预检请求,与预检请求相反的称为“简单请求”,可以参考:简单请求的触发条件 (opens new window)。
# 使用 Nginx 配置响应报头
通过跨域问题,让我们了解到了 Nginx 配置的重要性,下面我们就正式尝试使用 Nginx 来配置响应报头。
访问 Nginx 服务器及配置文件
第一步我们需要访问应用所在的 Nginx 服务器,这里笔者使用的是 finalshell 工具,该软件支持 Windows 和 Mac 系统。
登录成功之后我们可以进入控制台使用 vim 命令针对 nginx 配置文件进行编辑(首先得知道 nginx 配置文件的目录地址,一般以 nginx.conf 命名):
vim /etc/nginx/nginx.conf
打开 nginx.conf 文件后可以通过以下常用命令进行操作:
编辑:按 i 键,进入编辑模式
保存:按下 :w
保存并退出:按下 :wq
退出:按下 :q
返回命令模式:按 esc 键,返回命令模式
修改跨域相关配置
nginx.conf 文件中包含了很多参数项,如果要修改上述的跨域配置,那么首先找到对应的应用端口,修改 location / 中的参数:
server {
listen 80;
location / {
add_header Access-Control-Allow-Origin *;
add_header Access-Control-Allow-Methods 'PUT,POST,GET,DELETE,OPTIONS';
add_header Access-Control-Allow-Headers 'Content-Type,Content-Length, Authorization, Accept,X-Requested-With';
if ($request_method = 'OPTIONS') {
return 204;
}
}
}
修改完我们保存并退出后需要重启下 nginx 配置才会生效,运行 nginx -s reload 命令。最终我们刷新页面观察响应报头成功返回了配置字段:
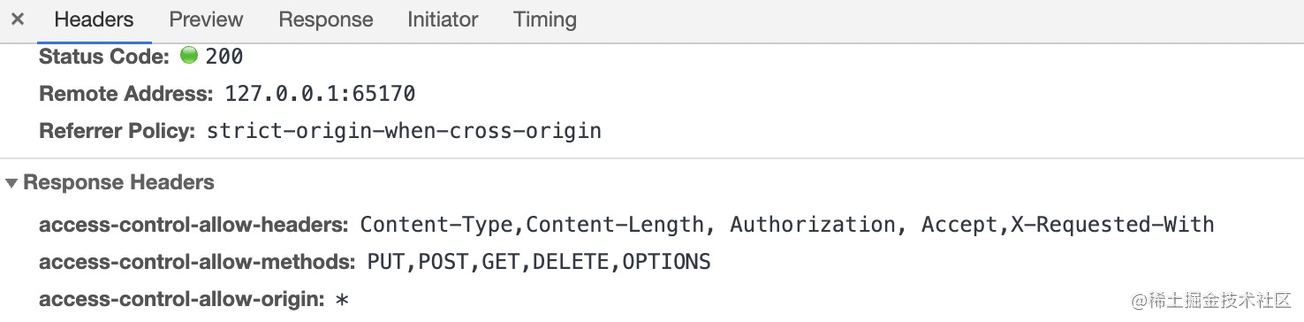
修改缓存相关配置
nginx 作为一个代理服务器,当处理静态资源时资源的一些如 eTag、last-modified 等首部大都是由源服务器返回的,一般在 nginx 配置中不会对其进行修改,而主要修改的是缓存方式和过期时间的配置。比如我们不想 html 文件命中强缓存,希望其走协商缓存,可以添加如下响应报头配置:
server {
listen 80;
location / {
if ($request_filename ~* .*.(html|htm)$) {
add_header Cache-Control 'no-cache';
}
}
}
而像 js、css 和图片这样的静态资源,我们希望浏览器命中强缓存,nginx 可以设置相应的过期时间:
server {
listen 80;
location ~ .*.(gif|jpg|jpeg|png|bmp|swf|js|css)$ {
expires 1d;
}
}
上述配置我们以 1 天为例,最终浏览器将返回响应报头 Cache-Control: max-age=86400。
add_header 的继承问题
倘若我们在 html 的判断上层又添加了如下首部:
server {
listen 80;
location / {
add_header Test '掘金';
if ($request_filename ~* .*.(html|htm)$) {
add_header Cache-Control 'no-cache';
}
}
}
那么如果按照 JavaScript 从上往下的执行顺序来猜想,最终 html 文件响应报头中将会被添加以上两个首部,而经过实际检验会发现只会添加 Cache-Control 首部,导致该结果的原因主要是 add_header 的继承问题。官方给出的解释如下:
There could be several
add_headerdirectives. These directives are inherited from the previous level if and only if there are noadd_headerdirectives defined on the current level.
主要意思为当且仅当当前层级上未定义任何 add_header 时,才可以从上层继承 add_header。而上述的 if 模块便属于层级的概念,因此上层的 add_header 并不会起作用。
# 八、Memory Cache 与 Disk Cache
从本文开始,我们将进入浏览器缓存的话题,但是我们尚且不能抛开 HTTP 缓存不管,相反我们需要建立在其基础之上。只有扎实了前面部分的知识,后面的学习之路才能走的更加平坦和顺畅,切勿邯郸学步。正所谓“学而不思则罔,思而不学则殆”,大家最终还是要产生自己的见解和认知,提出疑惑,寻找答案。
在前面章节介绍 HTTP 缓存的过程中,笔者多次提到了浏览器的 Memory Cache 与 Disk Cache 这两种缓存,但因当时它们并不是“主角”,生怕介绍起来喧宾夺主,因此并没有进行详细的阐述。而从本文开始我们已经步入了浏览器缓存的篇章,笔者将以此作为起点,发挥其承上启下的效果。
# Memory Cache 与 Disk Cache 介绍
在了解它们之前,我们不妨先来段“自我介绍”。
Memory Cache
Memory Cache 翻译过来便是“内存缓存”,顾名思义,它是存储在浏览器内存中的。其优点为获取速度快、优先级高,从内存中获取资源耗时为 0 ms,而其缺点也显而易见,比如生命周期短,当网页关闭后内存就会释放,同时虽然内存非常高效,但它也受限制于计算机内存的大小,是有限的。
那么如果要存储大量的资源,这是还得用到磁盘缓存。
Disk Cache
Disk Cache 翻译过来是“磁盘缓存”的意思,它是存储在计算机硬盘中的一种缓存,它的优缺点与 Memory Cache 正好相反,比如优点是生命周期长,不触发删除操作则一直存在,而缺点则是获取资源的速度相对内存缓存较慢。
Disk Cache 会根据保存下来的资源的 HTTP 首部字段来判断它们是否需要重新请求,如果重新请求那便是强缓存的失效流程,否则便是生效流程。
从两者的优缺点中我们可以发现,Memory Cache 与 Disk Cache 珠联璧合,优势互补,共同构成了浏览器本地缓存的左右手。
介绍完这两位“老朋友”,接下来我们继续来了解下浏览器的缓存机制,因为目前市面上浏览器众多,不同浏览器的缓存机制都可能不同,笔者还是以主流的 Chrome 为例进行介绍。
# 浏览器缓存机制
浏览器缓存机制包含了 Http 缓存中强缓存、协商缓存的知识点,这里就不再进行赘述,下面主要介绍与 Memory Cache、 Disk Cache 相关的机制。
缓存获取顺序
按照缓存顺序来讲,当一个资源准备加载时,浏览器会根据其三级缓存原理进行判断。
- 浏览器会率先查找内存缓存,如果资源在内存中存在,那么直接从内存中加载
- 如果内存中没找到,接下去会去磁盘中查找,找到便从磁盘中获取
- 如果磁盘中也没有找到,那么就进行网络请求,并将请求后符合条件的资源存入内存和磁盘中
按照以上顺序,浏览器缓存与 HTTP 缓存才得以相辅相成,在有效的沟通和判断中尽可能的减少不必要的资源浪费。
缓存存储优先级
上述我们讲解了缓存资源的获取顺序,那么在获取之前,浏览器又是按照什么优先级来存储资源的?这一问题也可以直接换成“浏览器判断一个资源是存入内存缓存还是磁盘缓存的依据是什么?”。
其实答案在介绍内存缓存和磁盘缓存时已经有所涉及,我们以掘金首页为例子进行介绍。
当我们打开开发者工具并在浏览器输入 url 访问后,发现除了 base64 的图片永远从内存加载外,其他大部分资源会从磁盘加载。

磁盘缓存会将命中强缓存的 js、css、图片等资源都收入囊中,也省去我们担心它“挑食”的问题。
而内存缓存不这样,为了保持“苗条的身材”,它不得不控制“饮食”,尽可能的去挑选适合自己的“食物”。此时我们刷新下页面让内存缓存生效:
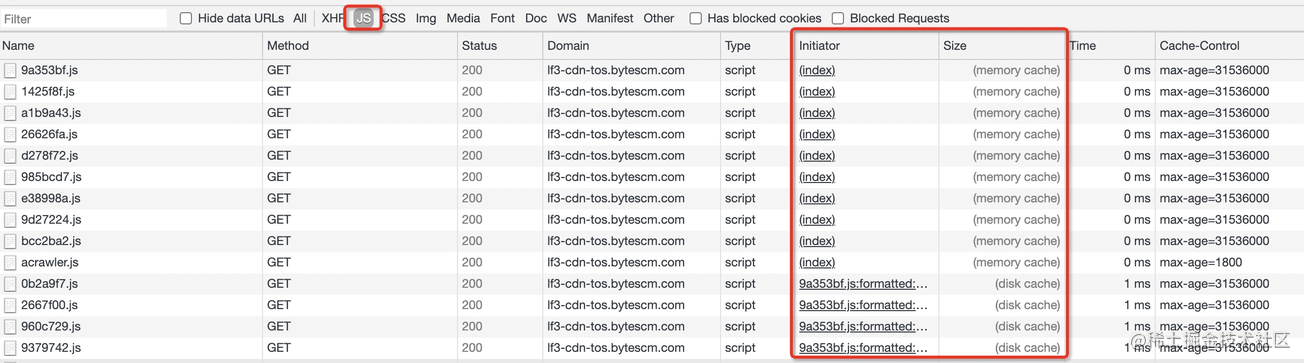
我们先过滤下只看 JS 资源的加载情况,发现有些被内存缓存了,有些则没有,这是为什么?
有些读者可能会猜测是不是没有被缓存的是因为资源比较大,其实不然,上方图片笔者圈出了 Initiator 列,通过该列便可以找到答案。
Initiator 列表示资源加载发起的位置,我们点击从内存获取资源的该列值后可以发现资源是在 HTML 渲染阶段就被加载的,如以下代码所示:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<title>Demo</title>
<script src="https://i.snssdk.com/slardar/sdk.js"></script>
</head>
<body>
<div id="cache">加载的 JS 资源大概率会存储到内存中</div>
</body>
</html>
而被内存抛弃的资源我们也可以发现其都是异步加载的资源,这些资源没有被内存缓存,比如像这样:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<title>Demo</title>
</head>
<body>
<div id="cache">异步加载的 JS 资源没有存储到内存中</div>
<script>
window.onload = function () {
setTimeout(function () {
var s = document.createElement("script");
s.type = "text/javascript";
s.async = true;
s.src = "https://i.snssdk.com/slardar/sdk.js";
var x = document.getElementsByTagName("script")[0];
x.parentNode.insertBefore(s, x);
}, 2000);
};
</script>
</body>
</html>
根据以上测试代码很容易产生错误的判断结论:异步加载的 JS 资源不会存储到内存中。
其实这里异步函数只是起到了协助性的作用,并不是造成不存内存的根本性原因,就好比“羚羊遇见了狼,羚羊没有被狼吃了并不是因为羚羊会跑,而是因为其跑过了狼”。
我们可以把 JS 资源看作是“羚羊”,把浏览器内存看作是“狼”,“羚羊没有被狼吃了”便可以理解为异步加载的 JS 资源没有存储到内存中,此时“羚羊跑过了狼”就可以看作是异步资源的加载晚于浏览器内存的生效时间,最终笔者得出的结论便很好理解:
浏览器内存缓存生效的前提下,JS 资源的执行加载时间会影响其是否被内存缓存
我们可以修改上述的 setTimeout 时间为 1 秒后再次进行验证,大家会发现即使异步了,JS 资源还是很容易被内存缓存,原因便是异步 JS 资源加载时浏览器渲染进程可能还没有结束,而进程没结束就有被存入内存的可能。
此外图片资源(非 base64)也有和 JS 资源同样的现象,而 CSS 资源比较与众不同,其被磁盘缓存的概率远大于被内存缓存。

这一现象目前还没有找到标准的答案,网上给出的非标准解释是:
因为 CSS 文件加载一次就可渲染出来,我们不会频繁读取它,所以它不适合缓存到内存中,但是 JS 之类的脚本却随时可能会执行,如果脚本在磁盘当中,我们在执行脚本的时候需要从磁盘取到内存中来,这样 IO 开销就很大了,有可能导致浏览器失去响应。
以上所述的内存缓存(Memory Cache)在浏览器标准中并没有详尽的描述,笔者也是根据自身实践及总结得出的一些结论,不同的浏览器在加载资源时可能会所有差异,读者还需根据自己的理解和实践进行进一步探索。
Preload 与 Prefetch
基于上述现象的前提下,笔者还发现了与资源加载相关的两个功能(Preload 与 Prefetch)也会潜移默化的影响着浏览器缓存。
preload 也被称为预加载,其用于 link 标签中,可以指明哪些资源是在页面加载完成后即刻需要的,浏览器会在主渲染机制介入前预先加载这些资源,并不阻塞页面的初步渲染。例如:
<link rel="preload" href="https://i.snssdk.com/slardar/sdk.js" as="script" />
而当使用 preload 预加载资源后,笔者发现该资源一直会从磁盘缓存中读取,JS、CSS 及图片资源都有同样的表现,这主要还是和资源的渲染时机有关,在渲染机制还没有介入前的资源加载不会被内存缓存。
相反 prefetch 则表示预提取,告诉浏览器加载下一页面可能会用到的资源,浏览器会利用空闲状态进行下载并将资源存储到缓存中。
<link rel="prefetch" href="https://i.snssdk.com/slardar/sdk.js" />
使用 prefetch 加载的资源,刷新页面时大概率会从磁盘缓存中读取,如果跳转到使用它的页面,则直接会从磁盘中加载该资源。
利用好 preload 和 prefetch 这“两员大将”,我们可以优化浏览器资源加载的顺序和时机,在页面性能优化环节至关重要。
# 九、Service Worker
在浏览器缓存的世界中,不同的缓存扮演着不同的角色,缓存存储的位置的也不尽相同,除了上文介绍的内存和磁盘外,本文将介绍在服务器与浏览器间扮演中间人角色的缓存 —— Service Worker。
提及 Service Worker 有些人可能会觉得陌生,因为不是所有的项目都适合使用它,但如果你的网页正在追求一种极致的性能体验,那么 Service Worker 可以帮你达成这一目标,而要了解 Service Worker 首先还得从渐进式 Web 应用说起。
# 从渐进式 Web 应用开始
随着移动互联网的发展,为了满足用户在手机上操作页面的便捷性,诸多 PC 应用也纷纷推出了自己的移动版本,而移动原生应用不管在用户体验还是功能上都比传统的 web 应用强大得多,比如快速的页面加载、及时的信息推送和离线可用等,而这些功能当时在 web 应用中都存在着限制,于是成千上万个采用 iOS、Android 原生技术开发的应用如雨后春笋般出现,成功打下了该领域的一片“江山”。
为了让 web 技术在移动时代的浪潮中能够分得一杯羹,各大浏览器厂商便纷纷开始支持及推进渐进式 Web 应用(Progressive Web Apps)的使用,即我们熟知的 PWA。
那么什么是渐进式 Web 应用?
从本质上讲,渐进式 Web 应用程序仍然是 Web 应用程序,但其支持渐进式增强,在现代浏览器中可以使用新功能,如果新功能不可用,用户仍然可以获得核心的体验。
其特性主要体现在:
- 功能强大(在现代 API、WebAssembly 和新的即将推出的 API 之间,Web 应用程序比以往任何时候都更强大)
- 可靠性(无论网络如何,可靠的渐进式 Web 应用程序都会让用户感觉到快速)
- 可安装(已安装的渐进式 Web 应用程序在独立窗口中运行,而不是在浏览器 tab 页中运行)
而实现以上特性的关键技术就是本文的主人公 Service Worker。
# Service Worker 登场
概念
Service Worker 本质上是一种用 JavaScript 编写的脚本,其作为一个独立的线程,它可以使应用程序能够控制网络请求,缓存这些请求以提高性能,并提供对缓存内容的离线访问。
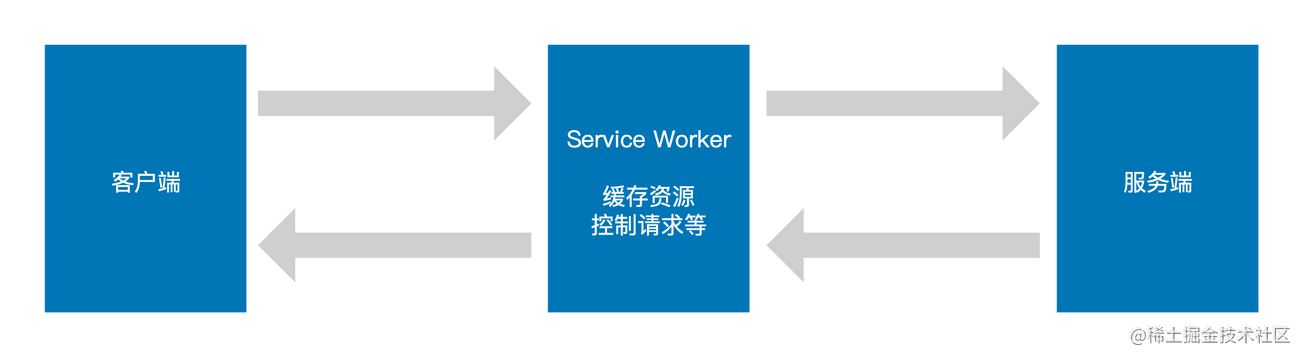
Service Worker 依赖两个 API 使应用程序离线工作:Cache (opens new window)(应用程序数据的持久性内容存储)和 Fetch (opens new window)(一种从网络检索内容的标准方法)。Service Worker 缓存是持久的,独立于浏览器缓存或网络状态。
生命周期与缓存
Service Worker 在其生命周期中会经历以下三个步骤:
- 注册
- 安装
- 激活
通常我们会编写以下脚本进行 Service Worker 的注册:
if ('serviceWorker' in navigator) {
navigator.serviceWorker.register('/sw.js').then(function(registration) {
console.log('Registration successful, scope is:', registration.scope);
})
.catch(function(error) {
console.log('Service worker registration failed, error:', error);
});
}
首先判断浏览器支不支持 serviceWorker API,支持后注册时会去读取对应的 sw.js 文件,默认情况下 Service Worker 的作用范围不能超出其脚本所在的路径,如果上述脚本放在根目录下,那么代表项目根目录下的所有请求都可以代理。当然也可以在注册时指定对应的作用域:
navigator.serviceWorker.register('/sw.js', {
scope: '/xxx'
})
此时 Service Worker 只会代理 xxx 目录下的请求。
一旦浏览器执行了注册流程后,在 sw.js 文件中,其便会尝试执行 Service Worker 的 install 安装事件,该事件只会触发一次,即在首次注册或者有新的 Service Worker 之后执行。在安装事件中我们可以下载并预缓存应用的部分内容,以便在用户下次访问时立即得到加载。以 Chrome 官网的例子为例:
// sw.js
// 此版本的 Service Worker 中使用的两个缓存的名称,更新任意一个缓存名称,都将再次触发安装事件
const PRECACHE = 'precache-v1'
const RUNTIME = 'runtime'
// 想被缓存的本地资源列表
const PRECACHE_URLS = [
'index.html',
'./', // index.html 的别名
'styles.css',
'../../styles/main.css',
'demo.js'
]
// 安装事件中缓存预先我们想要缓存的资源
self.addEventListener('install', event => {
event.waitUntil(
// 调用浏览器 CacheStorage open 方法
caches.open(PRECACHE)
.then(cache => cache.addAll(PRECACHE_URLS))
.then(self.skipWaiting()) // self.skipWaiting 可以阻止等待,让新的 Service Worker 安装成功后立即激活
)
})
在安装事件中我们会缓存预先想要缓存的资源,成功安装 Service Worker 后,它会过渡到激活阶段。如果有前一个 Service Worker 控制的打开页面存在,则新的 Service Worker 会进入一个 waiting 状态。新的 Service Worker 仅在不再加载任何仍在使用旧 Service Worker 的页面时激活,这确保在任何给定时间只有一个版本的 Service Worker 正在运行。
我们也可以调用 skipWaiting() 方法阻止 Service Worker 等待,让新的 Service Worker 安装成功后立即激活。
当新的 Service Worker 激活时,其会触发 active 事件,我们可以使用 addEventListener 来监听 activate 事件。在此事件中我们通常会清理过期的缓存:
// sw.js
// active 事件负责清理过期缓存
self.addEventListener('activate', event => {
const currentCaches = [PRECACHE, RUNTIME]
event.waitUntil(
caches.keys().then(cacheNames => {
return cacheNames.filter(cacheName => !currentCaches.includes(cacheName));
}).then(cachesToDelete => {
return Promise.all(cachesToDelete.map(cacheToDelete => {
return caches.delete(cacheToDelete) // 删除不存在的过期缓存
}))
}).then(() => self.clients.claim()) // 启用新的 Service Worker
)
})
上述我们在 active 生命周期中通过调用浏览器的 Cache (opens new window) API 的 delete 方法将过期的缓存进行了删除操作,防止过期缓存影响现有的功能。
一旦激活,Service Worker 将控制在其范围内加载的所有页面,新的 Service Worker 只会在我们关闭并重新打开应用时启用,或者调用 clients.claim() 方法。
至此相信大家对 Service Worker 在其生命周期中会经历的三个步骤“注册、安装和激活”以及如何将资源添加到缓存中已经有了一定的认识,那么下面我们再来了解下 Service Worker 如何拦截网络请求并从缓存中获取资源。
优先从缓存中获取资源
如果大家想让自己的网页离线可用,那么拦截网络请求并从缓存中获取资源是最主要的方法,当然前提是缓存中已经存在了所要访问的资源。
我们一般会采用缓存回退网络的方式进行代码的编写,即拦截请求时如果缓存中存在该资源则直接获取,否则再向服务端请求资源并进行缓存。示例代码如下:
// sw.js
// fetch 处理事件会处理同源资源的响应,如果缓存中存在,则会直接返回缓存资源
self.addEventListener('fetch', event => {
// 跳过跨域请求
if (event.request.url.startsWith(self.location.origin)) {
event.respondWith(
// 从缓存中匹配请求的资源
caches.match(event.request).then(cachedResponse => {
// 存在则直接返回
if (cachedResponse) {
return cachedResponse;
}
// 不存在则回退网络请求
return caches.open(RUNTIME).then(cache => {
return fetch(event.request).then(response => {
// 拷贝响应资源存入 runtime 缓存.
return cache.put(event.request, response.clone()).then(() => {
return response;
})
})
})
})
)
}
})
上述代码我们通过监听 fetch 事件处理程序进行资源请求的拦截操作,实现了 Service Worker 基本的优先从缓存中获取资源的功能。
最终我们将代码组合起来便完成了一个简单的可离线访问功能。当浏览器命中 Service Worker 缓存时,资源在开发者工具中将被显示为从 ServiceWorker 获取。

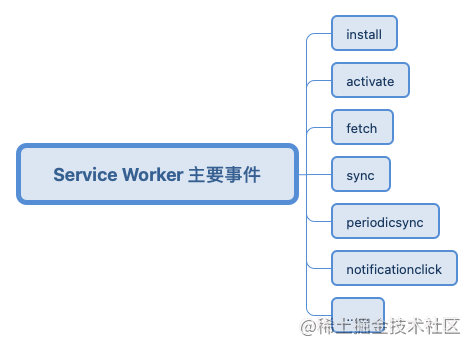
当然除了上述介绍的 install、activate、fetch 事件,Service Worker 还有其他几个主要的事件,通过按需集成这些事件我们便可以开发强大而体验友好的渐进式 web 应用程序。
这里笔者用一张图汇总了 Service Worker 的一些主要事件,大家有兴趣可以继续探索。
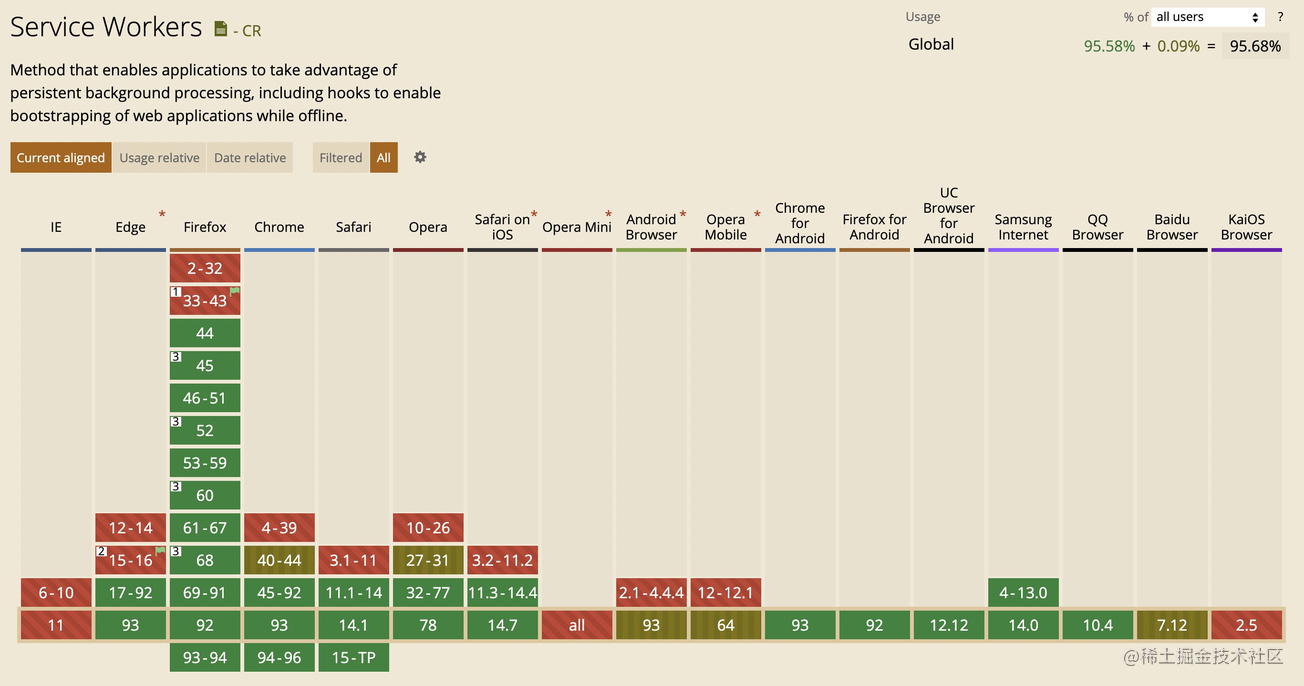
兼容性
虽然 Service Worker 具有强大的功能,但不同浏览器及其版本对它的兼容性都有所不同,从 caniuse (opens new window) 中查询 Service Worker 的浏览器兼容性结果如下:
因此出于渐进式体验的考虑,在不支持 Service Worker 的低版本浏览器中,我们可能仍然需要进行一些兼容处理,使用户可以使用其主要功能。
同时出于安全考虑,Service worker 只能在 https 及 localhost 下被使用。
# 十、存储型缓存的道与术
浏览器存储型缓存包含了 Cookie、Web Storage、IndexedDB 等,它们也是我们日常开发中经常会接触的缓存,而正因为经常接触,往往也更容易忽视它们的“道与术”。此处的“道”指的是存储型缓存的设计初衷与背景,“术”指的是存储型缓存的使用技巧和方案。
下面不妨让我们从上述提到的“不用重复登录”的现象出发,一起进一步认识浏览器存储型缓存的“道与术”。
# 网站登录背后的存储逻辑
网站登录功能几乎在大多数应用中都普遍存在,其也是服务端搜集并存储用户信息的必要途径。用户登录也可以看作是前端与服务端的一次授权对话。
当用户从客户端界面输入账号密码点击登录后,前端会将数据发送给服务端进行验证,如果服务端判断用户存在且账号密码正确则向客户端返回响应并颁发有效的 token 信息,如果校验失败则会返回错误信息。
一旦唯一并有效的 token 信息返回到客户端,后续的所有需登录访问的接口请求客户端都需要携带 token 给服务端判断用户登录的有效性,因此 token 信息在客户端的存储及传输是用户不必重复登录的关键。
常见的客户端存储 token 信息的方式有两种:服务端自动植入和前端手动存储。
服务端自动植入
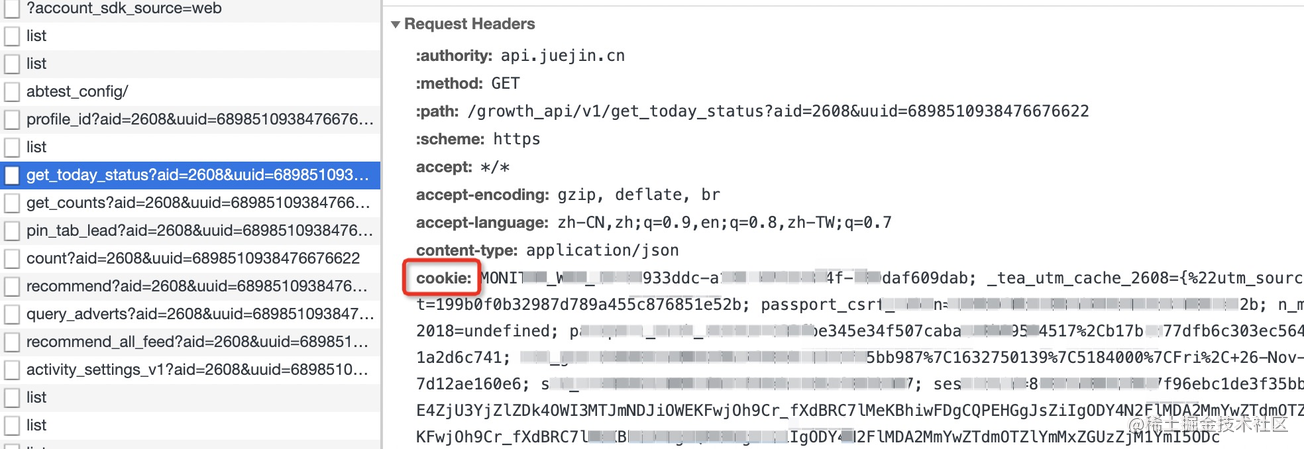
服务端登录接口可以在返回前端的响应报头中设置首部字段 set-cookie 来将 token 信息植入浏览器 cookie 中,如下图所示:

set-cookie 指令值包含了必选项 <cookie-name>=<cookie-value> 值和名的形式,同时还包括了可选项 Path(路径)、Domain(域名)、Max-Age(有效时间)等,以分号分隔。
服务端可以返回多个 set-cookie 指令来达到设置多个 cookie 的目的。最终我们可以在开发者工具 Application 面板中查看当前网页设置的 cookie 值。

之后前端调用任何同域下的接口时,浏览器会自动将网站的 cookie 值附加在请求头中传给后端进行校验,前端则不需要关心 token 的存取问题。
前端手动存储
相比服务端自动植入,前端存储的方式不受限于浏览器环境,比如像 APP 或小程序等一些没有浏览器 cookie 的环境下也可以使用该种方式。
服务端登录接口成功后直接将用户的 token 信息通过响应实体的方式返回给前端,比如像下面这样:
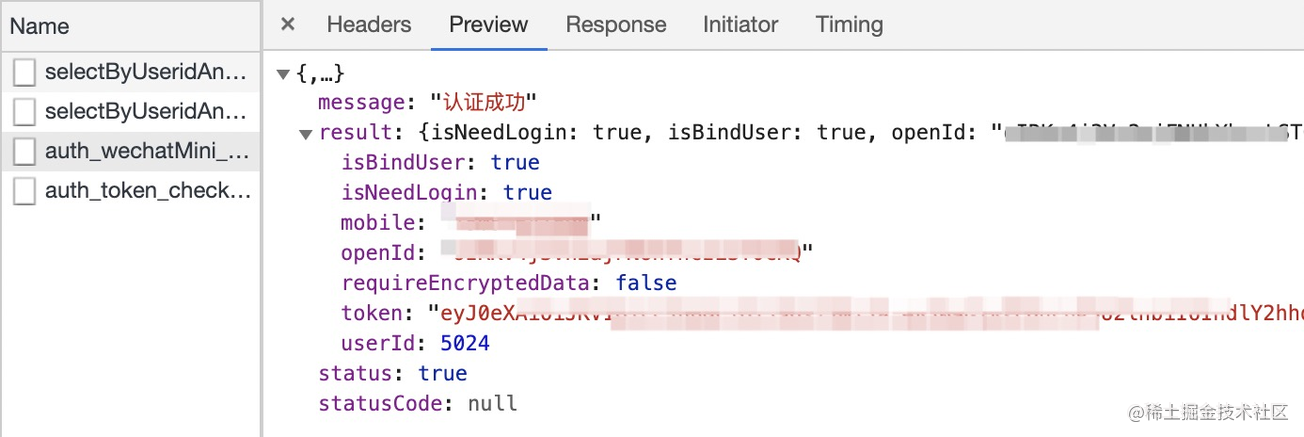
前端获取到 token 信息后可以通过前端存储方法将数据持久化缓存起来,并在退出后手动清除。同时在调用后端接口时需要手动将 token 传递给服务端,以一个简单的 axios 调用为例:
import axios from 'axios'
export const http = params => {
let instance = axios.create({
baseURL: 'https://juejin.cn',
})
let token = localStorage.getItem('token') // 从缓存中获取对应 name 值
return instance({
url: '/xxx/xxx',
method: 'post',
data: params,
headers: {
'x-token': token // 前端手动设置自定义 token 响应头
}
})
}
大家可以根据实际场景和环境进行 token 的存取,在不同环境中使用当前环境支持的存取方法即可。如浏览器环境支持 localStorage。
# 浏览器存储型缓存方案
在浏览器环境中,不同的存储型缓存并非适应所有的场景,作为一名合格的前端开发,我们应该在实现方案中进行合理的权衡,最终采用最佳的缓存方案。
Cookie 存储方案
Cookie 作为最老牌的存储型缓存,其诞生之初其实并不是为了提供浏览器存储的功能,而是为了辨别用户身份,实现页面间状态的维持和传递,上述介绍的网站不用重复登录的现象便很好的阐述了这一设计初衷。
Cookie 的存储空间很小,不能超过 4KB,因此这一缺点也限制了它用于存储较大容量数据的能力。 当然笔者也不建议将非用户身份类的数据存储在 Cookie 中,因为 Cookie 在同域下会伴随着每一次资源请求的请求报头传递到服务端进行验证,试想一下如果大量非必要的数据存储在 Cookie 中,伴随着请求响应会造成多大的无效资源传输及性能浪费。
而利用 Cookie 无法跨域携带的特点我们可以在 CDN 域名上有所作为。假如 CDN 资源和主站采用了同样的域名,那么必然会造成因 Cookie 传输带来的巨大性能浪费,相反我们可以将 CDN 的域名与主站区分开来来规避这一问题。比如掘金的 CDN 域名为 https://lf3-cdn-tos.bytescm.com,而主站的域名为 https://juejin.cn。
在 Cookie 存储 API 方面,浏览器提供的原始 API 使用起来也不是特别方便,比如:
// 存储 Cookie
document.cookie='name=juejin; domain=juejin.cn'
// 读取 Cookie
// 只能通过 document.cookie 读取所有 Cookie 并进行字符串截取,非常不便
// 删除 Cookie
let date = new Date()
date.setTime(date.getTime() - 10000) // 设置一个过期时间
document.cookie=`name=test; domain=juejin.cn; expires=${date.toGMTString()}`
如此操作起来会编写大量重复糟心的代码,因此封装 Cookie 的增删改查操作十分必要。
这里笔者推荐大家安装目前较为流行的一款封装 Cookie 操作的库 js-cookie (opens new window) 进行使用,其 API 操作如下:
import Cookies from 'js-cookie'
// 存储 Cookie
Cookies.set('name', 'juejin', { domain: 'juejin.cn' })
// 读取 Cookie
Cookies.get('name')
// 删除 Cookie
Cookies.remove('name')
对比一下,显然封装过后的 API 变得“丝滑”许多。
Web Storage 存储方案
在验证用户身份及维持状态方面,Cookie 有明显的特点和优势,但其并不是存储网页数据的小能手,相反 Web Storage 在这方面却有显著的优势。
Web Storage 作为 HTML5 推出的浏览器存储机制,其又可分为 Session Storage 和 Local Storage,两者相辅相成。
Session Storage 作为临时性的本地存储,其生命周期存在于网页会话期间,即使用 Session Storage 存储的缓存数据在网页关闭后会自动释放,并不是持久性的。而 Local Storage 则存储于浏览器本地,除非手动删除或过期,否则其一直存在,属于持久性缓存。
Web Storage 与 Cookie 相比存储大小得到了明显的提升,一般为 2.5-10M 之间(各家浏览器不同),这容量对于用于网页数据存储来说已经十分充足。
我们再来看一下 Web Storage 相关的操作 API(以 Local Storage 为例):
// 存储 Local Storage 数据
localStorage.setItem('name', 'juejin')
// 读取 Local Storage 数据
localStorage.getItem('name')
// 删除 Local Storage 数据
localStorage.removeItem('name')
在存储简单的数据类型时,Web Storage 提供的原始 API 可以轻松完成任务,但是一旦数据类型变为 Object 类型时,其应付起来就变得捉襟见肘,主要原因在于使用 Web Storage 存储的数据最终都会转化成字符串类型,比如:
localStorage.setItem('age', 18)
localStorage.getItem('age') // 最终获取的会是字符串 '18'
而存储对象时如果没有提前采用序列化方法 JSON.stringify 转化为字符串对象,那么最终获取的值会变成 [object Object]。
因此 Web Storage 的原始存储方案会存在繁碎的序列化与反序列化的缺点:
let userinfo = { name: 'juejin', age: 18 }
// 存储时进行序列化操作
localStorage.setItem('userinfo', JSON.stringify(userinfo))
// 获取时进行反序列化操作
JSON.parse(localStorage.getItem('userinfo'))
此时我们唯一需要做的便还是进行二次封装,比如以封装 Local Storage 为例:
let storage = {
// 存储方法
setStorage: function (key, value, duration) {
let data = {
value: value,
expiryTime: !duration || isNaN(duration) ? 0 : this.getCurrentTimeStamp() + parseInt(duration)
}
localStorage[key] = JSON.stringify(data) // 进行序列化操作
},
// 获取方法
getStorage: function (key) {
let data = localStorage[key]
if (!data || data === "null") {
return null
}
let now = this.getCurrentTimeStamp()
let obj
try {
obj = JSON.parse(data); // 进行反序列化操作
} catch (e) {
return null
}
if (obj.expiryTime === 0 || obj.expiryTime > now) {
return obj.value
}
return null
},
// 删除方法
removeStorage: function (key) {
localStorage.removeItem(key)
},
// 获取当前时间戳
getCurrentTimeStamp: function () {
return Date.parse(new Date())
}
}
这是十分常用的 Local Storage 封装方法,赋予了其过期时间和自动序列化反序列化的能力,此时我们便无需再关心存储数据的格式问题。
// 存储
let userinfo = { name: 'juejin', age: 18 }
storage.setStorage('userinfo', userinfo)
// 获取
storage.getStorage('userinfo') // { name: 'juejin', age: 18 }
目前 npm 市场上也有相关封装 Web Storage 的包可以进行使用,比如 web-storage-cache (opens new window)。
IndexedDB 存储方案
通过使用 Web Storage,我们实现了网页间数据的临时和持久化存储,但和大容量的数据库相比 Web Storage 存储的空间还是相对有限,此时最终的解决方案便是 —— IndexedDB。
IndexedDB 是一个大规模的 NoSQL 存储系统,它几乎可以存储浏览器中的任何数据内容,包括二进制数据(ArrayBuffer 对象和 Blob 对象),其可以存储不少于 250M 的数据。
在使用 IndexedDB 前,我们需要判断浏览器是否支持:
if (!('indexedDB' in window)) {
console.log('浏览器不支持 indexedDB')
return
}
在浏览器支持的前提下,我们便可以对其进行增删改查操作。首先我们先得打开或者创建数据库:
let idb
// 打开名为 juejin,版本号为 1 的数据库,如果不存在则自动创建
let request = window.indexedDB.open('juejin', 1)
// 错误回调
request.onerror = function (event) {
console.log('打开数据库失败')
}
// 成功回调
request.onsuccess = function (event) {
idb = request.result
console.log('打开数据库成功')
}
如果是新建数据库那么会触发版本变化的 onupgradeneeded 方法,因为此时版本是从有到无的:
request.onupgradeneeded = function(e) {
idb = e.target.result;
console.log('running onupgradeneeded')
// 新建对象表时,先判断该表是否存在
if (!idb.objectStoreNames.contains('store')) {
// 创建名为 store 的表,以 id 为主键
let storeOS = idb.createObjectStore('store', { keyPath: 'id' })
}
};
当我们创建完数据库表(仓库)后,就可以对其进行数据的新增操作:
// 新增方法
function addItem(item) {
// 新增时必须指定表名和操作模式
let transaction = idb.transaction(['store'], 'readwrite')
// 获取表对象
let store = transaction.objectStore('store')
// 调用 add 方法新增数据
store.add(item)
}
let data = {
id: 1, // 主键 id
name: 'test',
age: '18',
}
addItem(data) // 调用新增方法
通过主键 id 我们可以方便的获取到想要的数据:
// 读取方法
function readItem(id) {
// 创建事务,指定表名
let transaction = idb.transaction(['store'])
// 获取表对象
let store = transaction.objectStore('store')
// 调用 get 方法获取数据
let requestStore = store.get(id)
requestStore.onsuccess = function() {
if (requestStore.result) {
console.log(requestStore.result) // { id: 1, name: 'test', age: '18' }
}
}
}
readItem(1) // 获取主键 id 为 1 的数据
更多关于 IndexedDB 的 API 大家可以参考 w3 的文档:www.w3.org/TR/IndexedD… (opens new window)
当然我们也可以不必使用原始的 API 像上面那样进行比较繁琐的操作,目前 npm 市场上比较流行的封装 IndexedDB 的包 idb (opens new window) 可以简化原始 API 的操作流程。比如使用 idb 库后我们可以将上述创建数据库、新增和读取方法换成类似 localStorage 一样的同步方式:
import { openDB } from 'idb'
const dbPromise = openDB('juejin', 1, {
upgrade(db) {
db.createObjectStore('store', { keyPath: 'id' })
},
})
// 新增方法
export async function add(val) {
return (await dbPromise).add('store', val)
}
// 读取方法
export async function get(key) {
return (await dbPromise).get('store', key)
}
相对于 Cookie 和 Web Storage,IndexedDB 目前在不同浏览器中的兼容性并不是那么好,因此使用 IndexedDB 时还需进行权衡,遵循渐进增强原则。
