# 设计模式
# 一、基础篇
# this、new、bind、call、apply
1. this 指向的类型
刚开始学习 JavaScript 的时候,
this总是最能让人迷惑,下面我们一起看一下在 JavaScript 中应该如何确定 this 的指向。this是在函数被调用时确定的,它的指向完全取决于函数调用的地方,而不是它被声明的地方(除箭头函数外)。当一个函数被调用时,会创建一个执行上下文,它包含函数在哪里被调用(调用栈)、函数的调用方式、传入的参数等信息,this 就是这个记录的一个属性,它会在函数执行的过程中被用到。
this 在函数的指向有以下几种场景:
- 作为构造函数被 new 调用;
- 作为对象的方法使用;
- 作为函数直接调用;
- 被
call、apply、bind调用; - 箭头函数中的
this;
1.1 new 绑定
函数如果作为构造函数使用
new调用时,this绑定的是新创建的构造函数的实例。
function Foo() {
console.log(this)
}
var bar = new Foo() // 输出: Foo 实例,this 就是 bar
实际上使用
new调用构造函数时,会依次执行下面的操作:
- 创建一个新对象;
- 构造函数的
prototype被赋值给这个新对象的__proto__; - 将新对象赋给当前的
this; - 执行构造函数;
- 如果函数没有返回其他对象,那么
new表达式中的函数调用会自动返回这个新对象,如果返回的不是对象将被忽略;
1.2 显式绑定
通过
call、apply、bind我们可以修改函数绑定的this,使其成为我们指定的对象。通过这些方法的第一个参数我们可以显式地绑定this。
function foo(name, price) {
this.name = name
this.price = price
}
function Food(category, name, price) {
foo.call(this, name, price) // call 方式调用
// foo.apply(this, [name, price]) // apply 方式调用
this.category = category
}
new Food('食品', '汉堡', '5块钱')
// 浏览器中输出: {name: "汉堡", price: "5块钱", category: "食品"}
call 和 apply 的区别是 call 方法接受的是参数列表,而 apply 方法接受的是一个参数数组。
func.call(thisArg, arg1, arg2, ...) // call 用法
func.apply(thisArg, [arg1, arg2, ...]) // apply 用法
而
bind方法是设置this为给定的值,并返回一个新的函数,且在调用新函数时,将给定参数列表作为原函数的参数序列的前若干项。
func.bind(thisArg[, arg1[, arg2[, ...]]]) // bind 用法
举个例子:
var food = {
name: '汉堡',
price: '5块钱',
getPrice: function(place) {
console.log(place + this.price)
}
}
food.getPrice('KFC ') // 浏览器中输出: "KFC 5块钱"
var getPrice1 = food.getPrice.bind({ name: '鸡腿', price: '7块钱' }, '肯打鸡 ')
getPrice1() // 浏览器中输出: "肯打鸡 7块钱"
关于 bind 的原理,我们可以使用 apply 方法自己实现一个 bind 看一下:
// ES5 方式
Function.prototype.bind = Function.prototype.bind || function() {
var self = this
var rest1 = Array.prototype.slice.call(arguments)
var context = rest1.shift()
return function() {
var rest2 = Array.prototype.slice.call(arguments)
return self.apply(context, rest1.concat(rest2))
}
}
// ES6 方式
Function.prototype.bind = Function.prototype.bind || function(...rest1) {
const self = this
const context = rest1.shift()
return function(...rest2) {
return self.apply(context, [...rest1, ...rest2])
}
}
ES6方式用了一些ES6的知识比如rest参数、数组解构
注意: 如果你把 null 或 undefined 作为 this 的绑定对象传入 call、apply、bind,这些值在调用时会被忽略,实际应用的是默认绑定规则。
var a = 'hello'
function foo() {
console.log(this.a)
}
foo.call(null) // 浏览器中输出: "hello"
1.3 隐式绑定
函数是否在某个上下文对象中调用,如果是的话
this绑定的是那个上下文对象。
var a = 'hello'
var obj = {
a: 'world',
foo: function() {
console.log(this.a)
}
}
obj.foo() // 浏览器中输出: "world"
上面代码中,
foo方法是作为对象的属性调用的,那么此时foo方法执行时,this指向obj对象。也就是说,此时this指向调用这个方法的对象,如果嵌套了多个对象,那么指向最后一个调用这个方法的对象:
var a = 'hello'
var obj = {
a: 'world',
b:{
a:'China',
foo: function() {
console.log(this.a)
}
}
}
obj.b.foo() // 浏览器中输出: "China"
最后一个对象是
obj上的b,那么此时foo方法执行时,其中的this指向的就是b对象。
1.4 默认绑定
函数独立调用,直接使用不带任何修饰的函数引用进行调用,也是上面几种绑定途径之外的方式。非严格模式下 this 绑定到全局对象(浏览器下是
winodw,node环境是global),严格模式下this绑定到undefined(因为严格模式不允许this指向全局对象)。
var a = 'hello'
function foo() {
var a = 'world'
console.log(this.a)
console.log(this)
}
foo() // 相当于执行 window.foo()
// 浏览器中输出: "hello"
// 浏览器中输出: Window 对象
上面代码中,变量
a被声明在全局作用域,成为全局对象window的一个同名属性。函数foo被执行时,this此时指向的是全局对象,因此打印出来的a是全局对象的属性。
注意有一种情况:
var a = 'hello'
var obj = {
a: 'world',
foo: function() {
console.log(this.a)
}
}
var bar = obj.foo
bar() // 浏览器中输出: "hello"
此时
bar函数,也就是obj上的foo方法为什么又指向了全局对象呢,是因为bar方法此时是作为函数独立调用的,所以此时的场景属于默认绑定,而不是隐式绑定。这种情况和把方法作为回调函数的场景类似:
var a = 'hello'
var obj = {
a: 'world',
foo: function() {
console.log(this.a)
}
}
function func(fn) {
fn()
}
func(obj.foo) // 浏览器中输出: "hello"
- 参数传递实际上也是一种隐式的赋值,只不过这里
obj.foo方法是被隐式赋值给了函数func的形参fn,而之前的情景是自己赋值,两种情景实际上类似。这种场景我们遇到的比较多的是setTimeout和setInterval,如果回调函数不是箭头函数,那么其中的this指向的就是全局对象. - 其实我们可以把默认绑定当作是隐式绑定的特殊情况,比如上面的
bar(),我们可以当作是使用window.bar()的方式调用的,此时 bar 中的this根据隐式绑定的情景指向的就是window。
2. this 绑定的优先级
this存在多个使用场景,那么多个场景同时出现的时候,this到底应该如何指向呢。这里存在一个优先级的概念,this根据优先级来确定指向。优先级:new 绑定 > 显示绑定 > 隐式绑定 > 默认绑定
所以 this 的判断顺序:
new绑定: 函数是否在new中调用?如果是的话this绑定的是新创建的对象;- 显式绑定: 函数是否是通过
bind、call、apply调用?如果是的话,this绑定的是指定的对象; - 隐式绑定: 函数是否在某个上下文对象中调用?如果是的话,
this绑定的是那个上下文对象; - 如果都不是的话,使用默认绑定。如果在严格模式下,就绑定到
undefined,否则绑定到全局对象;
3. 箭头函数中的 this
- 箭头函数 是根据其声明的地方来决定
this的 - 箭头函数的
this绑定是无法通过call、apply、bind被修改的,且因为箭头函数没有构造函数constructor,所以也不可以使用 new 调用,即不能作为构造函数,否则会报错。
var a = 'hello'
var obj = {
a: 'world',
foo: () => {
console.log(this.a)
}
}
obj.foo() // 浏览器中输出: "hello"
4. 一个 this 的小练习
用一个小练习来实战一下:
var a = 20
var obj = {
a: 40,
foo:() => {
console.log(this.a)
function func() {
this.a = 60
console.log(this.a)
}
func.prototype.a = 50
return func
}
}
var bar = obj.foo() // 浏览器中输出: 20
bar() // 浏览器中输出: 60
new bar() // 浏览器中输出: 60
稍微解释一下:
var a = 20这句在全局变量window上创建了个属性a并赋值为20;- 首先执行的是
obj.foo(),这是一个箭头函数,箭头函数不创建新的函数作用域直接沿用语句外部的作用域,因此obj.foo()执行时箭头函数中this是全局window,首先打印出 window 上的属性 a 的值 20,箭头函数返回了一个原型上有个值为50的属性a的函数对象func给bar; - 继续执行的是
bar(),这里执行的是刚刚箭头函数返回的闭包func,其内部的this指向window,因此this.a修改了window.a的值为60并打印出来; - 然后执行的是
new bar(),根据之前的表述,new操作符会在func函数中创建一个继承了func原型的实例对象并用this指向它,随后this.a = 60又在实例对象上创建了一个属性a,在之后的打印中已经在实例上找到了属性a,因此就不继续往对象原型上查找了,所以打印出第三个60; - 如果把上面例子的箭头函数换成普通函数呢,结果会是什么样?
var a = 20
var obj = {
a: 40,
foo: function() {
console.log(this.a)
function func() {
this.a = 60
console.log(this.a)
}
func.prototype.a = 50
return func
}
}
var bar = obj.foo() // 浏览器中输出: 40
bar() // 浏览器中输出: 60
new bar() // 浏览器中输出: 60
# 闭包与高阶函数
1. 闭包
1.1 什么是闭包
当函数可以记住并访问所在的词法作用域时,就产生了闭包,即使函数是在当前词法作用域之外执行。
我们首先来看一个闭包的例子:
function foo() {
var a = 2
function bar() {
console.log(a)
}
return bar
}
var baz = foo()
baz() // 输出: 2
foo函数传递出了一个函数bar,传递出来的bar被赋值给baz并调用,虽然这时baz是在foo作用域外执行的,但baz在调用的时候可以访问到前面的bar函数所在的foo的内部作用域。- 由于
bar声明在foo函数内部,bar拥有涵盖foo内部作用域的闭包,使得foo的内部作用域一直存活不被回收。一般来说,函数在执行完后其整个内部作用域都会被销毁,因为JavaScript的GC(Garbage Collection)垃圾回收机制会自动回收不再使用的内存空间。但是闭包会阻止某些GC,比如本例中foo()执行完,因为返回的bar函数依然持有其所在作用域的引用,所以其内部作用域不会被回收。 - 注意: 如果不是必须使用闭包,那么尽量避免创建它,因为闭包在处理速度和内存消耗方面对性能具有负面影响。
1.2 利用闭包实现结果缓存(备忘模式)
备忘模式就是应用闭包的特点的一个典型应用。比如有个函数:
function add(a) {
return a + 1;
}
- 多次运行
add()时,每次得到的结果都是重新计算得到的,如果是开销很大的计算操作的话就比较消耗性能了,这里可以对已经计算过的输入做一个缓存。 - 所以这里可以利用闭包的特点来实现一个简单的缓存,在函数内部用一个对象存储输入的参数,如果下次再输入相同的参数,那就比较一下对象的属性,如果有缓存,就直接把值从这个对象里面取出来。
/* 备忘函数 */
function memorize(fn) {
var cache = {}
return function() {
var args = Array.prototype.slice.call(arguments)
var key = JSON.stringify(args)
return cache[key] || (cache[key] = fn.apply(fn, args))
}
}
/* 复杂计算函数 */
function add(a) {
return a + 1
}
var adder = memorize(add)
adder(1) // 输出: 2 当前: cache: { '[1]': 2 }
adder(1) // 输出: 2 当前: cache: { '[1]': 2 }
adder(2) // 输出: 3 当前: cache: { '[1]': 2, '[2]': 3 }
使用
ES6的方式会更优雅一些:
/* 备忘函数 */
function memorize(fn) {
const cache = {}
return function(...args) {
const key = JSON.stringify(args)
return cache[key] || (cache[key] = fn.apply(fn, args))
}
}
/* 复杂计算函数 */
function add(a) {
return a + 1
}
const adder = memorize(add)
adder(1) // 输出: 2 当前: cache: { '[1]': 2 }
adder(1) // 输出: 2 当前: cache: { '[1]': 2 }
adder(2) // 输出: 3 当前: cache: { '[1]': 2, '[2]': 3 }
稍微解释一下:
- 备忘函数中用
JSON.stringify把传给adder函数的参数序列化成字符串,把它当做cache的索引,将add函数运行的结果当做索引的值传递给cache,这样adder运行的时候如果传递的参数之前传递过,那么就返回缓存好的计算结果,不用再计算了,如果传递的参数没计算过,则计算并缓存fn.apply(fn, args),再返回计算的结果。 - 当然这里的实现如果要实际应用的话,还需要继续改进一下,比如:
- 缓存不可以永远扩张下去,这样太耗费内存资源,我们可以只缓存最新传入的
n个; - 在浏览器中使用的时候,我们可以借助浏览器的持久化手段,来进行缓存的持久化,比如
cookie、localStorage等; - 这里的复杂计算函数可以是过去的某个状态,比如对某个目标的操作,这样把过去的状态缓存起来,方便地进行状态回退。
- 复杂计算函数也可以是一个返回时间比较慢的异步操作,这样如果把结果缓存起来,下次就可以直接从本地获取,而不是重新进行异步请求。
注意:
cache不可以是Map,因为Map的键是使用===比较的,因此当传入引用类型值作为键时,虽然它们看上去是相等的,但实际并不是,比如[1]!==[1],所以还是被存为不同的键。
// X 错误示范
function memorize(fn) {
const cache = new Map()
return function(...args) {
return cache.get(args) || cache.set(args, fn.apply(fn, args)).get(args)
}
}
function add(a) {
return a + 1
}
const adder = memorize(add)
adder(1) // 2 cache: { [ 1 ] => 2 }
adder(1) // 2 cache: { [ 1 ] => 2, [ 1 ] => 2 }
adder(2) // 3 cache: { [ 1 ] => 2, [ 1 ] => 2, [ 2 ] => 3 }
2. 高阶函数
高阶函数就是输入参数里有函数,或者输出是函数的函数。
2.1 函数作为参数
如果你用过
setTimeout、setInterval、ajax请求,那么你已经用过高阶函数了,这是我们最常看到的场景:回调函数,因为它将函数作为参数传递给另一个函数。
比如
ajax请求中,我们通常使用回调函数来定义请求成功或者失败时的操作逻辑:
$.ajax("/request/url", function(result){
console.log("请求成功!")
})
在
Array、Object、String等等基本对象的原型上有很多操作方法,可以接受回调函数来方便地进行对象操作。这里举一个很常用的Array.prototype.filter()方法,这个方法返回一个新创建的数组,包含所有回调函数执行后返回true或真值的数组元素。
var words = ['spray', 'limit', 'elite', 'exuberant', 'destruction', 'present'];
var result = words.filter(function(word) {
return word.length > 6
}) // 输出: ["exuberant", "destruction", "present"]
回调函数还有一个应用就是钩子,如果你用过 Vue 或者 React 等框架,那么你应该对钩子很熟悉了,它的形式是这样的:
function foo(callback) {
// ... 一些操作
callback()
}
2.2 函数作为返回值
另一个经常看到的高阶函数的场景是在一个函数内部输出另一个函数,比如:
function foo() {
return function bar() {}
}
主要是利用闭包来保持着作用域:
function add() {
var num = 0
return function(a) {
return num = num + a
}
}
var adder = add()
adder(1) // 输出: 1
adder(2) // 输出: 3
1. 柯里化
- 柯里化(Currying),又称部分求值(Partial Evaluation),是把接受多个参数的原函数变换成接受一个单一参数(原函数的第一个参数)的函数,并且返回一个新函数,新函数能够接受余下的参数,最后返回同原函数一样的结果。
- 核心思想是把多参数传入的函数拆成单(或部分)参数函数,内部再返回调用下一个单(或部分)参数函数,依次处理剩余的参数。
柯里化有 3 个常见作用:
- 参数复用
- 提前返回
- 延迟计算/运行
- 先来看看柯里化的通用实现:
// ES5 方式
function currying(fn) {
var rest1 = Array.prototype.slice.call(arguments)
rest1.shift()
return function() {
var rest2 = Array.prototype.slice.call(arguments)
return fn.apply(null, rest1.concat(rest2))
}
}
// ES6 方式
function currying(fn, ...rest1) {
return function(...rest2) {
return fn.apply(null, rest1.concat(rest2))
}
}
用它将一个
sayHello函数柯里化试试:
// 接上面
function sayHello(name, age, fruit) {
console.log(console.log(`我叫 ${name},我 ${age} 岁了, 我喜欢吃 ${fruit}`))
}
var curryingShowMsg1 = currying(sayHello, '小明')
curryingShowMsg1(22, '苹果') // 输出: 我叫 小明,我 22 岁了, 我喜欢吃 苹果
var curryingShowMsg2 = currying(sayHello, '小衰', 20)
curryingShowMsg2('西瓜') // 输出: 我叫 小衰,我 20 岁了, 我喜欢吃 西瓜
更高阶的用法参见:JavaScript 函数式编程技巧 - 柯里化
2. 反柯里化
- 柯里化是固定部分参数,返回一个接受剩余参数的函数,也称为部分计算函数,目的是为了缩小适用范围,创建一个针对性更强的函数。核心思想是把多参数传入的函数拆成单参数(或部分)函数,内部再返回调用下一个单参数(或部分)函数,依次处理剩余的参数。
- 而反柯里化,从字面讲,意义和用法跟函数柯里化相比正好相反,扩大适用范围,创建一个应用范围更广的函数。使本来只有特定对象才适用的方法,扩展到更多的对象。
先来看看反柯里化的通用实现吧~
// ES5 方式
Function.prototype.unCurrying = function() {
var self = this
return function() {
var rest = Array.prototype.slice.call(arguments)
return Function.prototype.call.apply(self, rest)
}
}
// ES6 方式
Function.prototype.unCurrying = function() {
const self = this
return function(...rest) {
return Function.prototype.call.apply(self, rest)
}
}
如果你觉得把函数放在 Function 的原型上不太好,也可以这样:
// ES5 方式
function unCurrying(fn) {
return function (tar) {
var rest = Array.prototype.slice.call(arguments)
rest.shift()
return fn.apply(tar, rest)
}
}
// ES6 方式
function unCurrying(fn) {
return function(tar, ...argu) {
return fn.apply(tar, argu)
}
}
下面简单试用一下反柯里化通用实现,我们将
Array上的push方法借出来给arguments这样的类数组增加一个元素:
// 接上面
var push = unCurrying(Array.prototype.push)
function execPush() {
push(arguments, 4)
console.log(arguments)
}
execPush(1, 2, 3) // 输出: [1, 2, 3, 4]
简单说,函数柯里化就是对高阶函数的降阶处理,缩小适用范围,创建一个针对性更强的函数。
function(arg1, arg2) // => function(arg1)(arg2)
function(arg1, arg2, arg3) // => function(arg1)(arg2)(arg3)
function(arg1, arg2, arg3, arg4) // => function(arg1)(arg2)(arg3)(arg4)
function(arg1, arg2, ..., argn) // => function(arg1)(arg2)…(argn)
而反柯里化就是反过来,增加适用范围,让方法使用场景更大。使用反柯里化, 可以把原生方法借出来,让任何对象拥有原生对象的方法。
obj.func(arg1, arg2) // => func(obj, arg1, arg2)
可以这样理解柯里化和反柯里化的区别:
- 柯里化是在运算前提前传参,可以传递多个参数;
- 反柯里化是延迟传参,在运算时把原来已经固定的参数或者 this 上下文等当作参数延迟到未来传递。
- 更高阶的用法参见:JavaScript 函数式编程技巧 - 反柯里化
3. 偏函数
偏函数是创建一个调用另外一个部分(参数或变量已预制的函数)的函数,函数可以根据传入的参数来生成一个真正执行的函数。其本身不包括我们真正需要的逻辑代码,只是根据传入的参数返回其他的函数,返回的函数中才有真正的处理逻辑比如:
var isType = function(type) {
return function(obj) {
return Object.prototype.toString.call(obj) === `[object ${type}]`
}
}
var isString = isType('String')
var isFunction = isType('Function')
这样就用偏函数快速创建了一组判断对象类型的方法~
偏函数和柯里化的区别:
- 柯里化是把一个接受
n个参数的函数,由原本的一次性传递所有参数并执行变成了可以分多次接受参数再执行,例如:add = (x, y, z) => x + y + z→curryAdd = x => y => z => x + y + z; - 偏函数固定了函数的某个部分,通过传入的参数或者方法返回一个新的函数来接受剩余的参数,数量可能是一个也可能是多个;
- 当一个柯里化函数只接受两次参数时,比如
curry()(),这时的柯里化函数和偏函数概念类似,可以认为偏函数是柯里化函数的退化版
# ES6
1. let、const
一个显而易见特性是 let 声明的变量还可以更改,而 const 一般用来声明常量,声明之后就不能更改了:
let foo = 1;
const bar = 2;
foo = 3;
bar = 3; // 报错 TypeError
1.1 作用域差别
刚学 JavaScript 的时候,我们总是看到类似于「JavaScript 中没有块级作用域,只有函数作用域」的说法。举个例子:
var arr = [];
for (var i = 0; i < 4; i++) {
arr[i] = function () {
console.log(i)
}
}
arr[2]() // 期望值:2,输出: 4
因为
i变量是var命令声明的,var声明的变量的作用域是函数作用域,因此此时 i 变量是在全局范围内都有效,也就是说全局只有一个变量 i,每次循环只是修改同一个变量 i 的值。虽然函数的定义是在循环中进行,但是每个函数的 i 都指向这个全局唯一的变量 i。在函数执行时,for 循环已经结束,i 最终的值是 4,所以无论执行数组里的哪个函数,结果都是 i 最终的值 4。
ES6 引入的 let、const 声明的变量是仅在块级作用域中有效:
var arr = [];
for (let i = 0; i < 4; i++) {
arr[i] = function () {
console.log(i)
}
}
arr[2]() // 期望值:2,输出: 2
这个代码中,变量
i是let声明的,也就是说i只在本轮循环有效,所以每次循环i都是一个新的变量,最后输出的是 2。
那如果我们不使用
ES6的let、const怎样去实现?可以使用函数的参数来缓存变量的值,让闭包在执行时索引到的变量为函数作用域中缓存的函数参数变量值:
var arr = []
for (var i = 0; i < 4; i++) {
(function(j) {
arr[i] = function(j) {
console.log(j)
}
})(i)
}
arr[2]() // 输出: 2
这个做法归根结底还是使用函数作用域来变相实现块级作用域,事实上 Babel 编译器也是使用这个做法,我们来看看 Babel 编译的结果:
// 编译前,ES6 语法
var arr = [];
for (let i = 0; i < 4; i++) {
arr[i] = function () {
console.log(i)
}
}
arr[2]() // 输出: 2
// 编译后,Babel 编译后的 ES5 语法
"use strict";
var arr = [];
var _loop = function _loop(i) {
arr[i] = function () {
console.log(i);
};
};
for (var i = 0; i < 4; i++) {
_loop(i);
}
arr[2](); // 输出: 2
可以看到 Babel 编译后的代码,也是使用了这个做法。
1.2 不存在变量提升
var命令声明的变量会发生变量提升的现象,也就是说变量在声明之前使用,其值为undefined,function声明的函数也是有这样的特性。而let、const命令声明的变量没有变量提升,如果在声明之前使用,会直接报错。
// var 命令存在变量提升
console.log(tmp) // undefined
var tmp = 1
console.log(tmp) // 1
// let、const 命令不存在变量提升
console.log(boo) // 报错 ReferenceError
let boo = 2
1.3 暂时性死区
在一个块级作用域中对一个变量使用
let、const声明前,该变量都是不可使用的,这被称为暂时性死区(Temporal Dead Zone, TDZ):
tmp = 'asd';
if (true) {
// 虽然在这之前定义了一个全局变量 tmp,但是块内重新定义了一个 tmp
console.log(tmp); // 报错 ReferenceError
let tmp;
}
1.4 不允许重复声明
let、const命令是不允许重复声明同一个变量的:
if (true) {
let tmp;
let tmp; // 报错 SyntaxError
}
function func(arg) { // 因为已经有一个 arg 变量名的形参了
let arg;
}
func() // 报错 SyntaxError
2. 箭头函数
2.1 基本用法
ES6 中可以使用箭头函数来定义函数。下面例子中,同名函数的定义是等价的:
// 基础用法
const test1 = function (参数1, 参数2, …, 参数N) { 函数声明 }
const test1 = (参数1, 参数2, …, 参数N) => { 函数声明 }
// 当只有一个参数时,圆括号是可选的
const test2 = (单一参数) => { 函数声明 }
const test2 = 单一参数 => { 函数声明 }
// 没有参数时,圆括号不能省略
const test3 = () => { 函数声明 }
// 当函数体只是 return 一个单一表达式时,可以省略花括号和 return 关键词
const test4 = () { return 表达式(单一) }
const test4 = () => 表达式(单一)
// 函数体返回对象字面表达式时,如果省略花括号和 return 关键词,返回值需要加括号
const test5 = () => { return {foo: 'bar'} }
const test5 = () => ({foo: 'bar'}) // 输出 {foo: 'bar'}
const test6 = () => {foo: 'bar'} // 输出 undefined,大括号被识别为代码块
总结:
- 参数如果只有一个,可以不加圆括号
(); - 没有参数时,不能省略圆括号
(); - 如果函数体只返回单一表达式,那么函数体可以不使用大括号
{}和return,直接写表达式即可; - 在 3 的基础上,如果返回值是一个对象字面量,那么返回值需要加圆括号
(),避免被识别为代码块。
2.2 箭头函数中的 this
箭头函数出来之前,函数在执行时才能确定
this的指向,所以会经常出现闭包中的this指向不是期望值的情况。在以前的做法中,如果要给闭包指定this,可以用bind\call\apply,或者把this值分配给封闭的变量(一般是that)。箭头函数出来之后,给我们提供了不一样的选择。
箭头函数不会创建自己的 this,只会从自己定义位置的作用域的上一层直接继承 this。
function Person(){
this.age = 10;
setInterval(() => {
this.age++; // this 正确地指向 p 实例
}, 1000);
}
var p = new Person(); // 1s后打印出 10
另外因为箭头函数没有自己的
this指针,因此对箭头函数使用call、apply、bind时,只能传递函数,不能绑定this,它们的第一个参数将被忽略:
this.param = 1
const func1 = () => console.log(this.param)
const func2 = function() {
console.log(this.param)
}
func1.apply({ param: 2 }) // 输出: 1
func2.apply({ param: 2 }) // 输出: 2
总结一下:
- 箭头函数中的
this就是定义时所在的对象,而不是使用时所在的对象; - 无法作为构造函数,不可以使用
new命令,否则会抛错; - 箭头函数中不存在
arguments对象,但我们可以通过Rest参数来替代; - 箭头函数无法使用
yield命令,所以不能作为Generator函数; - 不可以通过
bind、call、apply绑定this,但是可以通过call、apply传递参数。
3. class 语法
在
class语法出来之前,我们一般通过上一章介绍的一些方法,来间接实现面向对象三个要素:封装、继承、多态。ES6 给我们提供了更面向对象(更OO,Object Oriented)的写法,我们可以通过class关键字来定义一个类。
基本用法:
// ES5 方式定义一个类
function Foo() { this.kind = 'foo' }
Foo.staticMethod = function() { console.log('静态方法') }
Foo.prototype.doThis = function() { console.log(`实例方法 kind:${ this.kind }`) }
// ES6 方式定义一个类
class Foo {
/* 构造函数 */
constructor() { this.kind = 'foo' }
/* 静态方法 */
static staticMethod() { console.log('静态方法') }
/* 实例方法 */
doThis() {
console.log(`实例方法 kind:${ this.kind }`)
}
}
ES6 方式实现继承:
// 接上
class Bar extends Foo {
constructor() {
super()
this.type = 'bar'
}
doThat() {
console.log(`实例方法 type:${ this.type } kind:${ this.kind }`)
}
}
const bar = new Bar()
bar.doThat() // 实例方法 type:bar kind:foo
总结一下:
static关键字声明的是静态方法,不会被实例继承,只可以直接通过类来调用;class没有变量提升,因此必须在定义之后才使用;constructor为构造函数,子类构造函数中的super代表父类的构造函数,必须执行一次,否则新建实例时会抛错;new.target一般用在构造函数中,返回new命令作用于的那个构造函数;class用extends来实现继承,子类继承父类所有实例方法和属性。
4. 解构赋值
ES6 允许按照一定方式,从数组和对象中提取值。本质上这种写法属于模式匹配,只要等号两边的模式相同,左边的变量就会被赋予相对应的值。
数组解构基本用法:
let [a, b, c] = [1, 2, 3] // a:1 b:2 c:3
let [a, [[b], c]] = [1, [[2], 3]] // a:1 b:2 c:3
let [a, , b] = [1, 2, 3] // a:1 b:3
let [a,...b] = [1, 2, 3] // a:1 b:[2, 3]
let [a, b,...c] = [1] // a:1 b:undefined c:[]
let [a, b = 4] = [null, undefined] // a:null b:4
let [a, b = 4] = [1] // a:1 b:4
let [a, b = 4] = [1, null] // a:1 b:null
- 解构不成功,变量的值为
undefined; - 解构可以指定默认值,如果被解构变量的对应位置没有值,即为空,或者值为
undefined,默认值才会生效。
对象解构基本用法:
let { a, b } = { a: 1, b: 2 } // a:1 b:2
let { c } = { a: 1, b: 2 } // c:undefined
let { c = 4 } = { a: 1, b: 2 } // c:4
let { a: c } = { a: 1, b: 2 } // c:1
let { a: c = 4, d: e = 5 } = { a: 1, b: 2 } // c:1 e:5
let { length } = [1, 2] // length:2
- 解构不成功,变量的值为
undefined; - 解构可以指定默认值,如果被解构变量严格为
undefined或为空,默认值才会生效; - 如果变量名和属性名不一致,可以赋给其它名字的变量
{a:c},实际上对象解构赋值{a}是简写{a:a},对象的解构赋值是先找到同名属性,再赋给对应的变量,真正被赋值的是后者。
5. 扩展运算符
扩展运算符和
Rest参数的形式一样...,作用相当于Rest参数的逆运算。它将一个数组转化为逗号分割的参数序列。事实上实现了迭代器(Iterator)接口的对象都可以使用扩展运算符,包括Array、String、Set、Map、NodeList、arguments等。
数组可以使用扩展运算符:
console.log(...[1, 2, 3]) // 1 2 3
console.log(1, ...[2, 3, 4], 5) // 1 2 3 4 5
[...document.querySelectorAll('div')] // [<div>, <div>, <div>]
[...[1], ...[2, 3]] // [1, 2, 3]
const arr = [1]
arr.push(...[2, 3]) // arr:[1, 2, 3]
对象也可以使用扩展运算符,通常被用来合并对象:
{...{a: 1}, ...{a: 2, b: 3}} // {a: 2, b: 3}
6. 默认参数
ES6 允许给函数的参数设置默认值,如果不传递、或者传递为 undefined 则会采用默认值:
function log(x, y = 'World') {
console.log(x, y)
}
log('Hello') // Hello World
log('Hello', undefined) // Hello World
log('Hello', 'China') // Hello China
log(undefined, 'China') // undefined China
log(, 'China') // 报错 SyntaxError
log('Hello', '') // Hello
log('Hello', null) // Hello null
注意:
- 参数不传递或者传递
undefined会让参数等于默认值,但是如果参数不是最后一个,不传递参数会报错; - 特别注意,传递
null不会让函数参数等于默认值。 - 默认参数可以和解构赋值结合使用:
function log({x, y = 'World'} = {}) {
console.log(x, y)
}
log({x: 'hello'}) // hello World
log({x: 'hello',y: 'China'}) // hello China
log({y: 'China'}) // undefined "China"
log({}) // undefined "World"
log() // undefined "World"
分析一下后两种情况:
- 传递参数为
{}时,因为被解构变量既不为空,也不是undefined,所以不会使用解构赋值的默认参数{}。虽然最终形参的赋值过程还是{x, y = 'World'} = {},但是这里等号右边的空对象是调用时传递的,而不是形参对象的默认值; - 不传参时,即被解构变量为空,那么会使用形参的默认参数
{},形参的赋值过程相当于{x, y = 'World'} = {},注意这里等号右边的空对象,是形参对象的默认值。 - 上面是给被解构变量的整体设置了一个默认值
{}。下面细化一下,给默认值{}中的每一项也设置默认值:
function log({x, y} = {x: 'yes', y: 'World'}) {
console.log(x, y)
}
log({x: 'hello'}) // hello undefined
log({x: 'hello',y: 'China'}) // hello China
log({y: 'China'}) // undefined "China"
log({}) // undefined undefined
log() // yes World
也分析一下后两种情况:
- 传递参数为
{}时,被解构变量不为空,也不为undefined,因此不使用默认参数{x, y: 'World'},形参的赋值过程相当于{x, y} = {},所以 x 与 y 都是undefined; - 不传参时,等式右边采用默认参数,形参赋值过程相当于
{x, y} = {x: 'yes', y: 'World'}。
7. Rest 参数
我们知道
arguments是类数组,没有数组相关方法。为了使用数组上的一些方法,我们需要先 用Array.prototype.slice.call(arguments)或者[...arguments]来将arguments类数组转化为数组。
ES6 允许我们通过 Rest 参数来获取函数的多余参数:
// 获取函数所有的参数,rest 为数组
function func1(...rest){ /* ... */}
// 获取函数第一个参数外其他的参数,rest 为数组
function func1(val, ...rest){ /* ... */}
注意,
Rest参数只能放在最后一个,否则会报错:
// 报错 SyntaxError: Rest 参数必须是最后一个参数
function func1(...rest, a){ /* ... */}
形参名并不必须是
rest,也可以是其它名称,使用者可以根据自己的习惯来命名
# 继承与原型链
JavaScript 是一种灵活的语言,兼容并包含面向对象风格、函数式风格等编程风格。我们知道面向对象风格有三大特性和六大原则,三大特性是封装、继承、多态,六大原则是单一职责原则(SRP)、开放封闭原则(OCP)、里氏替换原则(LSP)、依赖倒置原则(DIP)、接口分离原则(ISP)、最少知识原则(LKP)。
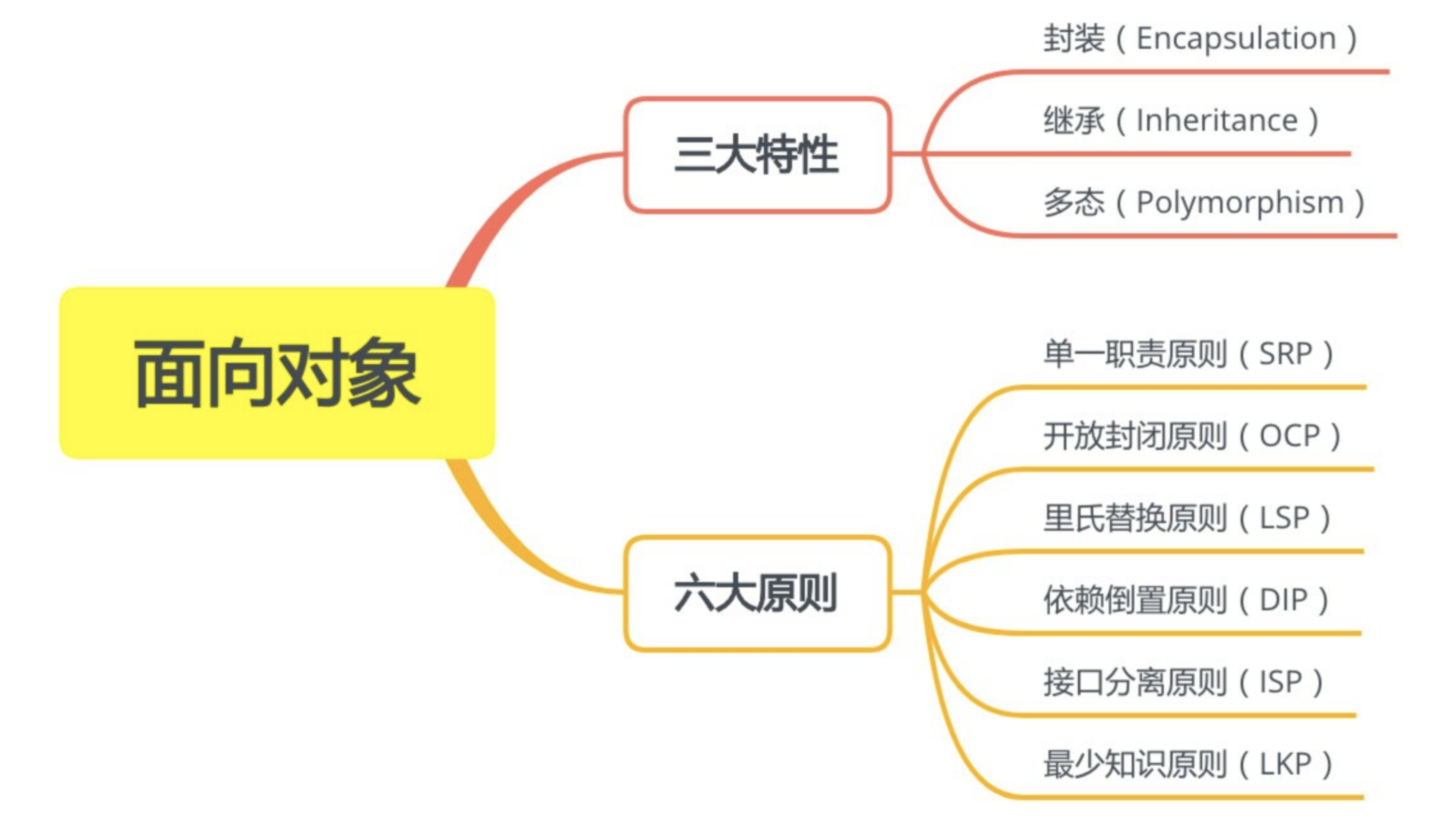
JavaScript并不是强面向对象语言,因此它的灵活性决定了并不是所有面向对象的特征都适合 JavaScript 开发,本教程将会着重介绍三大特性中的继承,和六大原则里的单一职责原则、开放封闭原则、最少知识原则
1. 原型对象链
JavaScript 内建的继承方法被称为原型对象链,又称为原型对象继承。对于一个对象,因为它继承了它的原型对象的属性,所以它可以访问到这些属性。同理,原型对象也是一个对象,它也有自己的原型对象,因此也可以继承它的原型对象的属性。
这就是原型继承链:对象继承其原型对象,而原型对象继承它的原型对象,以此类推。
2. 对象继承
使用对象字面量形式创建对象时,会隐式指定
Object.prototype为新对象的[[Prototype]]。使用Object.create()方式创建对象时,可以显式指定新对象的[[Prototype]]。该方法接受两个参数:第一个参数为新对象的[[Prototype]],第二个参数描述了新对象的属性,格式如在Object.defineProperties()` 中使用的一样。
// 对象字面量形式,原型被隐式地设置为 Object.prototype
var rectangle = { sizeType: '四边形' }
// Object.create() 创建,显示指定为 Object.prototype, 等价于 ↑
var rectangle = Object.create(Object.prototype, {
sizeType: {
configurable: true,
enumerable: true,
value: '四边形',
writable: true
}
})
我们可以用这个方法来实现对象继承:
var rectangle = {
sizeType: '四边形',
getSize: function() {
console.log(this.sizeType)
}
}
var square = Object.create(rectangle, {
sizeType: { value: '正方形' }
})
rectangle.getSize() // "四边形"
square.getSize() // "正方形"
console.log(rectangle.hasOwnProperty('getSize')) // true
console.log(rectangle.isPrototypeOf(square)) // true
console.log(square.hasOwnProperty('getSize')) // false
console.log('getSize' in square) // true
console.log(square.__proto__ === rectangle) // true
console.log(square.__proto__.__proto__ === Object.prototype) // true

- 对象
square继承自对象rectangle,也就继承了rectangle的sizeType属性和getSize()方法,又通过重写sizeType属性定义了一个自有属性,隐藏并替代了原型对象中的同名属性。所以rectangle.getSize()输出 「四边形」 而square.getSize()输出 「正方形」。 - 在访问一个对象的时候,JavaScript 引擎会执行一个搜索过程,如果在对象实例上发现该属性,该属性值就会被使用,如果没有发现则搜索其原型对象
[[Prototype]],如果仍然没有发现,则继续搜索该原型对象的原型对象[[Prototype]],直到继承链顶端,顶端通常是一个Object.prototype,其[[prototype]]为null。这就是原型链的查找过程。 - 可以通过
Object.create()创建[[Prototype]]为null的对象:var obj = Object.create(null)。对象obj是一个没有原型链的对象,这意味着toString()和valueOf等存在于Object原型上的方法同样不存在于该对象上,通常我们将这样创建出来的对象为纯净对象。
3. 原型链继承
- JavaScript 中的对象继承是构造函数继承的基础,几乎所有的函数都有
prototype属性(通过Function.prototype.bind方法构造出来的函数是个例外),它可以被替换和修改。 - 函数声明创建函数时,函数的
prototype属性被自动设置为一个继承自Object.prototype的对象,该对象有个自有属性constructor,其值就是函数本身。
// 构造函数
function YourConstructor() {}
// JavaScript 引擎在背后做的:
YourConstructor.prototype = Object.create(Object.prototype, {
constructor: {
configurable: true,
enumerable: true,
value: YourConstructor,
writable: true
}
})
console.log(YourConstructor.prototype.__proto__ === Object.prototype) // true
JavaScript 引擎帮你把构造函数的
prototype属性设置为一个继承自Object.prototype的对象,这意味着我们创建出来的构造函数都继承自Object.prototype。由于prototype可以被赋值和改写,所以通过改写它来改变原型链:
/* 四边形 */
function Rectangle(length, width) {
this.length = length // 长
this.width = width // 宽
}
/* 获取面积 */
Rectangle.prototype.getArea = function() {
return this.length * this.width
}
/* 获取尺寸信息 */
Rectangle.prototype.getSize = function() {
console.log(`Rectangle: ${ this.length }x${ this.width },面积: ${ this.getArea() }`)
}
/* 正方形 */
function Square(size) {
this.length = size
this.width = size
}
Square.prototype = new Rectangle()
Square.prototype.constructor = Square // 原本为 Rectangle,重置回 Square 构造函数
Square.prototype.getSize = function() {
console.log(`Square: ${ this.length }x${ this.width },面积: ${ this.getArea() }`)
}
var rect = new Rectangle(5, 10)
var squa = new Square(6)
rect.getSize() // Rectangle: 5x10,面积: 50
squa.getSize() // Square: 6x6,面积: 36
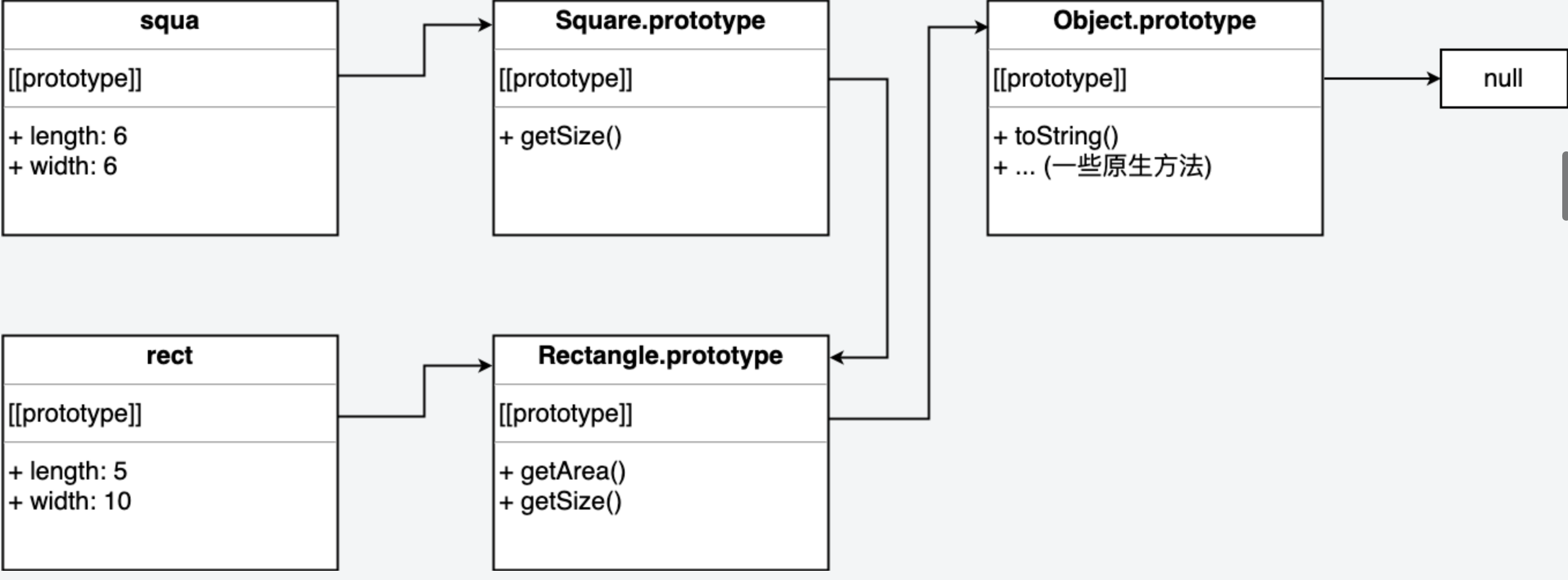
- 为什么使用
Square.prototype = new Rectangle()而不用Square.prototype = Rectangle.prototype呢。这是因为后者使得两个构造函数的prototype指向了同一个对象,当修改其中一个函数的 prototype 时,另一个函数也会受影响。 - 所以
Square构造函数的prototype属性被改写为了Rectagle的一个实例。 - 但是仍然有问题。当一个属性只存在于构造函数的
prototype上,而构造函数本身没有时,该属性会在构造函数的所有实例间共享,其中一个实例修改了该属性,其他所有实例都会受影响:
/* 四边形 */
function Rectangle(sizes) {
this.sizes = sizes
}
/* 正方形 */
function Square() {}
Square.prototype = new Rectangle([1, 2])
var squa1 = new Square() // sizes: [1, 2]
squa1.sizes.push(3) // 在 squa1 中修改了 sizes
console.log(squa1.sizes) // sizes: [1, 2, 3]
var squa2 = new Square()
console.log(squa2.sizes) // sizes: [1, 2, 3] 应该是 [1, 2],得到的是修改后的 sizes
4. 构造函数窃取
构造函数窃取又称构造函数借用、经典继承。这种技术的基本思想相当简单,即在子类型构造函数的内部调用父类构造函数。
function getArea() {
return this.length * this.width
}
/* 四边形 */
function Rectangle(length, width) {
this.length = length
this.width = width
}
/* 获取面积 */
Rectangle.prototype.getArea = getArea
/* 获取尺寸信息 */
Rectangle.prototype.getSize = function() {
console.log(`Rectangle: ${ this.length }x${ this.width },面积: ${ this.getArea() }`)
}
/* 正方形 */
function Square(size) {
Rectangle.call(this, size, size)
this.getArea = getArea
this.getSize = function() {
console.log(`Square: ${ this.length }x${ this.width },面积: ${ this.getArea() }`)
}
}
var rect = new Rectangle(5, 10)
var squa = new Square(6)
rect.getSize() // Rectangle: 5x10,面积: 50
squa.getSize() // Square: 6x6,面积: 36
- 这样的实现避免了引用类型的属性被所有实例共享的问题,在父类实例创建时还可以自定义地传参,缺点是方法都是在构造函数中定义,每次创建实例都会重新赋值一遍方法,即使方法的引用是一致的。
- 这种方式通过构造函数窃取来设置属性,模仿了那些基于类的语言的类继承,所以这通常被称为伪类继承或经典继承。
5. 组合继承
组合继承又称伪经典继承,指的是将原型链和借用构造函数的技术组合发挥二者之长的一种继承模式。其背后的思路是使用原型链实现对原型属性和方法的继承,而通过借用构造函数来实现对实例属性的继承。这样,既通过在原型上定义方法实现了函数复用,又能够保证每个实例都有它自己的属性。
/* 四边形 */
function Rectangle(length, width) {
this.length = length
this.width = width
this.color = 'red'
}
/* 获取面积 */
Rectangle.prototype.getArea = function() {
return this.length * this.width
}
/* 获取尺寸信息 */
Rectangle.prototype.getSize = function() {
console.log(`Rectangle: ${ this.length }x${ this.width },面积: ${ this.getArea() }`)
}
/* 正方形 */
function Square(size) {
Rectangle.call(this, size, size) // 第一次调用 Rectangle 函数
this.color = 'blue'
}
Square.prototype = new Rectangle() // 第二次调用 Rectangle 函数
Square.prototype.constructor = Square
Square.prototype.getSize = function() {
console.log(`Square: ${ this.length }x${ this.width },面积: ${ this.getArea() }`)
}
var rect = new Rectangle(5, 10)
var squa = new Square(6)
rect.getSize() // Rectangle: 5x10,面积: 50
squa.getSize() // Square: 6x6,面积: 36
组合继承是 JavaScript 中最常用的继承模式,但是父类构造函数被调用了两次。
6. 寄生组合式继承
/* 实现继承逻辑 */
function inheritPrototype(sub, sup) {
var prototype = Object.create(sup.prototype)
prototype.constructor = sub
sub.prototype = prototype
}
/* 四边形 */
function Rectangle(length, width) {
this.length = length
this.width = width
this.color = 'red'
}
/* 获取面积 */
Rectangle.prototype.getArea = function() {
return this.length * this.width
}
/* 获取尺寸信息 */
Rectangle.prototype.getSize = function() {
console.log(`Rectangle: ${ this.length }x${ this.width },面积: ${ this.getArea() }`)
}
/* 正方形 */
function Square(size) {
Rectangle.call(this, size, size) // 第一次调用 Rectangle 函数
this.color = 'blue'
}
// 实现继承
inheritPrototype(Square, Rectangle)
Square.prototype.getSize = function() {
console.log(`Square: ${ this.length }x${ this.width },面积: ${ this.getArea() }`)
}
var rect = new Rectangle(5, 10)
var squa = new Square(6)
rect.getSize() // Rectangle: 5x10,面积: 50
squa.getSize() // Square: 6x6,面积: 36
- 这种方式的高效率体现它只调用了一次父类构造函数,并且因此避免了在
Rectangle.prototype上面创建不必要的、多余的属性。与此同时,原型链还能保持不变。因此,还能够正常使用instanceof和isPrototypeOf。开发人员普遍认为寄生组合式继承是引用类型最理想的继承范式。 - 不过这种实现有些麻烦,推介使用组合继承和下面的 ES6 方式实现继承。
7. ES6 的 extends 方式实现继承
ES6中引入了class关键字,class之间可以通过extends关键字实现继承,这比 ES5 的通过修改原型链实现继承,要清晰、方便和语义化的多。
/* 四边形 */
class Rectangle {
constructor(length, width) {
this.length = length
this.width = width
this.color = 'red'
}
/* 获取面积 */
getArea() {
return this.length * this.width
}
/* 获取尺寸信息 */
getSize() {
console.log(`Rectangle: ${ this.length }x${ this.width },面积: ${ this.getArea() }`)
}
}
/* 正方形 */
class Square extends Rectangle {
constructor(size) {
super(size, size)
this.color = 'blue'
}
getSize() {
console.log(`Square: ${ this.length }x${ this.width },面积: ${ this.getArea() }`)
}
}
var rect = new Rectangle(5, 10)
var squa = new Square(6)
rect.getSize() // Rectangle: 5x10,面积: 50
squa.getSize() // Square: 6x6,面积: 36
然而并不是所有浏览器都支持
class/extends关键词,不过我们可以引入Babel来进行转译。class语法实际上也是之前语法的语法糖,用户可以把上面的代码放到 Babel 的在线编译中看看,编译出来是什么样子
# 设计原则
在前文我们介绍了面向对象三大特性之继承,本文将主要介绍面向对象六大原则中的单一职责原则(SRP)、开放封闭原则(OCP)、最少知识原则(LKP)。
设计原则是指导思想,从思想上给我们指明程序设计的正确方向,是我们在开发设计过程中应该尽力遵守的准则。而设计模式是实现手段,因此设计模式也应该遵守这些原则,或者说,设计模式就是这些设计原则的一些具体体现。要达到的目标就是高内聚低耦合,高内聚是说模块内部要高度聚合,是模块内部的关系,低耦合是说模块与模块之间的耦合度要尽量低,是模块与模块间的关系。
注意,遵守设计原则是好,但是过犹不及,在实际项目中我们不要刻板遵守,需要根据实际情况灵活运用
1. 单一职责原则 SRP
- 单一职责原则 (Single Responsibility Principle, SRP)是指对一个类(方法、对象,下文统称对象)来说,应该仅有一个引起它变化的原因。也就是说,一个对象只做一件事。
- 单一职责原则可以让我们对对象的维护变得简单,如果一个对象具有多个职责的话,那么如果一个职责的逻辑需要修改,那么势必会影响到其他职责的代码。如果一个对象具有多种职责,职责之间相互耦合,对一个职责的修改会影响到其他职责的实现,这就是属于模块内低内聚高耦合的情况。负责的职责越多,耦合越强,对模块的修改就越来越危险。
优点:
- 降低单个类(方法、对象)的复杂度,提高可读性和可维护性,功能之间的界限更清晰; 类(方法、对象)之间根据功能被分为更小的粒度,有助于代码的复用;
- 缺点: 增加系统中类(方法、对象)的个数,实际上也增加了这些对象之间相互联系的难度,同时也引入了额外的复杂度。
2. 开放封闭原则 OCP
开放封闭原则 (Open-Close Principle, OCP)是指一个模块在扩展性方面应该是开放的,而在更改性方面应该是封闭的,也就是对扩展开放,对修改封闭。
当需要增加需求的时候,则尽量通过扩展新代码的方式,而不是修改已有代码。因为修改已有代码,则会给依赖原有代码的模块带来隐患,因此修改之后需要把所有依赖原有代码的模块都测试一遍,修改一遍测试一遍,带来的成本很大,如果是上线的大型项目,那么代价和风险可能更高。
优点:
- 增加可维护性,避免因为修改给系统带来的不稳定性。
3. 最少知识原则 LKP
- 最少知识原则 (Least Knowledge Principle, LKP)又称为迪米特原则 (Law of Demeter, LOD),一个对象应该对其他对象有最少的了解。
- 通俗地讲,一个类应该对自己需要耦合或调用的类知道得最少,类的内部如何实现、如何复杂都与调用者或者依赖者没关系,调用者或者依赖者只需要知道他需要的方法即可,其他的我一概不关心。类与类之间的关系越密切,耦合度越大,当一个类发生改变时,对另一个类的影响也越大。
- 通常为了减少对象之间的联系,是通过引入一个第三者来帮助进行通信,阻隔对象之间的直接通信,从而减少耦合。
优点:
- 降低类(方法、对象)之间不必要的依赖,减少耦合。
缺点:
- 类(方法、对象)之间不直接通信也会经过一个第三者来通信,那么就要权衡引入第三者带来的复杂度是否值得。
# 二、创建型模式
# 单例模式
- 单例模式可能是设计模式里面最简单的模式了,虽然简单,但在我们日常生活和编程中却经常接触到,本节我们一起来学习一下。
- 单例模式 (Singleton Pattern)又称为单体模式,保证一个类只有一个实例,并提供一个访问它的全局访问点。也就是说,第二次使用同一个类创建新对象的时候,应该得到与第一次创建的对象完全相同的对象。
1. 你曾经遇见过的单例模式
- 当我们在电脑上玩经营类的游戏,经过一番眼花缭乱的骚操作好不容易走上正轨,夜深了我们去休息,第二天打开电脑,发现要从头玩,立马就把电脑扔窗外了,所以一般希望从前一天的进度接着打,这里就用到了存档。每次玩这游戏的时候,我们都希望拿到同一个存档接着玩,这就是属于单例模式的一个实例。
- 编程中也有很多对象我们只需要唯一一个,比如数据库连接、线程池、配置文件缓存、浏览器中的 window/document 等,如果创建多个实例,会带来资源耗费严重,或访问行为不一致等情况。
- 类似于数据库连接实例,我们可能频繁使用,但是创建它所需要的开销又比较大,这时只使用一个数据库连接就可以节约很多开销。一些文件的读取场景也类似,如果文件比较大,那么文件读取就是一个比较重的操作。比如这个文件是一个配置文件,那么完全可以将读取到的文件内容缓存一份,每次来读取的时候访问缓存即可,这样也可以达到节约开销的目的。
在类似场景中,这些例子有以下特点:
- 每次访问者来访问,返回的都是同一个实例;
- 如果一开始实例没有创建,那么这个特定类需要自行创建这个实例;
2. 实例的代码实现
- 如果你是一个前端er,那么你肯定知道浏览器中的
window和document全局变量,这两个对象都是单例,任何时候访问他们都是一样的对象,window表示包含DOM文档的窗口,document是窗口中载入的DOM文档,分别提供了各自相关的方法。 - 在 ES6 新增语法的
Module模块特性,通过import/export导出模块中的变量是单例的,也就是说,如果在某个地方改变了模块内部变量的值,别的地方再引用的这个值是改变之后的。除此之外,项目中的全局状态管理模式 Vuex、Redux、MobX 等维护的全局状态,vue-router、react-router等维护的路由实例,在单页应用的单页面中都属于单例的应用(但不属于单例模式的应用)。 - 在 JavaScript 中使用字面量方式创建一个新对象时,实际上没有其他对象与其类似,因为新对象已经是单例了:
{ a: 1 } === { a: 1 } // false
- 那么问题来了,如何对构造函数使用 new 操作符创建多个对象时,仅获取同一个单例对象呢。
- 对于刚刚打经营游戏的例子,我们可以用 JavaScript 来实现一下:
function ManageGame() {
if (ManageGame._schedule) { // 判断是否已经有单例了
return ManageGame._schedule
}
ManageGame._schedule = this
}
ManageGame.getInstance = function() {
if (ManageGame._schedule) { // 判断是否已经有单例了
return ManageGame._schedule
}
return ManageGame._schedule = new ManageGame()
}
const schedule1 = new ManageGame()
const schedule2 = ManageGame.getInstance()
console.log(schedule1 === schedule2)
稍微解释一下,这个构造函数在内部维护(或者直接挂载自己身上)一个实例,第一次执行 new 的时候判断这个实例有没有创建过,创建过就直接返回,否则走创建流程。我们可以用
ES6的class语法改造一下:
class ManageGame {
static _schedule = null
static getInstance() {
if (ManageGame._schedule) { // 判断是否已经有单例了
return ManageGame._schedule
}
return ManageGame._schedule = new ManageGame()
}
constructor() {
if (ManageGame._schedule) { // 判断是否已经有单例了
return ManageGame._schedule
}
ManageGame._schedule = this
}
}
const schedule1 = new ManageGame()
const schedule2 = ManageGame.getInstance()
console.log(schedule1 === schedule2) // true
上面方法的缺点在于维护的实例作为静态属性直接暴露,外部可以直接修改。
3. 单例模式的通用实现
根据上面的例子提炼一下单例模式,游戏可以被认为是一个特定的类(Singleton),而存档是单例(instance),每次访问特定类的时候,都会拿到同一个实例。主要有下面几个概念:
Singleton:特定类,这是我们需要访问的类,访问者要拿到的是它的实例;instance:单例,是特定类的实例,特定类一般会提供 getInstance 方法来获取该单例;getInstance:获取单例的方法,或者直接由 new 操作符获取;
这里有几个实现点要关注一下:
- 访问时始终返回的是同一个实例;
- 自行实例化,无论是一开始加载的时候就创建好,还是在第一次被访问时;
- 一般还会提供一个 getInstance 方法用来获取它的实例;
结构大概如下图:
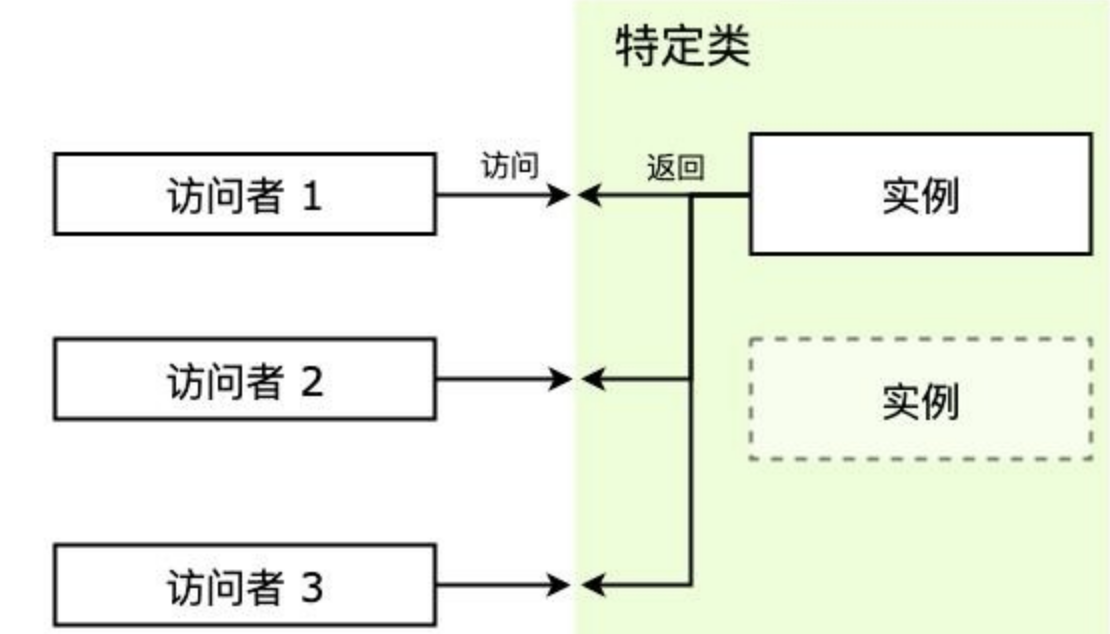
下面使用通用的方法来实现一下。
3.1 IIFE 方式创建单例模式
- 简单实现中,我们提到了缺点是实例会暴露,那么这里我们首先使用立即调用函数 IIFE 将不希望公开的单例实例 instance 隐藏。
- 当然也可以使用构造函数复写将闭包进行的更彻底,具体代码参看 Github 仓库,这里就不贴了。
const Singleton = (function() {
let _instance = null // 存储单例
const Singleton = function() {
if (_instance) return _instance // 判断是否已有单例
_instance = this
this.init() // 初始化操作
return _instance
}
Singleton.prototype.init = function() {
this.foo = 'Singleton Pattern'
}
return Singleton
})()
const visitor1 = new Singleton()
const visitor2 = new Singleton()
console.log(visitor1 === visitor2) // true
- 这样一来,虽然仍使用一个变量
_instance来保存单例,但是由于在闭包的内部,所以外部代码无法直接修改。 - 在这个基础上,我们可以继续改进,增加
getInstance静态方法:
const Singleton = (function() {
let _instance = null // 存储单例
const Singleton = function() {
if (_instance) return _instance // 判断是否已有单例
_instance = this
this.init() // 初始化操作
return _instance
}
Singleton.prototype.init = function() {
this.foo = 'Singleton Pattern'
}
Singleton.getInstance = function() {
if (_instance) return _instance
_instance = new Singleton()
return _instance
}
return Singleton
})()
const visitor1 = new Singleton()
const visitor2 = new Singleton() // 既可以 new 获取单例
const visitor3 = Singleton.getInstance() // 也可以 getInstance 获取单例
console.log(visitor1 === visitor2) // true
console.log(visitor1 === visitor3) // true
- 代价和上例一样是闭包开销,并且因为 IIFE 操作带来了额外的复杂度,让可读性变差。
- IIFE 内部返回的 Singleton 才是我们真正需要的单例的构造函数,外部的 Singleton 把它和一些单例模式的创建逻辑进行了一些封装。
- IIFE 方式除了直接返回一个方法/类实例之外,还可以通过模块模式的方式来进行,就不贴代码了,代码实现在 Github 仓库中,读者可以自己瞅瞅。
3.2 块级作用域方式创建单例
IIFE 方式本质还是通过函数作用域的方式来隐藏内部作用域的变量,有了 ES6 的
let/const之后,可以通过{ }块级作用域的方式来隐藏内部变量:
let getInstance
{
let _instance = null // 存储单例
const Singleton = function() {
if (_instance) return _instance // 判断是否已有单例
_instance = this
this.init() // 初始化操作
return _instance
}
Singleton.prototype.init = function() {
this.foo = 'Singleton Pattern'
}
getInstance = function() {
if (_instance) return _instance
_instance = new Singleton()
return _instance
}
}
const visitor1 = getInstance()
const visitor2 = getInstance()
console.log(visitor1 === visitor2)
输出: true
怎么样,是不是对块级作用域的理解更深了呢~
3.3 单例模式赋能
之前的例子中,单例模式的创建逻辑和原先这个类的一些功能逻辑(比如
init等操作)混杂在一起,根据单一职责原则,这个例子我们还可以继续改进一下,将单例模式的创建逻辑和特定类的功能逻辑拆开,这样功能逻辑就可以和正常的类一样。
/* 功能类 */
class FuncClass {
constructor(bar) {
this.bar = bar
this.init()
}
init() {
this.foo = 'Singleton Pattern'
}
}
/* 单例模式的赋能类 */
const Singleton = (function() {
let _instance = null // 存储单例
const ProxySingleton = function(bar) {
if (_instance) return _instance // 判断是否已有单例
_instance = new FuncClass(bar)
return _instance
}
ProxySingleton.getInstance = function(bar) {
if (_instance) return _instance
_instance = new Singleton(bar)
return _instance
}
return ProxySingleton
})()
const visitor1 = new Singleton('单例1')
const visitor2 = new Singleton('单例2')
const visitor3 = Singleton.getInstance()
console.log(visitor1 === visitor2) // true
console.log(visitor1 === visitor3) // true
- 这样的单例模式赋能类也可被称为代理类,将业务类和单例模式的逻辑解耦,把单例的创建逻辑抽象封装出来,有利于业务类的扩展和维护。代理的概念我们将在后面代理模式的章节中更加详细地探讨。
- 使用类似的概念,配合
ES6引入的Proxy来拦截默认的new方式,我们可以写出更简化的单例模式赋能方法:
/* Person 类 */
class Person {
constructor(name, age) {
this.name = name
this.age = age
}
}
/* 单例模式的赋能方法 */
function Singleton(FuncClass) {
let _instance
return new Proxy(FuncClass, {
construct(target, args) {
return _instance || (_instance = Reflect.construct(FuncClass, args)) // 使用 new FuncClass(...args) 也可以
}
})
}
const PersonInstance = Singleton(Person)
const person1 = new PersonInstance('张小帅', 25)
const person2 = new PersonInstance('李小美', 23)
console.log(person1 === person2) // true
4. 惰性单例、懒汉式-饿汉式
- 有时候一个实例化过程比较耗费性能的类,但是却一直用不到,如果一开始就对这个类进行实例化就显得有些浪费,那么这时我们就可以使用惰性创建,即延迟创建该类的单例。之前的例子都属于惰性单例,实例的创建都是
new的时候才进行。
惰性单例又被成为懒汉式,相对应的概念是饿汉式:
- 懒汉式单例是在使用时才实例化
- 饿汉式是当程序启动时或单例模式类一加载的时候就被创建。
- 我们可以举一个简单的例子比较一下:
class FuncClass {
constructor() { this.bar = 'bar' }
}
// 饿汉式
const HungrySingleton = (function() {
const _instance = new FuncClass()
return function() {
return _instance
}
})()
// 懒汉式
const LazySingleton = (function() {
let _instance = null
return function() {
return _instance || (_instance = new FuncClass())
}
})()
const visitor1 = new HungrySingleton()
const visitor2 = new HungrySingleton()
const visitor3 = new LazySingleton()
const visitor4 = new LazySingleton()
console.log(visitor1 === visitor2) // true
console.log(visitor3 === visitor4) // true
可以打上
debugger在控制台中看一下,饿汉式在 HungrySingleton 这个 IIFE 执行的时候就进入到 FuncClass 的实例化流程了,而懒汉式的 LazySingleton 中 FuncClass 的实例化过程是在第一次 new 的时候才进行的。
惰性创建在实际开发中使用很普遍,了解一下对以后的开发工作很有帮助。
5. 源码中的单例模式
以
ElementUI为例,ElementUI中的全屏Loading蒙层调用有两种形式:
// 1. 指令形式
Vue.use(Loading.directive)
// 2. 服务形式
Vue.prototype.$loading = service
- 上面的是指令形式注册,使用的方式
<div :v-loading.fullscreen="true">...</div>; - 下面的是服务形式注册,使用的方式
this.$loading({ fullscreen: true });
用服务方式使用全屏
Loading是单例的,即在前一个全屏Loading关闭前再次调用全屏Loading,并不会创建一个新的Loading实例,而是返回现有全屏Loading的实例。
下面我们可以看看 ElementUI 2.9.2 的源码是如何实现的,为了观看方便,省略了部分代码:
import Vue from 'vue'
import loadingVue from './loading.vue'
const LoadingConstructor = Vue.extend(loadingVue)
let fullscreenLoading
const Loading = (options = {}) => {
if (options.fullscreen && fullscreenLoading) {
return fullscreenLoading
}
let instance = new LoadingConstructor({
el: document.createElement('div'),
data: options
})
if (options.fullscreen) {
fullscreenLoading = instance
}
return instance
}
export default Loading
- 这里的单例是
fullscreenLoading,是存放在闭包中的,如果用户传的options的fullscreen为true且已经创建了单例的情况下则回直接返回之前创建的单例,如果之前没有创建过,则创建单例并赋值给闭包中的fullscreenLoading后返回新创建的单例实例。 - 这是一个典型的单例模式的应用,通过复用之前创建的全屏蒙层单例,不仅减少了实例化过程,而且避免了蒙层叠加蒙层出现的底色变深的情况。
6. 单例模式的优缺点
单例模式主要解决的问题就是节约资源,保持访问一致性。
简单分析一下它的优点:
- 单例模式在创建后在内存中只存在一个实例,节约了内存开支和实例化时的性能开支,特别是需要重复使用一个创建开销比较大的类时,比起实例不断地销毁和重新实例化,单例能节约更多资源,比如数据库连接;
- 单例模式可以解决对资源的多重占用,比如写文件操作时,因为只有一个实例,可以避免对一个文件进行同时操作;
- 只使用一个实例,也可以减小垃圾回收机制 GC(Garbage Collecation) 的压力,表现在浏览器中就是系统卡顿减少,操作更流畅,CPU 资源占用更少;
单例模式也是有缺点的
- 单例模式对扩展不友好,一般不容易扩展,因为单例模式一般自行实例化,没有接口;
- 与单一职责原则冲突,一个类应该只关心内部逻辑,而不关心外面怎么样来实例化;
. 单例模式的使用场景
那我们应该在什么场景下使用单例模式呢:
- 当一个类的实例化过程消耗的资源过多,可以使用单例模式来避免性能浪费;
- 当项目中需要一个公共的状态,那么需要使用单例模式来保证访问一致性;
# 工厂模式
工厂模式 (Factory Pattern),根据不同的输入返回不同类的实例,一般用来创建同一类对象。工厂方式的主要思想是将对象的创建与对象的实现分离。
1. 你曾见过的工厂模式
今天你的老同学找你来玩,你决定下个馆子(因为不会做饭),于是你来到了小区门口的饭店,跟老板说,来一份鱼香肉丝,一份宫保鸡丁。等会儿菜就烧好端到你的面前,不用管菜烧出来的过程,你只要负责吃就行了。
上面这两个例子都是工厂模式的实例,老板相当于工厂,负责生产产品,访问者通过老板就可以拿到想要的产品。
在类似场景中,这些例子有以下特点:
- 访问者只需要知道产品名,就可以从工厂获得对应实例;
- 访问者不关心实例创建过程;
2. 实例的代码实现
如果你使用过
document.createElement方法创建过DOM元素,那么你已经使用过工厂方法了,虽然这个方法实际上很复杂,但其使用的就是工厂方法的思想:访问者只需提供标签名(如div、img),那么这个方法就会返回对应的 DOM 元素。
我们可以使用 JavaScript 将上面饭馆例子实现一下:
/* 饭店方法 */
function restaurant(menu) {
switch (menu) {
case '鱼香肉丝':
return new YuXiangRouSi()
case '宫保鸡丁':
return new GongBaoJiDin()
default:
throw new Error('这个菜本店没有 -。-')
}
}
/* 鱼香肉丝类 */
function YuXiangRouSi() { this.type = '鱼香肉丝' }
YuXiangRouSi.prototype.eat = function() {
console.log(this.type + ' 真香~')
}
/* 宫保鸡丁类 */
function GongBaoJiDin() { this.type = '宫保鸡丁' }
GongBaoJiDin.prototype.eat = function() {
console.log(this.type + ' 让我想起了外婆做的菜~')
}
const dish1 = restaurant('鱼香肉丝')
dish1.eat() // 输出: 鱼香肉丝 真香~
const dish2 = restaurant('红烧排骨') // 输出: Error 这个菜本店没有 -。-
工厂方法中这里使用
switch-case语法,你也可以用if-else,都可以。
下面使用 ES6 的 class 语法改写一下:
/* 饭店方法 */
class Restaurant {
static getMenu(menu) {
switch (menu) {
case '鱼香肉丝':
return new YuXiangRouSi()
case '宫保鸡丁':
return new GongBaoJiDin()
default:
throw new Error('这个菜本店没有 -。-')
}
}
}
/* 鱼香肉丝类 */
class YuXiangRouSi {
constructor() { this.type = '鱼香肉丝' }
eat() { console.log(this.type + ' 真香~') }
}
/* 宫保鸡丁类 */
class GongBaoJiDin {
constructor() { this.type = '宫保鸡丁' }
eat() { console.log(this.type + ' 让我想起了外婆做的菜~') }
}
const dish1 = Restaurant.getMenu('鱼香肉丝')
dish1.eat() // 输出: 鱼香肉丝 真香~
const dish2 = Restaurant.getMenu('红烧排骨') // 输出: Error 这个菜本店没有 -。-
- 这样就完成了一个工厂模式,但是这个实现有一个问题:工厂方法中包含了很多与创建产品相关的过程,如果产品种类很多的话,这个工厂方法中就会罗列很多产品的创建逻辑,每次新增或删除产品种类,不仅要增加产品类,还需要对应修改在工厂方法,违反了开闭原则,也导致这个工厂方法变得臃肿、高耦合。
- 严格上这种实现在面向对象语言中叫做简单工厂模式。适用于产品种类比较少,创建逻辑不复杂的时候使用。
- 工厂模式的本意是将实际创建对象的过程推迟到子类中,一般用抽象类来作为父类,创建过程由抽象类的子类来具体实现。JavaScript 中没有抽象类,所以我们可以简单地将工厂模式看做是一个实例化对象的工厂类即可。关于抽象类的有关内容,可以参看抽象工厂模式。
- 然而作为灵活的 JavaScript,我们不必如此较真,可以把易变的参数提取出来:
/* 饭店方法 */
class Restaurant {
constructor() {
this.menuData = {}
}
/* 创建菜品 */
getMenu(menu) {
if (!this.menuData[menu])
throw new Error('这个菜本店没有 -。-')
const { type, message } = this.menuData[menu]
return new Menu(type, message)
}
/* 增加菜品种类 */
addMenu(menu, type, message) {
if (this.menuData[menu]) {
console.Info('已经有这个菜了!')
return
}
this.menuData[menu] = { type, message }
}
/* 移除菜品 */
removeMenu(menu) {
if (!this.menuData[menu]) return
delete this.menuData[menu]
}
}
/* 菜品类 */
class Menu {
constructor(type, message) {
this.type = type
this.message = message
}
eat() { console.log(this.type + this.message) }
}
const restaurant = new Restaurant()
restaurant.addMenu('YuXiangRouSi', '鱼香肉丝', ' 真香~') // 注册菜品
restaurant.addMenu('GongBaoJiDin', '宫保鸡丁', ' 让我想起了外婆做的菜~')
const dish1 = restaurant.getMenu('YuXiangRouSi')
dish1.eat() // 输出: 鱼香肉丝 真香~
const dish2 = restaurant.getMenu('HongSaoPaiGu') // 输出: Error 这个菜本店没有 -。-
- 我们还给 Restaurant 类增加了
addMenu/removeMenu私有方法,以便于扩展。 - 当然这里如果菜品参数不太一致,可以在
addMenu时候注册构造函数或者类,创建的时候返回new出的对应类实例,灵活变通即可。
3. 工厂模式的通用实现
根据上面的例子我们可以提炼一下工厂模式,饭店可以被认为是工厂类(Factory),菜品是产品(Product),如果我们希望获得菜品实例,通过工厂类就可以拿到产品实例,不用关注产品实例创建流程。主要有下面几个概念:
- Factory :工厂,负责返回产品实例;
- Product :产品,访问者从工厂拿到产品实例;
结构大概如下:
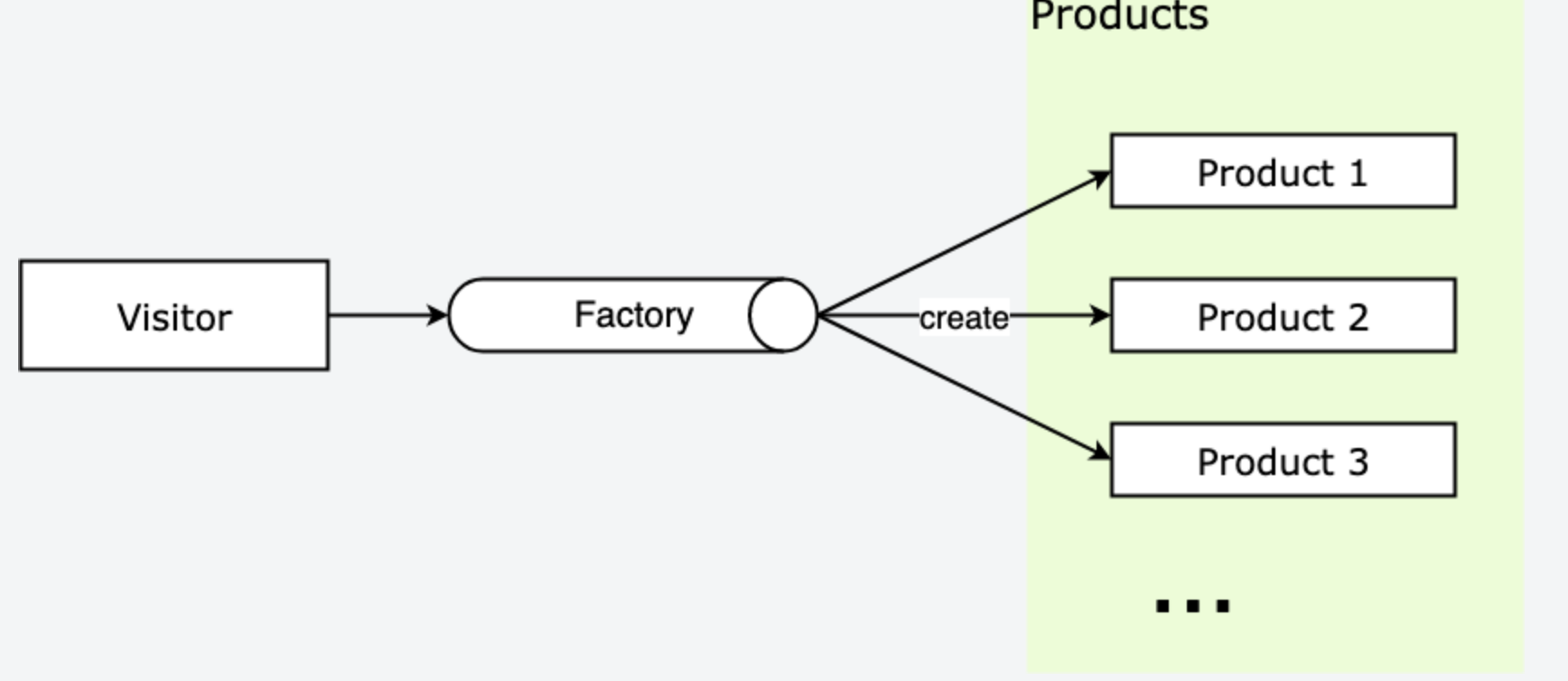
下面用通用的方法实现,这里直接用 class 语法:
/* 工厂类 */
class Factory {
static getInstance(type) {
switch (type) {
case 'Product1':
return new Product1()
case 'Product2':
return new Product2()
default:
throw new Error('当前没有这个产品')
}
}
}
/* 产品类1 */
class Product1 {
constructor() { this.type = 'Product1' }
operate() { console.log(this.type) }
}
/* 产品类2 */
class Product2 {
constructor() { this.type = 'Product2' }
operate() { console.log(this.type) }
}
const prod1 = Factory.getInstance('Product1')
prod1.operate() // 输出: Product1
const prod2 = Factory.getInstance('Product3') // 输出: Error 当前没有这个产品
注意,由于 JavaScript 的灵活,简单工厂模式返回的产品对象不一定非要是类实例,也可以是字面量形式的对象,所以读者可以根据场景灵活选择返回的产品对象形式。
4. 源码中的工厂模式
4.1 Vue/React 源码中的工厂模式
和原生的
document.createElement类似,Vue 和React这种具有虚拟DOM树(Virtual Dom Tree)机制的框架在生成虚拟DOM的时候,都提供了createElement方法用来生成VNode,用来作为真实 DOM 节点的映射:
// Vue
createElement('h3', { class: 'main-title' }, [
createElement('img', { class: 'avatar', attrs: { src: '../avatar.jpg' } }),
createElement('p', { class: 'user-desc' }, '长得帅老的快,长得丑活得久')
])
// React
React.createElement('h3', { className: 'user-info' },
React.createElement('img', { src: '../avatar.jpg', className: 'avatar' }),
React.createElement('p', { className: 'user-desc' }, '长得帅老的快,长得丑活得久')
)
createElement 函数结构大概如下:
class Vnode (tag, data, children) { ... }
function createElement(tag, data, children) {
return new Vnode(tag, data, children)
}
可以看到
createElement函数内会进行VNode的具体创建,创建的过程是很复杂的,而框架提供的createElement工厂方法封装了复杂的创建与验证过程,对于使用者来说就很方便了。
4.2 vue-router 源码中的工厂模式
工厂模式在源码中应用频繁,以
vue-router中的源码为例,代码位置:vue-router/src/index.js
// src/index.js
export default class VueRouter {
constructor(options) {
this.mode = mode // 路由模式
switch (mode) { // 简单工厂
case 'history': // history 方式
this.history = new HTML5History(this, options.base)
break
case 'hash': // hash 方式
this.history = new HashHistory(this, options.base, this.fallback)
break
case 'abstract': // abstract 方式
this.history = new AbstractHistory(this, options.base)
break
default:
// ... 初始化失败报错
}
}
}
稍微解释一下这里的源码。mode 是路由创建的模式,这里有三种
History、Hash、Abstract,前两种我们已经很熟悉了,History是H5的路由方式,Hash是路由中带 # 的路由方式,Abstract代表非浏览器环境中路由方式,比如Node、weex等;this.history用来保存路由实例,vue-router中使用了工厂模式的思想来获得响应路由控制类的实例。
- 源码里没有把工厂方法的产品创建流程封装出来,而是直接将产品实例的创建流程暴露在
VueRouter的构造函数中,在被 new 的时候创建对应产品实例,相当于VueRouter的构造函数就是一个工厂方法。 - 如果一个系统不是
SPA(Single Page Application,单页应用),而是是MPA(Multi Page Application,多页应用),那么就需要创建多个VueRouter的实例,此时VueRouter的构造函数也就是工厂方法将会被多次执行,以分别获得不同实例。
5. 工厂模式的优缺点
工厂模式将对象的创建和实现分离,这带来了优点:
- 良好的封装,代码结构清晰,访问者无需知道对象的创建流程,特别是创建比较复杂的情况下;
- 扩展性优良,通过工厂方法隔离了用户和创建流程隔离,符合开放封闭原则;
- 解耦了高层逻辑和底层产品类,符合最少知识原则,不需要的就不要去交流;
- 工厂模式的缺点:带来了额外的系统复杂度,增加了抽象性;
6. 工厂模式的使用场景
那么什么时候使用工厂模式呢:
- 对象的创建比较复杂,而访问者无需知道创建的具体流程;
- 处理大量具有相同属性的小对象;
什么时候不该用工厂模式:滥用只是增加了不必要的系统复杂度,过犹不及。
7. 其他相关模式
7.1 工厂模式与抽象工厂模式
这两个方式可以组合使用,具体联系与区别在抽象工厂模式中讨论。
7.2 工厂模式与模板方法模式
这两个模式看起来比较类似,不过主要区别是:
- 工厂模式 主要关注产品实例的创建,对创建流程封闭起来;
- 模板方法模式 主要专注的是为固定的算法骨架提供某些步骤的实现;
- 这两个模式也可以组合一起来使用,比如在模板方法模式里面,使用工厂方法来创建模板方法需要的对象。
# 抽象工厂模式
工厂模式 (Factory Pattern),根据输入的不同返回不同类的实例,一般用来创建同一类对象。工厂方式的主要思想是将对象的创建与对象的实现分离。
- 抽象工厂 (Abstract Factory):通过对类的工厂抽象使其业务用于对产品类簇的创建,而不是负责创建某一类产品的实例。关键在于使用抽象类制定了实例的结构,调用者直接面向实例的结构编程,从实例的具体实现中解耦。
- 我们知道 JavaScript 并不是强面向对象语言,所以使用传统编译型语言比如 JAVA、C#、C++ 等实现的设计模式和 JavaScript 不太一样,比如 JavaScript 中没有原生的类和接口等(不过 ES6+ 渐渐提供类似的语法糖),我们可以用变通的方式来解决。最重要的是设计模式背后的核心思想,和它所要解决的问题。
1. 你曾见过的抽象工厂模式
还是使用上一节工厂模式中使用的饭店例子。
你再次来到了小区的饭店,跟老板说来一份鱼香肉丝,来一份宫保鸡丁,来一份番茄鸡蛋汤,来一份排骨汤(今天可能比较想喝汤)。无论什么样的菜,还是什么样的汤,他们都具有同样的属性,比如菜都可以吃,汤都可以喝。所以我们不论拿到什么菜,都可以吃,而不论拿到什么汤,都可以喝。对于饭店也一样,这个饭店可以做菜做汤,另一个饭店也可以,那么这两个饭店就具有同样的功能结构。
面的场景都是属于抽象工厂模式的例子。菜类属于抽象产品类,制定具体产品菜类所具备的属性,而饭店和之前的工厂模式一样,负责具体生产产品实例,访问者通过老板获取想拿的产品。只要我们点的是汤类,即使还没有被做出来,我们就知道是可以喝的。推广一下,饭店功能也可以被抽象(抽象饭店类),继承这个类的饭店实例都具有做菜和做汤的功能,这样也完成了抽象类对实例的结构约束。
在类似场景中,这些例子有特点:只要实现了抽象类的实例,都实现了抽象类制定的结构;
2. 实例的代码实现
我们知道 JavaScript 并不强面向对象,也没有提供抽象类(至少目前没有提供),但是可以模拟抽象类。用对
new.target来判断 new 的类,在父类方法中throw new Error(),如果子类中没有实现这个方法就会抛错,这样来模拟抽象类:
/* 抽象类,ES6 class 方式 */
class AbstractClass1 {
constructor() {
if (new.target === AbstractClass1) {
throw new Error('抽象类不能直接实例化!')
}
}
/* 抽象方法 */
operate() { throw new Error('抽象方法不能调用!') }
}
/* 抽象类,ES5 构造函数方式 */
var AbstractClass2 = function () {
if (new.target === AbstractClass2) {
throw new Error('抽象类不能直接实例化!')
}
}
/* 抽象方法,使用原型方式添加 */
AbstractClass2.prototype.operate = function(){ throw new Error('抽象方法不能调用!') }
下面用 JavaScript 将上面介绍的饭店例子实现一下。
首先使用原型方式:
/* 饭店方法 */
function Restaurant() {}
Restaurant.orderDish = function(type) {
switch (type) {
case '鱼香肉丝':
return new YuXiangRouSi()
case '宫保鸡丁':
return new GongBaoJiDing()
case '紫菜蛋汤':
return new ZiCaiDanTang()
default:
throw new Error('本店没有这个 -。-')
}
}
/* 菜品抽象类 */
function Dish() { this.kind = '菜' }
/* 抽象方法 */
Dish.prototype.eat = function() { throw new Error('抽象方法不能调用!') }
/* 鱼香肉丝类 */
function YuXiangRouSi() { this.type = '鱼香肉丝' }
YuXiangRouSi.prototype = new Dish()
YuXiangRouSi.prototype.eat = function() {
console.log(this.kind + ' - ' + this.type + ' 真香~')
}
/* 宫保鸡丁类 */
function GongBaoJiDing() { this.type = '宫保鸡丁' }
GongBaoJiDing.prototype = new Dish()
GongBaoJiDing.prototype.eat = function() {
console.log(this.kind + ' - ' + this.type + ' 让我想起了外婆做的菜~')
}
const dish1 = Restaurant.orderDish('鱼香肉丝')
dish1.eat()
const dish2 = Restaurant.orderDish('红烧排骨')
// 输出: 菜 - 鱼香肉丝 真香~
// 输出: Error 本店没有这个 -。-
使用 class 语法改写一下:
/* 饭店方法 */
class Restaurant {
static orderDish(type) {
switch (type) {
case '鱼香肉丝':
return new YuXiangRouSi()
case '宫保鸡丁':
return new GongBaoJiDin()
default:
throw new Error('本店没有这个 -。-')
}
}
}
/* 菜品抽象类 */
class Dish {
constructor() {
if (new.target === Dish) {
throw new Error('抽象类不能直接实例化!')
}
this.kind = '菜'
}
/* 抽象方法 */
eat() { throw new Error('抽象方法不能调用!') }
}
/* 鱼香肉丝类 */
class YuXiangRouSi extends Dish {
constructor() {
super()
this.type = '鱼香肉丝'
}
eat() { console.log(this.kind + ' - ' + this.type + ' 真香~') }
}
/* 宫保鸡丁类 */
class GongBaoJiDin extends Dish {
constructor() {
super()
this.type = '宫保鸡丁'
}
eat() { console.log(this.kind + ' - ' + this.type + ' 让我想起了外婆做的菜~') }
}
const dish0 = new Dish() // 输出: Error 抽象方法不能调用!
const dish1 = Restaurant.orderDish('鱼香肉丝')
dish1.eat() // 输出: 菜 - 鱼香肉丝 真香~
const dish2 = Restaurant.orderDish('红烧排骨') // 输出: Error 本店没有这个 -。-
- 这里的 Dish 类就是抽象产品类,继承该类的子类需要实现它的方法 eat。
- 上面的实现将产品的功能结构抽象出来成为抽象产品类。事实上我们还可以更进一步,将工厂类也使用抽象类约束一下,也就是抽象工厂类,比如这个饭店可以做菜和汤,另一个饭店也可以做菜和汤,存在共同的功能结构,就可以将共同结构作为抽象类抽象出来,实现如下:
/* 饭店 抽象类,饭店都可以做菜和汤 */
class AbstractRestaurant {
constructor() {
if (new.target === AbstractRestaurant)
throw new Error('抽象类不能直接实例化!')
this.signborad = '饭店'
}
/* 抽象方法:创建菜 */
createDish() { throw new Error('抽象方法不能调用!') }
/* 抽象方法:创建汤 */
createSoup() { throw new Error('抽象方法不能调用!') }
}
/* 具体饭店类 */
class Restaurant extends AbstractRestaurant {
constructor() { super() }
createDish(type) {
switch (type) {
case '鱼香肉丝':
return new YuXiangRouSi()
case '宫保鸡丁':
return new GongBaoJiDing()
default:
throw new Error('本店没这个菜')
}
}
createSoup(type) {
switch (type) {
case '紫菜蛋汤':
return new ZiCaiDanTang()
default:
throw new Error('本店没这个汤')
}
}
}
/* 菜 抽象类,菜都有吃的功能 eat */
class AbstractDish {
constructor() {
if (new.target === AbstractDish) {
throw new Error('抽象类不能直接实例化!')
}
this.kind = '菜'
}
/* 抽象方法 */
eat() { throw new Error('抽象方法不能调用!') }
}
/* 菜 鱼香肉丝类 */
class YuXiangRouSi extends AbstractDish {
constructor() {
super()
this.type = '鱼香肉丝'
}
eat() { console.log(this.kind + ' - ' + this.type + ' 真香~') }
}
/* 菜 宫保鸡丁类 */
class GongBaoJiDing extends AbstractDish {
constructor() {
super()
this.type = '宫保鸡丁'
}
eat() { console.log(this.kind + ' - ' + this.type + ' 让我想起了外婆做的菜~') }
}
/* 汤 抽象类,汤都有喝的功能 drink */
class AbstractSoup {
constructor() {
if (new.target === AbstractDish) {
throw new Error('抽象类不能直接实例化!')
}
this.kind = '汤'
}
/* 抽象方法 */
drink() { throw new Error('抽象方法不能调用!') }
}
/* 汤 紫菜蛋汤类 */
class ZiCaiDanTang extends AbstractSoup {
constructor() {
super()
this.type = '紫菜蛋汤'
}
drink() { console.log(this.kind + ' - ' + this.type + ' 我从小喝到大~') }
}
const restaurant = new Restaurant()
const soup1 = restaurant.createSoup('紫菜蛋汤')
soup1.drink() // 输出: 汤 - 紫菜蛋汤 我从小喝到大~
const dish1 = restaurant.createDish('鱼香肉丝')
dish1.eat() // 输出: 菜 - 鱼香肉丝 真香~
const dish2 = restaurant.createDish('红烧排骨') // 输出: Error 本店没有这个 -。-
这样如果创建新的饭店,新的饭店继承这个抽象饭店类,那么也要实现抽象饭店类,这样就都具有抽象饭店类制定的结构。
3. 抽象工厂模式的通用实现
我们提炼一下抽象工厂模式,饭店还是工厂(Factory),菜品种类是抽象类(AbstractFactory),而实现抽象类的菜品是具体的产品(Product),通过工厂拿到实现了不同抽象类的产品,这些产品可以根据实现的抽象类被区分为类簇。主要有下面几个概念:
- Factory :工厂,负责返回产品实例;
- AbstractFactory :虚拟工厂,制定工厂实例的结构;
- Product :产品,访问者从工厂中拿到的产品实例,实现抽象类;
- AbstractProduct :产品抽象类,由具体产品实现,制定产品实例的结构;
概略图如下:

下面是通用的实现,原型方式略过:
/* 工厂 抽象类 */
class AbstractFactory {
constructor() {
if (new.target === AbstractFactory)
throw new Error('抽象类不能直接实例化!')
}
/* 抽象方法 */
createProduct1() { throw new Error('抽象方法不能调用!') }
}
/* 具体饭店类 */
class Factory extends AbstractFactory {
constructor() { super() }
createProduct1(type) {
switch (type) {
case 'Product1':
return new Product1()
case 'Product2':
return new Product2()
default:
throw new Error('当前没有这个产品 -。-')
}
}
}
/* 抽象产品类 */
class AbstractProduct {
constructor() {
if (new.target === AbstractProduct)
throw new Error('抽象类不能直接实例化!')
this.kind = '抽象产品类1'
}
/* 抽象方法 */
operate() { throw new Error('抽象方法不能调用!') }
}
/* 具体产品类1 */
class Product1 extends AbstractProduct {
constructor() {
super()
this.type = 'Product1'
}
operate() { console.log(this.kind + ' - ' + this.type) }
}
/* 具体产品类2 */
class Product2 extends AbstractProduct {
constructor() {
super()
this.type = 'Product2'
}
operate() { console.log(this.kind + ' - ' + this.type) }
}
const factory = new Factory()
const prod1 = factory.createProduct1('Product1')
prod1.operate() // 输出: 抽象产品类1 - Product1
const prod2 = factory.createProduct1('Product3') // 输出: Error 当前没有这个产品 -。-
- 如果希望增加第二个类簇的产品,除了需要改一下对应工厂类之外,还需要增加一个抽象产品类,并在抽象产品类基础上扩展新的产品。
- 我们在实际使用的时候不一定需要每个工厂都继承抽象工厂类,比如只有一个工厂的话我们可以直接使用工厂模式,在实战中灵活使用。
4. 抽象工厂模式的优缺点
抽象模式的优点:
抽象产品类将产品的结构抽象出来,访问者不需要知道产品的具体实现,只需要面向产品的结构编程即可,从产品的具体实现中解耦;
抽象模式的缺点:
- 扩展新类簇的产品类比较困难,因为需要创建新的抽象产品类,并且还要修改工厂类,违反开闭原则;
- 带来了系统复杂度,增加了新的类,和新的继承关系;
5. 抽象工厂模式的使用场景
如果一组实例都有相同的结构,那么就可以使用抽象工厂模式。
6. 其他相关模式 6.1 抽象工厂模式与工厂模式
工厂模式和抽象工厂模式的区别:
- 工厂模式 主要关注单独的产品实例的创建;
- 抽象工厂模式 主要关注产品类簇实例的创建,如果产品类簇只有一个产品,那么这时的抽象工厂模式就退化为工厂模式了;根据场景灵活使用即可。
# 建造者模式
建造者模式(Builder Pattern)又称生成器模式,分步构建一个复杂对象,并允许按步骤构造。同样的构建过程可以采用不同的表示,将一个复杂对象的构建层与其表示层分离。
- 在工厂模式中,创建的结果都是一个完整的个体,我们对创建的过程并不关心,只需了解创建的结果。而在建造者模式中,我们关心的是对象的创建过程,因此我们通常将创建的复杂对象的模块化,使得被创建的对象的每一个子模块都可以得到高质量的复用,当然在灵活的 JavaScript 中我们可以有更灵活的实现。
1. 你曾见过的建造者模式
- 假定我们需要建造一个车,车这个产品是由多个部件组成,车身、引擎、轮胎。汽车制造厂一般不会自己完成每个部件的制造,而是把部件的制造交给对应的汽车零部件制造商,自己只进行装配,最后生产出整车。整车的每个部件都是一个相对独立的个体,都具有自己的生产过程,多个部件经过一系列的组装共同组成了一个完整的车。
- 类似的场景还有很多,比如生产一个笔记本电脑,由主板、显示器、壳子组成,每个部件都有自己独立的行为和功能,他们共同组成了一个笔记本电脑。笔记本电脑厂从部件制造商处获得制造完成的部件,再由自己完成组装,得到笔记本电脑这个完整的产品。
在这些场景中,有以下特点:
- 整车制造厂(指挥者)无需知道零部件的生产过程,零部件的生产过程一般由零部件厂商(建造者)来完成;
- 整车制造厂(指挥者)决定以怎样的装配方式来组装零部件,以得到最终的产品;
2. 实例的代码实现
我们可以使用 JavaScript 来将上面的装配汽车的例子实现一下。
// 建造者,汽车部件厂家,提供具体零部件的生产
function CarBuilder({ color = 'white', weight = 0 }) {
this.color = color
this.weight = weight
}
// 生产部件,轮胎
CarBuilder.prototype.buildTyre = function(type) {
switch (type) {
case 'small':
this.tyreType = '小号轮胎'
this.tyreIntro = '正在使用小号轮胎'
break
case 'normal':
this.tyreType = '中号轮胎'
this.tyreIntro = '正在使用中号轮胎'
break
case 'big':
this.tyreType = '大号轮胎'
this.tyreIntro = '正在使用大号轮胎'
break
}
}
// 生产部件,发动机
CarBuilder.prototype.buildEngine = function(type) {
switch (type) {
case 'small':
this.engineType = '小马力发动机'
this.engineIntro = '正在使用小马力发动机'
break
case 'normal':
this.engineType = '中马力发动机'
this.engineIntro = '正在使用中马力发动机'
break
case 'big':
this.engineType = '大马力发动机'
this.engineIntro = '正在使用大马力发动机'
break
}
}
/* 奔驰厂家,负责最终汽车产品的装配 */
function benChiDirector(tyre, engine, param) {
var _car = new CarBuilder(param)
_car.buildTyre(tyre)
_car.buildEngine(engine)
return _car
}
// 获得产品实例
var benchi1 = benChiDirector('small', 'big', { color: 'red', weight: '1600kg' })
console.log(benchi1)
// 输出:
// {
// color: "red"
// weight: "1600kg"
// tyre: Tyre {tyreType: "小号轮胎", tyreIntro: "正在使用小号轮胎"}
// engine: Engine {engineType: "大马力发动机", engineIntro: "正在使用大马力发动机"}
// }
如果访问者希望获得另一个型号的车,比如有「空调」功能的车,那么我们只需要给
CarBuilder的原型prototype上增加一个空调部件的建造方法,然后再新建一个新的奔驰厂家指挥者方法。
也可以使用 ES6 的写法改造一下:
// 建造者,汽车部件厂家,提供具体零部件的生产
class CarBuilder {
constructor({ color = 'white', weight = 0 }) {
this.color = color
this.weight = weight
}
/* 生产部件,轮胎 */
buildTyre(type) {
const tyre = {}
switch (type) {
case 'small':
tyre.tyreType = '小号轮胎'
tyre.tyreIntro = '正在使用小号轮胎'
break
case 'normal':
tyre.tyreType = '中号轮胎'
tyre.tyreIntro = '正在使用中号轮胎'
break
case 'big':
tyre.tyreType = '大号轮胎'
tyre.tyreIntro = '正在使用大号轮胎'
break
}
this.tyre = tyre
}
/* 生产部件,发动机 */
buildEngine(type) {
const engine = {}
switch (type) {
case 'small':
engine.engineType = '小马力发动机'
engine.engineIntro = '正在使用小马力发动机'
break
case 'normal':
engine.engineType = '中马力发动机'
engine.engineIntro = '正在使用中马力发动机'
break
case 'big':
engine.engineType = '大马力发动机'
engine.engineIntro = '正在使用大马力发动机'
break
}
this.engine = engine
}
}
/* 指挥者,负责最终汽车产品的装配 */
class BenChiDirector {
constructor(tyre, engine, param) {
const _car = new CarBuilder(param)
_car.buildTyre(tyre)
_car.buildEngine(engine)
return _car
}
}
// 获得产品实例
const benchi1 = new BenChiDirector('small', 'big', { color: 'red', weight: '1600kg' })
console.log(benchi1)
// 输出:
// {
// color: "red"
// weight: "1600kg"
// tyre: Tyre {tyreType: "小号轮胎", tyreIntro: "正在使用小号轮胎"}
// engine: Engine {engineType: "大马力发动机", engineIntro: "正在使用大马力发动机"}
// }
作为灵活的 JavaScript,我们还可以使用链模式来完成部件的装配,对链模式还不熟悉的同学可以看一下后面有一篇单独介绍链模式的文章~
// 建造者,汽车部件厂家
class CarBuilder {
constructor({ color = 'white', weight = '0' }) {
this.color = color
this.weight = weight
}
/* 生产部件,轮胎 */
buildTyre(type) {
const tyre = {}
switch (type) {
case 'small':
tyre.tyreType = '小号轮胎'
tyre.tyreIntro = '正在使用小号轮胎'
break
case 'normal':
tyre.tyreType = '中号轮胎'
tyre.tyreIntro = '正在使用中号轮胎'
break
case 'big':
tyre.tyreType = '大号轮胎'
tyre.tyreIntro = '正在使用大号轮胎'
break
}
this.tyre = tyre
return this
}
/* 生产部件,发动机 */
buildEngine(type) {
const engine = {}
switch (type) {
case 'small':
engine.engineType = '小马力发动机'
engine.engineIntro = '正在使用小马力发动机'
break
case 'normal':
engine.engineType = '中马力发动机'
engine.engineIntro = '正在使用中马力发动机'
break
case 'big':
engine.engineType = '大马力发动机'
engine.engineIntro = '正在使用大马力发动机'
break
}
this.engine = engine
return this
}
}
// 汽车装配,获得产品实例
const benchi1 = new CarBuilder({ color: 'red', weight: '1600kg' })
.buildTyre('small')
.buildEngine('big')
console.log(benchi1)
// 输出:
// {
// color: "red"
// weight: "1600kg"
// tyre: Tyre {tyre: "小号轮胎", tyreIntro: "正在使用小号轮胎"}
// engine: Engine {engine: "大马力发动机", engineIntro: "正在使用大马力发动机"}
// }
这样将最终产品的创建流程使用链模式来实现,相当于将指挥者退化,指挥的过程通过链模式让用户自己实现,这样既增加了灵活性,装配过程也一目了然。如果希望扩展产品的部件,那么在建造者上增加部件实现方法,再适当修改链模式即可。
3. 建造者模式的通用实现
我们提炼一下建造者模式,这里的生产汽车的奔驰厂家就相当于指挥者(Director),厂家负责将不同的部件组装成最后的产品(Product),而部件的生产者是部件厂家相当于建造者(Builder),我们通过指挥者就可以获得希望的复杂的产品对象,再通过访问不同指挥者获得装配方式不同的产品。主要有下面几个概念:
- Director: 指挥者,调用建造者中的部件具体实现进行部件装配,相当于整车组装厂,最终返回装配完毕的产品;
- Builder: 建造者,含有不同部件的生产方式给指挥者调用,是部件真正的生产者,但没有部件的装配流程;
- Product: 产品,要返回给访问者的复杂对象;
- 建造者模式的主要功能是构建复杂的产品,并且是复杂的、需要分步骤构建的产品,其构建的算法是统一的,构建的过程由指挥者决定,只要配置不同的指挥者,就可以构建出不同的复杂产品来。也就是说,建造者模式将产品装配的算法和具体部件的实现分离,这样构建的算法可以扩展和复用,部件的具体实现也可以方便地扩展和复用,从而可以灵活地通过组合来构建出不同的产品对象。
概略图如下:
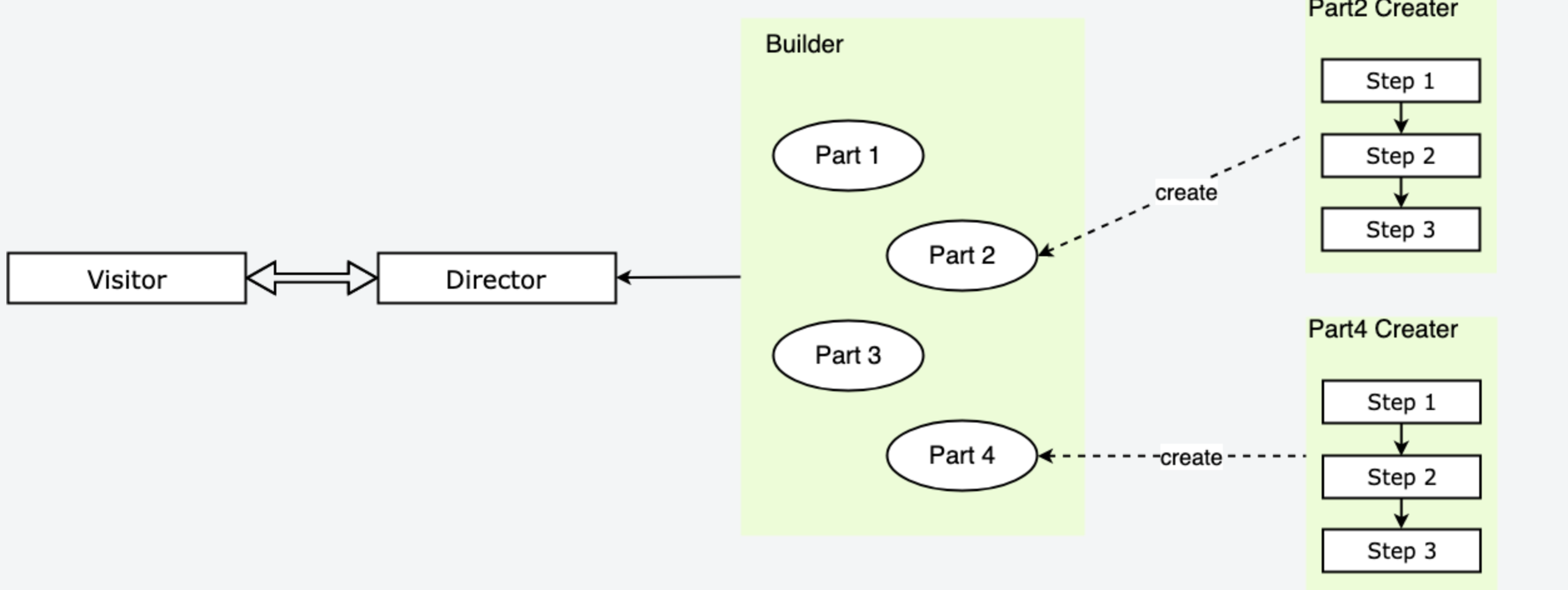
下面是通用的实现。
首先使用 ES6 的 class 语法:
// 建造者,部件生产
class ProductBuilder {
constructor(param) {
this.param = param
}
/* 生产部件,part1 */
buildPart1() {
// ... Part1 生产过程
this.part1 = 'part1'
}
/* 生产部件,part2 */
buildPart2() {
// ... Part2 生产过程
this.part2 = 'part2'
}
}
/* 指挥者,负责最终产品的装配 */
class Director {
constructor(param) {
const _product = new ProductBuilder(param)
_product.buildPart1()
_product.buildPart2()
return _product
}
}
// 获得产品实例
const product = new Director('param')
结合链模式:
// 建造者,汽车部件厂家
class CarBuilder {
constructor(param) {
this.param = param
}
/* 生产部件,part1 */
buildPart1() {
this.part1 = 'part1'
return this
}
/* 生产部件,part2 */
buildPart2() {
this.part2 = 'part2'
return this
}
}
// 汽车装配,获得产品实例
const benchi1 = new CarBuilder('param')
.buildPart1()
.buildPart2()
- 如果希望扩展实例的功能,那么只需要在建造者类的原型上增加一个实例方法,再返回
this即可。 - 值得一提的是,结合链模式的建造者模式中,装配复杂对象的链式装配过程就是指挥者 Director 角色,只不过在链式装配过程中不再封装在具体指挥者中,而是由使用者自己确定装配过程。
4. 实战中的建造者模式
4.1 重构一个具有很多参数的构造函数
有时候你会遇到一个参数很多的构造函数,比如:
// 汽车建造者
class CarBuilder {
constructor(engine, weight, height, color, tyre, name, type) {
this.engine = engine
this.weight = weight
this.height = height
this.color = color
this.tyre = tyre
this.name = name
this.type = type
}
}
const benchi = new CarBuilder('大马力发动机', '2ton', 'white', '大号轮胎', '奔驰', 'AMG')
如果构造函数的参数多于 3 个,在使用的时候就很容易弄不清哪个参数对应的是什么含义,你可以使用对象解构赋值的方式来提高可读性和使用便利性,也可以使用建造者模式的思想来进行属性赋值,这是另一个思路。代码如下:
// 汽车建造者
class CarBuilder {
constructor(engine, weight, height, color, tyre, name, type) {
this.engine = engine
this.weight = weight
this.height = height
this.color = color
this.tyre = tyre
this.name = name
this.type = type
}
setCarProperty(key, value) {
if (Object.getOwnPropertyNames(this).includes(key)) {
this[key] = value
return this
}
throw new Error(`Key error : ${ key } 不是本实例上的属性`)
}
}
const benchi = new CarBuilder()
.setCarProperty('engine', '大马力发动机')
.setCarProperty('weight', '2ton')
.setCarProperty('height', '2000mm')
.setCarProperty('color', 'white')
.setCarProperty('tyre', '大号轮胎')
.setCarProperty('name', '奔驰')
.setCarProperty('type', 'AMG')
每个键都是用一个同样的方法来设置,或许你觉得不太直观,我们可以将设置每个属性的操作都单独列为一个方法,这样可读性就更高了:
// 汽车建造者
class CarBuilder {
constructor(engine, weight, height, color, tyre, name, type) {
this.engine = engine
this.weight = weight
this.height = height
this.color = color
this.tyre = tyre
this.name = name
this.type = type
}
setPropertyFuncChain() {
Object.getOwnPropertyNames(this)
.forEach(key => {
const funcName = 'set' + key.replace(/^\w/g, str => str.toUpperCase())
this[funcName] = value => {
this[key] = value
return this
}
})
return this
}
}
const benchi = new CarBuilder().setPropertyFuncChain()
.setEngine('大马力发动机')
.setWeight('2ton')
.setHeight('2000mm')
.setColor('white')
.setTyre('大号轮胎')
.setName('奔驰')
.setType('AMG')
4.2 重构 React 的书写形式
- 注意: 这个方式不一定推荐,只是用来开阔视野。
- 当我们写一个 React 组件的时候,一般结构形式如下;
class ContainerComponent extends Component {
componentDidMount() {
this.props.fetchThings()
}
render() {
return <PresentationalComponent {...this.props}/>
}
}
ContainerComponent.propTypes = {
fetchThings: PropTypes.func.isRequired
}
const mapStateToProps = state => ({
things: state.things
})
const mapDispatchToProps = dispatch => ({
fetchThings: () => dispatch(fetchThings()),
selectThing: id => dispatch(selectThing(id)),
blowShitUp: () => dispatch(blowShitUp())
})
export default connect(
mapStateToProps,
mapDispatchToProps
)(ContainerComponent)
通过建造者模式重构,我们可以将组件形式写成如下方式:
export default ComponentBuilder('ContainerComponent')
.render(props => <PresentationalComponent {...props}/>)
.componentDidMount(props => props.fetchThings())
.propTypes({
fetchThings: PropTypes.func.isRequired
})
.mapStateToProps(state => ({
things: state.things
}))
.mapDispatchToProps(dispatch => ({
fetchThings: () => dispatch(fetchThings()),
selectThing: id => dispatch(selectThing(id)),
blowShitUp: () => dispatch(blowShitUp())
}))
.build()
5. 建造者模式的优缺点
建造者模式的优点:
- 使用建造者模式可以使产品的构建流程和产品的表现分离,也就是将产品的创建算法和产品组成的实现隔离,访问者不必知道产品部件实现的细节;
- 扩展方便,如果希望生产一个装配顺序或方式不同的新产品,那么直接新建一个指挥者即可,不用修改既有代码,符合开闭原则;
- 更好的复用性,建造者模式将产品的创建算法和产品组成的实现分离,所以产品创建的算法可以复用,产品部件的实现也可以复用,带来很大的灵活性;
建造者模式的缺点:
- 建造者模式一般适用于产品之间组成部件类似的情况,如果产品之间差异性很大、复用性不高,那么不要使用建造者模式;
- 实例的创建增加了许多额外的结构,无疑增加了许多复杂度,如果对象粒度不大,那么我们最好直接创建对象;
6. 建造者模式的适用场景
- 相同的方法,不同的执行顺序,产生不一样的产品时,可以采用建造者模式;
- 产品的组成部件类似,通过组装不同的组件获得不同产品时,可以采用建造者模式;
7. 其他相关模式
7.1 建造者模式与工厂模式
- 建造者模式和工厂模式最终都是创建一个完整的产品,但是在建造者模式中我们更关心对象创建的过程,将创建对象的方法模块化,从而更好地复用这些模块。
- 当然建造者模式与工厂模式也是可以组合使用的,比如建造者中一般会提供不同的部件实现,那么这里就可以使用工厂模式来提供具体的部件对象,再通过指挥者来进行装配。
7.2 建造者模式与模版方法模式
- 指挥者的实现可以和模版方法模式相结合。也就是说,指挥者中部件的装配过程,可以使用模版方法模式来固定装配算法,把部件实现方法分为模板方法和基本方法,进一步提取公共代码,扩展可变部分。
- 是否采用模版方法模式看具体场景,如果产品的部件装配顺序很明确,但是具体的实现是未知的、灵活的,那么你可以适当考虑是否应该将算法骨架提取出来。
# 三、结构型模式
# 代理模式
代理模式 (Proxy Pattern)又称委托模式,它为目标对象创造了一个代理对象,以控制对目标对象的访问。
- 代理模式把代理对象插入到访问者和目标对象之间,从而为访问者对目标对象的访问引入一定的间接性。正是这种间接性,给了代理对象很多操作空间,比如在调用目标对象前和调用后进行一些预操作和后操作,从而实现新的功能或者扩展目标的功能。
1. 你曾见过的代理模式
明星总是有个助理,或者说经纪人,如果某导演来请这个明星演出,或者某个品牌来找明星做广告,需要经纪人帮明星做接洽工作。而且经纪人也起到过滤的作用,毕竟明星也不是什么电影和广告都会接。类似的场景还有很多,再比如领导和秘书…(emmm)
- 再看另一个例子。打官司是件非常麻烦的事,包括查找法律条文、起草法律文书、法庭辩论、签署法律文件、申请法院执行等等流程。此时,当事人就可聘请代理律师来完成整个打官司的所有事务。当事人只需与代理律师签订全权委托协议,那么整个打官司的过程,当事人都可以不用出现。法院的一些复杂事务都可以通过代理律师来完成,而法院需要当事人完成某些工作的时候,比如出庭,代理律师才会通知当事人,并为当事人出谋划策。
在类似的场景中,有以下特点:
- 导演/法院(访问者)对明星/当事人(目标)的访问都是通过经纪人/律师(代理)来完成;
- 经纪人/律师(代理)对访问有过滤的功能;
2. 实例的代码实现
我们使用 JavaScript 来将上面的明星例子实现一下。
/* 明星 */
var SuperStar = {
name: '小鲜肉',
playAdvertisement: function(ad) {
console.log(ad)
}
}
/* 经纪人 */
var ProxyAssistant = {
name: '经纪人张某',
playAdvertisement: function(reward, ad) {
if (reward > 1000000) { // 如果报酬超过100w
console.log('没问题,我们小鲜鲜最喜欢拍广告了!')
SuperStar.playAdvertisement(ad)
} else
console.log('没空,滚!')
}
}
ProxyAssistant.playAdvertisement(10000, '纯蒸酸牛奶,味道纯纯,尽享纯蒸')
// 输出: 没空,滚
这里我们通过经纪人的方式来和明星取得联系,经纪人会视条件过滤一部分合作请求。
- 我们可以升级一下,比如如果明星没有档期的话,可以通过经纪人安排档期,当明星有空的时候才让明星来拍广告。这里通过
Promise的方式来实现档期的安排:
/* 明星 */
const SuperStar = {
name: '小鲜肉',
playAdvertisement(ad) {
console.log(ad)
}
}
/* 经纪人 */
const ProxyAssistant = {
name: '经纪人张某',
scheduleTime() {
return new Promise((resolve, reject) => {
setTimeout(() => {
console.log('小鲜鲜有空了')
resolve()
}, 2000) // 发现明星有空了
})
},
playAdvertisement(reward, ad) {
if (reward > 1000000) { // 如果报酬超过100w
console.log('没问题,我们小鲜鲜最喜欢拍广告了!')
ProxyAssistant.scheduleTime() // 安排上了
.then(() => SuperStar.playAdvertisement(ad))
} else
console.log('没空,滚!')
}
}
ProxyAssistant.playAdvertisement(10000, '纯蒸酸牛奶,味道纯纯,尽享纯蒸')
// 输出: 没空,滚
ProxyAssistant.playAdvertisement(1000001, '纯蒸酸牛奶,味道纯纯,尽享纯蒸')
// 输出: 没问题,我们小鲜鲜最喜欢拍广告了!
// 2秒后
// 输出: 小鲜鲜有空了
// 输出: 纯蒸酸牛奶,味道纯纯,尽享纯蒸
这里就简单实现了经纪人对请求的过滤,对明星档期的安排,实现了一个代理对象的基本功能。
3. 代理模式的概念
对于上面的例子,明星就相当于被代理的目标对象(
Target),而经纪人就相当于代理对象(Proxy),希望找明星的人是访问者(Visitor),他们直接找不到明星,只能找明星的经纪人来进行业务商洽。主要有以下几个概念:
Target: 目标对象,也是被代理对象,是具体业务的实际执行者;Proxy: 代理对象,负责引用目标对象,以及对访问的过滤和预处理;
概略图如下:
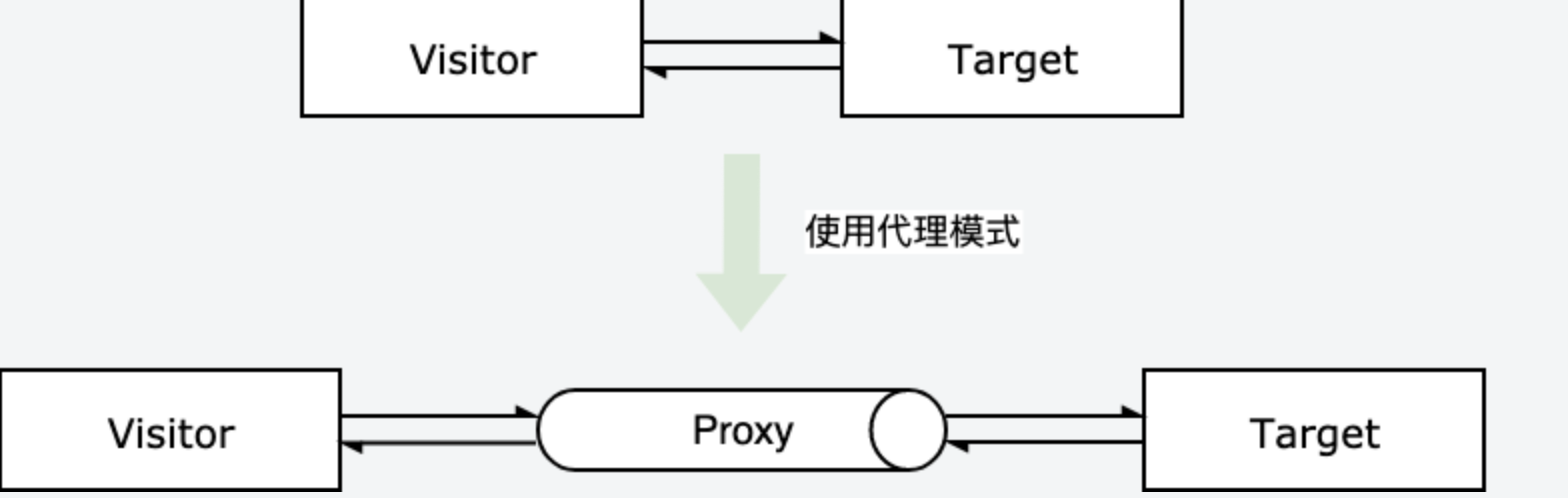
ES6 原生提供了
Proxy构造函数,这个构造函数让我们可以很方便地创建代理对象:
var proxy = new Proxy(target, handler);
参数中
target是被代理对象,handler用来设置代理行为。
这里使用 Proxy 来实现一下上面的经纪人例子:
/* 明星 */
const SuperStar = {
name: '小鲜肉',
scheduleFlag: false, // 档期标识位,false-没空(默认值),true-有空
playAdvertisement(ad) {
console.log(ad)
}
}
/* 经纪人 */
const ProxyAssistant = {
name: '经纪人张某',
scheduleTime(ad) {
const schedule = new Proxy(SuperStar, { // 在这里监听 scheduleFlag 值的变化
set(obj, prop, val) {
if (prop !== 'scheduleFlag') return
if (obj.scheduleFlag === false &&
val === true) { // 小鲜肉现在有空了
obj.scheduleFlag = true
obj.playAdvertisement(ad) // 安排上了
}
}
})
setTimeout(() => {
console.log('小鲜鲜有空了')
schedule.scheduleFlag = true // 明星有空了
}, 2000)
},
playAdvertisement(reward, ad) {
if (reward > 1000000) { // 如果报酬超过100w
console.log('没问题,我们小鲜鲜最喜欢拍广告了!')
ProxyAssistant.scheduleTime(ad)
} else
console.log('没空,滚!')
}
}
ProxyAssistant.playAdvertisement(10000, '纯蒸酸牛奶,味道纯纯,尽享纯蒸')
// 输出: 没空,滚
ProxyAssistant.playAdvertisement(1000001, '纯蒸酸牛奶,味道纯纯,尽享纯蒸')
// 输出: 没问题,我们小鲜鲜最喜欢拍广告了!
// 2秒后
// 输出: 小鲜鲜有空了
// 输出: 纯蒸酸牛奶,味道纯纯,尽享纯蒸
在 ES6 之前,一般是使用 Object.defineProperty 来完成相同的功能,我们可以使用这个 API 改造一下:
/* 明星 */
const SuperStar = {
name: '小鲜肉',
scheduleFlagActually: false, // 档期标识位,false-没空(默认值),true-有空
playAdvertisement(ad) {
console.log(ad)
}
}
/* 经纪人 */
const ProxyAssistant = {
name: '经纪人张某',
scheduleTime(ad) {
Object.defineProperty(SuperStar, 'scheduleFlag', { // 在这里监听 scheduleFlag 值的变化
get() {
return SuperStar.scheduleFlagActually
},
set(val) {
if (SuperStar.scheduleFlagActually === false &&
val === true) { // 小鲜肉现在有空了
SuperStar.scheduleFlagActually = true
SuperStar.playAdvertisement(ad) // 安排上了
}
}
})
setTimeout(() => {
console.log('小鲜鲜有空了')
SuperStar.scheduleFlag = true
}, 2000) // 明星有空了
},
playAdvertisement(reward, ad) {
if (reward > 1000000) { // 如果报酬超过100w
console.log('没问题,我们小鲜鲜最喜欢拍广告了!')
ProxyAssistant.scheduleTime(ad)
} else
console.log('没空,滚!')
}
}
ProxyAssistant.playAdvertisement(10000, '纯蒸酸牛奶,味道纯纯,尽享纯蒸')
// 输出: 没空,滚
ProxyAssistant.playAdvertisement(1000001, '纯蒸酸牛奶,味道纯纯,尽享纯蒸')
// 输出: 没问题,我们小鲜鲜最喜欢拍广告了!
// 2秒后
// 输出: 小鲜鲜有空了
// 输出: 纯蒸酸牛奶,味道纯纯,尽享纯蒸
4. 代理模式在实战中的应用 4.1 拦截器
上一小节使用代理模式代理对象的访问的方式,一般又被称为拦截器。
- 拦截器的思想在实战中应用非常多,比如我们在项目中经常使用
Axios的实例来进行HTTP的请求,使用拦截器interceptor可以提前对request请求和response返回进行一些预处理,比如: request请求头的设置,和Cookie信息的设置;- 权限信息的预处理,常见的比如验权操作或者
Token验证; - 数据格式的格式化,比如对组件绑定的
Date类型的数据在请求前进行一些格式约定好的序列化操作; - 空字段的格式预处理,根据后端进行一些过滤操作;
response的一些通用报错处理,比如使用Message控件抛出错误;除了HTTP相关的拦截器之外,还有路由跳转的拦截器,可以进行一些路由跳转的预处理等操作。
4.2 前端框架的数据响应式化
- 现在的很多前端框架或者状态管理框架都使用上面介绍的
Object.defineProperty和Proxy来实现数据的响应式化,比如Vue、Mobx、AvalonJS等,Vue 2.x与AvalonJS使用前者,而Vue 3.x与Mobx 5.x使用后者。 Vue 2.x中通过Object.defineProperty来劫持各个属性的setter/getter,在数据变动时,通过发布-订阅模式发布消息给订阅者,触发相应的监听回调,从而实现数据的响应式化,也就是数据到视图的双向绑定。
为什么
Vue 2.x到3.x要从Object.defineProperty改用Proxy呢,是因为前者的一些局限性,导致的以下缺陷:
- 无法监听利用索引直接设置数组的一个项,例如:
vm.items[indexOfItem] = newValue; - 无法监听数组的长度的修改,例如:
vm.items.length = newLength; - 无法监听
ES6的Set、WeakSet、Map、WeakMap的变化; - 无法监听
Class类型的数据; - 无法监听对象属性的新加或者删除;
- 除此之外还有性能上的差异,基于这些原因,
Vue 3.x改用Proxy来实现数据监听了。当然缺点就是对IE用户的不友好,兼容性敏感的场景需要做一些取舍。
4.3 缓存代理
在高阶函数的文章中,就介绍了备忘模式,备忘模式就是使用缓存代理的思想,将复杂计算的结果缓存起来,下次传参一致时直接返回之前缓存的计算结果。
4.4 保护代理和虚拟代理
有的书籍中着重强调代理的两种形式:保护代理和虚拟代理:
- 保护代理 :当一个对象可能会收到大量请求时,可以设置保护代理,通过一些条件判断对请求进行过滤;
- 虚拟代理 :在程序中可以能有一些代价昂贵的操作,此时可以设置虚拟代理,虚拟代理会在适合的时候才执行操作。
保护代理其实就是对访问的过滤,之前的经纪人例子就属于这种类型。
而虚拟代理是为一个开销很大的操作先占位,之后再执行,比如:
一个很大的图片加载前,一般使用菊花图、低质量图片等提前占位,优化图片加载导致白屏的情况; 现在很流行的页面加载前使用骨架屏来提前占位,很多
WebApp和NativeApp都采用这种方式来优化用户白屏体验

4.5 正向代理与反向代理
还有个经常用的例子是反向代理(Reverse Proxy),反向代理对应的是正向代理(Forward Proxy),他们的区别是:
- 正向代理: 一般的访问流程是客户端直接向目标服务器发送请求并获取内容,使用正向代理后,客户端改为向代理服务器发送请求,并指定目标服务器(原始服务器),然后由代理服务器和原始服务器通信,转交请求并获得的内容,再返回给客户端。正向代理隐藏了真实的客户端,为客户端收发请求,使真实客户端对服务器不可见;
- 反向代理: 与一般访问流程相比,使用反向代理后,直接收到请求的服务器是代理服务器,然后将请求转发给内部网络上真正进行处理的服务器,得到的结果返回给客户端。反向代理隐藏了真实的服务器,为服务器收发请求,使真实服务器对客户端不可见。
反向代理一般在处理跨域请求的时候比较常用,属于服务端开发人员的日常操作了,另外在缓存服务器、负载均衡服务器等等场景也是使用到代理模式的思想。
5. 代理模式的优缺点
代理模式的主要优点有:
- 代理对象在访问者与目标对象之间可以起到中介和保护目标对象的作用;
- 代理对象可以扩展目标对象的功能;
- 代理模式能将访问者与目标对象分离,在一定程度上降低了系统的耦合度,如果我们希望适度扩展目标对象的一些功能,通过修改代理对象就可以了,符合开闭原则;
- 代理模式的缺点主要是增加了系统的复杂度,要斟酌当前场景是不是真的需要引入代理模式(十八线明星就别请经纪人了)
6. 其他相关模式
很多其他的模式,比如状态模式、策略模式、访问者模式其实也是使用了代理模式,包括在之前高阶函数处介绍的备忘模式,本质上也是一种缓存代理。
6.1 代理模式与适配器模式
代理模式和适配器模式都为另一个对象提供间接性的访问,他们的区别:
- 适配器模式: 主要用来解决接口之间不匹配的问题,通常是为所适配的对象提供一个不同的接口;
- 代理模式: 提供访问目标对象的间接访问,以及对目标对象功能的扩展,一般提供和目标对象一样的接口;
6.2 代理模式与装饰者模式
装饰者模式实现上和代理模式类似,都是在访问目标对象之前或者之后执行一些逻辑,但是目的和功能不同:
- 装饰者模式: 目的是为了方便地给目标对象添加功能,也就是动态地添加功能;
- 代理模式: 主要目的是控制其他访问者对目标对象的访问;
# 享元模式
享元模式 (Flyweight Pattern)运用共享技术来有效地支持大量细粒度对象的复用,以减少创建的对象的数量。
享元模式的主要思想是共享细粒度对象,也就是说如果系统中存在多个相同的对象,那么只需共享一份就可以了,不必每个都去实例化每一个对象,这样来精简内存资源,提升性能和效率。
Fly 意为苍蝇,Flyweight 指轻蝇量级,指代对象粒度很小。
1. 你曾见过的享元模式
我们去驾考的时候,如果给每个考试的人都准备一辆车,那考场就挤爆了,考点都堆不下考试车,因此驾考现场一般会有几辆车给要考试的人依次使用。如果考生人数少,就分别少准备几个自动档和手动档的驾考车,考生多的话就多准备几辆。如果考手动档的考生比较多,就多准备几辆手动档的驾考车。
我们去考四六级的时候(为什么这么多考试?😅),如果给每个考生都准备一个考场,怕是没那么多考场也没有这么多监考老师,因此现实中的大多数情况都是几十个考生共用一个考场。四级考试和六级考试一般同时进行,如果考生考的是四级,那么就安排四级考场,听四级的听力和试卷,六级同理。
生活中类似的场景还有很多,比如咖啡厅的咖啡口味,餐厅的菜品种类,拳击比赛的重量级等等。
在类似场景中,这些例子有以下特点:
- 目标对象具有一些共同的状态,比如驾考考生考的是自动档还是手动档,四六级考生考的是四级还是六级;
- 这些共同的状态所对应的对象,可以被共享出来;
2. 实例的代码实现
首先假设考生的 ID 为奇数则考的是手动档,为偶数则考的是自动档。如果给所有考生都 new 一个驾考车,那么这个系统中就会创建了和考生数量一致的驾考车对象:
var candidateNum = 10 // 考生数量
var examCarNum = 0 // 驾考车的数量
/* 驾考车构造函数 */
function ExamCar(carType) {
examCarNum++
this.carId = examCarNum
this.carType = carType ? '手动档' : '自动档'
}
ExamCar.prototype.examine = function(candidateId) {
console.log('考生- ' + candidateId + ' 在' + this.carType + '驾考车- ' + this.carId + ' 上考试')
}
for (var candidateId = 1; candidateId <= candidateNum; candidateId++) {
var examCar = new ExamCar(candidateId % 2)
examCar.examine(candidateId)
}
console.log('驾考车总数 - ' + examCarNum)
// 输出: 驾考车总数 - 10
如果考生很多,那么系统中就会存在更多个驾考车对象实例,假如驾考车对象比较复杂,那么这些新建的驾考车实例就会占用大量内存。这时我们将同种类型的驾考车实例进行合并,手动档和自动档档驾考车分别引用同一个实例,就可以节约大量内存:
var candidateNum = 10 // 考生数量
var examCarNum = 0 // 驾考车的数量
/* 驾考车构造函数 */
function ExamCar(carType) {
examCarNum++
this.carId = examCarNum
this.carType = carType ? '手动档' : '自动档'
}
ExamCar.prototype.examine = function(candidateId) {
console.log('考生- ' + candidateId + ' 在' + this.carType + '驾考车- ' + this.carId + ' 上考试')
}
var manualExamCar = new ExamCar(true)
var autoExamCar = new ExamCar(false)
for (var candidateId = 1; candidateId <= candidateNum; candidateId++) {
var examCar = candidateId % 2 ? manualExamCar : autoExamCar
examCar.examine(candidateId)
}
console.log('驾考车总数 - ' + examCarNum)
// 输出: 驾考车总数 - 2
可以看到我们使用 2 个驾考车实例就实现了刚刚 10 个驾考车实例实现的功能。这是仅有 10 个考生的情况,如果有几百上千考生,这时我们节约的内存就比较可观了,这就是享元模式要达到的目的。
3. 享元模式改进
- 如果你阅读了之前文章关于继承部分的讲解,那么你实际上已经接触到享元模式的思想了。相比于构造函数窃取,在原型链继承和组合继承中,子类通过原型 prototype 来复用父类的方法和属性,如果子类实例每次都创建新的方法与属性,那么在子类实例很多的情况下,内存中就存在有很多重复的方法和属性,即使这些方法和属性完全一样,因此这部分内存完全可以通过复用来优化,这也是享元模式的思想。
- 传统的享元模式是将目标对象的状态区分为内部状态和外部状态,内部状态相同的对象可以被共享出来指向同一个内部状态。正如之前举的驾考和四六级考试的例子中,自动档还是手动档、四级还是六级,就属于驾考考生、四六级考生中的内部状态,对应的驾考车、四六级考场就是可以被共享的对象。而考生的年龄、姓名、籍贯等就属于外部状态,一般没有被共享出来的价值。
主要的原理可以参看下面的示意图:

- 享元模式的主要思想是细粒度对象的共享和复用,因此对之前的驾考例子,我们可以继续改进一下:
- 如果某考生正在使用一辆驾考车,那么这辆驾考车的状态就是被占用,其他考生只能选择剩下未被占用状态的驾考车;
- 如果某考生对驾考车的使用完毕,那么将驾考车开回考点,驾考车的状态改为未被占用,供给其他考生使用;
- 如果所有驾考车都被占用,那么其他考生只能等待正在使用驾考车的考生使用完毕,直到有驾考车的状态变为未被占用;
- 组织单位可以根据考生数量多准备几辆驾考车,比如手动档考生比较多,那么手动档驾考车就应该比自动档驾考车多准备几辆;
- 我们可以简单实现一下,为了方便起见,这里就直接使用 ES6 的语法。
- 首先创建 3 个手动档驾考车,然后注册 10 个考生参与考试,一开始肯定有 3 个考生同时上车,然后在某个考生考完之后其他考生接着后面考。为了实现这个过程,这里使用了 Promise,考试的考生在 0 到 2 秒后的随机时间考试完毕归还驾考车,其他考生在前面考生考完之后接着进行考试:
let examCarNum = 0 // 驾考车总数
/* 驾考车对象 */
class ExamCar {
constructor(carType) {
examCarNum++
this.carId = examCarNum
this.carType = carType ? '手动档' : '自动档'
this.usingState = false // 是否正在使用
}
/* 在本车上考试 */
examine(candidateId) {
return new Promise((resolve => {
this.usingState = true
console.log(`考生- ${ candidateId } 开始在${ this.carType }驾考车- ${ this.carId } 上考试`)
setTimeout(() => {
this.usingState = false
console.log(`%c考生- ${ candidateId } 在${ this.carType }驾考车- ${ this.carId } 上考试完毕`, 'color:#f40')
resolve() // 0~2秒后考试完毕
}, Math.random() * 2000)
}))
}
}
/* 手动档汽车对象池 */
ManualExamCarPool = {
_pool: [], // 驾考车对象池
_candidateQueue: [], // 考生队列
/* 注册考生 ID 列表 */
registCandidates(candidateList) {
candidateList.forEach(candidateId => this.registCandidate(candidateId))
},
/* 注册手动档考生 */
registCandidate(candidateId) {
const examCar = this.getManualExamCar() // 找一个未被占用的手动档驾考车
if (examCar) {
examCar.examine(candidateId) // 开始考试,考完了让队列中的下一个考生开始考试
.then(() => {
const nextCandidateId = this._candidateQueue.length && this._candidateQueue.shift()
nextCandidateId && this.registCandidate(nextCandidateId)
})
} else this._candidateQueue.push(candidateId)
},
/* 注册手动档车 */
initManualExamCar(manualExamCarNum) {
for (let i = 1; i <= manualExamCarNum; i++) {
this._pool.push(new ExamCar(true))
}
},
/* 获取状态为未被占用的手动档车 */
getManualExamCar() {
return this._pool.find(car => !car.usingState)
}
}
ManualExamCarPool.initManualExamCar(3) // 一共有3个驾考车
ManualExamCarPool.registCandidates([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) // 10个考生来考试
在浏览器中运行下试试:

可以看到一个驾考的过程被模拟出来了,这里只简单实现了手动档,自动档驾考场景同理,就不进行实现了。上面的实现还可以进一步优化,比如考生多的时候自动新建驾考车,考生少的时候逐渐减少驾考车,但又不能无限新建驾考车对象,这些情况读者可以自行发挥~
- 如果可以将目标对象的内部状态和外部状态区分的比较明显,就可以将内部状态一致的对象很方便地共享出来,但是对 JavaScript 来说,我们并不一定要严格区分内部状态和外部状态才能进行资源共享,比如资源池模式。
4. 资源池 上
- 面这种改进的模式一般叫做资源池(Resource Pool),或者叫对象池(Object Pool),可以当作是享元模式的升级版,实现不一样,但是目的相同。资源池一般维护一个装载对象的池子,封装有获取、释放资源的方法,当需要对象的时候直接从资源池中获取,使用完毕之后释放资源等待下次被获取。
- 在上面的例子中,驾考车相当于有限资源,考生作为访问者根据资源的使用情况从资源池中获取资源,如果资源池中的资源都正在被占用,要么资源池创建新的资源,要么访问者等待占用的资源被释放。
- 资源池在后端应用相当广泛,比如缓冲池、连接池、线程池、字符常量池等场景,前端使用场景不多,但是也有使用,比如有些频繁的
DOM创建销毁操作,就可以引入对象池来节约一些 DOM 创建损耗。
下面介绍资源池的几种主要应用。
4.1 线程池
以
Node.js中的线程池为例,Node.js的JavaScript引擎是执行在单线程中的,启动的时候会新建 4 个线程放到线程池中,当遇到一些异步I/O操作(比如文件异步读写、DNS查询等)或者一些 CPU 密集的操作(Crypto、Zlib模块等)的时候,会在线程池中拿出一个线程去执行。如果有需要,线程池会按需创建新的线程。
线程池在整个
Node.js事件循环中的位置可以参照下图:
上面这个图就是 Node.js 的事件循环(Event Loop)机制,简单解读一下(扩展视野,不一定需要懂):
- 所有任务都在主线程上执行,形成执行栈(Execution Context Stack);
- 主线程之外维护一个任务队列(Task Queue),接到请求时将请求作为一个任务放入这个队列中,然后继续接收其他请求;
- 一旦执行栈中的任务执行完毕,主线程空闲时,主线程读取任务队列中的任务,检查队列中是否有要处理的事件,这时要分两种情况:如果是非 I/O 任务,就亲自处理,并通过回调函数返回到上层调用;如果是 I/O 任务,将传入的参数和回调函数封装成请求对象,并将这个请求对象推入线程池等待执行,主线程则读取下一个任务队列的任务,以此类推处理完任务队列中的任务;
- 线程池当线程可用时,取出请求对象执行 I/O 操作,任务完成以后归还线程,并把这个完成的事件放到任务队列的尾部,等待事件循环,当主线程再次循环到该事件时,就直接处理并返回给上层调用;
4.2 缓存
根据二八原则,80% 的请求其实访问的是 20% 的资源,我们可以将频繁访问的资源缓存起来,如果用户访问被缓存起来的资源就直接返回缓存的版本,这就是 Web 开发中经常遇到的缓存。
缓存服务器就是缓存的最常见应用之一,也是复用资源的一种常用手段。缓存服务器的示意图如下:
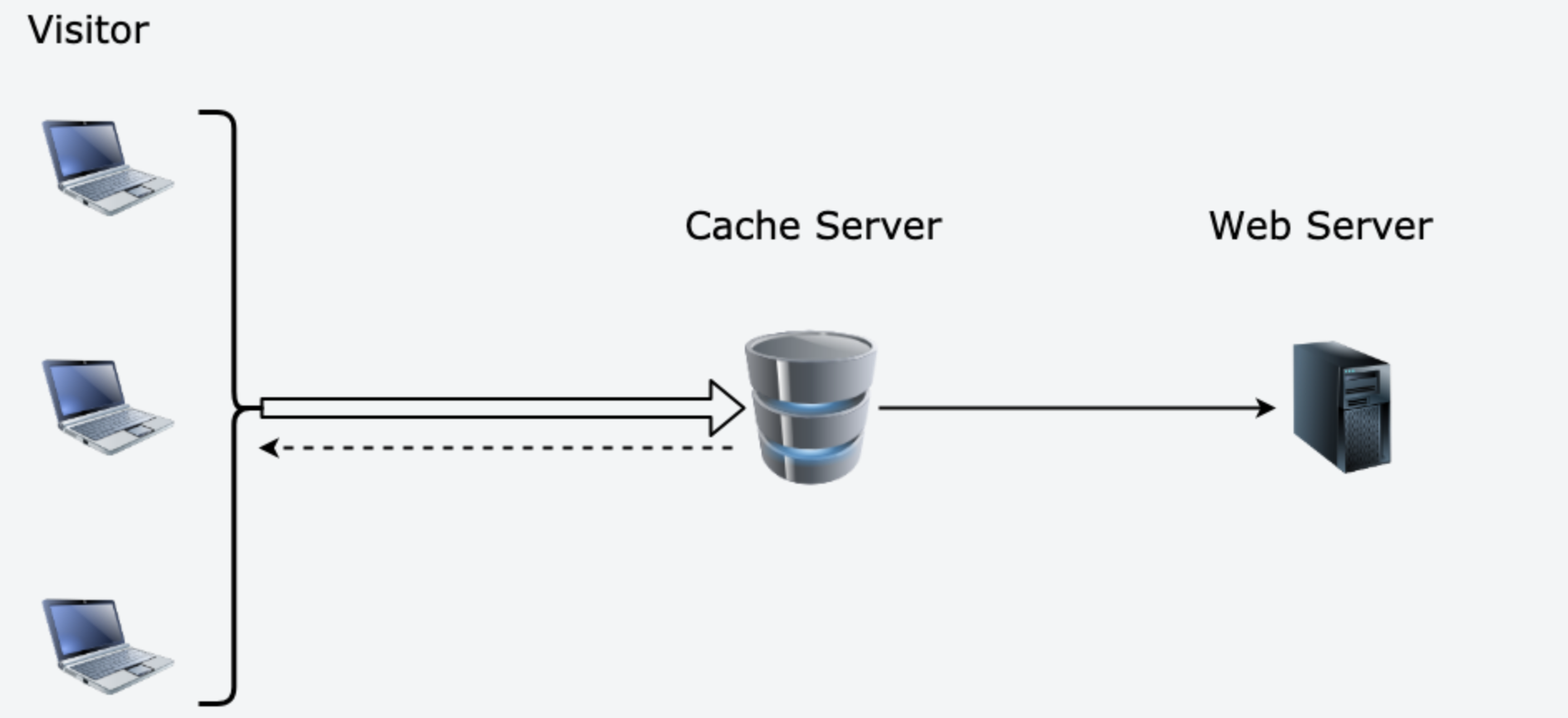
- 缓存服务器位于访问者与业务服务器之间,对业务服务器来说,减轻了压力,减小了负载,提高了数据查询的性能。对用户来说,提升了网页打开速度,优化了体验。
- 缓存技术用的非常多,不仅仅用在缓存服务器上,浏览器本地也有缓存,查询的 DNS 也有缓存,包括我们的电脑 CPU 上,也有缓存硬件。
4.3 连接池
我们知道对数据库进行操作需要先创建一个数据库连接对象,然后通过创建好的数据库连接来对数据库进行 CRUD(增删改查)操作。如果访问量不大,对数据库的 CRUD 操作就不多,每次访问都创建连接并在使用完销毁连接就没什么,但是如果访问量比较多,并发的要求比较高时,频繁创建和销毁连接就比较消耗资源了。
- 这时,可以不销毁连接,一直使用已创建的连接,就可以避免频繁创建销毁连接的损耗了。但是有个问题,一个连接同一时间只能做一件事,某使用者(一般是线程)正在使用时,其他使用者就不可以使用了,所以如果只创建一个不关闭的连接显然不符合要求,我们需要创建多个不关闭的连接。
- 这就是连接池的来源,创建多个数据库连接,当有调用的时候直接在创建好的连接中拿出来使用,使用完毕之后将连接放回去供其他调用者使用。
- 我们以
Node.js中mysql模块的连接池应用为例,看看后端一般是如何使用数据库连接池的。在 Node.js 中使用mysql创建单个连接,一般这样使用:
var mysql = require('mysql')
var connection = mysql.createConnection({ // 创建数据库连接
host: 'localhost',
user: 'root', // 用户名
password: '123456', // 密码
database: 'db', // 指定数据库
port: '3306' // 端口号
})
// 连接回调,在回调中增删改查
connection.connect(...)
// 关闭连接
connection.end(...)
在 Node.js 中使用 mysql 模块的连接池创建连接:
var mysql = require('mysql')
var pool = mysql.createPool({ // 创建数据库连接池
host: 'localhost',
user: 'root', // 用户名
password: '123456', // 密码
database: 'db', // 制定数据库
port: '3306' // 端口号
})
// 从连接池中获取一个连接,进行增删改查
pool.getConnection(function(err, connection) {
// ... 数据库操作
connection.release() // 将连接释放回连接池中
})
// 关闭连接池
pool.end()
- 一般连接池在初始化的时候,都会自动打开
n个连接,称为连接预热。如果这n个连接都被使用了,再从连接池中请求新的连接时,会动态地隐式创建额外连接,即自动扩容。如果扩容后的连接池一段时间后有不少连接没有被调用,则自动缩容,适当释放空闲连接,增加连接池中连接的使用效率。在连接失效的时候,自动抛弃无效连接。在系统关闭的时候,自动释放所有连接。为了维持连接池的有效运转和避免连接池无限扩容,还会给连接池设置最大最小连接数。 - 这些都是连接池的功能,可以看到连接池一般可以根据当前使用情况自动地进行缩容和扩容,来进行连接池资源的最优化,和连接池连接的复用效率最大化。这些连接池的功能点,看着是不是和之前驾考例子的优化过程有点似曾相识呢~
- 在实际项目中,除了数据库连接池外,还有
HTTP连接池。使用HTTP连接池管理长连接可以复用HTTP连接,省去创建TCP连接的3次握手和关闭TCP连接的4次挥手的步骤,降低请求响应的时间。
连接池某种程度也算是一种缓冲池,只不过这种缓冲池是专门用来管理连接的。
4.4 字符常量池
很多语言的引擎为了减少字符串对象的重复创建,会在内存中维护有一个特殊的内存,这个内存就叫字符常量池。当创建新的字符串时,引擎会对这个字符串进行检查,与字符常量池中已有的字符串进行比对,如果存在有相同内容的字符串,就直接将引用返回,否则在字符常量池中创建新的字符常量,并返回引用。
似于
Java、C#这些语言,都有字符常量池的机制。JavaScript 有多个引擎,以 Chrome 的 V8 引擎为例,V8 在把 JavaScript 编译成字节码过程中就引入了字符常量池这个优化手段,这就是为什么很多 JavaScript 的书籍都提到了 JavaScript 中的字符串具有不可变性,因为如果内存中的字符串可变,一个引用操作改变了字符串的值,那么其他同样的字符串也会受到影响。
可以引用《JavaScript 高级程序设计》中的话解释一下:
ECMAScript 中的字符串是不可变的,也就是说,字符串一旦创建,它们的值就不能改变。要改变某个变量保存的字符串,首先要销毁原来的字符串,然后再用另一个包含新值的字符串填充该变量。
字符常量池也是复用资源的一种手段,只不过这种手段通常用在编译器的运行过程中,通常开发(搬砖)过程用不到,了解即可。
5. 享元模式的优缺点
享元模式的优点:
- 由于减少了系统中的对象数量,提高了程序运行效率和性能,精简了内存占用,加快运行速度;
- 外部状态相对独立,不会影响到内部状态,所以享元对象能够在不同的环境被共享;
享元模式的缺点:
- 引入了共享对象,使对象结构变得复杂;
- 共享对象的创建、销毁等需要维护,带来额外的复杂度(如果需要把共享对象维护起来的话);
6. 享元模式的适用场景
- 如果一个程序中大量使用了相同或相似对象,那么可以考虑引入享元模式;
- 如果使用了大量相同或相似对象,并造成了比较大的内存开销;
- 对象的大多数状态可以被转变为外部状态;
- 剥离出对象的外部状态后,可以使用相对较少的共享对象取代大量对象;
- 在一些程序中,如果引入享元模式对系统的性能和内存的占用影响不大时,比如目标对象不多,或者场景比较简单,则不需要引入,以免适得其反。
7. 其他相关模式
- 享元模式和单例模式、工厂模式、组合模式、策略模式、状态模式等等经常会一起使用。
7.1 享元模式和工厂模式、单例模式
- 在区分出不同种类的外部状态后,创建新对象时需要选择不同种类的共享对象,这时就可以使用工厂模式来提供共享对象,在共享对象的维护上,经常会采用单例模式来提供单实例的共享对象。
7.2 享元模式和组合模式
- 在使用工厂模式来提供共享对象时,比如某些时候共享对象中的某些状态就是对象不需要的,可以引入组合模式来提升自定义共享对象的自由度,对共享对象的组成部分进一步归类、分层,来实现更复杂的多层次对象结构,当然系统也会更难维护。
7.3 享元模式和策略模式
策略模式中的策略属于一系列功能单一、细粒度的细粒度对象,可以作为目标对象来考虑引入享元模式进行优化,但是前提是这些策略是会被频繁使用的,如果不经常使用,就没有必要了。
# 适配器模式
- 适配器模式(Adapter Pattern)又称包装器模式,将一个类(对象)的接口(方法、属性)转化为用户需要的另一个接口,解决类(对象)之间接口不兼容的问题。
- 主要功能是进行转换匹配,目的是复用已有的功能,而不是来实现新的接口。也就是说,访问者需要的功能应该是已经实现好了的,不需要适配器模式来实现,适配器模式主要是负责把不兼容的接口转换成访问者期望的格式而已。
1. 你曾见过的适配器模式
- 现实生活中我们会遇到形形色色的适配器,最常见的就是转接头了,比如不同规格电源接口的转接头、iPhone 手机的 3.5 毫米耳机插口转接头、DP/miniDP/HDMI/DVI/VGA 等视频转接头、电脑、手机、ipad 的电源适配器,都是属于适配器的范畴。
- 还有一个比较典型的翻译官场景,比如老板张三去国外谈合作,带了个翻译官李四,那么李四就是作为讲不同语言的人之间交流的适配器 ?,老板张三的话的内容含义没有变化,翻译官将老板的话转换成国外客户希望的形式。
在类似场景中,这些例子有以下特点:
- 旧有接口格式已经不满足现在的需要;
- 通过增加适配器来更好地使用旧有接口;
2. 适配器模式的实现
我们可以实现一下电源适配器的例子,一开始我们使用的中国插头标准:
var chinaPlug = {
type: '中国插头',
chinaInPlug() {
console.log('开始供电')
}
}
chinaPlug.chinaInPlug()
// 输出:开始供电
但是我们出国旅游了,到了日本,需要增加一个日本插头到中国插头的电源适配器,来将我们原来的电源线用起来:
var chinaPlug = {
type: '中国插头',
chinaInPlug() {
console.log('开始供电')
}
}
var japanPlug = {
type: '日本插头',
japanInPlug() {
console.log('开始供电')
}
}
/* 日本插头电源适配器 */
function japanPlugAdapter(plug) {
return {
chinaInPlug() {
return plug.japanInPlug()
}
}
}
japanPlugAdapter(japanPlug).chinaInPlug()
// 输出:开始供电
由于适配器模式的例子太简单,如果希望看更多的实战相关应用,可以看下一个小节。
适配器模式的原理大概如下图:
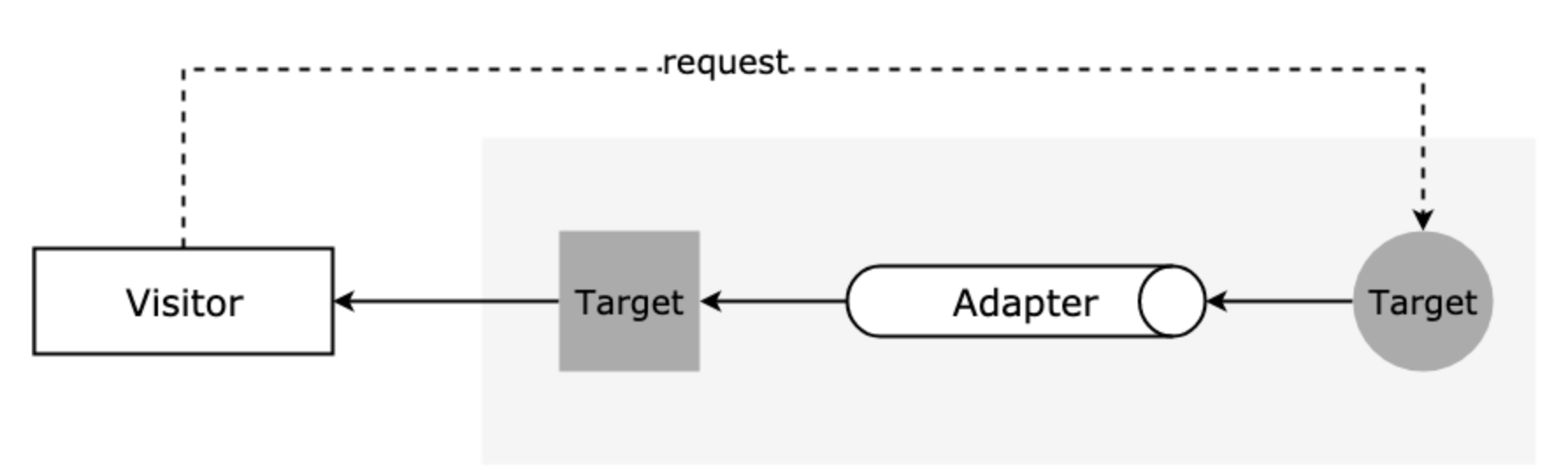
访问者需要目标对象的某个功能,但是这个对象的接口不是自己期望的,那么通过适配器模式对现有对象的接口进行包装,来获得自己需要的接口格式。
3. 适配器模式在实战中的应用
适配器模式在日常开发中还是比较频繁的,其实可能你已经使用了,但却不知道原来这就是适配器模式啊。 ?
我们可以推而广之,适配器可以将新的软件实体适配到老的接口,也可以将老的软件实体适配到新的接口,具体如何来进行适配,可以根据具体使用场景来灵活使用。
3.1 jQuery.ajax 适配 Axios
有的使用
jQuery的老项目使用$.ajax来发送请求,现在的新项目一般使用Axios,那么现在有个老项目的代码中全是$.ajax,如果你挨个修改,那么bug可能就跟地鼠一样到处冒出来让你焦头烂额,这时可以采用适配器模式来将老的使用形式适配到新的技术栈上:
/* 适配器 */
function ajax2AxiosAdapter(ajaxOptions) {
return axios({
url: ajaxOptions.url,
method: ajaxOptions.type,
responseType: ajaxOptions.dataType,
data: ajaxOptions.data
})
.then(ajaxOptions.success)
.catch(ajaxOptions.error)
}
/* 经过适配器包装 */
$.ajax = function(options) {
return ajax2AxiosAdapter(options)
}
$.ajax({
url: '/demo-url',
type: 'POST',
dataType: 'json',
data: {
name: '张三',
id: '2345'
},
success: function(data) {
console.log('访问成功!')
},
error: function(err) {
console.err('访问失败~')
}
})
可以看到老的代码表现形式依然不变,但是真正发送请求是通过新的发送方式来进行的。当然你也可以把
Axios的请求适配到$.ajax上,就看你如何使用适配器了。
3.2 业务数据适配
- 在实际项目中,我们经常会遇到树形数据结构和表形数据结构的转换,比如全国省市区结构、公司组织结构、军队编制结构等等。以公司组织结构为例,在历史代码中,后端给了公司组织结构的树形数据,在以后的业务迭代中,会增加一些要求非树形结构的场景。比如增加了将组织维护起来的功能,因此就需要在新增组织的时候选择上级组织,在某个下拉菜单中选择这个新增组织的上级菜单。或者增加了将人员归属到某一级组织的需求,需要在某个下拉菜单中选择任一级组织。
- 在这些业务场景中,都需要将树形结构平铺开,但是我们又不能直接将旧有的树形结构状态进行修改,因为在项目别的地方已经使用了老的树形结构状态,这时我们可以引入适配器来将老的数据结构进行适配:
/* 原来的树形结构 */
const oldTreeData = [
{
name: '总部',
place: '一楼',
children: [
{ name: '财务部', place: '二楼' },
{ name: '生产部', place: '三楼' },
{
name: '开发部', place: '三楼', children: [
{
name: '软件部', place: '四楼', children: [
{ name: '后端部', place: '五楼' },
{ name: '前端部', place: '七楼' },
{ name: '技术支持部', place: '六楼' }]
}, {
name: '硬件部', place: '四楼', children: [
{ name: 'DSP部', place: '八楼' },
{ name: 'ARM部', place: '二楼' },
{ name: '调试部', place: '三楼' }]
}]
}
]
}
]
/* 树形结构平铺 */
function treeDataAdapter(treeData, lastArrayData = []) {
treeData.forEach(item => {
if (item.children) {
treeDataAdapter(item.children, lastArrayData)
}
const { name, place } = item
lastArrayData.push({ name, place })
})
return lastArrayData
}
treeDataAdapter(oldTreeData)
// 返回平铺的组织结构
增加适配器后,就可以将原先状态的树形结构转化为所需的结构,而并不改动原先的数据,也不对原来使用旧数据结构的代码有所影响。
3.3 Vue 计算属性
Vue中的计算属性也是一个适配器模式的实例,以官网的例子为例,我们可以一起来理解一下:
<template>
<div id="example">
<p>Original message: "{{ message }}"</p> <!-- Hello -->
<p>Computed reversed message: "{{ reversedMessage }}"</p> <!-- olleH -->
</div>
</template>
<script type='text/javascript'>
export default {
name: 'demo',
data() {
return {
message: 'Hello'
}
},
computed: {
reversedMessage: function() {
return this.message.split('').reverse().join('')
}
}
}
</script>
旧有
data中的数据不满足当前的要求,通过计算属性的规则来适配成我们需要的格式,对原有数据并没有改变,只改变了原有数据的表现形式。
4. 源码中的适配器模式
Axios是比较热门的网络请求库,在浏览器中使用的时候,Axios的用来发送请求的adapter本质上是封装浏览器提供的API XMLHttpRequest,我们可以看看源码中是如何封装这个API的,为了方便观看,进行了一些省略:
module.exports = function xhrAdapter(config) {
return new Promise(function dispatchXhrRequest(resolve, reject) {
var requestData = config.data
var requestHeaders = config.headers
var request = new XMLHttpRequest()
// 初始化一个请求
request.open(config.method.toUpperCase(),
buildURL(config.url, config.params, config.paramsSerializer), true)
// 设置最大超时时间
request.timeout = config.timeout
// readyState 属性发生变化时的回调
request.onreadystatechange = function handleLoad() { ... }
// 浏览器请求退出时的回调
request.onabort = function handleAbort() { ... }
// 当请求报错时的回调
request.onerror = function handleError() { ... }
// 当请求超时调用的回调
request.ontimeout = function handleTimeout() { ... }
// 设置HTTP请求头的值
if ('setRequestHeader' in request) {
request.setRequestHeader(key, val)
}
// 跨域的请求是否应该使用证书
if (config.withCredentials) {
request.withCredentials = true
}
// 响应类型
if (config.responseType) {
request.responseType = config.responseType
}
// 发送请求
request.send(requestData)
})
}
可以看到这个模块主要是对请求头、请求配置和一些回调的设置,并没有对原生的
API有改动,所以也可以在其他地方正常使用。这个适配器可以看作是对XMLHttpRequest的适配,是用户对Axios调用层到原生XMLHttpRequest这个 API 之间的适配层。
源码可以参见 Github 仓库: axios/lib/adapters/xhr.js
5. 适配器模式的优缺点
适配器模式的优点:
- 已有的功能如果只是接口不兼容,使用适配器适配已有功能,可以使原有逻辑得到更好的复用,有助于避免大规模改写现有代码;
- 可扩展性良好,在实现适配器功能的时候,可以调用自己开发的功能,从而方便地扩展系统的功能;
- 灵活性好,因为适配器并没有对原有对象的功能有所影响,如果不想使用适配器了,那么直接删掉即可,不会对使用原有对象的代码有影响;
- 适配器模式的缺点:会让系统变得零乱,明明调用 A,却被适配到了 B,如果系统中这样的情况很多,那么对可阅读性不太友好。如果没必要使用适配器模式的话,可以考虑重构,如果使用的话,可以考虑尽量把文档完善。
6. 适配器模式的适用场景
- 当你想用已有对象的功能,却想修改它的接口时,一般可以考虑一下是不是可以应用适配器模式。
- 如果你想要使用一个已经存在的对象,但是它的接口不满足需求,那么可以使用适配器模式,把已有的实现转换成你需要的接口;
- 如果你想创建一个可以复用的对象,而且确定需要和一些不兼容的对象一起工作,这种情况可以使用适配器模式,然后需要什么就适配什么;
7. 其他相关模式
适配器模式和代理模式、装饰者模式看起来比较类似,都是属于包装模式,也就是用一个对象来包装另一个对象的模式,他们之间的异同在代理模式中已经详细介绍了,这里再简单对比一下。
7.1 适配器模式与代理模式
- 适配器模式: 提供一个不一样的接口,由于原来的接口格式不能用了,提供新的接口以满足新场景下的需求;
- 代理模式: 提供一模一样的接口,由于不能直接访问目标对象,找个代理来帮忙访问,使用者可以就像访问目标对象一样来访问代理对象;
7.2 适配器模式、装饰者模式与代理模式
- 适配器模式: 功能不变,只转换了原有接口访问格式;
- 装饰者模式: 扩展功能,原有功能不变且可直接使用;
- 代理模式: 原有功能不变,但一般是经过限制访问的;
# 装饰者模式
装饰者模式 (Decorator Pattern)又称装饰器模式,在不改变原对象的基础上,通过对其添加属性或方法来进行包装拓展,使得原有对象可以动态具有更多功能。
本质是功能动态组合,即动态地给一个对象添加额外的职责,就增加功能角度来看,使用装饰者模式比用继承更为灵活。好处是有效地把对象的核心职责和装饰功能区分开,并且通过动态增删装饰去除目标对象中重复的装饰逻辑。
1. 你曾见过的装饰者模式
- 相信大家都有过房屋装修的经历,当毛坯房建好的时候,已经可以居住了,虽然不太舒适。一般我们自己住当然不会住毛坯,因此我们还会通水电、墙壁刷漆、铺地板、家具安装、电器安装等等步骤,让房屋渐渐具有各种各样的特性,比如墙壁刷漆和铺地板之后房屋变得更加美观,有了家具居住变得更加舒适,但这些额外的装修并没有影响房屋是用来居住的这个基本功能,这就是装饰的作用。
- 再比如现在我们经常喝的奶茶,除了奶茶之外,还可以添加珍珠、波霸、椰果、仙草、香芋等等辅料,辅料的添加对奶茶的饮用并无影响,奶茶喝起来还是奶茶的味道,只不过辅料的添加让这杯奶茶的口感变得更多样化。
- 生活中类似的场景还有很多,比如去咖啡厅喝咖啡,点了杯摩卡之后我们还可以选择添加糖、冰块、牛奶等等调味品,给咖啡添加特别的口感和风味,但这些调味品的添加并没有影响咖啡的基本性质,不会因为添加了调味品,咖啡就变成奶茶。
在类似场景中,这些例子有以下特点:
- 装饰不影响原有的功能,原有功能可以照常使用;
- 装饰可以增加多个,共同给目标对象添加额外功能;
2. 实例的代码实现
我们可以使用 JavaScript 来将装修房子的例子实现一下:
/* 毛坯房 - 目标对象 */
function OriginHouse() {}
OriginHouse.prototype.getDesc = function() {
console.log('毛坯房')
}
/* 搬入家具 - 装饰者 */
function Furniture(house) {
this.house = house
}
Furniture.prototype.getDesc = function() {
this.house.getDesc()
console.log('搬入家具')
}
/* 墙壁刷漆 - 装饰者 */
function Painting(house) {
this.house = house
}
Painting.prototype.getDesc = function() {
this.house.getDesc()
console.log('墙壁刷漆')
}
var house = new OriginHouse()
house = new Furniture(house)
house = new Painting(house)
house.getDesc()
// 输出: 毛坯房 搬入家具 墙壁刷漆
使用 ES6 的 Class 语法:
/* 毛坯房 - 目标对象 */
class OriginHouse {
getDesc() {
console.log('毛坯房')
}
}
/* 搬入家具 - 装饰者 */
class Furniture {
constructor(house) {
this.house = house
}
getDesc() {
this.house.getDesc()
console.log('搬入家具')
}
}
/* 墙壁刷漆 - 装饰者 */
class Painting {
constructor(house) {
this.house = house
}
getDesc() {
this.house.getDesc()
console.log('墙壁刷漆')
}
}
let house = new OriginHouse()
house = new Furniture(house)
house = new Painting(house)
house.getDesc()
// 输出: 毛坯房 搬入家具 墙壁刷漆
是不是感觉很麻烦,装饰个功能这么复杂?我们 JSer 大可不必走这一套面向对象花里胡哨的,毕竟 JavaScript 的优点就是灵活:
/* 毛坯房 - 目标对象 */
var originHouse = {
getDesc() {
console.log('毛坯房 ')
}
}
/* 搬入家具 - 装饰者 */
function furniture() {
console.log('搬入家具 ')
}
/* 墙壁刷漆 - 装饰者 */
function painting() {
console.log('墙壁刷漆 ')
}
/* 添加装饰 - 搬入家具 */
originHouse.getDesc = function() {
var getDesc = originHouse.getDesc
return function() {
getDesc()
furniture()
}
}()
/* 添加装饰 - 墙壁刷漆 */
originHouse.getDesc = function() {
var getDesc = originHouse.getDesc
return function() {
getDesc()
painting()
}
}()
originHouse.getDesc()
// 输出: 毛坯房 搬入家具 墙壁刷漆
简洁明了,且更符合前端日常使用的场景。
3. 装饰者模式的原理
装饰者模式的原理如下图:
可以从上图看出,在表现形式上,装饰者模式和适配器模式比较类似,都属于包装模式。在装饰者模式中,一个对象被另一个对象包装起来,形成一条包装链,并增加了原先对象的功能。
4. 实战中的装饰者模式 4.1 给浏览器事件添加新功能
之前介绍的添加装饰器函数的方式,经常被用来给原有浏览器或
DOM绑定事件上绑定新的功能,比如在onload上增加新的事件,或在原来的事件绑定函数上增加新的功能,或者在原本的操作上增加用户行为埋点:
window.onload = function() {
console.log('原先的 onload 事件 ')
}
/* 发送埋点信息 */
function sendUserOperation() {
console.log('埋点:用户当前行为路径为 ...')
}
/* 将新的功能添加到 onload 事件上 */
window.onload = function() {
var originOnload = window.onload
return function() {
originOnload && originOnload()
sendUserOperation()
}
}()
// 输出: 原先的 onload 事件
// 输出: 埋点:用户当前行为路径为 ...
可以看到通过添加装饰函数,为
onload事件回调增加新的方法,且并不影响原本的功能,我们可以把上面的方法提取出来作为一个工具方法:
window.onload = function() {
console.log('原先的 onload 事件 ')
}
/* 发送埋点信息 */
function sendUserOperation() {
console.log('埋点:用户当前行为路径为 ...')
}
/* 给原生事件添加新的装饰方法 */
function originDecorateFn(originObj, originKey, fn) {
originObj[originKey] = function() {
var originFn = originObj[originKey]
return function() {
originFn && originFn()
fn()
}
}()
}
// 添加装饰功能
originDecorateFn(window, 'onload', sendUserOperation)
// 输出: 原先的 onload 事件
// 输出: 埋点:用户当前行为路径为 ...
4.2 TypeScript 中的装饰器
- 现在的越来越多的前端项目或
Node项目都在拥抱JavaScript的超集语言TypeScript,如果你了解过C#中的特性Attribute、Java中的注解Annotation、Python中的装饰器Decorator,那么你就不会对TypeScript中的装饰器感到陌生,下面我们简单介绍一下TypeScript中的装饰器。
TypeScript中的装饰器可以被附加到类声明、方法、访问符、属性和参数上,装饰器的类型有参数装饰器、方法装饰器、访问器或参数装饰器、参数装饰器。
TypeScript中的装饰器使用@expression这种形式,expression求值后为一个函数,它在运行时被调用,被装饰的声明信息会被做为参数传入。
多个装饰器应用使用在同一个声明上时:
- 由上至下依次对装饰器表达式求值;
- 求值的结果会被当成函数,由下至上依次调用;
那么使用官网的一个例子:
function f() {
console.log("f(): evaluated");
return function (target, propertyKey: string, descriptor: PropertyDescriptor) {
console.log("f(): called");
}
}
function g() {
console.log("g(): evaluated");
return function (target, propertyKey: string, descriptor: PropertyDescriptor) {
console.log("g(): called");
}
}
class C {
@f()
@g()
method() {}
}
// f(): evaluated
// g(): evaluated
// g(): called
// f(): called
可以看到上面的代码中,高阶函数
f与g返回了另一个函数(装饰器函数),所以f、g这里又被称为装饰器工厂,即帮助用户传递可供装饰器使用的参数的工厂。另外注意,演算的顺序是从下到上,执行的时候是从下到上的。
再比如下面一个场景
class Greeter {
greeting: string;
constructor(message: string) {
this.greeting = message;
}
greet() {
return "Hello, " + this.greeting;
}
}
for (let key in new Greeter('Jim')) {
console.log(key);
}
// 输出: greeting greet
如果我们不希望
greet被for-in循环遍历出来,可以通过装饰器的方式来方便地修改属性的属性描述符:
function enumerable(value: boolean) {
return function (target: any, propertyKey: string, descriptor: PropertyDescriptor) {
descriptor.enumerable = value;
};
}
class Greeter {
greeting: string;
constructor(message: string) {
this.greeting = message;
}
@enumerable(false)
greet() {
return "Hello, " + this.greeting;
}
}
for (let key in new Greeter('Jim')) {
console.log(key);
}
// 输出: greeting
- 这样
greet就变成不可枚举了,使用起来比较方便,对其他属性进行声明不可枚举的时候也只用在之前加一行@enumerable(false)即可,不用大费周章的Object.defineProperty(...)进行繁琐的声明了。 TypeScript的装饰器还有很多有用的用法,感兴趣的同学可以阅读一下TypeScript的Decorators官网文档 相关内容。
5. 装饰者模式的优缺点
装饰者模式的优点:
- 我们经常使用继承的方式来实现功能的扩展,但这样会给系统中带来很多的子类和复杂的继承关系,装饰者模式允许用户在不引起子类数量暴增的前提下动态地修饰对象,添加功能,装饰者和被装饰者之间松耦合,可维护性好;
- 被装饰者可以使用装饰者动态地增加和撤销功能,可以在运行时选择不同的装饰器,实现不同的功能,灵活性好;
- 装饰者模式把一系列复杂的功能分散到每个装饰器当中,一般一个装饰器只实现一个功能,可以给一个对象增加多个同样的装饰器,也可以把一个装饰器用来装饰不同的对象,有利于装饰器功能的复用;
- 可以通过选择不同的装饰者的组合,创造不同行为和功能的结合体,原有对象的代码无须改变,就可以使得原有对象的功能变得更强大和更多样化,符合开闭原则;
装饰者模式的缺点:
- 使用装饰者模式时会产生很多细粒度的装饰者对象,这些装饰者对象由于接口和功能的多样化导致系统复杂度增加,功能越复杂,需要的细粒度对象越多;
- 由于更大的灵活性,也就更容易出错,特别是对于多级装饰的场景,错误定位会更加繁琐;
6. 装饰者模式的适用场景
- 如果不希望系统中增加很多子类,那么可以考虑使用装饰者模式;
- 需要通过对现有的一组基本功能进行排列组合而产生非常多的功能时,采用继承关系很难实现,这时采用装饰者模式可以很好实现;
- 当对象的功能要求可以动态地添加,也可以动态地撤销,可以考虑使用装饰者模式;
7. 其他相关模式 7.1 装饰者模式与适配器模式
装饰者模式和适配器模式都是属于包装模式,然而他们的意图有些不一样:
- 装饰者模式: 扩展功能,原有功能还可以直接使用,一般可以给目标对象多次叠加使用多个装饰者;
- 适配器模式: 功能不变,但是转换了原有接口的访问格式,一般只给目标对象使用一次;
7.2 装饰者模式与组合模式
这两个模式有相似之处,都涉及到对象的递归调用,从某个角度来说,可以把装饰者模式看做是只有一个组件的组合模式。
- 装饰者模式: 动态地给对象增加功能;
- 组合模式: 管理组合对象和叶子对象,为它们提供一致的操作接口给客户端,方便客户端的使用;
7.3 装饰者模式与策略模式
装饰者模式和策略模式都包含有许多细粒度的功能模块,但是他们的使用思路不同:
- 装饰者模式: 可以递归调用,使用多个功能模式,功能之间可以叠加组合使用;
- 策略模式: 只有一层选择,选择某一个功能;
# 外观模式
外观模式 (Facade Pattern)又叫门面模式,定义一个将子系统的一组接口集成在一起的高层接口,以提供一个一致的外观。外观模式让外界减少与子系统内多个模块的直接交互,从而减少耦合,让外界可以更轻松地使用子系统。本质是封装交互,简化调用。
外观模式在源码中使用很多,具体可以参考后文中源码阅读部分。
1. 你曾见过的外观模式
最近这些年无人机很流行,特别是大疆的旋翼无人机。旋翼无人机的种类也很多,四旋翼、六旋翼、八旋翼、十六旋翼甚至是共轴双桨旋翼机,他们因为结构不同而各自有一套原理类似,但实现细节不同的旋翼控制方式。
- 如果用户需要把每种旋翼的控制原理弄清楚,那么门槛就太高了,所以无人机厂商会把具体旋翼控制的细节封装起来,用户所要接触的只是手上的遥控器,无论什么类型的无人机,遥控器的控制方式都一样,前后左右上下和左转右转。
- 对于使用者来说,遥控器就相当于是无人机系统的外观,使用者只要操纵遥控器就可以达到控制无人机的目的,而具体无人机内部的飞行控制器、电调(电子调速器)、电机、数字电传、陀螺仪、加速度计等等子模块之间复杂的调用关系将被封装起来,对于使用者而言不需要了解,因此也降低了使用难度。
- 类似的例子也有不少,比如常见的空调、冰箱、洗衣机、洗碗机,内部结构都并不简单,对于我们使用者而言,理解他们内部的运行机制的门槛比较高,但是理解遥控器/控制面板上面寥寥几个按钮就相对容易的多,这就是外观模式的意义。
在类似场景中,这些例子有以下特点:
- 一个统一的外观为复杂的子系统提供一个简单的高层功能接口;
- 原本访问者直接调用子系统内部模块导致的复杂引用关系,现在可以通过只访问这个统一的外观来避免;
2. 实例的代码实现
无人机系统的模块图大概如下:
可以看到无人机系统还是比较复杂的,系统内模块众多,如果用户需要对每个模块的作用都了解的话,那就太麻烦了,有了遥控器之后,使用者只要操作摇杆,发出前进、后退等等的命令,无人机系统接受到信号之后会经过算法把计算后的指令发送到电调,控制对应电机以不同转速带动桨叶,给无人机提供所需的扭矩和升力,从而实现目标运动。
关于无人机的例子,因为子模块众多,写成代码有点太啰嗦,这里只给出一个简化版本的代码:
var uav = {
/* 电子调速器 */
diantiao1: {
up() {
console.log('电调1发送指令:电机1增大转速')
uav.dianji1.up()
},
down() {
console.log('电调1发送指令:电机1减小转速')
uav.dianji1.up()
}
},
diantiao2: {
up() {
console.log('电调2发送指令:电机2增大转速')
uav.dianji2.up()
},
down() {
console.log('电调2发送指令:电机2减小转速')
uav.dianji2.down()
}
},
diantiao3: {
up() {
console.log('电调3发送指令:电机3增大转速')
uav.dianji3.up()
},
down() {
console.log('电调3发送指令:电机3减小转速')
uav.dianji3.down()
}
},
diantiao4: {
up() {
console.log('电调4发送指令:电机4增大转速')
uav.dianji4.up()
},
down() {
console.log('电调4发送指令:电机4减小转速')
uav.dianji4.down()
}
},
/* 电机 */
dianji1: {
up() { console.log('电机1增大转速') },
down() { console.log('电机1减小转速') }
},
dianji2: {
up() { console.log('电机2增大转速') },
down() { console.log('电机2减小转速') }
},
dianji3: {
up() { console.log('电机3增大转速') },
down() { console.log('电机3减小转速') }
},
dianji4: {
up() { console.log('电机4增大转速') },
down() { console.log('电机4减小转速') }
},
/* 遥控器 */
controller: {
/* 上升 */
up() {
uav.diantiao1.up()
uav.diantiao2.up()
uav.diantiao3.up()
uav.diantiao4.up()
},
/* 前进 */
forward() {
uav.diantiao1.down()
uav.diantiao2.down()
uav.diantiao3.up()
uav.diantiao4.up()
},
/* 下降 */
down() {
uav.diantiao1.down()
uav.diantiao2.down()
uav.diantiao3.down()
uav.diantiao4.down()
},
/* 左转 */
left() {
uav.diantiao1.up()
uav.diantiao2.down()
uav.diantiao3.up()
uav.diantiao4.down()
}
}
}
/* 操纵无人机 */
uav.controller.down() // 发送下降指令
uav.controller.left() // 发送左转指令
无人机系统是比较复杂,但是可以看到无人机的操纵却比较简单,正是因为有遥控器这个外观的存在。
3. 外观模式的原理
- 正如之前无人机的例子,虽然无人机实际操控比较复杂,但是通过对 controller 这个遥控器的使用,让使用者对无人机这个系统的控制变得简单,只需调用遥控器这个外观提供的方法即可,而这个方法里封装的一系列复杂操作,则不是我们要关注的重点。
- 从中就可以理解外观模式的意义了,遥控器作为无人机系统的功能出口,降低了使用者对复杂的无人机系统使用的难度,甚至让广场上的小朋友都能玩起来了
概略图如下:
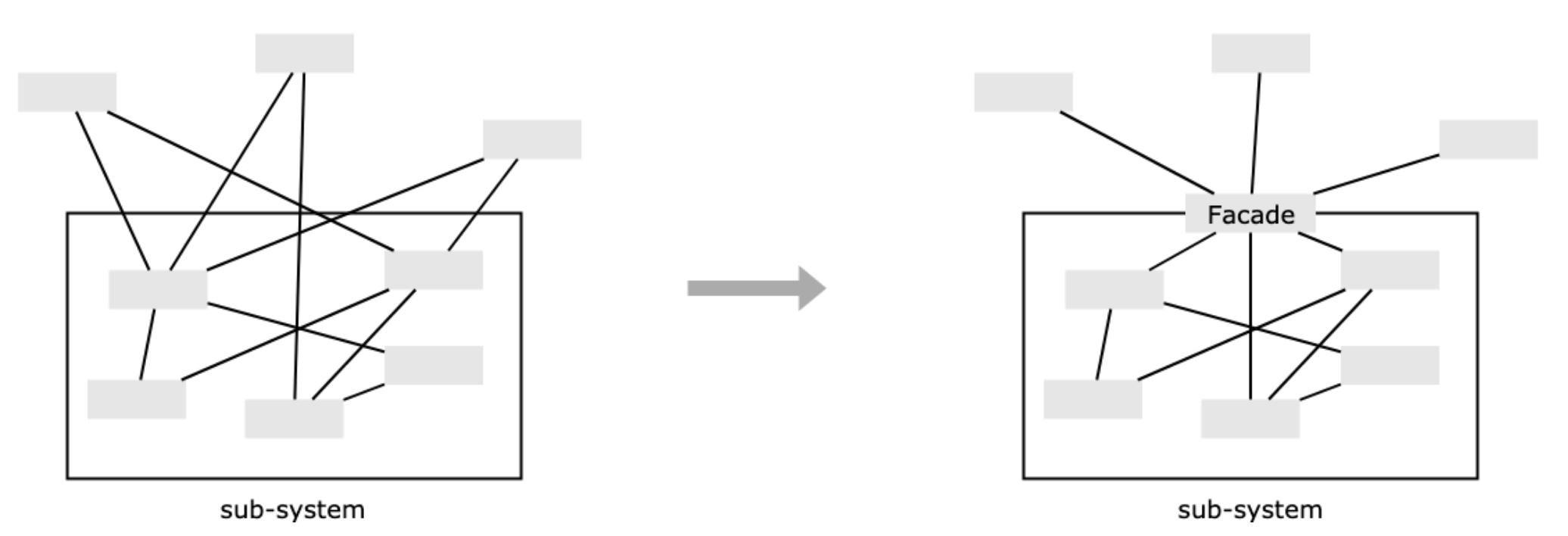
注意:外观模式一般是作为子系统的功能出口出现,使用的时候可以在其中增加新的功能,但是不推介这样做,因为外观应该是对已有功能的包装,不应在其中掺杂新的功能。
4. 实战中的外观模式 4.1 函数参数重载
有一种情况,比如某个函数有多个参数,其中一个参数可以传递也可以不传递,你当然可以直接弄两个接口,但是使用函数参数重载的方式,可以让使用者获得更大的自由度,让两个使用上基本类似的方法获得统一的外观。
function domBindEvent(nodes, type, selector, fn) {
if (fn === undefined) {
fn = selector
selector = null
}
// ... 剩下相关逻辑
}
domBindEvent(nodes, 'click', '#div1', fn)
domBindEvent(nodes, 'click', fn)
- 这种方式在一些工具库或者框架提供的多功能方法上经常得到使用,特别是在通用 API 的某些参数可传可不传的时候。
- 参数重载之后的函数在使用上会获得更大的自由度,而不必重新创建一个新的
API,这在Vue、React、jQuery、Lodash等库中使用非常频繁。
4.2 抹平浏览器兼容性问题
外观模式经常被用于
JavaScript的库中,封装一些接口用于兼容多浏览器,让我们可以间接调用我们封装的外观,从而屏蔽了浏览器差异,便于使用。
比如经常用的兼容不同浏览器的事件绑定方法:
function addEvent(element, type, fn) {
if (element.addEventListener) { // 支持 DOM2 级事件处理方法的浏览器
element.addEventListener(type, fn, false)
} else if (element.attachEvent) { // 不支持 DOM2 级但支持 attachEvent
element.attachEvent('on' + type, fn)
} else {
element['on' + type] = fn // 都不支持的浏览器
}
}
var myInput = document.getElementById('myinput')
addEvent(myInput, 'click', function() {
console.log('绑定 click 事件')
})
- 下面一个小节我们可以看看 jQuery 的源码是如何进行事件绑定的。
- 除了事件绑定之外,在抹平浏览器兼容性的其他问题上我们也经常使用外观模式:
// 移除 DOM 上的事件
function removeEvent(element, type, fn) {
if (element.removeEventListener) {
element.removeEventListener(type, fn, false)
} else if (element.detachEvent) {
element.detachEvent('on' + type, fn)
} else {
element['on' + type] = null
}
}
// 获取样式
function getStyle(obj, styleName) {
if (window.getComputedStyle) {
var styles = getComputedStyle(obj, null)[styleName]
} else {
var styles = obj.currentStyle[styleName]
}
return styles
}
// 阻止默认事件
var preventDefault = function(event) {
if (event.preventDefault) {
event.preventDefault()
} else { // IE 下
event.returnValue = false
}
}
// 阻止事件冒泡
var cancelBubble = function(event) {
if (event.stopPropagation) {
event.stopPropagation()
} else { // IE 下
event.cancelBubble = true
}
}
通过将处理不同浏览器兼容性问题的过程封装成一个外观,我们在使用的时候可以直接使用外观方法即可,在遇到兼容性问题的时候,这个外观方法自然帮我们解决,方便又不容易出错。
5. 源码中的外观模式 5.1 Vue 源码中的函数参数重载
Vue提供的一个创建元素的方法createElement就使用了函数参数重载,使得使用者在使用这个参数的时候很灵活:
export function createElement(
context,
tag,
data,
children,
normalizationType,
alwaysNormalize
) {
if (Array.isArray(data) || isPrimitive(data)) { // 参数的重载
normalizationType = children
children = data
data = undefined
}
// ...
}
createElement方法里面对第三个参数data进行了判断,如果第三个参数的类型是array、string、number、boolean中的一种,那么说明是createElement(tag [, data], children, ...)这样的使用方式,用户传的第二个参数不是data,而是children。data这个参数是包含模板相关属性的数据对象,如果用户没有什么要设置,那这个参数自然不传,不使用函数参数重载的情况下,需要用户手动传递null或者undefined之类,参数重载之后,用户对data这个参数可传可不传,使用自由度比较大,也很方便。createElement方法的源码参见 Github 链接vue/src/core/vdom/create-element.js
5.2 Lodash 源码中的函数参数重载
Lodash的 range 方法的 API 为_.range([start=0], end, [step=1]),这就很明显使用了参数重载,这个方法调用了一个内部函数createRange:
function createRange(fromRight) {
return (start, end, step) => {
// ...
if (end === undefined) {
end = start
start = 0
}
// ...
}
}
意思就是,如果没有传第二个参数,那么就把传入的第一个参数作为 end,并把 start 置为默认值。
createRange 方法的源码参见 Github 链接 lodash/.internal/createRange.js
5.3 jQuery 源码中的函数参数重载
函数参数重载在源码中使用比较多,jQuery 中也有大量使用,比如
on、off、bind、one、load、ajaxPrefilter等方法,这里以off方法为例,该方法在选择元素上移除一个或多个事件的事件处理函数。源码如下:
off: function (types, selector, fn) {
// ...
if (selector === false || typeof selector === 'function') {
// ( types [, fn] ) 的使用方式
fn = selector
selector = undefined
}
// ...
}
可以看到如果传入第二个参数为
false或者是函数的时候,就是off(types [, fn])的使用方式。
off方法的源码参见 Github 链接jquery/src/event.js
再比如 load 方法的源码:
jQuery.fn.load = function(url, params, callback) {
// ...
if (isFunction(params)) {
callback = params
params = undefined
}
// ...
}
- 可以看到
jQuery对第二个参数进行了判断,如果是函数,就是load(url [, callback])的使用方式。 load方法的源码参见 Github 链接jquery/src/ajax/load.js
5.4 jQuery 源码中的外观模式
当我们使用
jQuery的$(document).ready(...)来给浏览器加载事件添加回调时,jQuery会使用源码中的bindReady方法:
bindReady: function() {
// ...
// Mozilla, Opera and webkit 支持
if (document.addEventListener) {
document.addEventListener('DOMContentLoaded', DOMContentLoaded, false)
// A fallback to window.onload, that will always work
window.addEventListener('load', jQuery.ready, false)
// 如果使用了 IE 的事件绑定形式
} else if (document.attachEvent) {
document.attachEvent('onreadystatechange', DOMContentLoaded)
// A fallback to window.onload, that will always work
window.attachEvent('onload', jQuery.ready)
}
// ...
}
- 通过这个方法,
jQuery帮我们将不同浏览器下的不同绑定形式隐藏起来,从而简化了使用。 bindReady 方法的源码参见 Github 链接jquery/src/core.js
除了屏蔽浏览器兼容性问题之外,jQuery 还有其他的一些其他外观模式的应用:
- 比如修改
css的时候可以$('p').css('color', 'red'),也可以$('p').css('width', 100),对不同样式的操作被封装到同一个外观方法中,极大地方便了使用,对不同样式的特殊处理(比如设置width的时候不用加px)也一同被封装了起来。 - 源码参见 Github 链接
jquery/src/css.js - 再比如
jQuery的ajax的API$.ajax(url [, settings]),当我们在设置以JSONP的形式发送请求的时候,只要传入 dataType: 'jsonp' 设置,jQuery会进行一些额外操作帮我们启动JSONP流程,并不需要使用者手动添加代码,这些都被封装在$.ajax()` 这个外观方法中了。
源码参见 Github 链接 jquery/src/ajax/jsonp.js
5.5 Axios 源码中的外观模式
Axios可以使用在不同环境中,那么在不同环境中发送HTTP请求的时候会使用不同环境中的特有模块,Axios这里是使用外观模式来解决这个问题的:
function getDefaultAdapter() {
// ...
if (typeof process !== 'undefined' && Object.prototype.toString.call(process) === '[object process]') {
// Nodejs 中使用 HTTP adapter
adapter = require('./adapters/http');
} else if (typeof XMLHttpRequest !== 'undefined') {
// 浏览器使用 XHR adapter
adapter = require('./adapters/xhr');
}
// ...
}
这个方法进行了一个判断,如果在
Nodejs的环境中则使用Nodejs的HTTP模块来发送请求,在浏览器环境中则使用XMLHTTPRequest这个浏览器API。
getDefaultAdapter方法源码参见 Github 链接axios/lib/defaults.js
6. 外观模式的优缺点
外观模式的优点:
- 访问者不需要再了解子系统内部模块的功能,而只需和外观交互即可,使得访问者对子系统的使用变得简单,符合最少知识原则,增强了可移植性和可读性;
- 减少了与子系统模块的直接引用,实现了访问者与子系统中模块之间的松耦合,增加了可维护性和可扩展性;
- 通过合理使用外观模式,可以帮助我们更好地划分系统访问层次,比如把需要暴露给外部的功能集中到外观中,这样既方便访问者使用,也很好地隐藏了内部的细节,提升了安全性;
外观模式的缺点:
- 不符合开闭原则,对修改关闭,对扩展开放,如果外观模块出错,那么只能通过修改的方式来解决问题,因为外观模块是子系统的唯一出口;
- 不需要或不合理的使用外观会让人迷惑,过犹不及;
7. 外观模式的适用场景
- 维护设计粗糙和难以理解的遗留系统,或者系统非常复杂的时候,可以为这些系统设置外观模块,给外界提供清晰的接口,以后新系统只需与外观交互即可;
- 你写了若干小模块,可以完成某个大功能,但日后常用的是大功能,可以使用外观来提供大功能,因为外界也不需要了解小模块的功能;
- 团队协作时,可以给各自负责的模块建立合适的外观,以简化使用,节约沟通时间;
- 如果构建多层系统,可以使用外观模式来将系统分层,让外观模块成为每层的入口,简化层间调用,松散层间耦合;
8. 其他相关模式 8.1 外观模式与中介者模式
- 外观模式: 封装子使用者对子系统内模块的直接交互,方便使用者对子系统的调用;
- 中介者模式: 封装子系统间各模块之间的直接交互,松散模块间的耦合;
8.2 外观模式与单例模式
有时候一个系统只需要一个外观,比如之前举的
Axios的HTTP模块例子。这时我们可以将外观模式和单例模式可以一起使用,把外观实现为单例。
# 组合模式
组合模式 (Composite Pattern)又叫整体-部分模式,它允许你将对象组合成树形结构来表现整体-部分层次结构,让使用者可以以一致的方式处理组合对象以及部分对象
1. 你曾见过的组合模式
大家电脑里的文件夹结构相比很熟悉了,文件夹下面可以有子文件夹,也可以有文件,子文件夹下面还可以有文件夹和文件,以此类推,共同组成了一个文件树,结构如下:
Folder 1
├── Folder 2
│ ├── File 1.txt
│ ├── File 2.txt
│ └── File 3.txt
└── Folder 3
├── File 4.txt
├── File 5.txt
└── File 6.txt
文件夹是树形结构的容器节点,容器节点可以继续包含其他容器节点,像树枝上还可以有其他树枝一样;也可以包含文件,不再增加新的层级,就像树的叶子一样处于末端,因此被称为叶节点。本文中,叶节点又称为叶对象,容器节点因为可以包含容器节点和非容器节点,又称为组合对象。
- 类似这样的结构还有公司的组织层级,比如企业下面可以有部门,部门有部门员工和科室,科室可以有科室员工和团队,团队下面又可以有团队员工和组,依次类推,共同组成完整的企业。还有生活中的容器,比如柜子可以直接放东西,也可以放盆,盆里可以放东西也可以放碗,以此类推。甚至我们的家庭结构也属于这种结构,祖父家庭有父亲家庭、伯伯家庭、叔叔家庭、姑姑家庭等,父亲家庭又有哥哥家庭、弟弟家庭,这也是很典型的整体-部分层次的结构。
- 当我们在某个文件夹下搜索某个文件的时候,通常我们希望搜索的结果包含组合对象的所有子孙对象;开家族会议的时候,开会的命令会被传达到家族中的每一个成员;领导希望我们 996 的时候,只要跟部门领导说一声,部门领导就会通知所有的员工来修福报,无论你是下属哪个组织的,都跑不掉…😅
在类似的场景中,有以下特点:
- 结构呈整体-部分的树形关系,整体部分一般称为组合对象,组合对象下还可以有组合对象和叶对象;
- 组合对象和叶对象有一致的接口和数据结构,以保证操作一致;
- 请求从树的最顶端往下传递,如果当前处理请求的对象是叶对象,叶对象自身会对请求作出相应的处理;如果当前处理的是组合对象,则遍历其下的子节点(叶对象),将请求继续传递给这些子节点;
2. 实例的代码实现
我们可以使用 JavaScript 来将之前的文件夹例子实现一下。
在本地一个「电影」文件夹下有两个子文件夹「漫威英雄电影」和「DC英雄电影」,分别各自有一些电影文件,我们要做的就是在这个电影文件夹里找大于 2G 的电影文件,无论是在这个文件夹下还是在子文件夹下,并输出它的文件名和文件大小。
/* 创建文件夹 */
var createFolder = function(name) {
return {
name: name,
_children: [],
/* 在文件夹下增加文件或文件夹 */
add(fileOrFolder) {
this._children.push(fileOrFolder)
},
/* 扫描方法 */
scan(cb) {
this._children.forEach(function(child) {
child.scan(cb)
})
}
}
}
/* 创建文件 */
var createFile = function(name, size) {
return {
name: name,
size: size,
/* 在文件下增加文件,应报错 */
add() {
throw new Error('文件下面不能再添加文件')
},
/* 执行扫描方法 */
scan(cb) {
cb(this)
}
}
}
var foldMovies = createFolder('电影')
// 创建子文件夹,并放入根文件夹
var foldMarvelMovies = createFolder('漫威英雄电影')
foldMovies.add(foldMarvelMovies)
var foldDCMovies = createFolder('DC英雄电影')
foldMovies.add(foldDCMovies)
// 为两个子文件夹分别添加电影
foldMarvelMovies.add(createFile('钢铁侠.mp4', 1.9))
foldMarvelMovies.add(createFile('蜘蛛侠.mp4', 2.1))
foldMarvelMovies.add(createFile('金刚狼.mp4', 2.3))
foldMarvelMovies.add(createFile('黑寡妇.mp4', 1.9))
foldMarvelMovies.add(createFile('美国队长.mp4', 1.4))
foldDCMovies.add(createFile('蝙蝠侠.mp4', 2.4))
foldDCMovies.add(createFile('超人.mp4', 1.6))
console.log('size 大于2G的文件有:')
foldMovies.scan(function(item) {
if (item.size > 2) {
console.log('name:' + item.name + ' size:' + item.size + 'GB')
}
})
// size 大于2G的文件有:
// name:蜘蛛侠.mp4 size:2.1GB
// name:金刚狼.mp4 size:2.3GB
// name:蝙蝠侠.mp4 size:2.4GB
作为灵活的 JavaScript,我们还可以使用链模式来进行改造一下,让我们添加子文件更加直观和方便。对链模式还不熟悉的同学可以看一下后面有一篇单独介绍链模式的文章~
/* 创建文件夹 */
const createFolder = function(name) {
return {
name: name,
_children: [],
/* 在文件夹下增加文件或文件夹 */
add(...fileOrFolder) {
this._children.push(...fileOrFolder)
return this
},
/* 扫描方法 */
scan(cb) {
this._children.forEach(child => child.scan(cb))
}
}
}
/* 创建文件 */
const createFile = function(name, size) {
return {
name: name,
size: size,
/* 在文件下增加文件,应报错 */
add() {
throw new Error('文件下面不能再添加文件')
},
/* 执行扫描方法 */
scan(cb) {
cb(this)
}
}
}
const foldMovies = createFolder('电影')
.add(
createFolder('漫威英雄电影')
.add(createFile('钢铁侠.mp4', 1.9))
.add(createFile('蜘蛛侠.mp4', 2.1))
.add(createFile('金刚狼.mp4', 2.3))
.add(createFile('黑寡妇.mp4', 1.9))
.add(createFile('美国队长.mp4', 1.4)),
createFolder('DC英雄电影')
.add(createFile('蝙蝠侠.mp4', 2.4))
.add(createFile('超人.mp4', 1.6))
)
console.log('size 大于2G的文件有:')
foldMovies.scan(item => {
if (item.size > 2) {
console.log(`name:${ item.name } size:${ item.size }GB`)
}
})
// size 大于2G的文件有:
// name:蜘蛛侠.mp4 size:2.1GB
// name:金刚狼.mp4 size:2.3GB
// name:蝙蝠侠.mp4 size:2.4GB
上面的代码比较 JavaScript 特色,如果我们使用传统的类呢,也是可以实现的,下面使用 ES6 的 class 语法来改写一下:
/* 文件夹类 */
class Folder {
constructor(name, children) {
this.name = name
this.children = children
}
/* 在文件夹下增加文件或文件夹 */
add(...fileOrFolder) {
this.children.push(...fileOrFolder)
return this
}
/* 扫描方法 */
scan(cb) {
this.children.forEach(child => child.scan(cb))
}
}
/* 文件类 */
class File {
constructor(name, size) {
this.name = name
this.size = size
}
/* 在文件下增加文件,应报错 */
add(...fileOrFolder) {
throw new Error('文件下面不能再添加文件')
}
/* 执行扫描方法 */
scan(cb) {
cb(this)
}
}
const foldMovies = new Folder('电影', [
new Folder('漫威英雄电影', [
new File('钢铁侠.mp4', 1.9),
new File('蜘蛛侠.mp4', 2.1),
new File('金刚狼.mp4', 2.3),
new File('黑寡妇.mp4', 1.9),
new File('美国队长.mp4', 1.4)]),
new Folder('DC英雄电影', [
new File('蝙蝠侠.mp4', 2.4),
new File('超人.mp4', 1.6)])
])
console.log('size 大于2G的文件有:')
foldMovies.scan(item => {
if (item.size > 2) {
console.log(`name:${ item.name } size:${ item.size }GB`)
}
})
// size 大于2G的文件有:
// name:蜘蛛侠.mp4 size:2.1GB
// name:金刚狼.mp4 size:2.3GB
// name:蝙蝠侠.mp4 size:2.4GB
在传统的语言中,为了保证叶对象和组合对象的外观一致,还会让他们实现同一个抽象类或接口。
3. 组合模式的概念
- 组合模式定义的包含组合对象和叶对象的层次结构,叶对象可以被组合成更复杂的组合对象,而这个组合对象又可以被组合,这样不断地组合下去。
- 在实际使用时,任何用到叶对象的地方都可以使用组合对象了。使用者可以不在意到底处理的节点是叶对象还是组合对象,也就不用写一些判断语句,让客户可以一致地使用组合结构的各节点,这就是所谓面向接口编程,从而减少耦合,便于扩展和维护。
组合模式的示意图如下:
4. 实战中的组合模式
类似于组合模式的结构其实我们经常碰到,比如浏览器的 DOM 树,从
<html/>根节点到<head/>、<body/>、<style/>等节点,而<body/>节点又可以有<div/>、<span/>、<p/>、<a/>等等节点,这些节点下面还可以有节点,而且这些节点的操作方式有的也比较类似。
我们可以借用上面示例代码的例子,方便地创建一个 DOM 树,由于浏览器 API 的返回值不太友好,因此我们稍微改造一下;
const createElement = ({ tag, attr, children }) => {
const node = tag
? document.createElement(tag)
: document.createTextNode(attr.text)
tag && Object.keys(attr)
.forEach(key => node.setAttribute(key, attr[key]))
children && children
.forEach(child =>
node.appendChild(createElement.call(null, child)))
return node
}
const ulElement = createElement({
tag: 'ul',
attr: { id: 'data-list' },
children: [
{
tag: 'li',
attr: { class: 'data-item' },
children: [{ attr: { text: 'li-item 1' } }]
},
{
tag: 'li',
attr: { class: 'data-item' },
children: [{ attr: { text: 'li-item 2' } }]
},
{
tag: 'li',
attr: { class: 'data-item' },
children: [{ attr: { text: 'li-item 3' } }]
}
]
})
// 输出:
// <ul id='data-list'>
// <li class='data-item'>li-item 1</li>
// <li class='data-item'>li-item 2</li>
// <li class='data-item'>li-item 3</li>
// </ul>
另外,之前的代码中添加文件的方式是不是很眼熟 😏,
Vue/React里创建元素节点的方法createElement也是类似这样使用,来组装元素节点:
// Vue
createElement('h3', { class: 'main-title' }, [
createElement('img', { class: 'avatar', attrs: { src: '../avatar.jpg' } }),
createElement('p', { class: 'user-desc' }, '长得帅老的快,长得丑活得久')
])
// React
React.createElement('h3', { className: 'user-info' },
React.createElement('img', { src: '../avatar.jpg', className: 'avatar' }),
React.createElement('p', { className: 'user-desc' }, '长得帅老的快,长得丑活得久')
)
类似的,
Vue中的虚拟DOM树,也是这样的结构:
{
tagName: 'ul', // 节点标签名
props: { // 属性
id: 'data-list'
},
children: [ // 节点的子节点
{
tagName: 'li',
props: { class: 'data-item' },
children: ['li-item 1']
},
{
tagName: 'li',
props: { class: 'data-item' },
children: ['li-item 2']
}, {
tagName: 'li',
props: { class: 'data-item' },
children: ['li-item 3']
}]
}
这样的虚拟 DOM 树,会被渲染成:
<ul id='data-list'>
<li class='data-item'>li-item 1</li>
<li class='data-item'>li-item 2</li>
<li class='data-item'>li-item 3</li>
</ul>
- 虚拟
DOM树中的每个虚拟DOM都是VNode类的实例,因此具有基本统一的外观,在操作时对父节点和子节点的操作是一致的,这也是组合模式的思想。 - 浏览器的
DOM树、Vue的虚拟DOM树等可以说和组织模式形似,也就是具有整体-部分的层次结构,但是在操作传递方面,没有组合模式所定义的特性。 - 这个特性就是职责链模式的特性,组合模式天生具有职责链,当请求组合模式中的组合对象时,请求会顺着父节点往子节点传递,直到遇到可以处理这个请求的节点,也就是叶节点。
5. 组合模式的优缺点 组合模式的优点:
- 由于组合对象和叶对象具有同样的接口,因此调用的是组合对象还是叶对象对使用者来说没有区别,使得使用者面向接口编程;
- 如果想在组合模式的树中增加一个节点比较容易,在目标组合对象中添加即可,不会影响到其他对象,对扩展友好,符合开闭原则,利于维护;
组合模式的缺点:
- 增加了系统复杂度,如果树中对象不多,则不一定需要使用;
- 如果通过组合模式创建了太多的对象,那么这些对象可能会让系统负担不起;
6. 组合模式的适用场景
- 如果对象组织呈树形结构就可以考虑使用组合模式,特别是如果操作树中对象的方法比较类似时;
- 使用者希望统一对待树形结构中的对象,比如用户不想写一堆 if-else 来处理树中的节点时,可以使用组合模式;
7. 其他相关模式 7.1 组合模式和职责链模式
正如前文所说,组合模式是天生实现了职责链模式的。
- 组合模式: 请求在组合对象上传递,被深度遍历到组合对象的所有子孙叶节点具体执行;
- 职责链模式: 实现请求的发送者和接受者之间的解耦,把多个接受者组合起来形成职责链,请求在链上传递,直到有接受者处理请求为止;
7.2 组合模式和迭代器模式
组合模式可以结合迭代器模式一起使用,在遍历组合对象的叶节点的时候,可以使用迭代器模式来遍历。
7.3 组合模式和命令模式
命令模式里有一个用法「宏命令」,宏命令就是组合模式和命令模式一起使用的结果,是组合模式组装而成
# 桥接模式
- 桥接模式(Bridge Pattern)又称桥梁模式,将抽象部分与它的实现部分分离,使它们都可以独立地变化。使用组合关系代替继承关系,降低抽象和实现两个可变维度的耦合度。
- 抽象部分和实现部分可能不太好理解,举个例子,香蕉、苹果、西瓜,它们共同的抽象部分就是水果,可以吃,实现部分就是不同的水果实体。再比如黑色手提包、红色钱包、蓝色公文包,它们共同的抽象部分是包和颜色,这部分的共性就可以被作为抽象提取出来。
1. 你曾见过的桥接模式
厂家在生产洗衣机、冰箱、空调等电器的时候,不同型号产品之间有一些部件,比如变频洗衣机:
- 产品型号 A 有小功率电机、直立滚筒、小功率变频器;
- 产品型号 B 有中功率电机、横置滚筒、中功率变频器;
- 产品型号 C 有大功率电机、横置滚筒、大功率变频器;
洗衣机产品由这三个部分组成,那么可以提取电机、滚筒、变频器部件作为抽象维度,在新建洗衣机实例的时候,把抽象出来的部件桥接起来组成一个完整的洗衣机实例。在变频洗衣机系列产品中,产品的部件可以沿着各自维度独立地变化。
再比如皮包,包的种类比如钱包、书包、公文包是一个维度,包的尺寸是一个维度,包的颜色又是一个维度,这些维度可以自由变化。这种情况在系统设计中,如果给每个种类对应的每个尺寸和颜色都设置一个类,那么系统中的类就会很多,如果根据实际需要对种类、尺寸、颜色这些维度进行组合,那么将大大减少系统中类的个数。
在类似场景中,这些例子有以下特点:
- 将抽象和实现分离,互相独立互不影响;
- 产品有多个维度(部件),每个维度都可以独立变化(实例化过程),洗衣机这个例子的维度就是电机、滚筒、变频器,洗衣机- 产品在这几个维度可以独立地进行变化,从而组装成不同的洗衣机产品;
2. 实例的代码实现
我们可以使用 JavaScript 来将之前的变频洗衣机例子实现一下。
/* 组装洗衣机 */
function Washer(motorType, rollerType, transducerType) {
this.motor = new Motor(motorType)
this.roller = new Roller(rollerType)
this.transducer = new Transducer(transducerType)
}
Washer.prototype.work = function() {
this.motor.run()
this.roller.run()
this.transducer.run()
}
/* 电机 */
function Motor(type) {
this.motorType = type + '电机'
}
Motor.prototype.run = function() {
console.log(this.motorType + '开始工作')
}
/* 滚筒 */
function Roller(type) {
this.rollerType = type + '滚筒'
}
Roller.prototype.run = function() {
console.log(this.rollerType + '开始工作')
}
/* 变频器 */
function Transducer(type) {
this.transducerType = type + '变频器'
}
Transducer.prototype.run = function() {
console.log(this.transducerType + '开始工作')
}
// 新建洗衣机
var washerA = new Washer('小功率', '直立', '小功率')
washerA.work()
// 输出:小功率电机开始工作
// 直立滚筒开始工作
// 小功率变频器开始工作
由于产品部件可以独立变化,所以创建新的洗衣机产品就非常容易:
var washerD = new Washer('小功率', '直立', '中功率')
washerD.work()
// 输出:小功率电机开始工作
// 直立滚筒开始工作
// 中功率变频器开始工作
可以看到由于洗衣机的结构被分别抽象为几个部件的组合,部件的实例化是在部件类各自的构造函数中完成,因此部件之间的实例化不会相互影响,新产品的创建也变得容易,这就是桥接模式的好处。
下面我们用 ES6 的 Class 语法实现一下:
/* 组装洗衣机 */
class Washer {
constructor(motorType, rollerType, transducerType) {
this.motor = new Motor(motorType)
this.roller = new Roller(rollerType)
this.transducer = new Transducer(transducerType)
}
/* 开始使用 */
work() {
this.motor.run()
this.roller.run()
this.transducer.run()
}
}
/* 电机 */
class Motor {
constructor(type) {
this.motorType = type + '电机'
}
run() {
console.log(this.motorType + '开始工作')
}
}
/* 滚筒 */
class Roller {
constructor(type) {
this.rollerType = type + '滚筒'
}
run() {
console.log(this.rollerType + '开始工作')
}
}
/* 变频器 */
class Transducer {
constructor(type) {
this.transducerType = type + '变频器'
}
run() {
console.log(this.transducerType + '开始工作')
}
}
const washerA = new Washer('小功率', '直立', '小功率')
washerA.work()
// 输出:小功率电机开始工作
// 直立滚筒开始工作
// 小功率变频器开始工作
- 如果再精致一点,可以让电机、滚筒、变频器等部件实例继承自各自的抽象类,将面向抽象进行到底,但是桥接模式在 JavaScript 中应用不多,适当了解即可,不用太死扣。
- 有时候为了更复用部件,可以将部件的实例化拿出来,对于洗衣机来说一个实体部件当然不能用两次,这里使用皮包的例子:
/* 皮包 */
class Bag {
constructor(type, color) {
this.type = type
this.color = color
}
/* 展示 */
show() {
console.log(
this.color.show() + this.type.show()
)
}
}
/* 皮包类型 */
class Type {
constructor(type) {
this.typeType = type
}
show() {
return this.typeType
}
}
/* 皮包颜色 */
class Color {
constructor(type) {
this.colorType = type
}
show() {
return this.colorType
}
}
/* 抽象实例化 */
const redColor = new Color('红色')
const walletType = new Type('钱包')
const briefcaseType = new Type('公文包')
const bagA = new Bag(walletType, redColor)
bagA.show()
// 输出:红色钱包
const bagB = new Bag(briefcaseType, redColor)
bagB.show()
// 输出:红色公文包
3. 桥接模式的原理
我们可以提炼一下桥接模式,洗衣机是产品(Product),电机、滚筒、变频器属于抽象出来的部件种类(Components),也属于独立的维度,而具体的部件实体小功率电机、直立滚筒、大功率变频器等属于部件实例(Instances),这些实例可以沿着各自维度变化,共同组成对应产品。主要有以下几个概念:
Product: 产品,由多个独立部件组成的产品;Component: 部件,组成产品的部件类;Instance: 部件类的实例;
概略图如下:

4. 实战中的桥接模式
在某一个开发场景,一个按钮的前景色本为黑色背景色为浅灰色,当光标 mouseover 的时候改变前景色为蓝色、背景色为绿色、尺寸变为 1.5 倍,当光标 mouseleave 的时候还原前景色、背景色、尺寸,在鼠标按下的时候前景色变为红色、背景色变为紫色、尺寸变为 0.5 倍,抬起后恢复原状。怎么样,这个需求是不是有点麻烦,别管为什么有这么奇葩的需求(产品:这个需求很简单,怎么实现我不管),现在需求已经怼到脸上了,我们要如何去实现呢?
我们自然可以这样写:
var btn = document.getElementById('btn')
btn.addEventListener('mouseover', function() {
btn.style.setProperty('color', 'blue')
btn.style.setProperty('background-color', 'green')
btn.style.setProperty('transform', 'scale(1.5)')
})
btn.addEventListener('mouseleave', function() {
btn.style.setProperty('color', 'black')
btn.style.setProperty('background-color', 'lightgray')
btn.style.setProperty('transform', 'scale(1)')
})
btn.addEventListener('mousedown', function() {
btn.style.setProperty('color', 'red')
btn.style.setProperty('background-color', 'purple')
btn.style.setProperty('transform', 'scale(.5)')
})
btn.addEventListener('mouseup', function() {
btn.style.setProperty('color', 'black')
btn.style.setProperty('background-color', 'lightgray')
btn.style.setProperty('transform', 'scale(1)')
})
的确可以达到目标需求,但是我们可以使用桥接模式来改造一下,我们可以把 DOM 对象的前景色、背景色作为其外观部件,尺寸属性是另一个尺寸部件,这样的话对各自部件的操作可以作为抽象被提取出来,使得对各自部件可以独立且方便地操作:
var btn = document.getElementById('btn')
/* 设置前景色和背景色 */
function setColor(element, color = 'black', bgc = 'lightgray') {
element.style.setProperty('color', color)
element.style.setProperty('background-color', bgc)
}
/* 设置尺寸 */
function setSize(element, size = '1') {
element.style.setProperty('transform', `scale(${ size })`)
}
btn.addEventListener('mouseover', function() {
setColor(btn, 'blue', 'green')
setSize(btn, '1.5')
})
btn.addEventListener('mouseleave', function() {
setColor(btn)
setSize(btn)
})
btn.addEventListener('mousedown', function() {
setColor(btn, 'red', 'purple')
setSize(btn, '.5')
})
btn.addEventListener('mouseup', function() {
setColor(btn)
setSize(btn)
})
是不是看起来清晰多了,这里的
setColor、setSize就是桥接函数,是将DOM(产品)及其属性(部件)连接在一起的桥梁,用户只要给桥接函数传递参数即可,十分便捷。其他DOM要有类似的对外观部件和尺寸部件的操作,也可以方便地进行复用。
5. 桥接模式的优缺点
桥接模式的优点:
- 分离了抽象和实现部分,将实现层(DOM 元素事件触发并执行具体修改逻辑)和抽象层( 元素外观、尺寸部分的修改函数)解耦,有利于分层;
- 提高了可扩展性,多个维度的部件自由组合,避免了类继承带来的强耦合关系,也减少了部件类的数量;
- 使用者不用关心细节的实现,可以方便快捷地进行使用;
桥接模式的缺点:
- 桥接模式要求两个部件没有耦合关系,否则无法独立地变化,因此要求正确的对系统变化的维度进行识别,使用范围存在局限性;
- 桥接模式的引入增加了系统复杂度;
6. 桥接模式的适用场景
- 如果产品的部件有独立的变化维度,可以考虑桥接模式;
- 不希望使用继承,或因为多层次继承导致系统类的个数急剧增加的系统;
- 产品部件的粒度越细,部件复用的必要性越大,可以考虑桥接模式;
7. 其他相关模式 7.1 桥接模式和策略模式
- 桥接模式: 复用部件类,不同部件的实例相互之间无法替换,但是相同部件的实例一般可以替换;
- 策略模式: 复用策略类,不同策略之间地位平等,可以相互替换;
7.2 桥接模式与模板方法模式
- 桥接模式: 将组成产品的部件实例的创建,延迟到实例的具体创建过程中;
- 模版方法模式: 将创建产品的某一步骤,延迟到子类中实现;
7.3 桥接模式与抽象工厂模式
这两个模式可以组合使用,比如部件类实例的创建可以结合抽象工厂模式,因为部件类实例也属于一个产品类簇,明显属于抽象工厂模式的适用范围,如果创建的部件类不多,或者比较简单,也可以使用简单工厂模式
# 四、行为型模式
# 发布-订阅模式
在众多设计模式中,可能最常见、最有名的就是发布-订阅模式了,本篇我们一起来学习这个模式。
- 发布-订阅模式 (
Publish-Subscribe Pattern, pub-sub)又叫观察者模式(Observer Pattern),它定义了一种一对多的关系,让多个订阅者对象同时监听某一个发布者,或者叫主题对象,这个主题对象的状态发生变化时就会通知所有订阅自己的订阅者对象,使得它们能够自动更新自己。 - 当然有人提出发布-订阅模式和观察者模式之间是有一些区别的,但是大部分情况下你可以将他们当成是一个模式,本文将不对它们之间进行区分,文末会简单讨论一下他们之间的微妙区别,了解即可
1. 你曾遇见过的发布-订阅模式
在现实生活中其实我们会经常碰到发布-订阅模式的例子。
- 比如当我们进入一个聊天室/群,如果有人在聊天室发言,那么这个聊天室里的所有人都会收到这个人的发言。这是一个典型的发布-订阅模式,当我们加入了这个群,相当于订阅了在这个聊天室发送的消息,当有新的消息产生,聊天室会负责将消息发布给所有聊天室的订阅者。
- 再举个栗子,当我们去 adadis 买鞋,发现看中的款式已经售罄了,售货员告诉你不久后这个款式会进货,到时候打电话通知你。于是你留了个电话,离开了商场,当下周某个时候 adadis 进货了,售货员拿出小本本,给所有关注这个款式的人打电话。
- 这也是一个日常生活中的一个发布-订阅模式的实例,虽然不知道什么时候进货,但是我们可以登记号码之后等待售货员的电话,不用每天都打电话问鞋子的信息。
- 上面两个小栗子,都属于发布-订阅模式的实例,群成员/买家属于消息的订阅者,订阅消息的变化,聊天室/售货员属于消息的发布者,在合适的时机向群成员/小本本上的订阅者发布消息。
adadis 售货员这个例子的各方关系大概如下图:
在这样的逻辑中,有以下几个特点:
- 买家(订阅者)只要声明对消息的一次订阅,就可以在未来的某个时候接受来自售货员(发布者)的消息,不用一直轮询消息的变化;
- 售货员(发布者)持有一个小本本(订阅者列表),对这个本本上记录的订阅者的情况并不关心,只需要在消息发生时挨个去通知小本本上的订阅者,当订阅者增加或减少时,只需要在小本本上增删记录即可;
- 将上面的逻辑升级一下,一个人可以加多个群,售货员也可以有多个小本本,当不同的群产生消息或者不款式的鞋进货了,发布者可以按照不同的名单/小本本分别去通知订阅了不同类型消息的订阅者,这里有个消息类型的概念;
2. 实例的代码实现
- 如果你在
DOM上绑定过事件处理函数addEventListener,那么你已经使用过发布-订阅模式了。 - 我们经常将一些操作挂载在
onload事件上执行,当页面元素加载完毕,就会触发你注册在onload事件上的回调。我们无法预知页面元素何时加载完毕,但是通过订阅window的onload事件,window会在加载完毕时向订阅者发布消息,也就是执行回调函数。
window.addEventListener('load', function () {
console.log('loaded!')
})
这与买鞋的例子类似,我们不知道什么时候进货,但只需订阅鞋子的消息,进货的时候售货员会打电话通知我们。
在现实中和编程中我们还会遇到很多这样类似的问题,我们可以将 adadis 的例子提炼一下,用 JavaScript 来实现:
const adadisPub = {
adadisBook: [], // adadis售货员的小本本
subShoe(phoneNumber) { // 买家在小本本是登记号码
this.adadisBook.push(phoneNumber)
},
notify() { // 售货员打电话通知小本本上的买家
for (const customer of this.adadisBook) {
customer.update()
}
}
}
const customer1 = {
phoneNumber: '152xxx',
update() {
console.log(this.phoneNumber + ': 去商场看看')
}
}
const customer2 = {
phoneNumber: '138yyy',
update() {
console.log(this.phoneNumber + ': 给表弟买双')
}
}
adadisPub.subShoe(customer1) // 在小本本上留下号码
adadisPub.subShoe(customer2)
adadisPub.notify() // 打电话通知买家到货了
// 152xxx: 去商场看看
// 138yyy: 给表弟买双
这样我们就实现了在有新消息时对买家的通知。
当然还可以对功能进行完善,比如:
在登记号码的时候进行一下判重操作,重复号码就不登记了; 买家登记之后想了一下又不感兴趣了,那么以后也就不需要通知了,增加取消订阅的操作;
const adadisPub = {
adadisBook: [], // adadis售货员的小本本
subShoe(customer) { // 买家在小本本是登记号码
if (!this.adadisBook.includes(customer)) // 判重
this.adadisBook.push(customer)
},
unSubShoe(customer) { // 取消订阅
if (!this.adadisBook.includes(customer)) return
const idx = this.adadisBook.indexOf(customer)
this.adadisBook.splice(idx, 1)
},
notify() { // 售货员打电话通知小本本上的买家
for (const customer of this.adadisBook) {
customer.update()
}
}
}
const customer1 = {
phoneNumber: '152xxx',
update() {
console.log(this.phoneNumber + ': 去商场看看')
}
}
const customer2 = {
phoneNumber: '138yyy',
update() {
console.log(this.phoneNumber + ': 给表弟买双')
}
}
adadisPub.subShoe(customer1) // 在小本本上留下号码
adadisPub.subShoe(customer1)
adadisPub.subShoe(customer2)
adadisPub.unSubShoe(customer1)
adadisPub.notify() // 打电话通知买家到货了
// 138yyy: 给表弟买双
到现在我们已经简单完成了一个发布-订阅模式。
但是还可以继续改进,比如买家可以关注不同的鞋型,那么当某个鞋型进货了,只通知关注了这个鞋型的买家,总不能通知所有买家吧。改写后的代码:
const adadisPub = {
adadisBook: {}, // adadis售货员的小本本
subShoe(type, customer) { // 买家在小本本是登记号码
if (this.adadisBook[type]) { // 如果小本本上已经有这个type
if (!this.adadisBook[type].includes(customer)) // 判重
this.adadisBook[type].push(customer)
} else this.adadisBook[type] = [customer]
},
unSubShoe(type, customer) { // 取消订阅
if (!this.adadisBook[type] ||
!this.adadisBook[type].includes(customer)) return
const idx = this.adadisBook[type].indexOf(customer)
this.adadisBook[type].splice(idx, 1)
},
notify(type) { // 售货员打电话通知小本本上的买家
if (!this.adadisBook[type]) return
this.adadisBook[type].forEach(customer =>
customer.update(type)
)
}
}
const customer1 = {
phoneNumber: '152xxx',
update(type) {
console.log(this.phoneNumber + ': 去商场看看' + type)
}
}
const customer2 = {
phoneNumber: '138yyy',
update(type) {
console.log(this.phoneNumber + ': 给表弟买双' + type)
}
}
adadisPub.subShoe('运动鞋', customer1) // 订阅运动鞋
adadisPub.subShoe('运动鞋', customer1)
adadisPub.subShoe('运动鞋', customer2)
adadisPub.subShoe('帆布鞋', customer1) // 订阅帆布鞋
adadisPub.notify('运动鞋') // 打电话通知买家运动鞋到货了
// 152xxx: 去商场看看运动鞋
// 138yyy: 给表弟买双运动鞋
这样买家就可以订阅不同类型的鞋子,售货员也可以只通知关注某特定鞋型的买家了。
3. 发布-订阅模式的通用实现
我们可以把上面例子的几个核心概念提取一下,买家可以被认为是订阅者(Subscriber),售货员可以被认为是发布者(Publisher),售货员持有小本本(SubscriberMap),小本本上记录有买家订阅(subscribe)的不同鞋型(Type)的信息,当然也可以退订(unSubscribe),当鞋型有消息时售货员会给订阅了当前类型消息的订阅者发布(notify)消息。
主要有下面几个概念:
Publisher:发布者,当消息发生时负责通知对应订阅者Subscriber:订阅者,当消息发生时被通知的对象SubscriberMap:持有不同type的数组,存储有所有订阅者的数组type:消息类型,订阅者可以订阅的不同消息类型subscribe:该方法为将订阅者添加到SubscriberMap中对应的数组中unSubscribe:该方法为在SubscriberMap中删除订阅者notify:该方法遍历通知SubscriberMap中对应type的每个订阅者
现在的结构如下图
下面使用通用化的方法实现一下。
首先我们使用立即调用函数
IIFE(Immediately Invoked Function Expression) 方式来将不希望公开的 SubscriberMap 隐藏,然后可以将注册的订阅行为换为回调函数的形式,这样我们可以在消息通知时附带参数信息,在处理通知的时候也更灵活:
const Publisher = (function() {
const _subsMap = {} // 存储订阅者
return {
/* 消息订阅 */
subscribe(type, cb) {
if (_subsMap[type]) {
if (!_subsMap[type].includes(cb))
_subsMap[type].push(cb)
} else _subsMap[type] = [cb]
},
/* 消息退订 */
unsubscribe(type, cb) {
if (!_subsMap[type] ||
!_subsMap[type].includes(cb)) return
const idx = _subsMap[type].indexOf(cb)
_subsMap[type].splice(idx, 1)
},
/* 消息发布 */
notify(type, ...payload) {
if (!_subsMap[type]) return
_subsMap[type].forEach(cb => cb(...payload))
}
}
})()
Publisher.subscribe('运动鞋', message => console.log('152xxx' + message)) // 订阅运动鞋
Publisher.subscribe('运动鞋', message => console.log('138yyy' + message))
Publisher.subscribe('帆布鞋', message => console.log('139zzz' + message)) // 订阅帆布鞋
Publisher.notify('运动鞋', ' 运动鞋到货了 ~') // 打电话通知买家运动鞋消息
Publisher.notify('帆布鞋', ' 帆布鞋售罄了 T.T') // 打电话通知买家帆布鞋消息
// 输出: 152xxx 运动鞋到货了 ~
// 输出: 138yyy 运动鞋到货了 ~
// 输出: 139zzz 帆布鞋售罄了 T.T
上面是使用
IIFE实现的,现在ES6如此流行,也可以使用class语法来改写一下:
class Publisher {
constructor() {
this._subsMap = {}
}
/* 消息订阅 */
subscribe(type, cb) {
if (this._subsMap[type]) {
if (!this._subsMap[type].includes(cb))
this._subsMap[type].push(cb)
} else this._subsMap[type] = [cb]
}
/* 消息退订 */
unsubscribe(type, cb) {
if (!this._subsMap[type] ||
!this._subsMap[type].includes(cb)) return
const idx = this._subsMap[type].indexOf(cb)
this._subsMap[type].splice(idx, 1)
}
/* 消息发布 */
notify(type, ...payload) {
if (!this._subsMap[type]) return
this._subsMap[type].forEach(cb => cb(...payload))
}
}
const adadis = new Publisher()
adadis.subscribe('运动鞋', message => console.log('152xxx' + message)) // 订阅运动鞋
adadis.subscribe('运动鞋', message => console.log('138yyy' + message))
adadis.subscribe('帆布鞋', message => console.log('139zzz' + message)) // 订阅帆布鞋
adadis.notify('运动鞋', ' 运动鞋到货了 ~') // 打电话通知买家运动鞋消息
adadis.notify('帆布鞋', ' 帆布鞋售罄了 T.T') // 打电话通知买家帆布鞋消息
// 输出: 152xxx 运动鞋到货了 ~
// 输出: 138yyy 运动鞋到货了 ~
// 输出: 139zzz 帆布鞋售罄了 T.T
4. 实战中的发布-订阅模式 4.1 使用 jQuery 的方式
我们使用
jQuery的时候可以通过其自带的API比如on、trigger、off来轻松实现事件的订阅、发布、取消订阅等操作:
function eventHandler() {
console.log('自定义方法')
}
/* ---- 事件订阅 ---- */
$('#app').on('myevent', eventHandler)
// 发布
$('#app').trigger('myevent')
// 输出:自定义方法
/* ---- 取消订阅 ---- */
$('#app').off('myevent')
$('#app').trigger('myevent')
// 没有输出
甚至我们可以使用原生的
addEventListener、dispatchEvent、removeEventListener来实现发布订阅:
// 输出:自定义方法
function eventHandler(dom) {
console.log('自定义方法', dom)
}
var app = document.getElementById('app')
/* ---- 事件订阅 ---- */
app.addEventListener('myevent', eventHandler)
// 发布
app.dispatchEvent(new Event('myevent'))
// 输出:自定义方法+DOM
/* ---- 取消订阅 ---- */
app.removeEventListener('myevent', eventHandler)
app.dispatchEvent(new Event('myevent'))
// 没有输出
4.2 使用 Vue 的 EventBus
和
jQuery一样,Vue 也是实现有一套事件机制,其中一个我们熟知的用法是EventBus。在多层组件的事件处理中,如果你觉得一层层$on、$emit比较麻烦,而你又不愿意引入Vuex,那么这时候推介使用EventBus来解决组件间的数据通信:
// event-bus.js
import Vue from 'vue'
export const EventBus = new Vue()
使用时:
// 组件A
import { EventBus } from "./event-bus.js";
EventBus.$on("myevent", args => {
console.log(args)
})
// 组件B
import { EventBus } from "./event-bus.js";
EventBus.$emit("myevent", 'some args')
实现组件间的消息传递,不过在中大型项目中,还是推介使用
Vuex,因为如果Bus上的事件挂载过多,事件满天飞,就分不清消息的来源和先后顺序,对可维护性是一种破坏。
5. 源码中的发布-订阅模式
发布-订阅模式在源码中应用很多,特别是现在很多前端框架都会有的双向绑定机制的场景,这里以现在很火的
Vue为例,来分析一下Vue是如何利用发布-订阅模式来实现视图层和数据层的双向绑定。先借用官网的双向绑定原理图:
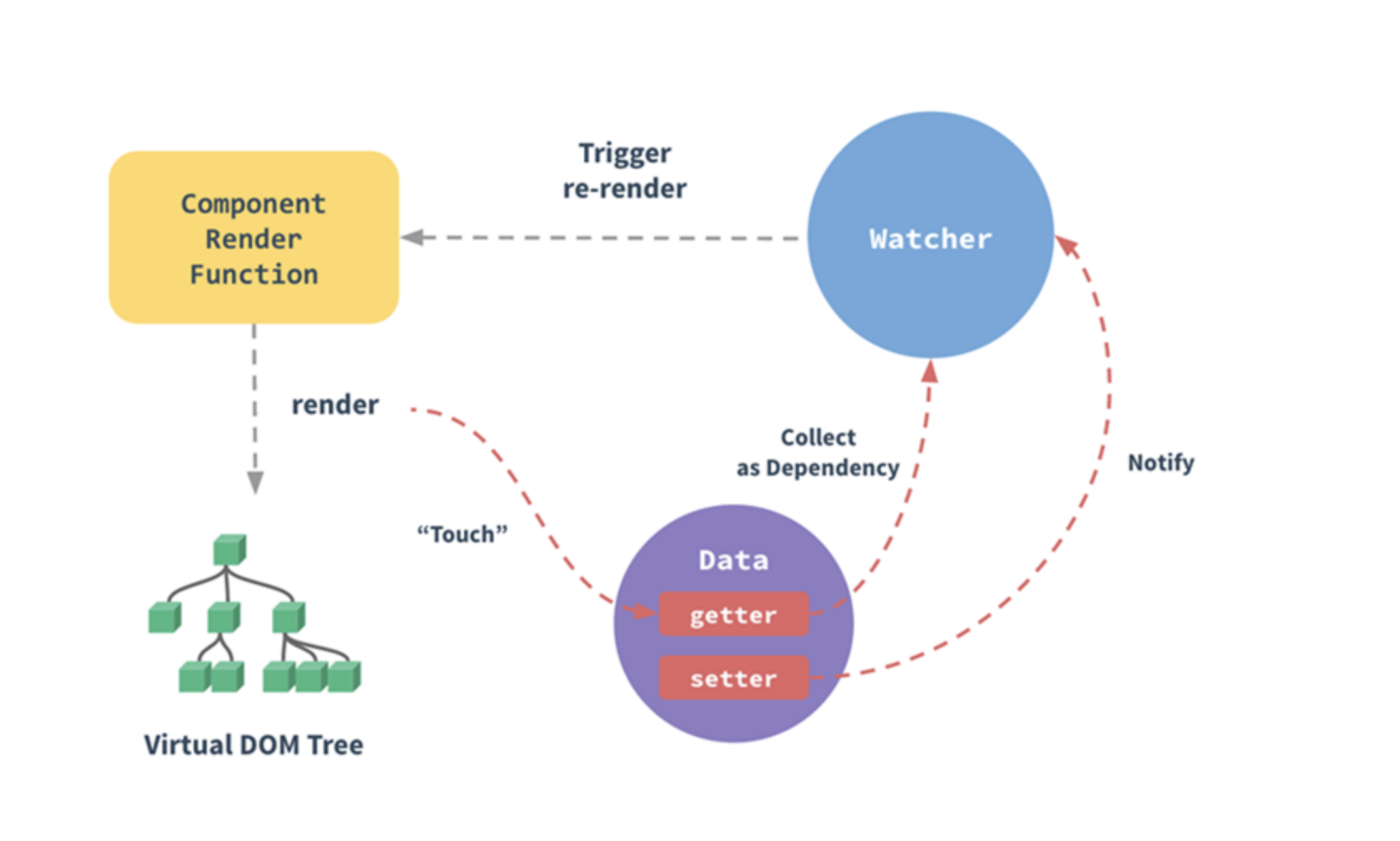
下面稍微解释一下这个图(框架源码整个过程比较复杂,如果现在看不懂下面几段也没关系,大致了解一下即可)。
组件渲染函数(Component Render Function)被执行前,会对数据层的数据进行响应式化。响应式化大致就是使用
Object.defineProperty把数据转为getter/setter,并为每个数据添加一个订阅者列表的过程。这个列表是getter闭包中的属性,将会记录所有依赖这个数据的组件。
- 也就是说,响应式化后的数据相当于发布者。
- 每个组件都对应一个
Watcher订阅者。当每个组件的渲染函数被执行时,都会将本组件的Watcher放到自己所依赖的响应式数据的订阅者列表里,这就相当于完成了订阅,一般这个过程被称为依赖收集(Dependency Collect)。 - 组件渲染函数执行的结果是生成虚拟
DOM树(Virtual DOM Tree),这个树生成后将被映射为浏览器上的真实的 DOM 树,也就是用户所看到的页面视图。 - 当响应式数据发生变化的时候,也就是触发了
setter时,setter会负责通知(Notify)该数据的订阅者列表里的Watcher,Watcher会触发组件重渲染(Trigger re-render)来更新(update)视图。
我们可以看看 Vue 的源码:
// src/core/observer/index.js 响应式化过程
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter() {
// ...
const value = getter ? getter.call(obj) : val // 如果原本对象拥有getter方法则执行
dep.depend() // 进行依赖收集,dep.addSub
return value
},
set: function reactiveSetter(newVal) {
// ...
if (setter) { setter.call(obj, newVal) } // 如果原本对象拥有setter方法则执行
dep.notify() // 如果发生变更,则通知更新
}
})
而这个
dep上的depend和notify就是订阅和发布通知的具体方法。
- 简单来说,响应式数据是消息的发布者,而视图层是消息的订阅者,如果数据更新了,那么发布者会发布数据更新的消息来通知视图更新,从而实现数据层和视图层的双向绑定。
6. 发布-订阅模式的优缺点
发布-订阅模式最大的优点就是解耦:
- 时间上的解耦 :注册的订阅行为由消息的发布方来决定何时调用,订阅者不用持续关注,当消息发生时发布者会负责通知;
- 对象上的解耦 :发布者不用提前知道消息的接受者是谁,发布者只需要遍历处理所有订阅该消息类型的订阅者发送消息即可(迭代器模式),由此解耦了发布者和订阅者之间的联系,互不持有,都依赖于抽象,不再依赖于具体;
- 由于它的解耦特性,发布-订阅模式的使用场景一般是:当一个对象的改变需要同时改变其它对象,并且它不知道具体有多少对象需要改变。发布-订阅模式还可以帮助实现一些其他的模式,比如中介者模式。
发布-订阅模式也有缺点:
- 增加消耗 :创建结构和缓存订阅者这两个过程需要消耗计算和内存资源,即使订阅后始终没有触发,订阅者也会始终存在于内存;
- 增加复杂度 :订阅者被缓存在一起,如果多个订阅者和发布者层层嵌套,那么程序将变得难以追踪和调试,参考一下 Vue 调试的时候你点开原型链时看到的那堆 deps/subs/watchers 们…
- 缺点主要在于理解成本、运行效率、资源消耗,特别是在多级发布-订阅时,情况会变得更复杂。
7. 其他相关模式 7.1 发布-订阅模式和观察者模式
观察者模式与发布-订阅者模式,在平时你可以认为他们是一个东西,但是某些场合(比如面试)下可能需要稍加注意,借用网上一张流行的图:
区别主要在发布-订阅模式中间的这个 Event Channel:
- 观察者模式 中的观察者和被观察者之间还存在耦合,被观察者还是知道观察者的;
- 发布-订阅模式 中的发布者和订阅者不需要知道对方的存在,他们通过消息代理来进行通信,解耦更加彻底;
7.2 发布-订阅模式和责任链模式
发布-订阅模式和责任链模式也有点类似,主要区别在于:
- 发布-订阅模式 传播的消息是根据需要随时发生变化,是发布者和订阅者之间约定的结构,在多级发布-订阅的场景下,消息可能完全不一样;
- 责任链模式 传播的消息是不变化的,即使变化也是在原来的消息上稍加修正,不会大幅改变结构;
# 策略模式
略模式 (Strategy Pattern)又称政策模式,其定义一系列的算法,把它们一个个封装起来,并且使它们可以互相替换。封装的策略算法一般是独立的,策略模式根据输入来调整采用哪个算法。关键是策略的实现和使用分离
1. 你曾见过的策略模式
- 现在电子产品种类繁多,尺寸多种多样,有时候你会忍不住想拆开看看里面啥样(想想小时候拆的玩具车还有遥控器),但是螺丝规格很多,螺丝刀尺寸也不少,如果每碰到一种规格就买一个螺丝刀,家里就得堆满螺丝刀了。所以现在人们都用多功能的螺丝刀套装,螺丝刀把只需要一个,碰到不同规格的螺丝只要换螺丝刀头就行了,很方便,体积也变小很多。
- 再举个栗子,一辆车的轮胎有很多规格,在泥泞路段开的多的时候可以用泥地胎,在雪地开得多可以用雪地胎,高速公路上开的多的时候使用高性能轮胎,针对不同使用场景更换不同的轮胎即可,不需更换整个车。
- 这些都是策略模式的实例,螺丝刀/车属于封装上下文,封装和使用不同的螺丝刀头/轮胎,螺丝刀头/轮胎这里就相当于策略,可以根据需求不同来更换不同的使用策略。
在这些场景中,有以下特点:
- 螺丝刀头/轮胎(策略)之间相互独立,但又可以相互替换;
- 螺丝刀/车(封装上下文)可以根据需要的不同选用不同的策略;
2. 实例的代码实现
具体的例子我们用编程上的例子来演示,比较好量化。
场景是这样的,某个电商网站希望举办一个活动,通过打折促销来销售库存物品,有的商品满 100 减 30,有的商品满 200 减 80,有的商品直接 8 折出售(想起被双十一支配的恐惧),这样的逻辑交给我们,我们要怎样去实现呢。
function priceCalculate(discountType, price) {
if (discountType === 'minus100_30') { // 满100减30
return price - Math.floor(price / 100) * 30
}
else if (discountType === 'minus200_80') { // 满200减80
return price - Math.floor(price / 200) * 80
}
else if (discountType === 'percent80') { // 8折
return price * 0.8
}
}
priceCalculate('minus100_30', 270) // 输出: 210
priceCalculate('percent80', 250) // 输出: 200
通过判断输入的折扣类型来计算商品总价的方式,几个
if-else就满足了需求,但是这样的做法的缺点也很明显:
priceCalculate函数随着折扣类型的增多,if-else判断语句会变得越来越臃肿;- 如果增加了新的折扣类型或者折扣类型的算法有所改变,那么需要更改
priceCalculate函数的实现,这是违反开放封闭原则的; - 可复用性差,如果在其他的地方也有类似这样的算法,但规则不一样,上述代码不能复用;
- 我们可以改造一下,将计算折扣的算法部分提取出来保存为一个对象,折扣的类型作为
key,这样索引的时候通过对象的键值索引调用具体的算法:
const DiscountMap = {
minus100_30: function(price) {
return price - Math.floor(price / 100) * 30
},
minus200_80: function(price) {
return price - Math.floor(price / 200) * 80
},
percent80: function(price) {
return price * 0.8
}
}
/* 计算总售价*/
function priceCalculate(discountType, price) {
return DiscountMap[discountType] && DiscountMap[discountType](price)
}
priceCalculate('minus100_30', 270)
priceCalculate('percent80', 250)
// 输出: 210
// 输出: 200
这样算法的实现和算法的使用就被分开了,想添加新的算法也变得十分简单:
DiscountMap.minus150_40 = function(price) {
return price - Math.floor(price / 150) * 40
}
如果你希望计算算法隐藏起来,那么可以借助 IIFE 使用闭包的方式,这时需要添加增加策略的入口,以方便扩展:
const PriceCalculate = (function() {
/* 售价计算方式 */
const DiscountMap = {
minus100_30: function(price) { // 满100减30
return price - Math.floor(price / 100) * 30
},
minus200_80: function(price) { // 满200减80
return price - Math.floor(price / 200) * 80
},
percent80: function(price) { // 8折
return price * 0.8
}
}
return {
priceClac: function(discountType, price) {
return DiscountMap[discountType] && DiscountMap[discountType](price)
},
addStrategy: function(discountType, fn) { // 注册新计算方式
if (DiscountMap[discountType]) return
DiscountMap[discountType] = fn
}
}
})()
PriceCalculate.priceClac('minus100_30', 270) // 输出: 210
PriceCalculate.addStrategy('minus150_40', function(price) {
return price - Math.floor(price / 150) * 40
})
PriceCalculate.priceClac('minus150_40', 270) // 输出: 230
这样算法就被隐藏起来,并且预留了增加策略的入口,便于扩展。
3. 策略模式的通用实现
- 根据上面的例子提炼一下策略模式,折扣计算方式可以被认为是策略(Strategy),这些策略之间可以相互替代,而具体折扣的计算过程可以被认为是封装上下文(Context),封装上下文可以根据需要选择不同的策略。
主要有下面几个概念:
- Context :封装上下文,根据需要调用需要的策略,屏蔽外界对策略的直接调用,只对外提供一个接口,根据需要调用对应的策略;
- Strategy :策略,含有具体的算法,其方法的外观相同,因此可以互相代替;
- StrategyMap :所有策略的合集,供封装上下文调用;
结构图如下:
下面使用通用化的方法实现一下。
const StrategyMap = {}
function context(type, ...rest) {
return StrategyMap[type] && StrategyMap[type](...rest)
}
StrategyMap.minus100_30 = function(price) {
return price - Math.floor(price / 100) * 30
}
context('minus100_30', 270) // 输出: 210
通用实现看起来似乎比较简单,这里分享一下项目实战。
4. 实战中的策略模式 4.1 表格 formatter
这里举一个
Vue + ElementUI项目中用到的例子,其他框架的项目原理也类似,和大家分享一下。
Element的表格控件的Column接受一个formatter参数,用来格式化内容,其类型为函数,并且还可以接受几个特定参数,像这样:Function(row, column, cellValue, index)。- 以文件大小转化为例,后端经常会直接传
bit单位的文件大小,那么前端需要根据后端的数据,根据需求转化为自己需要的单位的文件大小,比如KB/MB。
首先实现文件计算的算法:
export const StrategyMap = {
/* Strategy 1: 将文件大小(bit)转化为 KB */
bitToKB: val => {
const num = Number(val)
return isNaN(num) ? val : (num / 1024).toFixed(0) + 'KB'
},
/* Strategy 2: 将文件大小(bit)转化为 MB */
bitToMB: val => {
const num = Number(val)
return isNaN(num) ? val : (num / 1024 / 1024).toFixed(1) + 'MB'
}
}
/* Context: 生成el表单 formatter */
const strategyContext = function(type, rowKey){
return function(row, column, cellValue, index){
StrategyMap[type](row[rowKey])
}
}
export default strategyContext
那么在组件中我们可以直接:
<template>
<el-table :data="tableData">
<el-table-column prop="date" label="日期"></el-table-column>
<el-table-column prop="name" label="文件名"></el-table-column>
<!-- 直接调用 strategyContext -->
<el-table-column prop="sizeKb" label="文件大小(KB)"
:formatter='strategyContext("bitToKB", "sizeKb")'>
</el-table-column>
<el-table-column prop="sizeMb" label="附件大小(MB)"
:formatter='strategyContext("bitToMB", "sizeMb")'>
</el-table-column>
</el-table>
</template>
<script type='text/javascript'>
import strategyContext from './strategyContext.js'
export default {
name: 'ElTableDemo',
data() {
return {
strategyContext,
tableData: [
{ date: '2019-05-02', name: '文件1', sizeKb: 1234, sizeMb: 1234426 },
{ date: '2019-05-04', name: '文件2', sizeKb: 4213, sizeMb: 8636152 }]
}
}
}
</script>
<style scoped></style>
运行结果如下图:
4.2 表单验证
- 除了表格中的
formatter之外,策略模式也经常用在表单验证的场景,这里举一个Vue + ElementUI项目的例子,其他框架同理。 ElementUI的Form表单 具有表单验证功能,用来校验用户输入的表单内容。实际需求中表单验证项一般会比较复杂,所以需要给每个表单项增加validator自定义校验方法。- 我们可以像官网示例一样把表单验证都写在组件的状态 data 函数中,但是这样就不好复用使用频率比较高的表单验证方法了,这时我们可以结合策略模式和函数柯里化的知识来重构一下。首先我们在项目的工具模块(一般是 utils 文件夹)实现通用的表单验证方法:
// src/utils/validates.js
/* 姓名校验 由2-10位汉字组成 */
export function validateUsername(str) {
const reg = /^[\u4e00-\u9fa5]{2,10}$/
return reg.test(str)
}
/* 手机号校验 由以1开头的11位数字组成 */
export function validateMobile(str) {
const reg = /^1\d{10}$/
return reg.test(str)
}
/* 邮箱校验 */
export function validateEmail(str) {
const reg = /^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$/
return reg.test(str)
}
然后在 utils/index.js 中增加一个柯里化方法,用来生成表单验证函数:
// src/utils/index.js
import * as Validates from './validates.js'
/* 生成表格自定义校验函数 */
export const formValidateGene = (key, msg) => (rule, value, cb) => {
if (Validates[key](value)) {
cb()
} else {
cb(new Error(msg))
}
}
上面的
formValidateGene函数接受两个参数,第一个是验证规则,也就是src/utils/validates.js文件中提取出来的通用验证规则的方法名,第二个参数是报错的话表单验证的提示信息。
<template>
<el-form ref="ruleForm"
label-width="100px"
class="demo-ruleForm"
:rules="rules"
:model="ruleForm">
<el-form-item label="用户名" prop="username">
<el-input v-model="ruleForm.username"></el-input>
</el-form-item>
<el-form-item label="手机号" prop="mobile">
<el-input v-model="ruleForm.mobile"></el-input>
</el-form-item>
<el-form-item label="邮箱" prop="email">
<el-input v-model="ruleForm.email"></el-input>
</el-form-item>
</el-form>
</template>
<script type='text/javascript'>
import * as Utils from '../utils'
export default {
name: 'ElTableDemo',
data() {
return {
ruleForm: { pass: '', checkPass: '', age: '' },
rules: {
username: [{
validator: Utils.formValidateGene('validateUsername', '姓名由2-10位汉字组成'),
trigger: 'blur'
}],
mobile: [{
validator: Utils.formValidateGene('validateMobile', '手机号由以1开头的11位数字组成'),
trigger: 'blur'
}],
email: [{
validator: Utils.formValidateGene('validateEmail', '不是正确的邮箱格式'),
trigger: 'blur'
}]
}
}
}
}
</script>
可以看见在使用的时候非常方便,把表单验证方法提取出来作为策略,使用柯里化方法动态选择表单验证方法,从而对策略灵活运用,大大加快开发效率。
运行结果:
5. 策略模式的优缺点
策略模式将算法的实现和使用拆分,这个特点带来了很多优点:
- 策略之间相互独立,但策略可以自由切换,这个策略模式的特点给策略模式带来很多灵活性,也提高了策略的复用率;
- 如果不采用策略模式,那么在选策略时一般会采用多重的条件判断,采用策略模式可以避免多重条件判断,增加可维护性;
- 可扩展性好,策略可以很方便的进行扩展;
策略模式的缺点:
- 策略相互独立,因此一些复杂的算法逻辑无法共享,造成一些资源浪费;
- 如果用户想采用什么策略,必须了解策略的实现,因此所有策略都需向外暴露,这是违背迪米特法则/最少知识原则的,也增加了用户对策略对象的使用成本。
6. 策略模式的适用场景 那么应该在什么场景下使用策略模式呢:
- 多个算法只在行为上稍有不同的场景,这时可以使用策略模式来动态选择算法;
- 算法需要自由切换的场景;
- 有时需要多重条件判断,那么可以使用策略模式来规避多重条件判断的情况;
7. 其他相关模式 7.1 策略模式和模板方法模式
策略模式和模板方法模式的作用比较类似,但是结构和实现方式有点不一样。
- 策略模式 让我们在程序运行的时候动态地指定要使用的算法;
- 模板方法模式 是在子类定义的时候就已经确定了使用的算法;
7.2 策略模式和享元模式
见享元模式中的介绍
# 状态模式
状态模式 (State Pattern)允许一个对象在其内部状态改变时改变它的行为,对象看起来似乎修改了它的类,类的行为随着它的状态改变而改变。
当程序需要根据不同的外部情况来做出不同操作时,最直接的方法就是使用 switch-case 或 if-else 语句将这些可能发生的情况全部兼顾到,但是这种做法应付复杂一点的状态判断时就有点力不从心,开发者得找到合适的位置添加或修改代码,这个过程很容易出错,这时引入状态模式可以某种程度上缓解这个问题
1. 你曾见过的状态模式
等红绿灯的时候,红绿灯的状态和行人汽车的通行逻辑是有关联的:
- 红灯亮:行人通行,车辆等待;
- 绿灯亮:行人等待,车辆通行;
- 黄灯亮:行人等待,车辆等待;
还有下载文件的时候,就有好几个状态,比如下载验证、下载中、暂停下载、下载完毕、失败,文件在不同状态下表现的行为也不一样,比如下载中时显示可以暂停下载和下载进度,下载失败时弹框提示并询问是否重新下载等等。类似的场景还有很多,比如电灯的开关状态、电梯的运行状态等,女生作为你的朋友、好朋友、女朋友、老婆等不同状态的时候,行为也不同 。
在这些场景中,有以下特点:
- 对象有有限多个状态,且状态间可以相互切换;
- 各个状态和对象的行为逻辑有比较强的对应关系,即在不同状态时,对应的处理逻辑不一样;
2. 实例的代码实现
我们使用 JavaScript 来将上面的交通灯例子实现一下。
先用 IIFE 的方式:
// 反模式,不推介
var trafficLight = (function() {
var state = '绿灯' // 闭包缓存状态
return {
/* 设置交通灯状态 */
setState: function(target) {
if (target === '红灯') {
state = '红灯'
console.log('交通灯颜色变为 红色,行人通行 & 车辆等待')
} else if (target === '黄灯') {
state = '黄灯'
console.log('交通灯颜色变为 黄色,行人等待 & 车辆等待')
} else if (target === '绿灯') {
state = '绿灯'
console.log('交通灯颜色变为 绿色,行人等待 & 车辆通行')
} else {
console.error('交通灯还有这颜色?')
}
},
/* 获取交通灯状态 */
getState: function() {
return state
}
}
})()
trafficLight.setState('红灯') // 输出: 交通灯颜色变为 红色,行人通行 & 车辆等待
trafficLight.setState('黄灯') // 输出: 交通灯颜色变为 黄色,行人等待 & 车辆等待
trafficLight.setState('绿灯') // 输出: 交通灯颜色变为 绿色,行人等待 & 车辆通行
trafficLight.setState('紫灯') // 输出: 交通灯还有这颜色?
- 在模块模式里面通过
if-else来区分不同状态的处理逻辑,也可以使用switch-case - 但是这个实现存在有问题,这里的处理逻辑还不够复杂,如果复杂的话,在添加新的状态时,比如增加了 蓝灯、紫灯 等颜色及其处理逻辑的时候,需要到
setState方法里找到对应地方修改。在实际项目中,if-else伴随的业务逻辑处理通常比较复杂,找到要修改的状态就不容易,特别是如果是别人的代码,或者接手遗留项目时,需要看完这个if-else的分支处理逻辑,新增或修改分支逻辑的过程中也很容易引入Bug。 - 那有没有什么方法可以方便地维护状态及其对应行为,又可以不用维护一个庞大的分支判断逻辑呢。这就引入了状态模式的理念,状态模式把每种状态和对应的处理逻辑封装在一起(后文为了统一,统称封装到状态类中),比如下面我们用一个类实例将逻辑封装起来:
/* 抽象状态类 */
var AbstractState = function() {}
/* 抽象方法 */
AbstractState.prototype.employ = function() {
throw new Error('抽象方法不能调用!')
}
/* 交通灯状态类 */
var State = function(name, desc) {
this.color = { name, desc }
}
State.prototype = new AbstractState()
State.prototype.employ = function(trafficLight) {
console.log('交通灯颜色变为 ' + this.color.name + ',' + this.color.desc)
trafficLight.setState(this)
}
/* 交通灯类 */
var TrafficLight = function() {
this.state = null
}
/* 获取交通灯状态 */
TrafficLight.prototype.getState = function() {
return this.state
}
/* 设置交通灯状态 */
TrafficLight.prototype.setState = function(state) {
this.state = state
}
// 实例化一个红绿灯
var trafficLight = new TrafficLight()
// 实例化红绿灯可能有的三种状态
var redState = new State('红色', '行人等待 & 车辆等待')
var greenState = new State('绿色', '行人等待 & 车辆通行')
var yellowState = new State('黄色', '行人等待 & 车辆等待')
redState.employ(trafficLight) // 输出: 交通灯颜色变为 红色,行人通行 & 车辆等待
yellowState.employ(trafficLight) // 输出: 交通灯颜色变为 黄色,行人等待 & 车辆等待
greenState.employ(trafficLight) // 输出: 交通灯颜色变为 绿色,行人等待 & 车辆通行
这里的不同状态是同一个类的类实例,比如
redState这个类实例,就把所有红灯状态处理的逻辑封装起来,如果要把状态切换为红灯状态,那么只需要redState.employ()` 把交通灯的状态切换为红色,并且把交通灯对应的行为逻辑也切换为红灯状态。
- 如果你看过前面的策略模式,是不是感觉到有那么一丝似曾相识,策略模式把可以相互替换的策略算法提取出来,而状态模式把事物的状态及其行为提取出来。
- 这里我们使用
ES6的Class语法改造一下:
/* 抽象状态类 */
class AbstractState {
constructor() {
if (new.target === AbstractState) {
throw new Error('抽象类不能直接实例化!')
}
}
/* 抽象方法 */
employ() {
throw new Error('抽象方法不能调用!')
}
}
/* 交通灯类 */
class State extends AbstractState {
constructor(name, desc) {
super()
this.color = { name, desc }
}
/* 覆盖抽象方法 */
employ(trafficLight) {
console.log('交通灯颜色变为 ' + this.color.name + ',' + this.color.desc)
trafficLight.setState(this)
}
}
/* 交通灯类 */
class TrafficLight {
constructor() {
this.state = null
}
/* 获取交通灯状态 */
getState() {
return this.state
}
/* 设置交通灯状态 */
setState(state) {
this.state = state
}
}
const trafficLight = new TrafficLight()
const redState = new State('红色', '行人等待 & 车辆等待')
const greenState = new State('绿色', '行人等待 & 车辆通行')
const yellowState = new State('黄色', '行人等待 & 车辆等待')
redState.employ(trafficLight) // 输出: 交通灯颜色变为 红色,行人通行 & 车辆等待
yellowState.employ(trafficLight) // 输出: 交通灯颜色变为 黄色,行人等待 & 车辆等待
greenState.employ(trafficLight) // 输出: 交通灯颜色变为 绿色,行人等待 & 车辆通行
如果要新建状态,不用修改原有代码,只要加上下面的代码:
// 接上面
const blueState = new State('蓝色', '行人倒立 & 车辆飞起')
blueState.employ(trafficLight) // 输出: 交通灯颜色变为 蓝色,行人倒立 & 车辆飞起
传统的状态区分一般是基于状态类扩展的不同状态类,如何实现实现看需求具体了,比如逻辑比较复杂,通过新建状态实例的方法已经不能满足需求,那么可以使用状态类的方式。
这里提供一个状态类的实现,同时引入状态的切换逻辑:
/* 抽象状态类 */
class AbstractState {
constructor() {
if (new.target === AbstractState) {
throw new Error('抽象类不能直接实例化!')
}
}
/* 抽象方法 */
employ() {
throw new Error('抽象方法不能调用!')
}
changeState() {
throw new Error('抽象方法不能调用!')
}
}
/* 交通灯类-红灯 */
class RedState extends AbstractState {
constructor() {
super()
this.colorState = '红色'
}
/* 覆盖抽象方法 */
employ() {
console.log('交通灯颜色变为 ' + this.colorState + ',行人通行 & 车辆等待')
// const redDom = document.getElementById('color-red') // 业务相关操作
// // redDom.click()
}
changeState(trafficLight) {
trafficLight.setState(trafficLight.yellowState)
}
}
/* 交通灯类-绿灯 */
class GreenState extends AbstractState {
constructor() {
super()
this.colorState = '绿色'
}
/* 覆盖抽象方法 */
employ() {
console.log('交通灯颜色变为 ' + this.colorState + ',行人等待 & 车辆通行')
// const greenDom = document.getElementById('color-green')
// greenDom.click()
}
changeState(trafficLight) {
trafficLight.setState(trafficLight.redState)
}
}
/* 交通灯类-黄灯 */
class YellowState extends AbstractState {
constructor() {
super()
this.colorState = '黄色'
}
/* 覆盖抽象方法 */
employ() {
console.log('交通灯颜色变为 ' + this.colorState + ',行人等待 & 车辆等待')
// const yellowDom = document.getElementById('color-yellow')
// yellowDom.click()
}
changeState(trafficLight) {
trafficLight.setState(trafficLight.greenState)
}
}
/* 交通灯类 */
class TrafficLight {
constructor() {
this.redState = new RedState()
this.greenState = new GreenState()
this.yellowState = new YellowState()
this.state = this.greenState
}
/* 设置交通灯状态 */
setState(state) {
state.employ(this)
this.state = state
}
changeState() {
this.state.changeState(this)
}
}
const trafficLight = new TrafficLight()
trafficLight.changeState() // 输出: 交通灯颜色变为 红色,行人通行 & 车辆等待
trafficLight.changeState() // 输出: 交通灯颜色变为 黄色,行人等待 & 车辆等待
trafficLight.changeState() // 输出: 交通灯颜色变为 绿色,行人等待 & 车辆通行
如果我们要增加新的交通灯颜色,也是很方便的:
// 接上面
/* 交通灯类-蓝灯 */
class BlueState extends AbstractState {
constructor() {
super()
this.colorState = '蓝色'
}
/* 覆盖抽象方法 */
employ() {
console.log('交通灯颜色变为 ' + this.colorState + ',行人倒立 & 车辆飞起')
const redDom = document.getElementById('color-blue')
redDom.click()
}
}
const blueState = new BlueState()
trafficLight.employ(blueState) // 输出: 交通灯颜色变为 蓝色,行人倒立 & 车辆飞起
对原来的代码没有修改,非常符合开闭原则了。
3. 状态模式的原理
- 所谓对象的状态,通常指的就是对象实例的属性的值。行为指的就是对象的功能,行为大多可以对应到方法上。状态模式把状态和状态对应的行为从原来的大杂烩代码中分离出来,把每个状态所对应的功能处理封装起来,这样选择不同状态的时候,其实就是在选择不同的状态处理类。
- 也就是说,状态和行为是相关联的,它们的关系可以描述总结成:状态决定行为。由于状态是在运行期被改变的,因此行为也会在运行期根据状态的改变而改变,看起来,同一个对象,在不同的运行时刻,行为是不一样的,就像是类被修改了一样。
- 为了提取不同的状态类共同的外观,可以给状态类定义一个共同的状态接口或抽象类,正如之前最后的两个代码示例一样,这样可以面向统一的接口编程,无须关心具体的状态类实现。
4. 状态模式的优缺点 状态模式的优点:
- 结构相比之下清晰,避免了过多的
switch-case或if-else语句的使用,避免了程序的复杂性提高系统的可维护性; - 符合开闭原则,每个状态都是一个子类,增加状态只需增加新的状态类即可,修改状态也只需修改对应状态类就可以了;
- 封装性良好,状态的切换在类的内部实现,外部的调用无需知道类内部如何实现状态和行为的变换。
状态模式的缺点:
- 引入了多余的类,每个状态都有对应的类,导致系统中类的个数增加。
5. 状态模式的适用场景
- 操作中含有庞大的多分支的条件语句,且这些分支依赖于该对象的状态,那么可以使用状态模式来将分支的处理分散到单独的状态类中;
- 对象的行为随着状态的改变而改变,那么可以考虑状态模式,来把状态和行为分离,虽然分离了,但是状态和行为是对应的,再通过改变状态调用状态对应的行为;
6. 其他相关模式 6.1 状态模式和策略模式
状态模式和策略模式在之前的代码就可以看出来,看起来比较类似,他们的区别:
- 状态模式: 重在强调对象内部状态的变化改变对象的行为,状态类之间是平行的,无法相互替换;
- 策略模式: 策略的选择由外部条件决定,策略可以动态的切换,策略之间是平等的,可以相互替换;
- 状态模式的状态类是平行的,意思是各个状态类封装的状态和对应的行为是相互独立、没有关联的,封装的业务逻辑可能差别很大毫无关联,相互之间不可替换。但是策略模式中的策略是平等的,是同一行为的不同描述或者实现,在同一个行为发生的时候,可以根据外部条件挑选任意一个实现来进行处理。
6.2 状态模式和发布-订阅模式
- 这两个模式都是在状态发生改变的时候触发行为,不过发布-订阅模式的行为是固定的,那就是通知所有的订阅者,而状态模式是根据状态来选择不同的处理逻辑。
- 状态模式: 根据状态来分离行为,当状态发生改变的时候,动态地改变行为;
- 发布-订阅模式: 发布者在消息发生时通知订阅者,具体如何处理则不在乎,或者直接丢给用户自己处理;
- 这两个模式是可以组合使用的,比如在发布-订阅模式的发布消息部分,当对象的状态发生了改变,触发通知了所有的订阅者后,可以引入状态模式,根据通知过来的状态选择相应的处理。
6.3 状态模式和单例模式
之前的示例代码中,状态类每次使用都
new出来一个状态实例,实际上使用同一个实例即可,因此可以引入单例模式,不同的状态类可以返回的同一个实例。
# 模板方法模式:咖啡厅制作咖啡
模板方法模式(Template Method Pattern)父类中定义一组操作算法骨架,而将一些实现步骤延迟到子类中,使得子类可以不改变父类的算法结构的同时,重新定义算法中的某些实现步骤。模板方法模式的关键是算法步骤的骨架和具体实现分离。
1. 你曾见过的模板方法模式
这里举个经典的咖啡厅例子,咖啡厅制作饮料的过程有一些类似的步骤:
- 先把水煮沸
- 冲泡饮料(咖啡、茶、牛奶)
- 倒进杯子中
- 最后加一些调味料(咖啡伴侣、枸杞、糖)
- 无论冲饮的是咖啡、茶、牛奶,他们的制作过程都类似,可以被总结为这几个流程。也就是说这个流程是存在着类似的流程结构的,这就给我们留下了将操作流程抽象封装出来的余地。
再举个栗子,做菜的过程也可以被总结为固定的几个步骤:
- 准备食材(肉、蔬菜、菌菇)
- 食材放到锅里
- 放调味料(糖、盐、油)
- 炒菜
- 倒到容器里(盘子、碗)
- 在类似的场景中,这些例子都有这些特点:
- 有一个基本的操作流程,这个流程我们可以抽象出来,由具体实例的操作流程来实现,比如做咖啡的时候冲泡的就是咖啡,做茶的时候冲泡的就是茶;
- 一些共用的流程,就可以使用通用的公共步骤,比如把水煮沸,比如将食材放到锅里,这样的共用流程就可以共用一个具体方法就可以了;
2. 实例的代码实现
如果你已经看过抽象工厂模式,那么你对 JavaScript 中面向对象的方式提取公共结构应该比较熟悉了,这里再复习一下。JavaScript 中可以使用下面的方式来模拟抽象类:
/* 抽象类,ES6 class 方式 */
class AbstractClass1 {
constructor() {
if (new.target === AbstractClass1) {
throw new Error('抽象类不能直接实例化!')
}
}
/* 抽象方法 */
operate() { throw new Error('抽象方法不能调用!') }
}
/* 抽象类,ES5 构造函数方式 */
var AbstractClass2 = function () {
if (new.target === AbstractClass2) {
throw new Error('抽象类不能直接实例化!')
}
}
/* 抽象方法,使用原型方式添加 */
AbstractClass2.prototype.operate = function(){ throw new Error('抽象方法不能调用!') }
下面实现一下咖啡厅例子。
首先我们使用原型继承的方式:
/* 饮料类,父类,也是抽象类 */
var Beverage = function() {
if (new.target === Beverage) {
throw new Error('抽象类不能直接实例化!')
}
}
/* 烧开水,共用方法 */
Beverage.prototype.boilWater = function() {
console.log('水已经煮沸')
}
/* 冲泡饮料,抽象方法 */
Beverage.prototype.brewDrink = function() {
throw new Error('抽象方法不能调用!')
}
/* 倒杯子里,共用方法 */
Beverage.prototype.pourCup = function() {
console.log('倒进杯子里')
}
/* 加调味品,抽象方法 */
Beverage.prototype.addCondiment = function() {
throw new Error('抽象方法不能调用!')
}
/* 制作流程,模板方法 */
Beverage.prototype.init = function() {
this.boilWater()
this.brewDrink()
this.pourCup()
this.addCondiment()
}
/* 咖啡类,子类 */
var Coffee = function() {}
Coffee.prototype = new Beverage()
/* 冲泡饮料,实现抽象方法 */
Coffee.prototype.brewDrink = function() {
console.log('冲泡咖啡')
}
/* 加调味品,实现抽象方法 */
Coffee.prototype.addCondiment = function() {
console.log('加点咖啡伴侣')
}
var coffee = new Coffee()
coffee.init()
// 输出:水已经煮沸
// 输出:冲泡咖啡
// 输出:倒进杯子里
// 输出:加点咖啡伴侣
我们用 ES6 的 class 方式来改写一下:
/* 饮料类,父类 */
class Beverage {
constructor() {
if (new.target === Beverage) {
throw new Error('抽象类不能直接实例化!')
}
}
/* 烧开水,共用方法 */
boilWater() { console.log('水已经煮沸') }
/* 冲泡饮料,抽象方法 */
brewDrink() { throw new Error('抽象方法不能调用!') }
/* 倒杯子里,共用方法 */
pourCup() { console.log('倒进杯子里') }
/* 加调味品,抽象方法 */
addCondiment() { throw new Error('抽象方法不能调用!') }
/* 制作流程,模板方法 */
init() {
this.boilWater()
this.brewDrink()
this.pourCup()
this.addCondiment()
}
}
/* 咖啡类,子类 */
class Coffee extends Beverage {
constructor() { super() }
/* 冲泡饮料,实现抽象方法 */
brewDrink() { console.log('冲泡咖啡') }
/* 加调味品,实现抽象方法 */
addCondiment() { console.log('加点咖啡伴侣') }
}
const coffee = new Coffee()
coffee.init()
// 输出:水已经煮沸
// 输出:冲泡咖啡
// 输出:倒进杯子里
// 输出:加点咖啡伴侣
如果需要创建一个新的饮料,那么增加一个新的实例类,并实现父类中的抽象方法。如果不实现就去调用
init方法即报错:
// 接上一段代码
/* 茶类,子类 */
class Tea extends Beverage {
constructor() { super() }
/* 冲泡饮料,实现抽象方法 */
brewDrink() { console.log('冲泡茶') }
/* 注意这里,没有实现加调味品抽象方法 */
}
const tea = new Tea()
tea.init()
// 输出:水已经煮沸
// 输出:冲泡茶
// 输出:倒进杯子里
// Error: 抽象方法不能调用!
那么这样就把冲泡饮料的流程框架抽象到了
init方法中,在实例类中实现对应抽象方法,调用实例的init方法时就会调用覆盖后的实例方法,实现可变流程的扩展。
- 在灵活的 JavaScript 中,其实我们还可以使用默认参数来间接实现:
/* 虚拟方法 */
const abstractFunc = function() { throw new Error('抽象方法不能调用!') }
/* 饮料方法,方法体就是模板方法,即上面的 init() */
function BeverageFunc({
boilWater = function() { // 烧开水,共用方法
console.log('水已经煮沸')
},
brewDrink = abstractFunc, // 冲泡饮料,抽象方法
pourCup = function() { // 倒杯子里,共用方法
console.log('倒进杯子里')
},
addCondiment = abstractFunc // 加调味品,抽象方法
}) {
boilWater()
brewDrink()
pourCup()
addCondiment()
}
/* 制作咖啡 */
BeverageFunc({
/* 冲泡饮料,实现抽象方法 */
brewDrink: function() { console.log('水已经煮沸') },
/* 加调味品,实现抽象方法 */
addCondiment: function() { console.log('加点咖啡伴侣') }
})
// 输出:水已经煮沸
// 输出:冲泡咖啡
// 输出:倒进杯子里
// 输出:加点咖啡伴侣
但是这样实现语义化并不太好,我们可以把默认参数用在构造函数中,这样可以使用
new关键字来创建实例,语义化良好,也符合直觉:
/* 虚拟方法 */
const abstractFunc = function() { throw new Error('抽象方法不能调用!') }
/* 饮料方法 */
class Beverage {
constructor({
brewDrink = abstractFunc, // 冲泡饮料,抽象方法
addCondiment = abstractFunc // 加调味品,抽象方法
}) {
this.brewDrink = brewDrink
this.addCondiment = addCondiment
}
/* 烧开水,共用方法 */
boilWater() { console.log('水已经煮沸') }
/* 倒杯子里,共用方法 */
pourCup() { console.log('倒进杯子里') }
/* 模板方法 */
init() {
this.boilWater()
this.brewDrink()
this.pourCup()
this.addCondiment()
}
}
/* 咖啡 */
const coffee = new Beverage({
/* 冲泡饮料,覆盖抽象方法 */
brewDrink: function() { console.log('水已经煮沸') },
/* 加调味品,覆盖抽象方法 */
addCondiment: function() { console.log('加点咖啡伴侣') }
})
coffee.init() // 执行模板方法
// 输出:水已经煮沸
// 输出:冲泡咖啡
// 输出:倒进杯子里
// 输出:加点咖啡伴侣
这样通过构造函数默认参数来实现类似于继承的功能。
3. 模板方法模式的通用实现
根据上面的例子,我们可以提炼一下模板方法模式。饮料类可以被认为是父类(AbstractClass),父类中实现了模板方法(templateMethod),模板方法中抽象了操作的流程,共用的操作流程是普通方法,而非共用的可变方法是抽象方法,需要被子类(ConcreteClass)实现,或者说覆盖,子类在实例化后执行模板方法,就可以按照模板方法定义好的算法一步步执行。主要有下面几个概念:
AbstractClass:抽象父类,把一些共用的方法提取出来,把可变的方法作为抽象类,最重要的是把算法骨架抽象出来为模板方法;templateMethod:模板方法,固定了希望执行的算法骨架;ConcreteClass:子类,实现抽象父类中定义的抽象方法,调用继承的模板方法时,将执行模板方法中定义的算法流程;
下面用通用的方法实现,这里直接用 class 语法:
/* 抽象父类 */
class AbstractClass {
constructor() {
if (new.target === AbstractClass) {
throw new Error('抽象类不能直接实例化!')
}
}
/* 共用方法 */
operate1() { console.log('operate1') }
/* 抽象方法 */
operate2() { throw new Error('抽象方法不能调用!') }
/* 模板方法 */
templateMethod() {
this.operate1()
this.operate2()
}
}
/* 实例子类,继承抽象父类 */
class ConcreteClass extends AbstractClass {
constructor() { super() }
/* 覆盖抽象方法 operate2 */
operate2() { console.log('operate2') }
}
const instance = new ConcreteClass()
instance.templateMethod()
// 输出:operate1
// 输出:operate2
使用上面介绍的默认参数的方法:
/* 虚拟方法 */
const abstractFunc = function() { throw new Error('抽象方法不能调用!') }
/* 饮料方法 */
class AbstractClass {
constructor({
operate2 = abstractFunc // 抽象方法
}) {
this.operate2 = operate2
}
/* 共用方法 */
operate1() { console.log('operate1') }
/* 模板方法 */
init() {
this.operate1()
this.operate2()
}
}
/* 实例 */
const instance = new AbstractClass({
/* 覆盖抽象方法 */
operate2: function() { console.log('operate2') }
})
instance.init()
// 输出:operate1
// 输出:operate2
我们也可以不用构造函数的默认参数,使用高阶函数也是可以的,毕竟 JavaScript 如此灵活。
4. 模板方法模式的优缺点
模板方法模式的优点:
- 封装了不变部分,扩展可变部分, 把算法中不变的部分封装到父类中直接实现,而可变的部分由子类继承后再具体实现; 提取了公共代码部分,易于维护, 因为公共的方法被提取到了父类,那么如果我们需要修改算法中不变的步骤时,不需要到每- 一个子类中去修改,只要改一下对应父类即可;
- 行为被父类的模板方法固定, 子类实例只负责执行模板方法,具备可扩展性,符合开闭原则;
- 模板方法模式的缺点:增加了系统复杂度,主要是增加了的抽象类和类间联系,需要做好文档工作;
5. 模板方法模式的使用场景
- 如果知道一个算法所需的关键步骤,而且很明确这些步骤的执行顺序,但是具体的实现是未知的、灵活的,那么这时候就可以使用模板方法模式来将算法步骤的框架抽象出来;
- 重要而复杂的算法,可以把核心算法逻辑设计为模板方法,周边相关细节功能由各个子类实现;
- 模板方法模式可以被用来将子类组件将自己的方法挂钩到高层组件中,也就是钩子,子类组件中的方法交出控制权,高层组件在模板方法中决定何时回调子类组件中的方法,类似的用法场景还有发布-订阅模式、回调函数;
6. 其他相关模式 6.1 模板方法模式与工厂模式
模板方法模式的实现可以使用工厂模式来获取所需的对象。
另外,模板方法模式和抽象工厂模式比较类似,都是使用抽象类来提取公共部分,不一样的是:
- 抽象工厂模式 提取的是实例的功能结构;
- 模板方法模式 提取的是算法的骨架结构;
# 迭代器模式:银行的点钞机
迭代器模式 (Iterator Pattern)用于顺序地访问聚合对象内部的元素,又无需知道对象内部结构。使用了迭代器之后,使用者不需要关心对象的内部构造,就可以按序访问其中的每个元素。
1. 什么是迭代器
银行里的点钞机就是一个迭代器,放入点钞机的钞票里有不同版次的人民币,每张钞票的冠字号也不一样,但当一沓钞票被放入点钞机中,使用者并不关心这些差别,只关心钞票的数量,以及是否有假币。
这里我们使用 JavaScript 的方式来点一下钞:
var bills = ['MCK013840031', 'MCK013840032', 'MCK013840033', 'MCK013840034', 'MCK013840035']
bills.forEach(function(bill) {
console.log('当前钞票的冠字号为 ' + bill)
})
是不是很简单,这是因为 JavaScript 已经内置了迭代器的实现,在某些个很老的语言中,使用者可能会为了实现迭代器而烦恼,但是在 JavaScript 中则完全不用担心。
2. 迭代器的简单实现
前面的
forEach方法是在IE9之后才原生提供的,那么在IE9之前的时代里,如何实现一个迭代器呢,我们可以使用for循环自己实现一个forEach:
var forEach = function(arr, cb) {
for (var i = 0; i < arr.length; i++) {
cb.call(arr[i], arr[i], i, arr)
}
}
forEach(['hello', 'world', '!'], function(currValue, idx, arr) {
console.log('当前值 ' + currValue + ',索引为 ' + idx)
})
// 输出: 当前值 hello,索引为 0
// 输出: 当前值 world,索引为 1
// 输出: 当前值 ! ,索引为 2
2.1 jQuery 源码中迭代器实现
jQuery也提供了一个$.each的遍历方法:
``js // jquery 源码 /src/core.js#L246-L265 each: function (obj, callback) { var i = 0
// obj 为数组时
if (isArrayLike(obj)) {
for (; i < obj.length; i++) {
if (callback.call(obj[i], i, obj[i]) === false) {
break
}
}
}
// obj 为对象时
else {
for (i in obj) {
if (callback.call(obj[i], i, obj[i]) === false) {
break
}
}
}
return obj
}
// 使用 $.each(['hello', 'world', '!'], function(idx, currValue){ console.log('当前值 ' + currValue + ',索引为 ' + idx) })
> 这里的源码分为两个部分,前一个部分是形参 `obj` 为数组情况下的处理,使用 `for` 循环,以数组下标依次使用 `call/apply` 传入回调中执行,第二部分是形参 obj 为对象情况下的处理,是使用 `for-in` 循环来获取对象上的属性。另外可以看到如果 `callback.call` 返回的结果是 `false` 的话,这个循环会被 `break`。
> 源码位于: `jquery/src/core.js#L246-L265`
由于处理对象时使用的是 `for-in`,所以原型上的变量也会被遍历出来:
```js
var foo = { paramProto: '原型上的变量' }
var bar = Object.create(foo, {
paramPrivate: {
configurable: true,
enumerable: true,
value: '自有属性',
writable: true
}
})
$.each(bar, function(key, currValue) {
console.log('当前值为 「' + currValue + '」,键为 ' + key)
})
// 输出: 当前值为 「自有属性」 ,键为 paramPrivate
// 输出: 当前值为 「原型上的属性」,键为 paramProto
- 因此可以使用
hasOwnProperty来判断键是否是在原型链上还是对象的自有属性。 - 我们还可以利用如果
callback.call返回的结果是false则break的特点,来进行一些操作:
$.each([1, 2, 3, 4, 5], function(idx, currValue) {
if (currValue > 3)
return false
console.log('当前值为 ' + currValue)
})
// 输出: 当前值为 1
// 输出: 当前值为 2
// 输出: 当前值为 3
2.2 underscore 源码中的迭代器实现
underscore 作为兼容到 IE6 的古董级工具库,自然也是有迭代器的实现:
// underscore 源码
_.each = function(obj, iteratee) {
var i, length
// obj 为数组时
if (isArrayLike(obj)) {
for (i = 0, length = obj.length; i < length; i++) {
iteratee(obj[i], i, obj)
}
}
// obj 为对象时
else {
var keys = _.keys(obj)
for (i = 0, length = keys.length; i < length; i++) {
iteratee(obj[keys[i]], keys[i], obj)
}
}
return obj
}
// 使用
_.each(['hello', 'world', '!'], function(currValue, idx, arr) {
console.log('当前值 ' + currValue + ',索引为 ' + idx)
})
underscore迭代器部分的实现跟jQuery的差不多,只是回调iteratee的执行是直接调用,而不是像 jQuery 是使用call,也不像 jQuery 那样提供了迭代终止break的支持,所以总的来说还是 jQuery 的实现更优。- 另外,这里 iteratee 变量的命名也可以看出来迭代器的含义。
- 源码位于:
underscore.js#L181-L195
3. JavaScript 原生支持
- 随着
JavaScript的ECMAScript标准每年的发展,给越来越多好用的API提供了支持,比如Array上的filter、forEach、reduce、flat等,还有Map、Set、String等数据结构,也提供了原生的迭代器支持,给我们的开发提供了很多便利,也让 underscore 这些工具库渐渐淡出历史舞台。
另外,JavaScript 中还有很多类数组结构,比如:
arguments:函数接受的所有参数构成的类数组对象;NodeList:是querySelector接口族返回的数据结构;HTMLCollection:是getElementsBy接口族返回的数据结构;
对于这些类数组结构,我们可以通过一些方式来转换成普通数组结构,以 arguments 为例:
// 方法一
var args = Array.prototype.slice.call(arguments)
// 方法二
var args = [].slice.call(arguments)
// 方法三 ES6提供
const args = Array.from(arguments)
// 方法四 ES6提供
const args = [...arguments];
转换成数组之后,就可以快乐使用
JavaScript在Array上提供的各种方法了。
4. ES6 中的迭代器
ES6规定,默认的迭代器部署在对应数据结构的Symbol.iterator属性上,如果一个数据结构具有Symbol.iterator属性,就被视为可遍历的,就可以用for...of循环遍历它的成员。也就是说,for...of循环内部调用的是数据结构的Symbol.iterator方法。for-of循环可以使用的范围包括Array、Set、Map结构、上文提到的类数组结构、Generator对象,以及字符串。
注意:
ES6的Iterator相关内容与本节主题无关,所以不做更详细的介绍,如果读者希望更深入,推介先阅读阮一峰的<Iterator 和 for...of 循环>相关内容。
- 通过
for-of可以使用Symbol.iterator这个属性提供的迭代器可以遍历对应数据结构,如果对没有提供Symbol.iterator的目标使用for-of则会抛错:
var foo = { a: 1 }
for (var key of foo) {
console.log(key)
}
// 输出: Uncaught TypeError: foo is not iterable
我们可以给一个对象设置一个迭代器,让一个对象也可以使用
for-of循环:
var bar = {
a: 1,
[Symbol.iterator]: function() {
var valArr = [
{ value: 'hello', done: false },
{ value: 'world', done: false },
{ value: '!', done: false },
{ value: undefined, done: true }
]
return {
next: function() {
return valArr.shift()
}
}
}
}
for (var key of bar) {
console.log(key)
}
// 输出: hello
// 输出: world
// 输出: !
可以看到
for-of循环连bar对象自己的属性都不遍历了,遍历获取的值只和Symbol.iterator方法实现有关。
5. 迭代器模式总结
- 迭代器模式早已融入我们的日常开发中,在使用
filter、reduce、map等方法的时候,不要忘记这些便捷的方法就是迭代器模式的应用。当我们使用迭代器方法处理一个对象时,我们可以关注与处理的逻辑,而不必关心对象的内部结构,侧面将对象内部结构和使用者之间解耦,也使得代码中的循环结构变得紧凑而优美
# 命令模式:江湖通缉令
行为型模式:命令模式
- 命令模式 (Command Pattern)又称事务模式,将请求封装成对象,将命令的发送者和接受者解耦。本质上是对方法调用的封装。
- 通过封装方法调用,也可以做一些有意思的事,例如记录日志,或者重复使用这些封装来实现撤销(undo)、重做(redo)操作。
1. 你曾见过的命令模式
某日,著名门派蛋黄派于江湖互联网发布江湖通缉令一张「通缉偷电瓶车贼窃格瓦拉,抓捕归案奖鸭蛋 10 个」。对于通缉令发送者蛋黄派来说,不需向某个特定单位通知通缉令,而通缉令发布之后,蛋黄派也不用管是谁来完成这个通缉令,也就是说,通缉令的发送者和接受者之间被解耦了。
大学宿舍的时候,室友们都上床了,没人起来关灯,不知道有谁提了一句「谁起来把灯关一下」,此时比的是谁装睡装得像,如果沉不住气,就要做命令的执行者,去关灯了。
比较经典的例子是餐馆订餐,客人需要向厨师发送请求,但是不知道这些厨师的联系方式,也不知道厨师炒菜的流程和步骤,一般是将客人订餐的请求封装成命令对象,也就是订单。这个订单对象可以在程序中被四处传递,就像订单可以被服务员传递到某个厨师手中,客人不需要知道是哪个厨师完成自己的订单,厨师也不需要知道是哪个客户的订单。
在类似场景中,这些例子有以下特点:
- 命令的发送者和接收者解耦,发送者与接收者之间没有直接引用关系,发送请求的对象只需要知道如何发送请求,而不必知道如何完成请求;
- 对命令还可以进行撤销、排队等操作,比如用户等太久不想等了撤销订单,厨师不够了将订单进行排队,等等操作;
2. 实例的代码实现
为了方便演示命令的撤销和重做,下面使用 JavaScript 来实现对超级玛丽的操控 🤣。
2.1 马里奥的操控实现
首先我们新建一个移动对象类,在以后的代码中是通用的:
var canvas = document.getElementById('my-canvas')
var CanvasWidth = 400 // 画布宽度
var CanvasHeight = 400 // 画布高度
var CanvasStep = 40 // 动作步长
canvas.width = CanvasWidth
canvas.height = CanvasHeight
// 移动对象类
var Role = function(x, y, imgSrc) {
this.position = { x, y }
this.canvas = document.getElementById('my-canvas')
this.ctx = this.canvas.getContext('2d')
this.img = new Image()
this.img.style.width = CanvasStep
this.img.style.height = CanvasStep
this.img.src = imgSrc
this.img.onload = () => {
this.ctx.drawImage(this.img, x, y, CanvasStep, CanvasStep)
this.move(0, 0)
}
}
Role.prototype.move = function(x, y) {
var pos = this.position
this.ctx.clearRect(pos.x, pos.y, CanvasStep, CanvasStep)
pos.x += x
pos.y += y
this.ctx.drawImage(this.img, pos.x, pos.y, CanvasStep, CanvasStep)
}
下面如果要实现操控超级玛丽,可以直接:
var mario = new Role(200, 200, 'https://i.loli.net/2019/08/09/sqnjmxSZBdPfNtb.jpg')
// 设置按钮回调
var elementUp = document.getElementById('up-btn')
elementUp.onclick = function() {
mario.move(0, -CanvasStep)
}
var elementDown = document.getElementById('down-btn')
elementDown.onclick = function() {
mario.move(0, CanvasStep)
}
var elementLeft = document.getElementById('left-btn')
elementLeft.onclick = function() {
mario.move(-CanvasStep, 0)
}
var elementRight = document.getElementById('right-btn')
elementRight.onclick = function() {
mario.move(CanvasStep, 0)
}
如果要新建一个小怪兽角色,可以:
var monster = new Role(160, 160, 'https://i.loli.net/2019/08/12/XCTzcdbhriLlskv.png')
2.2 引入命令模式
- 面的实现逻辑上没有问题,但当我们在页面上点击按钮发送操作请求时,需要向具体负责实现行为的对象发送请求操作,对应上面的例子中的 mario、monster,这些对象就是操作的接受者。也就是说,操作的发送者直接持有操作的接受者,逻辑直接暴露在页面 DOM 的事件回调中,耦合较强。如果要增加新的角色,需要对 DOM 的回调函数进行改动,如果对操作行为进行修改,对应地,也需修改 DOM 回调函数。
- 此时,我们可以引入命令模式,以便将操作的发送者和操作的接受者解耦。在这个例子中,我们将操作马里奥的行为包装成命令类,操作的发送者只需要持有对应的命令实例并执行,命令的内容是具体的行为逻辑。
- 多说无益,直接看代码(从这里之后就直接用 ES6):
const canvas = document.getElementById('my-canvas')
const CanvasWidth = 400 // 画布宽度
const CanvasHeight = 400 // 画布高度
const CanvasStep = 40 // 动作步长
canvas.width = CanvasWidth
canvas.height = CanvasHeight
const btnUp = document.getElementById('up-btn')
const btnDown = document.getElementById('down-btn')
const btnLeft = document.getElementById('left-btn')
const btnRight = document.getElementById('right-btn')
// 移动对象类
class Role {
constructor(x, y, imgSrc) {
this.x = x
this.y = y
this.canvas = document.getElementById('my-canvas')
this.ctx = this.canvas.getContext('2d')
this.img = new Image()
this.img.style.width = CanvasStep
this.img.style.height = CanvasStep
this.img.src = imgSrc
this.img.onload = () => {
this.ctx.drawImage(this.img, x, y, CanvasStep, CanvasStep)
this.move(0, 0)
}
}
move(x, y) {
this.ctx.clearRect(this.x, this.y, CanvasStep, CanvasStep)
this.x += x
this.y += y
this.ctx.drawImage(this.img, this.x, this.y, CanvasStep, CanvasStep)
}
}
// 向上移动命令类
class MoveUpCommand {
constructor(receiver) {
this.receiver = receiver
}
execute(role) {
this.receiver.move(0, -CanvasStep)
}
}
// 向下移动命令类
class MoveDownCommand {
constructor(receiver) {
this.receiver = receiver
}
execute(role) {
this.receiver.move(0, CanvasStep)
}
}
// 向左移动命令类
class MoveLeftCommand {
constructor(receiver) {
this.receiver = receiver
}
execute(role) {
this.receiver.move(-CanvasStep, 0)
}
}
// 向右移动命令类
class MoveRightCommand {
constructor(receiver) {
this.receiver = receiver
}
execute(role) {
this.receiver.move(CanvasStep, 0)
}
}
// 设置按钮命令
const setCommand = function(element, command) {
element.onclick = function() {
command.execute()
}
}
/* ----- 客户端 ----- */
const mario = new Role(200, 200, 'https://i.loli.net/2019/08/09/sqnjmxSZBdPfNtb.jpg')
const moveUpCommand = new MoveUpCommand(mario)
const moveDownCommand = new MoveDownCommand(mario)
const moveLeftCommand = new MoveLeftCommand(mario)
const moveRightCommand = new MoveRightCommand(mario)
setCommand(btnUp, moveUpCommand)
setCommand(btnDown, moveDownCommand)
setCommand(btnLeft, moveLeftCommand)
setCommand(btnRight, moveRightCommand)
- 我们把操作的逻辑分别提取到对应的
Command类中,并约定Command类的execute方法存放命令接收者需要执行的逻辑,也就是前面例子中的onclick回调方法部分。 - 按下操作按钮之后会发生事情这个逻辑是不变的,而具体发生什么事情的逻辑是可变的,这里我们可以提取出公共逻辑,把一定发生事情这个逻辑提取到
setCommand 方法中,在这里调用命令类实例的execute方法,而不同事情具体逻辑的不同体现在各个execute` 方法的不同实现中。 - 至此,命令的发送者已经知道自己将会执行一个
Command类实例的execute实例方法,但是具体是哪个操作类的类实例来执行,还不得而知,这时候需要调用setCommand方法来告诉命令的发送者,执行的是哪个命令。
综上,一个命令模式改造后的实例就完成了,但是在
JavaScript中,命令不一定要使用类的形式:
// 前面代码一致
// 向上移动命令对象
const MoveUpCommand = {
execute(role) {
role.move(0, -CanvasStep)
}
}
// 向下移动命令对象
const MoveDownCommand = {
execute(role) {
role.move(0, CanvasStep)
}
}
// 向左移动命令对象
const MoveLeftCommand = {
execute(role) {
role.move(-CanvasStep, 0)
}
}
// 向右移动命令对象
const MoveRightCommand = {
execute(role) {
role.move(CanvasStep, 0)
}
}
// 设置按钮命令
const setCommand = function(element, role, command) {
element.onclick = function() {
command.execute(role)
}
}
/* ----- 客户端 ----- */
const mario = new Role(200, 200, 'https://i.loli.net/2019/08/09/sqnjmxSZBdPfNtb.jpg')
setCommand(btnUp, mario, MoveUpCommand)
setCommand(btnDown, mario, MoveDownCommand)
setCommand(btnLeft, mario, MoveLeftCommand)
setCommand(btnRight, mario, MoveRightCommand)
2.3 命令模式升级
- 可以对这个项目进行升级,记录这个角色的行动历史,并且提供一个 redo、undo 按钮,撤销和重做角色的操作,可以想象一下如果不使用命令模式,记录的 Log 将比较乱,也不容易进行操作撤销和重做。
下面我们可以使用命令模式来对上面马里奥的例子进行重构,有下面几个要点:
- 命令对象包含有 execute 方法和 undo 方法,前者是执行和重做时执行的方法,后者是撤销时执行的反方法;
- 每次执行操作时将当前操作命令推入撤销命令栈,并将当前重做命令栈清空;
- 撤销操作时,将撤销命令栈中最后推入的命令取出并执行其 undo 方法,且将该命令推入重做命令栈;
- 重做命令时,将重做命令栈中最后推入的命令取出并执行其 execute 方法,且将其推入撤销命令栈;
// 向上移动命令对象
const MoveUpCommand = {
execute(role) {
role.move(0, -CanvasStep)
},
undo(role) {
role.move(0, CanvasStep)
}
}
// 向下移动命令对象
const MoveDownCommand = {
execute(role) {
role.move(0, CanvasStep)
},
undo(role) {
role.move(0, -CanvasStep)
}
}
// 向左移动命令对象
const MoveLeftCommand = {
execute(role) {
role.move(-CanvasStep, 0)
},
undo(role) {
role.move(CanvasStep, 0)
}
}
// 向右移动命令对象
const MoveRightCommand = {
execute(role) {
role.move(CanvasStep, 0)
},
undo(role) {
role.move(-CanvasStep, 0)
}
}
// 命令管理者
const CommandManager = {
undoStack: [], // 撤销命令栈
redoStack: [], // 重做命令栈
executeCommand(role, command) {
this.redoStack.length = 0 // 每次执行清空重做命令栈
this.undoStack.push(command) // 推入撤销命令栈
command.execute(role)
},
/* 撤销 */
undo(role) {
if (this.undoStack.length === 0) return
const lastCommand = this.undoStack.pop()
lastCommand.undo(role)
this.redoStack.push(lastCommand) // 放入redo栈中
},
/* 重做 */
redo(role) {
if (this.redoStack.length === 0) return
const lastCommand = this.redoStack.pop()
lastCommand.execute(role)
this.undoStack.push(lastCommand) // 放入undo栈中
}
}
// 设置按钮命令
const setCommand = function(element, role, command) {
if (typeof command === 'object') {
element.onclick = function() {
CommandManager.executeCommand(role, command)
}
} else {
element.onclick = function() {
command.call(CommandManager, role)
}
}
}
/* ----- 客户端 ----- */
const mario = new Role(200, 200, 'https://i.loli.net/2019/08/09/sqnjmxSZBdPfNtb.jpg')
setCommand(btnUp, mario, MoveUpCommand)
setCommand(btnDown, mario, MoveDownCommand)
setCommand(btnLeft, mario, MoveLeftCommand)
setCommand(btnRight, mario, MoveRightCommand)
setCommand(btnUndo, mario, CommandManager.undo)
setCommand(btnRedo, mario, CommandManager.redo)
我们可以给马里奥画一个蘑菇 ,当马里奥走到蘑菇上面的时候提示「挑战成功!
有了撤销和重做命令之后,做一些小游戏比如围棋、象棋,会很容易就实现悔棋、复盘等功能。
3. 命令模式的优缺点
命令模式的优点:
- 命令模式将调用命令的请求对象与执行该命令的接收对象解耦,因此系统的可扩展性良好,加入新的命令不影响原有逻辑,所以增加新的命令也很容易;
- 命令对象可以被不同的请求者角色重用,方便复用;
- 可以将命令记入日志,根据日志可以容易地实现对命令的撤销和重做;
- 命令模式的缺点:命令类或者命令对象随着命令的变多而膨胀,如果命令对象很多,那么使用者需要谨慎使用,以免带来不必要的系统复杂度。
4. 命令模式的使用场景
- 需要将请求调用者和请求的接收者解耦的时候;
- 需要将请求排队、记录请求日志、撤销或重做操作时;
5. 其他相关模式 5.1 命令模式与职责链模式
命令模式和职责链模式可以结合使用,比如具体命令的执行,就可以引入职责链模式,让命令由职责链中合适的处理者执行。
5.2 命令模式与组合模式
命令模式和组合模式可以结合使用,比如不同的命令可以使用组合模式的方法形成一个宏命令,执行完一个命令之后,再继续执行其子命令。
5.3 命令模式与工厂模式
命令模式与工厂模式可以结合使用,比如命令模式中的命令可以由工厂模式来提供
# 职责链模式:领导,我想请个假
1. 你曾经见过的职责链模式
小伙伴来你的城市找你玩耍,因此你需要请两天假。首先跟你的小组领导提了一句,小领导说不行呐我只能批半天假,建议找部门经理。于是你来到了部门经理办公室,部门经理说不行呐我只能批一天假,建议找总经理。来到总经理办公室,总经理勉为其难的说,好叭,不过要扣你四天工资。于是你请到了两天假,和小伙伴快乐(并不 )玩耍了。
当你作为请求者提出请假申请时,这个申请会由小组领导、部门经理、总经理之中的某一位领导来进行处理,但一开始提出申请的时候,并不知道这个申请之后由哪个领导来处理,也许是部门经理,或者是总经理,请求者事先不知道这个申请最后到底应该由哪个领导处理。
再比如,某个快乐的下午正在快乐次冰棍,你的胃突然有点不舒服,于是决定看看什么情况。首先你去了社区医院,社区医生看了看说可能很严重但也不能确定,你大吃一惊,去了县城的医院。县城的医院做了简单的检查,跟你说可能是胃炎但不确定,建议去更大的医院。然后你来到了省城的医院,医生看了看说,没啥,这就是消化不良(来自在下的亲身经历 )。
和上面请假的例子类似,看病的医院会告诉看病者是否可以治疗,社区医院不成就转院到县城医院,再不行就转院到更大的医院,而看病者一开始在社区医院看病的时候,并不知道这个病最后哪个医院可以治疗,也许是县城医院,也许是省城医院。
在类似的场景中,这些例子有以下特点:
- 请求在一系列对象中传递,形成一条链;
- 链中的请求接受者对请求进行分析,要么处理这个请求,要么把这个请求传递给链的下一个接受者;
2. 实例的代码实现 2.1 代码实现
我们可以使用 JavaScript 来将之前的请假例子实现一下。
var askLeave = function(duration) {
if (duration <= 0.5) {
console.log('小组领导经过一番心理斗争:批准了')
} else if (duration <= 1) {
console.log('部门领导经过一番心理斗争:批准了')
} else if (duration <= 2) {
console.log('总经理经过一番心理斗争:批准了')
} else {
console.log('总经理:不准请这么长的假')
}
}
askLeave(0.5) // 小组领导经过一番心理斗争:批准了
askLeave(1) // 部门领导经过一番心理斗争:批准了
askLeave(2) // 总经理经过一番心理斗争:批准了
askLeave(3) // 总经理:不准请这么长的假
2.2 初步优化
上面的实现没有问题,也可以正常运行,但正常情况下,处理逻辑可能就不仅仅是一个 console.log 这么简单,而是包含一些年假、调休、项目忙碌情况的复杂判断,此时这个 askLeave 方法就变得庞大而臃肿,如果中间增加一个新的领导层,可以批准 1.5 天的假期,那么你就要修改这个庞大的 askLeave 方法,维护工作变得复杂。
这里我们可以将不同领导的处理逻辑(也就是职责节点)提取出来,让不同节点的职责逻辑界限变得明显,代码结构更明显。请假的时候直接找小组领导,如果小组领导处理不好,直接把请求传递给部门领导,部门领导处理不了则传递给总经理。
/* 小组领导处理逻辑 */
var askLeaveGroupLeader = function(duration) {
if (duration <= 0.5) {
console.log('小组领导经过一番心理斗争:批准了')
} else
askLeaveDepartmentLeader(duration)
}
/* 部门领导处理逻辑 */
var askLeaveDepartmentLeader = function(duration) {
if (duration <= 1) {
console.log('部门领导经过一番心理斗争:批准了')
} else
askLeaveGeneralLeader(duration)
}
/* 总经理处理逻辑 */
var askLeaveGeneralLeader = function(duration) {
if (duration <= 2) {
console.log('总经理经过一番心理斗争:批准了')
} else
console.log('总经理:不准请这么长的假')
}
askLeaveGroupLeader(0.5) // 小组领导经过一番心理斗争:批准了
askLeaveGroupLeader(1) // 部门领导经过一番心理斗争:批准了
askLeaveGroupLeader(2) // 总经理经过一番心理斗争:批准了
askLeaveGroupLeader(3) // 总经理:不准请这么长的假
2.3 使用职责链模式重构
上面的实现,逻辑倒是清晰了,也不会有个超大的函数一把梭,但是还有个问题,比如 askLeaveGroupLeader 这个函数里就直接耦合了 askLeaveDepartmentLeader 这个函数,其他函数也是各自耦合在一起,如果要在其中两个职责节点中间增加一个节点,或者去掉一个节点,那么就要同时改动相邻的职责节点函数,这就违反了开闭原则,我们希望增加新的职责节点的时候,对原来的代码没有影响。
这时我们可以引入职责链模式,将职责节点的下一个节点使用拼接的方式,而不是在声明的时候就固定。这里我们:
/* 小组领导 */
var GroupLeader = {
nextLeader: null,
setNext: function(next) {
this.nextLeader = next
},
handle: function(duration) {
if (duration <= 0.5) {
console.log('小组领导经过一番心理斗争:批准了')
} else
this.nextLeader.handle(duration)
}
}
/* 部门领导 */
var DepartmentLeader = {
nextLeader: null,
setNext: function(next) {
this.nextLeader = next
},
handle: function(duration) {
if (duration <= 1) {
console.log('部门领导经过一番心理斗争:批准了')
} else
this.nextLeader.handle(duration)
}
}
/* 总经理 */
var GeneralLeader = {
nextLeader: null,
setNext: function(next) {
this.nextLeader = next
},
handle: function(duration) {
if (duration <= 2) {
console.log('总经理经过一番心理斗争:批准了')
} else
console.log('总经理:不准请这么长的假')
}
}
GroupLeader.setNext(DepartmentLeader) // 设置小组领导的下一个职责节点为部门领导
DepartmentLeader.setNext(GeneralLeader) // 设置部门领导的下一个职责节点为总经理
GroupLeader.handle(0.5) // 小组领导经过一番心理斗争:批准了
GroupLeader.handle(1) // 部门领导经过一番心理斗争:批准了
GroupLeader.handle(2) // 总经理经过一番心理斗争:批准了
GroupLeader.handle(3) // 总经理:不准请这么长的假
这样,将职责的链在使用的时候再拼起来,灵活性好,比如如果要在部门领导和总经理中间增加一个新的职责节点,那么在使用时:
/* 新领导 */
var MewLeader = {
nextLeader: null,
setNext: function(next) {
this.nextLeader = next
},
handle: function(duration) { ... }
}
GroupLeader.setNext(DepartmentLeader) // 设置小组领导的下一个职责节点为部门领导
DepartmentLeader.setNext(MewLeader) // 设置部门领导的下一个职责节点为新领导
MewLeader.setNext(GeneralLeader) // 设置新领导的下一个职责节点为总经理
- 删除节点也是类似操作,非常符合开闭原则了,给维护带来很大方便。
- 但是我们看到之前的内容有很多重复代码,比如
Leader对象里的nextLeader、setNext里的逻辑就是一样的,可以用继承来避免这部分重复。
首先使用 ES5 的方式:
/* 领导基类 */
var Leader = function() {
this.nextLeader = null
}
Leader.prototype.setNext = function(next) {
this.nextLeader = next
}
/* 小组领导 */
var GroupLeader = new Leader()
GroupLeader.handle = function(duration) {
if (duration <= 0.5) {
console.log('小组领导经过一番心理斗争:批准了')
} else
this.nextLeader.handle(duration)
}
/* 部门领导 */
var DepartmentLeader = new Leader()
DepartmentLeader.handle = function(duration) {
if (duration <= 1) {
console.log('部门领导经过一番心理斗争:批准了')
} else
this.nextLeader.handle(duration)
}
/* 总经理 */
var GeneralLeader = new Leader()
GeneralLeader.handle = function(duration) {
if (duration <= 2) {
console.log('总经理经过一番心理斗争:批准了')
} else
console.log('总经理:不准请这么长的假')
}
GroupLeader.setNext(DepartmentLeader) // 设置小组领导的下一个职责节点为部门领导
DepartmentLeader.setNext(GeneralLeader) // 设置部门领导的下一个职责节点为总经理
GroupLeader.handle(0.5) // 小组领导经过一番心理斗争:批准了
GroupLeader.handle(1) // 部门领导经过一番心理斗争:批准了
GroupLeader.handle(2) // 总经理经过一番心理斗争:批准了
GroupLeader.handle(3) // 总经理:不准请这么长的假
我们使用 ES6 的 Class 语法改造一下:
/* 领导基类 */
class Leader {
constructor() {
this.nextLeader = null
}
setNext(next) {
this.nextLeader = next
}
}
/* 小组领导 */
class GroupLeader extends Leader {
handle(duration) {
if (duration <= 0.5) {
console.log('小组领导经过一番心理斗争:批准了')
} else
this.nextLeader.handle(duration)
}
}
/* 部门领导 */
class DepartmentLeader extends Leader {
handle(duration) {
if (duration <= 1) {
console.log('部门领导经过一番心理斗争:批准了')
} else
this.nextLeader.handle(duration)
}
}
/* 总经理 */
class GeneralLeader extends Leader {
handle(duration) {
if (duration <= 2) {
console.log('总经理经过一番心理斗争:批准了')
} else
console.log('总经理:不准请这么长的假')
}
}
const zhangSan = new GroupLeader()
const liSi = new DepartmentLeader()
const wangWu = new GeneralLeader()
zhangSan.setNext(liSi) // 设置小组领导的下一个职责节点为部门领导
liSi.setNext(wangWu) // 设置部门领导的下一个职责节点为总经理
zhangSan.handle(0.5) // 小组领导经过一番心理斗争:批准了
zhangSan.handle(1) // 部门领导经过一番心理斗争:批准了
zhangSan.handle(2) // 总经理经过一番心理斗争:批准了
zhangSan.handle(3) // 总经理:不准请这么长的假
2.4 使用链模式重构
之前的代码实现,我们可以使用链模式稍加重构,在设置下一个职责节点的方法 setNext 中返回下一个节点实例,使得在职责链的组装过程是一个链的形式,代码结构更加简洁。
首先是 ES5 方式:
/* 领导基类 */
var Leader = function() {
this.nextLeader = null
}
Leader.prototype.setNext = function(next) {
this.nextLeader = next
return next
}
/* 小组领导 */
var GroupLeader = new Leader()
GroupLeader.handle = function(duration) { ... }
/* 部门领导 */
var DepartmentLeader = new Leader()
DepartmentLeader.handle = function(duration) { ... }
/* 总经理 */
var GeneralLeader = new Leader()
GeneralLeader.handle = function(duration) { ... }
/* 组装职责链 */
GroupLeader
.setNext(DepartmentLeader) // 设置小组领导的下一个职责节点为部门领导
.setNext(GeneralLeader) // 设置部门领导的下一个职责节点为总经理
ES6 方式同理:
/* 领导基类 */
class Leader {
constructor() {
this.nextLeader = null
}
setNext(next) {
this.nextLeader = next
return next
}
}
/* 小组领导 */
class GroupLeader extends Leader {
handle(duration) { ... }
}
/* 部门领导 */
class DepartmentLeader extends Leader {
handle(duration) { ... }
}
/* 总经理 */
class GeneralLeader extends Leader {
handle(duration) { ... }
}
const zhangSan = new GroupLeader()
const liSi = new DepartmentLeader()
const wangWu = new GeneralLeader()
/* 组装职责链 */
zhangSan
.setNext(liSi) // 设置小组领导的下一个职责节点为部门领导
.setNext(wangWu) // 设置部门领导的下一个职责节点为总经理
3. 职责链模式的原理
职责链模式可能在真实的业务代码中见的不多,但是作用域链、原型链、DOM 事件流的事件冒泡,都有职责链模式的影子:
- 作用域链: 查找变量时,先从当前上下文的变量对象中查找,如果没有找到,就会从父级执行上下文的变量对象中查找,一直找到全局上下文的变量对象。
- 原型链: 当读取实例的属性时,如果找不到,就会查找当前对象关联的原型中的属性,如果还查不到,就去找原型的原型,一直找到最顶层为止。
- 事件冒泡: 事件在 DOM 元素上触发后,会从最内层的元素开始发生,一直向外层元素传播,直到全局 document 对象。
以事件冒泡为例,事件在某元素上触发后,会一级级往外层元素传递事件,如果当前元素没有处理这个事件并阻止冒泡,那么这个事件就会往外层节点传递,就像请求在职责链中的职责节点上传递一样,直到某个元素处理了事件并阻止冒泡。
事件冒泡示意图如下:
可见虽然某些设计模式我们用的不多,但其实已经默默渗入到我们的日常开发中了。
4. 职责链模式的优缺点
职责链模式的优点:
- 和命令模式类似,由于处理请求的职责节点可能是职责链上的任一节点,所以请求的发送者和接受者是解耦的;
- 通过改变链内的节点或调整节点次序,可以动态地修改责任链,符合开闭原则;
职责链模式的缺点:
- 并不能保证请求一定会被处理,有可能到最后一个节点还不能处理;
- 调试不便,调用层次会比较深,也有可能会导致循环引用;
5. 职责链模式的适用场景
- 需要多个对象可以处理同一个请求,具体该请求由哪个对象处理在运行时才确定;
- 在不明确指定接收者的情况下,向多个对象中的其中一个提交请求的话,可以使用职责链模式;
- 如果想要动态指定处理一个请求的对象集合,可以使用职责链模式;
6. 其他相关模式 6.1 职责链模式与组合模式
- 职责链模式可以和组合模式一起使用,比如把职责节点通过组合模式来组合,从而形成组合起来的树状职责链。
6.2 职责链模式与装饰模式
- 这两个模式都是在运行期间动态组合,装饰模式是动态组合装饰器,可以有任意多个对象来装饰功能,而职责链是动态组合职责节点,有一个职责节点处理的话就结束。
- 另外他们的目的也不同,装饰模式为对象添加功能,而职责链模式是要实现发送者和接收者解耦。
# 中介者模式:找媒人介绍对象
- 中介者模式 (Mediator Pattern)又称调停模式,使得各对象不用显式地相互引用,将对象与对象之间紧密的耦合关系变得松散,从而可以独立地改变他们。核心是多个对象之间复杂交互的封装。
- 根据最少知识原则,一个对象应该尽量少地了解其他对象。如果对象之间耦合性太高,改动一个对象则会影响到很多其他对象,可维护性差。复杂的系统,对象之间的耦合关系会得更加复杂,中介者模式就是为了解决这个问题而诞生的。
1. 你曾见过的中介者模式
举一个有点意思的例子。相亲是一个多方博弈、互相选择(嫌弃)的场景,男生和女生相亲,不仅仅是男生和女生两方关系,还有:
男方的角度:
- 男生会考虑女生的长相、身高、性格、三观、家境、和自己父母能不能合得来、对方家长是否好相处等等;
- 男生的家长会考虑女生的条件、和自己儿子搭不搭、对方家长的性格等等;
女方的角度:
- 女生会考虑男生的性格、上进心、是不是高富帅、能不能通过自己父母的法眼、对方家长是否好相处等等;
- 女生的家长也会考虑男生的条件、是不是配得上自己女儿、对方家长的性格等等;
- 双方的家长可能还有博弈和交换,比如你家是公务员,那么可以稍微穷一点;我家比较帅,那么矮一点对方也可以接受…总之,男生、女生、男方家长、女方家长各方的关系交错复杂,每个人都有自己的考量,如果某一方有什么想法,要和其他三方进行沟通,牵一发动全身。这时候我们可以引入媒人,无论哪一方有什么要求或者什么想法,都可以直接告诉媒人,这样就不用各方自己互相沟通了。
再看另一个例子。比如买房子的时候,我们不必自己去跑到每个卖家那里了解情况,而一般选择从中介那里获取房源信息。卖家们把各自的房源信息提供给中介,包括房源的大小、楼层、朝向等,有的卖家说价格还可以谈,有的卖家说我的房子带阁楼,有的卖家说要跟车库一起卖,等等。买家从中介处就可以获取自己所需的房源信息,比如你不需要车库,也不住一楼和顶楼,只考虑一百平米以上的屋子,中介就会给你筛选出满足你需要的所有房源供你查看,而不需买家一个个的找卖家们了解信息,当你正关注的卖家房子卖出去了中介也会及时告诉你,这就是中介的作用。
类似的例子还有很多,比如电商平台之于买家与店家,聊天平台之于每个聊天者,澳门大型线上赌场之于每个参与赌博的人
在类似的场景中,有以下特点:
- 相亲各方/房源买家卖家(目标对象)之间的关系复杂,引入媒人/中介(中介者)会极大方便各方之间的沟通;
- 相亲各方/房源买家卖家(目标对象)之间如果有什么想法和要求上的变动,通过媒人/中介(中介者)就可以及时通知到相关各方,而目标对象之间相互不通信;
2. 实例的代码实现
我们使用 JavaScript 将刚刚的相亲例子实现一下。
首先我们考虑一个场景,男方和女方都有一定的条件,双方之间有要求,双方家长对对方孩子也有要求,如果达不到要求则不同意这门婚事。(也就是说暂时不考虑男女双方对于对方家长,和双方家长之间的要求,因为这样代码就太长了)
class Person {
/* 个人信息 */
constructor(name, info, target) {
this.name = name
this.info = info // 是一个对象,每一项为数字,比如身高、工资..
this.target = target // 也是对象,每一项为两个数字的数组,表示可接受的最低和最高值
this.enemyList = [] // 考虑列表
}
/* 注册相亲对象及家长 */
registEnemy(...enemy) {
this.enemyList.push(...enemy)
}
/* 检查所有相亲对象及其家长的条件 */
checkAllPurpose() {
this.enemyList.forEach(enemy => enemy.info && this.checkPurpose(enemy))
}
/* 检查对方是否满足自己的要求,并发信息 */
checkPurpose(enemy) {
const result = Object.keys(this.target) // 是否满足自己的要求
.every(key => {
const [low, high] = this.target[key]
return low <= enemy.info[key] && enemy.info[key] <= high
})
enemy.receiveResult(result, this, enemy) // 通知对方
}
/* 接受到对方的信息 */
receiveResult(result, they, me) {
result
? console.log(`${ they.name }:我觉得合适~ \t(我的要求 ${ me.name } 已经满足)`)
: console.log(`${ they.name }:你是个好人! \t(我的要求 ${ me.name } 不能满足!)`)
}
}
/* 男方 */
const ZhangXiaoShuai = new Person(
'张小帅',
{ age: 25, height: 171, salary: 5000 },
{ age: [23, 27] })
/* 男方家长 */
const ZhangXiaoShuaiParent = new Person(
'张小帅家长',
null,
{ height: [160, 167] })
/* 女方 */
const LiXiaoMei = new Person(
'李小美',
{ age: 23, height: 160 },
{ age: [25, 27] })
/* 女方家长 */
const LiXiaoMeiParent = new Person(
'李小美家长',
null,
{ salary: [10000, 20000] })
/* 注册,每一个 person 实例都需要注册对方家庭成员的信息 */
ZhangXiaoShuai.registEnemy(LiXiaoMei, LiXiaoMeiParent)
LiXiaoMei.registEnemy(ZhangXiaoShuai, ZhangXiaoShuaiParent)
ZhangXiaoShuaiParent.registEnemy(LiXiaoMei, LiXiaoMeiParent)
LiXiaoMeiParent.registEnemy(ZhangXiaoShuai, ZhangXiaoShuaiParent)
/* 检查对方是否符合要求,同样,每一个 person 实例都需要执行检查 */
ZhangXiaoShuai.checkAllPurpose()
LiXiaoMei.checkAllPurpose()
ZhangXiaoShuaiParent.checkAllPurpose()
LiXiaoMeiParent.checkAllPurpose()
// 张小帅:我觉得合适~ (我的要求 李小美 已经满足)
// 李小美:我觉得合适~ (我的要求 张小帅 已经满足)
// 张小帅家长:我觉得合适~ (我的要求 李小美 已经满足)
// 李小美家长:你是个好人! (我的要求 张小帅 不能满足!)
当然作为灵活的 JavaScript,并不一定需要使用类,使用对象的形式也是可以的:
const PersonFunc = {
/* 注册相亲对象及家长 */
registEnemy(...enemy) {
this.enemyList.push(...enemy)
},
/* 检查所有相亲对象及其家长的条件 */
checkAllPurpose() {
this.enemyList.forEach(enemy => enemy.info && this.checkPurpose(enemy))
},
/* 检查对方是否满足自己的要求,并发信息 */
checkPurpose(enemy) {
const result = Object.keys(this.target) // 是否满足自己的要求
.every(key => {
const [low, high] = this.target[key]
return low <= enemy.info[key] && enemy.info[key] <= high
})
enemy.receiveResult(result, this, enemy) // 通知对方
},
/* 接受到对方的信息 */
receiveResult(result, they, me) {
result
? console.log(`${ they.name }:我觉得合适~ \t(我的要求 ${ me.name } 已经满足)`)
: console.log(`${ they.name }:你是个好人! \t(我的要求 ${ me.name } 不能满足!)`)
}
}
/* 男方 */
const ZhangXiaoShuai = {
...PersonFunc,
name: '张小帅',
info: { age: 25, height: 171, salary: 5000 },
target: { age: [23, 27] },
enemyList: []
}
/* 男方家长 */
const ZhangXiaoShuaiParent = {
...PersonFunc,
name: '张小帅家长',
info: null,
target: { height: [160, 167] },
enemyList: []
}
/* 女方 */
const LiXiaoMei = {
...PersonFunc,
name: '李小美',
info: { age: 23, height: 160 },
target: { age: [25, 27] },
enemyList: []
}
/* 女方家长 */
const LiXiaoMeiParent = {
...PersonFunc,
name: '李小美家长',
info: null,
target: { salary: [10000, 20000] },
enemyList: []
}
/* 注册 */
ZhangXiaoShuai.registEnemy(LiXiaoMei, LiXiaoMeiParent)
LiXiaoMei.registEnemy(ZhangXiaoShuai, ZhangXiaoShuaiParent)
ZhangXiaoShuaiParent.registEnemy(LiXiaoMei, LiXiaoMeiParent)
LiXiaoMeiParent.registEnemy(ZhangXiaoShuai, ZhangXiaoShuaiParent)
/* 检查对方是否符合要求 */
ZhangXiaoShuai.checkAllPurpose()
LiXiaoMei.checkAllPurpose()
ZhangXiaoShuaiParent.checkAllPurpose()
LiXiaoMeiParent.checkAllPurpose()
// 张小帅:我觉得合适~ (我的要求 李小美 已经满足)
// 李小美:我觉得合适~ (我的要求 张小帅 已经满足)
// 张小帅家长:我觉得合适~ (我的要求 李小美 已经满足)
// 李小美家长:你是个好人! (我的要求 张小帅 不能满足!)
我们还可以使用
Object.create()赋值原型的方式将方法放在原型上,也可以使用原型继承的方式,JavaScript 的灵活性让你可以自由选择习惯的方式。
单就结果而言,上面的代码可以实现整个逻辑。但是这几个对象之间相互引用、相互持有,并紧密耦合。如果继续引入关系,比如张小帅的七大姑、李小美的八大姨,或者考虑的情况更多一些,那么就要改动很多代码,上面的写法就满足不了要求了。
这时我们可以引入媒人(中介者),专门处理对象之间的耦合关系,所有对象间相互不了解,只与媒人交互,如果引入了新的相关方,也只需要通知媒人即可。看一下实现:
``js /* 男方 */ const ZhangXiaoShuai = { name: '张小帅', family: '张小帅家', info: { age: 25, height: 171, salary: 5000 }, target: { age: [23, 27] } }
/* 男方家长 */ const ZhangXiaoShuaiParent = { name: '张小帅家长', family: '张小帅家', info: null, target: { height: [160, 167] } }
/* 女方 */ const LiXiaoMei = { name: '李小美', family: '李小美家', info: { age: 23, height: 160 }, target: { age: [25, 27] } }
/* 女方家长 */ const LiXiaoMeiParent = { name: '李小美家长', family: '李小美家', info: null, target: { salary: [10000, 20000] } }
/* 媒人 */ const MatchMaker = { matchBook: {}, // 媒人的花名册
/* 注册各方 */
registPersons(...personList) {
personList.forEach(person => {
if (this.matchBook[person.family]) {
this.matchBook[person.family].push(person)
} else this.matchBook[person.family] = [person]
})
},
/* 检查对方家庭的孩子对象是否满足要求 */
checkAllPurpose() {
Object.keys(this.matchBook) // 遍历名册中所有家庭
.forEach((familyName, idx, matchList) =>
matchList
.filter(match => match !== familyName) // 对于其中一个家庭,过滤出名册中其他的家庭
.forEach(enemyFamily => this.matchBook[enemyFamily] // 遍历该家庭中注册到名册上的所有成员
.forEach(enemy => this.matchBook[familyName]
.forEach(person => // 逐项比较自己的条件和他们的要求
enemy.info && this.checkPurpose(person, enemy)
)
))
)
},
/* 检查对方是否满足自己的要求,并发信息 */
checkPurpose(person, enemy) {
const result = Object.keys(person.target) // 是否满足自己的要求
.every(key => {
const [low, high] = person.target[key]
return low <= enemy.info[key] && enemy.info[key] <= high
})
this.receiveResult(result, person, enemy) // 通知对方
},
/* 通知对方信息 */
receiveResult(result, person, enemy) {
result
? console.log(`${ person.name } 觉得合适~ \t(${ enemy.name } 已经满足要求)`)
: console.log(`${ person.name } 觉得不合适! \t(${ enemy.name } 不能满足要求!)`)
}
}
/* 注册 */ MatchMaker.registPersons(ZhangXiaoShuai, ZhangXiaoShuaiParent, LiXiaoMei, LiXiaoMeiParent)
MatchMaker.checkAllPurpose()
// 输出: 小帅 觉得合适~ (李小美 已经满足要求) // 输出: 张小帅家长 觉得合适~ (李小美 已经满足要求) // 输出: 李小美 觉得合适~ (张小帅 已经满足要求) // 输出: 李小美家长 觉得不合适! (张小帅 不能满足要求!)
> 可以看到,除了媒人之外,其他各个角色都是独立的,相互不知道对方的存在,对象间关系被解耦,我们甚至可以方便地添加新的对象。比如赵小美家同时还在考虑着孙小拽(emmm…):
```js
// 重写上面「注册」之后的代码
/* 引入孙小拽 */
const SunXiaoZhuai = {
name: '孙小拽',
familyType: '男方',
info: { age: 27, height: 173, salary: 20000 },
target: { age: [23, 27] }
}
/* 孙小拽家长 */
const SunXiaoZhuaiParent = {
name: '孙小拽家长',
familyType: '男方',
info: null,
target: { height: [160, 170] }
}
/* 注册,这里只需要注册一次 */
MatchMaker.registPersons(ZhangXiaoShuai,
ZhangXiaoShuaiParent,
LiXiaoMei,
LiXiaoMeiParent,
SunXiaoZhuai,
SunXiaoZhuaiParent)
/* 检查对方是否符合要求,也只需要检查一次 */
MatchMaker.checkAllPurpose()
// 输出: 张小帅 觉得合适~ (李小美 已经满足要求)
// 输出: 张小帅家长 觉得合适~ (李小美 已经满足要求)
// 输出: 孙小拽 觉得合适~ (李小美 已经满足要求)
// 输出: 孙小拽家长 觉得合适~ (李小美 已经满足要求)
// 输出: 李小美 觉得合适~ (张小帅 已经满足要求)
// 输出: 李小美家长 觉得不合适! (张小帅 不能满足要求!)
// 输出: 李小美 觉得合适~ (孙小拽 已经满足要求)
// 输出: 李小美家长 觉得合适~ (孙小拽 已经满足要求)
从这个例子就已经可以看出中介者模式的优点了,因为各对象之间的相互引用关系被解耦,从而令系统的可扩展性、可维护性更好。
3. 中介者模式的通用实现
对于上面的例子,张小帅、李小美、孙小拽和他们的家长们相当于容易产生耦合的对象(最早的一本设计模式书上将这些对象称为同事,这里也借用一下这个称呼,Colleague),而媒人就相当于中介者(Mediator)。在中介者模式中,同事对象之间互相不通信,而只与中介者通信,同事对象只需知道中介者即可。主要有以下几个概念:
- Colleague: 同事对象,只知道中介者而不知道其他同事对象,通过中介者来与其他同事对象通信;
- Mediator: 中介者,负责与各同事对象的通信;
结构图如下:
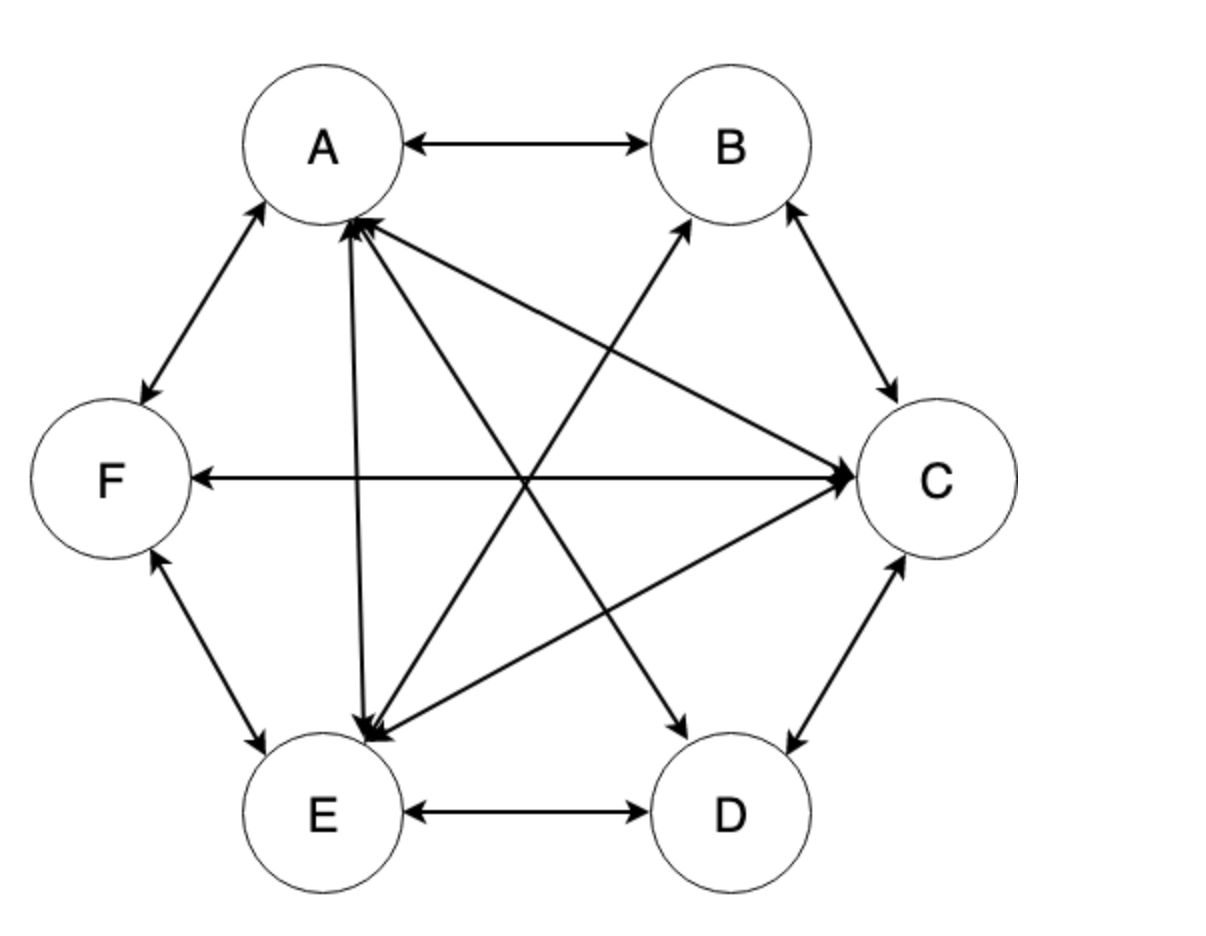
可以看到上图,使用中介者模式之后同事对象间的网状结构变成了星型结构,同事对象之间不需要知道彼此,符合最少知识原则。如果同事对象之间需要相互通信,只能通过中介者的方式,这样让同事对象之间原本的强耦合变成弱耦合,强相互依赖变成弱相互依赖,从而让这些同事对象可以独立地改变和复用。原本同事对象间的交互逻辑被中介者封装起来,各个同事对象只需关心自身即可。
4. 中介者模式的优缺点
中介者模式的主要优点有:
- 松散耦合,降低了同事对象之间的相互依赖和耦合,不会像之前那样牵一发动全身;
- 将同事对象间的一对多关联转变为一对一的关联,符合最少知识原则,提高系统的灵活性,使得系统易于维护和扩展;
- 中介者在同事对象间起到了控制和协调的作用,因此可以结合代理模式那样,进行同事对象间的访问控制、功能扩展;
- 因为同事对象间不需要相互引用,因此也可以简化同事对象的设计和实现;
主要缺点是:
- 逻辑过度集中化,当同事对象太多时,中介者的职责将很重,逻辑变得复杂而庞大,以至于难以维护。
当出现中介者可维护性变差的情况时,考虑是否在系统设计上不合理,从而简化系统设计,优化并重构,避免中介者出现职责过重的情况。
5. 中介者模式的适用场景
- 中介者模式适用多个对象间的关系确实已经紧密耦合,且导致扩展、维护产生了困难的场景,也就是当多个对象之间的引用关系变成了网状结构的时候,此时可以考虑使用引入中介者来把网状结构转化为星型结构。
- 但是,如果对象之间的关系耦合并不紧密,或者之间的关系本就一目了然,那么引入中介者模式就是多此一举、画蛇添足。
- 实际上,我们通常使用的
MVC/MVVM框架,就含有中介者模式的思想,Controller/ViewModel层作为中介者协调View/Model进行工作,减少View/Model之间的直接耦合依赖,从而做到视图层和数据层的最大分离。可以关注后面有单独一章分析MVC/MVVM模式,深入了解。
6. 其他相关模式 6.1 中介者模式和外观模式
外观模式和中介者模式思想上有一些相似的地方,但也有不同:
- 中介者模式 将多个平等对象之间内部的复杂交互关系封装起来,主要目的是为了多个对象之间的解耦;
- 外观模式 封装一个子系统内部的模块,是为了向系统外部提供方便的调用;
6.2 中介者模式与发布-订阅模式
- 中介者模式和发布-订阅模式都可以用来进行对象间的解耦,比如发布-订阅模式的发布者/订阅者和中介者模式里面的中介者/同事对象功能上就比较类似。
- 这两个模式也可以组合使用,比如中介者模式就可以使用发布-订阅模式,对相关同事对象进行消息的广播通知。
- 比如上面相亲的例子中,注册各方和通知信息就使用了发布-订阅模式。
6.3 中介者模式与代理模式
同事对象之间需要通信的时候,需要经由中介者,这时中介者就相当于同事对象间的代理。所以这时就可以引入代理模式的概念,对同事对象相互访问的时候,起到访问控制、功能扩展等等功能。
# 五、其他模式
# MVC、MVP、MVVM
在下文中,如果某些内容和你看的某本书或者某个帖子上的不一样,不要惊慌,多看几本书,多打开几个帖子,你会发现每个都不一样,所以模式具体是如何表现并不重要,重要的是,了解这三个模式主要的目的和思想是什么:
MVC模式: 从大锅烩时代进化,引入了分层的概念,但是层与层之间耦合明显,维护起来不容易;MVP模式: 在 MVC 基础上进一步解耦,视图层和模型层完全隔离,交互只能通过管理层来进行,问题是更新视图需要管理层手动来进行;MVVM模式: 引入双向绑定机制,帮助实现一些更新视图层和模型层的工作,让开发者可以更专注于业务逻辑,相比于之前的模式,可以使用更少的代码量完成更复杂的交互; MVC、MVP、MVVM 模式是我们经常遇到的概念,其中 MVVM 是最常用到的,在实际项目中往往没有严格按照模式的定义来设计的系统,开发中也不一定要纠结自己用的到底是哪个模式,合适的才是最好的。
1. MVC (Model View Controller)
MVC模式将程序分为三个部分:模型(Model)、视图(View)、控制器(Controller)。
Model模型层: 业务数据的处理和存储,数据更新后更新;View视图层: 人机交互接口,一般为展示给用户的界面;Controller控制器层 : 负责连接Model层和View层,接受并处理View层触发的事件,并在Model层的数据状态变动时更新View层;MVC模式的目的是通过引入Controller层来将Model层和View层分离,分层的引入是原来大锅烩方式的改进,使得系统在可维护性和可读性上有了进步。MVC模式提出已经有四十余年,MVC模式在各个书、各个教程、WIKI的解释有各种版本,甚至MVC模式在不同系统中的具体表现也不同,这里只介绍典型MVC模式的思路。
典型思路是
View层通过事件通知到Controller层,Controller层经过对事件的处理完成相关业务逻辑,要求Model层改变数据状态,Model层再将新数据更新到View层。示意图如下:
在实际操作时,用户可以直接对
View层的UI进行操作,以通过事件通知Controller层,经过处理后修改Model层的数据,Model层使用最新数据更新View。示意图如下:
用户也可以直接触发 Controller 去更新 Model 层状态,再更新 View 层:
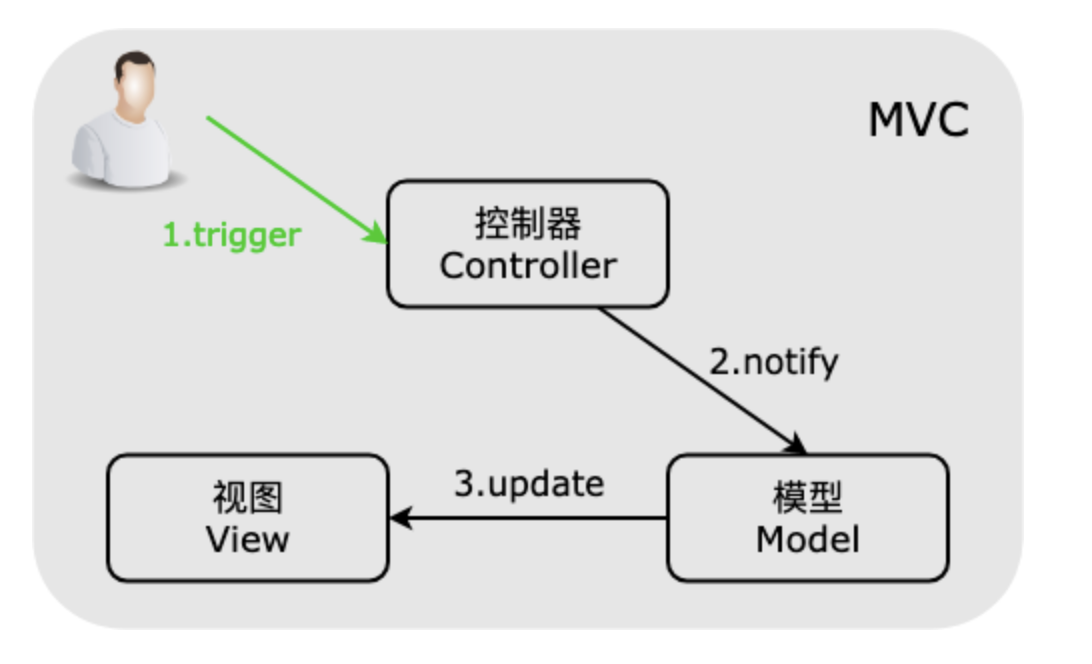
某些场景下,
View层直接采用观察者/发布订阅模式监听Model层的变化,这样View层和Model层相互持有、相互操作,导致紧密耦合,在可维护性上有待提升。由此,MVP模式应运而生 。
2. MVP (Model View Presenter)
MVP模式将程序分为三个部分:模型(Model)、视图(View)、管理层(Presenter)。
Model模型层: 只负责存储数据,与View呈现无关,也与UI处理逻辑无关,发生更新也不用主动通知View;View视图层: 人机交互接口,一般为展示给用户的界面;Presenter管理层 : 负责连接Model层和View层,处理View层的事件,负责获取数据并将获取的数据经过处理后更新View;MVC模式的View层和Model层存在耦合,为了解决这个问题,MVP模式将View层和Model层解耦,之间的交互只能通过Presenter层,实际上,MVP模式的目的就是将View层和 Model 层完全解耦,使得对View层的修改不会影响到Model层,而对Model层的数据改动也不会影响到View层。
典型流程是
View层触发的事件传递到Presenter层中处理,Presenter层去操作Model层,并且将数据返回给View层,这个过程中,View层和Model层没有直接联系。而View层不部署业务逻辑,除了展示数据和触发事件之外,其它时间都在等着Presenter层来更新自己,被称为「被动视图」。
示意图如下:
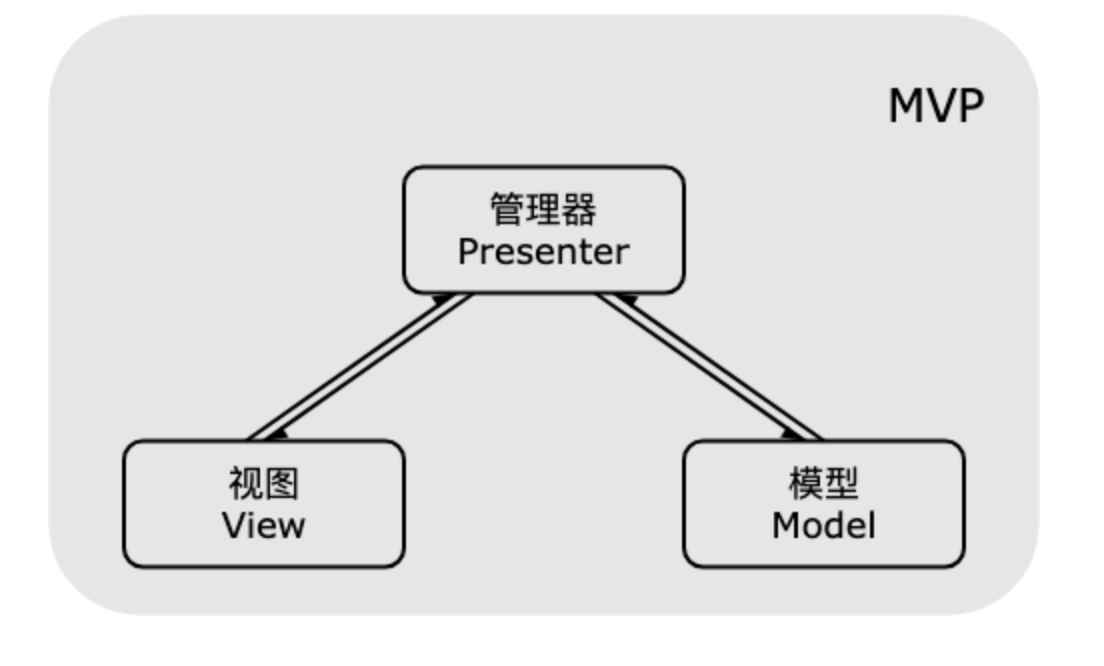
在实际操作时,用户可以直接对
View层的UI进行操作,View层通知Presenter层,Presenter层操作Model层的数据,Presenter层获取到数据之后更新View。示意图如下:
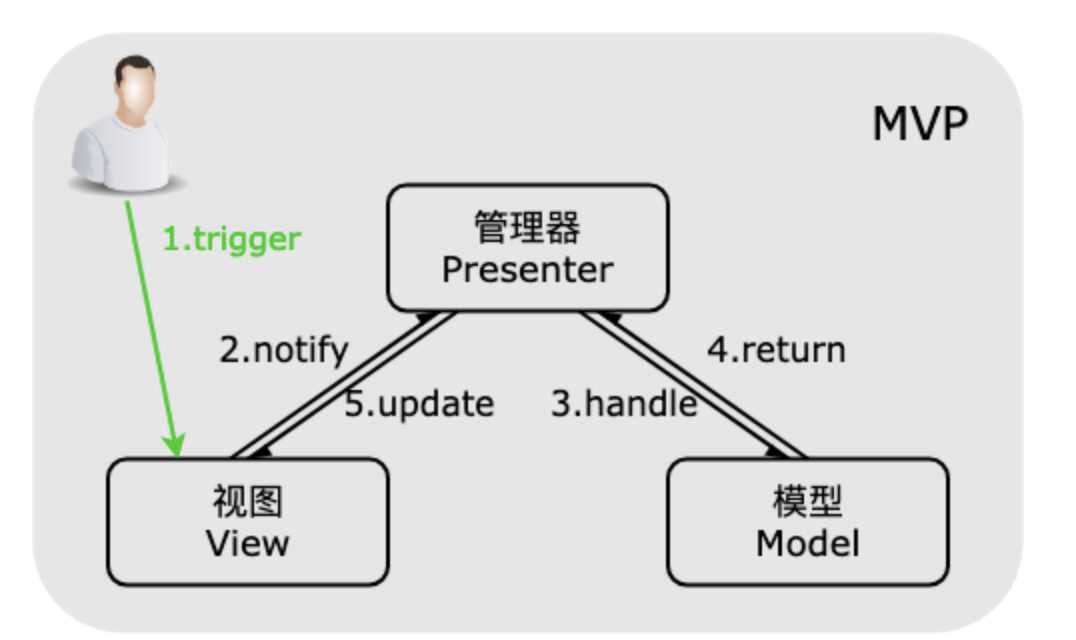
- 由于
Presenter层负责了数据获取、数据处理、交互逻辑、UI效果等等功能,所以Presenter层就变得强大起来,相应的,Model层只负责数据存储,而View层只负责视图,Model和View层的责任纯粹而单一,如果我们需要添加或修改功能模块,只需要修改Presenter层就够了。由于Presenter层需要调用View层的方法更新视图,Presenter层直接持有View层导致了Presenter对View的依赖。
正如上所说,更新视图需要
Presenter层直接持有View层,并通过调用View层中的方法来实现,还是需要一系列复杂操作,有没有什么机制自动去更新视图而不用我们手动去更新呢,所以,MVVM模式应运而生。
3. MVVM (Model View ViewModel)
MVVM模式将程序分为三个部分:模型(Model)、视图(View)、视图模型(View-Model)。
和 MVP 模式类似,Model 层和 View 层也被隔离开,彻底解耦,ViewModel 层相当于 Presenter 层,负责绑定 Model 层和 View 层,相比于 MVP 增加了双向绑定机制。
结构图如下:
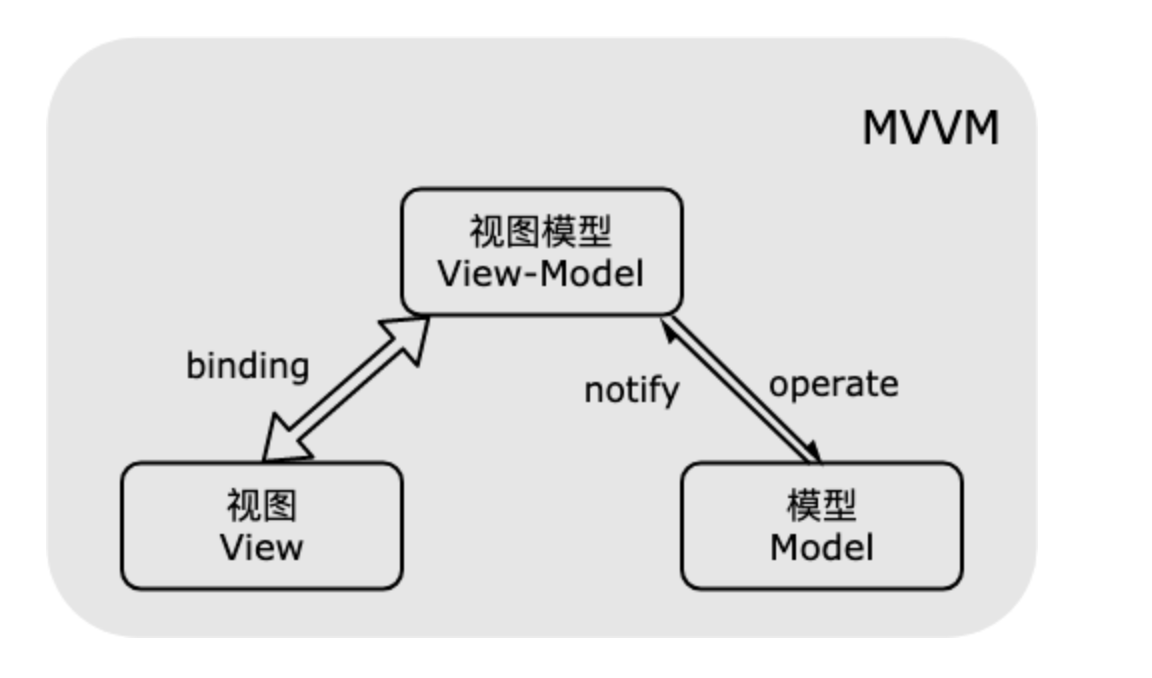
MVVM模式的特征是ViewModel层和View层采用双向绑定的形式(Binding),View层的变动,将自动反映在ViewModel层,反之亦然。
- 但是双向绑定给调试和错误定位带来困难,
View层的异常可能是View的代码有问题,也有可能是Model层的问题。数据绑定使得一个位置的Bug被传递到别的位置,要定位原始出问题的地方就变得不那么容易了。 - 对简单
UI来说,实现MVVM模式的开销是不必要的,而对于大型应用来说,引入 MVVM 模式则会节约大量手动更新视图的复杂过程,是否使用,还是看使用场景。 Vue的双向绑定机制应该算是比较有MVVM模式的影子,但Vue文档 里面是这么描述:
这是为什么呢,因为
MVVM模式要求Model层和View层完全解耦,但是由于Vue还提供了ref这样的API,使得Model也可以直接持有View:
但是大多数帖子都说直接称呼 Vue 为 MVVM 框架,可见这些模式的划分也不是那么严格。
# 模块模式
模块是任何健壮的应用程序体系结构不可或缺的一部分,特点是有助于保持应用项目的代码单元既能清晰地分离又有组织,下面我们来看看各种不同的模块模式解决方案。
1. 模块模式 1.1 命名空间模式
命名空间模式是一个简单的模拟模块的方法,即创建一个全局对象,然后将变量和方法添加到这个全局对象中,这个全局对象是作为命名空间一样的角色。
var MYNS = {}
MYNS.param1 = 'hello'
MYNS.param2 = 'world'
MYNS.param3 = { prop: 'name' }
MYNS.method1 = function() {
//...
}
这种方式可以隐藏系统中的变量冲突,但是也有一些缺点,比如:
- 命名空间如果比较复杂,调用可能就会变成 MYNS.param.prop.data... 长长一溜,使用不便且增加代码量;
- 变量嵌套关系越多,属性解析的性能消耗就越多;
- 安全性不佳,所有的成员都可以被访问到;
1.2 模块模式
除了命名空间模式,也可以使用闭包的特性来模拟实现私有成员的功能来提升安全性,这里可以通过 IIFE 快速创建一个闭包,将要隐藏的变量和方法放在闭包中,这就是模块模式。
var myModule = (function() {
var privateProp = '' // 私有变量
var privateMethod = function() { // 私有方法
console.log(privateProp)
}
return {
publicProp: 'foo', // 公有变量
publicMethod: function(prop) { // 共有方法
privateProp = prop
privateMethod()
}
}
})()
myModule.publicMethod('new prop') // 输出:new prop
myModule.privateProp // Uncaught TypeError: myModule.privateMethod is not a function
myModule.privateProp // undefined
- 这里的私有变量和私有方法,在闭包外面无法访问到,称为私有成员。而闭包返回的方法因为作用域的原因可以访问到私有成员,所以称为特权方法。
- 值得一提的是,在模块模式创建时,可以将参数传递到闭包中,以更自由地创建模块,也可以方便地将全局变量传入模块中,导入全局变量有助于加速即时函数中的全局符号解析的速度,因为导入的变量成了该函数的局部变量。
var myModule = (function(opt, global) {
// ...
})(options, this)
1.3 揭示模块模式
在上面的模块模式例子上稍加改动,可以得到揭示模块模式(Reveal Module Pattern),又叫暴露模块模式,在私有域中定义我们所有的函数和变量,并且返回一个匿名对象,把想要暴露出来的私有成员赋值给这个对象,使这些私有成员公开化。
var myModule = (function() {
var privateProp = ''
var printProp = function() {
console.log(privateProp)
}
function setProp(prop) {
privateProp = prop
printProp()
}
return {
print: printProp,
set: setProp
}
})()
myModule.set('new prop') // 输出:new prop
myModule.setProp() // Uncaught TypeError: myModule.setProp is not a function
myModule.privateProp // undefined
揭示模块暴露出来的私有成员可以在被重命名后公开访问,也增强了可读性。
2. ES6 module
继社区提出的
CommonJS和AMD之类的方案之后,从ES6开始,JavaScript就支持原生模块(module)了,下面我们一起来简单看一下ES6的module
ES6 的 module 功能主要由两个命令组成 export、import,export 用于规定模块对外暴露的接口,import 用于输入其他模块提供的接口,简单来说就是一个作为输出、一个作为输入。
// 1.js
// 写法一
export var a = 'a'
// 写法二
var b = 'b'
export { b }
// 写法三
var c = 'c'
export { c as e }
引入时:
// 2.js
import { a } from './1.js' // 写法一
import { b as f } from './1.js' // 写法二
import { e } from './1.js' // 写法二
从前面的例子可以看出,使用
import时,用户需要知道所要加载的变量名或函数名,否则无法加载,export default方式提供了模块默认输出的形式,给用户提供了方便:
// 3.js
// 写法一
export default function () {
console.log('foo')
}
// 写法二
function foo() {
console.log('foo')
}
export default foo
// 写法三
function foo(x, y) {
console.log('foo')
}
export {add as default}
// 写法四
export default 42
引入时:
// 4.js
import bar from './3.js' // 写法一
bar()
// 输出:foo
import { default as bar } from './3.js' // 写法二
bar()
// 输出:foo
值得一提的是
export、import都必须写在模块顶层,如果处于块级作用域内,就会报错,因为处于条件代码块之中,就没法做静态优化了,违背了ES6模块的设计初衷。
function foo() {
export default 'bar' // SyntaxError
}
foo()
}
# 链模式
通常情况下,通过对构造函数使用
new会返回一个绑定到this上的新实例,所以我们可以在new出来的对象上直接用 . 访问其属性和方法。如果在普通函数中也返回当前实例,那么我们就可以使用 . 在单行代码中一次性连续调用多个方法,就好像它们被链接在一起一样,这就是链式调用,又称链模式。
之前建造者模式、组合模式等文章已经用到了链模式,日常使用的 jQuery、Promise 等也使用了链模式,我们对使用形式已经很熟悉了,下面一起来看看链模式的原理。
1. 什么是链模式 1.1 链模式的实现
在 jQuery 时代,下面这样的用法我们很熟悉了:
// 使用链模式
$('div')
.show()
.addClass('active')
.height('100px')
.css('color', 'red')
.on('click', function(e) {
// ...
})
这就是很典型的链模式,对 jQuery 选择器选择的元素从上到下依次进行一系列操作,如果不使用链模式,则代码如下:
// 不使用链模式
var divEls = $('div')
divEls.show()
divEls.addClass('active')
divEls.height('100px')
divEls.css('color', 'red')
divEls.on('click', function(e) {
// ...
})
- 可以看到不使用链模式,代码量多了,代码结构也复杂了不少。链模式是 jQuery 的一个重要特性,也是 jQuery 深受大家喜爱,并且经久不衰的原因之一。
- 链模式和一般的函数调用的区别在于:链模式一般会在调用完方法之后返回一个对象,有时则直接返回 this ,因此又可以继续调用这个对象上的其他方法,这样可以对同一个对象连续执行多个方法。
比如这里我们可以自己实现一个链模式:
/* 四边形 */
var rectangle = {
length: null, // 长
width: null, // 宽
color: null, // 颜色
getSize: function() {
console.log(`length: ${ this.length }, width: ${ this.width }, color: ${ this.color }`)
},
/* 设置长度 */
setLength: function(length) {
this.length = length
return this
},
/* 设置宽度 */
setWidth: function(width) {
this.width = width
return this
},
/* 设置颜色 */
setColor: function(color) {
this.color = color
return this
}
}
var rect = rectangle
.setLength('100px')
.setWidth('80px')
.setColor('blue')
.getSize()
// 输出:length: 100px, width: 80px, color: blue
由于所有对象都会继承其原型对象的属性和方法,所以我们可以让原型方法都返回该原型的实例对象,这样就可以对那些方法进行链式调用了:
/* 四边形 */
function Rectangle() {
this.length = null // 长
this.width = null // 宽
this.color = null // 颜色
}
/* 设置长度 */
Rectangle.prototype.setLength = function(length) {
this.length = length
return this
}
/* 设置宽度 */
Rectangle.prototype.setWidth = function(width) {
this.width = width
return this
}
/* 设置颜色 */
Rectangle.prototype.setColor = function(color) {
this.color = color
return this
}
var rect = new Rectangle()
.setLength('100px')
.setWidth('80px')
.setColor('blue')
console.log(rect)
// 输出:{length: "100px", width: "80px", color: "blue"}
使用 Class 语法改造一下:
/* 四边形 */
class Rectangle {
constructor() {
this.length = null // 长
this.width = null // 宽
this.color = null // 颜色
}
/* 设置长度 */
setLength(length) {
this.length = length
return this
}
/* 设置宽度 */
setWidth(width) {
this.width = width
return this
}
/* 设置颜色 */
setColor(color) {
this.color = color
return this
}
}
const rect = new Rectangle()
.setLength('100px')
.setWidth('80px')
.setColor('blue')
console.log(rect)
// 输出:{length: "100px", width: "80px", color: "blue"}
1.2 链模式不一定必须返回 this
不一定在方法中
return this,也可以返回其他对象,这样后面的方法可以对这个新对象进行其他操作。比如在Promise的实现中,每次then方法返回的就不是this,而是一个新的Promise,只不过其外观一样,所以我们可以不断then下去。后面的每一个then都不是从最初的Promise实例点出来的,而是从前一个then返回的新的Promise实例点出来的。
const prom1 = new Promise((resolve, reject) => {
setTimeout(() => {
console.log('Promise 1 resolved')
resolve()
}, 500)
})
const prom2 = prom1.then(() => {
console.log('Then method')
})
console.log(prom1 === prom2)
// 输出: false
jQuery 中有一个有意思的方法
end(),是将匹配的元素还原为之前一次的状态,此时返回的也不是this,然后可以在返回的之前一次匹配的状态后继续进行链模式:
// html: <p><span>Hello</span>,how are you?</p>
$("p") // 选择所有 p 标签
.find("span") // 选择了 p 标签下的 span 标签
.css('color', 'red')
.end() // 返回之前匹配的 p 标签
.css('color', 'blue')
事实上,某些原生的方法就可以使用链模式,以数组操作为例,比如我们想查看一个数组中奇数的平方和:
[1, 2, 3, 4, 5, 6]
.filter(num => num % 2)
.map(num => num * num)
.reduce((pre, curr) => pre + curr, 0)
// 输出 35
那么这里为什么可以使用链模式呢,是因为
filter、map、reduce这些数组方法返回的仍然是数组,因此可以继续在后面调用数组的方法。
注意,并不是所有数组方法都返回数组,比如 push 的时候返回的是新数组的 length 属性。
2. 实战使用链模式
有时候 JavaScript 原生提供的方法不太好用,比如我们希望创建下面这样一个 DOM 树结构:
<ul id='data-list'>
<li class='data-item'>li-item 1</li>
<li class='data-item'>li-item 2</li>
<li class='data-item'>li-item 3</li>
</ul>
如果使用原生方法,由于
setAttribute等方法并没有返回原对象,而appendChild方法返回的却是,我们需要:
const ul = document.createElement('ul')
ul.setAttribute('id', 'data-list')
const li1 = document.createElement('li')
const li2 = document.createElement('li')
const li3 = document.createElement('li')
li1.setAttribute('id', 'data-item')
li2.setAttribute('id', 'data-item')
li3.setAttribute('id', 'data-item')
const text1 = document.createTextNode('li-item 1')
const text2 = document.createTextNode('li-item 2')
const text3 = document.createTextNode('li-item 3')
li1.appendChild(text1)
li2.appendChild(text2)
li3.appendChild(text3)
ul.appendChild(li1)
ul.appendChild(li2)
ul.appendChild(li3)
太不直观了,步骤零散且可维护性差。
这里我们可以彻底使用链模式来改造一下原生方法:
const createElement = function(tag) {
return tag === 'text'
? document.createTextNode(tag)
: document.createElement(tag)
}
HTMLElement.prototype._setAttribute = function(key, value) {
this.setAttribute(key, value)
return this
}
HTMLElement.prototype._appendChild = function(child) {
this.appendChild(child)
return this
}
createElement('ul')
._setAttribute('id', 'data-list')
._appendChild(
createElement('li')
._setAttribute('class', 'data-item')
._appendChild('text', 'li-item 1'))
._appendChild(
createElement('li')
._setAttribute('class', 'data-item')
._appendChild('text', 'li-item 2'))
._appendChild(
createElement('li')
._setAttribute('class', 'data-item')
._appendChild('text', 'li-item 3'))
这样就比较彻底地使用了链模式来生成
DOM结构树了,你可能感觉有点奇怪,但是如果你使用过vue-cli3,那么你可能对这个配置方式很熟悉。
3. 源码中的链模式 3.1 jQuery 中的链模式 1. jQuery 构造函数
jQuery 方法看似复杂,可以简写如下:
var jQuery = function(selector, context) {
// jQuery 方法返回的是 jQuery.fn.init 所 new 出来的对象
return new jQuery.fn.init(selector, context, rootjQuery)
}
jQuery.fn = jQuery.prototype = {
constructor: jQuery,
// jQuery 对象的构造函数
init: function(selector, context, rootjQuery) {
// ... 一顿匹配操作,返回一个拼装好的伪数组的自身实例
// 是 jQuery.fn.init 的实例,也就是我们常用的 jQuery 对象
return this
},
selector: '',
eq: function() { ... },
end: function() { ... },
map: function() { ... },
last: function() { ... },
first: function() { ... },
// ... 其他方法
}
// jQuery.fn.init 的实例都拥有 jQuery.fn 相应的方法
jQuery.fn.init.prototype = jQuery.fn
// 此处源码位于 src/core.js
return new jQuery.fn.init(...)这句看似复杂,其实也就是下面的这个init方法,这个方法最后返回的是我们常用的jQuery对象,下面还有一句jQuery.fn.init.prototype = jQuery.fn,因此最上面的jQuery方法返回的new出来的jQuery.fn.init实例将继承jQuery.fn` 上的方法:
const p = $("<p/>")
$.fn === p.__proto__ // true
因此返回出来的实例也将继承
eq、end、map、last等jQuery.fn上的方法。
2. jQuery 实例方法
下面我们一起看看,
show、hide、toggle这些方法是如何实现链模式的呢 :
jQuery.fn.extend({
show: function() {
var elem
for (i = 0; i < this.length; i++) {
// ...
elem = this[i]
if (elem.style.display === 'none') {
elem.style.display = 'block'
}
}
return this
},
hide: function() { ... },
toggle: function() { ... }
})
这里首先使用了一个方法
jQuery.fn.extend(),简单看一下这个方法做啥的:
jQuery.extend = jQuery.fn.extend = function(options) {
// ... 一系列啰啰嗦嗦的判断
for (name in options) {
this[name] = options[ name ] // 此处 this === jQuery.fn
}
}
// 此处源码位于 src/core.js
- 这个方法就是把传参的对象的值赋值给
jQuery.fn,因为这时候这个方法是通过上下文对象jQuery.fn.extend()方式来调用,属于隐式绑定。(对this绑定规则的同学参看本专栏第 2 篇文章) - 以
show方法为例,此时这个方法被赋到jQuery.fn对象上,而通过上文我们知道,jQuery.fn.init.prototype = jQuery.fn,而jQuery.fn.init这个方法是作为构造函数被jQuery函数new出来并返回,因此 show 方法此时可以被jQuery.fn.init实例访问到,也就可以被$('selector')访问到,因此此时我们已经可以:$('p').show()了。 - 那么我们再回头来看看
show方法的实现,show方法将匹配的元素的display置为block之后返回了this。注意了,此时的this也是隐式绑定,而且是通过$('p')点出来的,因此返回的值就是$('p')的引用。 - 经过以上步骤,我们知道
show方法返回的仍然是$('p')的引用,我们可以继续在之后点出来其他jQuery.fn对象上的方法,css、hide、toggle、addClasson等等方法同理,至此,jQuery` 的链模式就形成了。
3.2 Underscore 中的链模式
- 如果你用过
Underscore,那么你可能知道Underscore提供的一个链模式实现_.chain。通过这个方法,可以方便地使用Underscore提供的一些方法链模式地对数据进行处理。另外,Lodash的chain实现和Underscore的基本一样,可以自行去Lodash的 GitHub 仓库阅读。 - 比如这里我们需要对一个用户对象数组进行一系列操作,首先按年龄排序,去掉年龄为奇数的人,再将这些用户的名字列成数组:
var users = [
{ 'name': 'barney', 'age': 26 },
{ 'name': 'fred', 'age': 21 },
{ 'name': 'pebbles', 'age': 28 },
{ 'name': 'negolas', 'age': 23 }
]
_.chain(users)
.sortBy('age')
.reject(user => user.age % 2)
.map(user => user.name)
.value()
// 输出: ["barney", "pebbles"]
经过
_.chain方法处理后,就可以使用Underscore提供的其他方法对这个数据进行操作,下面一起来看看源码是如何实现链模式。
首先是
_.chain方法:
_.chain = function(obj) {
var instance = _(obj) // 获得一个经 underscore 包裹后的实例
instance._chain = true // 标记是否使用链式操作
return instance
}
此处源码位于
underscore.js#L1615-L1619
这里通过
_(obj)的方式把数据进行了包装,并返回了一个对象,结构如下:
{
_chain: true,
_wrapped: [...],
__proto__: ...
}
返回的对象的隐式原型可以访问到
Undersocre提供的很多方法,如下图:
这个
chain方法的作用就是创建一个包裹了obj的Underscore实例对象,并标记该实例是使用链模式,最后返回这个包装好的链式化实例(叫链式化是因为可以继续调用underscore上的方法)。
我们一起看看 sort 方法是如何实现的:
var chainResult = function (instance, obj) {
return instance._chain ? _(obj).chain() : obj; // 这里 _chain 为 true
};
_.each(['pop', 'push', 'reverse', 'shift', 'sort', 'splice', 'unshift'], function(name) {
var method = Array.prototype[name];
_.prototype[name] = function() {
var obj = this._wrapped;
method.apply(obj, arguments); // 执行方法
return chainResult(this, obj);
};
});
此处源码位于
underscore.js#L1649-L1657
sort方法执行之后,把结果重新放在_wrapped里,并执行chainResult方法,这个方法里由于_chain之前已经置为true,因此会继续对结果调用chain()方法,包装成链式化实例并返回。- 最后的这个
_.value方法比较简单,就是返回链式化实例的_wrapped值:
_.prototype.value = function() {
return this._wrapped;
};
此处源码位于
underscore.js#L1668-L1670
总结一下,只要一开始调用了
chain方法,_chain这个标志位就会被置为true,在类似的方法中,返回的值都用chainResult包裹一遍,并判断这个_chain这个标志位,为true则返回链式化实例,供给下一次方法调用,由此形成了链式化调用
# 中间件
中间件 (Middleware),又称中介层,是提供系统软件和应用软件之间连接的软件,以便于软件各部件之间的沟通,特别是应用软件对于系统软件的集中的逻辑。中间件在企业架构中表示各种软件套件,有助于抽象底层机制,比如操作系统 API、网络通信、内存管理等,开发者只需要关注应用中的业务模块。
从更广义的角度来看,中间件也可以定义为链接底层服务和应用的软件层。后文我们主要使用 Node.js 里最近很热门的框架 Koa2 里的中间件概念为例,并且自己实现一个中间件来加深理解。
1. 什么是中间件
- 在
Express、Koa2中,中间件代表一系列以管道形式被连接起来,以处理HTTP请求和响应的函数。换句话说,中间件其实就是一个函数,一个执行特定逻辑的函数。前端中类似的概念还有拦截器、Vue中的过滤器、vue-router中的路由守卫等。 - 工作原理就是进入具体业务之前,先对其进行预处理(在这一点上有点类似于装饰器模式),或者在进行业务之后,对其进行后处理。
示意图如下:

当接受到一个请求,对这个请求的处理过程可以看作是一个串联的管道,比如对于每个请求,我们都想插入一些相同的逻辑比如权限验证、数据过滤、日志统计、参数验证、异常处理等功能。对于开发者而言,自然不希望对于每个请求都特殊处理,因此引入中间件来简化和隔离这些基础设施与业务逻辑之间的细节,让开发者能够关注在业务的开发上,以达到提升开发效率的目的。
2. Koa 里的中间件 2.1 Koa2 里的中间件使用
Koa2 中的中间件形式为:
app.use(async function middleware(context, next){
// ... 前处理
await next() // 下一个中间件
// ... 后处理
})
- 其中第一个参数
context作为上下文封装了request和response信息,我们可以通过它来访问request和response;next是下一个中间件,当一个中间件处理完毕,调用 next() 就可以执行下一个中间件,下一个中间件处理完- 再使用next(),从而实现中间件的管道化,对消息的依次处理。
一般中间件模式都约定有个
use方法来注册中间件,Koa2也是如此。千言万语不及一行代码,这里写一个简单的中间件:
const koa = require('koa')
const app = new koa()
app.use((ctx, next) => { // 没错,这就是中间件
console.log('in 中间件1')
})
app.listen(10001)
// 输出: in 中间件1
Koa2 中的中间件有多种类型:
- 应用级中间件;
- 路由级中间件;
- 错误处理中间件;
- 第三方中间件;
除了使用第三方中间件比如
koa-router、koa-bodyparser、koa-static、koa-logger等提供一些通用的路由、序列化、反序列化、日志记录等功能外,我们还可以编写自己的应用级中间件,来完成业务相关的逻辑。
通过引入各种功能各异的中间件,可以完成很多业务相关的功能:
equest和response的解析和处理;- 生成访问日志;
- 管理
session、cookie等; - 提供网络安全防护;
2.2 洋葱模型
在使用多个中间件时,引用一张著名的洋葱模型图:

正如上面的洋葱图所示,请求在进入业务逻辑时,会依次经过一系列中间件,对数据进行有序处理,业务逻辑之后,又像栈的先入后出一样,倒序经过之前的中间件。洋葱模型允许当应用执行完主要逻辑之后进行一些后处理,再将响应返回给用户。
使用如下:
const Koa = require('koa')
const app = new Koa()
// 中间件1
app.use(async (ctx, next) => {
console.log('in 中间件1')
await next()
console.log('out 中间件1')
})
// 中间件2
app.use(async (ctx, next) => {
console.log('in 中间件2')
await next()
console.log('out 中间件2')
})
// response
app.use(async ctx => { ctx.body = 'Hello World' })
app.listen(10001)
console.log('app started at port http://localhost:10001')
// 输出: in 中间件1
// 输出: in 中间件2
// 输出: out 中间件2
// 输出: out 中间件1
我们可以引入
setTimeout来模拟异步请求的过程:
const Koa = require('koa')
const app = new Koa()
// 中间件1
app.use(async (ctx, next) => {
console.log('in 中间件1')
await next()
console.log('out 中间件1')
})
// 中间件2
app.use(async (ctx, next) => {
console.log('in 中间件2')
await new Promise((resolve, reject) => {
ctx.zjj_start2 = Date.now()
setTimeout(() => resolve(), 1000 + Math.random() * 1000)
}
)
await next()
const duration = Date.now() - ctx.zjj_start2
console.log('out 中间件2 耗时:' + duration + 'ms')
})
// 中间件3
app.use(async (ctx, next) => {
console.log('in 中间件3')
await new Promise((resolve, reject) => {
ctx.zjj_start3 = Date.now()
setTimeout(() => resolve(), 1000 + Math.random() * 1000)
}
)
await next()
const duration = Date.now() - ctx.zjj_start3
console.log('out 中间件3 耗时:' + duration + 'ms')
})
// response
app.use(async ctx => {
console.log(' ... 业务逻辑处理过程 ... ')
})
app.listen(10001)
console.log('app started at port http://localhost:10001')
在使用多个中间件时,特别是存在异步的场景,一般要
await来调用next来保证在异步场景中,中间件仍按照洋葱模型的顺序来执行,因此别忘了next也要通过await调用。