# 一、前言
有同学问:能否详细说一下 diff 算法。
简单说:diff 算法是一种优化手段,将前后两个模块进行差异化比较,修补(更新)差异的过程叫做 patch,也叫打补丁。
详细的说,请阅读这篇文章,有疑问的地方欢迎联系「松宝写代码」一起讨论。
文章主要解决的问题:
- 1、为什么要说这个 diff 算法?
- 2、虚拟 dom 的 diff 算法
- 3、为什么使用虚拟 dom?
- 4、diff 算法的复杂度和特点?
- 5、vue 的模板文件是如何被编译渲染的?
- 6、vue2.x 和 vue3.x 中的 diff 有区别吗
- 7、diff 算法的源头 snabbdom 算法
- 8、diff 算法与 snabbdom 算法的差异地方?
# 二、为什么要说这个 diff 算法?
因为 diff 算法是 vue2.x , vue3.x 以及 react 中关键核心点,理解 diff 算法,更有助于理解各个框架本质。
说到「diff 算法」,不得不说「虚拟 Dom」,因为这两个息息相关。
比如:
- vue 的响应式原理?
- vue 的 template 文件是如何被编译的?
- 介绍一下 Virtual Dom 算法?
- 为什么要用 virtual dom 呢?
- diff 算法复杂度以及最大的特点?
- vue2.x 的 diff 算法中节点比较情况?
等等
# 三、虚拟 dom 的 diff 算法
我们先来说说虚拟 Dom,就是通过 JS 模拟实现 DOM ,接下来难点就是如何判断旧对象和新对象之间的差异。
Dom 是多叉树结构,如果需要完整的对比两棵树的差异,那么算法的时间复杂度 O(n ^ 3),这个复杂度很难让人接收,尤其在 n 很大的情况下,于是 React 团队优化了算法,实现了 O(n) 的复杂度来对比差异。
实现 O(n) 复杂度的关键就是只对比同层的节点,而不是跨层对比,这也是考虑到在实际业务中很少会去跨层的移动 DOM 元素。
虚拟 DOM 差异算法的步骤分为 2 步:
- 首先从上至下,从左往右遍历对象,也就是树的深度遍历,这一步中会给每个节点添加索引,便于最后渲染差异
- 一旦节点有子元素,就去判断子元素是否有不同
# 3.1 vue 中 diff 算法
实际 diff 算法比较中,节点比较主要有 5 种规则的比较
- 1、如果新旧 VNode 都是静态的,同时它们的 key 相同(代表同一节点),并且新的 VNode 是 clone 或者是标记了 once(标记 v-once 属性,只渲染一次),那么只需要替换 elm 以及 componentInstance 即可。
- 2、新老节点均有 children 子节点,则对子节点进行 diff 操作,调用 updateChildren,这个 updateChildren 也是 diff 的核心。
- 3、如果老节点没有子节点而新节点存在子节点,先清空老节点 DOM 的文本内容,然后为当前 DOM 节点加入子节点。
- 4、当新节点没有子节点而老节点有子节点的时候,则移除该 DOM 节点的所有子节点。
- 5、当新老节点都无子节点的时候,只是文本的替换
function patchVnode(oldVnode, vnode, insertedVnodeQueue, ownerArray, index, removeOnly) {
if (oldVnode === vnode) {
return;
}
if (isDef(vnode.elm) && isDef(ownerArray)) {
// clone reused vnode
vnode = ownerArray[index] = cloneVNode(vnode);
}
const elm = (vnode.elm = oldVnode.elm);
if (isTrue(oldVnode.isAsyncPlaceholder)) {
if (isDef(vnode.asyncFactory.resolved)) {
hydrate(oldVnode.elm, vnode, insertedVnodeQueue);
} else {
vnode.isAsyncPlaceholder = true;
}
return;
}
if (
isTrue(vnode.isStatic) &&
isTrue(oldVnode.isStatic) &&
vnode.key === oldVnode.key &&
(isTrue(vnode.isCloned) || isTrue(vnode.isOnce))
) {
vnode.componentInstance = oldVnode.componentInstance;
return;
}
let i;
const data = vnode.data;
if (isDef(data) && isDef((i = data.hook)) && isDef((i = i.prepatch))) {
i(oldVnode, vnode);
}
const oldCh = oldVnode.children;
const ch = vnode.children;
if (isDef(data) && isPatchable(vnode)) {
for (i = 0; i < cbs.update.length; ++i) cbs.update[i](oldVnode, vnode);
if (isDef((i = data.hook)) && isDef((i = i.update))) i(oldVnode, vnode);
}
if (isUndef(vnode.text)) {
// 定义了子节点,且不相同,用diff算法对比
if (isDef(oldCh) && isDef(ch)) {
if (oldCh !== ch) updateChildren(elm, oldCh, ch, insertedVnodeQueue, removeOnly);
// 新节点有子元素。旧节点没有
} else if (isDef(ch)) {
if (process.env.NODE_ENV !== 'production') {
// 检查key
checkDuplicateKeys(ch);
}
// 清空旧节点的text属性
if (isDef(oldVnode.text)) nodeOps.setTextContent(elm, '');
// 添加新的Vnode
addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue);
// 如果旧节点的子节点有内容,新的没有。那么直接删除旧节点子元素的内容
} else if (isDef(oldCh)) {
removeVnodes(oldCh, 0, oldCh.length - 1);
// 如上。只是判断是否为文本节点
} else if (isDef(oldVnode.text)) {
nodeOps.setTextContent(elm, '');
}
// 如果文本节点不同,替换节点内容
} else if (oldVnode.text !== vnode.text) {
nodeOps.setTextContent(elm, vnode.text);
}
if (isDef(data)) {
if (isDef((i = data.hook)) && isDef((i = i.postpatch))) i(oldVnode, vnode);
}
}
# 3.2 React diff 算法
在 reconcileChildren 函数的入参中
workInProgress.child = reconcileChildFibers(
workInProgress,
current.child,
nextChildren,
renderLanes,
);
- workInProgress:作为父节点传入,新生成的第一个 fiber 的 return 会被指向它。
- current.child:旧 fiber 节点,diff 生成新 fiber 节点时会用新生成的 ReactElement 和它作比较。
- nextChildren:新生成的 ReactElement,会以它为标准生成新的 fiber 节点。
- renderLanes:本次的渲染优先级,最终会被挂载到新 fiber 的 lanes 属性上。
diff 的两个主体是:oldFiber(current.child)和 newChildren(nextChildren,新的 ReactElement),它们是两个不一样的数据结构。
部分源码
function reconcileChildrenArray(
returnFiber: Fiber,
currentFirstChild: Fiber | null,
newChildren: Array<*>,
lanes: Lanes,
): Fiber | null {
/* * returnFiber:currentFirstChild的父级fiber节点
* currentFirstChild:当前执行更新任务的WIP(fiber)节点
* newChildren:组件的render方法渲染出的新的ReactElement节点
* lanes:优先级相关
* */
// resultingFirstChild是diff之后的新fiber链表的第一个fiber。
let resultingFirstChild: Fiber | null = null;
// resultingFirstChild是新链表的第一个fiber。
// previousNewFiber用来将后续的新fiber接到第一个fiber之后
let previousNewFiber: Fiber | null = null;
// oldFiber节点,新的child节点会和它进行比较
let oldFiber = currentFirstChild;
// 存储固定节点的位置
let lastPlacedIndex = 0;
// 存储遍历到的新节点的索引
let newIdx = 0;
// 记录目前遍历到的oldFiber的下一个节点
let nextOldFiber = null;
// 该轮遍历来处理节点更新,依据节点是否可复用来决定是否中断遍历
for (; oldFiber !== null && newIdx < newChildren.length; newIdx++) {
// newChildren遍历完了,oldFiber链没有遍历完,此时需要中断遍历
if (oldFiber.index > newIdx) {
nextOldFiber = oldFiber;
oldFiber = null;
} else {
// 用nextOldFiber存储当前遍历到的oldFiber的下一个节点
nextOldFiber = oldFiber.sibling;
}
// 生成新的节点,判断key与tag是否相同就在updateSlot中
// 对DOM类型的元素来说,key 和 tag都相同才会复用oldFiber
// 并返回出去,否则返回null
const newFiber = updateSlot(returnFiber, oldFiber, newChildren[newIdx], lanes);
// newFiber为 null说明 key 或 tag 不同,节点不可复用,中断遍历
if (newFiber === null) {
if (oldFiber === null) {
// oldFiber 为null说明oldFiber此时也遍历完了
// 是以下场景,D为新增节点
// 旧 A - B - C
// 新 A - B - C - D oldFiber = nextOldFiber;
}
break;
}
if (shouldTrackSideEffects) {
// shouldTrackSideEffects 为true表示是更新过程
if (oldFiber && newFiber.alternate === null) {
// newFiber.alternate 等同于 oldFiber.alternate
// oldFiber为WIP节点,它的alternate 就是 current节点
// oldFiber存在,并且经过更新后的新fiber节点它还没有current节点,
// 说明更新后展现在屏幕上不会有current节点,而更新后WIP
// 节点会称为current节点,所以需要删除已有的WIP节点
deleteChild(returnFiber, oldFiber);
}
}
// 记录固定节点的位置
lastPlacedIndex = placeChild(newFiber, lastPlacedIndex, newIdx);
// 将新fiber连接成以sibling为指针的单向链表
if (previousNewFiber === null) {
resultingFirstChild = newFiber;
} else {
previousNewFiber.sibling = newFiber;
}
previousNewFiber = newFiber;
// 将oldFiber节点指向下一个,与newChildren的遍历同步移动
oldFiber = nextOldFiber;
}
// 处理节点删除。新子节点遍历完,说明剩下的oldFiber都是没用的了,可以删除.
if (newIdx === newChildren.length) {
// newChildren遍历结束,删除掉oldFiber链中的剩下的节点
deleteRemainingChildren(returnFiber, oldFiber);
return resultingFirstChild;
}
// 处理新增节点。旧的遍历完了,能复用的都复用了,所以意味着新的都是新插入的了
if (oldFiber === null) {
for (; newIdx < newChildren.length; newIdx++) {
// 基于新生成的ReactElement创建新的Fiber节点
const newFiber = createChild(returnFiber, newChildren[newIdx], lanes);
if (newFiber === null) {
continue;
}
// 记录固定节点的位置lastPlacedIndex
lastPlacedIndex = placeChild(newFiber, lastPlacedIndex, newIdx);
// 将新生成的fiber节点连接成以sibling为指针的单向链表
if (previousNewFiber === null) {
resultingFirstChild = newFiber;
} else {
previousNewFiber.sibling = newFiber;
}
previousNewFiber = newFiber;
}
return resultingFirstChild;
}
// 执行到这是都没遍历完的情况,把剩余的旧子节点放入一个以key为键,值为oldFiber节点的map中
// 这样在基于oldFiber节点新建新的fiber节点时,可以通过key快速地找出oldFiber
const existingChildren = mapRemainingChildren(returnFiber, oldFiber);
// 节点移动
for (; newIdx < newChildren.length; newIdx++) {
// 基于map中的oldFiber节点来创建新fiber
const newFiber = updateFromMap(
existingChildren,
returnFiber,
newIdx,
newChildren[newIdx],
lanes,
);
if (newFiber !== null) {
if (shouldTrackSideEffects) {
if (newFiber.alternate !== null) {
// 因为newChildren中剩余的节点有可能和oldFiber节点一样,只是位置换了,
// 但也有可能是是新增的.
// 如果newFiber的alternate不为空,则说明newFiber不是新增的。
// 也就说明着它是基于map中的oldFiber节点新建的,意味着oldFiber已经被使用了,所以需
// 要从map中删去oldFiber
existingChildren.delete(newFiber.key === null ? newIdx : newFiber.key);
}
}
// 移动节点,多节点diff的核心,这里真正会实现节点的移动
lastPlacedIndex = placeChild(newFiber, lastPlacedIndex, newIdx);
// 将新fiber连接成以sibling为指针的单向链表
if (previousNewFiber === null) {
resultingFirstChild = newFiber;
} else {
previousNewFiber.sibling = newFiber;
}
previousNewFiber = newFiber;
}
}
if (shouldTrackSideEffects) {
// 此时newChildren遍历完了,该移动的都移动了,那么删除剩下的oldFiber
existingChildren.forEach((child) => deleteChild(returnFiber, child));
}
return resultingFirstChild;
}
# 四、为什么使用虚拟 dom?
很多时候手工优化 dom 确实会比 virtual dom 效率高,对于比较简单的 dom 结构用手工优化没有问题,但当页面结构很庞大,结构很复杂时,手工优化会花去大量时间,而且可维护性也不高,不能保证每个人都有手工优化的能力。至此,virtual dom 的解决方案应运而生。
virtual dom 是“解决过多的操作 dom 影响性能”的一种解决方案。
virtual dom 很多时候都不是最优的操作,但它具有普适性,在效率、可维护性之间达到平衡。
virutal dom 的意义:
- 1、提供一种简单对象去代替复杂的 dom 对象,从而优化 dom 操作
- 2、提供一个中间层,js 去写 ui,ios 安卓之类的负责渲染,就像 reactNative 一样。
# 五、diff 算法的复杂度和特点?
vue2.x 的 diff 位于 patch.js 文件中,该算法来源于 snabbdom,复杂度为 O(n)。了解 diff 过程可以让我们更高效的使用框架。react 的 diff 其实和 vue 的 diff 大同小异。
最大特点:比较只会在同层级进行, 不会跨层级比较。
<!-- 之前 -->
<div> <!-- 层级1 -->
<p> <!-- 层级2 -->
<b> aoy </b> <!-- 层级3 -->
<span>diff</Span>
</p>
</div>
<!-- 之后 -->
<div> <!-- 层级1 -->
<p> <!-- 层级2 -->
<b> aoy </b> <!-- 层级3 -->
</p>
<span>diff</Span>
</div>
对比之前和之后:可能期望将<span>直接移动到<p>的后边,这是最优的操作。
但是实际的 diff 操作是:
- 1、移除
<p>里的<span>; - 2、在创建一个新的
<span>插到<p>的后边。 因为新加的<span>在层级 2,旧的在层级 3,属于不同层级的比较。
# 六、vue 的模板文件是如何被编译渲染的?
vue 中也使用 diff 算法,有必要了解一下 Vue 是如何工作的。通过这个问题,我们可以很好的掌握,diff 算法在整个编译过程中,哪个环节,做了哪些操作,然后使用 diff 算法后输出什么?
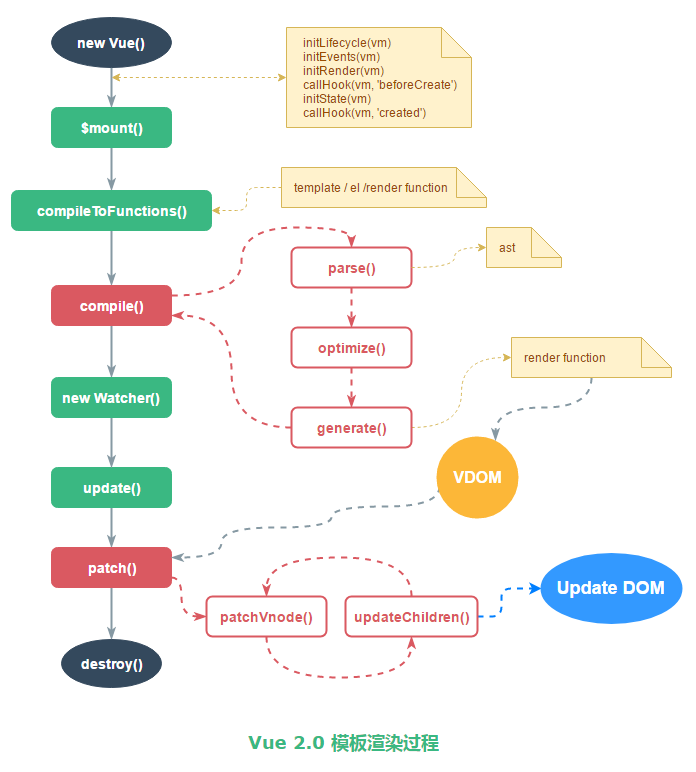
解释:
# 1、mount 函数
mount 函数主要是获取 template,然后进入 compileToFunctions 函数。
# 2、compileToFunction 函数
compileToFunction 函数主要是将 template 编译成 render 函数。首先读取缓存,没有缓存就调用 compile 方法拿到 render 函数的字符串形式,在通过 new Function 的方式生成 render 函数。
// 有缓存的话就直接在缓存里面拿
const key = options && options.delimiters ? String(options.delimiters) + template : template;
if (cache[key]) {
return cache[key];
}
const res = {};
const compiled = compile(template, options); // compile 后面会详细讲
res.render = makeFunction(compiled.render); //通过 new Function 的方式生成 render 函数并缓存
const l = compiled.staticRenderFns.length;
res.staticRenderFns = new Array(l);
for (let i = 0; i < l; i++) {
res.staticRenderFns[i] = makeFunction(compiled.staticRenderFns[i]);
}
// ......
return (cache[key] = res); // 记录至缓存中
# 3、compile 函数
compile 函数将 template 编译成 render 函数的字符串形式。后面我们主要讲解 render
完成 render 方法生成后,会进入到 mount 进行 DOM 更新。该方法核心逻辑如下:
// 触发 beforeMount 生命周期钩子
callHook(vm, 'beforeMount');
// 重点:新建一个 Watcher 并赋值给 vm._watcher
vm._watcher = new Watcher(
vm,
function updateComponent() {
vm._update(vm._render(), hydrating);
},
noop,
);
hydrating = false;
// manually mounted instance, call mounted on self
// mounted is called for render-created child components in its inserted hook
if (vm.$vnode == null) {
vm._isMounted = true;
callHook(vm, 'mounted');
}
return vm;
- 首先会 new 一个 watcher 对象(主要是将模板与数据建立联系),在 watcher 对象创建后,
- 会运行传入的方法 vm._update(vm._render(), hydrating) 。 其中的 vm._render()主要作用就是运行前面 compiler 生成的 render 方法,并返回一个 vNode 对象。
- vm.update() 则会对比新的 vdom 和当前 vdom,并把差异的部分渲染到真正的 DOM 树上。(watcher 背后的实现原理:vue2.x 的响应式原理)
上面提到的 compile 就是将 template 编译成 render 函数的字符串形式。核心代码如下:
export function compile(template: string, options: CompilerOptions): CompiledResult {
const AST = parse(template.trim(), options); //1. parse
optimize(AST, options); //2.optimize
const code = generate(AST, options); //3.generate
return {
AST,
render: code.render,
staticRenderFns: code.staticRenderFns,
};
}
compile 这个函数主要有三个步骤组成:
- parse,
- optimize
- generate
分别输出一个包含
- AST 字符串
- staticRenderFns 的对象字符串
- render 函数 的字符串。
parse 函数:主要功能是将 template 字符串解析成 AST(抽象语法树)。前面定义的 ASTElement 的数据结构,parse 函数就是将 template 里的结构(指令,属性,标签) 转换为 AST 形式存进 ASTElement 中,最后解析生成 AST。
optimize 函数(src/compiler/optomizer.js):主要功能是标记静态节点。后面 patch 过程中对比新旧 VNode 树形结构做优化。被标记为 static 的节点在后面的 diff 算法中会被直接忽略,不做详细比较。
generate 函数(src/compiler/codegen/index.js):主要功能根据 AST 结构拼接生成 render 函数的字符串。
const code = AST ? genElement(AST) : '_c("div")';
staticRenderFns = prevStaticRenderFns;
onceCount = prevOnceCount;
return {
render: `with(this){return ${code}}`, //最外层包一个 with(this) 之后返回
staticRenderFns: currentStaticRenderFns,
};
其中 genElement 函数(src/compiler/codgen/index.js)是根据 AST 的属性调用不同的方法生成字符串返回。
总之:
就是 compile 函数中三个核心步骤介绍,
- compile 之后我们得到 render 函数的字符串形式,后面通过 new Function 得到真正的渲染函数。
- 数据发生变化后,会执行 watcher 中的_update 函数(src/core/instance/lifecycle.js),_update 函数会执行这个渲染函数,输出一个新的 VNode 树形结构的数据。
- 然后调用 patch 函数,拿到这个新的 VNode 与旧的 VNode 进行对比,只有发生了变化的节点才会被更新到新的真实 DOM 树上。
# 4、patch 函数
patch 函数 就是新旧 VNode 对比的 diff 函数,主要是为了优化 dom,通过算法使操作 dom 的行为降低到最低, diff 算法来源于 snabbdom,是 VDOM 思想的核心。snabbdom 的算法是为了 DOM 操作跨级增删节点较少的这一目标进行优化, 它只会在同层级进行,不会跨层级比较。
# 总结一下
- compile 函数主要是将 template 转换为 AST,优化 AST,再将 AST 转换为 render 函数的字符串形式。
- 再通过 new Function 得到真正的 render 函数,render 函数与数据通过 Watcher 产生关联。
- 在数据反生变化的时候调用 patch 函数,执行 render 函数,生成新的 VNode,与旧的 VNode 进行 diff,最终更新 DOM 树。
# 七、vue2.x,vue3.x,React 中的 diff 有区别吗?
总的来说:
- vue2.x 的核心 diff 算法采用双端比较的算法,同时从新旧 children 的两端开始进行比较,借助 key 可以复用的节点。
- vue3.x 借鉴了一些别的算法 inferno(https://github.com/infernojs/inferno (opens new window)) 解决:1、处理相同的前置和后置元素的预处理;2、一旦需要进行 DOM 移动,我们首先要做的就是找到 source 的最长递增子序列。
在创建 VNode 就确定类型,以及在 mount/patch 的过程中采用位运算来判断一个 VNode 的类型,在这个优化的基础上再配合 Diff 算法,性能得到提升。
可以看一下 vue3.x 的源码: https://github.com/vuejs/vue/blob/8a219e3d4cfc580bbb3420344600801bd9473390/src/core/vdom/patch.js (opens new window)
- react 通过 key 和 tag 来对节点进行取舍,可直接将复杂的比对拦截掉,然后降级成节点的移动和增删这样比较简单的操作。
对 oldFiber 和新的 ReactElement 节点的比对,将会生成新的 fiber 节点,同时标记上 effectTag,这些 fiber 会被连到 workInProgress 树中,作为新的 WIP 节点。树的结构因此被一点点地确定,而新的 workInProgress 节点也基本定型。在 diff 过后,workInProgress 节点的 beginWork 节点就完成了,接下来会进入 completeWork 阶段。
# 八、diff 算法的源头 snabbdom 算法
snabbdom 算法: https://github.com/snabbdom/snabbdom (opens new window)
定位:一个专注于简单性、模块化、强大功能和性能的虚拟 DOM 库。
# 1、snabbdom 中定义 Vnode 的类型
snabbdom 中定义 Vnode 的类型(https://github.com/snabbdom/snabbdom/blob/27e9c4d5dca62b6dabf9ac23efb95f1b6045b2df/src/vnode.ts#L12 (opens new window))
export interface VNode {
sel: string | undefined; // selector的缩写
data: VNodeData | undefined; // 下面VNodeData接口的内容
children: Array<VNode | string> | undefined; // 子节点
elm: Node | undefined; // element的缩写,存储了真实的HTMLElement
text: string | undefined; // 如果是文本节点,则存储text
key: Key | undefined; // 节点的key,在做列表时很有用
}
export interface VNodeData {
props?: Props;
attrs?: Attrs;
class?: Classes;
style?: VNodeStyle;
dataset?: Dataset;
on?: On;
attachData?: AttachData;
hook?: Hooks;
key?: Key;
ns?: string; // for SVGs
fn?: () => VNode; // for thunks
args?: any[]; // for thunks
is?: string; // for custom elements v1
[key: string]: any; // for any other 3rd party module
}
# 2、init 函数分析
init 函数的地址:
init() 函数接收一个模块数组 modules 和可选的 domApi 对象作为参数,返回一个函数,即 patch() 函数。
domApi 对象的接口包含了很多 DOM 操作的方法。
# 3、patch 函数分析
源码:
- init() 函数返回了一个 patch() 函数
- patch() 函数接收两个 VNode 对象作为参数,并返回一个新 VNode。
# 4、h 函数分析
源码:
h() 函数接收多种参数,其中必须有一个 sel 参数,作用是将节点内容挂载到该容器中,并返回一个新 VNode。
# 九、diff 算法与 snabbdom 算法的差异地方?
在 vue2.x 不是完全 snabbdom 算法,而是基于 vue 的场景进行了一些修改和优化,主要体现在判断 key 和 diff 部分。
1、在 snabbdom 中 通过 key 和 sel 就判断是否为同一节点,那么在 vue 中,增加了一些判断 在满足 key 相等的同时会判断,tag 名称是否一致,是否为注释节点,是否为异步节点,或者为 input 时候类型是否相同等。
/**
* @param a 被对比节点
* @param b 对比节点
* 对比两个节点是否相同
* 需要组成的条件:key相同,tag相同,是否都为注释节点,是否同事定义了data,如果是input标签,那么type必须相同
*/
function sameVnode(a, b) {
return (
a.key === b.key &&
((a.tag === b.tag &&
a.isComment === b.isComment &&
isDef(a.data) === isDef(b.data) &&
sameInputType(a, b)) ||
(isTrue(a.isAsyncPlaceholder) &&
a.asyncFactory === b.asyncFactory &&
isUndef(b.asyncFactory.error)))
);
}
2、diff 差异,patchVnode 是对比模版变化的函数,可能会用到 diff 也可能直接更新。
function updateChildren(
parentElm,
oldCh,
newCh,
insertedVnodeQueue,
removeOnly
) {
let oldStartIdx = 0;
let newStartIdx = 0;
let oldEndIdx = oldCh.length - 1;
let oldStartVnode = oldCh[0];
let oldEndVnode = oldCh[oldEndIdx];
let newEndIdx = newCh.length - 1;
let newStartVnode = newCh[0];
let newEndVnode = newCh[newEndIdx];
let oldKeyToIdx, idxInOld, vnodeToMove, refElm;
const canMove = !removeOnly;
if (process.env.NODE_ENV !== "production") {
checkDuplicateKeys(newCh);
}
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (isUndef(oldStartVnode)) {
oldStartVnode = oldCh[++oldStartIdx]; // Vnode has been moved left
} else if (isUndef(oldEndVnode)) {
oldEndVnode = oldCh[--oldEndIdx];
} else if (sameVnode(oldStartVnode, newStartVnode)) {
patchVnode(
oldStartVnode,
newStartVnode,
insertedVnodeQueue,
newCh,
newStartIdx
);
oldStartVnode = oldCh[++oldStartIdx];
newStartVnode = newCh[++newStartIdx];
} else if (sameVnode(oldEndVnode, newEndVnode)) {
patchVnode(
oldEndVnode,
newEndVnode,
insertedVnodeQueue,
newCh,
newEndIdx
);
oldEndVnode = oldCh[--oldEndIdx];
newEndVnode = newCh[--newEndIdx];
} else if (sameVnode(oldStartVnode, newEndVnode)) {
// Vnode moved right
patchVnode(
oldStartVnode,
newEndVnode,
insertedVnodeQueue,
newCh,
newEndIdx
);
canMove &&
nodeOps.insertBefore(
parentElm,
oldStartVnode.elm,
nodeOps.nextSibling(oldEndVnode.elm)
);
oldStartVnode = oldCh[++oldStartIdx];
newEndVnode = newCh[--newEndIdx];
} else if (sameVnode(oldEndVnode, newStartVnode)) {
// Vnode moved left
patchVnode(
oldEndVnode,
newStartVnode,
insertedVnodeQueue,
newCh,
newStartIdx
);
canMove &&
nodeOps.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm);
oldEndVnode = oldCh[--oldEndIdx];
newStartVnode = newCh[++newStartIdx];
} else {
if (isUndef(oldKeyToIdx))
oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx);
idxInOld = isDef(newStartVnode.key)
? oldKeyToIdx[newStartVnode.key]
: findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx);
if (isUndef(idxInOld)) {
// New element
createElm(
newStartVnode,
insertedVnodeQueue,
parentElm,
oldStartVnode.elm,
false,
newCh,
newStartIdx
);
} else {
// vnodeToMove将要移动的节点
vnodeToMove = oldCh[idxInOld];
if (sameVnode(vnodeToMove, newStartVnode)) {
patchVnode(
vnodeToMove,
newStartVnode,
insertedVnodeQueue,
newCh,
newStartIdx
);
oldCh[idxInOld] = undefined;
canMove &&
nodeOps.insertBefore(parentElm, vnodeToMove.elm, oldStartVnode.elm);
} else {
// same key but different element. treat as new element
createElm(
newStartVnode,
insertedVnodeQueue,
parentElm,
oldStartVnode.elm,
false,
newCh,
newStartIdx
);
}
}
// vnodeToMove将要移动的节点
newStartVnode = newCh[++newStartIdx];
}
}
// 旧节点完成,新的没完成
if (oldStartIdx > oldEndIdx) {
refElm = isUndef(newCh[newEndIdx + 1]) ? null : newCh[newEndIdx + 1].elm;
addVnodes(
parentElm,
refElm,
newCh,
newStartIdx,
newEndIdx,
insertedVnodeQueue
);
// 新的完成,老的没完成
} else if (newStartIdx > newEndIdx) {
removeVnodes(oldCh, oldStartIdx, oldEndIdx);
}
}